
为弥补目前社区在生产环境可用的支持 GBDT 模型、GBDT+FM 二分类模型及 GBDT+FM 多分类模型部署的推理系统的空白,爱奇艺设计开发了灵活、高性能的 XGBoost Serving 推理系统,并在内部多个业务落地使用。近期,爱奇艺决定将这一系统开源,本文将详细介绍项目开发背景、系统实践、系统特性和架构及实现等内容。
系统背景及简介
2014 年,Facebook 首先提出了 GBDT + LR(Logistics Regression) [5] 的模型结构,利用 GBDT 自动组合特征生成新的特征向量,该特征向量再作为输入进入 LR 计算得到最后的结果,实验表明该模型结构较单独使用 GBDT 或者 LR ,能使效果提升至少 3%。
现代推荐系统或广告系统通常会使用高维稀疏特征如视频 ID 特征等来增强模型的记忆能力,由于 GBDT 不支持高维稀疏特征,如果使用 GBDT + LR 模型结构,则不可避免地要在 LR 模型中人工做特征组合,同时模型的计算复杂度也会变高。
因此,爱奇艺内部目前使用 FM 来替换 LR 模型部分,该模型结构支持高维稀疏特征及自动二阶特征组合。
实验表明,GBDT + FM 模型较 GBDT + LR 模型效果提升至少 4%。
GBDT + FM 模型经过训练及评估后,需要在推理系统上线落地才能产生实际的收益。社区现有的成熟推理系统 TensorFlow Serving [6] 只支持 TenosorFlow 模型,且没有明确计划支持其它框架的模型;其它推理系统诸如 zoltar [7]、kfserving XGBoost Server [8] 等只支持单独的 GBDT 或者 FM 模型推理,不支持多模型、多版本部署,不支持模型生命周期管理,且其非 C++ 原生实现性能较差。
因此,我们针对生产环境设计并开发了灵活、高性能的 XGBoost Serving 推理系统,支持 GBDT + FM 模型的在线推理。XGBoost Serving 是在 TensorFlow Serving 的基础上开发的,增加了 XGBoost Servable、alphaFM Servable 及 alphaFM_softmax Servable,分别用于支持纯 GBDT 模型在线推理、GBDT + FM 二分类模型在线推理及 GBDT + FM 多分类模型在线推理。
XGBoost Serving 现已在 GitHub 开源,地址为:https://github.com/iqiyi/xgboost-serving。
注:GBDT(Gradient Boosted Decision Tree) [1] 是常用的机器学习算法之一,其具有较高的准确率和出色的特征组合能力。XGBoost(eXtreme Gradient Boosting) [2] 是支持 GBDT 算法的一个高性能、可扩展、分布式实现,在 Kaggle 等数据科学竞赛及企业生产环境具有广泛应用。FM(Factorization Machines) [4] 是一个支持特征交叉的机器学习算法,对稠密特征和稀疏特征均具有良好的适用性,且其推理计算复杂度呈线性,在计算广告和推荐系统的 CTR(Click Through Rate) 点击率预估环节具有广泛应用。
推荐中台落地 XGBoost Serving 实践
XGBoost Serving 具体是如何落地的?效果又如何呢?
本节先以爱奇艺推荐中台落地 GBDT + FM 二分类模型为例,介绍如何使用 XGBoost Serving 推理系统。
在没有 XGBoost Serving 推理系统的年代,爱奇艺推荐中台在推荐引擎中支持 GBDT + FM 二分类模型部署。推荐引擎是整个推荐流程中非常复杂的一个模块,由于算法规则、深度模型、浅层模型盘根错节,很难保证计算过程不会相互干扰;多模型、多版本的生命周期管理需要人工介入。
有了 XGBoost Serving 推理系统后,推荐中台可以将模型部署及模型生命周期管理部分托管至 XGBoost Serving,自身聚焦于引擎业务逻辑调用。
如此一来,引擎不再需要关注模型计算部分,且人工管理模型生命周期的日子也一去不复返了。推荐中台使用 XGBoost Serving 的流程如图 1:

图 1 推荐中台使用 XGBoost Serving 流程
推荐中台训练好 GBDT + FM 二分类模型后,指定数字版本号,并将该版本的模型放入配置的路径下,XGBoost Serving 即会根据配置的 Servables 类型和 Version Policy 确定是否执行加载模型的操作。
如果模型加载成功,则 XGBoost Serving 会分别启动 GRPC 服务、HTTP 服务和 Metrics 服务。更新模型时,只需使用新的版本号命名模型并将该版本的模型放入配置的路径下即可,XGBoost Serving 会自动管理配置路径下的模型的生命周期。部署及更新操作可通过流水线任务流进一步自动化。
模型部署成功后,推荐中台在引擎侧使用 XGBoost Serving 提供的 GRPC 服务访问对应的模型,使用 HTTP 服务查看各模型的状态,使用 Metrics 服务监控模型的计算延时分布。
同等负载压力下,使用 XGBoost Serving 后,P99 长尾计算延时较引擎侧部署至少降低 50%。
了解了具体的落地效果后,我们再来详细了解下 XGBoost Serving 的系统特性和架构实现细节。
系统架构及实现
XGBoost Serving 是在 TensorFlow Serving 的基础上开发的,为了了解 XGBoost Serving 的架构及实现,首先需要了解 TensorFlow Serving 中的核心概念及架构。TensorFlow Serving 主要有以下核心概念:
(1)Servables
Servables 是 TensorFlow Serving 中最核心的抽象,表示用来执行具体计算的对象,如 TensorFlow SavedModel。
(2) Servable Versions
1 个 Servable 可以拥有多个 Versions。TensorFlow Serving 支持同时加载多个 Servable Versions。
(3) Loaders
Loaders 负责管理 Servables 的生命周期,提供标准化的独立于具体算法或者数据的加载和卸载 Servables 的 APIs。
(4) Sources
Sources 负责发现 Servables。Sources 支持本地文件系统等任意类型的存储系统。
(5) Aspired Versions
Aspired Versions 表示一组需要加载的 Servable Versions。
(6) Managers
Managers 负责管理 Servables 的完整生命周期,包括加载 Servables、服务 Servables 及卸载 Servables。
TensorFlow Servable 的生命周期如图 2:
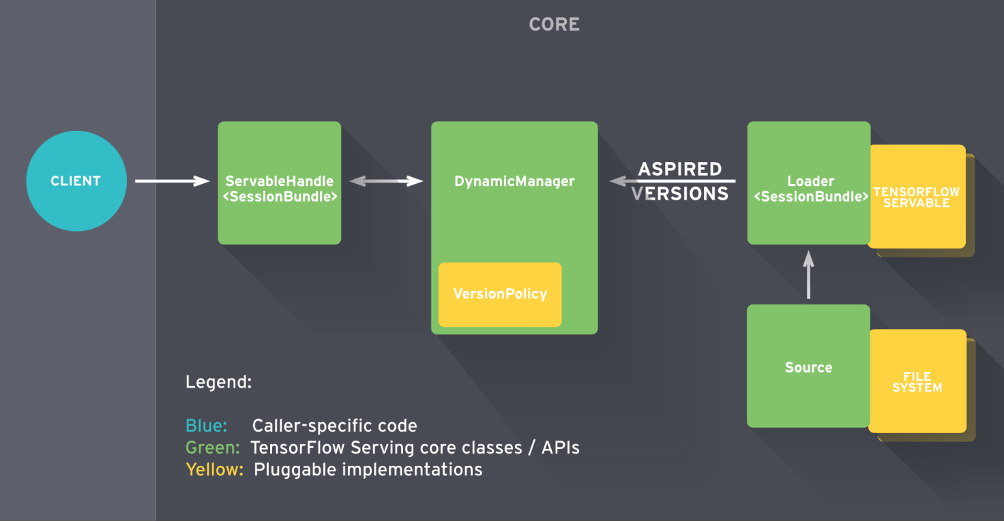
图 2 TensorFlow Servable 生命周期
Source 监听文件系统发现新的 Servable Version 后,创建 1 个 Loader,该 Loader 包括 1 个指向文件系统中模型数据的指针。Source 通过回调函数将 Aspired Versions 传递给 Manager。
Manager 根据配置的 Version Policy 执行加载新 Version 或者卸载旧 Version 的操作。Client 通过 Manager 来访问 Servable,可以访问指定版本的 Servable 或者缺省访问最新版本的 Servable。
了解了 TensorFlow Serving 的核心概念及架构后,我们发现开发 XGBoost Serving 最核心的部分是开发新的 Servables 支持 GBDT + FM 二分类模型计算、GBDT + FM 多分类模型计算及纯 GBDT 模型计算,然后将新的 Servables 集成到 Model Server 中,从而对外提供服务。
XGBoost Serving 的架构如图 3:
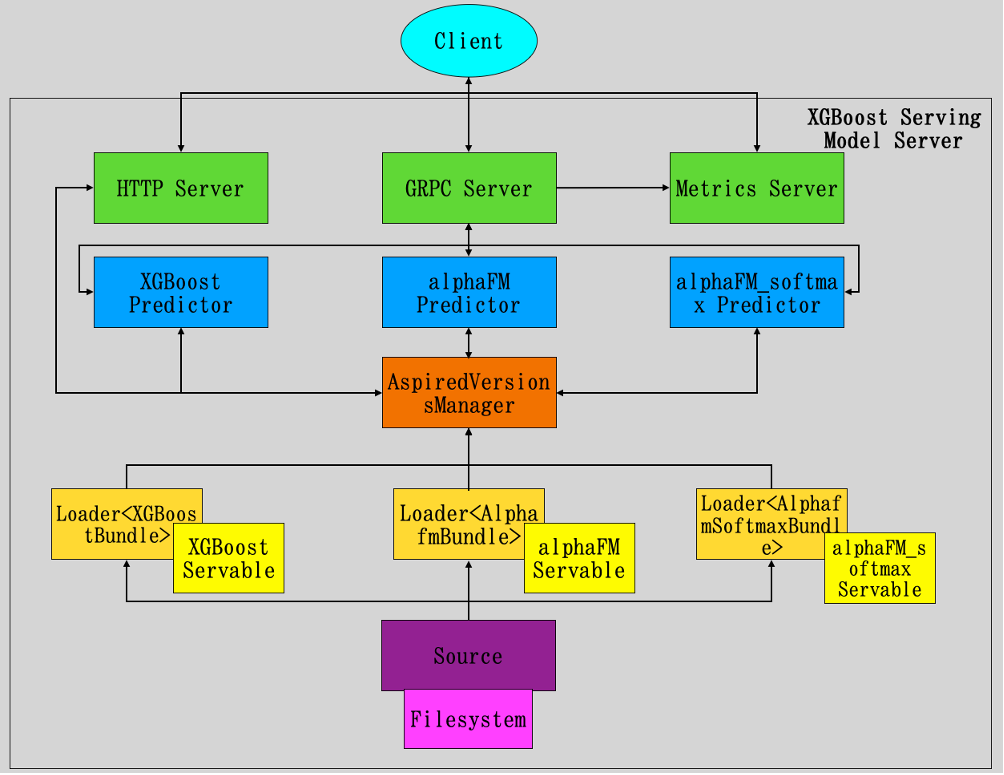
图 3 XGBoost Serving 架构
XGBoost Serving 的架构自底向上共分为 5 层:
(1) Source
(2) Servables
(3) AspiredVersionsManager
(4) Predictors
(5) Servers
Source 层通过定期 poll 文件系统中指定的路径来发现 Servables,支持配置 poll 文件系统的路径、poll 文件系统的时间间隔及 Servables 的加载策略等。
Servables 层共支持 3 种 Servables:
(1) XGBoost Servable
(2) alphaFM Servable
(3) alphaFM_softmax Servable
XGBoost Servable 支持纯 GBDT 模型的在线推理,其支持的模型为 XGBoost 导出的二进制 GBDT 模型。
alphaFM Servable 支持 GBDT + FM 二分类模型的在线推理,其合法的模型包括 GBDT 模型、FM 二分类模型及 FeatureMapping 模型 3 部分,GBDT 模型为 XGBoost 导出的二进制 GBDT 模型,FM 二分类模型为 FM 二分类算法训练导出的模型,FeatureMapping 模型为 GBDT 模型叶子节点转换为特征映射的模型文件。
alphaFM_softmax Servable 支持 GBDT + FM 多分类模型的在线推理,其合法的模型包括 GBDT 模 型、FM 多分类模型及 FeatureMapping 模型 3 部分,GBDT 模型和 FeatureMapping 模型同 alphaFM Servable 支持的相应模型,FM 多分类模型为 FM 多分类算法训练导出的模型。
AspiredVersionsManager 层通过 aspired-versions 的回调函数来确定加载及卸载哪些 Servables。AspiredVersionsManager 使用 AvailabilityPreservingPolicy 控制策略。
Predictors 层共支持 3 种 Predictors:
(1)XGBoost Predictor
(2)alphaFM Predictor
(3)alphaFM_softmax Predictor
XGBoost Predictor 使用 XGBoost Servable 计算,支持计算叶子节点的索引和计算值。
alphaFM Predictor 使用 alphaFM Servable 计算,GBDT 输入特征经过 GBDT 模型计算得到叶子节点的索引,叶子节点的索引经过 FeatureMapping 转换为特征 ID,GBDT 输入特征、FeatureMapping 转换的特征以及 FM 输入特征最终进入 FM 二分类模型进行计算并返回结果。
alphaFM_softmax Predictor 使用 alphaFM_softmax Servable 计算,计算过程和 alphaFM Predictor 相似,不同之处为 GBDT 输入特征、FeatureMapping 转换的特征以及 FM 输入特征最终进入 FM 多分类模型进行计算并返回结果。
Servers 层共支持 3 种类型的 Servers:
(1)GRPC Server
(2) HTTP Server
(3)Metrics Server
GRPC Server 对外提供 GRPC 在线推理服务,对不同类型的 Servables 提供不同的 APIs。
HTTP Server 对外提供 HTTP 模型管理服务,包括查看模型各版本的状态等。
Metrics Server 对外提供 Metrics 监控服务,包括 QPS、计算延时分布等监控数据。
总结
本文介绍了 XGBoost Serving 推理系统,包括开发背景、系统实践、系统特性和架构及实现等部分,该系统填补了社区没有生产环境可用的支持 GBDT 模型、GBDT + FM 二分类模型及 GBDT + FM 多分类模型部署的推理系统的空白,已经在爱奇艺内部多个业务落地使用,现在 GitHub 上开源,详见:https://github.com/iqiyi/xgboost-serving,欢迎使用、反馈 Issues 及提交 Pull-Requests。
参考文献
[1] J. Friedman. Greedy function approximation: a gradient boosting machine. Annals of Statistics, 29(5):1189–1232, 2001.
[2] Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM; 2016. p. 785–794.
[3] https://github.com/dmlc/xgboost
[4] S. Rendle, Factorization machines. In Proceedings of IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010.
[5] Xinran He et al, Practical Lessons from Predicting Clicks on Ads at Facebook. In ADKDD’14, August 24 - 27 2014, New York, NY, USA.
[6] https://github.com/tensorflow/serving
[7] https://spotify.github.io/zoltar/
[8] https://github.com/kubeflow/kfserving
[9] https://github.com/CastellanZhang/alphaFM
[10]https://github.com/CastellanZhang/alphaFM_softmax
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)




