
大语言模型(LLM)能力正在迅速提升,对包括软件工程在内的诸多行业产生了深远影响。GPT-4o、Claude3.5 等 LLM 已经逐步展现出胜任复杂任务的能力,例如文本总结、智能客服、代码生成,甚至能够分析和解决数学问题。在这一趋势下,AI Agent,即能够感知外部环境、操作工具并具有一定自主决策能力的智能体,受到了越来越多的研究关注。
豆包 MarsCode 在软件工程领域进行了一系列关于 AI Agent 应用的探索和尝试,通过构建 Agent 框架并为其提供代码检索、调试和编辑的交互接口和工具,使得 Agent 有可能接管部分软件工程开发任务。
在 Agent 框架方面,豆包 MarsCode 开发了多 Agent 协作框架,根据所要解决软工问题类型,分配静态或动态求解管道,从而灵活适配多样的软件工程问题;
在代码检索能力方面,豆包 MarsCode 结合代码知识图谱和语言服务,为 Agent 提供全面的代码实体召回、关系召回、定义与引用跳转等能力,从而使 Agent 具备人类开发者类似的代码浏览、分析过程;
在代码编辑方面,豆包 MarsCode 采用 Conflict 形式的代码编辑描述和静态语法检查,能够准确生成格式正确的代码编辑补丁;
在软件动态调试方面,豆包 MarsCode 基于 Docker 的容器化沙箱环境,让 Agent 具备了人类开发者的调试能力,比如缺陷复现、添加日志和运行测试框架等。
SWE-bench Lite 是由普林斯顿大学提出的一个极具挑战性的、针对 LLM 解决真实 GitHub Issue 的 benchmark,近期受到工业界、学术界和创业团队的广泛关注。近日,豆包 MarsCode Agent 在 SWE-bench Lite 排行榜上位列第一。

多 Agent 协作框架
开发者在日常的开发工作中常常会遇到各种问题,例如:
运行测试用例报错,有错误或异常堆栈等,这可能是由于代码逻辑错误或测试断言失败导致的问题;
代码输出结果不符合预期,没有显式的报错信息,但有明确的输出结果预期;
需要对现有功能进行扩展或增加新功能,有明确的开发需求及预期结果,但不知道如何实现和在哪实现;
需要进行简单的缺陷修复,有大致的修复思路,但不熟悉语言特性需要协助。
上述多样化的程序修复和开发任务通常无法用一种固定的模式来进行处理。例如,一些简单的缺陷修复或功能扩展仅需对代码进行 review 即可完成;而较深的异常堆栈或复杂的逻辑错误仅凭阅读代码往往很难发现问题所在,需要通过动态执行代码并追踪相关变量才能暴露出相关缺陷,从而对其进行修复。
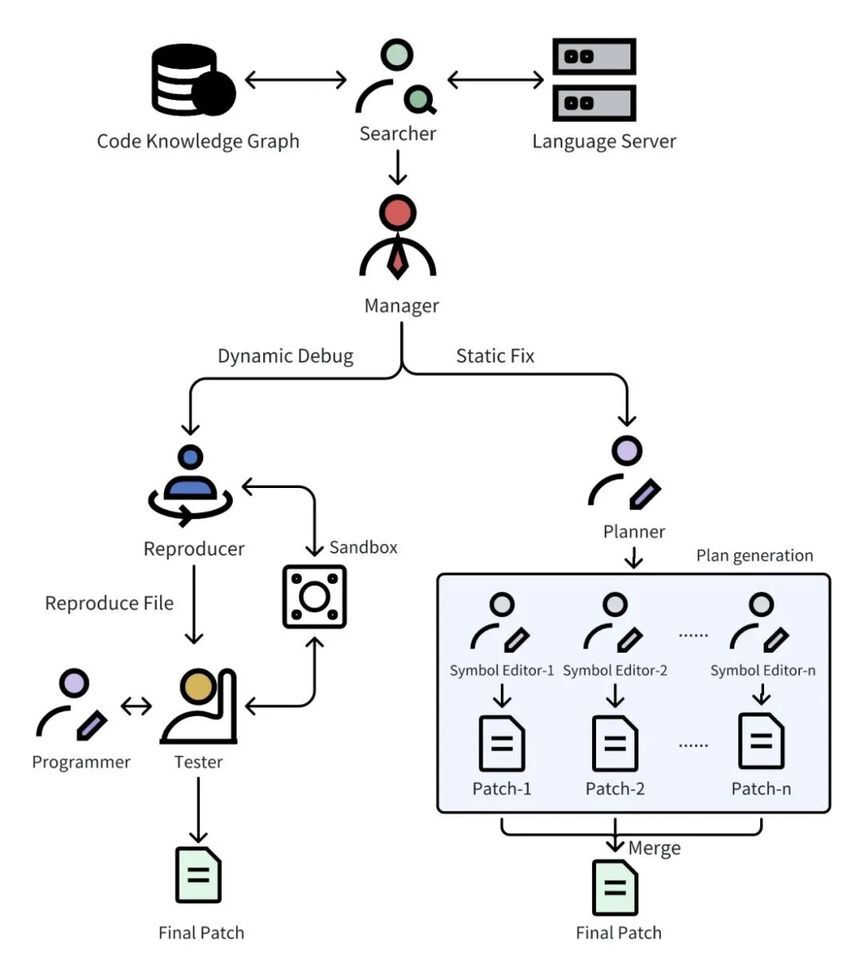
因此,我们采用了多 Agent 协作的框架来适应不同的开发场景。如下图所示,多 Agent 协作框架中包含以下 7 类角色:
Searcher:利用 CKG、LSP 等代码检索工具收集与当前问题相关的 repo 内代码片段;
Manager:根据收集到的相关代码片段对问题进行定性和分流,将问题场景分为动态调试修复和静态修复两类;
Reproducer:在动态调试修复场景下,根据相关代码和问题描述编写复现脚本,并在沙箱中对脚本进行动态调试以确认复现成功;
Programmer:根据问题描述和相关代码进行编辑代码,并结合 Tester 的测试结果进行多轮迭代修改;
Tester:根据问题复现脚本,对当前代码版本进行动态验证,检查问题是否得到解决;
Planner:在静态修复场景下,根据问题和相关代码,制定求解计划,规划需要修改哪些代码片段及其修改方式;
Symbol Editor:根据修改计划,对所负责的代码 Symbol 进行修改,返回修改补丁。
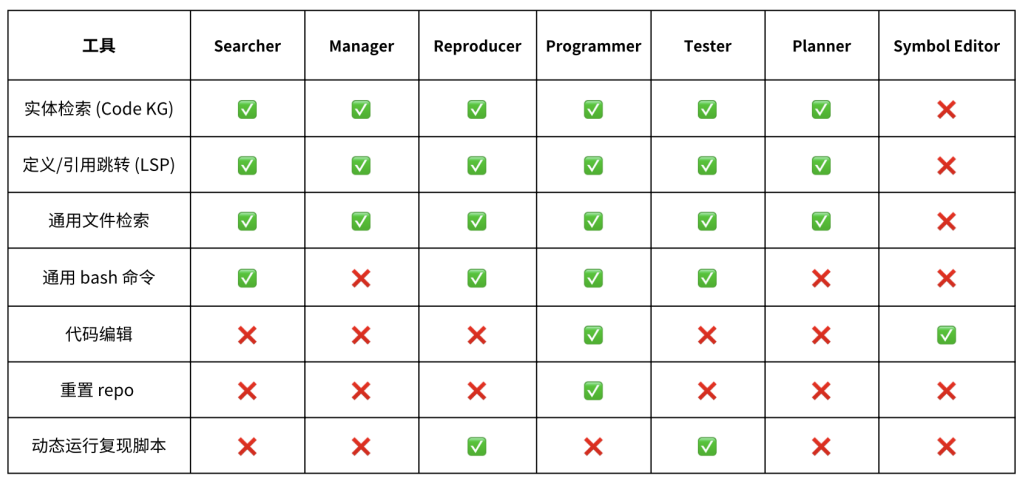
我们为不同的 Agent 配备了相应的工具集以支撑其完成指定任务,各 Agent 配备的工具集如下表所示。值得注意的是,我们并没有令每个 Agent 都拥有所有工具的使用权,而是尝试限制各个 Agent 的能力和职责范围,从而降低单个 Agent 解决当前环节问题的难度,以提高任务执行的稳定性和输出结果的质量。
在动态调试修复场景下,各 Agent 的协作求解流程如下:
由 Reproducer 根据描述对问题进行复现,生成与问题描述相符的复现脚本;
将复现脚本提供给 Tester 进行验证,将复现脚本运行得到的异常堆栈和其他输出信息提供给 Programmer 进行修复;
Programmer 完成修复后向 Tester 提出测试请求;
Tester 再基于复现脚本进行验证,并判断问题是否解决:
a.若问题已解决,则通过 diff 工具获取当前代码变更作为该问题的修复方案,动态调试结束;
b.若仍未解决,则再次将复现过程中异常堆栈和其他输出信息返回给 Programmer;
Programmer 可根据 Tester 的报错信息,选择继续修改,或重置 repo 放弃过往编辑,重新进行修改。直至提交测试给 Tester 验证通过为止。
在动态过程中,我们通过在 Docker 容器中搭建一个运行环境沙箱,以实现动态调试的问题复现和运行验证。
在静态修复场景下,由于无法直接对问题进行复现和动态验证,需要制定针对该问题的静态修复方案。过程如下:
由 Planner 根据检索到的相关代码片段,收集更多代码上下文,制定修改方案,修改方案以代码符号(Symbol)为单位组成,每条修改意见包含需要修改代码所在的 Symbol 名(类、函数、Top-Level 变量等)、修改处所在文件、该 Symbol 的代码行号范围、修改描述;
在生成修改方案的过程中,我们采用了一些轨迹采样和搜索的策略,使生成的 plan 有较高的准确性;
针对修改方案中的每一个 Symbol,实例化出一个 Symbol Editor,用于完成改 Symbol 的修改计划,每个 Symbol Editor 完成后通过 git commit 提交修改;
完成所有 Symbol 的修改后,将当前代码状态与 Base commit 进行差异对照,生成最终补丁作为该问题的修复方案。
代码检索
我们为豆包 MarsCode Agent 提供了多种可跨语言适配的代码检索工具,以适应各种软件工程开发场景下的代码检索需求。
代码知识图谱 Code Knowledge Graph
代码知识图谱是将代码元素、属性以及元素之间的关系表示为图结构,从而帮助 Agent 更好地理解和管理大规模的代码库。在这种图结构中,顶点代表代码的实体(如函数、变量、类等),边则代表实体之间的关系(如函数调用、变量引用、类的继承关系等)。通过这种方式,代码知识图谱可以为代码库提供更丰富且结构化的信息。
我们通过程序分析的技术,将仓库中的代码,文档信息进行分析组织,生成一个以变量,函数,类,文件等代码语义节点为实体,文件结构关系、函数调用关系,符号索引关系为边的多向图。构成一张融合了代码,文档,仓库信息等多数据源的代码知识图谱。
在给定的代码库中,每个节点和边都通过唯一标识符进行标记,确保每个代码实体在整个代码库中都是唯一的。在这种设计中,代码知识图谱将使用图属性来存储代码实体及其依赖关系。每个节点记录其在代码库中的位置、类型和名称。每条边标识两个节点之间的关系类型,以及关系在代码中的位置。
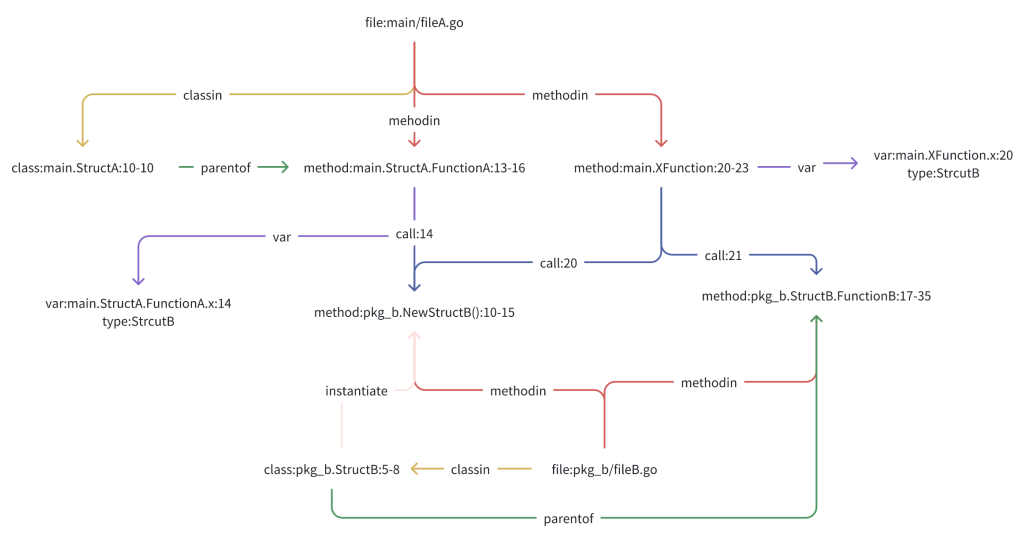
比如对下面这样一段代码:
// file: main/fileA.gopackage mainimport ( "ckg-prompt/main/cmd/pkg_b" "fmt")// StructA structtype StructA struct{}// FunctionA method for StructAfunc (a *StructA) FunctionA() pkg_b.StructB { x := pkg_b.NewStructB() // Instantiate StructB return x}// XFunction functionfunc XFunction() { x := pkg_b.NewStructB() // Instantiate StructB x.FunctionB() // Calls FunctionB}它的代码知识图谱如下图所示:
在构建完成代码知识图谱后,Agent 的代码检索请求将通过下图中的管道进行处理并实现召回。
将 Agent 的问题与代码语句(如有),通过模型进行实体识别,得到实体 mention + 类型,然后在知识图谱中进行 SQL 搜索查询,查询结果标记为候选实体列表 1;
将 Agent 的问题与代码语句(如有),进行 embedding,在知识图谱中进行 embedding 相似度匹配,取相似度最高的一批实体,为候选实体列表 2;
将 Agent 的问题直接通过关键词识别构造查询语句,在知识图谱中进行 SQL 搜索查询,查询结果标记为候选实体列表 3。
最后将候选实体列表 1 & 2 & 3 进行合并,通过精排模型,得到最终实体列表 X,返回给 Agent,完成代码检索。
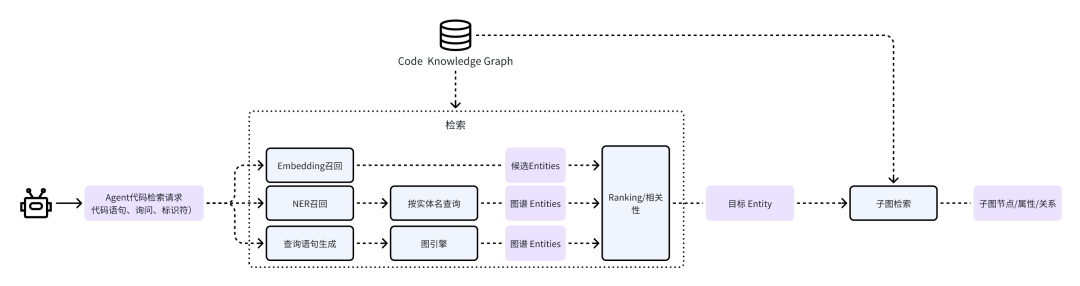
在豆包 MarsCode Agent 中,代码知识图谱工具能够实现广泛、全面的代码检索,为 Agent 提供了 repo 内知识问答的能力。目前,代码知识图谱支持包含 C、C#、CPP、Java、Kotlin、Javascript、Typescript、TSX、Rust、Golang、Python、Lua 在内的 12 种常用编程语言。
语言服务器协议 Language Server Protocol
代码知识图谱能够应对大部分目标工程下的类、函数定义与引用的检索需求,但仍存在以下盲区:
代码知识图谱是对目标工程进行构建,而目标工程外(如标准库、第三方库等)的类、函数、变量的定义和引用是无法通过代码知识图谱被准确召回的;
对于库中存在多个重名实体的情况,LSP 相比代码知识图谱能够更准确地跳转到相关类或函数定义,避免召回和 Rerank 过程带来的遗漏或冗余;
为解决上述问题,豆包 MarsCode Agent 利用通用的语言服务协议(Language Server Protocol)实现用户机器上全局、精确的代码召回。
语言服务器协议是一种由 Microsoft 开发的协议,广泛适配包含编程语言、标记语言、多种工具和框架在内的语法体系,在 IDE 场景下具有很好的通用性。豆包 MarsCode Agent 调用语言服务器协议实现代码召回的过程如下图所示:

Agent 调用语言服务器进行代码召回的过程与开发者在 IDE 中使用“Ctrl+左键”点击某个标识符进行代码跳转的过程是一致的,但由于 Agent 的数字定位和计算能力较弱,我们增加了模糊定位功能以进一步强化 Agent 使用 LSP 工具的能力:
根据 Agent 的提供的文件名和行号,在该行内寻找标识符并计算列号,构成 LSP 请求;
根据 Agent 的提供的文件名和行号,在该行附近寻找标识符并计算列号,构成 LSP 请求;
根据 Agent 的提供的标识符和行号,在 Agent 打开和浏览过的文件中寻找标识符,并构成 LSP 请求。
这三个服务的优先级自上而下由高到低,使用第一个成功得到响应的 LSP 请求结果作为工具的输出。
其他通用检索能力
除 LSP 和 CKG 外,我们将通用的项目内文件检索(find file)、项目或文件内标识符检索(grep)等能力在豆包 MarsCode Agent 框架下进行统一的封装,从而为 Agent 提供调用风格一致的代码检索工具库。
代码编辑
代码编辑描述
在我们对研发域 AI Agent 的长期探索过程中,尝试了各种使用 LLM 进行代码编辑描述的方式,发现目前 LLM 的代码修改能力普遍较弱。如下是我们曾经探索(失败)过的代码编辑方案:
要求 Agent 生成 Unified diff 格式的代码变更描述;
Unified diff 格式的变更是将原始文件和修改后文件以一种统一的方式展示出来,比如:
--- example.txt+++ example.txt@@ -1,4 +1,4 @@ This is a sample file.-It contains multiple lines of text.-Here is another line.-Goodbye!+It contains a few lines of text.+Here is yet another line.+See you later!Unified diff 的代码编辑描述有着非常严格的格式要求,而且 LLM 很难正确计算变更的代码行号增量,从而导致生成的 Unified diff 无法成功 apply。
要求 Agent 提供代码变更的起始行号、终止行号和替换的代码片段;
我们在所有的代码检索的结果中都对代码添加了行号,希望 Agent 能正确填写修改范围并完成修改,然而即便是 GPT-4,也不能完全正确地提供需要修改的代码范围,时常会出现 1~2 行的偏移,从而导致修改后出现重复行或误删;
对整个文件进行重写;
为 LLM 提供整个文件的内容和修改描述,要求 LLM 输出修改后的完整文件内容。这种方式能够避免 LLM 进行行号的计算,但显然每次代码编辑都使用闭源模型生成整个文件是非常不经济的,且在一些长文件中几乎不可用。我们也正在尝试通过 SFT 获取一个专门的代码编辑模型实现全文重写的能力,但这是一个长期计划。
经过大量的探索和尝试,我们认为 LLM 的代码编辑描述需要具备以下特点:
不需要严格的格式校验,编辑描述在经过处理和解析后能够稳定 apply;
不需要提供行号范围,或进行行号计算,LLM 在这方面的能力很不稳定;
出于 token 成本和时间成本的考虑,编辑描述要简明,不包含冗余信息。
基于此,我们注意到 Aider 的代码变更方式(https://aider.chat/docs/benchmarks.html#the-benchmark),受此启发并开发了我们目前认为相对稳定的代码编辑:豆包 MarsCode AutoDiff。
AutoDiff 的代码编辑描述与 git 冲突的表现方式是类似的,Agent 需要在 Conflict 标识栅栏中提供需要编辑的文件路径、代码原文、替换代码。AutoDiff 会对该代码编辑块进行解析,尝试在给定文件中匹配与 LLM 提供代码原文片段相似度最高的片段,并用 LLM 提供的替换代码进行替换操作,随后结合修改文件的上下文对替换代码的缩进进行自动调整。最后修改前后的文件进行差异对照从而获取 Unified diff 格式的变更文件。上述修改是模拟进行的,并未实际在用户设备上落盘,只是为了获取 Unified diff 格式的变更文件,最终代码修改需要经过后续的静态代码诊断。
```diffs/playground/swe_ws/testbed/matplotlib__matplotlib__3.6/lib/matplotlib/figure.py<<<<<<< SEARCH elif constrained_layout is not None:======= elif constrained_layout in [None, False]:>>>>>>> REPLACE<<<<<<< SEARCH else:======= elif constrained_layout in [None, False]: self.set_layout_engine(layout='none')>>>>>>> REPLACE静态代码诊断
尽管 AutoDiff 能够正确完成大部分的代码编辑请求,但仍然会存在诸如类型错误、变量未定义、缩进调整错误、括号没有正确闭合等 LLM 常见的代码编辑语法问题,针对这些问题,我们使用语言服务器协议对 AutoDiff 修改前后的文件进行静态代码诊断,过程如下:
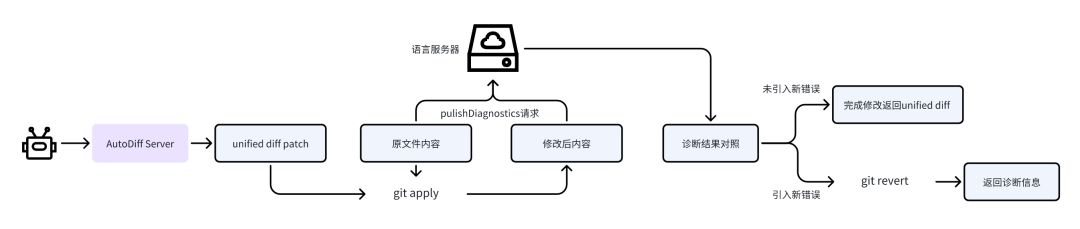
对 AutoDiff 生成的 Unified diff 格式的代码编辑补丁在原文件上进行 apply,得到修改后的文件内容;
对原文件内容进行 LSP 静态代码诊断,保存诊断结果;
对修改后文件内容进行 LSP 静态代码诊断,保存诊断结果;
对两次代码诊断结果进行对照,检查 Agent 的诊断结果是否引入新的静态错误(只关注 Fatal 和 Error 级别的诊断结果);
如果未引入新错误,则完成修改并向 Agent 返回修改成功的消息和相应的 Unified diff 描述;
如果引入了新错误,则将相关诊断信息返回给 Agent 进行修改和调整。
实验结果分析
我们在 SWE-bench Lite 数据集上对豆包 MarsCode Agent 的性能进行了详细评测。
SWE-bench 是由普林斯顿大学提出了一个极具挑战性的针对 LLM 解决程序逻辑 bug 的 benchmark。该数据集整理了真实的来自 Github 的 12 个工业级 Python 代码大仓中的 2294 个 issue 问题。给定一个代码库以及对要解决 issue 问题描述, Agent 需要从代码仓中检索并编辑代码,最终提交能解决相关问题的代码补丁。 在 SWE-bench 中解决问题通常需要同时理解和协调多个函数、类甚至文件之间的更改,要求模型与执行环境交互,处理极长的上下文并执行比传统代码生成更复杂的推理。作者评估表明,Claude2 和 GPT4 仅能解决其中 4.8%和 1.7%的实例。
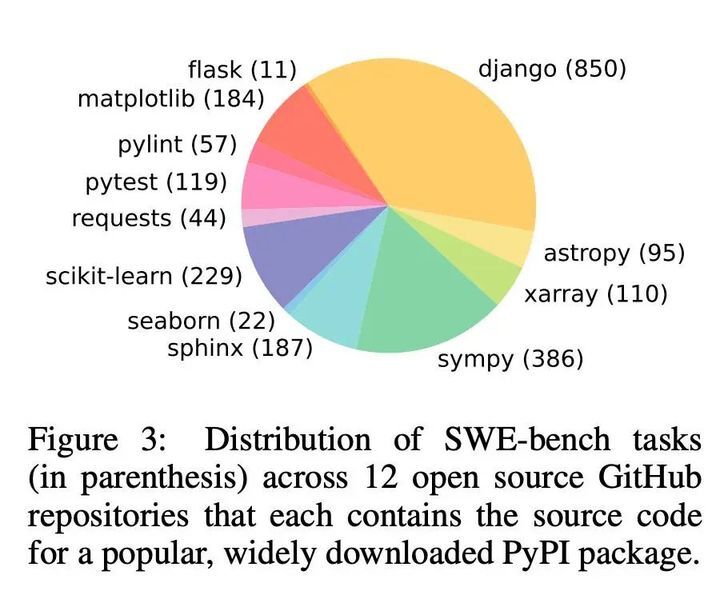
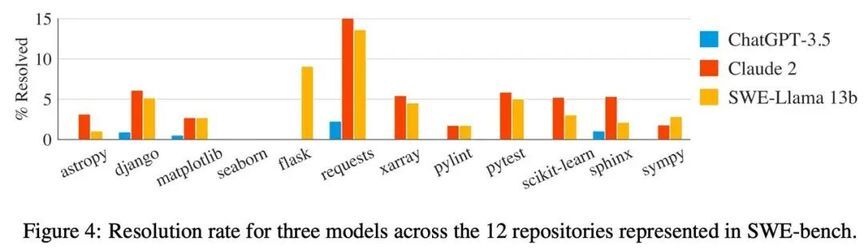
由于 SWE-bench 的难度很大,在后续的研究中,开发者们发现在 SWE-bench 的 2294 个实例上进行评测是一个时间与 Token 投入巨大且令人沮丧的过程,无法验证短期内的进展。所以 SWE-bench 作者从原本的数据集中抽取了 300 个 Issue 描述完整、求解逻辑清晰、相对易于解决的 300 个实例,组成 SWE-bench Lite 数据集。目前,SWE-bench Lite 数据集已经成为 Agent 解决软件工程问题水平的评测标杆,已有 20 多家企业与研究组织参与了 SWE-bench Lite 评测和提交中。
豆包 MarsCode Agent 在最新的 SWE-bench Lite 评测实验中,成功求解了其中的 118 个实例,求解率达到 39.33%。
下表展示了评测实验结果的详细分析:
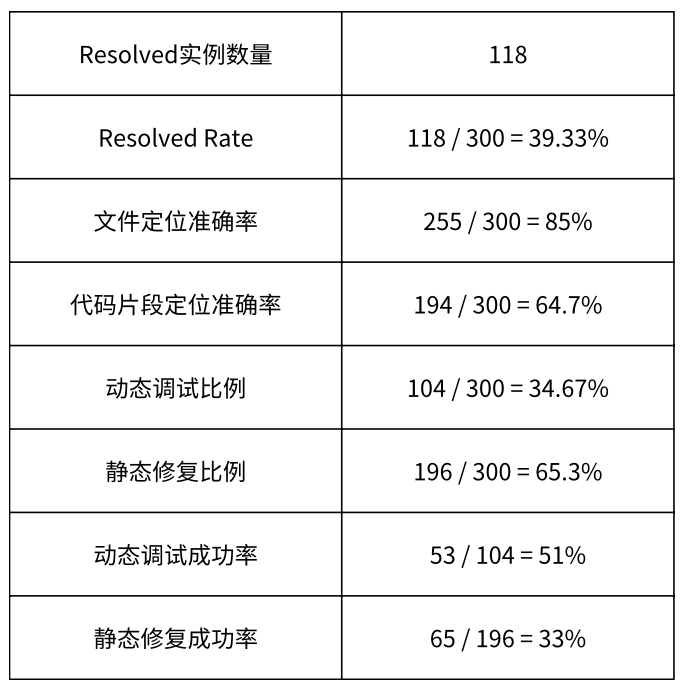
豆包 MarsCode Agent 的错误定位能力
我们对目前 SWE-bench Lite 排行榜上排名前三的工具(CodeStory Aide,Honeycomb 和 AbanteAI MentaBot)进行了错误定位能力评估。对于一个 patch,如果它修改的文件和 gold patch 所修改的文件相同,则认为错误定位正确,否则错误。分析结果如图 6 所示:
豆包 MarsCode Agent 通过代码知识图谱、语言服务等代码检索工具,在 300 个实例中成功定位到了 245 个实例的待修改文件(成功率 81.7%),而 CodeStory Aide 为 221(成功率 73.7%),Honeycomb 为 213(成功率 71%),AbanteAI MentatBot 为 211(成功率 70.3%)。从代码检索和错误定位能力看,豆包 MarsCode Agent 处于领先地位。
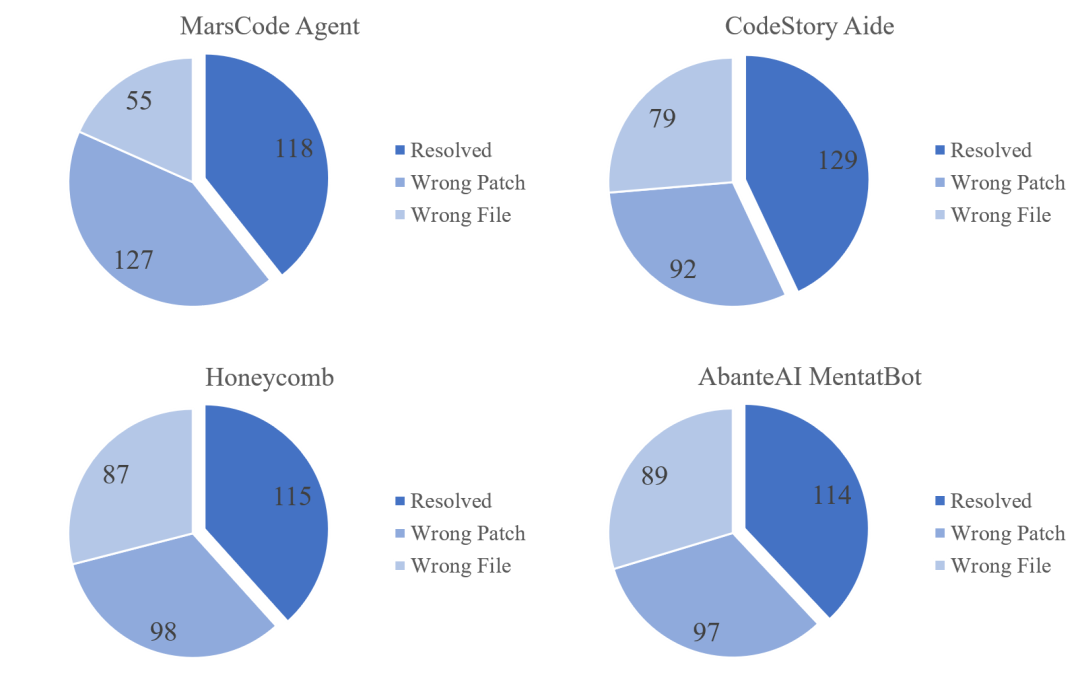
豆包 MarsCode Agent 动态静态求解的实例分布
我们分析了实验中静态和动态求解的实例分布,如下图所示,在所有实例中,有 104 / 300 = 34.67%的实例被 Planner Agent 认为适合动态求解,196 / 300 = 65.3%的实例被认为适合进行静态求解,通过动态方式成功求解 53 个实例,求解率为 51%,静态方式成功求解 65 个实例,求解率为 33%。由于动态调试有缺陷复现和和验证的过程,表现在求解率上略高于静态修复。在被求解的 118 个实例中,有 44.9%的实例是由动态方式修复,55.1%的实例由静态方式修复。
未来展望
豆包 MarsCode Agent 团队致力于 AI Agent 方法在软件工程领域的落地和应用。在未来将持续关注以下优化方向:
降低大语言模型调用成本,推广豆包 MarsCode Agent 在更多场景的落地,为更多用户提供高质量智能软件开发服务;
加强用户与 Agent 的协作和交互,提升用户对 Agent 作业过程的掌控感;
支持 Agent 对用户工作区的动态调试,同时避免用户环境污染等问题;
进一步提升文件错误定位准确率和代码修改正确率。
欢迎大家通过我们的论文了解更多信息:https://arxiv.org/abs/2409.00899




