
一、当 Kubernetes 成为云原生事实标准,可观测性挑战随之而来
当前,云原生技术以容器技术为基础,通过标准可扩展的调度、网络、存储、容器运行时接口来提供基础设施。同时,通过标准可扩展的声明式资源和控制器来提供运维能力,两层标准化推动了开发与运维关注点分离,各领域进一步提升规模化和专业化,达到成本、效率、稳定性的全面优化。
在这样的大技术背景下,越来越多的公司引入了云原生技术来开发、运维业务应用。正因为云原生技术带来了越发纷繁复杂的可能性,业务应用出现了微服务众多、多语言开发、多通信协议的鲜明特征。同时,云原生技术本身将复杂度下移,给可观测性带来了更多挑战:

1、混沌的微服务架构,多语言和多网络协议混杂
业务架构因为分工问题,容易出现服务数量多,调用协议和关系非常复杂的现象,导致的常见问题包括:
无法准确清晰了解、掌控全局的系统运行架构;
无法回答应用之间的连通性是否正确;
多语言、多网络调用协议带来埋点成本呈线性增长,且重复埋点 ROI 低,开发一般将这类需求优先级降低,但可观测数据又不得不采集。
2、下沉的基础设施能力屏蔽实现细节,问题定界越发困难
基础设施能力继续下沉,开发和运维关注点继续分离,分层后彼此屏蔽了实现细节,数据方面不好关联了,出现问题后不能迅速地定界问题出现在哪一层。开发同学只关注应用是否正常工作,并不关心底层基础设施细节,出现问题后需要运维同学协同排查问题。运维同学在问题排查过程中,需要开发同学提供足够的上下游来推进排查,否则只拿到“某某应用延迟高”这么笼统的表述,这很难有进一步结果。所以,开发同学和运维同学之间需要共同语言来提高沟通效率,Kubernetes 的 Label、Namespace 等概念非常适合用来构建上下文信息。
3、繁多监测系统,造成监测界面不一致
复杂系统带来的一个严重副作用就是监测系统繁多。数据链路不关联、不统一,监测界面体验不一致。很多运维同学或许大多都有过这样的体验:定位问题时浏览器打开几十个窗口,在 Grafana、控制台、日志等各种工具之间来回切换,不仅非常耗时巨大,且大脑能处理的信息有限,问题定位效率低下。如果有统一的可观测性界面,数据和信息得到有效地组织,减少注意力分散和页面切换,来提高问题定位效率,把宝贵时间投入到业务逻辑的构建上去。
二、解决思路与技术方案
为了解决上述问题,我们需要使用一种支持多语言,多通信协议的技术,并在产品层面尽可能覆盖软件栈端到端的可观测性需求,通过调研,我们提出一种立足于容器界面和底层操作系统,向上关联应用性能监测的可观测性解决思路。
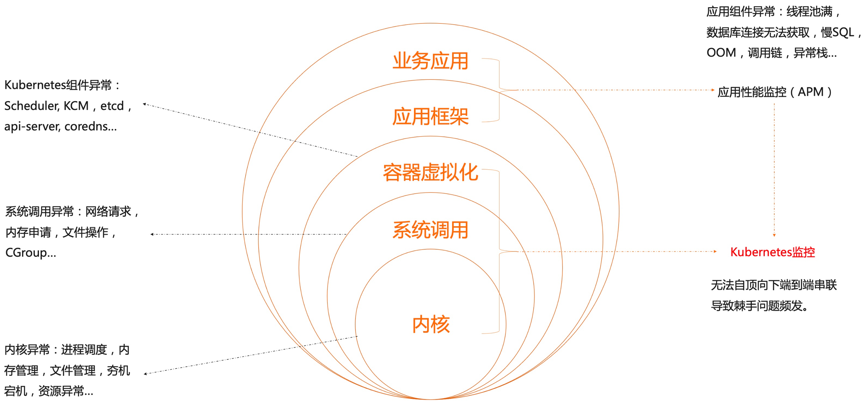
要采集容器、节点运行环境、应用、网络各个维度的数据挑战非常大,云原生社区针对不同需求给出了 cAdvisor、node exporter、kube-state-metics 等多种方式,但仍然无法满足全部需求。维护众多采集器的成本也不容小觑,引发的一个思考是能否有一种对应用无侵入的、支持动态扩展的数据采集方案?目前最好的答案是 eBPF。
数据采集(eBPF 超能力)
1、eBPF 的超能力
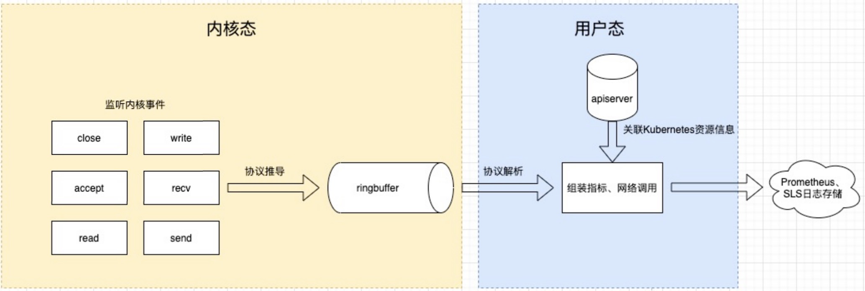
eBPF 相当于在内核中构建了一个执行引擎,通过内核调用将这段程序 attach 到某个内核事件上,实现监听内核事件。有了事件我们就能进一步做协议推导,筛选出感兴趣的协议,对事件进一步处理后放到 ringbuffer 或者 eBPF 自带的数据结构 Map 中,供用户态进程读取。用户态进程读取这些数据后,进一步关联 Kubernetes 元数据后推送到存储端。这是整体处理过程。
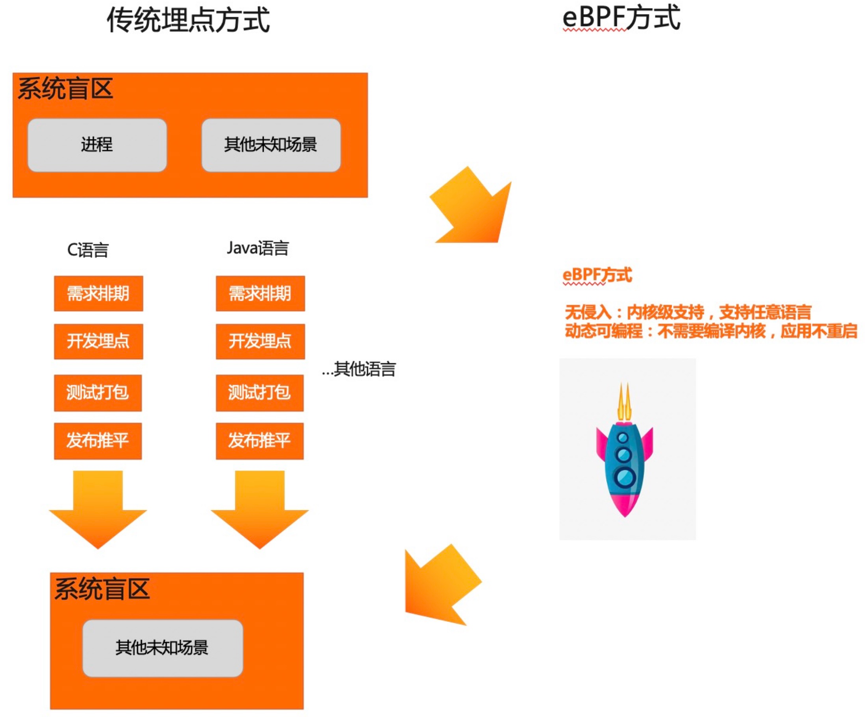
eBPF 的超能力体现在能订阅各种内核事件,如文件读写、网络流量等,运行在 Kubernetes 中的容器或者 Pod 里的一切行为都是通过内核系统调用来实现的,内核知道机器上所有进程中发生的所有事情,所以内核几乎是可观测性的最佳观测点,这也是我们为什么选择 eBPF 的原因。另一个在内核上做监测的好处是应用不需要变更,也不需要重新编译内核,做到了真正意义上的无侵入。当集群里有几十上百个应用的时候,无侵入的解决方案会帮上大忙。
但作为新技术,人们对 eBPF 也存在些许担忧,比如安全性与探针性能。为了充分保证内核运行时的安全性,eBPF 代码进行了诸多限制,如最大堆栈空间当前为 512、最大指令数为 100 万。与此同时,针对性能担忧,eBPF 探针控制在大约在 1%左右。其高性能主要体现在内核中处理数据,减少数据在内核态和用户态之间的拷贝。简单说就是数据在内核里算好了再给用户进程,比如一个 Gauge 值,以往的做法是将原始数据拷贝到用户进程再计算。
2、可编程的执行引擎天然适合可观测性
可观测性工程通过帮助用户更好的理解系统内部状态来消除知识盲区和及时消除系统性风险。eBPF 在可观测性方面有何威力呢?
以应用异常为例,当发现应用有异常后,解决问题过程中发现缺少应用层面可观测性,这时候通过埋点、测试、上线补充了应用可观测性,具体的问题得到了解决,但往往治标不治本,下一次别的地方有问题,又需要走同样的流程,另外多语言、多协议让埋点的成本更高。更好的做法是用无侵入方式去解决,以避免需要观测时没有数据。
eBPF 执行引擎可通过动态加载执行 eBPF 脚本来采集可观测性数据,举个具体例子,假设原本的 K8S 系统并没有做进程相关的监测,有一天发现了某个恶意进程(如挖矿程序)在疯狂地占用 CPU,这时候我们会发现这类恶意的进程创建应该被监测起来,这时候我们可以通过集成开源的进程事件检测库来是实现,但这往往需要打包、测试、发布这一整套流程,全部走完可能一个月就过去了。
相比之下,eBPF 的方式显得更为高效快捷,由于 eBPF 支持动态地加载到内核监听进程创建的事件,所以我们可以将 eBPF 脚本抽象成一个子模块,采集客户端每次只需要加载这个子模块里的脚本完成数据采集,再通过统一的数据通道将数据推送到后端。这样我们就省去了改代码、打包、测试、发布的繁琐流程,通过无侵入的方式动态地实现了进程监测这样的需求。所以,eBPF 可编程的执行引擎非常适合用来将增强可观测性,将丰富的内核数据采集上来,通过关联业务应用,方便问题排查。
三、从监测系统到可观测性
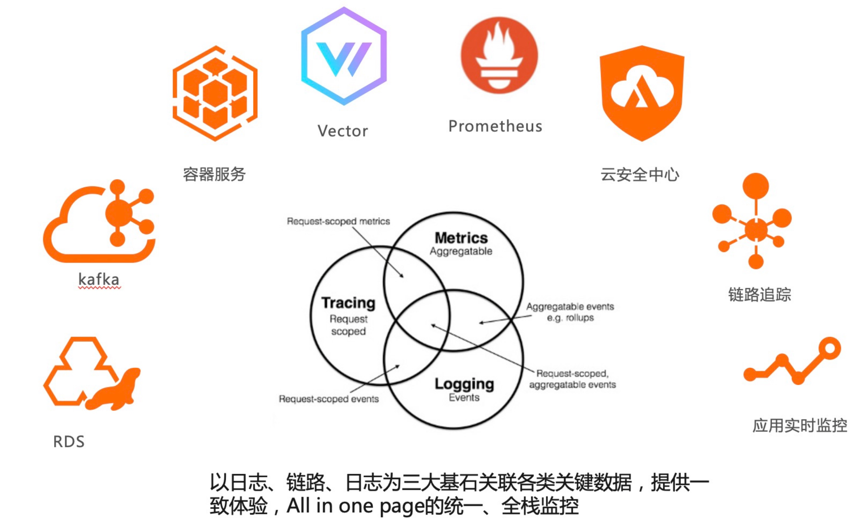
随着云原生浪潮,可观测性概念正深入人心。但仍离不开日志、指标、链路这三类可观测领域的数据基石。做过运维或 SRE 的同学经常遇到这样的问题:半夜被拉到应急群里,披头盖地地被质问为什么数据库不工作了,在没有上下文的情况下,无法立刻抓住问题核心。我们认为好的可观测性平台应该帮助用户很好地反馈上下文,就像 Datadog 的 CEO 说的那样:监测工具不是功能越多功能越好,而是要思考怎样在不同团队和成员之间架起桥梁,尽可能把信息放在同一个页面中(to bridge the gap between the teams and get everything on the same page)。
因此,在可观测性平台产品设计上需要以指标、链路、日志为基本,向外集成阿里云自家的各类云服务,同时也支持开源产品数据接入,将关键上下文信息关联起来,方便不同背景的工程师理解,进而加速问题排查。信息没有有效地组织就会产生理解成本,信息粒度上以事件->指标->链路->日志由粗到细地组织到一个页面中,方便下钻,不需要多个系统来回跳转,从而提供一致体验。
那么具体怎么关联呢?信息怎么组织呢?主要从两方面来看:
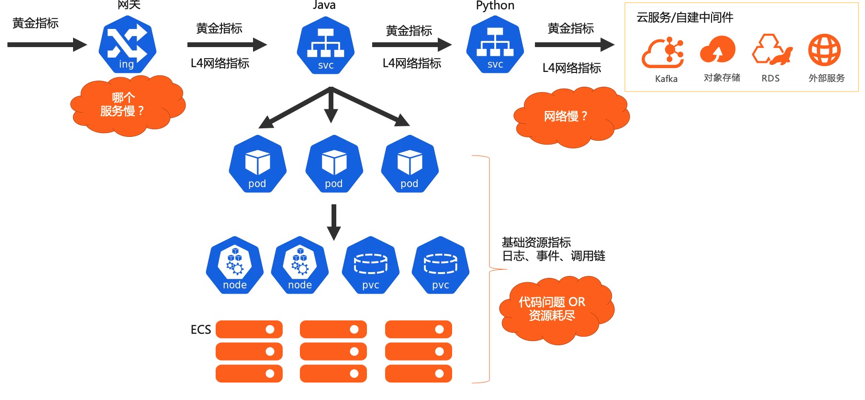
1、端到端:展开说就是应用到应用,服务到服务,Kubernetes 的标准化和关注点分离,各自开发运维各自关注各自领域,那么端到端的监测很多时候成了”三不管“区域,出现问题的时候很难排查链路上哪个环节出了问题。因此从端到端的角度来看,两者调用关系是关联的基础,因为系统调用才产生了联系。通过 eBPF 技术非常方便地以无侵入的方式采集网络调用,进而将调用解析成我们熟知的应用协议,如 HTTP、GRPC、MySQL 等,最后将拓扑关系构建起来,形成一张清晰的服务拓扑后方便快速定位问题,如下图中网关->Java 应用->Python 应用->云服务的完整链路中,任意一环出现延时,在服务拓扑中应能一眼看出问题所在。这是第一个管线点端到端。2、自顶向下全栈关联:以 Pod 为媒介,Kubernetes 层面关联 Workload、Service 等对象,基础设施层面可以关联节点、存储设备、网络等,应用层面关联日志、调用链路等。
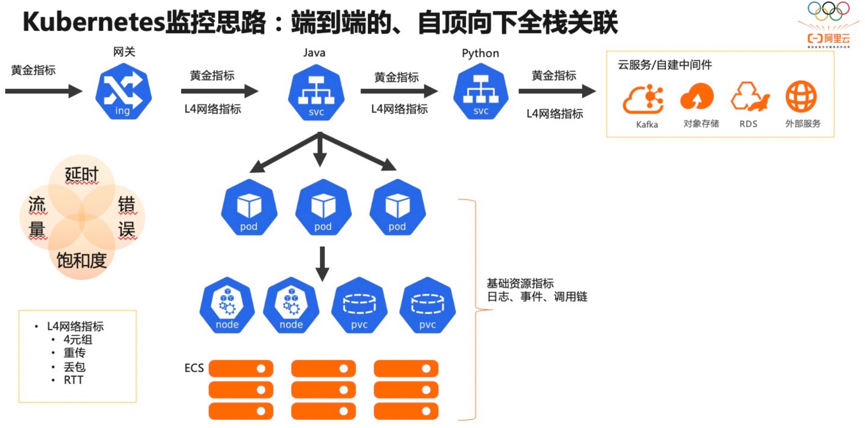
接下来介绍下 Kubernetes 监测的核心功能。
永不过时的黄金指标
黄金指标是用来用来监测系统性能和状态的最小集合。黄金指标有两个好处:一,直接了然地表达了系统是否正常对外服务。二,能快速评估对用户的影响或事态的严重性,能大量节省 SRE 或研发的时间,想象下如果我们取 CPU 使用率作为黄金指标,那么 SRE 或研发将会奔于疲命,因为 CPU 使用率高可能并不会造成多大的影响。
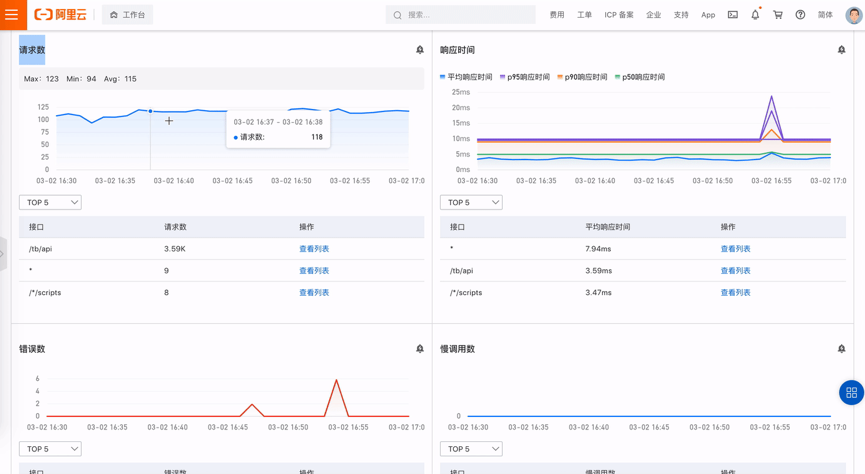
Kubernetes 监测支持这些指标:
请求数/QPS
响应时间及分位数(P50、P90、P95、P99)
错误数
慢调用数
如下图所示:
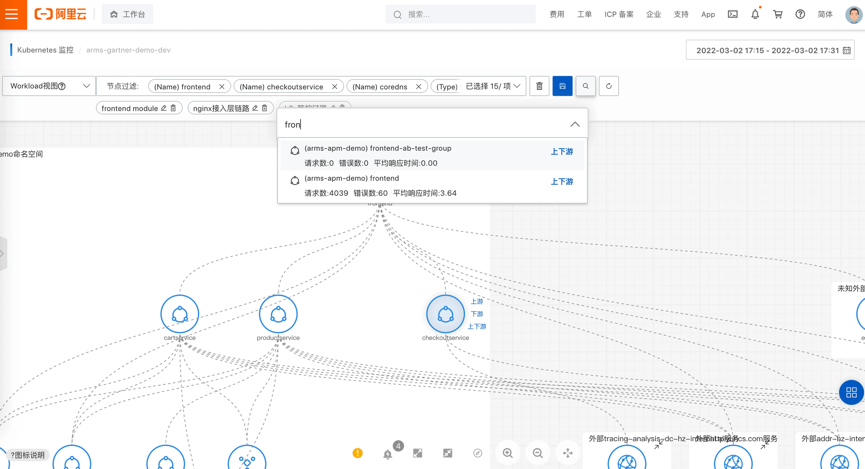
全局视角的服务拓扑
诸葛亮曾言“不谋全局者,不足谋一域 ”。随着当下技术架构、部署架构的复杂度越来越高,发生问题后定位问题变得越来越棘手,进而导致 MTTR 越来越高。另一个影响是对影响面的分析带来非常大的挑战,通常会造成顾此失彼。因此,有一张像地图一样的拓扑大图非常必要。全局拓扑具有以下特点:
系统架构感知:系统架构图是程序员了解一个新系统的重要参考,当拿到一个系统,起码需要知晓流量入口在哪里,有哪些核心模块,依赖了哪些内部外部组件等。在异常定位过程中,有一张全局架构的图对异常定位进程有非常大推动作用。
依赖分析:有一些问题是出现在下游依赖,如果这个依赖不是自己团队维护就会比较麻烦,当自己系统和下游系统没有足够的可观测性的时候就更麻烦了,这种情况下就很难跟依赖的维护者讲清楚问题。在我们的拓扑中,通过将黄金指标的上下游用调用关系连起来,形成了一张调用图。边作为依赖的可视化,能查看对应调用的黄金信号。有了黄金信号就能快速地分析下游依赖是否存在问题。
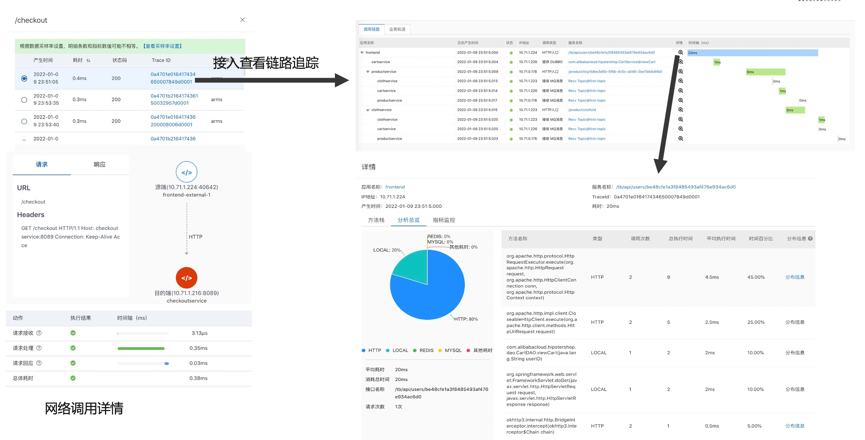
分布式 Tracing 助力根因定位
协议 Trace 同样是无入侵、语言无关的。如果请求内容中存在分布式链路 TraceID,能自动识别出来,方便进一步下钻到链路追踪。应用层协议的请求、响应信息有助于对请求内容、返回码进行分析,从而知道具体哪个接口有问题。如需查看代码级别或请求界别的详情,可点击 Trace ID 下钻到链路追踪分析查看。
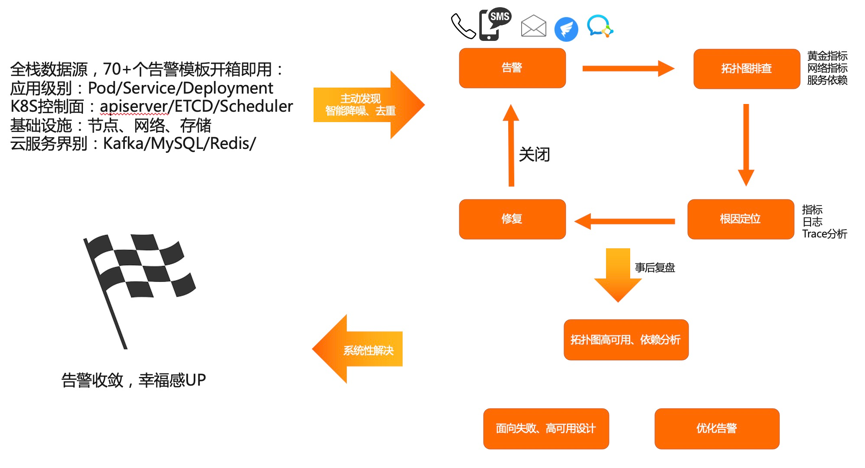
开箱即用的告警功能
开箱即用的告警模板,各个不同层次全覆盖,不需要手动配置告警,将大规模 Kubernetes 运维经验融入到告警模板里面,精心设计的告警规则加上智能降噪和去重,我们能够做到一旦告警就是有效的告警,并且告警里面带有关联信息,可以快速定位到异常实体。告警规则全栈覆盖的好处是能及时、主动地将高风险事件报给用户,用户通过排查定位、解决告警、事后复盘、面向失败设计等一系列手段,最终逐步达成更好的系统稳定性。
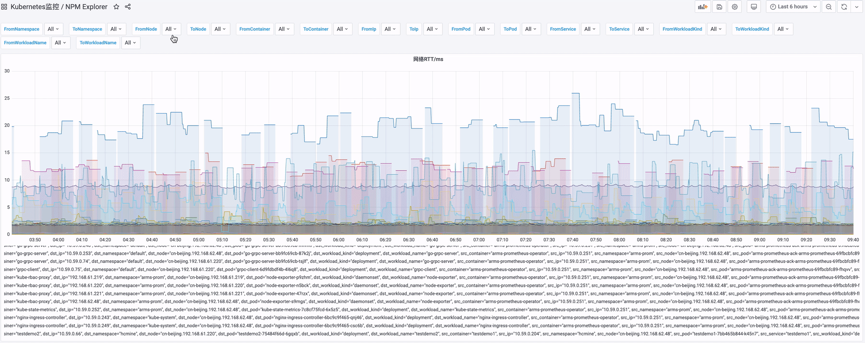
网络性能监测
网络性能问题在 Kubernetes 环境中很常见,由于 TCP 底层机制屏蔽了网络传输的复杂性,应用层对此是无感的,这对生产环境定位丢包率高、重传率高这种问题带来一定的麻烦。Kubernetes 监测支持了 RTT、重传 &丢包、TCP 连接信息来表征网络状况,下面以 RTT 为例,支持从命名空间、节点、容器、Pod、服务、工作负载这几个维度来看网络性能,支持以下各种网络问题的定位:
负载均衡无法访问某个 Pod,这个 Pod 上的流量为 0,需要确定是否这个 Pod 网络有问题,还是负载均衡配置有问题;
某个节点上的应用似乎性能都很差,需要确定是否节点网络有问题,通过对别的节点网络来达到;
链路上出现丢包,但不确定发生在那一层,可以通过节点、Pod、容器这样的顺序来排查。
四、Kubernetes 可观测性全景视角
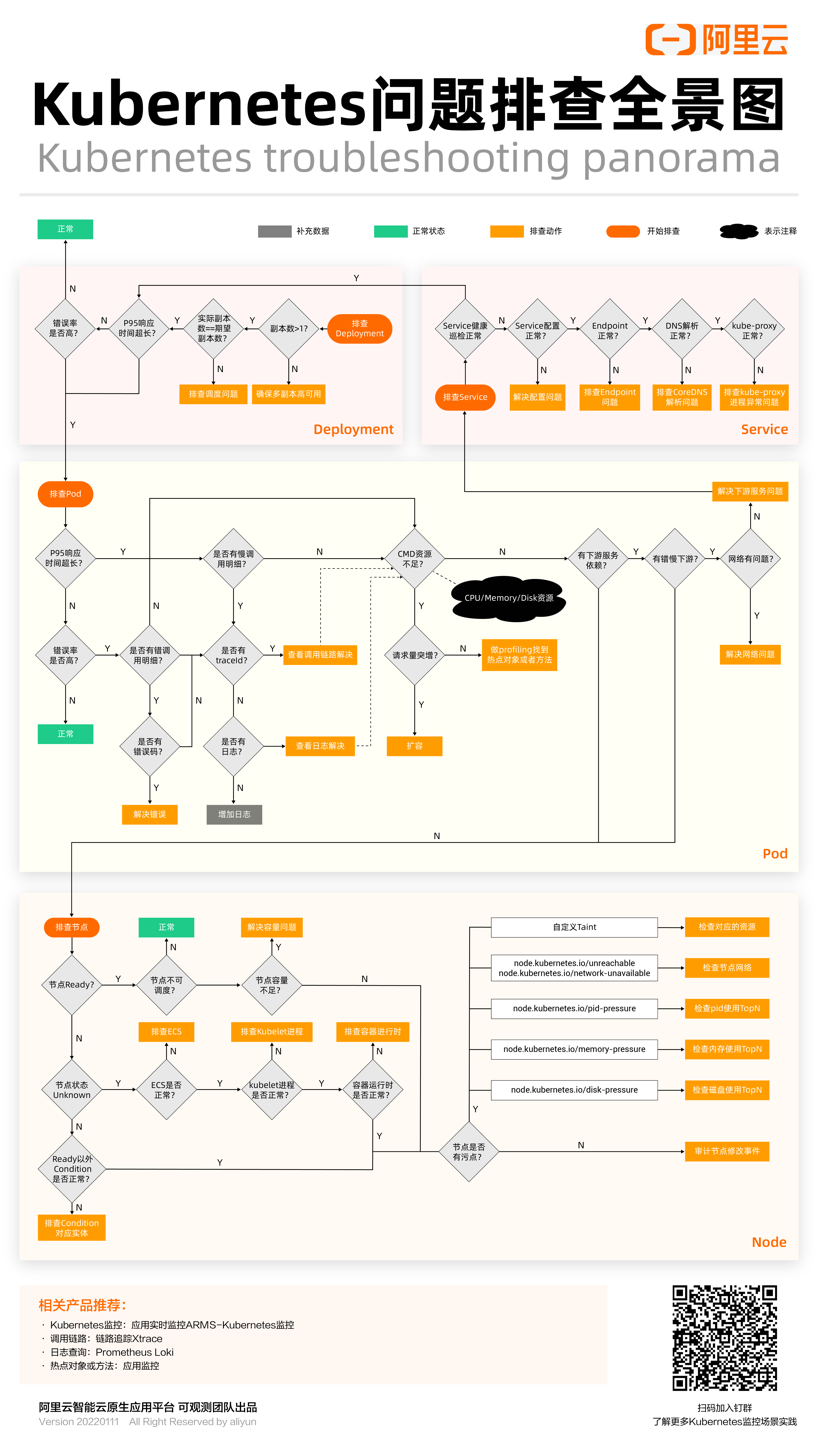
有了上述产品能力,基于阿里巴巴在容器、Kubernetes 方面有着丰富且极具深度的实践,我们将这些宝贵生产实践归纳、转化成产品能力,以帮助用户更有效、更快捷地定位生产环境问题。使用这个排查全景图可以通过以下方法:
大体结构上是以服务和 Deployment(应用)为入口,大多数开发只需要关注这一层就行了。重点关注服务和应用是否错慢,服务是否连通,副本数是否符合预期等
再往下一层是提供真正工作负载能力的 Pod。Pod 重点关注是否有错慢请求,是否健康,资源是否充裕,下游依赖是否健康等
最底下一层是节点,节点为 Pod 和服务提供运行环境和资源。重点关注节点是否健康,是否处于可调度状态,资源是否充裕等。
常见问题排查
一、网络问题
网络是 Kubernetes 中最棘手、最常见的问题,因为以下几个原因给我们定位生产环境网络问题带来麻烦:
Kubernetes 的网络架构复杂度高,节点、Pod、容器、服务、VPC 交相辉映,简直能让你眼花缭乱;
网络问题排查需要一定的专业知识,大多数对网络问题都有种天生的恐惧;
分布式 8 大谬误告诉我们网络不是稳定的、网络拓扑也不一成不变的、延时不可忽视,造成了端到端之间的网络拓扑不确定性。
Kubernetes 环境下场景的网络问题有:
conntrack 记录满问题;
IP 冲突;
CoreDNS 解析慢、解析失败;
节点没开外网。(对,你没听错);
服务访问不通;
配置问题(LoadBalance 配置、路由配置、device 配置、网卡配置);
网络中断造成整个服务不可用。
网络问题千千万万,但万变不离其宗的是网络有其表征其是否正常运行的”黄金指标“:
网络流量和带宽;
丢包数(率)和重传数(率);
RTT。
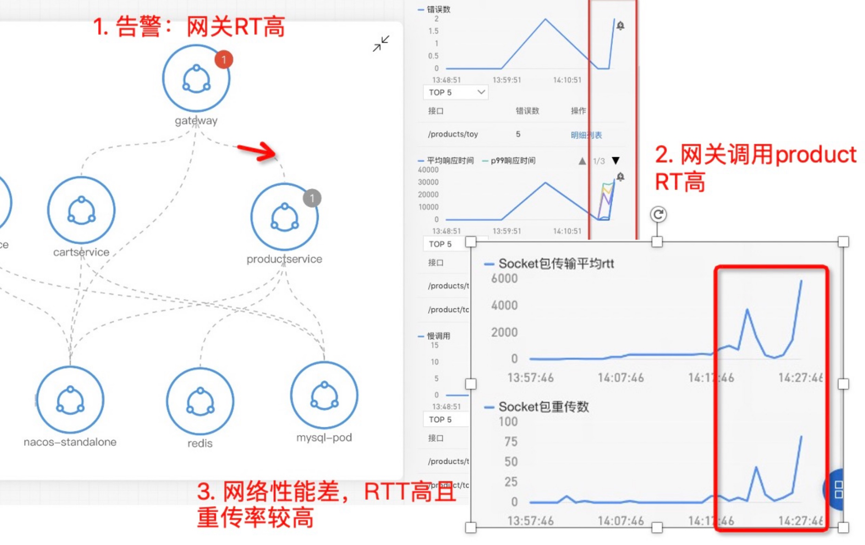
下面的示例展示了因网络问题导致的慢调用问题。从 gateway 来看发生了慢调用,查看拓扑发现调下游 product 的 RT 比较高,但是 product 本身的黄金指标来看 product 本身服务并没有问题,进一步查看两者之间的网络状况,发现 RTT 和重传都比较高,说明网络性能恶化了,导致了整体的网络传输变慢,TCP 重传机制掩盖了这个事实,在应用层面感知不到,日志也没法看出问题所在。这时候网络的黄金指标有助于定界出问题,从而加速了问题的排查。
二、节点问题
Kubernetes 做了大量工作,尽可能确保提供给工作负载和服务的节点是正常的,节点控制器 7x24 小时地检查节点的状态,发现影响节点正常运行的问题后,将节点置为 NotReady 或不可调度,通过 kubelet 把业务 Pod 从问题节点中驱逐出去。这是 Kubernetes 的第一道防线,第二道防线是云厂商针对节点高频异常场景设计的节点自愈组件,如阿里云的node repairer:发现问题节点后,执行排水驱逐、置换机器,从而做到自动化地保障业务正常运行。即便如此,节点在长期使用过程中不可避免地会产生各种奇奇怪怪的问题,定位起来比较费时耗力。常见问题分类和级别:
针对这些繁杂的问题,总结出如下排查流程图:
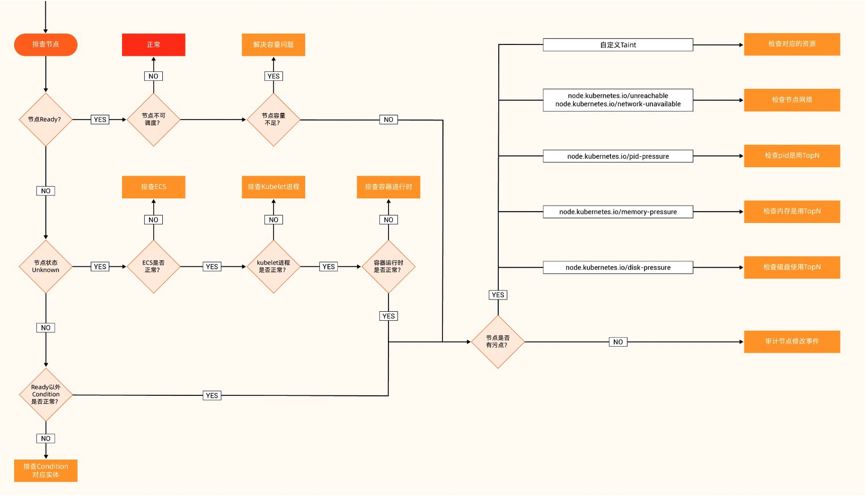
以一个 CPU 打满为例:
1、节点状态 OK,CPU 使用率超过了 90%

2、查看对应的 CPU 的三元组:使用率、TopN、时序图,首先每个核的使用率都很高,进而导致整体 CPU 使用高;接下来我们自然要知道谁在疯狂地使用 CPU,从 TopN 列表来看有个 Pod 一枝独秀地占用 CPU;最后我们得确认下 CPU 飙高是什么时候开始的。

三、服务响应慢
造成服务响应非常多,场景可能的原因有代码设计问题、网络问题、资源竞争问题、依赖服务慢等原因。在复杂的 Kubernetes 环境下,定位慢调用可以从两个方案去入手:首先,应用自身是否慢;其次,下游或网络是否慢;最后检查下资源的使用情况。如下图所示,Kubernetes 监测分别从横向和纵向来分析服务性能:
横向:主要是端到端层面来看,首先看自己服务的黄金指标是否有问题,再逐步看下游的网络指标。注意如果从客户端来看调用下游耗时高,但从下游本身的黄金指标来看是正常的,这时候非常有可能是网络问题或者操作系统层面的问题,此时可以用网络性能指标(流量、丢包、重传、RTT 等)来确定。
纵向:确定应用本身对外的延时高了,下一步就是确定具体哪个原因了,确定哪一步/哪个方法慢可以用火焰图来看。如果代码没有问题,那么可能执行代码的环境是有问题的,这时可以查看系统的 CPU/Memory 等资源是否有问题来做进一步排查。
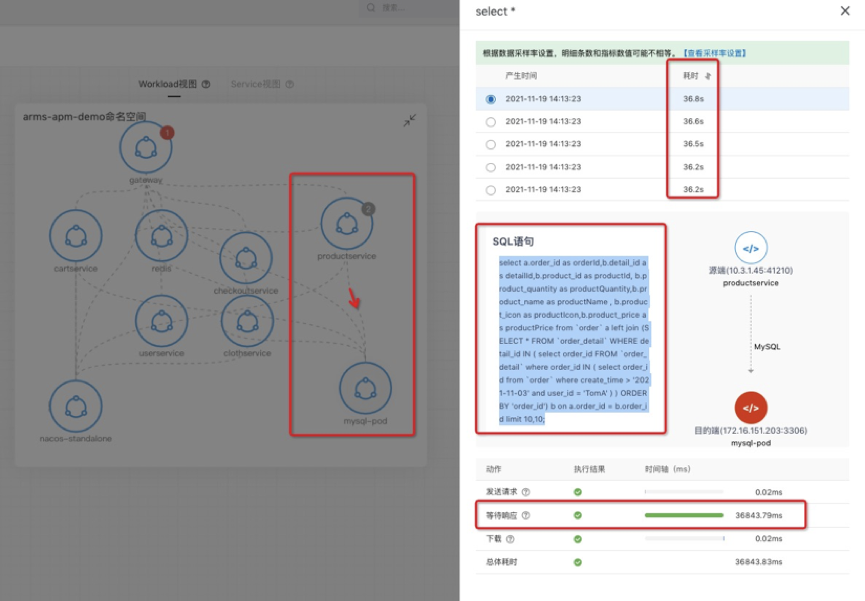
下面举个 SQL 慢查询的例子(如下图)。在这个例子中网关调用 product 服务,product 服务依赖了 MySQL 服务,逐步查看链路上的黄金指标,最终发现 product 执行了一条特别复杂的 SQL,关联了多张表,导致 MySQL 服务响应慢。MySQL 协议基于 TCP 之上的,我们的 eBPF 探针识别到 MySQL 协议后,组装、还原了 MySQL 协议内容,任何语言执行的 SQL 语句都能采集到。
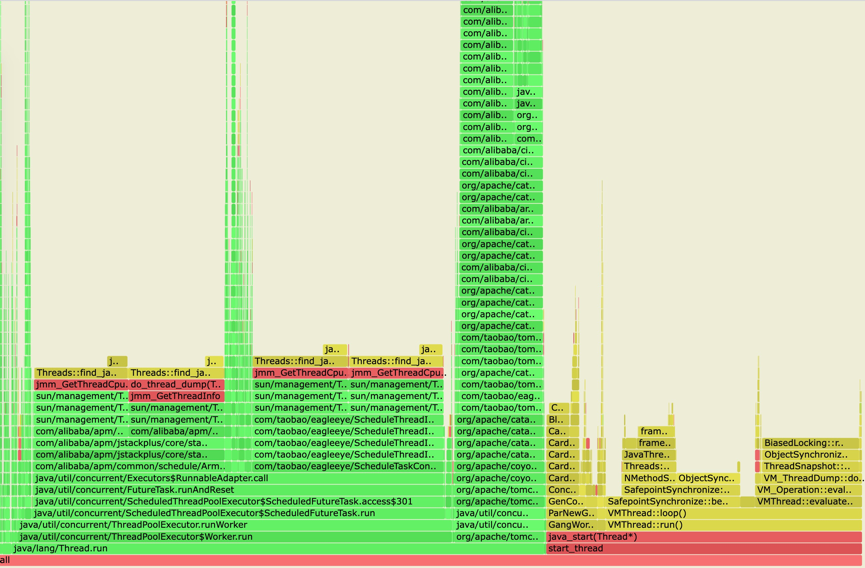
第二个例子是应用本身慢的例子,这时候自然会问具体哪一步、哪个函数造成了慢,ARMS 应用监控支持的火焰图通过对 CPU 耗时定期采样(如下图),帮助快速定位到代码级别问题。
四、应用/Pod 状态问题
Pod 负责管理容器,容器是真正执行业务逻辑的载体。同时 Pod 是 Kubernetes 调度的最小单元,所以 Pod 同时拥有了业务和基础设施的复杂度,需要结合着日志、链路、系统指标、下游服务指标综合来看。Pod 流量问题是生产环境高频问题,比如数据库流量陡增,当环境中有成千上万个 Pod 时,排查流量主要来自哪个 Pod 就显得特别困难。
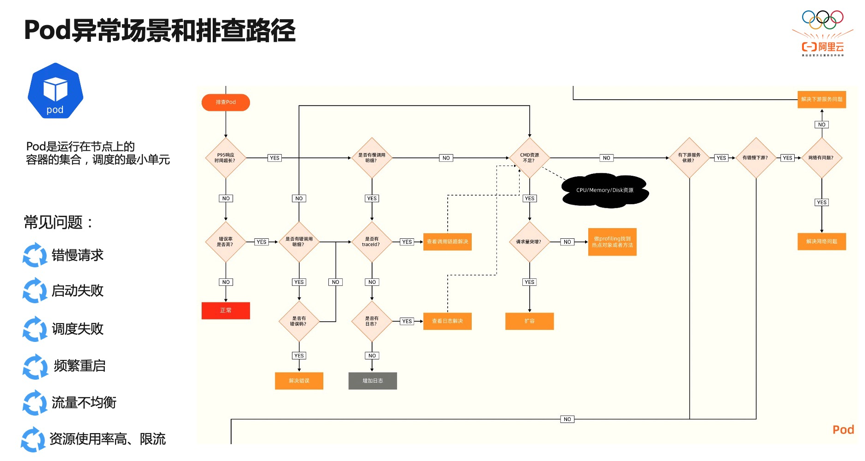
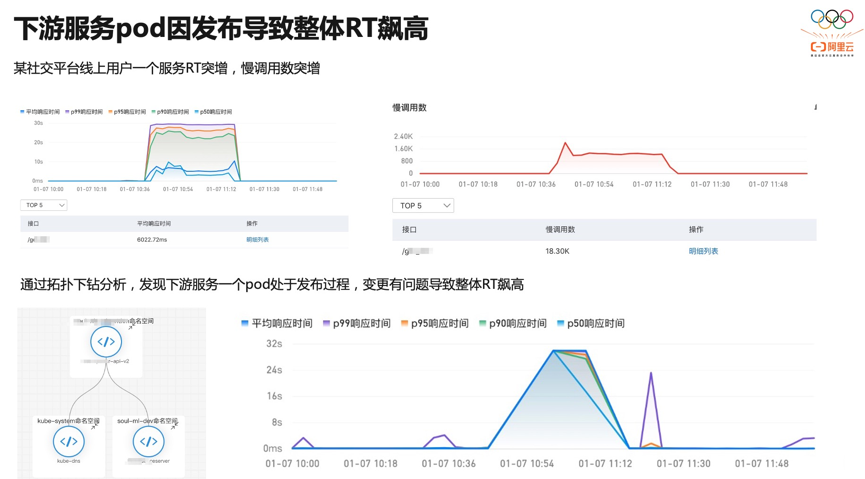
接下来我们看一个典型的案例:下游服务在发布过程中灰度了一个 Pod,该 Pod 因代码原因响应非常慢,导致上游都超时了。之所以能做到 Pod 级别的可观测,是因为我们用 ebpf 的技术来采集 Pod 的流量、黄金指标,因此可以通过拓扑、大盘的方式方便地查看 Pod 与 Pod、Pod 与服务、Pod 与外部的流量。
五、总结
通过 eBPF 无侵入地采集多语言、多网络协议的黄金指标/网络指标/Trace,通过关联 Kubernetes 对象、应用、云服务等各种上下文,同时在需要进一步下钻的时候提供专业化的监测工具(如火焰图),实现了 Kubernetes 环境下的一站式可观测性平台。




