
大家好,我是唯品会实施平台 OLAP 团队负责人王玉,负责唯品会、Presto、ClickHouse、Kylin、Kudu 等 OLAP 之间的开源修改,组建优化和维护,业务使用范围支持和指引等工作。本次我要分享的主题是唯品会基于 ClickHouse 的百亿级数据自助分析实践,主要分为以下 4 个部分:
唯品会 OLAP 的演进
实验平台基于 Flink 和 ClickHouse 如何实现数据自助分析
使用 ClickHouse 中遇到的问题和挑战
ClickHouse 未来在唯品会的展望
一、唯品会 OLAP 的演进
1、OLAP 在唯品会的演进

1)Presto
Presto 作为当前唯品会 OLAP 的主力军,经历了数次架构和使用方式的进化。目前,具有 500 多台高配的物理机,CPU 和内存都非常强悍,服务于 20 多个线上的业务。日均查询高峰可高达到 500 万次,每天读取和处理接近 3PB 的数据,查询的数据量也是几千亿级。另外,我们在的 Presto 的使用和改进上也做了一些工作,下面给大家详细地介绍一下。
2)Kylin
上图中中间的符号就是 Kylin,Kylin 是国人开源的 Apache 项目,Kylin 作为 Presto 的补充,在一些数据量级不适用于 Presto 实时查询原来的表的情况下,数据量又非常的大,例如需要查询几个月的打点流量数据,这样的数据有时候就可以用固定的规则预计算,这样就可以用 Kylin 作为补充。
3)ClickHouse
目前有两个集群,每个集群大概是 20 至 30 台高配物理机,服务于实验平台 A/B-test,还有 OLAP 的日志查询,打点监控等项目。ClickHouse 是未来我们发展的关键。
Kylin 的数据量比 Presto 要小很多,它主要是打点几个特定的查询,比如有供应规则的,类似于以前分析人们消费的品质或者出固定的报表才会用,它的数据量比 Presto 要小很多。
2、唯品会 OLAP 部署架构模式
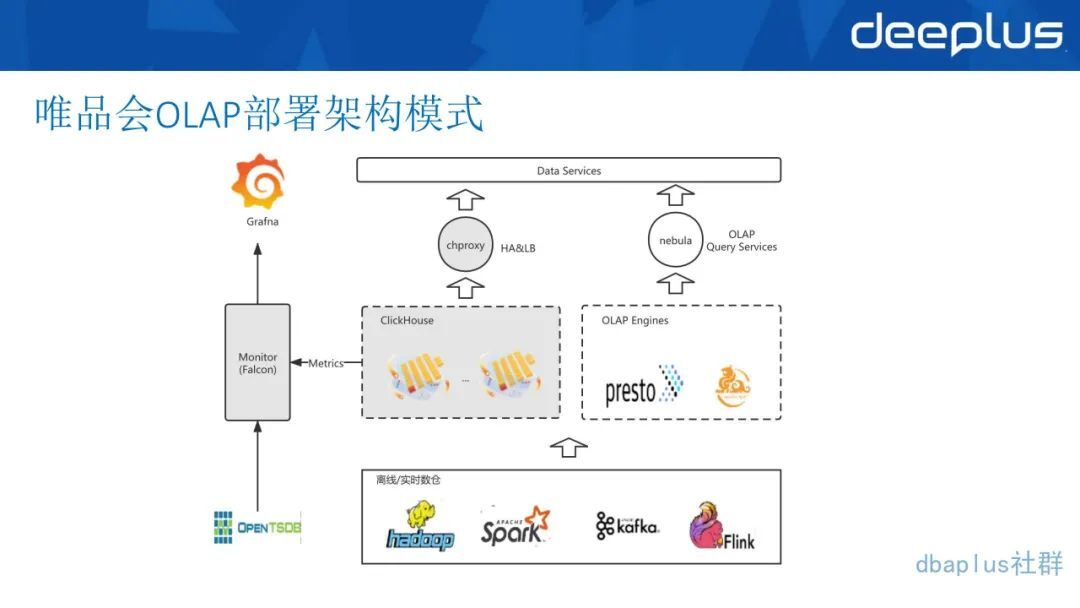
下面这一部分是数据层,有 Hadoop、Spark,例如 ClickHouse 从 Hive 导入数据到 ClickHouse 就是通过 Waterdrop,老版本使用 Waterdrop 是用 Spark 去实现,而新版本的 Waterdrop 可以使用 Flink 实现,用户可以通过不同的配置中心去配置。
另外还有 Kafka 和 Flink,实时数仓数据写入 ClickHouse 或者 Hbase 是用 Kafka 加 Flink 来写,根据具体的业务需求和架构而定,在引擎层上面有一层代理层,ClickHouse 我们是用 chproxy,这也是一个开源项目,而且它的功能比较完善,像有一些用户权限在 chproxy 里面都可以去设置。
我们自己在 chproxy 之上,还搭了一个 HAproxy,主要是做一层 HA 层,以防 chproxy 有时候可能会出现问题。
用户是直接连 HAproxy 的地址和端口,这样我们会去做 HA 分发,保障高可用,在 Presto 代理层都使用了我们自主研发的一个 OLAP 跨越的服务工具——Nebula,老版本是叫 Spider,就是各个对外提供的数据服务和各种业务,平行于右边的整套链路,向左侧对应的就是这部分的各个监控,有的是用 Prometheus,有的是用 Presto,Presto 会自己有 API 和 JDBC 来提供这些接口,我们会将这些接口采集过来,在 Open faculty 里面进行监控和告警。这就是整个 OLAP 的部署架构模式。
3、Presto 的业务架构图
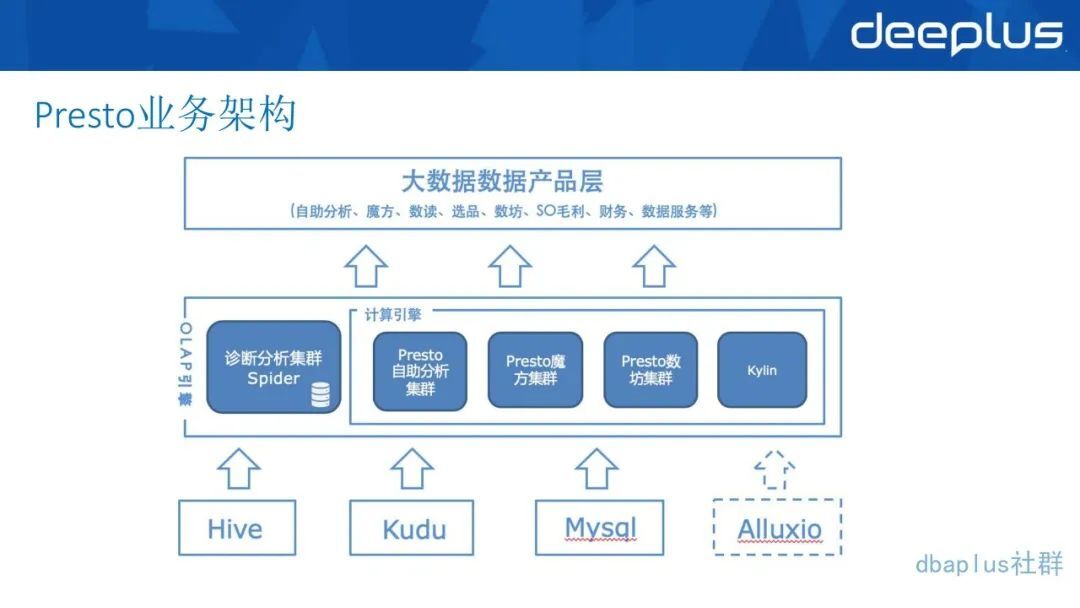
底层利用了 Presto 多数据源的 Connector 特性,如上图底层数据有 Hive、Kudu、MySQL、Alluxio。Presto 它是可以配置 Catelog 的,可以把数据源放在一个 SQL 里面做 JOIN,是非常方便的。
中间层包括有多个 Presto 集群,最初是根据不同的业务来独立不同的 Presto 集群。针对 Presto 集群,可以部署多个 Spider,诊断分析记录所有的查询,因为 Presto 本身的历史查询是不持久的,放在内存里面也会有过期时间。
最上层就是用 Presto 服务的业务应用,最初只有两个魔方和自主分析两个业务应用,发展到现在进入到 20 个业务应用。因为 Presto 在使用上确实十分方便,用户只需要写 SQL,而且 SQL 的语法跟 Hive 也比较相似,也有很多 UDF,并且接入也很方便,可以直接接 client 或者 JDBC。所以在 Presto 的使用上还是非常频繁的。
4、对 Presto 的改进
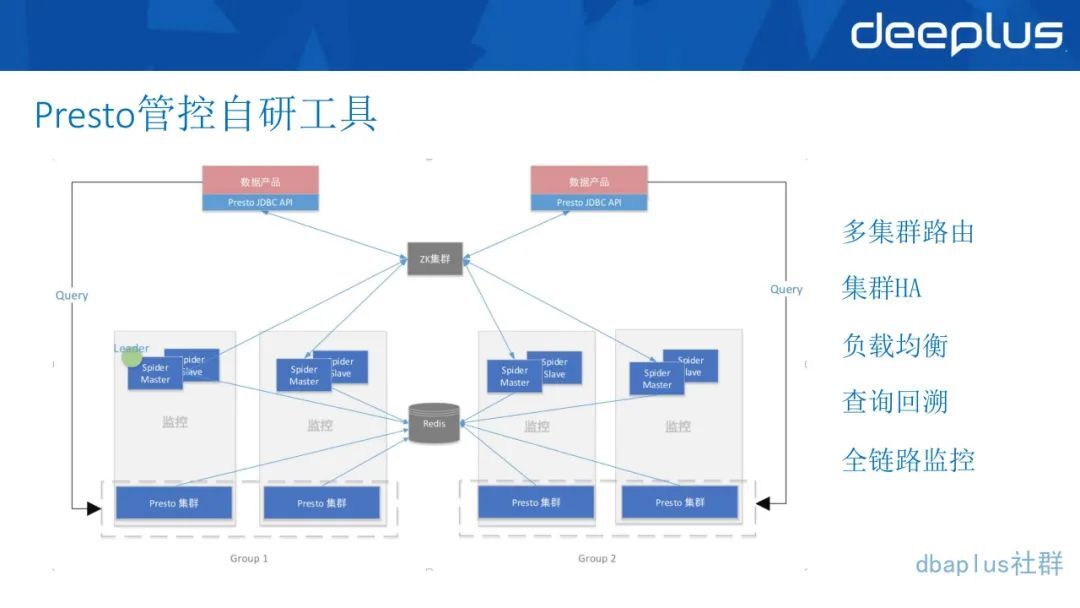
第一个是开发了一套 Presto 的管控工具,修改了 Presto server 和 kinda 的源码,用自营的管理工具 Spide/Nebula 从 Presto 所暴露的 API 和系统表里获取到节点和查询信息,一方面将查询落入 MySQL,通过 etl-job 落入 Hive 便于存储和分析,包括以后也可以做一些报表,考虑从哪些方面进行优化。
一方面根据集群查询数和节点信息来给集群打分。就是看 Presto 当前每个集群上面大概跑了多少个查询,查询量大不大?对 Presto 的集群负载情况如何?打了分以后,每次从 client 这边发起的查询,就会去选取分数相对较低的,也就是资源占用度比较低的集群,把 SQL 打进去,这样子就能实现负载均衡的效果。
很多熟悉 Presto 的同学都知道 Presto clinter 的 HA 是需要自己做的,因为官方的版本只提供了单节点的 clinter,我们通过打分和负载均衡的情况去做了 HA,这样子就保障了 Presto 的 HA,不管是在部署、升级,还是在评集群,这些时候用户都是无感。
5、Presto 容器化
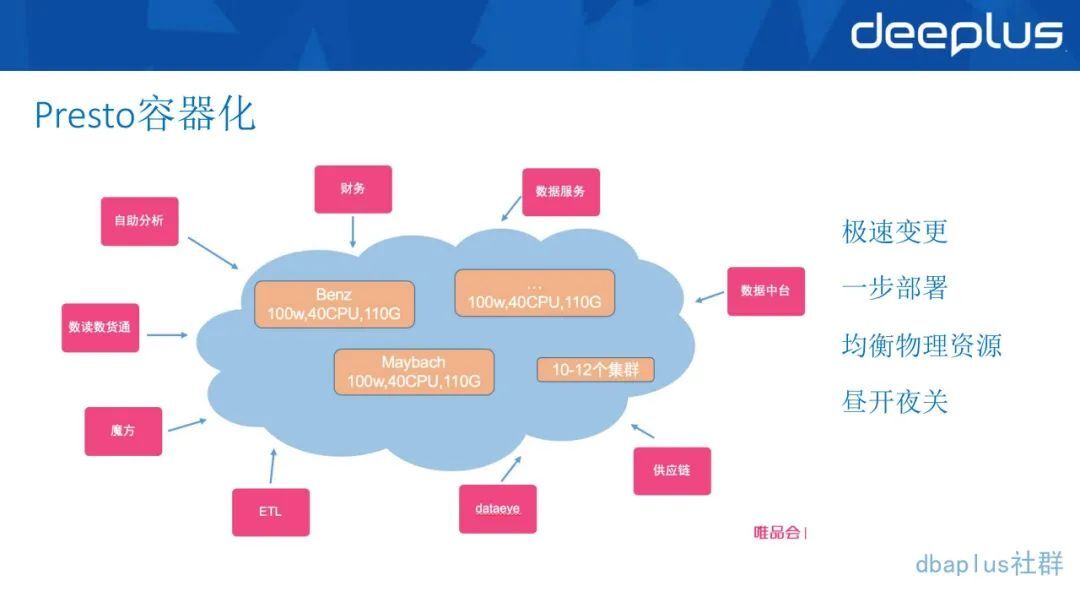
Presto 上云接入 K8S,可以智能扩缩容 Presto 集群,做到资源合理调度、智能部署等功能,运维起来就非常方便。我们只需要给 Presto 加一些容器就可以智能的调用它的资源情况。再配合上文提到的准入的工具,就形成了整个链路的智能路由效果。我们也通过这一套上云和广告工具,实现了和一线团队 Spark 资源集群借调。白天把资源返还给我们去做 PrestoADHOC,夜间我们会把资源释通过 k8s 释放出来,给 spark 去跑离线叫法,这样就实现了资源的高效利用。
6、ClickHouse 的引入
随着业务对于 OLAP 的要求越来越高,部分业务场景 Presto 和 Kylin 无法满足现在的需求,比如有百亿 JOIN 百亿(Local join)的低延迟实时数据场景,和对中等的 QPS 的查询平均响应时间要求低于 1 秒的 OLAP 使用场景等,所以我们现在把目光转向更快的 ClickHouse。
下图我们对比了 ClickHouse 和已经使用的 Presto 和 Kylin。

ClickHouse 的优势如下:
数据存储方面,ClickHouse 的原数据一部分会储存在 CK 里面,路径和其他东西会储存在 ZK 里面。本地也有文件目录储存原数据表、本地表、分布式表和线表文等信息。这些都在本地的文件目录里面,感兴趣的同学可以去看一下 ClickHouse 的整个的目录构成。
数据按照设置的策略存储在本地的目录上,在查询上的特定场景中,甚至可以比 Presto 快 10 倍。但是即使用了更新的表引擎还是存在很多限制和问题。
我们发现它的场景对于我们来说,比较实用的场景就是有百亿级数据量的 JOIN,和一些比较复杂的数学数字的查询,还有人群计算等,比如说涉及到一些 Bit map,后面将会详细的介绍这方面的内容。
7、ClickHouse 针对于 Presto 等传统的 OLAP 引擎的优势

大宽表查询性能优异,它主要的分析都是大宽表的 SQL 聚合,ClickHouse 整个聚合耗时都非常小,并且具有量级的提升。
单表性能分析以及分区对其的 join 计算都能取得很好的性能优势。比如百亿级数据量级 join 几十亿级数据量级的大表关联大表的场景,在 24C*128G*10shard(2 副本)通过优化取得了 10 秒左右的查询性能。如果数据量级更小一点的话,基本上都能维持在 1 到 2 秒内,就是用比 Presto 更少的物理资源,实现更快的查询。
ClickHouse 带来了很多比较高效的数据算法,比如各种估算,各种 map 的计算和 Bit map 与或非的预算。在很多场景下,这些都值得去深挖。后面我们会简单介绍一下,我们现在掌握的一些 Bit map 的场景。
二、实验平台基于 Flink 和 ClickHouse 如何实现数据自助分析

如今很多技术也都在围绕 A/B-test 展开,所以我们最近也在关注这些这样的应用场景。
1、实验平台 OLAP 业务场景
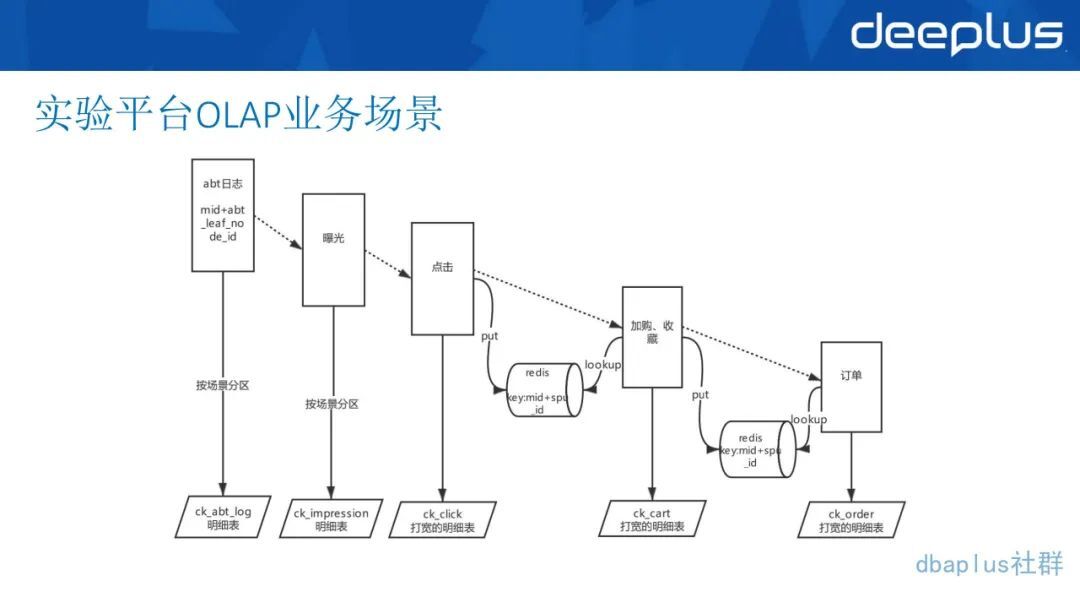
上图是实验平台一个典型的从最左侧的 A/B-test 的日志到下段再到曝光、点击、加入购物车、收藏,最后生成订单。这明显的是一个从上到下的漏斗下降的过程。我们实现了 Flink SQL Redis connector,支持 Redis 的 sink、Source 维表关联内可配置 cache,极大地提高应用的 TPS。通过 Flink SQL 实现实时数据流的 pipeline,最终将大宽表 sink 到 CK 里,并按照某个字段粒度做 murmurhash 的存储。保证相同用户的数据都存在同一个副本的节点组内。
我们自己在 Flink 的 ClickHouse 的 connector 这一端也做了一些代码的修改,支持写入本地表的一个相关功能。
2、Flink 写入 ClickHouse 本地表的流程
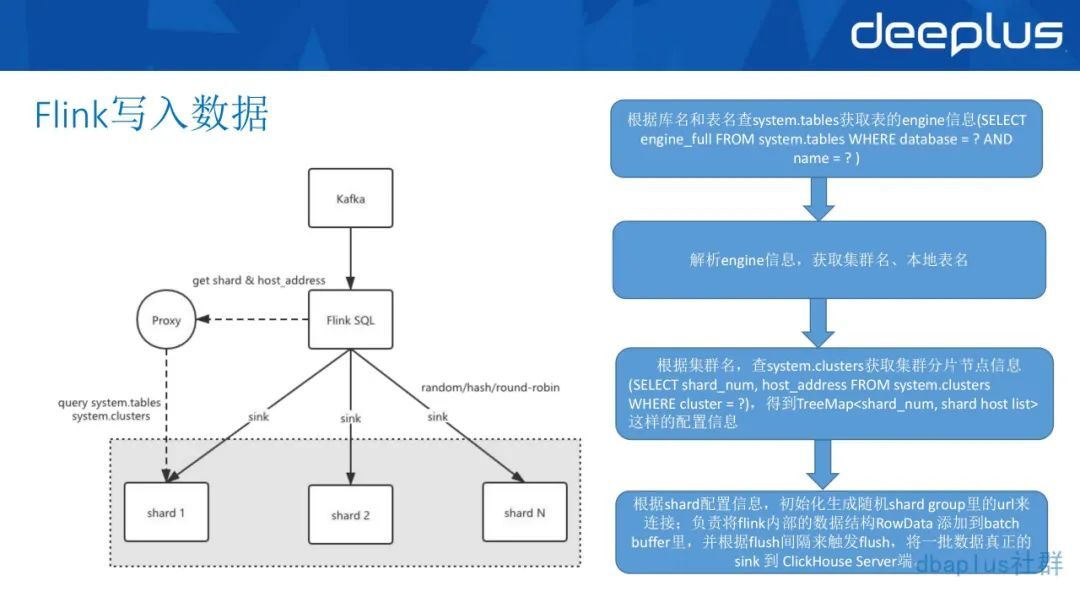
第一步是根据库名和表明查 ClickHouse 的原数据表, SQL 表示 system.tables,这是 ClickHouse 自带的系统表。获取要写入的表的 engine 信息。
第二步是解析 engine 信息,获取这个表所存储的一些集群名,获取本地表的表名等这些信息。
第三步是根据集群名和查询数据的表,通过 system.clusters 也就是 ClickHouse 的系统表,获取集群的分片节点信息。
最后根据下的配置的信息,初始化生成随机的 shard group 里的 URL 来连接。这样子 Flink 的 ClickHouse 就会通过 URL 来连接机器,并根据设置好的进度时间触发 flush,将一批数据真正的 sink 到 ClickHouse 的 server 端。(这里也涉及到一些参数优化)
以上就是我们如何经过修改,完整地把数据从 Kafka 通过 Flink 写入 ClickHouse 的一个流程。
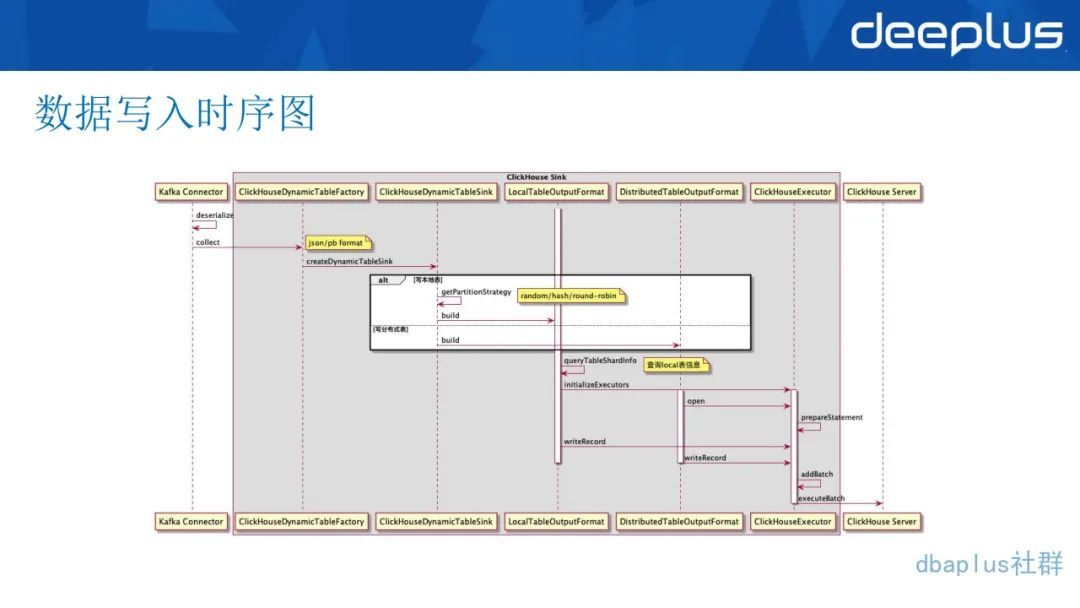
Flink 数据写入的时序图可以参考下图:
3、ClickHouse 百亿级数据 JOIN 的解决方案
在实际应用场景中我们发现了一些特定的场景,我们需要拿一天的用户流量点击情况,来 JOIN A/B-test 的日志,用以匹配实验和人群的关系,这就给我们带来了很大的挑战,因为需求是提到 Presto 这端的,在这端发现百亿 JOIN 百亿,直接内存爆表,直接报出 out of limit memory 这种错误,无法查出。两张大分布式表 JOIN 出来的性能也非常不理想,我们把它缩到几十亿 JOIN 十亿的情况,SQL 能查出来,但是可能要查个几分钟,这样子是完全不能作为 ADHOC 的性能来给用户提供服务的。
在这个情况下,甚至用户可能还会想加入几张尾表,这样的表格数据量会更多,查询会更加麻烦。我们想用 ClickHouse 去看看应该怎样去解决这样的问题。

分桶 join 字段
在这种情况下,我们用了类似于分桶概念。首先把左表和右表 join 的字段,建表时用 hash 来落到不同的机器节点,murmurHash3_64(mid)。
如果是写入分布式表的话,在建表的时候直接指定这个表的规则是 murmurhash 字段,insert into 分布式表,会自动按照 murmurhash 的规则,通过 ClickHouse 来写入不同的表。如果是写入本地表,在 Flink 写入段路由策略加入 murmurhash 即可。
总而言之不管你从哪里写,分桶规则一定要保持一致。在查询的时候,使用分布式表 JOIN 本地表,来达到想要的效果。如上图右边的 SQL,左表-all 是分布式表,JOIN 右边的-local 表,并不是用-all 表去 JOIN-all 表,这样就达到了分桶的效果。

这样分桶后 JOIN 的效果,是等于分布式表 JOIN 分布式表,我们做了多次验证,且处理的数据量只有总数据量/(集群机器数/副本数)。比如我们有 20 台机器,然后每个机器有两个副本,我们看一下 input size,等于总数据量除以 10,那么 20 台机器有 2 个副本的话就有 10 个不同的 shard。而且这个是可以通过扩容去进一步缩小数据量的。
所以我们第一步做的就是把 JOIN 的数据量放小,这样子的话 JOIN 写出来以后,它也是在本机上进行,根本不用走分布式表,只是在最后聚合运算的时候再去做分布式。值得注意的是,即在左表 JOIN 右表的过程中,如果左表是子查询,则分布规则不生效,查询出的结果也远远小于预期值。等于本地表 JOIN 本地表,对分布式没有要求。如上图所示,SELECT)左边是子查询 SELECT*FROM tableA_local,其实等同于 SELECT*FROM tableA_all,这个地方如果子查询写了 all 跟 local 其实效果是一样的,它都是当成 local 表来做。
这个是 ClickHouse 的自己的语义的解释,所以我们也不去评判它对不对。但它确实不同的语义查出来的效果也是不同的。
所以在用这种分桶效果的时候,要注意一下左表是不能用子查询的,如果用子查询,10 个 shard 查出来最后只有 1/10 左右,结果是不准确的。
4、增量数据更新场景
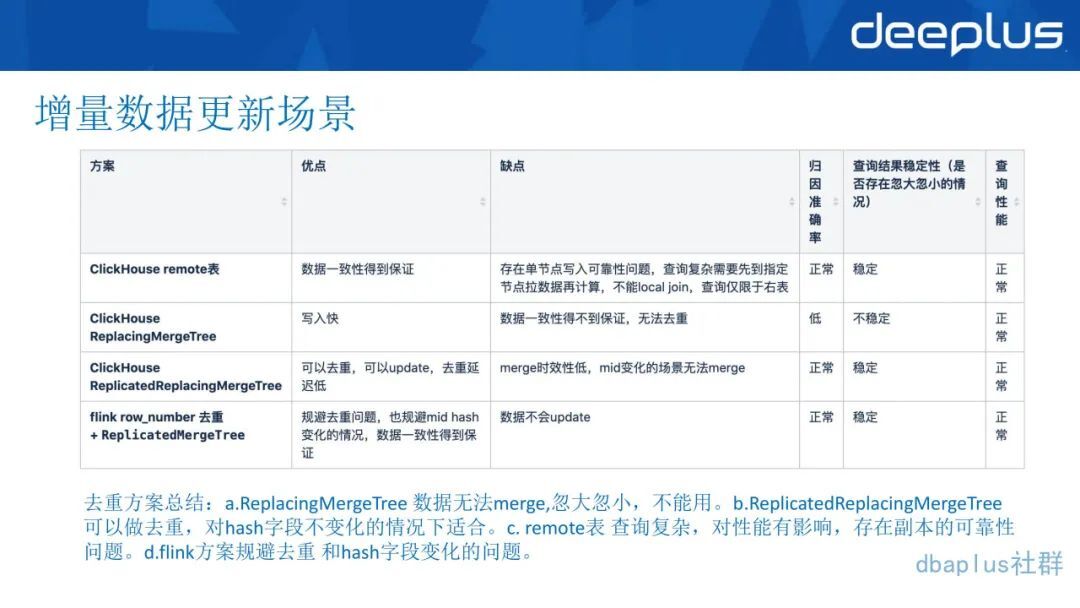
订单类数据需要像写 Kudu 或者 MySQL 一样,做去重,由于流量数据都实时写入数据,为了订单数据和流量数据做 JOIN,就需要对订单数据做去重,由于订单数据是有生命周期的,从产生之后会不停地 update。
我们用了一下这 4 种方案去验证了 ClickHouse,看看整个 ClickHouse 的性能如何:
ReplacingMergeTree 数据无法 merge,忽大忽小,不能满足需求。
带副本的 Mergetree 可以做去重。对 Hash 字段不变化的情况下合适。
remote 表。查询复杂,对性能有影响,存在副本的可靠性问题,但结果是准确的。
Flink 方案规避去重和 Hash 字段变化的问题。
总而言之,ClickHouse 并不是一个主打更新功能的引擎,有选择的使用,针对需求选择不同的使用方式,才比较合适。使用 ClickHouse 的更新的时候,个人建议要谨慎使用。
5、Flink 写入端遇到的问题及优化

需要注意:这样是为了满足两个场景,第一个是高写入场景速度快,可能 21 万条记录先到达,还有就是夜里可能打点数据很小,60 秒会产生一个半时再往里写,这样也是为了一个低延时,我们也是会选择 60 秒这样的场景做兜底。

需要注意:coalesce 空值处理函数是在 Flink SQL 里面加上的,这样子就能保障数据在 sink 的时候是完整的,这个是比较准确的,也是我们比较推荐的一种方法。
三、使用 ClickHouse 中遇到的问题和挑战
1、ClickHouse 查询优化
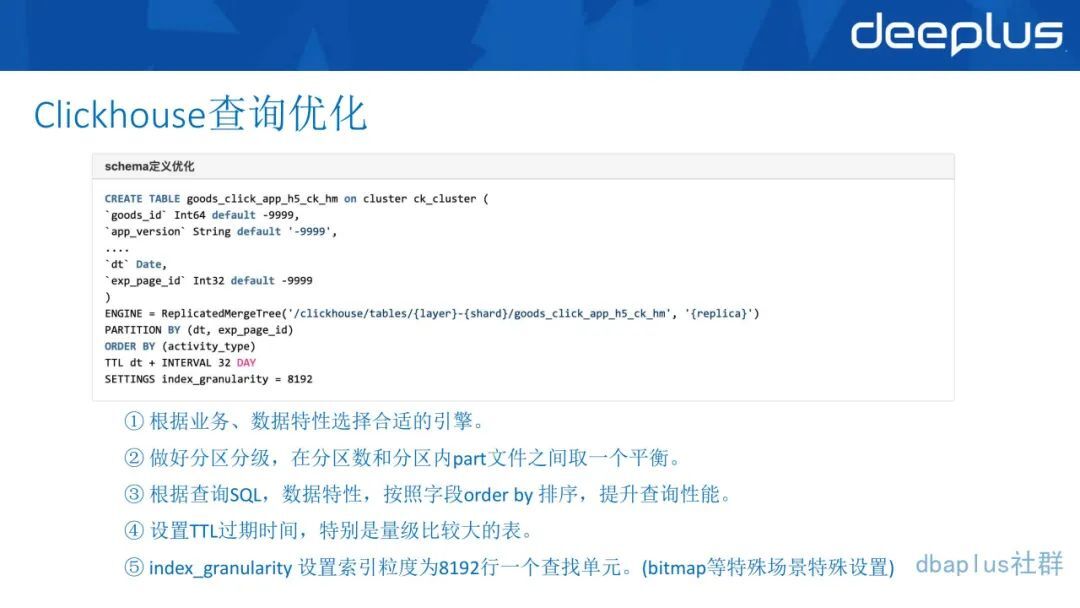
根据业务和数据特性选择合适的引擎,根据副本、Merge、更新之类的场景,选取表引擎。ClickHouse 表引擎选择好,能达到事半功倍的效果,而且选不选副本对数据的稳定性都很重要。
做好数据的分级分区,做好第一级分区、二级分区,很多时候分区是拿来运用数据的,比如日期分区、typed 种类等,都会起到第一层索引的作用,而且效果比索引的好,这样能方便快捷地找文件、找数据。最好是在分区数和分区内的 part 文件取一个平衡,一个分区的 Part 数也不宜过多,过多的话会导致扫描效率低下。
根据 SQL 特性,我们会去做 order by 的排序。类似于上图就是 order by 的 tape,做 OLAP 都知道,降低扫描的数据量对提升效率的加成是非常大的,这里也是为了减少查询主要的数据量,所以索引是非常重要的。
做好生命周期,生命周期是用 TTL ,这个 ClickHouse 建表的时候也是自带的,你看这里我们就是用了它自己的 dt,dt 是一个 date 类型,看到这两个是个 data 类型,然后加一个间隔,32 天的间隔做一个生命周期,生命周期也能省很多事情。这样的话历史数据等于也不会太多,我们也可以把历史数据导到其他的存储里面去,或者冷数据里面去做这个事情。
索引的粒度的设置,默认是 8192,但是在一些少行多列或者存在一些列特别大的表中就不是正式的,比如 Bit map,它是一行是一个标签,但是他 Bit map 一个字段非常大,可能是几十 G,一列就是几十 G,但是它一个表可能也就一两千行,这个时候值就要设置小一点。
2、常用参数调整
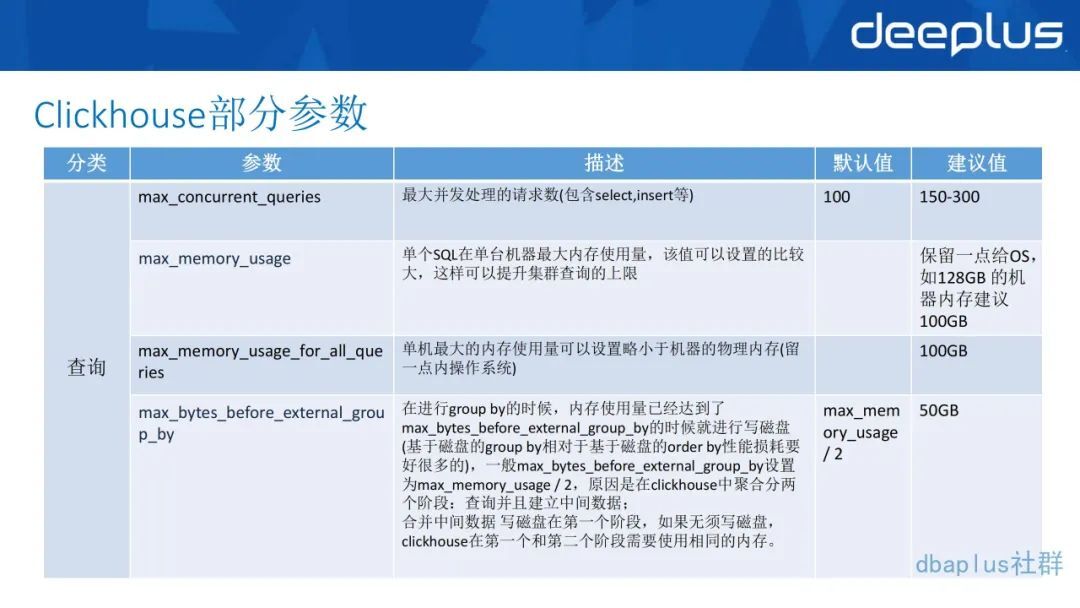

在正式的 ClickHouse 实践中,我们也一步步修改了 ClickHouse 默认的一些参数。
正如图上面针对查询和 merge 的并发度、内存设置的参数,配置都在 config 或者 user.xml 这些配置文件里面,针对一些特殊场景,可以用 session 来设计特殊参数,就不是全局的参数。这个参数的设置情况也可以在 CK 的系统表里面去查到。
第二个是 merge 的一些参数,包括它的后台线程数,这个也是按照 CPU 设的,根据你 CPU 的核数来设置线程数,这个都是根据业务和机器数去调优,然后再去写一些通用的 SQL 去测试。我们也是在很多次测试后设置了这么一个参数,现在性能也达到了一个比较满意的效果。
3、物化视图

说到 ClickHouse 就必须说说物化视图,因为 ClickHouse 的物化视图是一种查询结果的持久化,它确实是给我们带来了查询效率的提升。用户查起来跟表没有区别,它就是一张表,它也像是一张时刻在预计算的表,创建的过程它是用了一个特殊引擎,加上后来 as select,有点像我们写的 etl-join,熟悉 etl-join 的同事都知道,create 一个 table as select 的写法。
ClickHouse 的物化视图就是通过这种方式来表达所需要的需求和规则。如果历史数据也需要进行初始化,需要加上一个关键字 popular,但是这种创建的时候你要注意原表在往物化视图计算历史数据的时候,你要停止写,要不然他 popular 生成物化视图去追历史数据这段时间,你新写入的数据它是不会计算难度的,包括以后也不会统计这段时间你写的数据。
所以介入历史数据加 popular 的时候,在物化视图完成之前,不要写入,这是一个注意事项。
需要特别注意的就是我们在使用物化视图的过程中,也体会到它的一些优点和缺点。
优点:查询速度快,要是把物化视图这些规则全部写好,它比原数据查询快了很多,总的行数少了,因为都预计算好了。
缺点:它的本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去重、去核,或者是一些这样分析,在物化视图里面是不太好用的。在某些场景的使用也是有限的。而且如果一张表你加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源,你可能会发现你写数据的时候突然数据带宽码,或者是存储一下子增加了很多,你就会需要看一下整个物化视图的情况。
四、展望

1、RoaringBitmap 留存分析
用 RoaringBitmap 在人群标签的场景加速流程分析,利用 Bit map 能提升很多空间,而且能减少许多存储代价。可以用 ClickHouse 里自带的 Bit map and Bit map all 这种云或非的计算的定义性,来完成业务的需求。比如一个标签, A 标签有 1 亿个人群,它就是一个 Bit map,B 标签它有一个 5000 万人群,我们想要同时满足 A 和 B 标签,只要用一个 Bit map and 把这两个 Bit map 往里塞,它直接就可以告诉你估算的数值,效率很高。Bit map 对于几百万、几千万这样的量级,他可能 10 秒之内就能返回。如果用其他的方式想把 Presto 写出口,SQL 又麻烦表又大扫描的行数又多。
2、存算分离
我们准备找一个合适的分布式存储去研究。例如 Juice FS,这是我们国内开源的非常优秀的文件系统。还有一个 S3,前段时间在 ClickHouse 官方放出来的实践,就是用亚马逊 S3 来做一个底层的分布式存储,这样做一个分布式存储是为了解决因存储而频繁扩容 ClickHouse 集群的问题。
因为 ClickHouse 是单机性的,所以扩容起来比较麻烦,需要把老数据也拿过去搬。但鉴于老数据跟新数据的一些规则不一样,在扩容的时候,新机器和老机器的数量会不一样,它 murmurhash 的结果也不一样,放到集群也不一样。
而研究存在分离云存储这样的方法,虽然我们要用的机器数不变,但却可以解决上述的问题。
3、资源开发工具
目前我们属于 ClickHouse 业务推广阶段,对 ClickHouse 使用方管控较少,也没做过多的储存、计算、查询角色等方面的管控。数据安全乃大数据重中之重,我们将在接下来的工作逐渐完善这一块。
4、权限管控
在 ClickHouse 的新版中,已经加入了 RBAC 的访问控制,官方也推荐使用这种方式。我们也想把这一套授权用到我们自己的 ClickHouse 的集群里面来。
5、资源管控
在资源层面我们会结合存算分离,给不同的业务分配不同的用户,不同的用户在云平台上申请的存储资源,我们就可以对每个用户的储存进行价值计算。
以上 5 点是我们未来准备在 ClickHouse 这个方向上面继续要投入去计算的事情。像 Bit map 的话,我们现在已经在与广告、人群还有实验平台在深度的合作当中了,以后有机会再跟大家分享。
Q1:ClickHouse 数据入库的时延是多少?能达到秒级吗?在秒级时延下,单节点入库的吞吐量是多少?
A1:这里看你的 ClickHouse 用什么去写入,如果你是直接到 GEPC 端口插入的话,是可以达到秒级的,但是他主要是消耗在 merge 部分。这个是看你怎么用,如果你是用大数据的场景,用海量打点这样的数据,再用 GEPC 去查询的话就不太合适,它是达不到秒级这样的场景。但如果你是把它当成一个小存储,比如写入百万级这种的,它的 merger 也发挥不了什么作用,这也是能达到秒级的。
单节点入库的吞吐量是多少?其实这是要看是它的数据量条数还是它整个的量级,像 Flink 用 sink 去写入,我们达到的 TPS 峰值基本上是 60 万 GPS 左右,分到 10 台机器,每台机器大概是六七万 TPS 左右。这可能和机器的带宽、CPU、io 和底层存储是不是 SID 这方面有关。。
Q2:请问 OLAP 场景下都有哪些存储空间和访问效率优化方法?
A2:首先看一下 OLAP 场景你是用哪一种引擎,是哪一种存储,像我们现在用的比较多的就是 Presto,我们主要是用它的压缩或者是 HyperLogLog,这个是 Spark 和 Presto 都有的,但是不通用。我们是在 Spark 上把 Presto HyperLogLog 的类进行重构,所以说用 Spark 写入,然后用 Presto 去做 HyperLogLog,这样其实也是用一种预计算或是把储存的预计算和想要的结果数据场景来实现存储空间的优化,访问效率的话其实主要就是扫描数据量,第二就是 SQL 的优化。
我们主要是关注,根据这些 SQL 的 explain 去看它到底是慢在哪里,是慢在读取数据这一步,Presto 的 SOURCE 这一步有分 schedule 和 plan,还是慢在 HMS 一步,像我们最近做的就是把 HMS 搞组件分离。Presto 这边的话,我们有 etl,写这些的话是写主库的 HMS,读的话是读从库的 HMS,这样的话当你写的时候就不会影响读的效率,adhoc 写的就非常快,所以说这个问题本身还是很大的,每一个细节还值得深挖。
Q3:请问 Kudu 和 CK 的区别在哪?
A3:CK 本身是带了一套非常强大的查询引擎,Kudu 据我所知,要不就是用 Impala.,要不就是用 Presto 等引擎去查。CK 本身还是一个单机的储存模式,其实是用分布式表的概念,把这些单机的数据放在一起,然后去做聚合。它主要用的还是单机计算的效果。Kudu 的话本身更多地偏向于存储性能,偏向于实时数仓,像 update、upset 这些。像人群 Bit map 场景,我们可能只能用 CK 这一套,用它的储存和算法,用它 Bit map 的语法 function,这时候用 Kudu 就不太合适了。选型的时候会根据不同的业务场景来进行不同的架构选择。
Q4:请问 ClickHouse 和 Flink 如何保证一致性?
A4:我们这边的话,是 Kafka 首先会保留三天的数据,包括 offset 会自动保存。我们本身是实时这边一套,离线那边一套,我们会去监控离线那边五分钟的表,然后和 ClickHouse 做数据质量校验,如果发现数据不同,会看一下差异在哪些地方。在 ClickHouse 这边也会有分区把数据删了做一个重建,目前看来数据还是比较准确的。大部分数据不准确是在 Waterdrop 中,但是用 FlinkSQL 写入的话,现在看来 Flink Connector 的性能和准确性还是够的。另外我们已经做好了跟离线活动表的 JOIN,这个也可以用来判断。
Q5:请问 Kudu 在唯品会还有使用场景么?
A5:我们 Kudu 主要是做了订单数据,打点数据曝光数据很少上去,只有一定的曝光数据上去,我们 Kudu 的话机器不是特别多,只有不到 20 台,三个 Kudu master,其他都是 TABLET,主要是把数据通过 Flink 落到 Kudu 里面,然后用 Presto 来查,用 Presto 把 kudu 跟一些其他的 Hive 或 MySQL 的一些维表来 JOIN,基本上就是订单和很少的一部分曝光场景在用。
Q6:请问存算分离有什么方案?
A6: 存分离的话,现在用 Juice FS 非常合适,大家可以去看一下,这个是国内的开源的项目,他们也非常愿意跟 ClickHouse 来做这件事情。第一个情况就是把这种分布式的存储,直接当成本地存储的挂载,通过这种方式来实现。第二个就是更深度定制,就是通过写入文件流或者是那种 outsteam 流去改一些 CK 的源码,来对接 FS,直接把 Juice FS 这种文件系统的 FS 类拿过来,直接在 ClickHouse 源码里面去用。
如果刚开始不是深度使用的话,可以用第一种挂载方案来试一下。第二,如果有源码修改的能力,有意愿的公司可以去试一下。主要是在 FS、Stream 这种文件流的写入和读取这一块要改一下源码。
Q7:请问 ClickHouse 和 Kylin 如何选择?
A7: ClickHouse 和 Kylin 差别还是比较大的。首先 kylin 是通过 Hive 预计算以后,把数据放到 Hbase 里面,在最新的 Kylin 4.0 的话,它是用 Spark 去做一些事情。ClickHouse 它本身是用 C 写的,所以说他整个在 CPU 的 SIMD 这个层面,是有优势的。而且 ClickHouse 数据就存在那里,你会用不同的规则,不同的汇聚条件,更多的是根据更灵活的条件做查询 adhoc 的场景。像 Kylin 的话,我们更多的愿意把它作为固定报表或者预计算的场景,两个的使用方式可能还是不太一样的。
Q8:请问多表关联性能如何?
A8: 刚才我们看到很多表,如果你是用分布式表 JOIN 分布式表,不用我们这种分桶方案,它的 JOIN 性能是不行的,因为他的理论是把所有分布式表的数据,拿到一台单机上来做 JOIN,这个效果是不好的。
但是像我跟大家分享的,我就是通过一些具体的主键 ID 或者其他东西,把它进行分桶,就是 a 表、b 表、c 表三个表 JOIN,我们把三个表的某一个表的 user 这个字段都是按照一定规则落到这台机器,本地做一个 JOIN,10 台机器都把它本地化做起来,最后再通过整个分布式表,把他们放在一起。这样子就形成了一个多表 JOIN,就是刚才我分享的,大家可以看一看 PPT 里面说用分桶来做这种 JOIN,如果是分桶不了的话,你多表分布式 JOIN 的话,性能是比较一般的。
Q9:请问 ClickHouse 可不可以解读 Kafka?
A9: 可以,但是我们 Flink 里面还做了很多事情,比如数据处理,我们是通过 Flink SQL 做的,包括关联维表,关联 Redis 维表这种你直接链 kafka 引擎是做不了的事情。我们是有这种需求,就会去做这样的事情,能在 Flink 里面实现实时维表的这些功能的部分就在 Flink 里面做掉,减少 ClickHouse 这一端更多的关于维表关联和其他的工作。
Q10:请问 CK 的并发不好,如何解决 2c 场景?
A10: 目前解决方式就是加机器,用不同的 chproxy 连到不同的机器上,然后再用不同的 chproxy 去扛,chproxy 最终是会平均打到这么多台机器上,所以你机器越多,它并发的性能越好。但是它有一个瓶颈,就是如果 2c 的话,看你们公司的整个场景是如何的,如果是像淘宝这样的 2c,我觉得是不太合适的。
Q11:请问 Doris 有什么缺点,才采用 ClickHouse 替换?
A11: 目前解决方式就是加机器,用不同的 chproxy 连到不同的机器上,然后再用不同的 chproxy 去扛,chproxy 最终是会平均打到这么多台机器上,所以你机器越多,它并发的性能越好。但是它有一个瓶颈,就是如果 2c 的话,看你们公司的整个场景是如何的,如果是像淘宝这样的 2c,我觉得是不太合适的。
Q12:请问 Doris 有什么缺点,才采用 CK 替换?
A12: 我们替换并不是说 Doris 有什么缺点,更多的是 ClickHouse 有优点。像 Flink 这种维表的场景,在 ClickHouse 里面用大宽表 JOIN 的场景,包括后来 Bit map 场景,我们是根据场景需要用到 ClickHouse,而且也不太想多维护的原因才用 ClickHouse 替换,因为 Doris 是能实现的 ClickHouse 也能够实现,比如指标等。我们现在的监控日志用 ClickHouse 也能做,像有些 ClickHouse 能做,但 Doris 做不了,比如 Bit map。
Doris 本身引擎没有什么问题,是因为有更好更实用的场景,ClickHouse 能做更多的事情,所以我们也是基于这些考虑加过去 ClickHouse,把原来的一些东西都写到 ClickHouse 上去也可以减少维护成本。
嘉宾介绍:
王玉,唯品会实时平台 OLAP 团队负责人。负责唯品会 Presto、ClickHouse、Kylin、Kudu 等 OLAP 组件的开源修改、组件优化和维护,业务使用方案支持和指引等工作。
本文转载自:dbaplus 社群(ID:dbaplus)




