
这是关于为 The Marketing Technologist(TMT)网站打造基于内容的推荐系统系列的第二篇文章,我们将详细阐述基于内容的推荐系统的概念。在第一篇文章我们介绍了推荐系统的优点,大致可以把推荐系统分为两种类型:基于内容的推荐系统和协同过滤推荐系统。如果你还没有读过第一篇,推荐你在阅读完第一篇再继续阅读本篇。在这篇文章中,我们首先描述度量文章相似性的方法进而着手于基于内容的推荐系统中的第一个步骤。
本篇文章最终的代码可以在我们的 Bitbucket 上找到。
基于内容的推荐系统背后的概念
目标是为我们的读者推荐 TMT 上的其他文章。我们假设读者已经完整的看过一篇喜欢的文章,并希望阅读更多类似的文章。因此,基于用户的历史阅读行为,我们想要打造一个基于内容的、可以推荐新的类似文章的推荐系统。
为了得到准确和有用的推荐结果,我们希望用一个数学量化的方法来找到最好的推荐结果。否则,我们的网站会减少对读者的吸引力,进而他们会离开 TMT。因此,我们希望找到那些彼此相似的文章, 从而它们就是“彼此相近”的。也就是说,这些文章之间的“距离”是近的,一个较小的距离意味着更多的相似性。
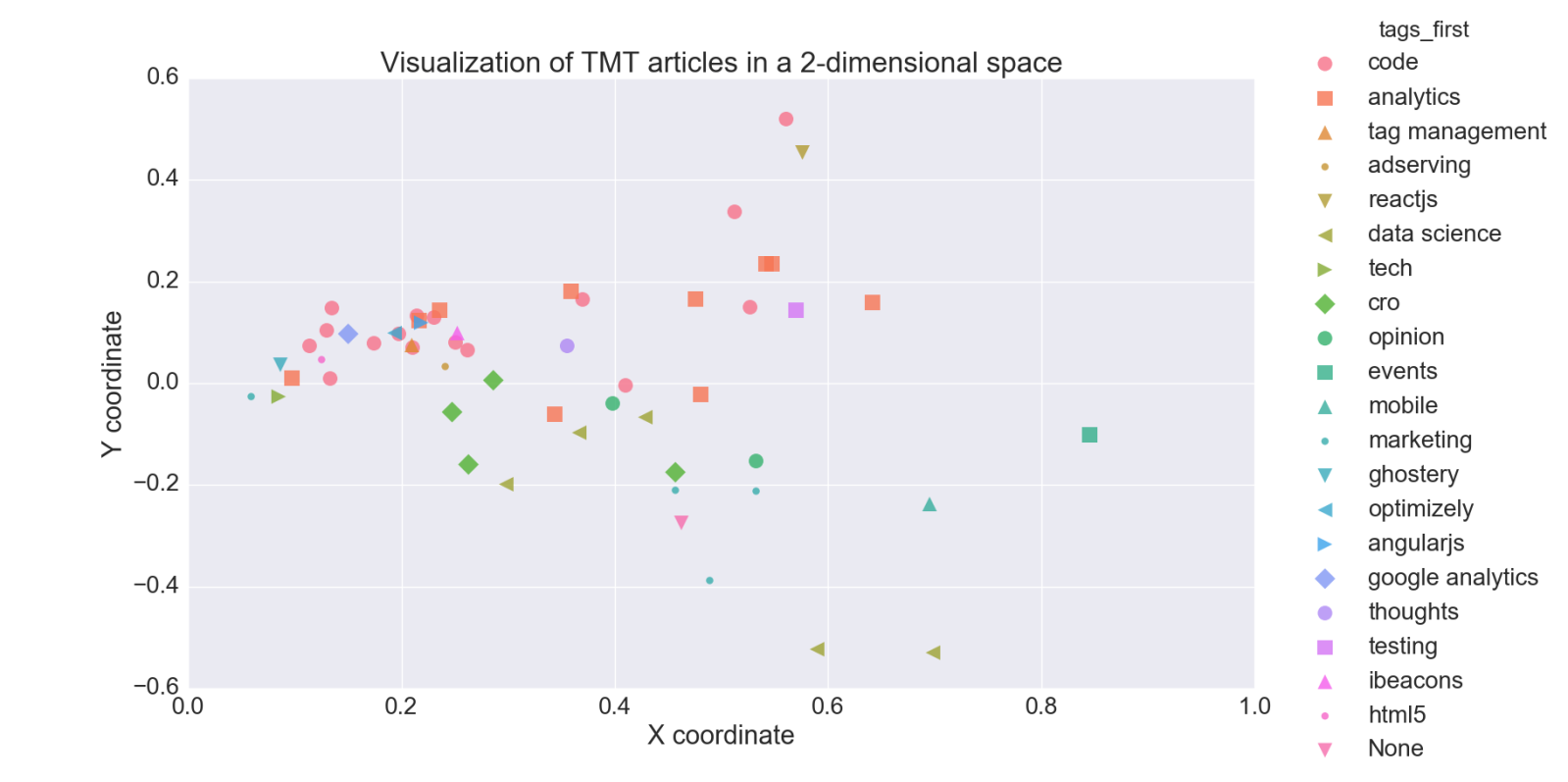
一篇 TMT 文章在 2 维空间可视化的例子
那么,这个距离的概念究竟是什么?假设我们可以将任意一篇 TMT 的文章映射为 2 维空间中的一个点。上面的图提供了一个将 76 篇 TMT 文章映射在 2 维空间中的例子。此外,我们假设两点越接近它们彼此就越相似。因此,如果把用户在读的文章当作 2 维空间中的一个点,则在这个空间中离这个点距离越近的点代表的那些文章可以被视为好的推荐结果,因为它们是相似的。这些点之间的距离有多远可以使用欧几里德距离公式来计算。在 2 维空间这个距离的公式可以简单地归纳为勾股定理。需要注意的是,这个距离公式也适用于更高维度的空间,例如 100 维空间(尽管超过 3 维空间的时候我们已经很难想象了)。
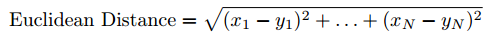
欧几里德距离公式
余弦相似性是另外一种计算两点的相似性的公式。想象一下,为每篇文章分配一个它倾向的方向。余弦相似函数使用的是两篇文章指向的方向差,即两篇文章方向之间的角度差。例如,在 2 维空间中,一篇文章方向是正北向和另外一篇文章是正西向,则他们在方向上的角度差是 -90 度。把这种角度差归一化在区间 [-1,1],其中 1 表示的是相同的方向,因此是完美的相似,-1 表示完全相反的方向,因此是完全没有相似性的可言的。
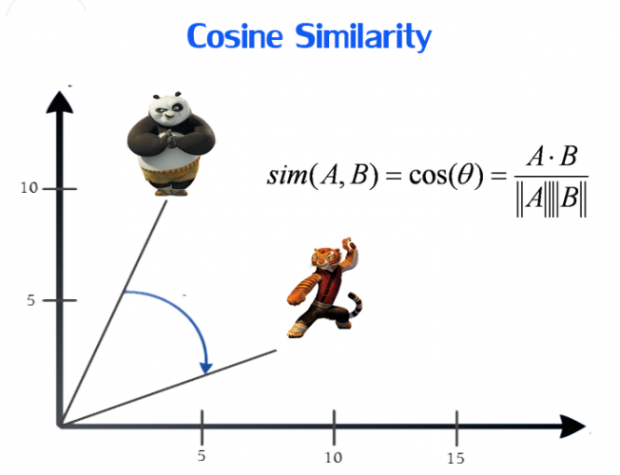
余弦相似性 ; 图片来自 Dataconomy.com
我们使用余弦相似性量度 TMT 文章的相似度是因为文章之间的方向比文章之间的精确距离更重要。此外,我们尝试了两个度量指标(欧氏距离和余弦相似性)并且余弦相似性度量指标表现的更好。:)
两个新的挑战
上面我们介绍了度量文章之间相似性的方法的概念。然而,现在两个新的挑战出现了:
- 我们如何把每篇文章映射成 2 维空间的点?
- 空间中的两点间的距离提供了有关文章的相似性的指标, 那么我们如何绘制这些代表文章的点之间的距离?
一篇文章可通过在 2 维空间中分配给它的坐标来绘制,例如一个 x 和 y 坐标。这意味着首先需要把我们的文章转换为数字格式,然后将其归约为两个值,例如 x 和 y 坐标。因此,我们首先要阐述一种通过应用特征提取算法来科学的量化 TMT 文章中文本的方法。
需要注意的是,我们将在下面讨论的处理文本的特征提取方法是专门为处理 TMT 中的文章而设计的。你可以想象一下,如果你正在构建一个针对电话的基于内容的推荐的系统,你可能需要一种不同的算法来将电话的属性(内容)转换为数字格式。
将 TMT 文章变换为数字格式
TMT 的文章是由大量的单词组成的短语和标点符号组成,需要被变换为数字向量,这个变换的过程中不允许损失文章的内容。我们希望最好是一个固定大小的向量。为什么我们想要固定大小?回想上面提到的 2 维空间的例子。将 2 维空间中的点和 100 维空间中的点进行比较是很荒谬的,对吧?此外,如果我们讨论两篇文章某些方面的相似性就需要用相同的方式来描述它们。
为了得到固定大小的向量我们将创建一些特征,例如那些文章可以测量的属性。在文本分析领域中,特征往往指的是单词、短语、数字或符号。所有的文章都可以被一个相同的特征集合来量化并表示,进而所有的文章就被变换为固定大小的数字向量。将文本变换为数字向量的整个过程称为特征提取,通常分为 3 个步骤:分词,计数和加权。

文本向量化的例子
步骤 1:分词
在特征数字化的第一步是分词。在文本分析中,分词被认为是从大量的文本中得到有意义的词汇单元。例如,物理速度可以用米 / 秒来表示。在文本分析中,文本的长字符串可以用词汇单元来表示。这些词汇单元通常对应单词。因此,获取句子I am happy, because the sun shines词汇单元的一种简单的分词方法就是通过空格进行分割。用这种分割方法得到 7 个词汇单元, 例如,I, am, happy,, because, the, sun, shines。分词之后,原始的句子就可以用这些词汇单元来表达了。
这种简单的分词方法引入了新的问题:
- 第一,这种方法不会过滤掉任何标点符号,从而导致了
happy,这个词汇单元是以逗号结尾的。这也就表明happy,和happy是两个不同的词汇单元,尽管他们实际上代表的是同一个单词。因此,我们需要过滤掉所有的标点符号,因为标点符号几乎和我们的文章中单词的含义是不相关的。需要注意的是,在其他场景中,标点符号可能和单词的含义是相关的。例如,在分析 Twitter 中的消息时,标点符号也是很重要的,因为它们通常被用来创建可以表达很多情感的笑脸。笑脸这个例子强调了每种数据源需要有自己的特征提取方法的事实。 - 第二,利用简单的分词方法,可能会获得的分词结果包含
works和working。然而这些都是同一个单词的不同形式,例如to work。当一个单词是另一个单词的复数形式时,同样也是上面的这种情况。在我们的基于内容的推荐系统中,我们假设这些单词不同的形式代表相同的含义。因此,这些单词可以归约到它们的词干形式并当作同一个词汇。为了达成这个目标,我们需要一种词干提取算法,可以把每个单词变换成其词干形式。需要注意的是这种词干提取算法每种语言都是专用的。幸运的是,已经有一些可用的免费程序库, 例如NLTK这个库可以帮我们完成这个工作。 - 第三,通常文本分析的存在的问题是如何处理单词的组合或者单词的否定语意。例如,如果仅仅用单独的单词
Google和Analytics并不能表明我们正在谈论的是Google Analytics这个产品。因此,我们需要创建两个或三个连续单词的短语,分别称为二元的 bi-gram 和三元的 tri-gram。I like big data这个句子,可以被转换为I,like,big,data,I like,like big,big data,I like big和like big data这些词组。
需要注意的是,这种分词方法并没有把单词所在的位置以及顺序考虑进来。例如,分词之后就不能确定单词big在原始的句子或文章出现的位置了。同时,单词自身也没有携带它前面和后面单词的任何信息。因此,我们在分词的过程中丢失了原始句子的某些信息。关键点是在保存一系列分词的同时也采集尽可能多的句子的原始信息。用我们的分词算法将会丢失原始句子的结构信息。有其他会把单词在文章中出现的位置和顺序考虑进来的分词算法。例如,Part-Of-Speech (POS)方法还增加了额外的标注信息,例如词性,如词汇是否是一个动词,形容词,名词或专有名词。然而,我们假设词性标注不会大大增加我们推荐引擎的推荐效果,因为词语在句子中的顺序在推荐的时候不是很重要。
步骤 2:词频统计
在第二步骤中,需要对每篇文章中的每个词汇单元的频率进行统计。这些词频数据将用于下一步骤,为文章中的词汇加权。此外这些词汇的计数信息将被用于稍后执行初步的特征选择,例如用来减少特征的维度。注意,文本分析的典型特性是,大多数的词汇仅在几篇文章中使用。因此,大多数的词汇在一篇文章中出现的频率为零。
步骤 3:加权
在最后步骤中,使用前面步骤得到的词汇和词频把所有文章转换为数字格式。把每篇文章编码成一个数字向量,向量的元素代表的就是步骤 1 得到的词汇单元。此外,词汇加权过程使用从第 2 步得到的词频。当给词汇赋完权重之后,它不在被认为是词汇而是被当作一个特征。因此,一个特征代表一个词汇,文章特征的的值是由加权方法确定的权重。
有多种可选的特征加权方法:
- 最基础的加权方法就是特征频率 (FF).FF 加权方法简单的使用文章中每个词汇单元出现的频率作为它的权重。例如,给定词汇的集合{mad,happy},句子
I am not mad, but happy, very happy,加权得到的结果向量就是 [1,2]. - Feature Presence (FP) 是一种类似的基础加权方法。在 FP 算法中,一个词汇被简单的赋予一个二元变量,1 代表这个词汇在这篇文章中出现,0 则相反。前面的例句用 FP 算法得到的结果向量是 [1,1],因为这两个词汇均在这个句子中出现了。使用 FP 加权算法一个额外的优势就是我们将会得到一个二元数据集,不会遇到扩展性的问题。扩展性问题可能在算法中遇到,例如在复杂计算中像计算特征值或 Hessian 矩阵时。
- 一种更加复杂的特征加权算法就是词频和逆文档频率 (TF-IDF)加权算法。这个方法使用两种类型的评分,例如
词频评分和逆文档频率评分。词频评分就是计算这个词汇在这篇文章中出现的频率。逆文档频率评分可以由总的文章数目除以包含该词语文章的数目,再将得到的商取对数得到。当这两个评分相乘时,如果得到的值比较大,表示该词语在一小部分文章里频繁地出现很多次,如果值较小则表示该词语在很多文章里都有出现。
在我们的基于内容的推荐系统中,我们将使用 FP 加权算法,因为这个方法非常快并且在推荐效果上不会比其他加权方法差。此外,用它得到的稀疏矩阵,在计算的时候有额外的优势。
降维
应用上述特征推荐方法后,我们会得到一个特征列表,用这些特征可以把每篇 TMT 文章数字化。我们可以在这个高维空间中计算出任意两篇文章间的相似度,但我们不倾向于这么做。因为有些特征不太可能表达文章之间的相似度,就像is和a,可从特征集合中移除掉,进而显著减少特征的数量,并提高的推荐结果的质量。此外,更小的数据集提高了推荐系统的速度。
文档频率 (DF)选择是用于降维最简单的特征选择方法,是很多文本分析问题的必需。我们首先删除最常见的英文停用词,例如the,a,is等在判断文章之间相似度时并不能提供太多信息的单词。做完这些,那些有着很高和很低的文档频率的特征也会被从特征集合中移除掉,因为这些特征也不太可能在判别文章相似度时起太大的作用。
回想一下,在本文的开头,我们可以想象在 2 维空间中的文章。然而,应用 DF 后我们仍处于一个非常高维的空间。因此,我们打算使用一种算法将高维空间降到 2 维空间,这让我们可以巧妙地将文章可视化。此外,在 2 维空间中很容易理解推荐系统的原理,因为距离的概念是很直观的。用来把我们带回了 2 维空间的算法是奇异值分解(SVD)。另外一种不同的算法是主成分分析(PCA)。我们在这篇文章中不会全面的介绍这些算法是如何工作的。总之,两者的本质都是找到最有意义的基,用这组基我们可以重造原始数据集和捕获尽可能多的原始方差。幸运的是, scikit-learn 已经包含了内置版本的 SVD 和 PCA 算法,因此我们可以很容易使用。
还有很多用来降维的方法,如信息增益和 X 平方准则或随机映射,为了简单起见,我们坚持使用 IDF 特征选择方法和 PCA 降维方法。
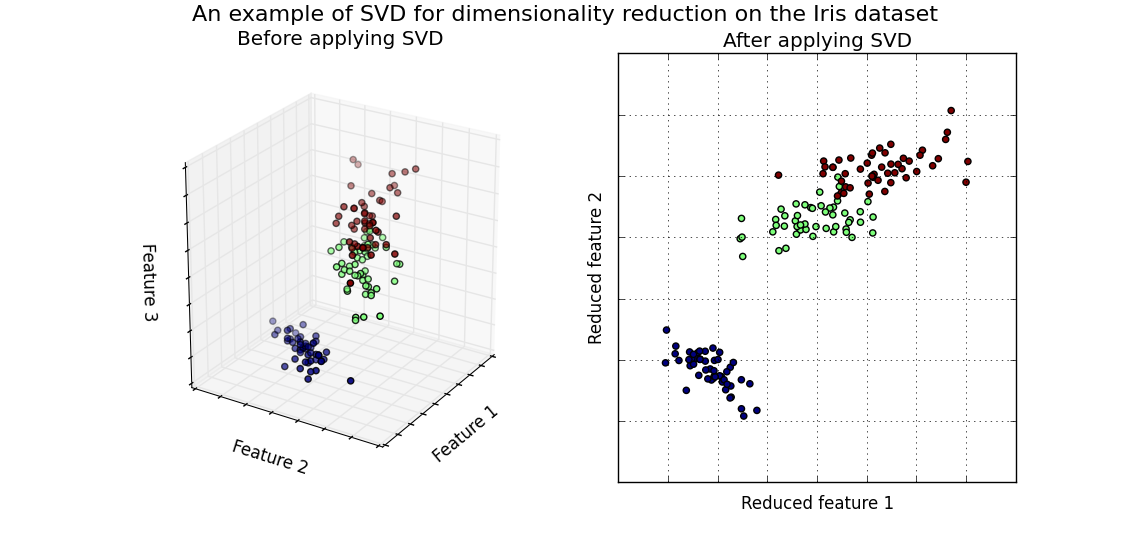
一个用 SVD 方法对 Iris 数据降维的例子。用 SVD 将从 3 维降到 2 维,并且不会丢失太多的信息。
标记推荐结果
应用所有上述步骤之后,所有的 TMT 文章被归约成一个 2 维空间的坐标。对于任意两篇文章,现在可以计算两个坐标之间的距离。我们现在唯一需要的一个函数,这个函数可以将当前的文章作为输入,返回与这篇文章固定数量的距离最小的 TMT 文章!使用欧氏距离公式这个函数是很容易实现的。
让我们构造一些场景来测试我们的基于内容的推荐系统。假设我们是刚刚读完 Caching $http requests in AngularJS 这篇文章的读者, 基于内容的推荐系统提供了以下 TMT 文章推荐结果供我们继续: Angular 2: Where have my factories, services, constants and values gone? 听起来很合理,对吧?下表提供的更多场景中的推荐结果。
Current article Recommendation Caching $http requests in AngularJS Angular 2: Where have my factories, services, constants and values gone? Track content performance using Google Analytics Enhanced Ecommerce report How article size helps you understand your content performance Data collection and strange values in CSV format Calculating ad stocks in a fast and readable way in Python How npm 3 solves WebStorm’s performance issues Webstorm 10 improves the performance of file indexing## 总结
我们将用几句话总结我们基于内容的推荐系统的第一步:
在最终的推荐系统,我们使用 SVD 算法将维度减少到 30 的而不是 2。这样做是因为当我们将其降低到一个 2 维空间,很多特征的信息将会丢失。因此,文章的相似性量度指标也是不太可信的。我们使用 2 维空间只是做可视化的。我们还对 TMT 文章的标题和标签应用了特征提取算法。这显著的改善了推荐结果的质量。
我们的推荐系统的参数是直观选择的,并没有做优化。这将在以后的文章中阐释!我们希望您从这篇文章学到了一些东西!此外,如果你喜欢这篇文章,我们推荐你继续阅读 TMT 中的 Optimizing media spends using S-response curves 这篇文章, 希望可以提高我在 TMT 网站中的 author value :-)
查看英文原文: A recommendation system for blogs: Content-based similarity (part 2)
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




