
12 月 19 日,百川智能宣布开放基于搜索增强的 Baichuan2-Turbo 系列 API,包含 Baichuan2-Turbo-192K 及 Baichuan2-Turbo。在支持 192K 超长上下文窗口的基础上,还增加了搜索增强知识库的能力。即日起,API 用户可上传文本资料来创建自身专属知识库,从而根据自身业务需求打造更完整、高效的智能解决方案。
“Baichuan2-Turbo 192K API 发布,一次可以输入 35 万字,代表今天行业最高的长窗口水准。”王小川说道。
此外,百川智能还升级了官网模型体验,目前其官网大模型已支持 PDF、Word 等多种文本上传以及 URL 网址输入,用户可通过官网入口体验搜索增强和长窗口加持后的通用智能。
体验官网:https://platform.baichuan-ai.com/playground
百川智能认为,搜索增强是大模型落地应用的关键,能够有效解决幻觉、时效性差、专业领域知识不足等阻碍大模型应用的核心问题。
一方面,搜索增强技术能有效提升模型性能,并且使大模型能“外挂硬盘”,实现互联网实时信息+企业完整知识库的“全知”;另一方面,搜索增强技术还能让大模型精准理解用户意图,在互联网和专业/企业知识库海量的文档中找到与用户意图最相关的知识,然后将足够多的知识加载到上下文窗口,借助长窗口模型对搜索结果做进一步的总结和提炼,更充分地发挥上下文窗口能力,帮助模型生成最优结果,从而实现各技术模块之间的联动,形成一个闭环的强大能力网络。

“大模型+搜索”构成完整技术栈
“没有搜索增强的大模型在企业里是没法落地的。”王小川说道。他解释道,很多行业需要垂直大模型来解决问题。普通改造有两个做法:一是 SFT、二是 Post-train,但两种方式都需要模型公司人才的介入,投入的成本巨大,企业做这件事情是一个巨大的挑战和资源消耗。一旦数据或算法更新,企业还得重训一次。因此,用行业大模型解决企业应用问题,虽然听着很好,但今天并没有良好的实践。
另外,大模型自身也并不完美,幻觉、时效性差、缺乏专业领域知识等问题,是其落地千行百业必须要面对的挑战。
当前,业界探索了多种解决方案,包括扩大参数规模、扩展上下文窗口长度、为大模型接入外部数据库,使用特定数据训练或微调垂直行业大模型等。这些路线各有优势,但也都存在自身的局限。例如,持续扩大模型参数虽然能够不断提升模型智能,但是需要海量数据和算力的支撑,巨额的成本对中小企业非常不友好,而且完全依靠预训练也很难解决模型的幻觉、时效性等问题。
在百川智能的技术思考中,“大模型+搜索增强”是大模型时代的新计算机,大模型类似于计算机的 CPU,通过预训练将知识内化在模型内部,然后根据用户的 Prompt 生成结果;上下文窗口可以看做计算机的内存,存储了当下正在处理的文本;互联网实时信息与企业完整知识库共同构成了大模型时代的硬盘。
百川智能认为,这样将大模型加上“外挂硬盘”的方式,能够让其在大多数领域里更加实用。
基于这一技术理念,百川智能以 Baichuan2 大模型为核心,将搜索增强技术与大模型深度融合,结合此前推出的超长上下文窗口,构建了一套“大模型+搜索增强”的完整技术栈,实现了大模型和领域知识、全网知识的链接。
百川智能表示,其在业内探索的长上下文窗口和向量数据库路径基础上,将向量数据库升级为搜索增强知识库,极大提升了大模型获取外部知识的能力,并且把搜索增强知识库和超长上下文窗口结合,让模型可以连接全部企业知识库以及全网信息,能够替代绝大部分的企业个性化微调,解决 99%企业知识库的定制化需求。

稀疏检索与向量检索并行
在大语言模型时代,用户需求(Prompt)与搜索的对齐成为了大模型获取外部知识过程中最为核心的问题。为更精准理解用户意图,百川智能使用自研大语言模型对用户意图理解进行微调,将用户连续多轮、口语化的 Prompt 信息转换为更符合传统搜索引擎理解的关键词或语义结构。
此外,百川智能还参考 Meta 的 CoVe(Chain-of-Verification Reduces Hallucination in Large Language Models)技术,将真实场景的用户复杂问题拆分成多个独立可并行检索的子结构问题,从而让大模型可以针对每个子问题进行定向的知识库搜索,提供更加准确和详尽的答案。同时,通过自研的 TSF(Think Step-Further)技术,百川智能知识库可推断出用户输入背后深层的问题,更精准的理解用户的意图,进而引导模型回答出更有价值的答案。
在精确理解用户需求基础上,想要进一步提升知识获取的效率和准确性,还需要借助向量模型解决用户需求和知识库的语义匹配问题。为此,百川智能表示,自研的向量模型使用了超过 1.5T token 的高质量中文数据进行预训练,通过自研的损失函数解决了对比学习对于 batchsize 的依赖,在 C-MTEB 评测集 6 个任务(分类、聚类、文本推理、排序、检索、文本相似度) 中的 5 个任务上都取得了效果的大幅领先,综合分数登上榜首:
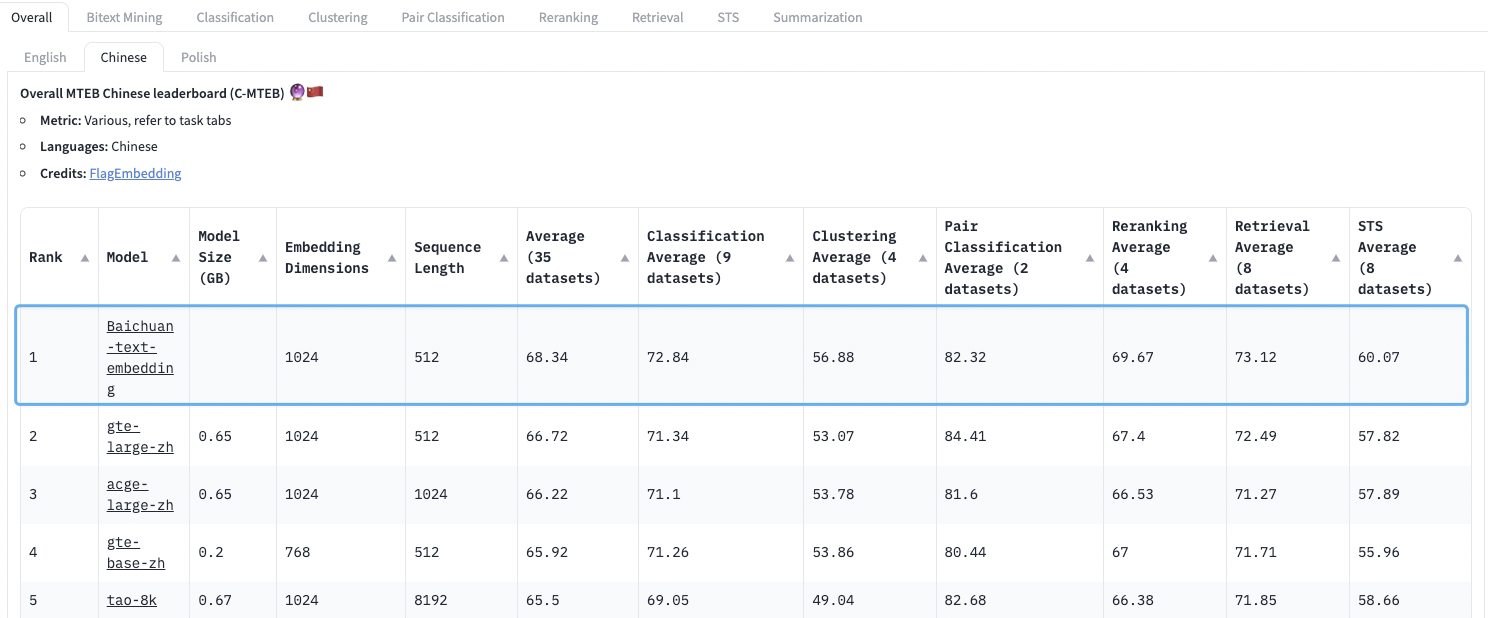
虽然向量检索是当下构建大模型知识库的主流方法,但向量模型的效果过于依赖训练数据的覆盖,在训练数据未覆盖的领域泛化能力会有明显折扣,并且用户 prompt 和知识库中文档长度的差距也给向量检索带来了很大挑战。
对此,百川智能在向量检索的基础上融合了稀疏检索和 rerank 模型。百川智能表示,通过稀疏检索与向量检索并行的混合检索方式,将目标文档的召回率提升到了 95%,而市面上绝大多数开源向量模型的召回率为 80%。
为解决模型“幻觉”加重现象,百川智能表示,在通用 RAG(检索增强生成)基础上首创了 Self-Critique 大模型自省技术,该技术能够让大模型基于 Prompt 对检索回来的内容从相关性、可用性等角度进行自省,筛选出最优质、最匹配的候选内容,提升材料的知识密度和广度,并降低检索结果中的知识噪声。

长窗口+搜索,实现“真·大海捞针”
长上下文窗口虽然可以接收更长的文本信息,但扩展上下文窗口长度会影响模型性能,在当前技术下存在上限。另外,长窗口每次回答问题都要将文档全部重读一遍,推理效率低、成本高。
百川智能通过长窗口+搜索增强的方式,在 192K 长上下文窗口的基础上,将大模型能够获取的原本文本规模提升了两个数量级,达到 5000 万 tokens。通过搜索增强,模型可以先根据用户的 Prompt 在海量的文档中检索出最相关的内容,再将这些文档与 Prompt 一起放到长窗口中,有效节省了推理费用和时间成本。
“大海捞针”测试(Needle in the Heystack)是由海外知名 AI 创业者兼开发者 Greg Kamradt 设计的,业内公认最权威的大模型长文本准确度测试方法。在“大海捞针”测试中,百川智能使用中文场景,实验配置如下:
大海(HayStack):博金大模型挑战赛-金融数据集中的 80 份长金融文档。
针(Needle):2023 年 12 月 16 日,王小川会上进一步分享了大模型的新思考。在王小川看来,大模型带来的新的开发范式下,产品经理的出发点,应该从思考产品市场匹配(PMF),到思考技术与产品的匹配怎么做,即 TPF(Technology Product Fit,技术产品匹配)。
查询问题:王小川认为大模型时代下,产品经理的出发点是什么?
对于 192k token 以内的请求,百川智能可以实现 100%回答精度:
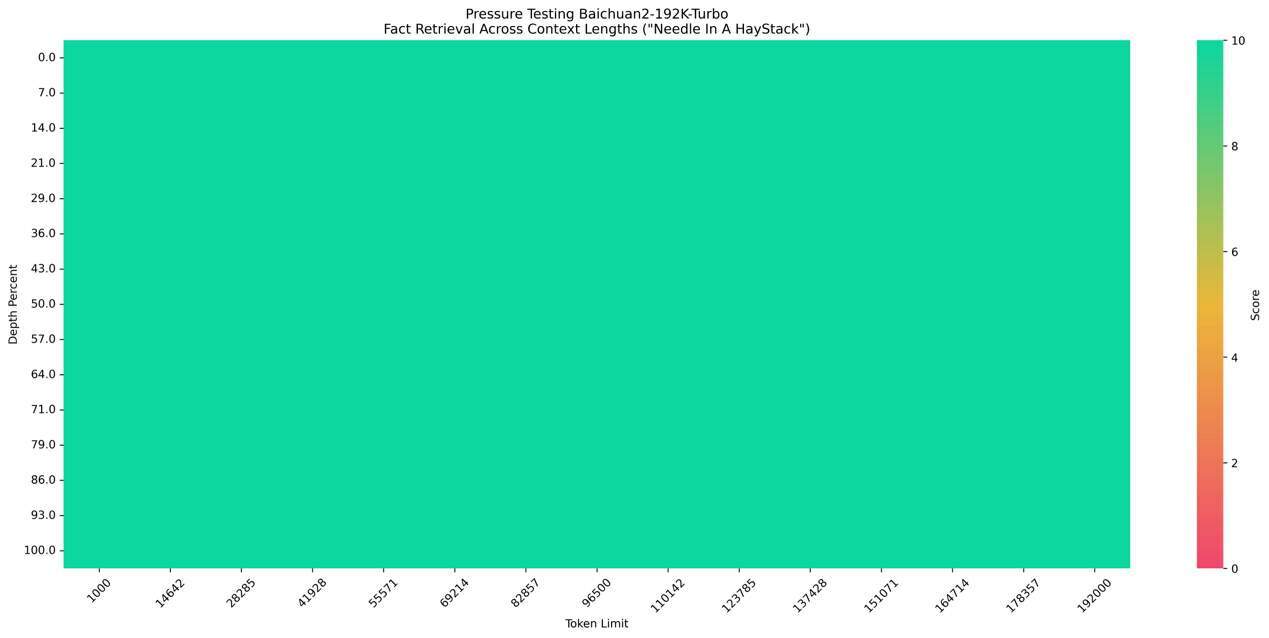
而对于 192k token 以上的文档数据,百川智能结合搜索系统,将测试集上下文长度扩展到 5000 万 tokens,分别评测了纯向量检索和稀疏检索+向量检索的检索的效果。
测试结果显示,稀疏检索+向量检索的方式可以实现 95%的回答精度,即使在 5000 万 tokens 的数据集中也可以做到接近全域满分,而单纯的向量检索只能实现 80%的回答精度。




