
本文首发于 InfoQ,由声网 Agora 开发者社区 与 InfoQ 联合策划,并由 InfoQ 审校。
实时视频通信已然成为当前互联网应用的亮点。特别在这疫情期间,全球都在“被隔离”,无法开展线下活动,更加迫切的需要以实时视频通信为技术支撑的各种虚拟线上交流。在可见的数年内,稳定高质量的互联网实时视频通信是各行各业的迫切需求,协同复工复产,帮助经济恢复;当用户习惯逐渐养成,实时视频通信又将成为生产生活的基本配置。
从应用的角度看,用户对服务的需求和网络基础设施永远是一对不可调和的矛盾。以实时视频通信为例,我们永远无法保证网络的全时稳定,弱网环境长期存在,特别在很多关乎到生活、生产乃至生命的关键时刻,通信网络往往受到极大的物理条件限制,如海事作业、应急救灾、高并发场景等。因此我们更加需要探索新理论新方法来有效的分析、精准的建模、准确的预判,以期实现弱网极限环境下(如极低带宽 <50kbps, 极不稳定网络抖动,极大时延等)的高质量实时视频通信。
过去的 5 年,我们南京大学电子学院团队在实时视频通信下做了一系列的探索工作,搭建了以互联网云游戏/云 VR 为应用的实时视频通信平台(https://www.anygame.info/),嵌入人工智能(AI)方法驱动自适应网络带宽调节和端到端用户体验优化。目前,该平台依然每天支持数百上千名用户实时操作,也帮助我们持续优化和更新,覆盖更多的应用场景。
近期乃至未来,我们认为实时视频通信的核心问题还未得到解决,特别是弱网下的高质量保证,而这些 corner case 往往是服务水平的直观体现。面对弱网的各种限制,我们提出极限实时视频通信:
第一次尝试实现全链路 AI 控制(包括编码和传输)
从 AlphaGo 开始,强化学习在任务决策方面展现了非凡的能力;三年前,我们提出基于强化学习的网络流控,自适应侦测调节带宽反馈给发送方优化视频压缩;这样的过程虽然带来了可见的效果,但是并没有真的解决网络流控和视频压缩流控的核心矛盾;网络流控的难点在于异构性,视频压缩的流控难点是内容多样性。近期,我们将强化学习的决策机制同时涵盖编码和传输,全链路 AI 控制(状态采集,决策预判),实现更加精准的带宽控制;
基于 IP 的分组交换网络在视频传输网络中占据主导地位,使得端到端网络的吞吐量、延迟等状态具有很高的时变性,并且在不同的用户之间由于网络资源竞争使得这些网络状态随时间动态波动。另一方面,由于实时视频通信要求的苛刻时延和视频内容复杂度差异,难以实现良好的码率控制。这使得难以通过对网路和内容建模生成统一、固定规则的码率自适应算法。
受人类行为决策思想启发,我们引入强化学习理论和工具,综合考虑视频编码与网络传输端到端流程,提出了基于强化学习的全链路网络流控,其系统框图如图 1 所示。智能体首先观察以往实时视频通信会话的经验,即从视频编码器和接收端收集的编码状态、网络和播放状态,使用神经网络挖掘编码和传输过程中视频内容和网络的潜在特征,并做出编码参数设置的决策。视频应用程序的发送端基于该决策编码和传输视频,在接收端进行解码播放后,产生新的状态,同时向智能体反馈当前决策的奖励。基于此奖励信号,智能体以最大化累积奖励为目标不断更新神经网络参数。最终,我们仅通过观察和学习编码、网络和播放的原始状态,对视频编码参数进行自适应调整,有效对抗网络波动的同时,有效提升用户体验质量(Quality of Experience, QoE)。
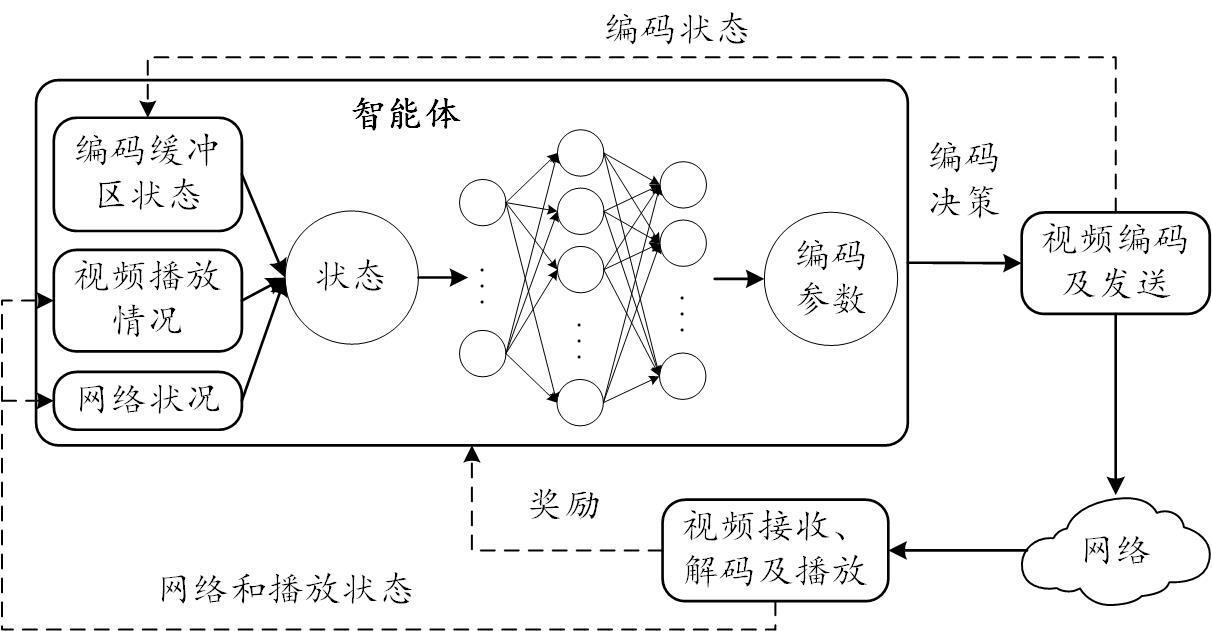
图 1 基于强化学习的全链路网络流控示意图
为评估基于强化学习的全链路网络流控的性能,我们选取当前先进的谷歌拥塞控制(Google Congestion Control,GCC)和瓶颈带宽与往返时延(Bottleneck Bandwidth and Round-trip time,BBR)算法进行了对比实验,结果如图 2 所示。可以看出,相对于 GCC 和 BBR 算法,我们可以提升分别 3.6%和 27.9%的归一化平均 QoE 分数。其中,我们以所有测试样本取得 QoE 的最小值与最大值进行归一化处理。
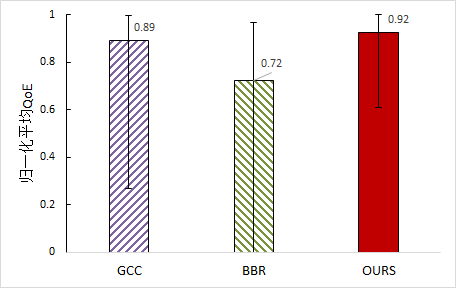
图 2 基于强化学习的全链路网络流控性能评估
引入网络多模态感知进行在线建模和推理
用户很难预判网络的好坏。网络的异构性让这个问题变得极为艰难。从医疗大样本数据分析推理得到启发,我们引入网络多模态感知,梳理网络的不同规则,应用在线建模逐步完善,覆盖各种网络情况。针对不同的网络情况应用对应的网络模型实现大幅性能提升;
对于实时视频通信场景,用于承载视频流的接入网络除了时变特性以外,还往往具备高度的异构性,如蜂窝链路(3G/4G/5G)、WiFi 无线链路、光纤链路等形态,这些接入网络具有不同的带宽、延迟和缓冲容量。此外,用户使用网络的环境也复杂多样,包括静止、步行、乘汽车、乘高铁等使用环境,使得带宽、延迟等网络特性动态改变,网络波动频繁。单一学习模型的性能往往难以覆盖如此复杂、异构的网络环境。
为此,我们引入了网络多模态感知进行在线建模和推理,其系统框图如图 3 所示。发送端经过视频获取、视频编码和视频流化等处理后将视频流发送到网络上,接收端接收视频数据进行解码和播放等操作,并收集网络状况和视频播放情况相关数据。为减小码率决策时延,我们将网路模态感知、码率自适应和在线建模与推理模块部署在接收端。首先,通过分析和挖掘历史网络状态特征,识别当前网络模态,初步感知整体网络质量情况。之后,使用基于强化学习理论的多模态码率自适应,依据网络模态动态切换码率自适应模型,从而针对不同网络状况精细化生成不同的码率自适应决策算法。在实际新网络环境下,基于多模态码率自适应模型应用在线建模和推理,进一步面向当前环境更新和优化模型和算法,解决新环境下模型性能退化问题。一次码率决策完成后,接收到通知和指导发送端的视频编码和视频流化模块对编码码率和发送码率进行调整,以抵抗动态网络波动。
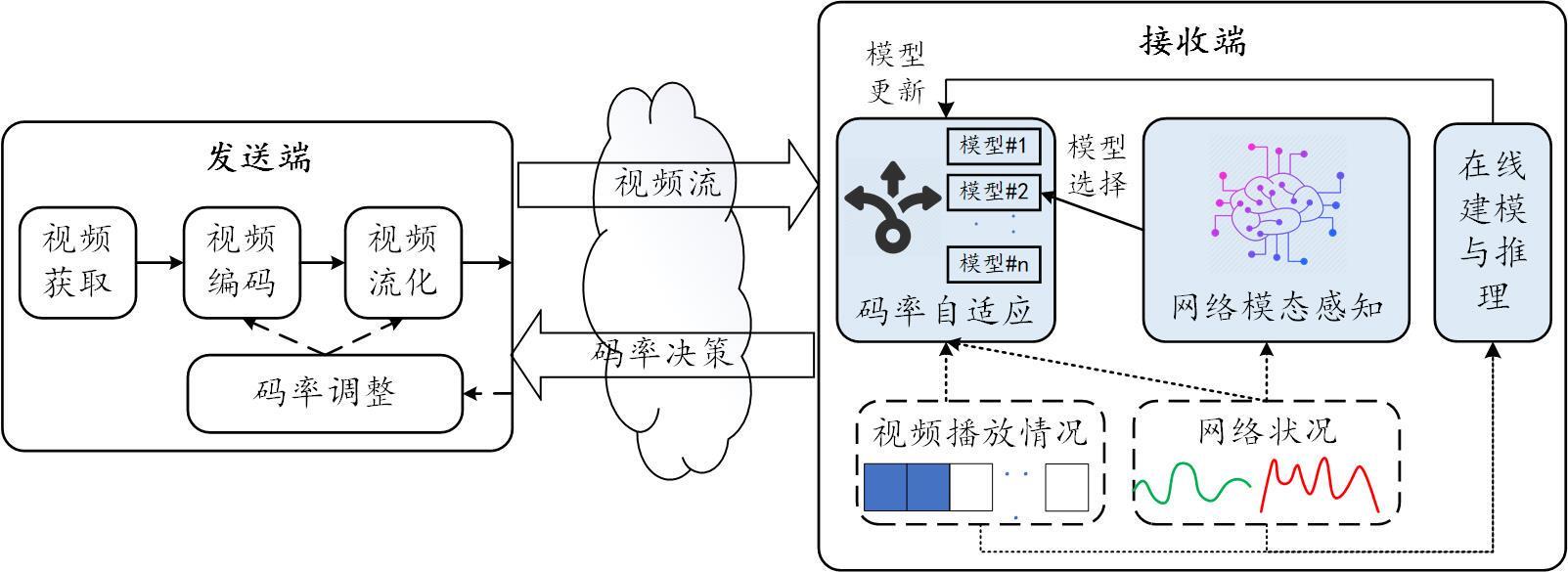
图 3 网络多模态感知进行在线建模和推理系统框图
鉴于图 2 中 BBR 性能差于 GCC,我们选取 GCC 算法作为评估网络多模态感知进行在线建模和推理性能的对比对象,结果如图 4 所示。对比于 GCC 算法,多模态码率自适应模型可以提升 9.1%归一化平均 QoE。其中,我们以测试样本取得 QoE 的最小值与最大值进行归一化处理。在线建模与推理方法相对于 GCC 算法,能够提升约 15.1%归一化平均 QoE,并且在训练时也达到相对稳定和可接受的码率自适应性能。
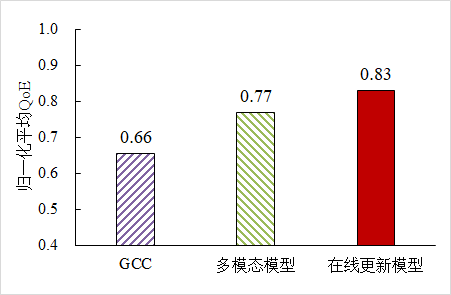
图 4 网络多模态感知进行在线建模和推理性能评估
强化网络主动决策
在网络状态变差的时候,视频传输总会丢包;目前策略是 FEC 或者重传。无论哪一种方式都让网络更拥塞。从另外一个角度看,视频内容具备很强时空一致性(Spatiotemporal Coherency);因此,与其进行保护,不如直接有选择的丢弃,后期利用时空一致性进行补偿。
为此,我们引入了智能时空预测补偿模块,通过联合多帧视频时空相关一致性来在解码端直接重建丢弃的视频帧,其系统框图如图 5 所示。接收端经过视频解码得到一系列时空相关的视频解码帧,这些视频帧在编码端编码过程中已通过有选择的丢弃,来确保已存在的视频解码帧有很强的时空一致性来对丢弃帧进行恢复。智能时空预测补偿模型能根据输入的解码视频帧构造一个非线性的二阶预测模型,该模型利用了物理概念对运动进行二阶建模,结合非线性的神经网络模型更好地预测丢失视频帧。模型可基于接收到的视频解码帧,有选择地采用直接法和引导法,对不同运动特性和场景的视频进行分区域多重运动补偿,重建丢失的视频帧。此外,为了获得极高的视觉流畅度,我们在重建过程中引入了时空一致性的约束,使得重建的视频序列得到极高的视频时空流畅度,基本上在视觉感知不变的情况下,通过主动丢包可以大幅降低网络压力,保证流畅服务。
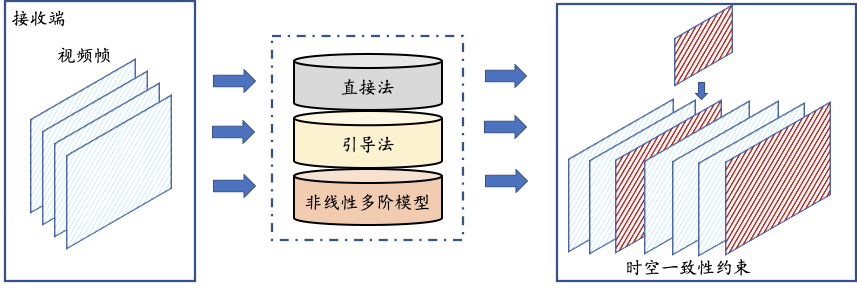
图 5 智能时空预测补偿模块
通过上述三个方面的创新,我们实现了 50kbps 下的高质量视频实时通信。
作者介绍:
马展,教授,南京大学, mazhan@nju.edu.cn
刘浩杰,博士生,南京大学, haojie@smail.nju.edu.cn
陈浩,副研究员,南京大学, chenhao1210@nju.edu.cn




