
文 | 潇湘
编辑 | 王一鹏
1 月 20 日, Kimi k1.5 发布,全球 SOTA 级多模态思考模型的队列里,新增了一名成员。
据 Kimi 官方发布的 Benchmark 测试结果,k1.5 在 short-CoT 模式下,大幅超越了 GPT-4o 和 Claude 3.5 Sonnet 的水平,领先达到 550%。尤其在 AIME 榜单上,k1.5 有 60.8,而最高的 DeepSeek-V3 只有 39.2。在 long-CoT 模式下,k1.5 已达到 OpenAI o1 正式版的水平。
“这应该是全球范围内,OpenAI 之外的公司首次实现 o1 正式版的多模态推理性能。”
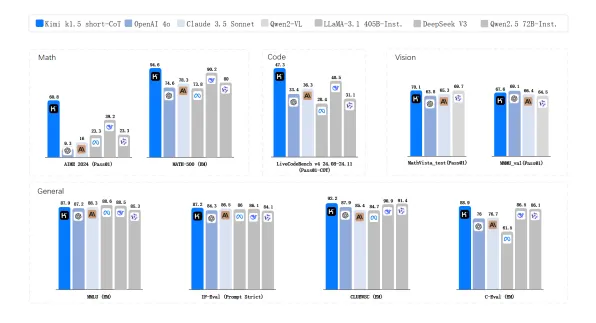
Kimi k1.5 Benchmarks(short-CoT)
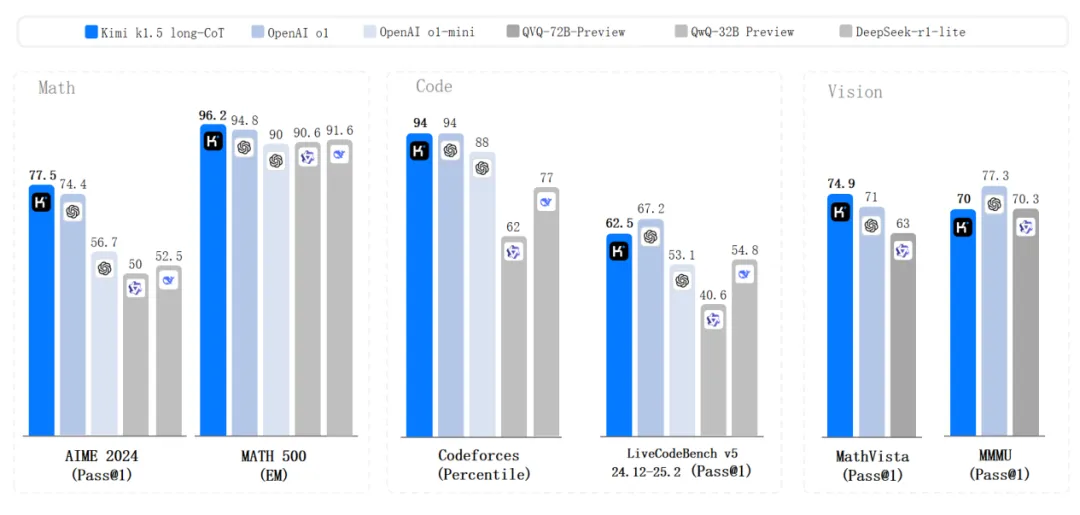
Kimi k1.5 Benchmarks(long-CoT)
作为 2025 伊始,国产大模型密集发版的一员,有人用游戏术语来形容月之暗面与其他模型厂商的竞争,戏称为“中门对狙”。
这一次月之暗面既没有急着倒向 B 端的某个行业场景,也没有固守“超长上下文”的技术阵地,而是在 k1.5 发布的同时附带了详细的技术报告,且成绩相当亮眼。
1 Kimi 如何为 2024 画上休止符
1.1 紧跟 GenAI 前沿方向,月之暗面的技术演进
一切都始于 2024 年,业界对于思考模型的成功尝试。
通常,思考模型,或者叫推理模型,基于 GenAI 技术构建,而依赖于逻辑链条(Chain-of-Thought,CoT)来逐步推导出解决方案,这是一种用技术换时间和算力资源的方案,使思考模型可以用 10 分钟做完一套高考数学卷,分数超过 120 分,在逻辑推理能力上,进一步靠近人类专家。
思考模型分为短链思维(short-CoT)和长链思维(long-CoT)两种。short-CoT 更注重快速生成简洁的解决方案,long-CoT 则是通过多步骤的逻辑推理解决复杂问题。
从 k0-math 数学模型到 k1 视觉思考模型,再到如今的多模态思考模型 k1.5,月之暗面也经历了在多模态推理、RL(强化学习)、长上下文扩展技术上的一些标志性突破。
以 short-CoT 和 long-CoT 为例,k0-math 仅能处理一些基础的数学问题,但无法处理复杂的多步骤推理任务。到了 k1,伴随监督学习和 RL 训练的引入,其已能够处理更为复杂的数学和编程问题。最新的 k1.5,在处理复杂逻辑和数学问题时,已具备了高级推理技能。
例如,在 AIME 2024 和 MATH-500 等基准测试中,Kimi k1.5 长链思维能力达到了 OpenAI o1 正式版的水平,在编程任务上也有更为出色的表现。
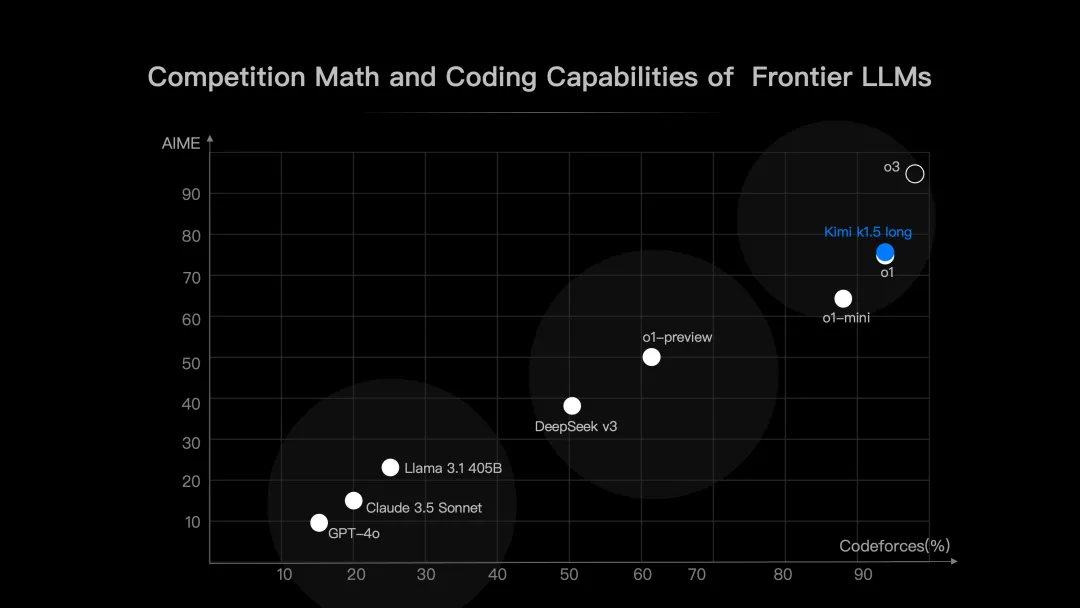
图注:k1.5 long 在 AIME、Codeforces 上的得分情况
相比 OpenAI o1 的数学解题能力更强,较其他大模型如 DeepSeek v3 等在两项测试上均表现更强
从 Kimi 首次公开的模型训练技术报告《Kimi k1.5: Scaling Reinforcement Learning with LLMs》中可以看出,上述技术演进的核心之一在于 RL 技术。
与传统的 short-CoT 模型不同,RL 通过试错、奖励和惩罚机制,来引导模型学习,也不再局限于静态的推理过程,因此能在复杂决策的过程和任务中,适应未知和变化环境,并根据环境反馈不断调整策略。
简而言之,就是它对“智能”的理解更深,不再是“检索信息 - 反馈结果”的模式,而是“整合 & 理解 - 解决问题”模式,提升了模型的推理能力和通用性。而月之暗面产研团队的追求,显然不止于技术实现更大的技术追求,而是试图让 RL 框架变得更简洁。
因此,Kimi k1.5 将强化学习与长上下文建模 (128k) 结合起来,并提出了针对性的优化策略,并构建了一个简洁有效的 RL 框架。“进化”后的 RL 框架,无需依赖复杂的蒙特卡洛树搜索(MCTS)、价值函数或过程奖励模型,就能来实现更优性能。
例如,MCTS 需要通过多次模拟来评估潜在的行动路径,选择最优的推理步骤,这在计算资源消耗、决策流程、泛化能力、可扩展性上都有较为明显的劣势。而 Kimi RL 框架学习的是通用的策略,相当于通过学习适应任务的策略而不是依赖于复杂的模拟或搜索过程。
1.2 Kimi RL 框架的核心是 Partial Rollout 技术的引入
此外,RL 框架中一个关键创新是引入“部分展开(Partial Rollout)”技术。据《模型训练技术报告》中提及提到的,Kimi 技术团队将 RL 的上下文窗口扩展到 128k,通过 Partial Rollouts 技术提升训练效率。该技术允许模型在训练过程中复用之前的轨迹片段,避免从头生成新轨迹,从而节省计算资源。
Kimi RL 训练系统通过迭代同步方法运行,每次迭代包括展开阶段和训练阶段。
展开阶段,回滚工作节点(Rollout Workers)通过与模型交互生成展开轨迹,产生对各种输入的响应序列。这些轨迹被存储在重放缓冲区(Replay Buffer)中。
训练阶段,训练工作节点(Trainer Workers)访问这些数据来更新模型的权重。这种循环过程允许模型不断从其行动中学习,随着时间的推移调整其策略以提高性能。
同时,该技术设定了一个固定的输出 token 预算,如果轨迹在 Rollout 阶段超过了 token 限制,未完成的部分也将保存在重放缓冲区,并在下一次迭代中继续,确保没有任何一条冗长的轨迹会垄断系统资源。在整个过程中,回滚工作节点是采用的异步机制,处理长 Rollout 时,其他节点可以处理短 Rollout,从而增加计算效率。
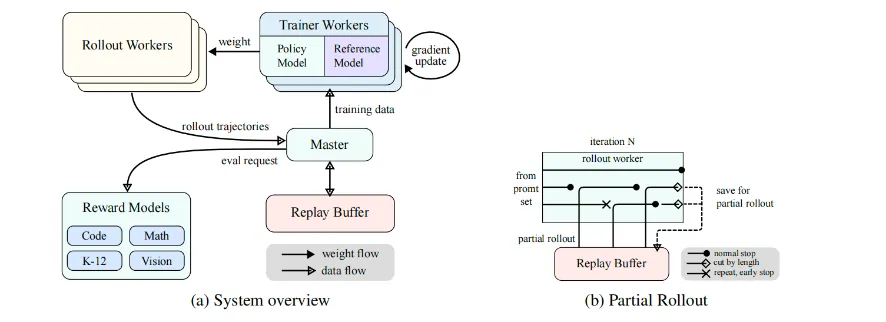
Kimi RL 训练系统工作原理
简而言之,“Partial Rollout”只对部分状态 - 动作序列进行模拟或采样,而不是对整个完整的 episode 进行 rollout(即从头到尾模拟整个任务)。完整 rollout 可能需要处理大量 tokens,计算成本很高,而通过部分 rollout,可以只对当前关键的部分进行模拟,从而减少计算量,同时仍然能够有效地更新策略。
这种方法,尤其在处理长序列任务场景中,可以显著提高训练效率,极大降低计算成本。在已知的公开信息上,月之暗面是实践这一技术,并且取得良好工程结果的先驱团队。
当然而从已公开的技术文档来看,对 Partial Rollout 的实践,并不是 Kimi k1.5 唯一的秘密武器。
2 来自月之暗面的“黑科技”有点多
2.1 long2short 技术的提出和工程实践效果
Kimi k1.5 的另一个技术亮点在于长到短的推理压缩(long2short)方法的提出。
其核心原理是依托如模型融合、最短拒绝采样、DPO 和长到短 RL 等技术,将长推理模型的知识迁移到短推理模型中,提升短推理模型的性能。包括通过长度惩罚(Length Penalty)和最大轨迹长度限制,进一步优化短推理路径模型,以及通过采样策略(如课程学习和优先采样)优化训练过程,使模型更专注于困难问题。
而且,通过 long2short,k1.5 能够在推理任务中消耗更少的 token,从而在实际应用中更具性价比。
正如文章一开始提到的,k1.5 在 short-CoT 模式下大幅超越其他大模型的测试结果,就得益于 long2short 技术。在下图中,也有一些更为系统性的数据反映。k1.5-short w/ rl 在 AIME2024 上实现了 60.8 的 Pass@1 得分(8 次运行的平均值),同样的,k1.5-shortest 在 MATH500 上达到了 88.2 的 Pass@1 得分,消耗的 token 大约与其他短模型相同。
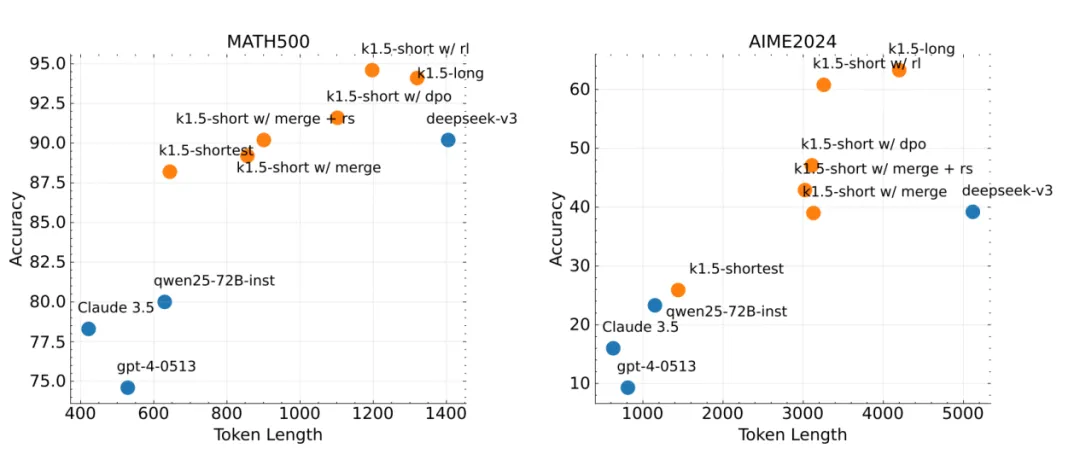
据网上公开的综合材料显示,对比 DeepSeek 同期发布的 R1(通过训练层面使用模型蒸馏技术降本的思路),k1.5 在推理层面用的 long2short 降本方法,后者虽然数据生成较为复杂,但可解释性更强,更适合推理任务;且消耗的推理 token 量,仅为前者一半。
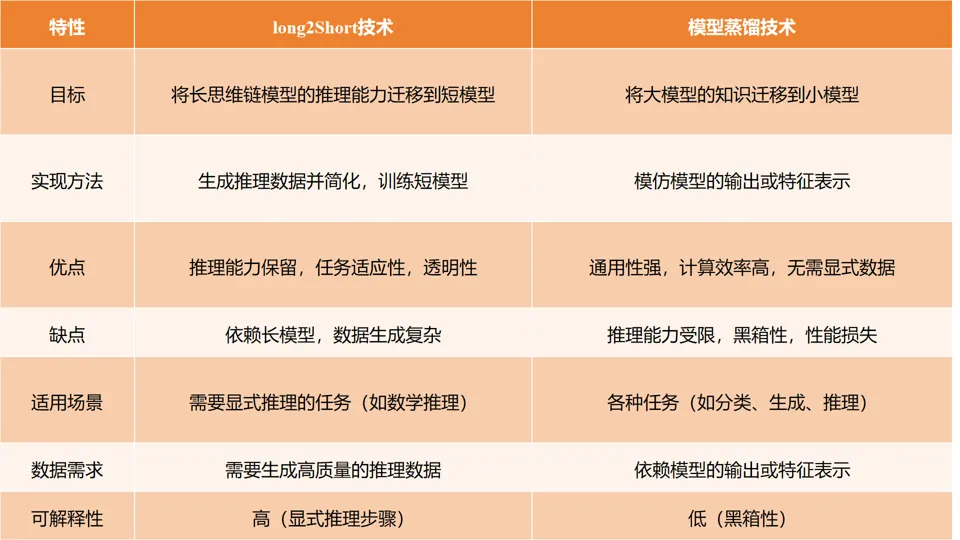
long2short 与模型蒸馏技术对比
对此,一些大模型的相关从业者也向 InfoQ 表示,“训练层面的扩展法已逼近极限后,推理层面的研究会是后续 AI 前进的突破点”。
2.2 好的大模型不仅意味着极致性能,还意味着对成本的最优控制
应该说,在技术路线的选择上,月之暗面始终追求高性能与较低成本的平衡——自上下文缓存费用大降 50% 后,月暗的技术路线继续保持着某种“完美主义”路线:既追求性能,也要成本足够低。
在传统系统中,训练和推理往往需要不同的 GPU 硬件资源,且在这两个阶段之间的切换时间通常较长,影响整体效率。因此,GPU 资源的最大化利用是很多大模型团队优先会解决的成本问题。
k1.5 采用了一套混合部署(Hybrid Deployment)优化技术,用于在训练和推理阶段之间实现高效切换。Kimi 技术团队发现,一方面,像 vLLM 在训练过程中会预留部分 GPU 而导致 GPU 资源闲置,另一方面,可以通过增加推理节点数量来实现对闲置资源的有效利用。因此,k1.5 利用 Kubernetes Sidecar 容器共享 GPU 资源,将两种工作负载共置在一个 pod 中,来实现训练和推理任务的高效调度。
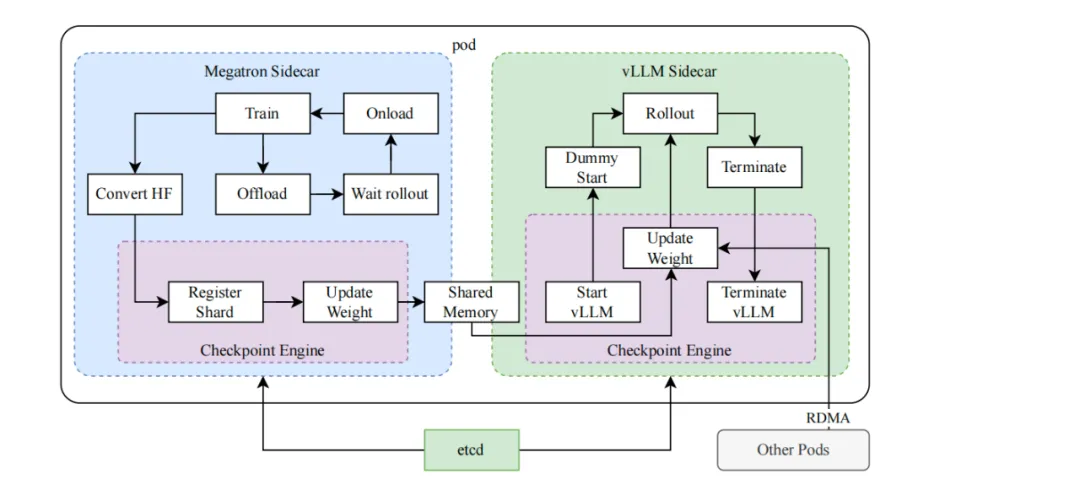
混合部署架构核心原理
对于 Kimi 技术团队在效率提升和成本优化上的实践结果,腾讯人工智能实验室首席研究员涂兆鹏评价“很高兴看到我们国家(的企业)在 o1 类模型中针对 long2short 问题的 token 效率做出了更多努力”。

除了在国内引起了广泛关注,k1.5 公布的研究成果也在国际上引发了讨论。英伟达科学家 Jim Fan 对其在 MathVista 等基准测试上展现出强大的多模态性能表示赞叹。同时,一些海外网友表示 k1.5 在 short-CoT 性能和多模态能力的显著提升,以及 long-to-short CoT 技术,值得业界更多关注。



3 写在最后
你永远可以相信国内技术团队“精耕细作”的能力。
对于月之暗面、DeepSeek 等一众企业而言,恰到好处的技术、产品能力,以及其与 AI 应用落地节奏的丝滑适配,才是 2025 中国 GenAI 商业牌桌上,各位“玩家”的终极追求。




