在 AI 时代,我们希望计算机能够拥有视觉、听觉、行动以及语言的智能,而相对于听和看以及行动,语言是我们人类区别于其他动物的最重要特征之一。语言是我们思维的载体,也因此我们对于语言的理解和处理,变得尤为重要。而在计算机领域,自然语言处理(NLP, Natural Language Processing)就是研究如何让计算机理解并生成人类的语言,从而和人类平等流畅地沟通交流。自然语言处理技术 在百度已经有悠久的历史,早在百度诞生之时就成为搜索技术的重要组成部分,一直伴随着百度的发展而进步。从中文分词、词性分析、改写,到机器翻译、篇章分析、语义理解、对话系统等等,NLP 技术已成功应用在百度各类产品中。
近期由百度开发者中心主办、极客邦科技承办的 75 期百度技术沙龙上,百度 NLP 和 AI 开放平台的多位资深工程师和产品经理,针对开发者如何利用百度 NLP 技术更好解决实际应用问题,进行了具体分享。百度 AI 技术生态部高级运营顾问张扬,通过具体应用案例,让大家对百度 NLP 开放的核心技术有一个感性的认知;自然语言处理部主任架构师孙宇,针对 NLP 语义计算技术的具体问题深入分析;自然语言处理部资深研发工程师何伯磊,用大量场景详细解释了情感分析领域的技术应用;自然语言处理部资深研发工程师姜迪,详细阐述了概率图模型技术如何应用;百度 AI 技术生态部资深产品经理张晶晶,为大家现场指导百度 AI 开放平台的使用方法。
NLP 是什么?
NLP 是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的学科。NLP 由两个主要的技术领域构成:自然语言理解和自然语言生成。
- 自然语言理解方向,主要目标是帮助机器更好理解人的语言,包括基础的词法、句法等语义理解,以及需求、篇章、情感层面的高层理解。
- 自然语言生成方向,主要目标是帮助机器生成人能够理解的语言,比如文本生成、自动文摘等。
NLP 技术基于大数据、知识图谱、机器学习、语言学等技术和资源,并可以形成机器翻译、深度问答、对话系统的具体应用系统,进而服务于各类实际业务和产品。
我们为什么需要 NLP?
在演讲中,为了让大家有更直观的感受,张扬首先举了个生活中的例子:人们在用百度搜索一个生僻字时,不知道拼音的情况下会搜索:“4 个又念什么?”,我们发现,搜索结果一定是告诉你这个“叕”字念什么,而不是“4 个又念什么”的这几个词表面的匹配结果,这其中已经用到自然语言理解的能力了,它帮助搜索引擎理解用户需要搜的是“由 4 个又组成的字”,而不是“4 个又是什么”这几个孤零零的词。由此可见,NLP 技术真正能够知道你所说的话的深层语义是什么,这项技术也把人工智能推向了一个新的高度。
那么 NLP 究竟能能够干什么?如何帮助业务实现,张扬继续介绍了百度 NLP 开放的几项典型技术:
情感倾向分析
针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度。情感极性分为积极、消极、中性。情感倾向分析能帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有力的决策 **** 支持。
(点击放大图像)

评论观点抽取
自动分析评论关注点和评论观点,并输出评论观点标签及评论观点极性。目前支持13 类产品用户评论的观点抽取,包括美食、酒店、汽车、景点等,可帮助商家进行产品分析,辅助用户进行消费决策。
(点击放大图像)

词义相似度计算
用于计算两个给定词语的语义相似度,基于自然语言中的分布假设,即越是经常共同出现的词之间的相似度越高。词义相似度是自然语言处理中的重要基础技术,是专名挖掘、query 改写、词性标注等常用技术的基础之一。
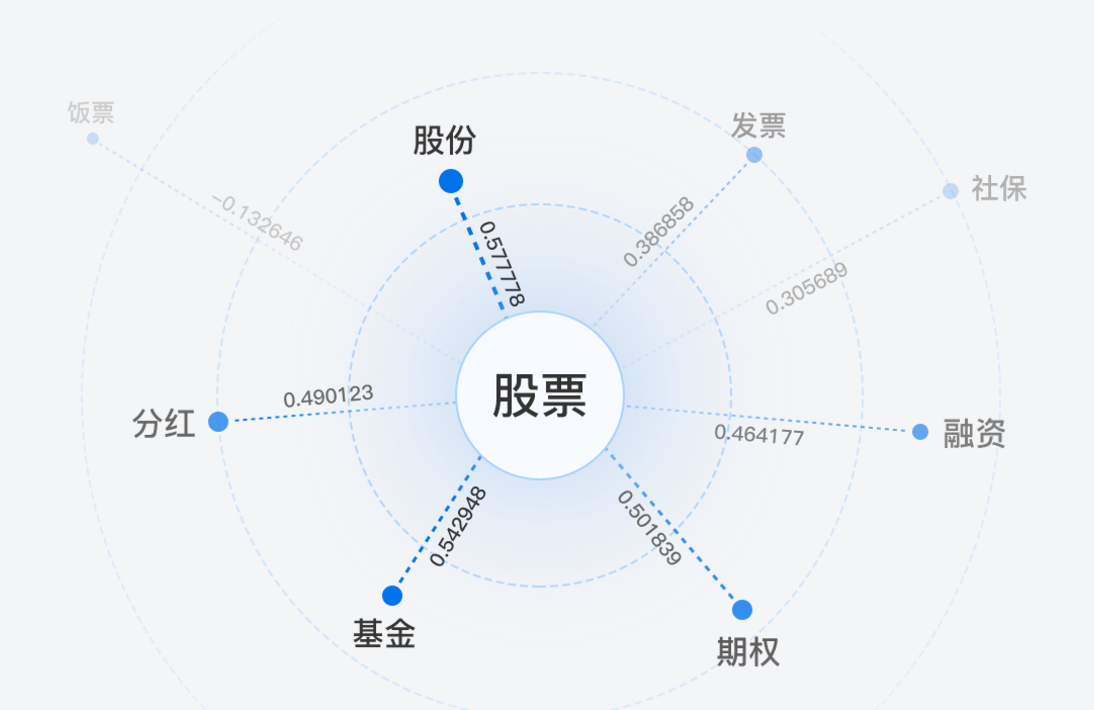
词法分析
百度词法分析向用户提供分词、词性标注、命名实体识别三大功能。该服务能够识别出文本串中的基本词汇标注和词汇的词性,并进一步识别出命名实体,百度词法分析的算法效果大幅领先已公开的主流中文词法分析模型。
(点击放大图像)

短文本相似度
能够提供不同短文本之间相似度的计算,输出的相似度是一个介于-1 到1 之间的实数值,越接近1 则相似度越高。这个相似度值可以直接用于结果排序,也可以作为一维基础特征作用于更复杂的系统。
(点击放大图像)

DNN 语言模型
语言模型是通过计算给定词组成的句子的概率,从而判断所组成的句子是否符合客观语言表达习惯。在机器翻译、拼写纠错、语音识别、问答系统、词性标注、句法分析和信息检索等系统中都有广泛应用。

词向量表示
词向量表示表示是通过训练的方法,将语言词表中的词映射成一个长度固定的向量。词表中所有的词向量构成一个向量空间,每一个词都是这个词向量空间中的一个点,利用这种方法,实现文本的可计算。
(点击放大图像)

依存句法分析
利用句子中词与词之间的依存关系来表示词语的句法结构信息(如主谓、动宾、定中等结构关系)
并用树状结构来表示整句的的结构(如主谓宾、定状补等)。
(点击放大图像)

百度语义计算技术是如何实现的?
在各个NLP 开放接口之中,语义计算是一个非常基础的技术。百度NLP 部门的主任架构师孙宇主要围绕NLP 语义计算整体技术框架展开分析,核心介绍了语义表示技术和语义匹配技术。百度NLP 语义计算整体框架主要分三大部分(如下图),最底层依托于大数据、网页数据和用户行为数据,以及高性能集群(GPU、CPU 和FPGA),打造了基于DNN 和概率图模型的语义计算引擎,通过文本输入到语义计算引擎当中,可以得到文本的语义表示,进而基于这个语义表示,进行语义层面的计算,包括语义匹配、语义检索、文本分类、序列生成以及序列标注。
(点击放大图像)

目前,百度在语义方面开放了四个技术,囊括了词汇和句子两个层面的语义技术。词汇层面包括了词语义向量表示,词义相似度计算;句子层面的包括短文本语义相似度计算和DNN 语言模型。孙宇对这些技术背后的原理进行了详细的介绍。
语义表示技术业界很早就开始研究,主要有两种流派,一个是形式化的方法,一个是基于统计的方法。关于基于形式化的方法,在上世纪八十年代普林斯顿有科学家提出:基于语言学知识构建一个词图,把知识通过词与词之间的关系构建到这个图里。九十年代又有人提出,将自然语言表示成一种逻辑的表达式,可以直接用于计算机计算和执行。但这两个技术都存在一个问题:自动化程度不高,适用性较差,因此,百度NLP 主要采用基于统计的方法。
短文本语义相似度计算是他们重点打造、应用广泛的技术。其中的核心模型是利用他们2013 年开始研发的SimNet 语义匹配框架,在千亿级别真实点击数据训练得到。该框架的基础匹配算法上包含两种匹配范式,一种侧重于表示层建模,另外一种则更侧重于匹配层建模。这两种模型各有优势,可解决不同问题。另外,针对不同应用场景他们还扩展研发了基于字符级别匹配和多视角匹配技术,这些技术都广泛应用于百度内部各产品中。
百度自然语言处理在情感分析领域有哪些技术和应用?
在演讲中,何伯磊主要针对用户日常的使用场景,分析了情感分析技术的原理和实际应用。百度情感分析技术依托于评论大数据、深度学习、语义理解等基础技术,建立了一套完整情感分类与观点挖掘的核心技术。在情感分类方面,我们研发了情感倾向性分析、情感的情绪分析,情感对象识别以及句子的主客观的分析。在观点挖掘方面,我们通过情感搭配知识自动构建和观点计算技术,我们能有效的进行文本数据的观点抽取。百度依托这些核心的技术,进行用户产品开发。
(点击放大图像)

这里重点介绍两类核心技术:
情感倾向性分析
情感倾向分析任务目标是能够判断用户文本是积极、消极或是中性的情感。传统方法有两类:一类利用情感词典进行规则匹配的方法进行判断,另外一类基于情感词典和文本特征建立一个2 分类任务的方法 。百度情感倾向性分析基于深度学习的方法,分别建立了句子级、实体级、篇章级多粒度完整的分析任务。句子级粒度上,通过基于Bi-LSTM 分类方法,系统更好的捕捉了情感极性在前后文表达的信息,效果上相对于传统的方法有了很大的提升。实体级粒度的任务概念稍有晦涩,举个例子:《成龙对战狼2 的看法》一篇文章可能有多个主题,这个任务就是希望能够把这篇文章对于“吴京”的态度分析出来。在这个任务中,我们通过建立层次化的语义表达方法,让整个系统更加精准的进行分析和判断。
评论观点抽取的技术
评论观点抽取目标:给定一个文本,把其中表达观点的信息抽取出来。举个例子,用户的评论:“这家旅店的服务还不错,但是房间比较简陋”,我们目标把“服务不错、房间简陋”这样的关键观点信息抽取出来。评论观点抽取技术在当前互联网产品中应用十分广泛,但是召回率一直不高,百度的评论观点抽取技术将任务从应用需求进行细致分析拆解,通过基于情感搭配的方法,基于语义计算的方法,基于维度预测的方法,以及基于维度预测加情感极性分类的方法完美的解决了应用中各种的问题,这也是一个技术和应用完结合经典案例。
概率图模型技术如何应用?
姜迪分享的主题是《Familia 可配置的主题模型框架》,Familia 是家族、家庭的意思。顾名思义,这个框架的特点就是涵盖了一族具有较大的工业价值的主题模型,这样一来,一线的工程师就有很多灵活性,可以根据具体任务,来选择适用的模型。
百度有一个贝叶斯技术体系的框架,主要分三大类:第一类是主题模型,这个框架的特点就是它有一个自配置的功能;第二类是点击模型,主要是应用在搜索引擎的领域,来量化分析用户的搜索行为以及搜索查询和网页的相关性;第三类是分类模型,包含最常见的基于贝叶斯网的分类器。
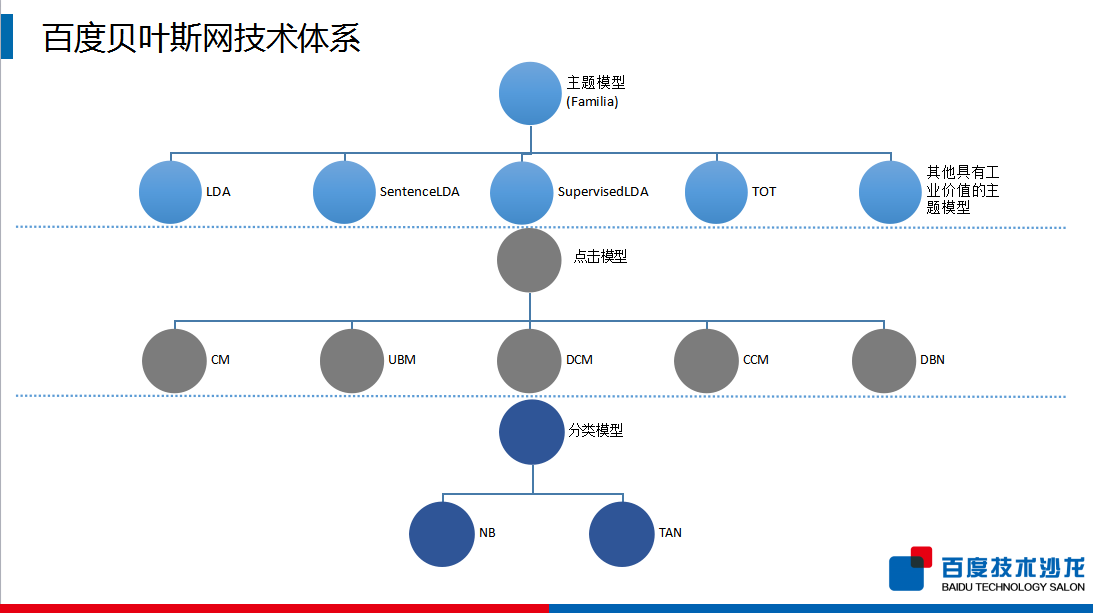
主题模型框架中有十几个主流的主题模型,其中包含LDA 模型、引入了句子结构的SentenceLDA 模型、引入了监督信号的SupervisedLDA,以及其他具有工业价值的主题模型,并且支持用户根据具体任务设计对应的模型。
那么,为什么要设计Familia 这个主题框架?业界大部分主题模型工具只支持PLSA 和LDA 两种模型,这两种模型非常类似,它们只支持一种数据假设,也就是说,我们只能用一种模型来适用不同的场景,不能支持用户的根据具体任务自定义扩展。当用户的数据本身和这两个模型的假设有较大差异时,效果可想而知。另一方面,当前的主题模型工具对下游的应用并不太友好,这些工作往往只注重模型的训练,忽略了模型如何在具体任务中应用。从模型的训练到应用之间有很长的距离,如何消除这个距离是我们这个工作的重点。Familia 在百度的应用场景其实非常多,包含了大家耳熟能详的百度搜索、百度新闻、糯米、贴吧这些平台,也部署到了百度自然语言的云处理平台上,这个工具目前每天有3000 万次的响应需求。
Familia 框架是怎么在工业界场景进行应用的?第一步,数据预处理,这里可以支持多种类型的数据,包括常见的网页数据、新闻数据和糯米数据,在内部将数据预处理步骤和百度的分词进行了一个深度的融合。在分词的前和后我们还有多种多样的过滤器,用户可以根据自己的需求,来选择什么信息要过滤掉,什么信息可以保留。第二步,概率图模型配置,Familia 支持多种主流的已有的主题模型,同时用户也可以自定义自己的主题模型。这个过程是通过一种数据组织抽象存储多种图模型的信息来实现的。第三步,采样公式自动推导,Familia 中的参数推导引擎可以自动推导出采样公式,降低了主题模型应用的数学门槛。第四步,模型的后期处理,Familia 进一步对训练好的主题模型进行优化和压缩操作。第五步,Familia 抽象了语义表示和语义匹配两个应用范式,用户可以根据具体任务来使用对应的范式。
目前 Familia 已经在 github 上完成开源( https://github.com/baidu/familia ),第一期提供网页、新闻、小说等多个垂类语料训练的工业级主题模型,并提供语义表示、语义匹配两类应用范式的大量应用场景指导。
对开发者而言,如何更好的使用百度 AI 开放平台?
张晶晶主要就自然语言使用的相关问题及整个百度 AI 开放平台的使用方法进行了介绍。目前百度自然语言处理技术开放 8 项语言处理的基础技术,基于这些基础的能力,百度对外开放了很多感知层和认知层的技术,在上面搭建了我们一个开放平台,在这个平台上百度把我们所有成熟的 AI 技术都在这里统一对外开放,使大家能够通过接口的方式,直接调用、直接使用,比如语音识别、语音合成、文字识别的各种模板、端口,人脸识别等。另外,百度也将开放个性化和定制服务,主要是有词法分析、评论观点抽取和情感倾向分析。词法分析的定制,可以帮助我们的行业客户实现个性化需求,若有识别不了的词汇,可以通过上传词表的方式,来把模型训练的更适合自己。

百度 AI 平台为开发过程提供了三方面的支持,首先是开发组建,其次是管理功能和配套资源。开发组建方面,每个技术领域里都以标准的方式提供了 API 和 SDK,有些方向上还提供了参考代码。有一些需要独立去配置的模块单独做了配置系统,让开发者可以先在平台上做好配置之后就可以直接调用。在后台管理上,有基础的应用管理,也支持很多跟企业业务相关的个性化的配置,随时查看调用的统计信息。开发者还可以在产品上使用百度 LOGO,标识出百度 AI 技术。开发者如果应用百度的 AI 技术解决了行业中的典型问题,百度也会担任伯乐的角色,将其案例进行宣传推广。




