
背景介绍
先介绍一下之前的埋点流程,如下图所示。产品提出埋点需求,开发人员在 mp 平台配置埋点事件,然后进行代码埋点,再测试埋点,没问题之后再提审。
小程序从提审到审核通过大概需要半天到两天的时间。通过之后还需要半天的线网验证,线网有问题之后又得重新走一遍发版流程。整个埋点流程比较长。
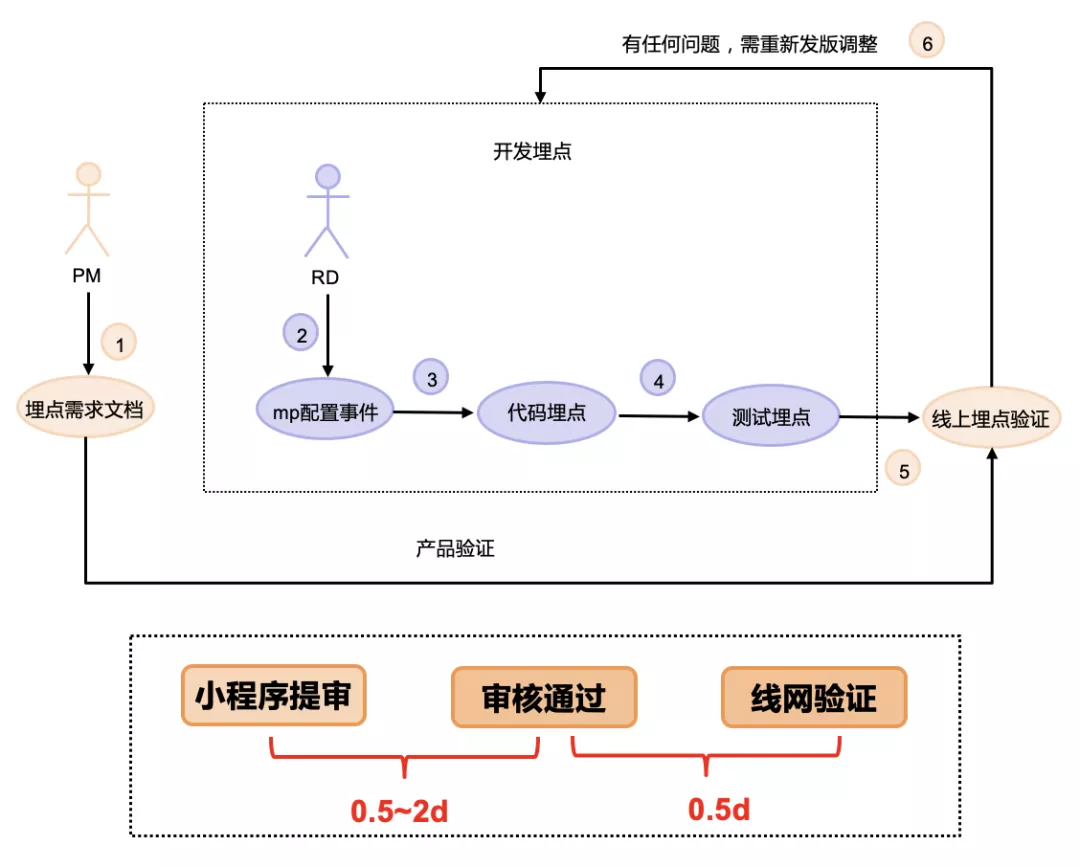
有一次在比赛前一天晚上彩排的时候,产品临时需要加个埋点需求,因为当时已经晚上 10 点多了,小程序没人审核,所以只能等到第二天早上找领导走内部紧急审核通道,这个时候如果有一个实时的埋点系统就可以完美解决了。
细心的同学还会发现,整个埋点流程开发还是需要费神费力的,这种重复性的工作也是比较繁琐的,而且对于技术能力的提升也没有多少帮助。
所以埋点系统的另外一个要求就是不需要开发介入,产品或者运营人员就可以单独完成埋点。
需求设计
1. 避免重复造轮子
在做之前,先来了解下公司内外已有的埋点方案,避免重复造轮子。如下图所示,目前公司外有 growingio 和神策两款产品,小程序官方也提供了埋点方案。

growingio 是全埋点,数据全。但是由于是全埋点,后期还需要开发介入清理数据,不满足埋点系统的要求;
神策和 MP 需要代码埋点,不能实时生效。
因此,现有的埋点方案都不能够完全满足我们的要求,需要独立开发一个系统。
2. 埋点方案设计
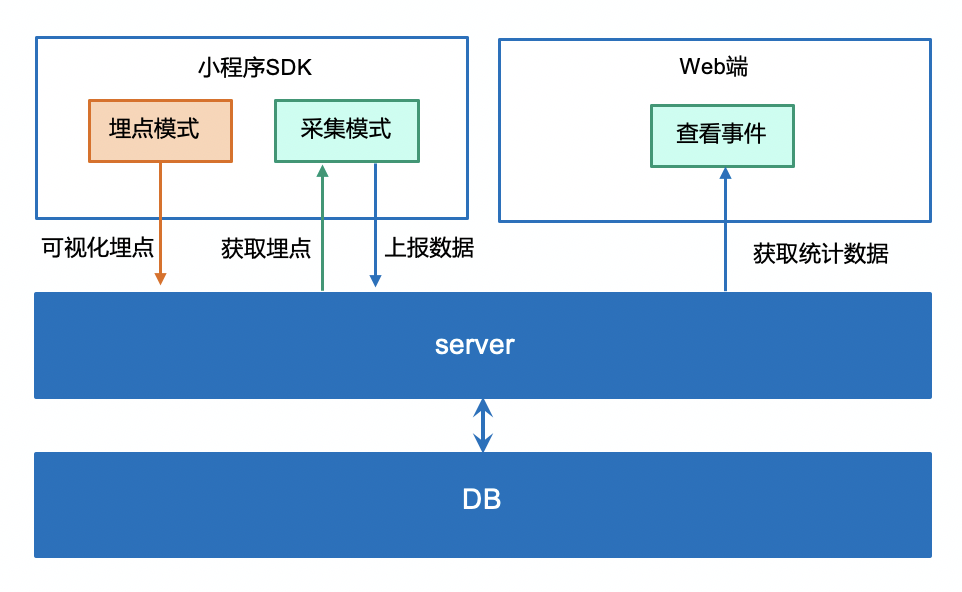
框架图如上所示,小程序的 SDK 分成两种模式:埋点模式和采集模式
埋点模式是产品操作的,供产品新增埋点事件;
采集模式就是采集用户的点击操作,在小程序启动的时候,从后台拉取产品需要的埋点事件,用户点击动作命中埋点事件之后自动进行上报。
在 Web 端,产品可以查看埋点数据。
埋点系统具体实现
1. 埋点整体流程
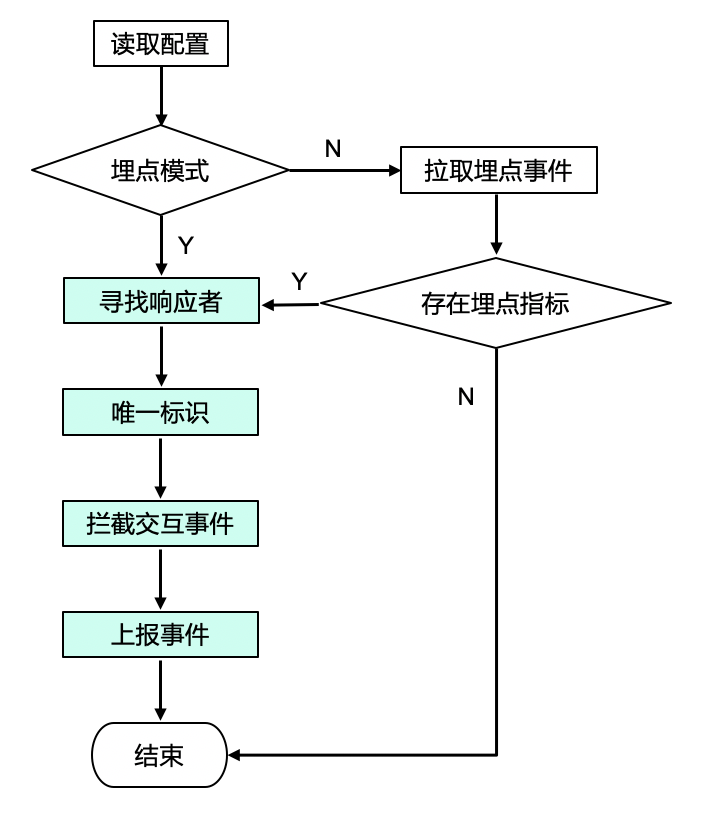
具体流程如下图所示,通过配置确定是埋点模式还是采集模式,假如是采集模式,需要获取埋点事件,判断是否有要统计的埋点事件。
接下来就是重点,用户点击之后,首先需要确定响应者,然后是唯一标识这个点击动作,最后是拦截这个交互事件,上报统计事件。简单的说就是:
寻找响应者;
唯一标识;
拦截交互事件。
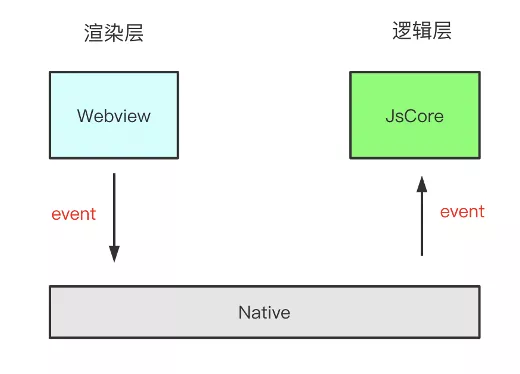
其中比较难的一个点是寻找响应者,因为小程序是双线程,视图层和逻辑层是分开的,跟 H5 不太一样。H5 是可以获取完整的 dom 节点信息。但是在小程序中可以获取到的信息很少。
2. 寻找响应者
(1)业界方案介绍
业界方案主要有两种,分别是工程化注入和冒泡采集。
工程化注入就是给所有标签注入点击事件,这种相当于全埋点,数据比较全。但是缺点也很明显,给所有标签加上点击事件会让项目显得比较重,而且假如原来的标签有点击事件,就更不好处理了。
冒泡采集就是在 wxml 代码的最外层添加一个 view,然后绑定 catchtap 事件。这种就比较轻量级,无需注入大量代码。但是依赖于冒泡事件,假如原来的业务代码阻止了冒泡,那就获取不了,可靠性比较差。
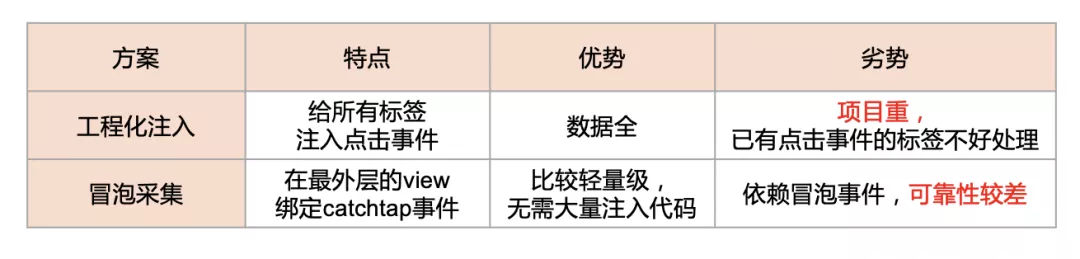
这两种方案都是从视图层出发,或多或少需要入侵业务代码,各有缺陷,不满足我们的需求。
(2)思路转换
上面的方案是从视图层出发,因为小程序的双线程模型,这里我从另外一个角度出发,从逻辑层下手。
原理是这样的:在渲染层触发的点击事件都会传递到逻辑层,所以可以从逻辑层入手,对逻辑层的每个函数提供 hook 方法,在 hook 中捕获到用户的点击事件。
(3)具体实现
目标分析:获取用户的点击行为,从 wxml=>js,也就是从渲染层转向逻辑层。小程序的逻辑层涉及到两个系统对象:
页面对象;
自定义组件。
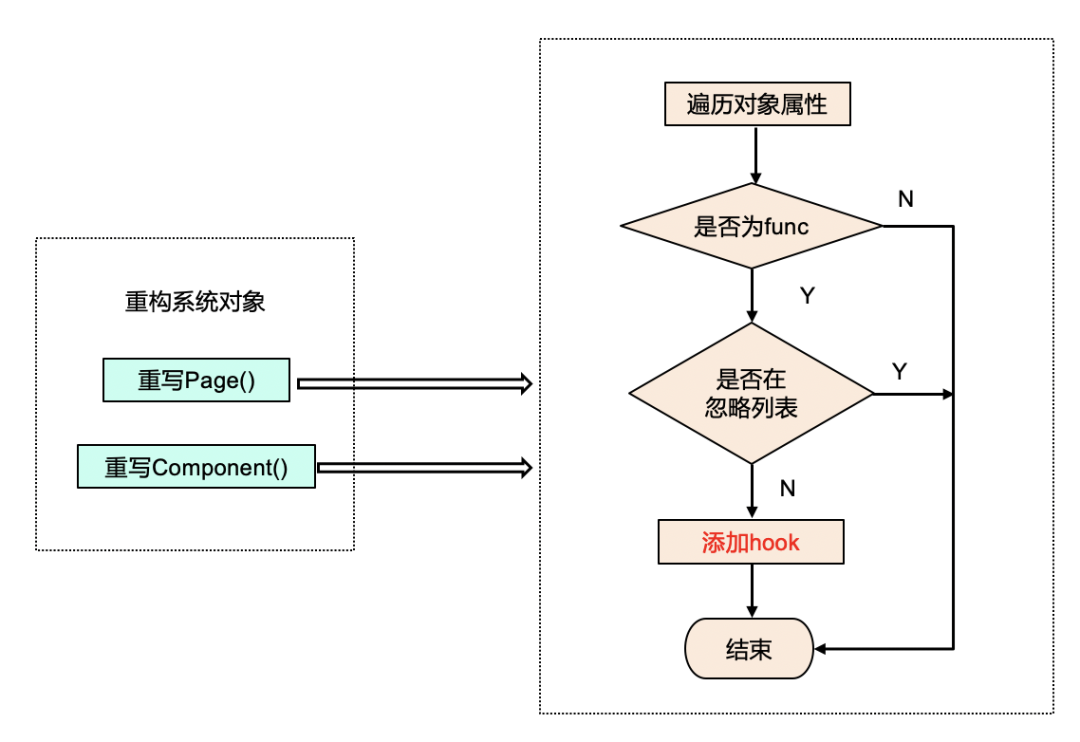
因此,只要重构这两个系统对象即可,具体做法如下:
在小程序启动的时候,重构 Page()和 Component()这两个系统对象,遍历对象里面的所有属性。如果属性类型是函数,则进一步判断是否在忽略名单,像监听页面滚动的函数这种是不需要添加 hook 的,最后才是给函数添加 hook。
不过在小程序启动的时候去给页面的函数添加 hook 还不完整,因为有些函数是在运行时添加的,像这种该怎么添加 hook 呢?给运行时的 func 添加 hook。这块我想到了几种方案:
给 Page 对象设置 proxy,监控 set 方法;
在所有 hook 中监控 Page 属性的数量;
Page 添加生命周期函数,onLoad 执行完之后给新生成的 func 添加 hook。
第一种和第二种都存在多次触发的情况,影响性能。只有第三种是一劳永逸的,只需要执行一次就可以了。
3. 唯一标识
唯一标识就是确定用户点击动作的唯一性,传统的标识大部分是通过视图栈方案,也叫特征值标识。在小程序中,就是通过标签的 id 来标识,id 就是标签的特征值。
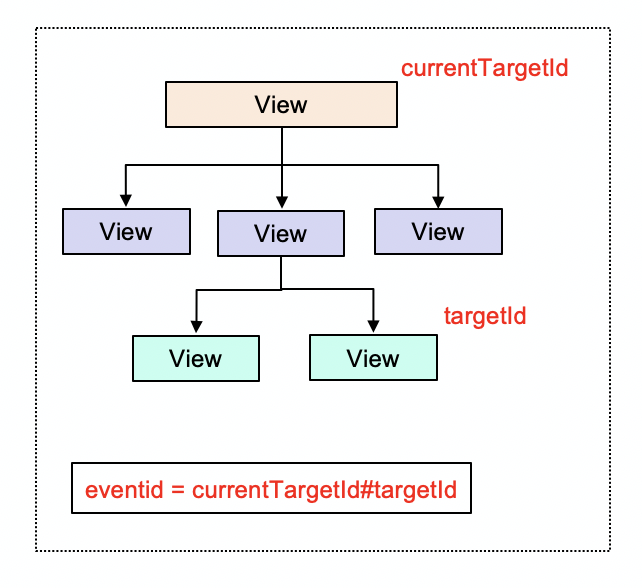
(1)视图栈方案
如图所示,当用户点击某个标签时,可以获取到两个 id,一个是 targetId,另一个是 currentTargetId,其中:Target 为触发事件的源组件,currentTarget 为事件绑定的当前组件。
这种方案,唯一标识就是通过这两个 id 进行组合得到。但是使用这种方案可靠性比较差,因为在写业务代码的时候,可能没有给标签添加 id,这样取到的 id 就是空字符串,使得标识并不唯一。
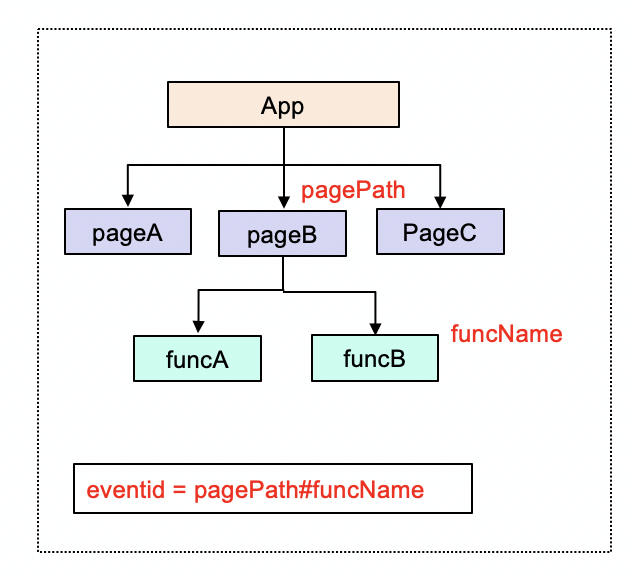
(2)变量名+新特征值
前面说过,用户点击某一个标签,都会对应到逻辑层的某个函数,所以这里把函数名作为新的特征值。为了确保唯一性,再加上当前页面路径,防止其他页面有相同的函数名。
这种方案的优势很明显,就是不依赖于 id,可靠性有保证。
不过细想一下,还是有一些情况需要考虑:
第一点,custom components 如何获取 pagePath?
因为组件的层级比页面层级低,从组件对象是没法获取页面信息的。但是由于是可视化埋点,所以组件所在的页面肯定在页面栈的最上面,因此,可以通过页面栈获取当前的页面对象,然后再获取页面路径
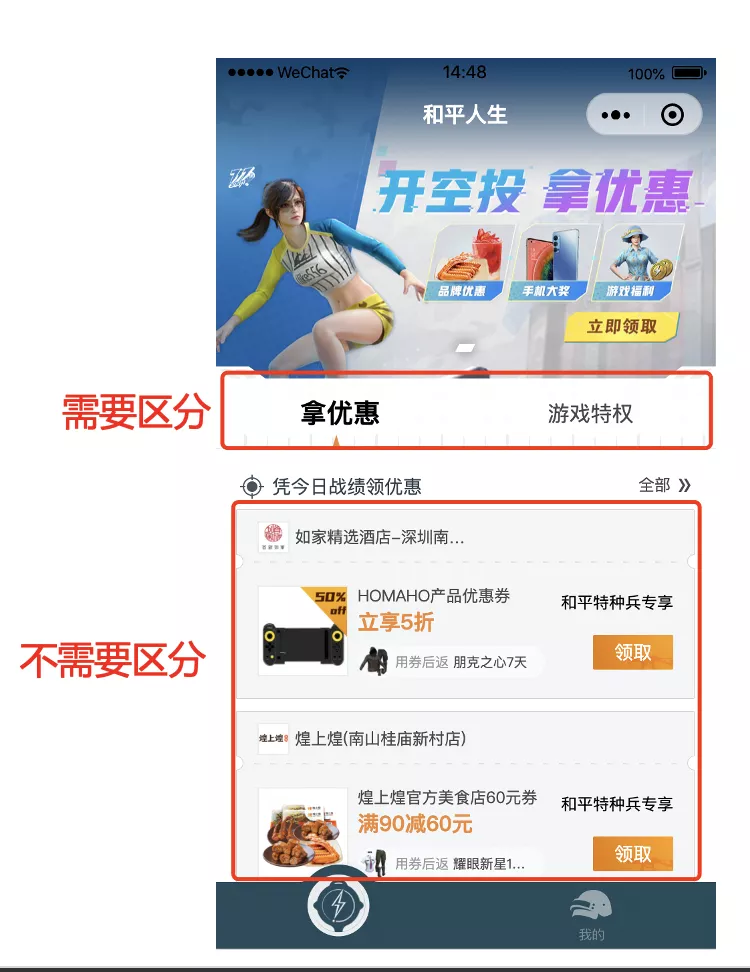
第二点,对于 list 点击事件,如何区分?
如下图所示,每个 tab 的点击情况是需要区分统计的,而对于下面列表中的奖励领取,一般是不需要区分的。不需要区分的按照原方案即可。
对于需要区分统计的,因为 tab 不同时,所触发的函数参数肯定也不同,所以唯一标识需要带上函数的参数。
第三点,如何统计一个事件在所有页面的情况?
对于全局范围的统计,因为要统计所有页面的情况,所以需要将页面路径和函数名称分开存放,其中函数名作为埋点事件的唯一标识,页面路径作为子标识。
4. 拦截交互事件
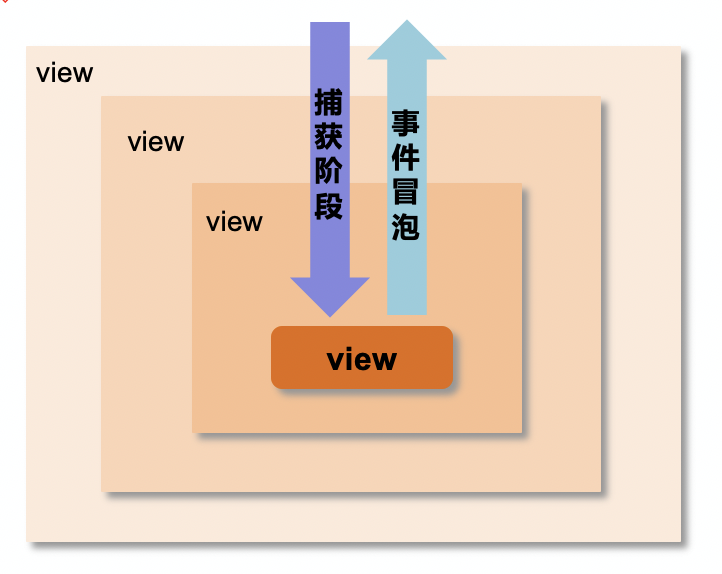
(1)事件模型分析
小程序的事件模型如下,用户点击某个 view 时,会从外到内进行捕获。事件冒泡的响应顺序相反,是从内到外进行冒泡。可以看到,用户点击一次可能会触发多个事件,所以重点是要防止多次上报统计事件。
为了防止多次上报,需要寻找当前点击事件的唯一性。
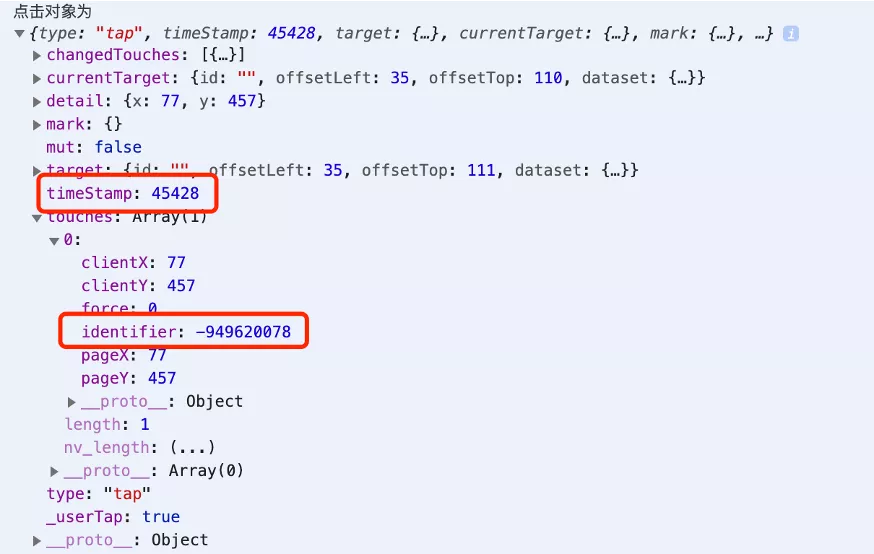
这是小程序的事件对象,可以看到,通过时间戳和标识符可以唯一确定当前的点击事件,其中时间戳 timeStamp 是用户打开小程序到点击事件产生的时间戳,标识符 identifier 是触摸点的标志符。
(2)埋点模式流程
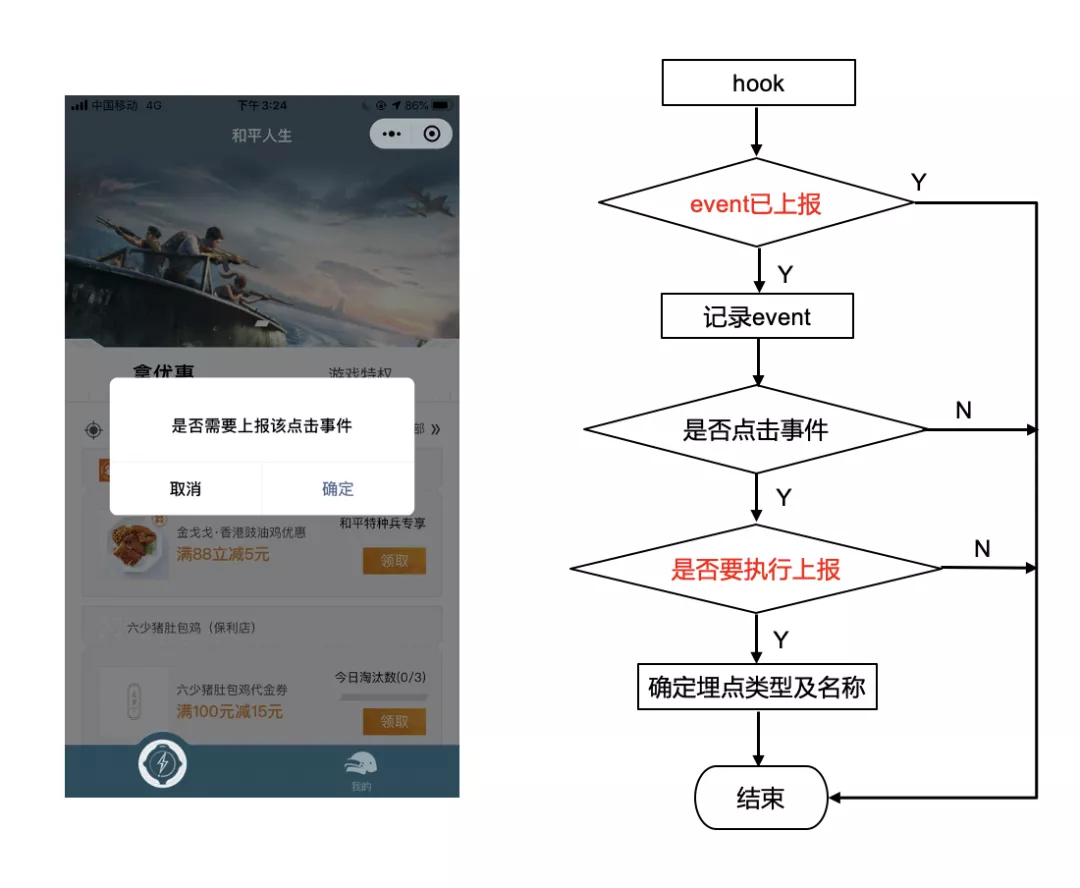
埋点模式是供产品使用的,产品点击页面时,会触发逻辑层的某个函数,前面说到,每个函数都会添加 hook。
Hook 的执行流程如下:首先会根据事件对象的事件戳和标识符来判断这个事件是否已经上报处理过,如果是就直接结束。否则就记录下这个事件已经处理过,防止后面重复处理。
然后再判断这个事件类型是否为点击事件,如果是就询问用户是否要执行埋点上报,最后确保埋点类型及名称。
(3)采集模式流程
采集模式是根据埋点事件进行数据上报。可以跟埋点模式一样:
给所有 func 添加 hook,在 hook 判断是否要上报。这种方案有个弊端,因为埋点事件的数量远比函数的数量要少,大多数函数是没必要进行 hook 的,给全部函数加上 hook 会影响页面的性能。
根据埋点事件找到需要上报的 func,只给这些 func 添加 hook。很明显,这种方案更佳,下面看看具体实现流程。
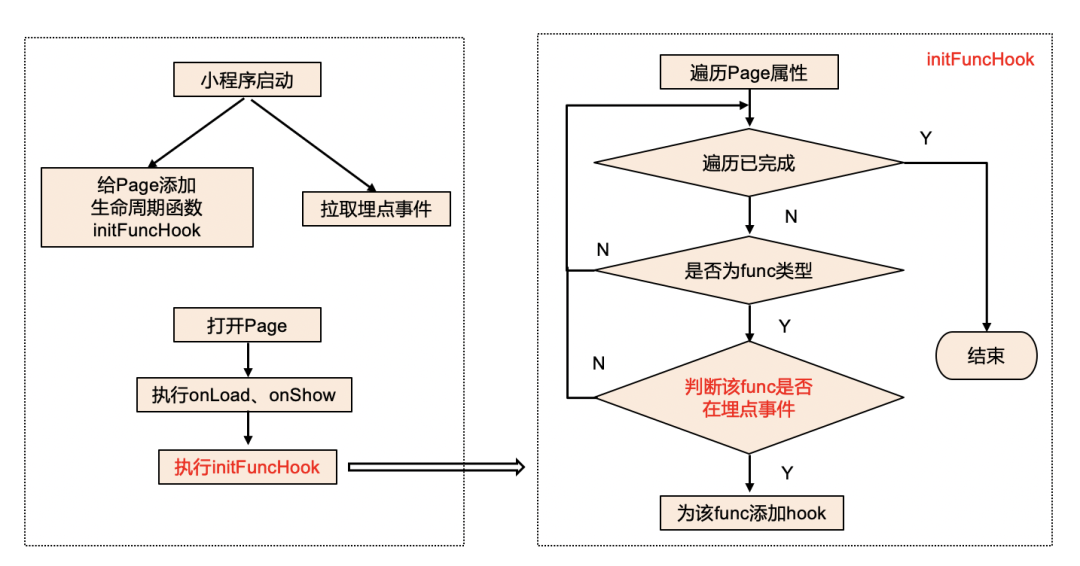
小程序启动的时候,同时进行两件事:
给页面添加一个生命周期函数 initFuncHook;
从后台拉取埋点事件。
当页面打开的时候,去执行 initFuncHook 生命周期函数,initFuncHook 的流程如下:
遍历页面的属性,判断属性是否为 fun 类型,并且是需要埋点的,如果需要则添加 hook,如果不需要就重新遍历对象属性,直到所有属性都遍历为止。
至此,小程序可视化实时埋点的整体思路就介绍完了。
头图:Unsplash
作者:杨浩彬
原文:https://mp.weixin.qq.com/s/g37cB0Qvn112yXpkrHKgnQ
原文:小程序可视化实时自动埋点设计
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




