
自从深度学习提出以来,AI 得到了快速的发展,每年都会有很多成果涌现,2020 年也是丰收的一年,在各个 AI 领域都有很多里程碑的成果,在计算机视觉领域,也有很多技术上的重要突破性进展,今天给大家分享的就是其中两个重要进展,一个是计算机视觉中的自监督学习,另一个是计算机视觉的 Transformer 注意力建模,同时介绍讲者所在的微软亚洲研究院研究小组在这方面所做的相关工作。
下面分三个部分来介绍具体的内容:
2020 年计算机视觉研究的三大突破
计算机视觉中的自监督学习
计算机视觉的 Transformer 注意力建模
2020 年计算机视觉研究的三大突破
首先介绍 2020 年的计算机视觉领域有哪些突破性的进展。

1. 自监督学习
第一个突破是在自监督学习领域,2020 年自监督学习首次超越了有监督预训练,这是一个里程碑。标志性的工作有何恺明等人的 MoCo(参见论文《Momentum Contrast for Unsupervised Visual Representation Learning》),以及 Hinton 等人的 SimCLR(参见论文《A Simple Framework for Contrastive Learning of Visual Representations》)。这两个工作在不到一年的时间里面已经收获了 450 和 550 个引用,对自监督学习是一个极大的促进。
2. Transformer 注意力建模
第二个重要的突破是 Transformer 成功应用于主流视觉问题,代表工作有 DETR(参见论文《End-to-End Object Detection with Transformers》)和 ViT(参见论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》),它首次将 transform 成功地应用于主流的视觉问题,具体来说是分别应用在目标检测和图像分类上。这两项工作对将 CV 和 NLP 统一在同一种模型下,并开辟了一个新的研究潮流。也正因为如此,2020 年的下半年涌现了很多 transform 相关的 CV 方向论文。
3. 用于视图合成的神经辐射场
第三个重要突破是 NeRF(参见论文《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》),它对于低层视觉来说是一个里程碑的进展。
视觉中的自监督学习
1. 自监督学习的重要性- Yann LeCun 的蛋糕
Yann LeCun 在他图灵奖颁奖典礼演讲中有一个著名蛋糕类比,即用一块蛋糕来类比各种学习方式,其中包括强化学习、有监督学习,以及自监督学习等。Yann LeCun 把强化学习比作蛋糕中的樱桃,认为它虽然耀眼,但不是根本的;又把有监督学习比作蛋糕中的冰激凌,虽然好吃但也不是根本;Yann LeCun 把自监督学习比作蛋糕本身,认为它才是实现人类智能最根本的东西。

自监督学习为什么这么重要?
Yann LeCun 认为人类婴儿就是通过自监督学习来认识这个世界的。婴儿出生后并不能与成人做直接交流和学习,所以他的学习不是有监督学习。婴儿与环境的交互有一些,但不够充分,因此他的学习主要也不是强化学习。事实上,婴儿大部分的学习是通过观察周围环境,从观察中蕴含的自监督任务来进行学习的,也就是说自监督学习才是人类通向智能最本质的一条道路。
关于婴儿是如何进行学习的,IBM 的 Linda Smith 和 Michael Gasser 在 2005 年发表的《The Development of Embodied Cognition: Six Lessons from Babies》主题报告中有一些很好的阐述,有意者可以阅读参考。
2. “有监督预训练+下游任务微调”范式
2012 年 AlexNet 横空出世,在当年的 ImageNet 比赛中,将错误率空前地降低了约 40%,从此人工智能步入深度学习时代,以后所发表的计算机视觉论文中越来越多的出现了“deep”一词,而在 2014 年开始“deep”一词出现的次数又有了明显的激增。
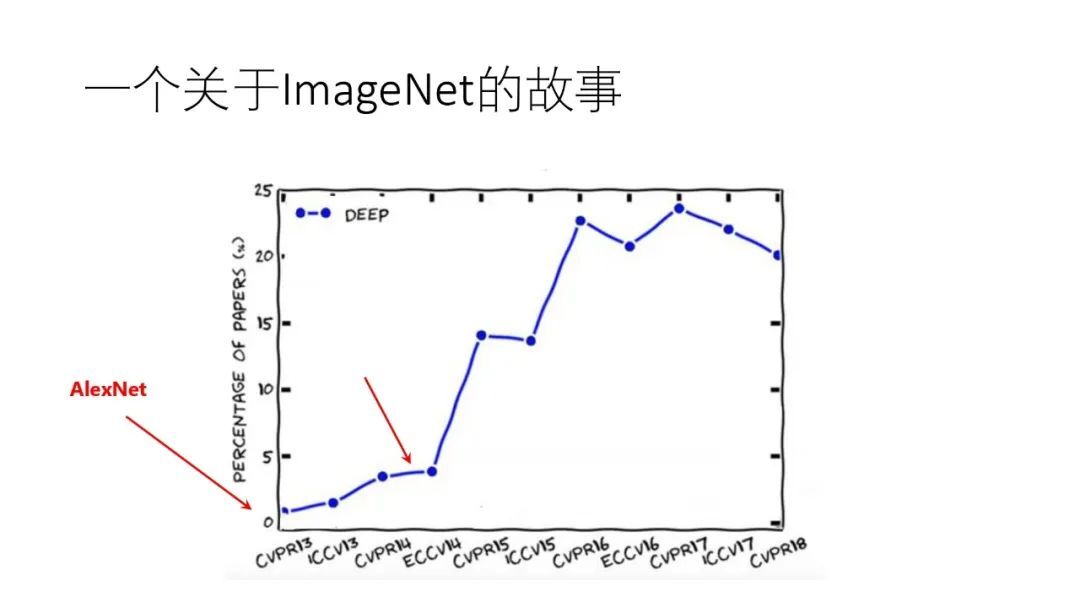
而导致激增一部分原因在于 2014 年在学术界验证了一个很重要的范式(另一原因可能在于开源深度学习框架开始涌现),即“有监督预训练+下游任务微调”范式。
众所周知,深度学习训练需要大量的数据,然而我们在实际的下游任务训练中并没有很多的标注样本数据,通常只有几千甚至几百个数据,但是依然能训练出效果很好的模型,原因就是我们使用了“有监督预训练+下游任务微调”这样的范式。
以 ImageNet 为例,模型首先是在有 120 万标注数据的 ImageNet 分类数据集进行预训练,得到预训练模型,此后,下游任务则是基于预训练模型进行微调,通常的下游任务包括语义分割、目标检测、细粒度识别等等。相比不使用预训练模型,使用预训练模型的下游任务在模型性能上有很大的提升。

3. “自监督预训练+下游任务微调”
上面讲述了“自监督学习”和“有监督预训练+下游任务微调”,在 2019 年,这两件事情走到了一起,即“自监督预训练+下游任务微调”。这得益于一个里程碑的工作,就是何恺明等人提出的“MoCo”,即在 2019 年 CVPR 上发表的论文:“Momentum Contrast for Unsupervised Visual Representation Learning”。
MoCo 在 7 个下游任务中,利用自监督预训练首次超越了有监督预训练的效果。这很可能意味着人工智能自监督或无监督时代的到来,这不但让我们可以利用几乎无限的训练数据而无需标注,更重要的是,从认知的角度看,“自监督预训练+下游任务微调”这样的训练范式也与人类的学习方式更加接近。
4. 自监督学习的发展历程
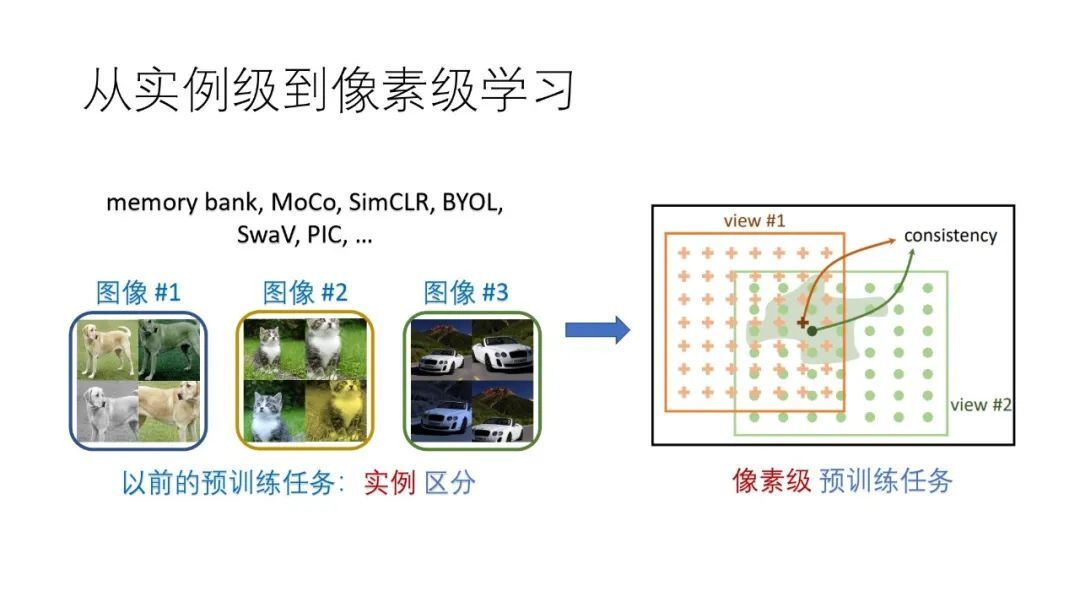
自监督训练是如何一步一步发展过来的呢?下面的图片中展示了过去十几年中出现的各种自监督学习方法。
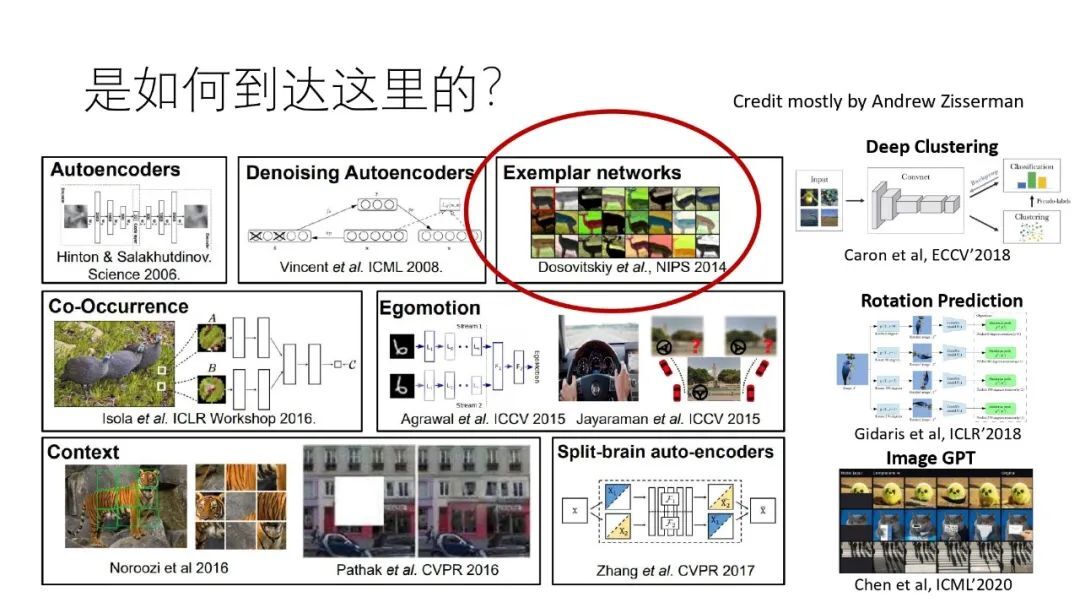
方法各种各样,值得注意的是最近的突破性进展主要发展自 2014 年的“Exemplar networks”,其特点是把每个样本图片都作为一个类别,例如 ImageNet 有 120 万张样本图片,那么就认为有 120 万个类别。这个任务其实蛮反直觉的,因为我们学习的目标通常是希望更多抽象,因此接着这个思路做的人最初并不多。终于在 2018 年中的“Memory bank”将这一思路推到了一个引人关注的程度,2018 年底的“Deep metric transfer”证明了这一思路在半监督学习中的重要价值,以及 2019 年底的 MoCo 取得了里程碑的结果,即在多个重要下游任务中超越有监督学习。从 MoCo 开始,自监督学习领域开始迅速发展,2020 年 2 月份,谷歌提出了 SimCLR,2020 年 6 月份我们研究小组提出了 PIC 和 PixPro,Deepmind 和 FAIR 分别提出了 BYOL 和 SwAV。2020 年 11 月份,我们研究小组进一步提出 PixPro,将自监督学习从图像级引入到像素级,显著地提升了物体检测和分割等下游任务的效果。

5. PIC:单分支无监督特征学习算法
Memory bank 、MoCo、SimCLR 等都是两分支算法,即对每个输入的图像都生成两个增强的视图,两个增强视图经过卷积网络提取其的特征,利用“将同一个图像两个视图的特征拉近,将不同图像生成的视图的特征推远的”原则,对网络进行训练。
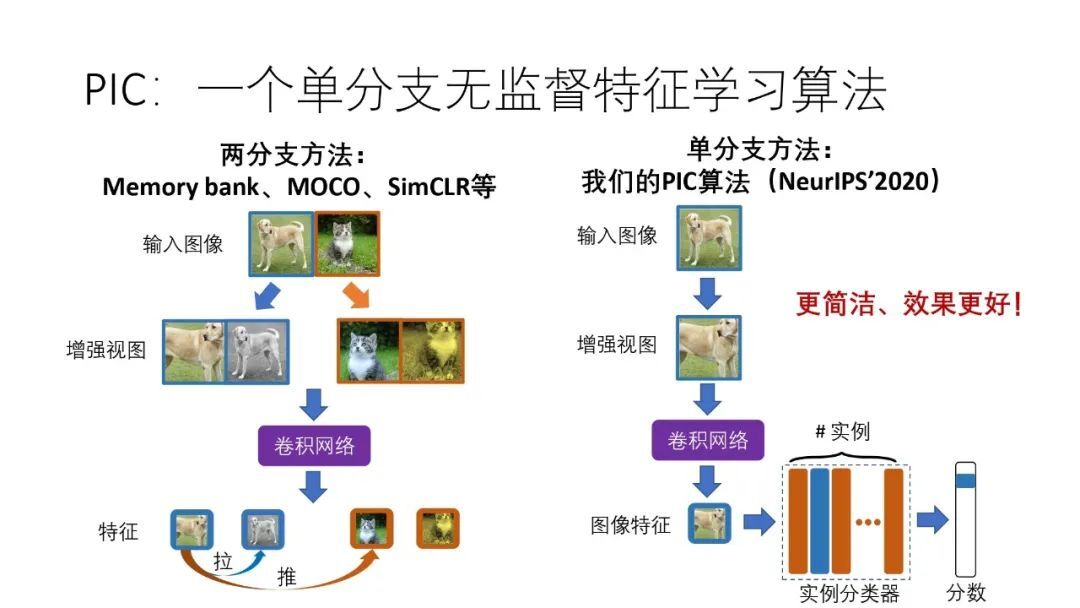
PIC 不是两分支网络,而是一个单分支网络,即对每个输入的图像生成一个增强视图,同样使用卷积网络提取特征,但在卷积后接了一个分类器用于图像的分类。相比两分支算法,PIC 更简洁,并具有同样好的效果。
6. PixPro:像素级自监督学习算法
过去一年,自监督学习在 ImageNet 的 1000 类线性分类评测上的性能有着明显的提升,从 MoCo 到 CLSA 有 15.6%的绝对性能提升。
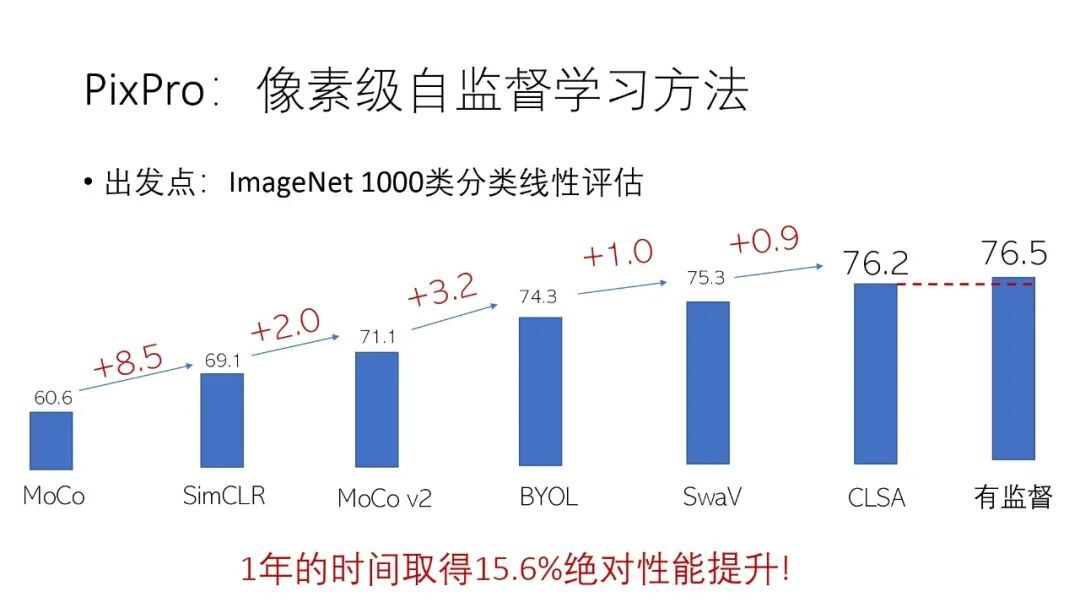
但是在一些依赖稠密预测的下游任务的效果上并没有多少提升,以 Pascal VOC 目标检测为例,从 MoCo 到 InfoMin 只有 1.7%的绝对性能提升,而 PixPro 相比 InfoMin 将 Pascal VOC 目标检测任务的性能提升了 2.6%。
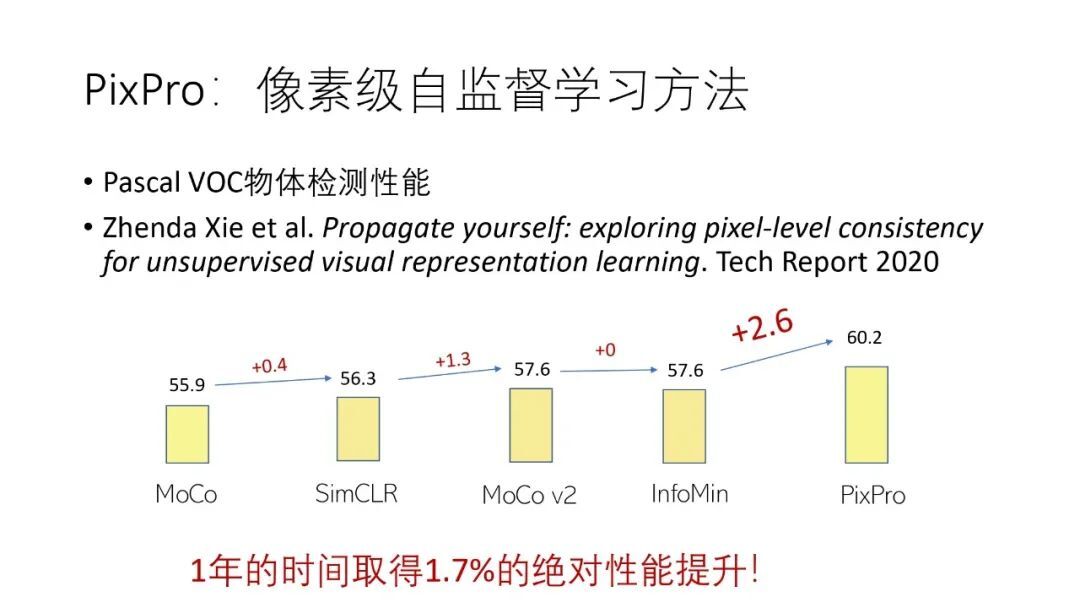
PixPro 在其他下游任务中也有性能上的提升:
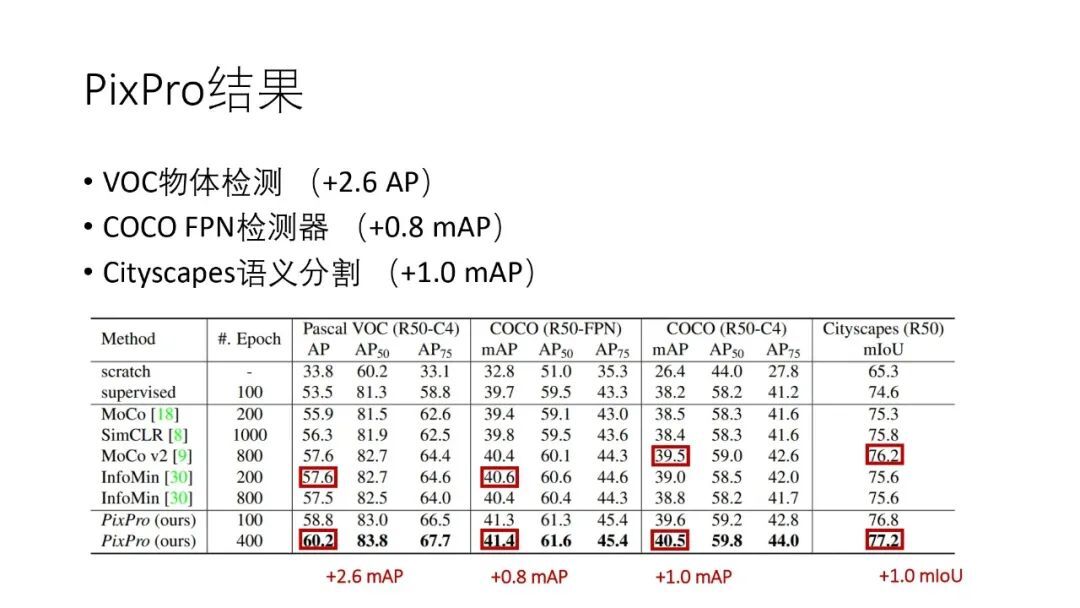
相比于其他的自监督训练算法,PixPro 的关键思想是将基于图像的预训练任务转变为基于像素的预训练任务。在下游任务中,很多都是基于像素的任务,例如图像分割、目标检测等。如果预训练是基于像素进行的训,那么其与下游的任务将更加契合,从而有可能带来更好的表现。
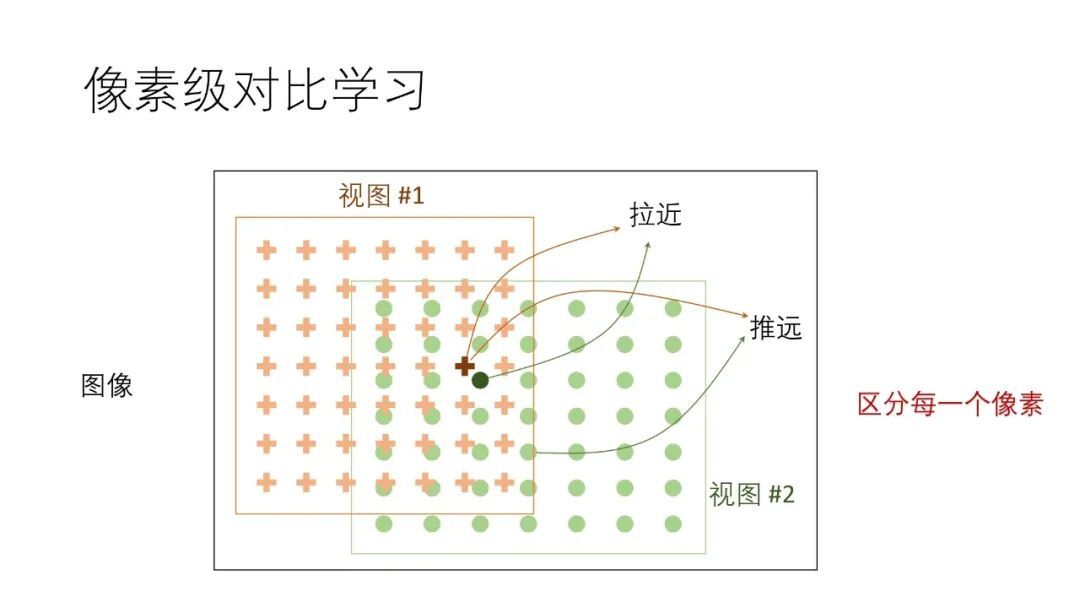
我们首先提出了一个区分每个像素的预训练任务,对于一个输入的图像,我们和此前的图像级方法一样,对其进行视图增强,得到两个增强的视图图像,然后使用“拉近两个视图中相近像素的特征,推远两个视图中距离较远的像素的特征”的任务来对网络进行训练,从而将基于图像的预训练推广到基于像素的预训练。我们将这种方法称为“区分像素”的预训练任务,简称 PixContrast
在此基础上,我们提出了 PixPro,它是对 PixContrast 的一个改进,具体有两点改动:
像素平滑:视图 1 特征提取保持不变,视图 2 的特征做平滑处理,即使用周围的像素对目标像素进行平滑。
去掉推远分支
我们称改进后的方法为 PixPro,即“像素-传播的一致性”的预训练任务。
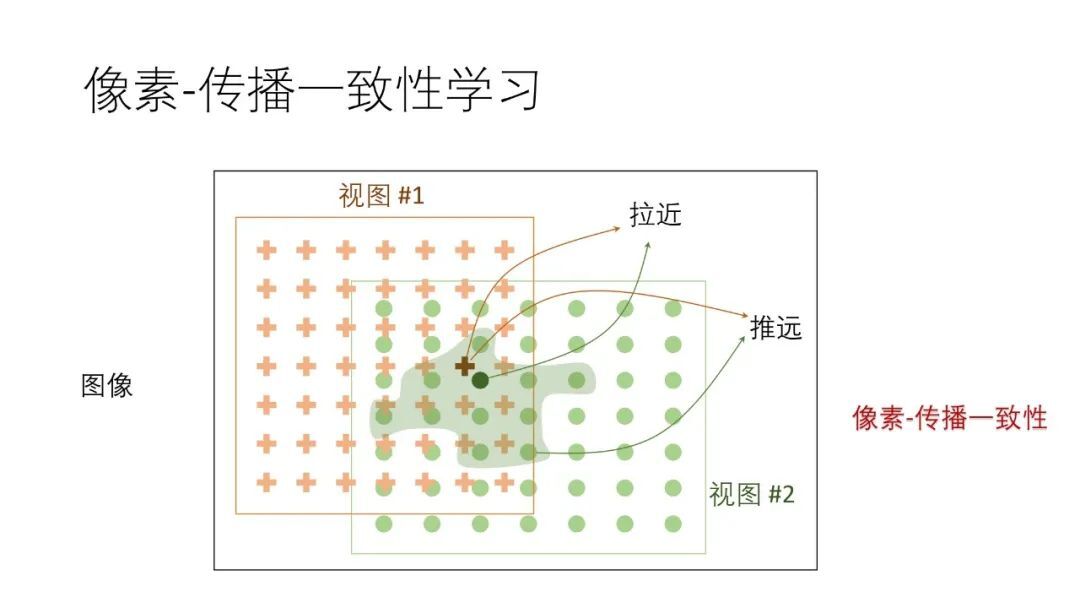
改进前的“区分像素”训练任务主要是进行像素对比,增强模型的空间敏感性;改进后的训练任务由于加入了像素平滑,增强了模型的空间光滑性。由于下游任务像素之间是有相关性的,所以增加模型的空间光滑性可以增强下游任务的训练效果。
PixPro 的结构图如下:
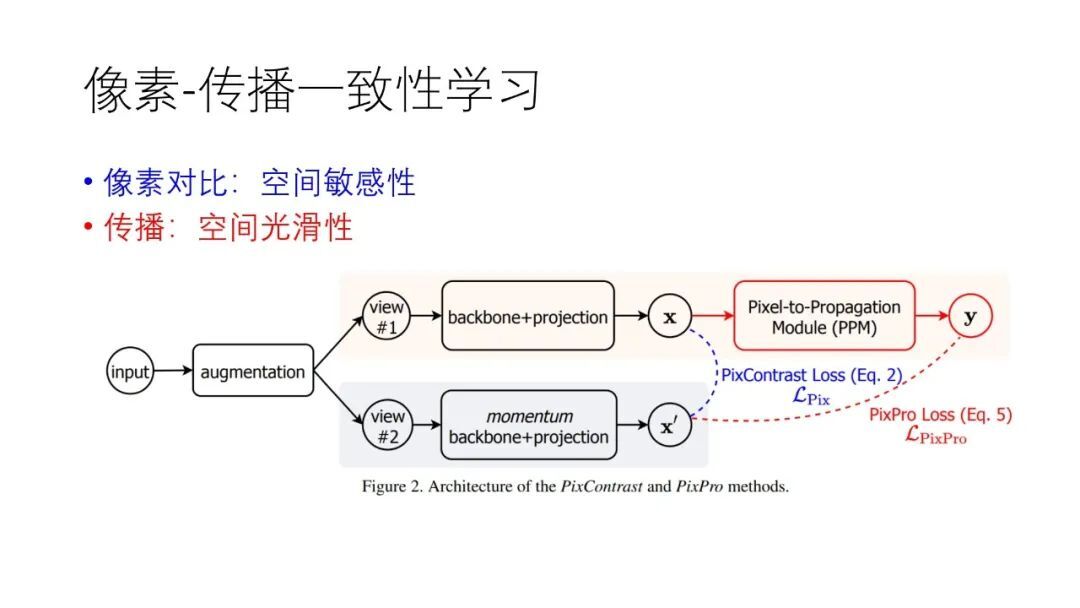
像素级别的自监督训练优点还在于:可以让预训练模型和下游任务训练模型采用相同的网络结构,例如可以把 FPN 引入到预训练模型中。
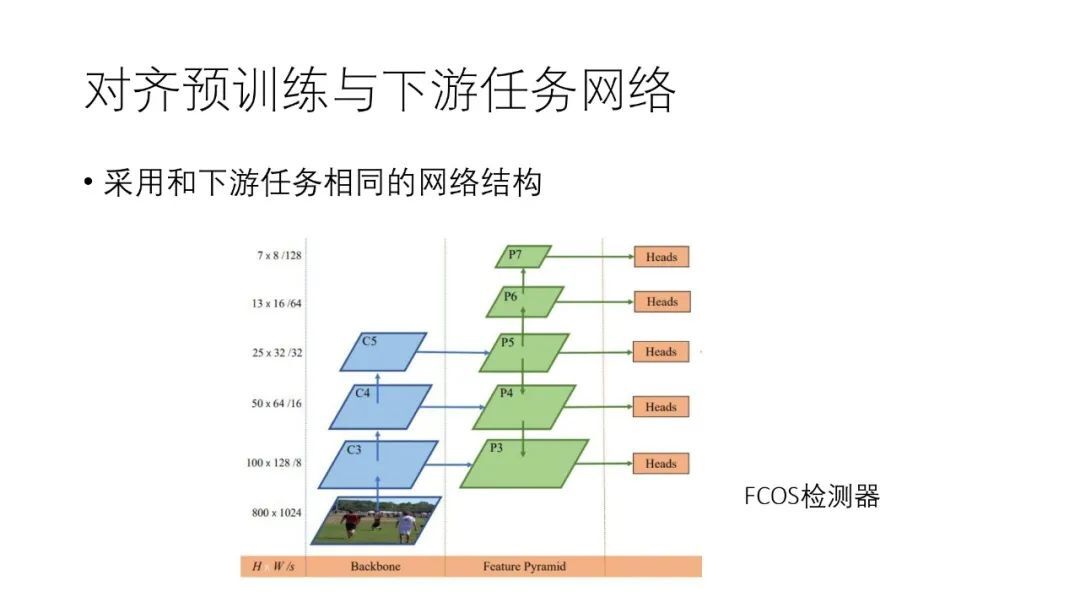
7. 非静态图片的自监督预训练
除了上诉基于静态图片的自监督预训练之外,过去一年中“基于视频的预训练”和“多模态特征预训练”也有一定进展。“基于视频的预训练”的代表性研究员和研究小组有牛津大学的 Andrew Zisserman、谢伟迪,以及加州大学伯克利分校的 Alexei Efros 和王小龙等人。“多模态特征预训练”是将图像与声音、语言等多种输入信息相结合来进行自监督训练,这种方式与人的学习很像。
视觉中的 Transformer 注意力建模
1. 人工智能的大统一故事
大统一理论是物理学的圣杯,无数人致力于将四种相互作用力统一起来。在人工智能领域也有这样一个目标,而且事实上深度学习的浪潮已经让我们在大一统上前进了很大一步,例如我们的学习机制基本已经统一:数据标注和基于误差反向传播的训练方法。
但是人工智能的不同领域的主流建模方法还是不尽相同的。
自从 Yann LeCun 提出 LeNet 到现在,CV 领域最基础模型一直是卷积网络。
而在 NLP 或者序列建模领域,其模型则经历了一个变迁的过程,直到 2017 年 Transformer 提出之后才稳定下来,如今 Transformer 成为了 NLP 的主流建模方法。NLP 或者序列建模领域的模型的主要变迁如下图所示:
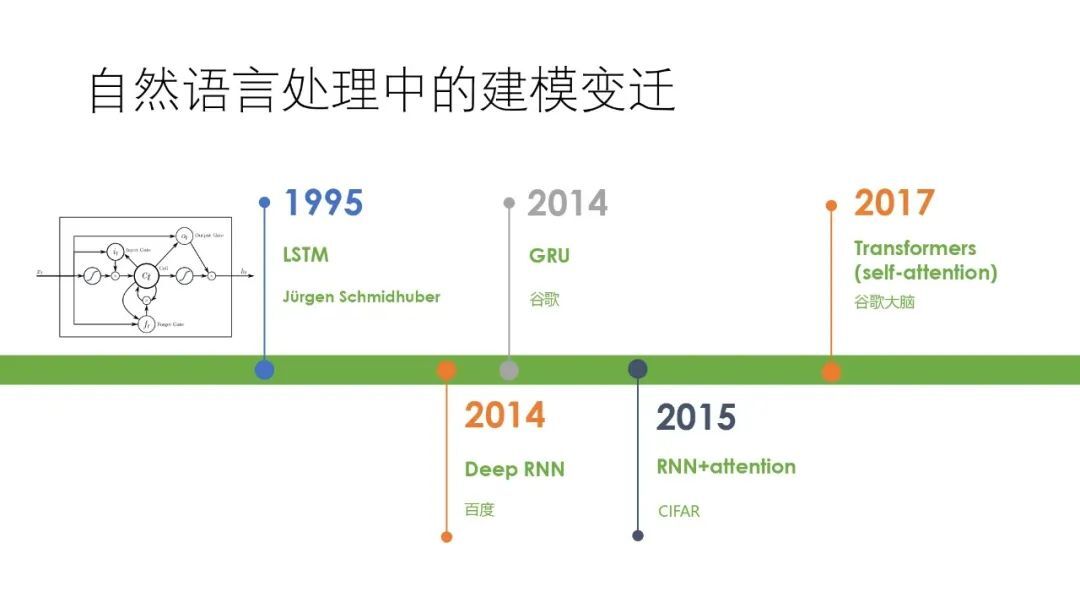
而 2020 年 Transformer 在计算机视觉领域的应用改变了 CV 和 NLP 两大领域模型结构不一样的局面,对视觉和自然语言处理两大领域的模型统一起到了极大的促进作用。我们对在视觉中使用 Transformer 已有了多年的探索,我们探索的出发点是“自然语音处理与计算机视觉的统一建模”,这一方面是为了实现自然语音处理与计算机视觉模型数学形式上的统一,另一方面是希望两个领域将来能更好的互通和相互促进。在 2020 年,学术界在这个方向上已经迈了很大一步。
2. CV 与 NLP 统一建模
① 卷积在 NLP 中的应用
在 NLP 领域,人们曾尝试将卷积应用在 NLP 领域,也切实地提出了一些不错的方法,例如 2017 年 FAIR 提出的 ConvSeq2Seq、2019 年 FAIR 提出的 Dynamic Convolution 以及微软亚洲研究院提出的 Deformable Convolution 等等都取得了一定效果,但离 Transformer 的性能都有些差距。特别是在 GPT、BERT 等预训练模型提出之后,Transformer 的地位更加稳固了。

② Transformer/注意力机制在 CV 中的应用
同样在 CV 领域,人们也在尝试使用 Transformer 进行建模,并且在 2020 年的几项工作使得 Transformer 在 CV 的应用得到了突破性的进展。首先得到广泛关注的是 FAIR 的“DeTR”,将 Transformer 整体成功应用于物体检测中,随后微软亚洲研究院提出了 RelationNet++,用 Transformer 解码器来解决融合不同物体表达方法的问题,在 10 月份谷歌又提出了 Vision Transformer,用 Transformer 来作为 backbone 网络进行图像分类。
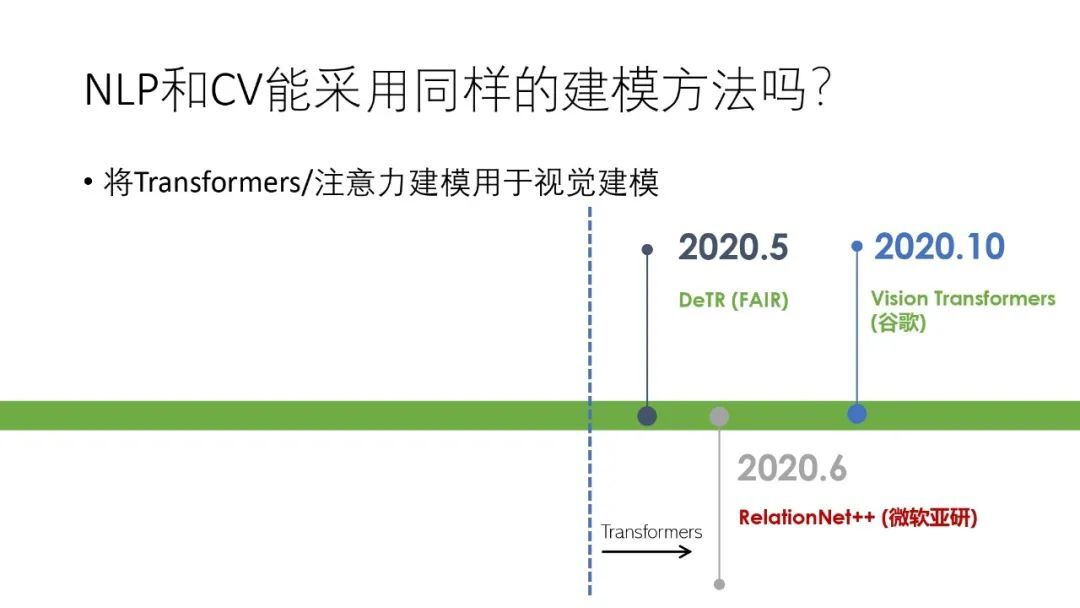
下面对这些工作一一进行介绍。
3. 将 Transformer 应用在 CV 领域的一些工作
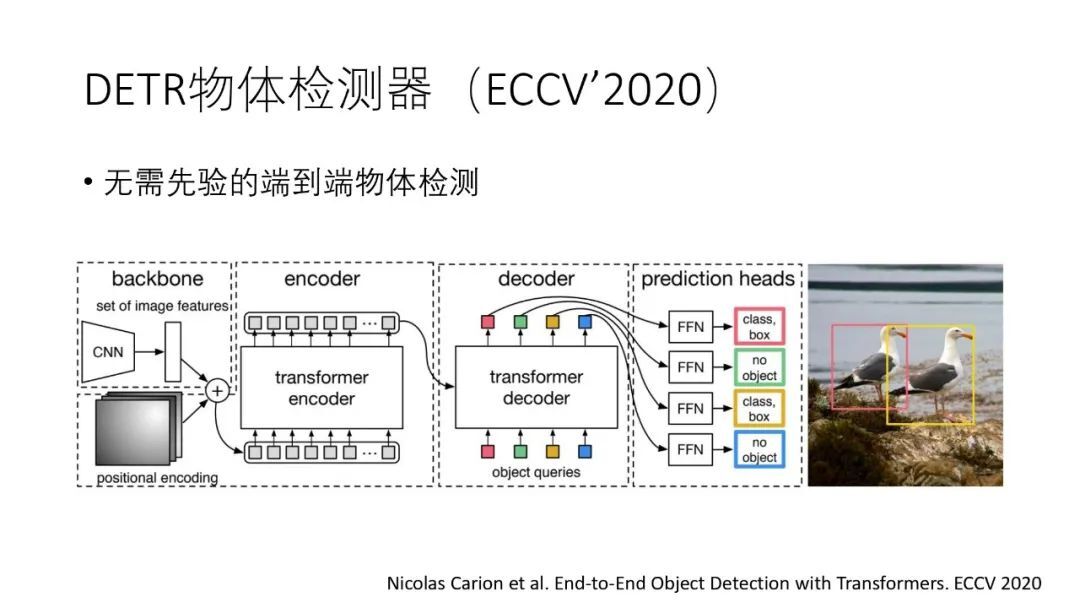
① DETR
DETR 是将 Transformer 应用到物体检测任务上,其特点是将 Transformer 在 NLP 上的应用方法照搬到 CV 领域,直接对图像特征进行编解码,并且实现了端到端的训练。但是它依然使用了 CNN 进行了特征提取,并没有完全摆脱 CNN 的使用。
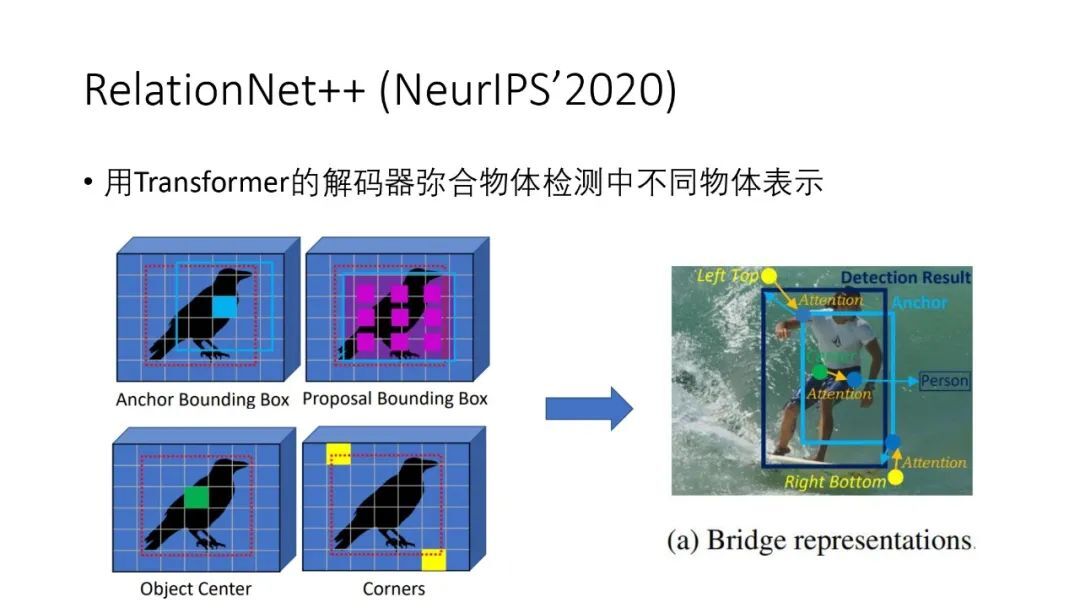
② RelationNet++
在 RelationNet++工作中,我们使用 Transformer 的解码器去拟合物体检测中不同物体的表示。目前表示物体的方法有多种,例如用物体的中心点、或者 anchor 框,或者 Bounding Box,或者物体框的对角位置等等,这些表示方法各有优点,但是我们一种物体检测模型中一般只使用一种表示方法,但是利用 Transformer 解码器就可以把各种表示方法统一起来,将各种表示方法的优点结合起来,这样在 CoCo 上单模型可以取得 52.7%的 mAP。
③ Vision Transformers
Vision Transformers 是将 Transformers 应用到了图像分类任务上,其实际速度和精度均超越了 ResNet。它的方法是将原图分割成多个尺寸是 16*16 的子图,对于 RGB 图像,每个子图就是一个 768(16*16*3)维的向量,然后将其输入到 Transformers 编码器中。虽然这个方法简单,但是其效果和实际运行速度都是不错的。
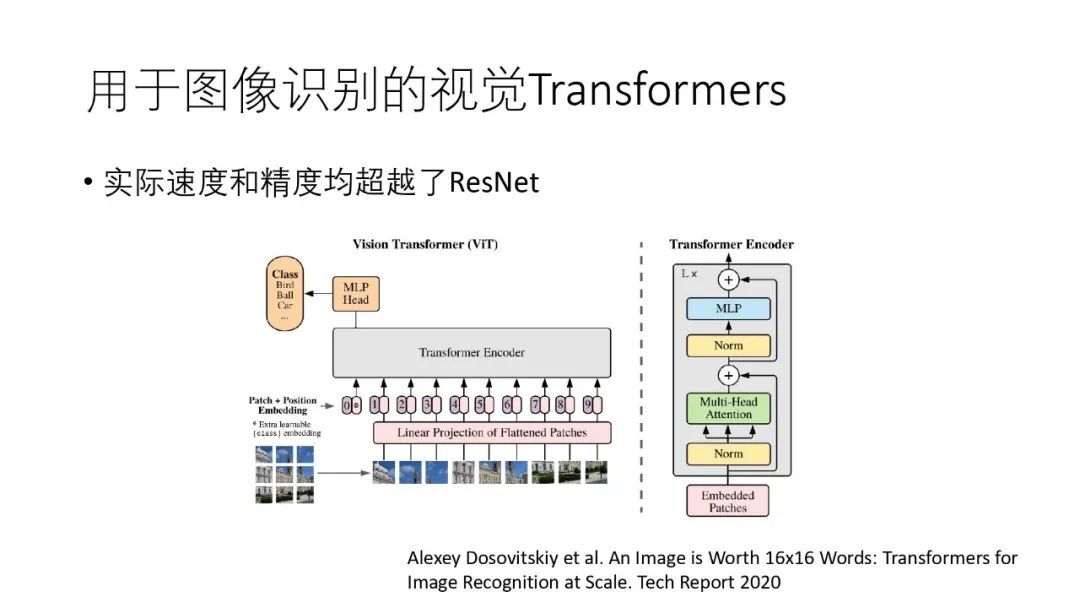
4. 注意力机制在 CV 上的应用
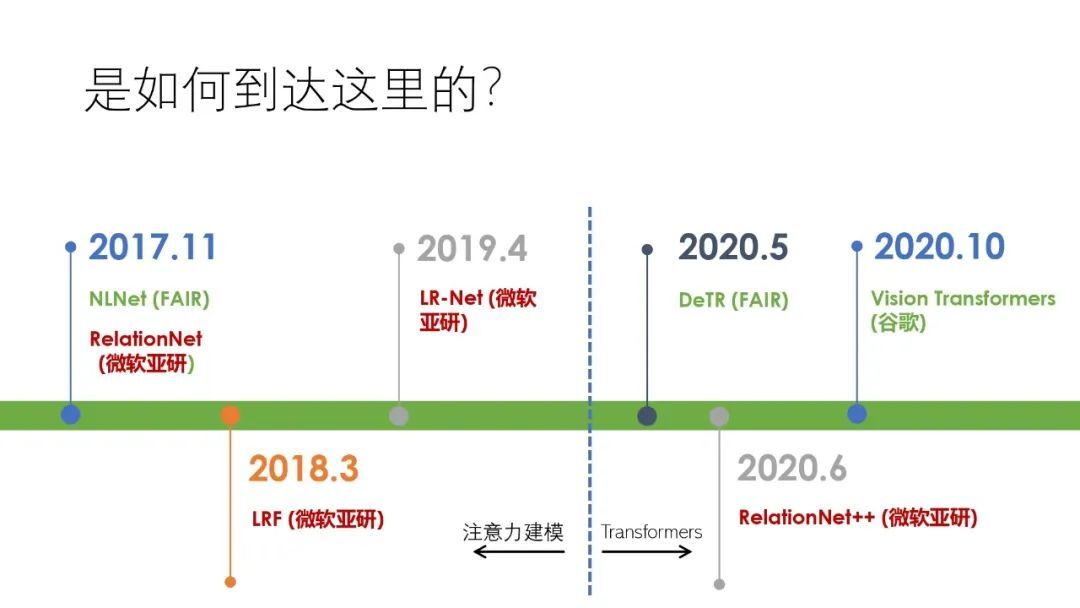
在 Transformers 应用在 CV 领域之前,人们就已经将 Transformers 中的注意力机制应用在了 CV 领域上,例如 FAIR 在 2017 年提出了 NLNet,我们的研究小组从 2017 年至 2020 年分别提出了 RelationNet、LRF 和 LR-Net。也应注意到这期间出现了大量利用注意力机制来解决视觉中各种问题的工作,由于时间关系,本次演讲中涉及就少。
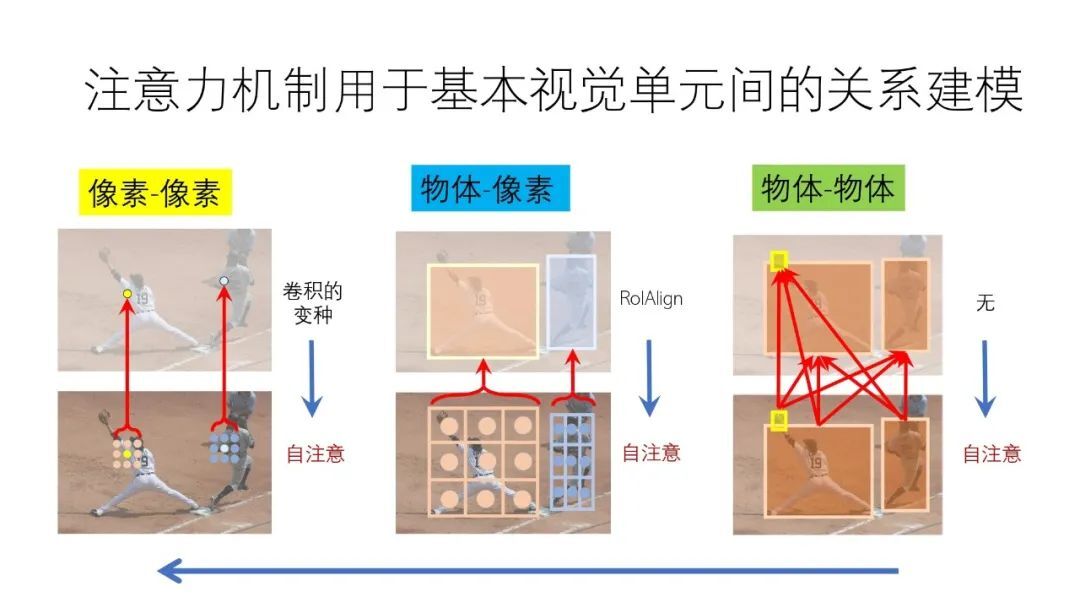
注意力机制用于基本视觉单元间的关系建模
我们在视觉的建模中都会涉及到两个层次的概念,一个是“像素”,一个是“物体”。而视觉的建模就是“像素和像素”之间或“物体和像素”之间或“物体和物体”之间的关系建模。针对“像素和像素”目前主流方法是用卷积进行关系建模,针对“物体和像素”目前主流的方法是利用 RoIAlign 等方法建立关系,而“物体和物体”的关系建模以前涉及较少。事实上,这些不同的关系建模其实都可以用注意力方法来代替。
5. 注意力机制的物体-物体关系建模
在将注意力机制引入 CV 领域之前,并没有考虑物体与物体之间的关系建模,引入注意力之后就可以考虑物体与物体之间的相互关系了,我们有很多工作都使用了注意力机制进行物体之间的关系建模,例如物体检测模型 RelationNet [CVPR’2018]、多目标跟踪模型 Spatial-Temporal Relation Network [ICCV’2019]、视频物体检测 MEGA [CVPR’2020]等。

① 物体检测器
我们首次使用注意力机制实现了端到端的物体检测,参见发表在 CVPR’2018 上的论文《Relation Networks for Object Detection》。
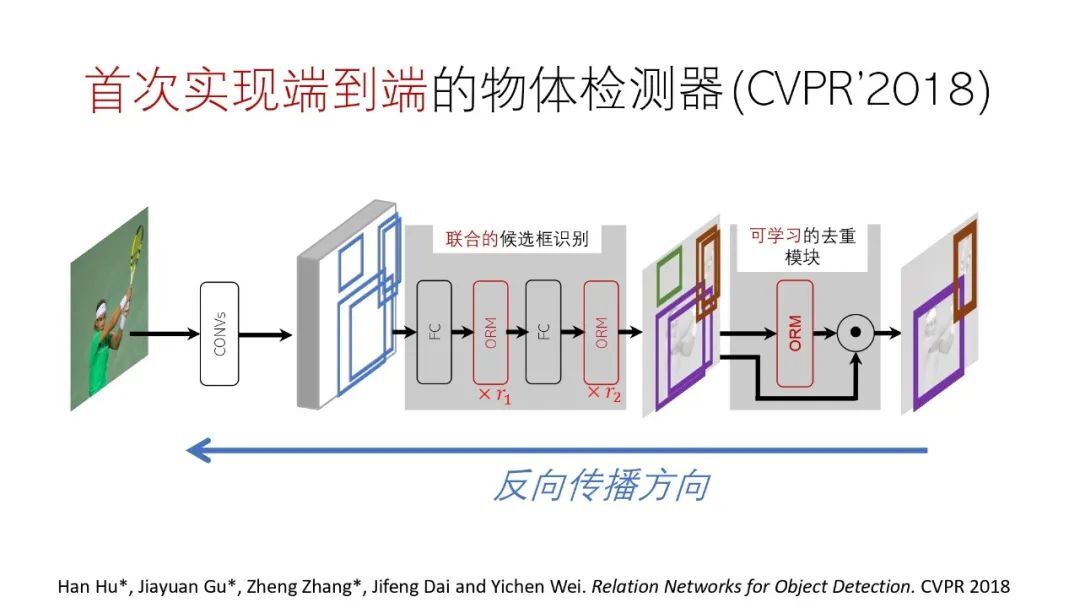
该方法的关键是使用注意力机制代替了 NMS 模块,这样整个过程就都可以使用反向传播进行训练,使去重模块也可以学习。
② 多目标跟踪模型
我们在目标跟踪任务上也使用了注意力机制,可参见发表在 ICCV’2019 上的论文《Spatial-Temporal Relation Networks for Multi-Object Tracking》
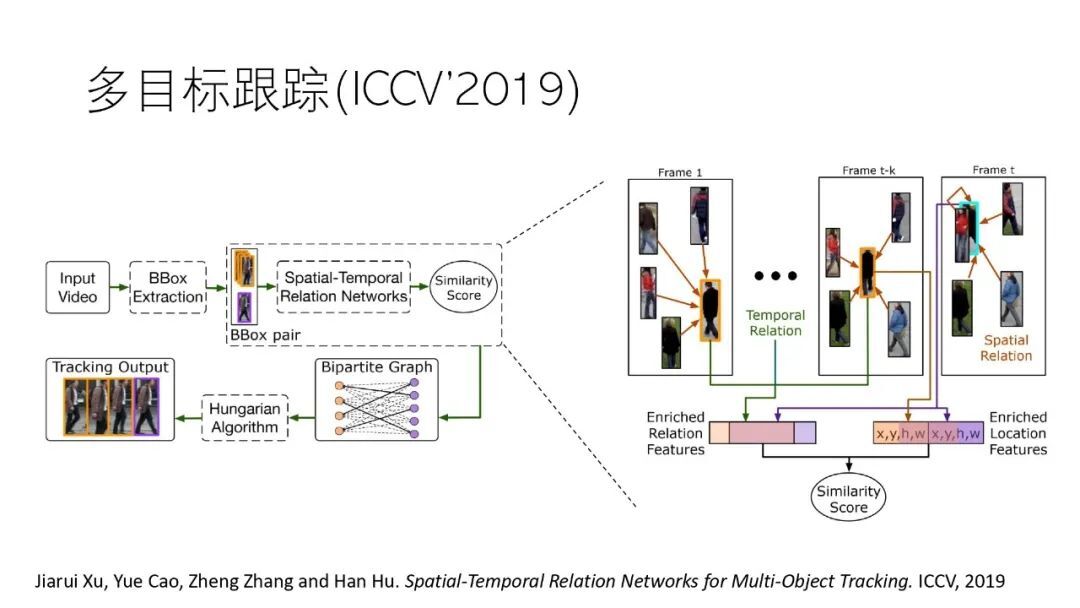
③ 视频物体检测
我们在 CVPR’2020 上发表的论文《Memory Enhanced Global-Local Aggregation for Video Object Detection》则是注意力机制在视频物体检测任务上的应用。目前效果最好的视频物体检测方法大多都使用了注意力建模。
6. 注意力机制的物体-像素关系建模
在使用注意力机制之前,基本上都是用 RoIAlign 等方法在 feature map 中截取目标物体的区域特征,在使用注意力之后,就可以自适应的去获取目标物体的区域特征。
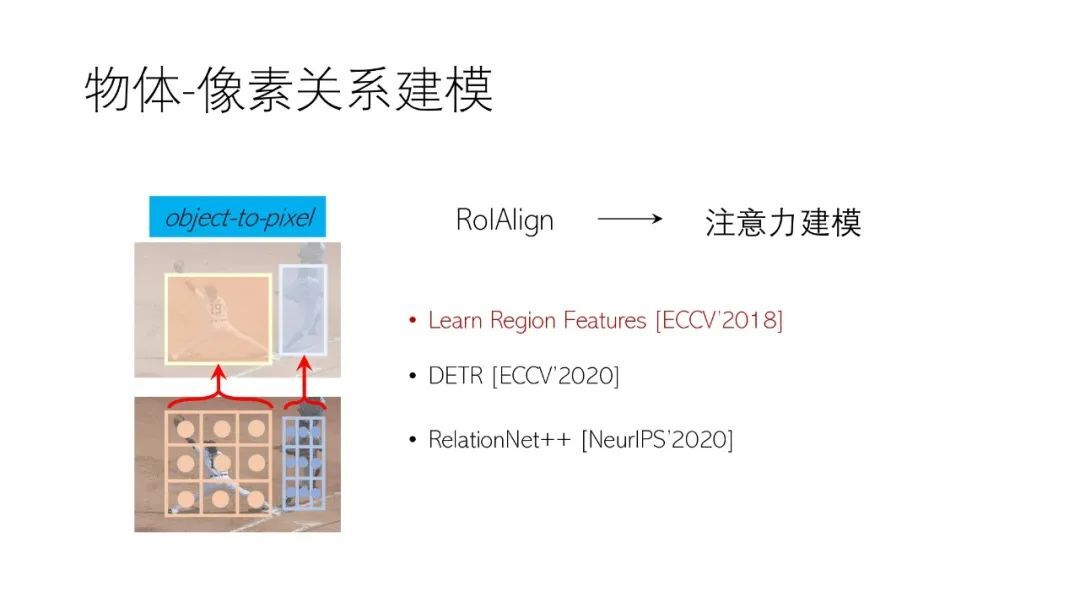
我们在 ECCV’2018 发表的论文《Learning Region Features for Object Detection》就使用注意力机制自动学习了区域特征的提取。

7. 注意力机制的像素-像素关系建模
在注意力机制之前,图像像素与像素的关系是使用卷积进行建模,在像素与像素之间关系建模引入注意力机制之后,注意力机制可以与卷积进行互补,甚至注意力机制完全代替卷积。
① 注意力机制与卷积互补
由于卷积自身的结构特性,用卷积进行像素与像素间关系建模会有区域的局部限制,如果用注意力机制进行补充,则可以获取全局的信息。王小龙和何凯明等人在 CVPR’2018 提出的非局部网络(NL-Net)在卷积网络中插入一种使用注意力实现的全局模块,这样可以提升很多任务的性能。
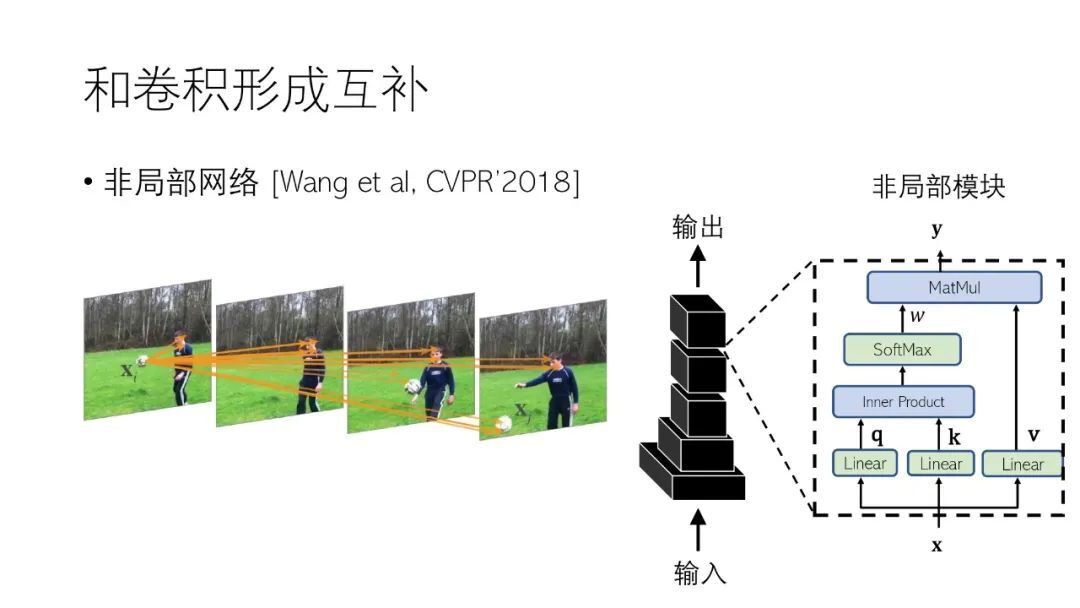
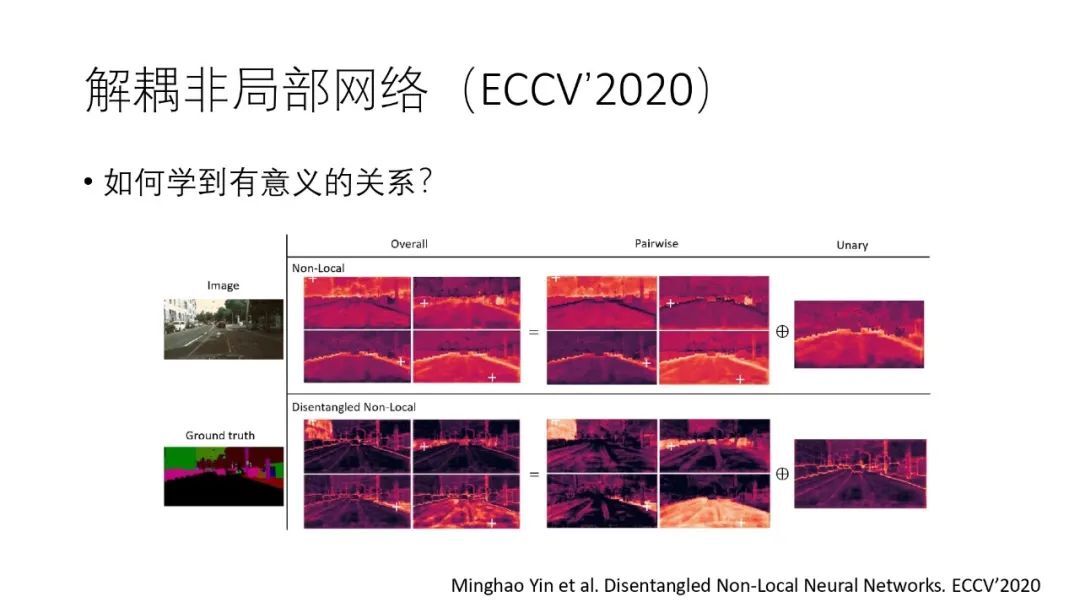
但是上面的方法会出现退化现象,即不同的查询像素,其实受到了一组 Key 像素的影响,我们将这个研究发表在了 TPAMI’2020 上。
针对非局部网络的退化问题,我们在 ECCV’2020 发表的《Disentangled Non-Local Neural Networks》论文中给出了一种解耦非局部网络的方法,使模型能够学到更有意义的物理关系。
② 用注意力机制替换卷积
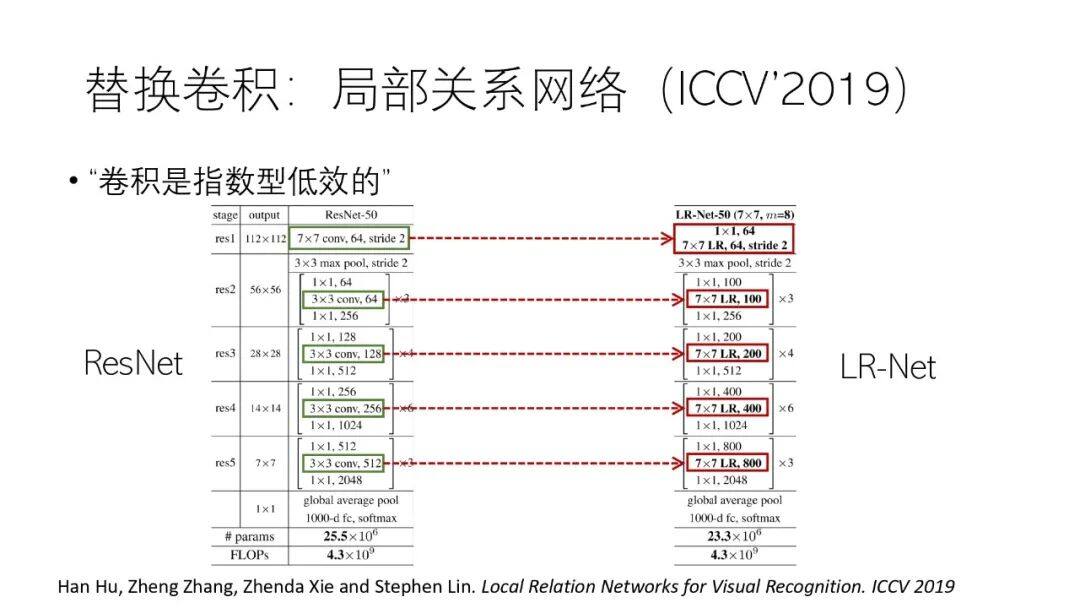
相比注意力机制与卷积配合,更进一步的是使用注意力机制完全代替卷积,我们在 ICCV’2019 发表的论文《Local Relation Networks for Visual Recognition》中提出了一种用注意力代替卷积的方法,即将 ResNet 中的卷积单元换成注意力单元,模型在相同 FLOPs 情况下取得了更高的精度。
总结
计算机视觉已经开始进入自监督或无监督训练的时代
Transformer 和注意力模型:目前最有可能统一视觉和自然语言的建模方法
分享嘉宾:
胡瀚 博士
微软亚洲研究院 | 研究员
演讲者简介:Han Hu is currently a principal researcher in Visual Computing Group at Microsoft Research Asia (MSRA). He received the Ph.D degree in 2014 and the B.S. degree in 2008 from Tsinghua University. His Ph.D dissertation was awarded Excellent Doctoral Dissertation Award of CAAI at 2016. He was a visiting student in University of Pennsylvania from October, 2012 to April, 2013. Before he joined MSRA in Dec. 2016, he worked at Institute of Deep Learning (IDL), Baidu Research, His research interest include visual representation learning, joint visual-linguistic representation learning and object recognition. He will serve as an area chair of CVPR2021.
Homepage:
https://ancientmooner.github.io/
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:计算机视觉中的自监督学习与注意力建模




