
Kafka 2.3 引入了将 Apache Kafka 消费者连接到相同可用区域(AZ)代理节点的能力,Grab 利用这一能力重新配置了消费者,将亚马逊云科技上的流量成本降低为零。这一更改大大降低了在亚马逊云科技上运行 Apache Kafka 的基础设施总成本。
Grab 以 Apache Kafka 为中心创建了一个流数据平台,支撑公司所有的产品。遵循 Kafka 最佳实践,他们的初始配置为每个 Kafka 分区三个副本,横跨亚马逊云科技区域中三个不同的可用区。负责该平台的团队观察到,跨 AZ 流量占了他们 Kafka 平台一半的成本,因为亚马逊云科技对跨AZ数据传输收费。
对于初始设置的成本,Fabrice Harbulot和Quang Minh Tran的看法如下:
这种设计的问题在于,它会产生惊人的跨 AZ 网络流量。这是因为,在默认情况下,Kafka 客户端只与分区 leader 通信,而分区 leader 有 67%的概率驻留在不同的 AZ 中。
跨 AZ 流量包括新发布的消息、代理之间的数据复制和消费者获取的消息。
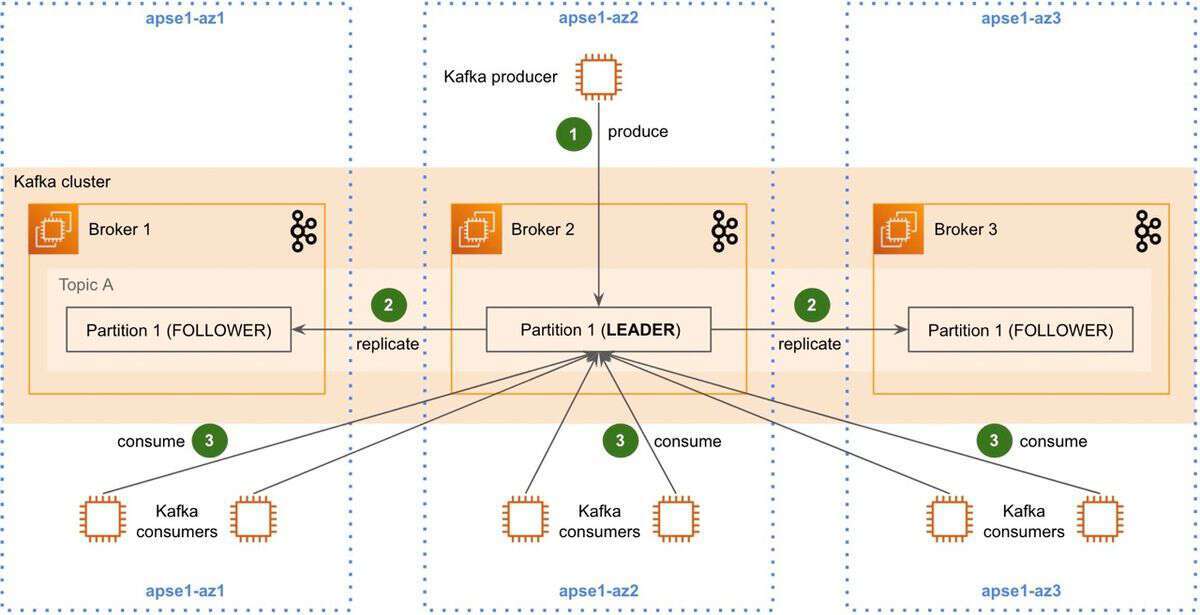
默认消费者配置,消费者从分区 leader 获取数据(图片来源:Grab工程博客)
从Apache Kafka 2.3开始,可以将消费者配置为从分区副本中获取数据了。这样,如果消费者只从同一 AZ 中的代理获取消息,就不会产生数据传输成本了。
这个特性要求 Kafka 代理和消费者都知道其所在的 AZ。对于 Kafka 代理,团队会使用 AZ ID(az1、az2、az3 等)配置broker.rack 。AZ ID 与 AZ 名称(1a、1b、1c 等)不同,因为AZ名称在亚马逊云科技账户间不一致。他们还将参数replica.selector.class的值设置为org.apache.kafka.common.replica.RackAwareReplicaSelector。
在消费者端,团队更新了内部 Kafka SDK,基于 EC2 主机元数据用 AZ ID 配置client.rack 参数,为的是应用程序团队可以通过导出环境变量来启用该功能。

自定义消费者配置,消费者从最近的副本获取数据(图片来源:Grab工程博客)
在某些服务上应用新设置后,团队观察发现,跨 AZ 流量成本下降,并且有一些值得注意的副作用。首先,端到端延迟最多增加了 500 毫秒。考虑到大多数消费者从副本获取消息,这也是意料之中的。延迟增加是由复制时间导致的。理论上,任何对延迟敏感的数据流都应该始终从分区 leader 获取数据,即使那样会产生额外的成本。
其次,在代理维护(停机)时,直接从副本获取消息的消费者可能会遇到代理不可用的情况,因此,它们应该等待/重试,直到同一 AZ 中的代理恢复在线。最后,团队观察到,代理的负载与跨 AZ 的消费者数量有关。这意味着,消费者的均匀分布对于确保代理的负载平衡至关重要。
原文链接:
https://www.infoq.com/news/2023/07/grab-apache-kafka-aws-cost/
相关阅读:




