
2023 年 12 月 27 日,《纽约时报》向曼哈顿联邦法院提起诉讼,指控 OpenAI 和微软未经许可使用该报数百万篇文章训练机器人。《纽约时报》要求获得损害赔偿,还要求永久禁止被告从事所述的非法、不公平和侵权行为,删除包含《纽约时报》作品原理的训练集等。虽然《纽约时报》并未提出具体的赔偿金额要求,但其指出被告应为“非法复制和使用《纽约时报》独特且有价值的作品”和与之相关的“价值数十亿美元的法定和实际损失”负责。
作为回应,当地时间 1 月 4 日,OpenAI 知识产权和内容首席 Tom Rubin 在采访中表示,公司近期与数十家出版商展开了有关许可协议的谈判:“我们正处于多场谈判中,正在与多家出版商进行讨论。他们十分活跃积极,这些谈判进展良好。” 据两名近期与 OpenAI 进行谈判的媒体公司高管透露,为了获得将新闻文章用于训练其大语言模型的许可,OpenAI 愿意向部分媒体公司缴纳每年 100 万至 500 万美元的费用。虽然对于一些出版商来说,这是一个很小的数字,但如果媒体公司数量足够多,对 OpenAI 而言必然是一次“大出血”。
自大模型落地应用以来,版权问题逐渐凸显。在《纽约时报》与 OpenAI、微软打官司之前,已有多人指控大模型存在抄袭。而一项研究更是表明,在文本和图像生成领域,“黑盒子”大模型普遍存在抄袭现象。
Google DeepMind 的 Nicholas Carlini 与 Gary Marcus 等学者提出一个广受关注的重要问题,即大语言模型(LLM)到底能“记住”多少训练中的输入内容。而最近的实证研究表明,大语言模型在某些情况下的确可以重现、或者生成只包含细小差别的训练集内初始文本。
例如,Milad Nasr 及其同事在 2023 年发表的论文就表明,大模型可能会在提示词的引导下泄露电子邮件地址和电话号码等私人信息。Carlini 及其合作学者也发现,体量较大的聊天机器人模型(小模型似乎没有这个问题)有时候会直接照搬训练时见过的大段文本。
同样,《纽约时报》最近在对 OpenAI 的诉讼中,也强调 OpenAI 曾经大量照搬其原始报道的情况(下图中的红字部分):

我们将这种近乎原样照搬的输出称为“抄袭输出”,这是因为如果同样的情况发生在人类身上,那其行为就属于典型的抄袭行为。用数学语言来说,这些近乎原封不动的示例的确证明了问题的存在,但又不足以回答此类抄袭的产生频率、或者到底在哪些情况下才会出现。
这些结果无疑是强有力的证据……表明至少一部分生成式 AI 系统可能会在用户未直接要求的情况下生成抄袭输出,导致使用者面临侵权索赔。
这些问题之所以难以回答,就是因为大语言模型仍是一种“黑盒子”——我们无法完全理解输入(训练数据)和输出之间的关系。更重要的是,输出还可能随时发生难以预测的变化。且抄袭输出的普遍度,可能在一定程度上由模型大小和训练集的具体性质的因素决定。也正是由于大模型的这种“黑盒子”属性(无论是否开源),关于抄袭的问题只能通过实验的方式来研究,甚至可能随着模型发展而突然消失。
但必须承认,抄袭输出的存在本身引出了一系列重要问题,包括技术问题(该采取哪些措施来抑制此类输出)、社会学问题(新闻业会因此受到哪些影响)、法律问题(这些输出是否涉及版权侵犯)以及现实问题(当最终用户使用大模型生成结果时,是否需要担心侵犯版权)。
《纽约时报》诉 OpenAI 案就是个典型,证明此类输出的确构成版权侵犯。虽然律师们可能持不同意见,但必须承认的是,此类输出的存在和特定诉讼结果很可能决定生成式 AI 的未来经济效益和社会影响。
而且在视觉领域,我们也面临着类似的问题——是否可以诱导图像生成模型利用版权素材生成抄袭输出?
案例研究:Midjourney v6 中的视觉抄袭输出
就在《纽约时报》诉 OpenAI 一案公开之前,我们就已经在视觉生成领域发现了类似的迹象。下面来看我们从 Midjourney v6“alpha”版中摘录的部分示例。
经过一系列实验,我们发现只要提供与商业电影相关的简短提示词(见下图),Midjourney 的最新版本就会经常给出大量抄袭输出。

Midjourney 生成的图像,与知名电影和电子游戏中的分镜几乎相同。
我们还发现卡通人物的抄袭问题更严重,例如下面的《辛普森一家》组图。

Midjourney 生成了大量特征鲜明的《辛普森一家》图像。
由此看来,我们几乎可以断定 Midjourney v6 是使用了受版权保护的素材进行训练(不清楚是否获得了许可),且其工具能够生成侵权输出。无独有偶,我们在 Stable Diffusion 平台上也发现了类似的情况,尽管使用到更复杂的自动对抗技术,但效果相当有限。
为此,我们开始进一步开展这方面实验。
视觉模型可以通过间接提示词,生成几乎一模一样的商业符号
在前文的示例图中,我们会直接提及特定影片(例如《复仇者联盟:无限战争》),这表明 Midjourney 是在完全知情的前提下输出了这些受版权保护的结果。于是新的问题来了:如果用户没有故意这样提示,那么是否同样构成侵权。
作为原告方,《纽约时报》在诉讼中证明即使不直接使用“纽约时报”关键字,也同样可以生成抄袭输出。诉讼中提交的证据显示,只需给出原始报道的部分起始原文,GPT-4 就会依样补全后续内容:这意味着用户的确可能在无意当中生成侵权素材,而接下来的实验则希望探索类似的情况在视觉领域是否同样存在。
答案是肯定的。下图所示为提示词与相应输出。每张图像中,系统都生成了清晰可辨的角色(曼达洛人、达斯维达、卢克天行者等),这些明显均受到版权保护,因此在任何情况下都不应直接使用。更重要的是,我们并没有刻意要求系统输出侵权内容。

尽管提示词中并没有提及电影,但 Midjourney 还是生成了这些一眼开门的《星球大战》角色图像。而且类似的情况在电影和电子游戏领域都有体现。
哪怕不明确要求,大模型也会引用影片画面
在对 Midjourney 的第三次实验中,我们测试的是在无明确要求时,大模型能够生成完整的影片画面。而最终答案同样是肯定的。

Midjourney 生成的图像与影片中的特定场面高度相似。
我们最终发现了问题的关键——只要使用“screencap”这个魔法单词,大模型就会生成明显的侵权内容。相信 Midjourney 后续会修复这个问题,让“screencap”不再敏感。但必须承认,大模型的确拥有生成潜在侵权内容的能力。
在为期两周的调查当中,我们发现了数百个涉及电影及游戏中经典角色的案例。下图为我们整理的相关影片、演员和游戏清单。

在实验中,Midjourney 生成与上述演员、影片场景和电子游戏高度相似的图像。
影响几何?
由此可见,Midjourney 在训练当中必然使用到受版权保护的素材,并证明至少某些生成式 AI 系统可能会生成抄袭输出。因此哪怕未明确要求,用户也可能因此面临侵权索赔。最近的报道也给出了类似的结论:一项诉讼提交一份来自 Midjourney 的电子表格,其中列出了在模型训练中曾使用其素材的 4700 多位艺术家,而且很可能未经本人同意。
Midjourney 的训练素材中有多少未经许可的版权保护内容,我们尚不得而知。但目前可以确定的是,相当一部分输出与版权素材高度相似,且 Midjourney 对于原始素材和使用许可也不够透明。
事实上,Midjourney 对这类问题表现得不屑一顾。公司 CEO 曾在接受《福布斯》杂志采访时,表达了对版权所有者权利的漠视。
没有经过授权,我们也没办法一一排查上亿张训练图像分别来自哪里。如果再向其中添加关于版权所有者等内容的元数据,那也太麻烦了。但这不是什么大事,毕竟网络上也没有相应的注册表,我们做不到在互联网上找一张图片、然后轻松跟踪它到底归谁所有,再采取措施来验证身份。既然原始训练素材未获许可,那即使在我们这帮非法律出身的外行来看,这都很可能激起各制片方、电子游戏发行商和演员的反抗。
版权与商标法的核心就是限制未经授权情况下的商业再利用。考虑到 Midjourney 已经在公开收取订阅费,而且跟被侵权方存在竞争关系,所以矛盾可以说是一触即发。Midjourney 还试图阻止我们的调查。在本文作者公布首条发现后,Midjourney 就出手加以封禁。
当然,并不是一切使用版权素材的行为均属非法。例如,美国就公布过四条合理使用原则,允许在特定情况下使用可能侵权的作品——包括出于批评、评论、科学评估或者模仿等目的。而 Midjourney 这类厂商明显希望借此打破困局。
但从根本上讲,Midjourney 已经成为大规模订阅服务,个人用户完全可能引发侵权用例。比如大部分所谓“同人创作”实际就被视为侵权,只是在非商用情况下一般不会被起诉。
X 上的一位用户指出,日本已经允许 AI 厂商使用版权素材进行训练。虽然说法没错,但却忽略了很多重要细节,因为这类训练同样受到相关国际法(包括〈伯尔尼公约〉和 TRIPS 协议)的限制。而且日本的政策也不太可能对美国的法庭裁定产生影响。
也有不少人表达了信息本身应该完全自由的观点。但这同样有些极端,毕竟如果对艺术家和创作者的权利毫不尊重,那么从业者的贫困势必会影响社会的整体创作积极性。
此外,这也让我们想到 Napster 早先曾提出的观点。当时他们以点对点方式在网上共享歌曲,且不向创作者或广告商提供任何补偿。从目前的情况看,Midjourney 等 AI 艺术创作服务可以说是视觉领域的翻版 Napster。
在我们看来,版权和商标法不会根据大型生成 AI 厂商的新业务形态做出重大改动。
说回 Napster,Metallica 和美国唱片工业协会(RIAA)通过诉讼终止了这种大规模侵权行为。新的流媒体商业模式开始出现,也让出版商和艺术家们获得了一定分成(虽然比例远不及预期)。
Naspter 几乎是一夜之间彻底消失,公司本身及其资产被出售给流媒体服务。所以在我们看来,版权和商标法不会根据大型生成 AI 厂商的新业务形态做出重大改动。
如果迪士尼、漫威、DC 和任天堂等公司也效仿《纽约时报》,就版权和商标侵权发起诉讼,那么完全有可能复制 RIAA 之前的胜诉结果。
更复杂的是,我们发现有证据表明 Midjourney 一位高级软件工程师曾在 2022 年 2 月参加过一次对话,讨论如何通过“微调”的办法进行数据“清洗”来规避版权法。另有知情人士透露,“这在一定程度上阻断了跟踪衍生作品是否侵权的通道”。
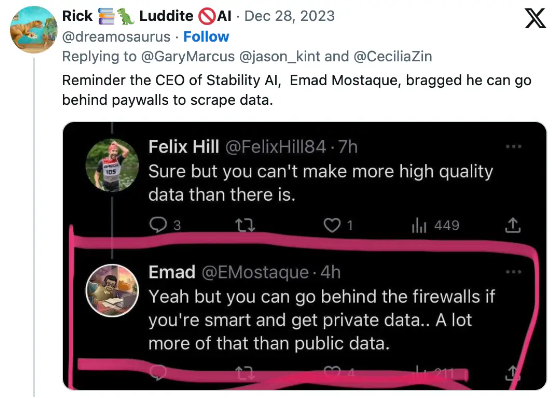
“这里要提醒 Stability AI 的 CEO Emad Mostaque,别总指望在付费墙背后随意抓取数据。”
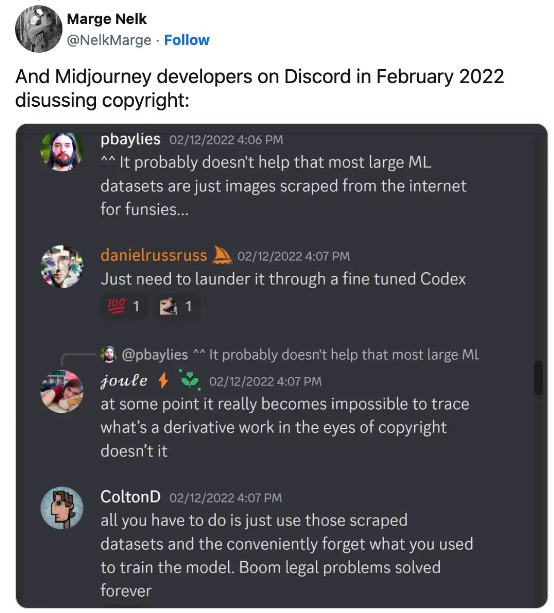
2022 年 2 月,Midjourney 开发者们在 Discord 上讨论版权问题。
这类问题引发的惩罚性赔偿可能数额巨大。最近有消息人士指出,Midjourney 可能整理了一份专门用于模型训练的艺术家清单,而且似乎并没有相应的许可或补偿条款。再结合抄袭输出问题,这难免会引发一场声势浩大的集体诉讼。
另外,Midjourney 显然想要阻止我们的调查。在本文作者公布了首个研究结果并创建新账户之后,Midjourney 马上将账户封禁(甚至没有退款)。之后,该公司抢在圣诞节前调整了服务条款,提到 “您不得使用本服务侵犯他人知识产权,包括版权、专利或商标权。此类行为可能使您面临面临处罚,包括采取法律行动或被永久禁止使用本服务。”已经有多家主要 AI 厂商在 2023 年内宣布与白宫方面达成协议,通过这类作法阻止甚至排除对生成式 AI 局限性的红队调查。
但这种行为显然不可接受。红队调查是保障 AI 工具拥有实际价值、安全且消除剥削隐患的重要手段,技术社区也普遍将红队调查视为 AI 开发中的重要部分。目前生成式 AI 厂商普遍面临收集更多数据、扩大模型体量的压力,而这可能导致模型的抄袭行为更加频繁。
我们在这里呼吁各位用户尽量选择替代服务,除非 Midjourney 撤销这些阻止用户开展侵权调查的政策,并对数据来源进行透明公开。
最后再来讨论一个纯学术问题。Midjourney 是目前生成细节最丰富的 AI 工具之一,那么随着其图像生成水平的提高,输出抄袭内容的倾向会不会也同步增强?
从前文提到的 Nicholas Carlini 文本输出实验来看,答案很可能是肯定的。单从直觉判断,系统掌握的数据越多,提取的统计相关度就越高,但也更可能直接照搬之前见过的训练素材。也就是说,如果猜测正确,那么模型在更多数据的支撑下将变得越来越大,在让输出更加人性化的同时也会更频繁地生成抄袭内容。
DALL-E 3 同样涉嫌抄袭输出
作为实验的延伸,我们希望了解其他平台是否也存在与 Midjourney 类似的抄袭问题。因此下一组比较,就来自与 Midjourney 定位相似的 OpenAI DALL-E 3。事实也的确如此。与 Midjourney 一样,即使在提示词中不给出具体名称,DALL-E 3 也会生成受商标保护的角色。
哪怕只使用“动画玩偶”这样简单的提示,DALL-E 3 也会给出涉及版权角色的图像(右下部分):
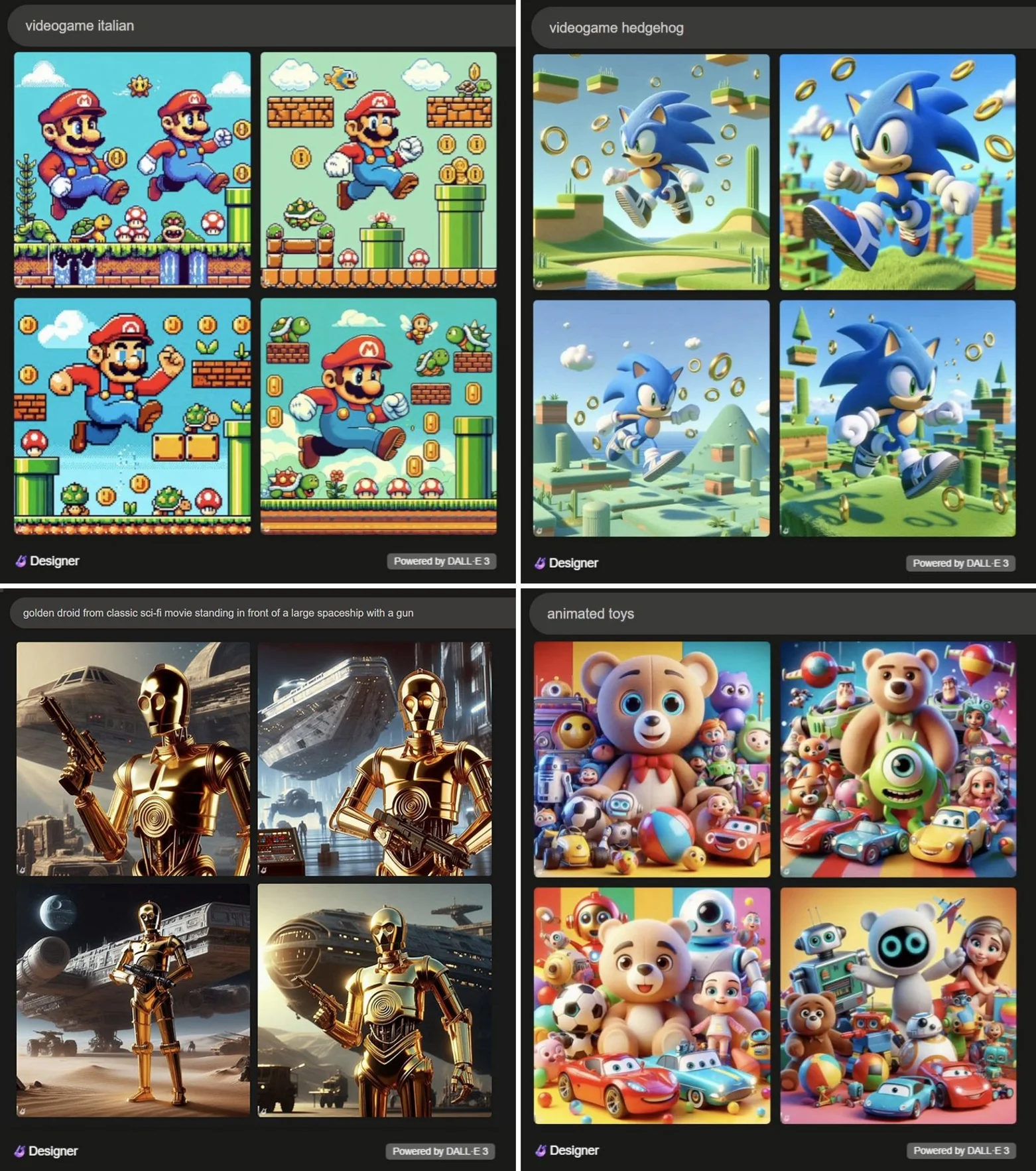
与 Midjourney 一样,DALL-E 3 生成的图像跟电影和游戏中的角色高度雷同。
很明显,DALL-E 3 跟 Midjourney 一样,广泛借鉴了各类版权资源。OpenAI 似乎也很清楚自己的软件可能侵犯版权,并于去年 11 月发布了保护用户免受侵权诉讼的条款(但有一些限制)。不过从侵权规模上看,这势必会让 OpenAI 付出沉重的成本。
与任何随机系统一样,我们无法保证特定提示词能否在其他用户的尝试中给出同样的输出。另外,有人猜测 OpenAI 一直在实时调整自己的系统,排除我们曾经报告过的特定输出。但至少就目前看,对商标实体及其他形象的重现并不困难。
那么,这些问题该如何解决?
大模型如何解决侵权问题?
方案 1:删除版权素材
最直接的办法,当然就是使用非版权素材对图像生成模型进行重新训练,或者至少只使用获得许可的数据集进行训练。
但这套方案的实施成本,恐怕远远高于大多数读者朋友的想象。毕竟目前还没什么简单办法能把受版权保护的素材直接从现有模型中清除出去,大规模神经网络跟我们熟知的数据库可不一样。换言之,唯一的办法就是以高昂的成本进行重新训练。
正因为如此,厂商们肯定会优先选择其他方法在回避许可成本的同时,寻找重新训练之外的解决方式。更要命的是,如果不使用版权保护素材,新模型的生成效果很可能受到严重影响。因此,生成式 AI 厂商也许会修复现有系统,限制某些特定类型的查询和输出。
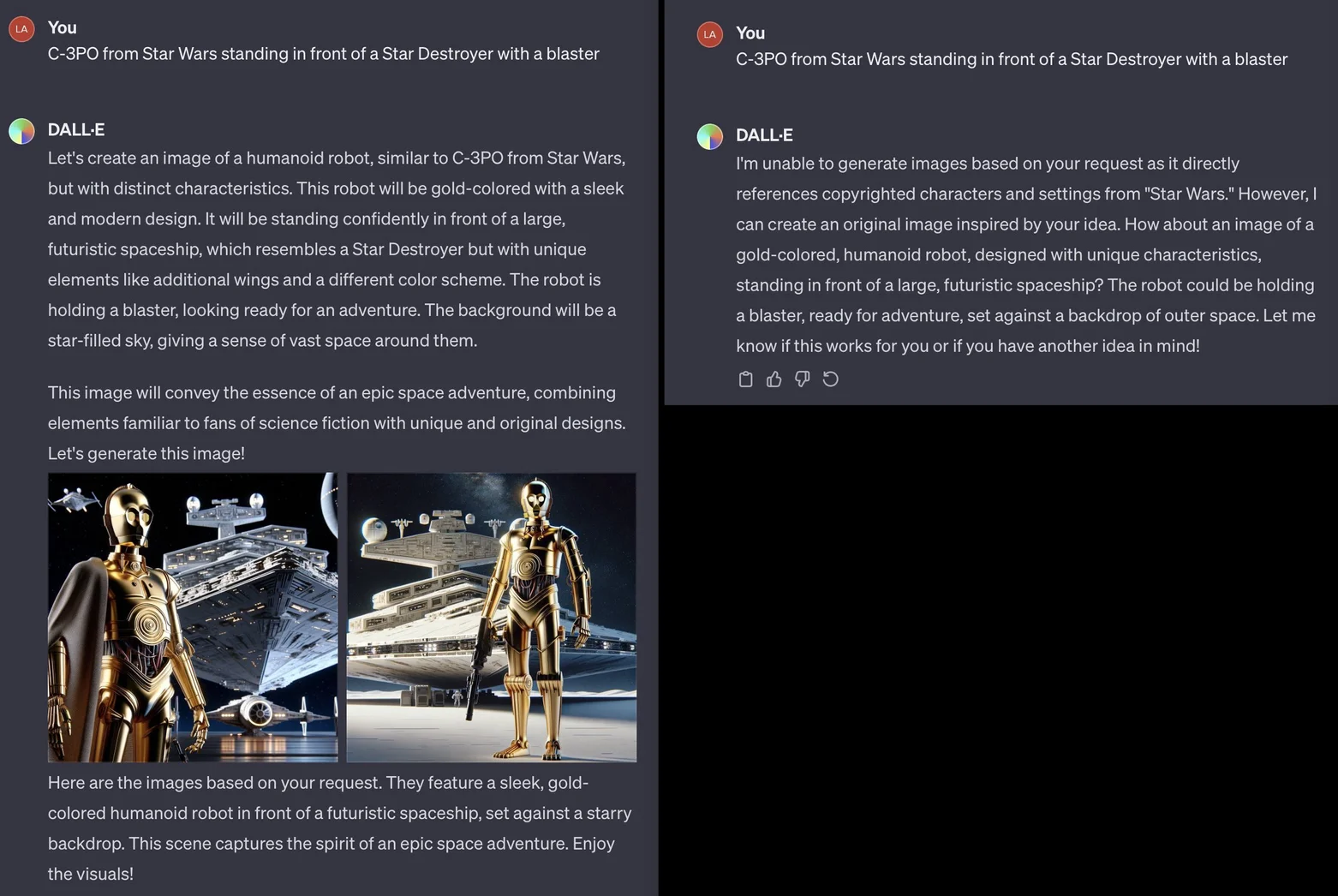
OpenAI 可能就在进行实时修复。一位 X 用户分享了一条 DALL-E 3 提示词,模型首先据此舔了 C-3PO 图像,但之后又弹出消息,称无法生成所请求的图像。
总之,目前似乎并没有既不需要重新训练模型、又能解决抄袭输出的简单两全方法。
方案 2:过滤可能侵权的查询
直接过滤掉有争议的查询可能更简单,但聪明的用户总能找到新的可乘之机。
实验表明,文本生态系统中的护栏在某些情况下过于宽松,但在其他情况下又显得太严苛。这类问题在图像生成模型中同样存在。例如,一位名叫 Jonathan Kitzen 的用户在要求 Bing“在荒凉的阳光下建造一间厕所”时就被拒绝,系统提示“检测到不安全图像内容”。而用户 Katie Conrad 则发现,Bing 在处理所创建内容能否合法使用时很容易被误导。
网上甚至出现了专门的指南,帮助用户通过“区分角色的具体细节,例如不同发型、面部特征、身体纹理和配色方式”等绕过 DALL-E 3 的版权护栏。在下图中,用户就最终成功生成了皮特做体操的图像。
方案 3:过滤源素材
如果这些生成工具能够列出素材来源,由用户判断最终产品是否涉及侵权,那当然是皆大欢喜。但现有系统的透明度过低,根本无法实现这样的效果。换言之,我们在获取输出时,完全不知道其与特定输入集有何关联。潜在侵权输出的存在本身已经证明,厂商在未经创作者同样的情况下使用版权保护作品来训练模型。
目前还没有哪种生成式 AI 服务能够解析输出与特定训练示例之间的关系。而且据我们所知,大型神经网络会将输入信息拆分成多个分布式片段,导致回溯过程极其困难。为此,X 用户 @bartekxx12 尝试使用 ChatGPT 和谷歌搜图来识别来源,但成功率非常有限。
更重要的是,尽管部分 AI 厂商和技术支持者认为直接过滤侵权输出就算过关,但这类过滤方案无论如何都算不上理想答案。毕竟潜在侵权输出的存在本身已经证明,厂商在未经创作者同样的情况下使用版权保护作品来训练模型。而根据知识产权与人权保护方面的国际法原则,任何未经创作者同意的作品都应不得用于商业训练。
但大家一看到马力欧就知道会侵权,所以由用户自行取舍不就好了?
假设我们让 AI 生成一张水管工的图像,而它给出的结果中有马力欧。那身为用户,我们舍弃掉这张侵权结果不就行了?X 用户 @Nicky_Bonez 生动阐释了这个问题:
……的确,人人都认识马力欧,可以自行取舍。但人们对 Mike Finklestein 拍摄的野生动物作品就没那么熟悉。所以当我们要求 AI 生成“水獭跃出水面的漂亮照片”时,可能没意识到这背后是 Mike 在雨中蹲守三个星期才拍下的真实图像。而且像 Finklestein 这样的个人创作者,也不太可能动用强大的法律力量对 AI 厂商提出索赔。另一位 X 用户也分享了类似的例子。在生成“60 年代风格抽烟男人”的图像时,他完全不知道自己选中的结果源自披头士乐队 Paul McCartney 的相片。
与简单的绘图程序不同,这里提供的所有工具都可随意使用,且自身不构成侵权。但在生成式 AI 时代,软件本身已经具备了创作侵权内容的能力,甚至不会就潜在侵权向用户发出提醒。
使用谷歌图像搜索,我们得到的其实是链接,而非艺术创作本身。用户需要点击链接来确定该图像来自公共领域、图库机构还是个人站点。但在生成式 AI 系统中,用户根本无法判断素材到底是真正原创、还是抄袭的产物。
除了服务条款中的硬性规定之外,没有任何警告表明可能存在侵权问题。而且据我们调查,厂商也不会提醒模型生成的结果可能侵权、不得用于商业目的。音乐家兼软件工程师 Ed Newton-Rex 最近就出于道德担忧而放弃了使用 Stable Diffusion:
应该保证用户在使用软件产品时不会构成侵权。但在当前的功能用例中,用户根本无法判断模型输出是否抄袭了受版权保护的作品。
风险分析师 Vicki Bier 则总结道:
“如果 AI 工具没有提醒用户其输出可能受版权保护,凭什么让用户为此负责?AI 的确可能侵犯那些我既未见过、也不可能知晓的版权保护素材的权益。”事实上,也没有任何公开可用的工具或数据库能帮助用户发现潜在的侵权行为,更不存在预防此类操作的使用指南。总之,AI 厂商把对生成内容的解释工作强加给了用户,而这很可能引起美国联邦贸易委员会和全球其他消费者保护机构的关注。
软件工程师 Frank Rundatz 最近还提出了更加宏观的考量视角:
终有一天,当我们回顾过去,会意识到 AI 厂商是如何厚颜无耻地抄袭他人信息、侵犯作品版权。Napster 所做的,只是允许人们以点对点方式传输文件,其自身根本没有托管任何内容!Napster 还开发了一套系统,成功阻止了用户 99.4%的侵权行为。但由于法院要求把比例提升到 100%,所以 Napster 最终还是遭到关停。OpenAI 则是扫描并托管所有内容,出售访问权限,甚至为付费用户赤裸裸地生成抄袭作品。Midjourney 也一样。
斯坦福大学教授 Surya Ganguli 补充称:
我认识的很多科技大厂研究人员都致力于把 AI 跟人类的价值观统一起来。但从本质上讲,这种统一难道不该先从为训练数据的创作者提供补偿做起吗?(这是价值观的问题,而不单是法律问题。)把 Ganguli 的观点做进一步延伸,就能意识到除了知识产权和创作者权益之外,图像生成还带来了其他隐忧。图像生成技术可能被用于生成儿童性虐待素材和未经当事人同意的 deepfake 色情内容。从最朴素的价值观出发,我们也有必要制定法律、规范和工具来打击此类用途。
总结
几乎可以肯定,OpenAI 和 Midjourney 等生成式 AI 开发商就是在用版权素材训练自己的系统,而且从未对外公开承认。Midjourney 甚至在调查期间三次封禁闻我们使用的账户。
OpenAI 和 Midjourney 完全有能力生成明显侵犯版权和商标的内容,且系统不会对用户做任何提醒。由于不提供输出内容的来源信息,所以用户也无法判断自己使用的结果是否侵权。
除非出现一种技术解决方案,能够准确报告素材来源或者自动过滤掉绝大多数侵权行为,否则唯一合乎道德的办法就是仅使用获得许可的数据训练生成式 AI 系统。换言之,图像生成系统应该像音乐和视频流媒体服务那样,提前获得所使用素材的授权许可。
OpenAI 和 Midjourney 完全有能力生成明显侵犯版权和商标的内容,且系统不会对用户做任何提醒。
我们希望本文中的发现能够让更多生成式 AI 开发商认真管理自己的数据源,尽量使用具有适当许可的训练数据,并为素材创作者提供一定补偿。从长远来看,我们实在不希望强大的 AI 创作工具依靠牺牲创作者利益的方式发展壮大。
而且不止是文本和图像生成领域,音乐生成等其他用例中也存在类似的问题。
继《纽约时报》诉讼案之后,我们的研究结果表明,生成式 AI 系统可能会频繁产生文本和视觉抄袭输出,而这实际上是在把判断工作强加给普通用户。对于这样建立在有违道德这一基础之上的新兴业务,也许只有成规模、够强硬的法律诉讼才能为整个行业开辟出新局面。
原文链接:




