
2019 年,据美联社报道,一名间谍利用 AI 生成的个人资料和图片,在全球知名的职场社交平台 LinkedIn 上欺骗联系人,包括政治专家和政府内部人员[1][2]。

这位 30 多岁的女性名叫凯蒂•琼斯,拥有一份顶级智库的工作,虽然她的关系网规模不大,只有 52 个联系人,但却都有着举足轻重的影响力,比如:一位副助理国务卿、一位参议员的高级助理、以及正在考虑谋求美联储一席之地的经济学家保罗•温弗里。
然而,经过许多相关人员和专家的调查采访,美联社证实了凯蒂•琼斯其实并不存在,她的人脸照片似乎是由一种典型的 GAN 技术生成的,这个角色只是潜伏在 LinkedIn 上的众多幻影资料之一,其目的极有可能是从事间谍活动。
这则报道让人们意识到,进入人工智能时代,影像篡改技术又发生了革命性的变化,而滥用这种 AI 伪造技术带来的安全问题更是与日俱增,甚至严重威胁到国家和社会的安定。今天我们就来说说这种神秘的 GAN 技术。
人工智能时代的 GAN 技术是指什么?
GAN,全称是生成式对抗网络 Generative Adversarial Network,它是一种 AI 深度学习模型,而关于 GAN 的诞生不承想竟然是一次“酒后的意外”[3][4]?
2014 年,当时“GAN 之父”Goodfellow 还在蒙特利尔大学读博士,一天晚上他与几个朋友在一家名为“三个酿酒师”的酒吧里给师兄庆祝博士毕业。
一群技术工程师们边喝酒边聊天,聊到了如何让计算机自动生成照片这个问题。Goodfellow 的朋友们提出了一个想法,将照片中的所有构成元素全部输入到计算机进行统计分析,以便让它能够自己生成照片。然而,Goodfellow 却认为这个想法是不太现实的,需要考虑的数学统计量实在太多。突然他灵光一闪:是否可以让一个神经网络来“监督指导”另一个神经网络生成照片呢?不过这个大胆的想法却让朋友们一致产生了怀疑。
酒后回到家,Goodfellow 连夜编写了程序来验证这个“不切实际”的想法,谁也不会想到竟然第一次测试就取得了成功。那一夜 Goodfellow 难以入眠,因为他所创造出来的东西就是如今大名鼎鼎的 GAN 技术。
那么,GAN 技术究竟是指什么呢?先举一个“印假钞者与警察”的例子[5]:
印假钞者通过参考真实钞票的样子来印制假钞,而警察需要辨别拿到的钞票是真是假;
起初,印假钞者的能力不足,印制的假钞很容易被警察识别,所以印假钞者就不断提升自己的造假能力;
同时,警察在辨别过程中也在不断积累经验,提升自己的假钞识别能力,这就形成了一个相互对抗的过程;
直到最后,印假钞者可以印制出完美的假钞,而警察再也无力区分它的真假。
实际上,GAN 技术的思想与这个例子是异曲同工的。
GAN 本身包含两个神经网络,一个是生成器(同印假钞者)用来从一个随机噪声生成一张照片;另一个是判别器(同警察)用来辨别生成照片和真实照片的真假。下面三张图很好的诠释了 GAN 网络的迭代训练过程[6]:
训练初期,Generator 生成器造出来的图像与真实图像 Real Data 相差很大,Discriminator 判别器很容易区分;
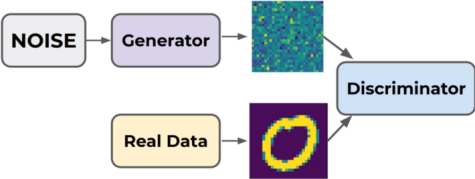
训练中期,Generator 生成器迭代更新,已经可以造出内容接近的图像,而 Discriminator 判别器的识别困难度也在不断增加;
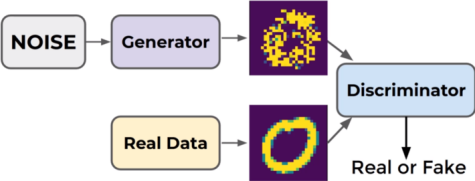
训练后期,Generator 生成器已经可以造出非常逼真的图像,而 Discriminator 判别器再难以区分真假,只能随机猜测,即 0.5 概率认为是真,0.5 概率认为是假。
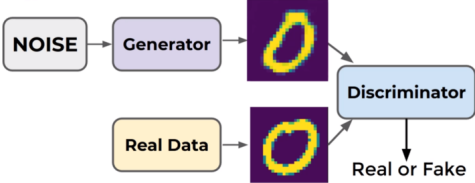
是的,当 GAN 网络训练收敛后的 Generator 生成器,就是所谓人工智能时代的一件影像篡改利器。当然,随着前几年 GAN 技术的火热,许多专家和学者都投入到了 GAN 的技术研究上来,如今 GAN 家族早已是“人丁兴旺”。
影像篡改的 AI 工具箱
继 Goodfellow 以后,GAN 技术并没有就此停下脚步,而是逐渐衍生出至少上百种模型,它们都可以轻易实现影像篡改处理,比如:CGAN、DCGAN、WGAN、CycleGAN、PGGAN、StarGAN、SAGAN、BigGAN、StyleGAN……
这些 AI 模型在生成虚假图片上,都不同程度地提升了人眼视觉质量以及模型鲁棒性,下面介绍三种比较流行的 GAN 模型。
(1)CycleGAN 模型
CycleGAN[7]是 2017 年伯克利 AI 研究室提出来的一种用于图像风格迁移的 GAN 模型。
什么是“图像风格迁移”呢?
简单理解就是,将一幅图像从一种风格变换成另一种风格,比如:水墨风格变成油画风格、雨天场景变成雪天场景、航拍照片变成谷歌地图等等。

上图展示了三组图像风格迁移示例,左边是莫奈油画和实景照片之间的转换,中间是斑马和普通马之间的转换,右边是夏天景色和冬天景色之间的转换。
那么,CycleGAN 是怎么做到的呢?
实际上,它包含两组风格映射关系,生成器 G 将 X 变换成 Y,生成器 F 将 Y 变换成 X,而判别器 DY 用来约束 Y 的生成质量,判别器 DX 用来约束 X 的生成质量。
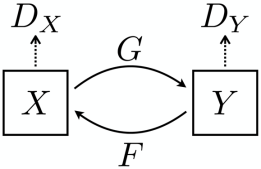
当然,为了保证图像风格迁移的质量,其实还引入了一种循环一致性约束。要怎么理解循环一致性呢?顾名思义,就是指经过一次循环变换仍保持图像内容的一致性,比如:图像 X 先经过生成器 G 变换为图像 Y,然后这个 Y 再经过生成器 F 变换为新 X,经历了一次完整的循环,这两个图像 X 应该尽可能保持一致才对。
我们可以看到,CycleGAN 比 Goodfellow 最初的 GAN 模型要复杂了一些,需要使用两组生成器和判别器一起协同工作。不过,它的虚假照片生成质量也是有目共睹的,而且在实际应用上也要更加广泛一些。
(2)PGGAN 模型
PGGAN[8]是 2017 年英伟达公司提出的一种渐进式训练 GAN 的模型。
或许你已经略微感觉到 GAN 有一丢丢复杂,嗯……可以理解,GAN 网络的训练过程是比较麻烦的,尤其是在训练一些大型复杂的图像时会比较容易崩掉。而 PGGAN 通过一种渐进式的训练方式可以很好地解决这个
问题,它是怎么做的呢?
我们不要一上来就直接“学习”复杂的高清图像,而应该从低清开始,学好了之后再逐步提升图像的分辨率,比如:4x4 到 8x8,……,最后到 1024x1024。
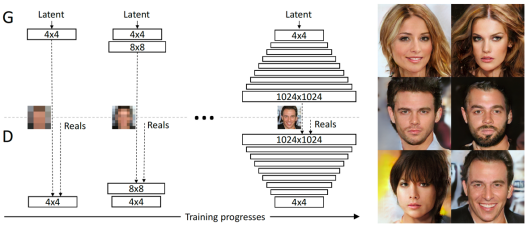
上图展示了从左到右渐进式地提升训练图像的分辨率和网络的层规模,可以看到,刚开始学习的 4x4 图像比较模糊,随后会逐步变得清晰起来。
当然,PGGAN 有了这种相对稳定的训练方式,自然会在一定程度上提升 GAN 网络生成虚假图像的视觉质量。
(3)StyleGAN 模型
StyleGAN[9]是 2018 年英伟达公司提出的一种风格迁移 GAN 模型,它号称可以自动学习对图像高级语义特征的解耦分离[10]。该怎么理解高级语义特征的解耦分离呢?
以一张人脸图片为例,如人脸的姿势、身份以及发型、发色、斑痕、皱纹、胡须等众多高级语义特征在一定程度上其实都是可以分别控制生成的。“解耦分离”这一点对于提升图像生成的多样性以及人们对“黑盒”神经网络的理解都有着重要的意义。
StyleGAN 是如何做到这一点的呢?
利用一个映射网络提前学习一种 style A 特征,分别输入到生成器的不同尺度层,A 可以用来控制生成风格的全局属性,如人脸的姿势、身份等;
通过高斯噪声获取一种 style B 特征,也分别输入到生成器的不同尺度层,B 可以用来控制一些次要的随机变化,如发型、发色、斑痕、皱纹、胡须等。
我们能够看出,StyleGAN 与以往 GAN 模型单一输入的生成器结构是不同的,它在生成器中引入了不同风格变量的输入,可以较好的控制不同的高级语义特征。当然,StyleGAN 生成的图片质量也有了更进一步的提升。

上图展示了一组风格混合的人脸生成效果,左边一列表示源 A 图片,上边一行表示源 B 图片,其余都是对应 A 与 B 图片的混合。可以发现,控制风格混合能够让生成人脸与源人脸具有一些的相似特征。

上图展示了通过控制输入噪声强度,在头发、轮廓和部分背景上能够产生不同的随机变化。左边是 StyleGAN 生成图片,中间是不同噪声输入在头发位置的局部放大图片,右边是利用超过 100 次的图像像素计算得到的标准偏差图,高亮部分指出了受噪声影响的位置。
3. GAN 技术也有积极的一面
庞大的 GAN 家族见证了 AI 生成虚假图片的发展,同样也加速了这些虚假图片的传播。或许曾经你也见到过许多利用 GAN 生成图片从事不道德活动的事件,不过,GAN 其实也是有它积极的一面的。
数据增强
众所周知,AI 技术是建立在大量数据之上的,比如:图像分类、目标检测、语义分割等,它们都需要庞大的数据来帮助 AI 模型进行充分地学习。
但是,在一些特定问题上搜集数据可能是比较困难的,那么,此时 GAN 技术就可以派上用场,通过现有的数据训练 GAN 模型,从而泛化生成更多的新数据。
影视创作
一部好的电影通常需要的制作成本和时间周期非常大,比如:从撰写剧本到布设场景,再到演员拍摄以及后期剪辑等等。
实际上,前期 GAN 技术就可以根据剧本里的文字描述进行学习并快速生成逼真影像,高效地创作出电影脚本,避免一些不必要的投入或者浪费[11]。下图展示了一幅 Google 在 2021 年提出的用于文本到图像转换的 XMC-GAN 模型效果[12]。

当然,在电影宣传方面,IBM 也在尝试利用以 GAN 为主的 AI 技术,识别电影台词和场景内容,通过快速生成电影宣传片来压缩所需的时间成本。
图像修复
通常在生活中,人们都会遇到一些因年深日久或无意破坏造成的照片残破、难以辨认的情况,以前只能寄希望于专家的修复工作。
现在,利用 GAN 技术也能快速的还原照片损毁的部分内容,下图展示了一幅 2019 年提出的 EdgeConnect 图像修复效果[13],有趣的是它利用两个生成器和两个判别器实现了“先画轮廓,再涂色”的新颖思路。

上图中包含 6 组损毁照片的修复效果,每组照片从左到右依次是原始图片、损毁图片、绘制轮廓图片、修复图片。
事实上,GAN 技术能够创造的价值远远不止这些,比如还可以用于 AI 游戏设计等更多充满想象力的领域。
篡改识别是需要人工智能的
GAN 生成的虚假影像有这么多的积极用途,但是总觉得似乎都难以盖过恶意篡改的风头,比如人脸伪造。也许是人们在这方面的关注更多一些,或者说是恶意篡改影像通常带来的危害过于严重吧。
那么,在人工智能时代有没有一些有效的篡改检测方法呢?
答案自然是肯定的,影像篡改识别需要强大的 AI 技术,而基于深度学习的神经网络正是解决这类图像篡改问题的一把好手。
首先,要怎么解释基于深度学习的神经网络呢?
假设有一个数学运算:y = k * x + b,其中 x 表示输入值,y 表示输出值,k 和 b 表示已知参数,当输入一个 x 值就能计算出一个 y 值。
而神经网络可以简单理解为:由无数个这样的计算组成的复杂计算结构,输入一个 x 值计算出一个 y 值,这个 y 值再作为另一个计算的输入,得出下一个输出……
至于深度学习,可以理解为:对一个有着足够“深”层次的计算结构进行训练学习,比如:
y = k * x + b,此时 k 和 b 都是未知参数,那么就需要搜集一组已知的[x, y]作为训练数据,带入计算式中“拟合”出 k 和 b 的数值,这就是所谓的学习过程。
当然,在影像篡改识别问题上,输入 x 通常指的是一张图片或一个图像块,而乘加运算指的可能是一种卷积运算,k 和 b 是训练好的模型参数,输出 y 指的是问题的结果,如图像的真假标志或者篡改的具体位置等。
解释了这么多,再来看看真实的例子。现如今,基于深度学习的影像篡改识别方法已经非常多了,下面介绍其中三种比较常见的 AI 方法。
(1)U-Net 模型
U-Net[14]是 2015 年德国弗莱堡大学的生物信号研究中心提出来的,之所以叫“U-Net”,是因为它的网络结构酷似 U 型。它最初是一种用于医学图像分割的卷积神经网络模型,不过在影像篡改识别问题上,这个网络也同样适用。
为什么说 U-Net 模型适用呢?
U-Net 是通过 U 型网络将医学 RGB 图片直接学习到二值分割图片的,当然,所谓的“分割特征”是根据网络中一系列的卷积运算自动学习的。
要是我们能够搜集一些篡改 RGB 图片作为训练数据“x”,然后人工标注篡改位置得到二值图片作为训练数据“y”,那么,是不是也可以让 U-Net 网络来集中精力学习图片篡改区域和真实区域之间的差别,进而训练出网络的模型参数“k”和“b”。

上图展示一组训练数据[x, y],左边是湖中复制粘贴两条小船的篡改图片“x”,右边是人工标注篡改位置的二值图片“y”,这个标签 y 是为了告诉模型篡改的位置在哪里。
那么,U-Net 网络要怎么做呢?
利用 U 型结构前半部分的卷积和下采样操作,逐层收缩图像数据的分辨率,提取有效的分割特征;
利用 U 型结构后半部分的卷积和上采样操作,逐层恢复图像数据的分辨率,实现篡改位置的定位。
U-Net 模型其实也相当于一种 Encoder-Decoder 结构,先对图像数据进行编码提取特征,然后再进行解码生成定位数据。
当 U-Net 网络经过大量的训练数据[x, y]学习后,模型就可以有效地区分出图像中正常区域与篡改区域的像素差异,而之后就算再给它输入一张从未见过的篡改图片,它也能准确地将篡改位置定位识别出来。
(2)双流网络模型
双流网络[15]是 2017 年马里兰大学帕克分校提出的一种人脸篡改检测模型。
它的设计思想非常简单,为避免专注于一种特定的鉴别特征,而使用了包含两个分支的神经网络,分别提取不同的篡改痕迹。这就好比人们想要确定一朵花,光描述它的形状或许是不够的,如果再加上颜色信息或者生长环境特点呢?会不会更准确些?
这个双流网络的结构具体是怎么设计的[16]呢?
人脸分类流,使用了一个成熟的 GoogleNet,通过真实的和篡改的人脸图片训练一个二分类器(真或假),可以捕捉一些如人脸轮廓、五官上的高级篡改痕迹;
块级 Triplet 流,训练了一个 Triplet 网络,试图捕捉一些低级隐藏特征,比如:CFA 模式、局部噪声残差等相机特征;
双流融合,将高级语义特征与低级噪声特征融合起来,可以有效地提升检测性能。
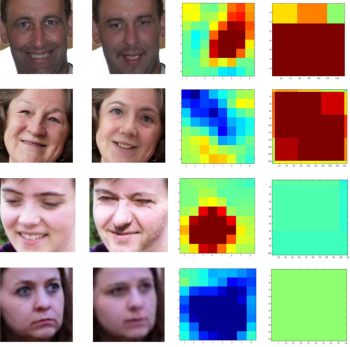
上图展示了双流网络的效果,第一列为真实人脸,第二列为篡改人脸,第三列为人脸分类流的输出特征,第四列为块级 Triplet 流的 SVM 分类得分,而右边两列中的红色表示篡改概率较强、蓝色表示篡改概率较弱。
图中可以看出,捕捉到的两种不同特征都可以在一定程度上记录篡改痕迹,哪怕有一种特征失败(第四列下面两个低级特征),另一种特征也是能够起到作用的。
(3)视频帧间光流模型
视频帧间光流模型[17]是 2019 年意大利佛罗伦萨大学 MICC 与帕尔马 CNIT 联合提出的一种用于视频篡改检测的模型。
众所周知,一个视频通常包含大量的图像帧(以一个 10s 视频为例,每秒 30 帧就会有 300 帧图像),而这些图像帧之间一般都具有高度相关性,比如:帧间内容的相似性、运动物体的连续性等。
那什么是视频帧间光流呢?
当人们观察空间物体时,物体的运动景象会在人眼的视网膜上形成一连串连续变化的影像,这些影像不断“流过”视网膜,就像是一种光的“流”,所以称作光流[18]。
而光流一般是指空间运动物体在观察成像平面上的像素运动的瞬时速度,它是由于空间物体本身的移动或相机的运动产生的。
对于视频帧间光流,可以简单理解为:在一个视频中,三维空间物体的运动会体现在二维图像帧上产生的一个位置变化,当运动间隔极小时,这种位置变化可以被视为一种描述运动物体瞬时速度的二维矢量。

上图左边展示了一个人说话的视频帧,说话引起嘴巴的运动会在局部产生光流变化,而右边是一个篡改视频的图像帧,可以看出,篡改并不具备这种光流变化特征。
当然,这种反映物体运动瞬时速度的光流,是可以根据视频中连续帧产生的位置变化以及图像帧的时间间隔估计出来的。实际上,这个视频帧间光流模型就是一种帧间光流结合 CNN 进行视频篡改识别的方法。

正如上图 Optical flow,模型先利用颜色编码方法[19]将光流转换成包含 3 个通道的图像数据,其中,像素的颜色由光流矢量方向与水平轴的夹角决定,而颜色的饱和度由运动强度决定。最后,光流特征会基于 CNN 实现篡改检测识别。
结束语
人工智能时代,是一个影像篡改识别技术革新的时代。
在篡改伪造方面,除了独占鳌头的 GAN 技术以外,实际上还有一些如变分编码器 VAE(Variational Auto-Encoder)等方法,都能产生以假乱真的影像效果。若这些篡改技术被恶意利用的话,将不由得令人生畏。
相比以前的检测识别,这个时代的特征提取在一定程度上解放了人工是一大进步(由神经网络代劳),但是从解决问题方面来讲仍然尚显不足,如何进一步有效鉴别虚假影像,估计还会在很长一段时间内给人们带来严峻的挑战。
参考文献
[1]https://apnews.com/article/ap-top-news-artificial-intelligence-social-platforms-think-tanks politics-bc2f19097a4c4fffaa00de6770b8a60d
[2] https://zhuanlan.zhihu.com/p/69124138
[3] https://www.sohu.com/a/133490643_308467
[4] https://baijiahao.baidu.com/s?id=1615737087826316102&wfr=spider&for=pc
[5] https://blog.csdn.net/hello_next_day/article/details/96970888
[7] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired Image-to-image Translation Using Cycle-consistent Adversarial Networks. In Proc. of ICCV 2017.
[8] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. CoRR, abs/1710.10196, 2017.
[9] T. Karras, S. Laine, and T. Aila. A Style-based Generator Architecture for Generative Adversarial Networks. In Proc. of CVPR 2018.
[10] https://zhuanlan.zhihu.com/p/353858823
[11] http://www.woshipm.com/ai/1949179.html
[12] H. Zhang, J. Koh, J. Baldridge, H. Lee, and Y. Yang, “Cross-Modal Contrastive learning for Text-to-Image Generation”. Arxiv: 2101.04702v4. 2021.
[13] K. Nazeri, E. Ng, T. Joseph, F. Qureshi, and M. Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning”. Arxiv: 1901.00212v3. 2019.
[14] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]. International Conference on Medical Image Computing & Computer-assisted Intervention. IEEE, 2015:234-241.
[15] P. Zhou, X. Han, V. Morariu, and L. Davis, “Two-stream neural networks for tampered face. detection,” in IEEE Computer Vision and Pattern Recognition Workshops, 2017.
[16] https://zhuanlan.zhihu.com/p/92474937
[17] Amerini I, Galteri L, Caldelli R, Bimbo A D. Deepfake Video Detection through Optical Flow based CNN[C]. Proceedings of the IEEE International Conference on Computer Vision Workshops. 2019.
[18] https://blog.csdn.net/qq_41368247/article/details/82562165




