
WeLM 能够在零/少样本的情境下完成多种 NLP 任务,现已部署应用于微信视频号
大规模语言模型领域迎来新“选手”。近日,微信 AI 推出自研 NLP 大规模语言模型 WeLM ,该模型是一个尺寸合理的中文模型,能够在零样本以及少样本的情境下完成包多语言任务在内的多种 NLP 任务。
同时,微信 AI 团队也提供了 WeLM 的体验网页和 API 接口。感兴趣的用户可前往https://welm.weixin.qq.com/docs/体验和申请API接口。相关技术论文《WeLM: A Well-Read Pre-trained Language Model for Chinese》也已经发布于论文预印本网站 arXiv。
WeLM 提供交互式网页 PlayGround 和 API 接口
在近几年自然语言处理(NLP)领域的发展浪潮中,OpenAI 开发的自然语言处理模型 GPT-3 无疑风头无两,发布之初便以 1750 亿参数规模的预训练模型所表现出来的零样本与小样本学习能力刷新了人们的认知,也引爆了 AI 大模型研究的热潮。
对业界来说,预训练大模型降低了 AI 应用的门槛,距离“AI 把人类从重复性劳动中解放出来”的目标越来越近,目前,基于 GPT-3,全球开发者已经探索出包括编程、回复邮件、UI 设计、回答数学问题、法律语言转化、总结中心思想、推理、文本处理等广泛应用场景,并且,各国研究者在多语言/多任务等角度的探索也正在呈现出大模型百家争鸣的格局。
在国内以中文为核心的大规模语言模型领域,微信 AI 推出的百亿级别大规模语言模型 WeLM,成为大模型百家争鸣格局中的新选手。
据介绍,WeLM 是一个百亿级别的中文模型,能够在零样本以及少样本的情境下完成包括对话-采访、阅读理解、翻译、改写、续写、多语言阅读理解在内的多种 NLP 任务,并具备记忆能力、自我纠正和检查能力。
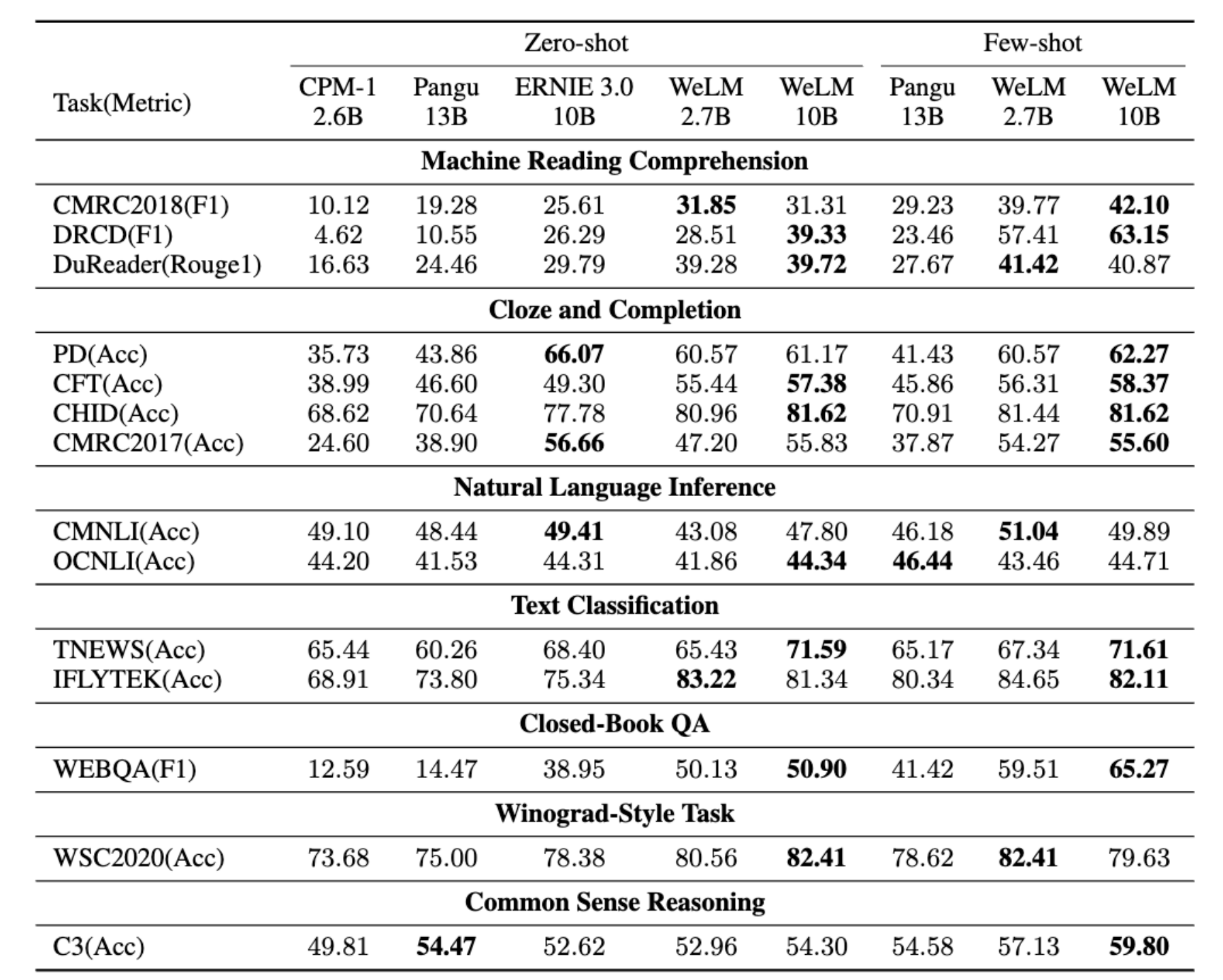
并且,WeLM 具有尺寸合理的优势,在 14 项中文 NLP 任务上,WeLM 的整体表现超出了所有同大小的模型,甚至能够匹配比它大 25 倍的模型。
以被普遍认为是更困难的 NLP 任务的文本风格转换(改写)为例,尽管用户给出的 5 个例子和最后需要生成的例子并没有重合的风格转换类型,但 WeLM 拥有出色的举一反三能力,通过学习少量的文本转换例子即可达到对任意类型的文本转换。并且,WeLM 在对话-采访、阅读理解、翻译、续写等多个中文文本生成任务中有着同样优异的表现。

除了具备强大的中文理解和生成能力,WeLM 还拥有处理跨多语言(中英日)任务的能力。以“微信 AI 推出の WeLM 是一个 language model that いろいろなtaskをperformができる”这句混合中日英三国语言的文本为例,WeLM 的翻译相较 Google 翻译更为精准。
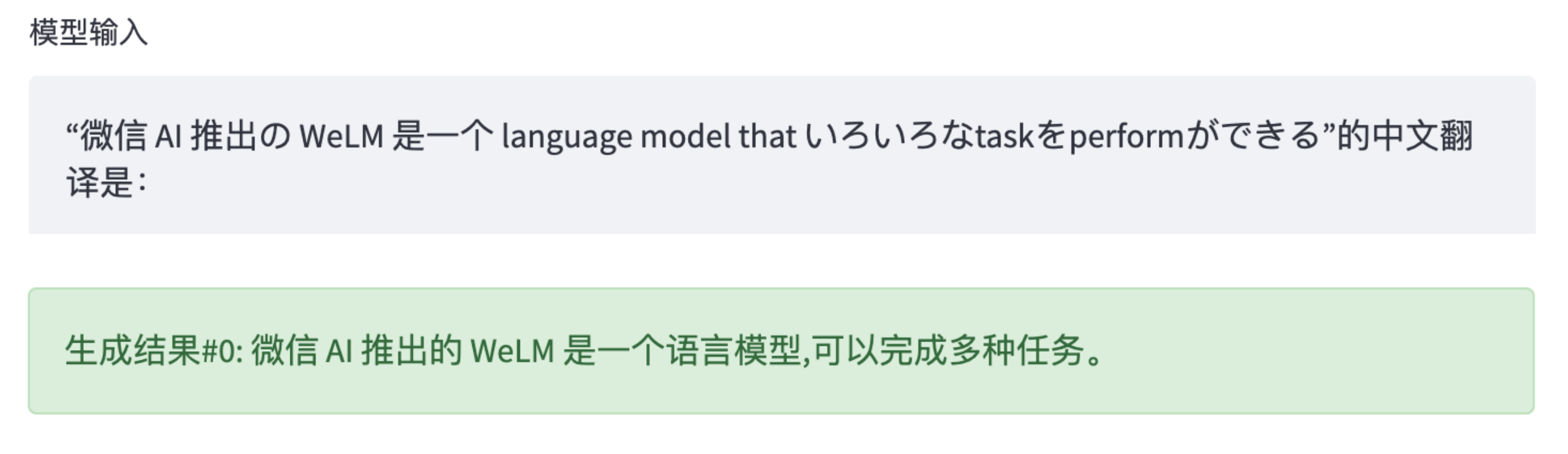
而且,在进一步微调后,WeLM 可以拥有更好的零样本学习能力,可以根据场景拥有更好的表现。目前,WeLM 已经部署应用于微信视频号的部分场景中,未来在进一步优化后还将应用于更多微信应用场景。
为进一步推动 WeLM 成为真正能落地且实用的工具,微信 AI 团队还发布了一个供用户体验的交互式网页 PlayGround,并开放了用于访问 WeLM 的 API 接口。

目前,用户可通过https://welm.weixin.qq.com/docs/体验WeLM的相关能力,并通过调整配置以实现更贴近的文本生成效果。对于想接入 WeLM 的开发者,也可通过https://welm.weixin.qq.com/docs/api/填写问卷后获得WeLM的API Token 并调用相应接口,将 WeLM 部署在自己的应用上。
具有丰富知识储备,在 14 项中文 NLP 任务中表现亮眼
据介绍,在纯 Encoder(Bert)、纯 Decoder(GPT) 以及 Encoder-Decode(T5) 结构等主流 NLP 模型路径的选择上,WeLM 和 GPT3、Google PaLM 一样,选择了自回归模型的路线。同时,考虑到不同的用户对于模型效果和推理延迟会有考量或者取舍(trade-off),微信 AI 的 WeLM 训练了 1.3B、2.7B 以及 10B 三个版本的模型,满足不同用户的调用需求。
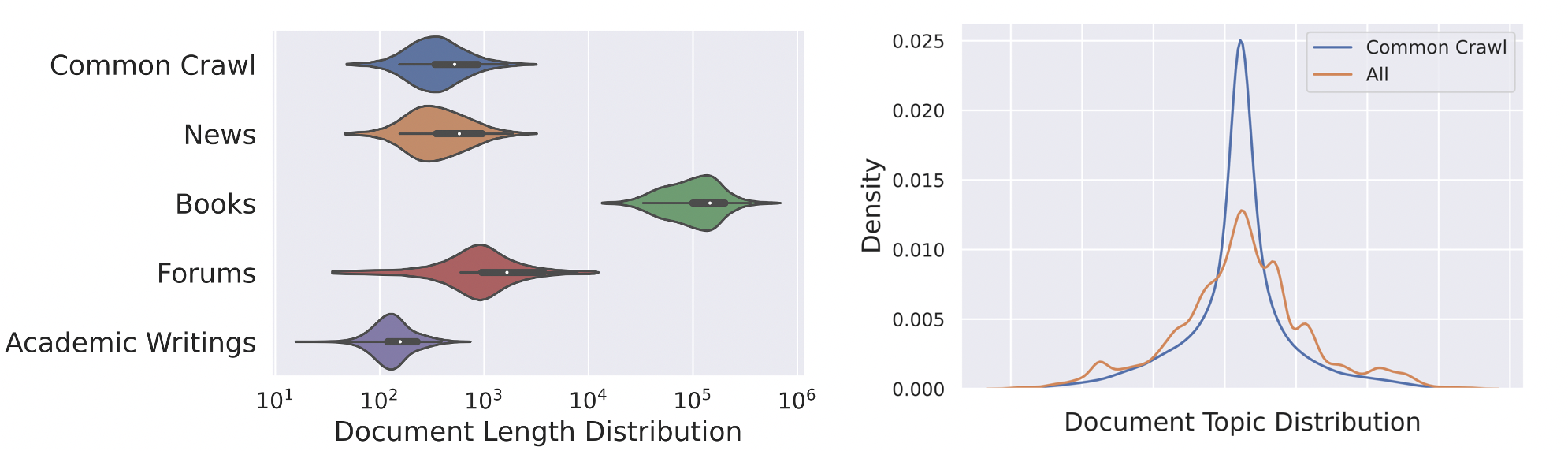
同时,在训练数据上,微信 AI 团队希望构建一个足够丰富、足够干净、足够公平的数据集,为此研究团队从 Common Crawl 下载了近两年的中文网页数据,大量的书籍、新闻。为了增强专业能力,微信 AI 团队还在数据集补充了知识密集的论坛数据和一些学术论文,搜集完成后的全量数据 10TB,其中包含了 750G 的英文数据,并保留了部分日韩文。
随后,通过规则过滤和额外训练的二分类 fasttext 模型,以及对测评相关数据的去除,数据集最终处理完的数据量为 262B tokens。为了更好的平衡各个数据源的比重,微信 AI 团队也对数据进行不同比重的采样,最终,整体数据集的 Topic 分布相比 Common Crawl 更加平滑。
在与业界同级别的 CPM、华为 Pangu 和百度 Ernie3.0 的对比测试中,WeLM 表现出极强的知识储备,在 14 项中文 NLP 任务上,WeLM 的整体表现超出了所有同大小的模型,甚至能够匹配比它大 25 倍的模型。同时,在强大的中文理解和生成能力外,WeLM 还有出色的多语言理解能力,用户的输入可以在中日英上自如切换。
目前,WeLM 的相关技术论文《WeLM: A Well-Read Pre-trained Language Model for Chinese》已经发布于论文预印本网站 arXiv,感兴趣的用户可前往https://arxiv.org/abs/2209.10372查看更多技术细节。
接下来,微信 AI 将针对 WeLM 进行进一步的微调优化,进一步提升其在新任务上的泛化效果。




