
整理 | 华卫
近日,据外媒报道,中国金融科技巨头蚂蚁集团在人工智能领域取得了重大突破。有知情人士透露,蚂蚁集团使用由阿里巴巴和华为制造的国产芯片,开发出了将人工智能训练成本降低 20% 的方法。
据称,蚂蚁集团在训练“专家混合”(Mixture of Experts,以下简称 MoE)模型时运用了多种优化方法,在国产芯片的基础上取得了与使用英伟达 H800 等芯片差不多的训练效果:计算成本从 635 万元人民币 / 万亿 Token 降低至 508 万元人民币,但模型性能却能与 Qwen2.5-72B-Instruct 和 DeepSeek-V2.5-1210-Chat 相媲美。
这一消息引发了广泛关注,蚂蚁所带来的成果令海外的网友感到震惊。许多人纷纷发出感叹:“中国变化太快”、“美国禁止向中国供应芯片,只会让中国芯片制造业更快发展”、“这释放出一个强有力的信号:人工智能领域的主导地位并非英伟达一家独揽”。
而蚂蚁的相关成果早在 3 月 11 日就已公开发表,蚂蚁集团 Ling 团队在其技术报告论文中,介绍了这一系列“不使用高级 GPU 来扩展模型性能”的创新策略。此外,蚂蚁还指出了他们在过程中遇到的挑战和教训。“即使是硬件或模型结构的微小改动,也可能引发问题,比如导致模型的错误率突然上升。”
具体做了哪些优化?
随着企业在人工智能领域投入大量资金,MoE 模型已成为一种热门选择。这种技术将任务划分为较小的数据组,就像组建了一支专家团队,每个成员专注于一项工作的某个部分,从而提高了工作效率。然而,虽然 DeepSeek、阿里 Qwen、MiniMax 等系列的 MoE 模型在特定任务中已展现出优越性能,但这类模型的训练通常依赖高性能计算资源,如英伟达 H100/H800 等先进 GPU,其高昂的成本让许多小公司望而却步,也限制了该技术的更广泛应用。
在技术报告中,蚂蚁首先就探讨了训练 MoE 模型所面临的这些挑战,重点是要克服此类系统中普遍存在的成本效率低下和资源限制问题。为此,他们提出了一系列系统优化策略,以便在有限的资源和预算约束下实现高效的 LLM 训练,平衡资源成本和模型性能,包括优化模型架构和训练策略、改进训练异常处理、提高模型评估效率和工具使用能力。
在优化模型方面,他们从架构、训练框架和存储三方面进行了优化。
模型架构优化:基于对密集模型和 MoE 模型缩放规律的综合分析,选择与可用计算资源最匹配的架构。
训练框架优化:针对异构计算平台,将多个训练框架整合为一个统一的分布式深度学习框架,即开源项目 DLRover DLRover 。其开发了一种轻量级调试工具 XPUTimer,它有助于快速、经济高效地分析任务性能,同时减少了 90% 的内存使用量。此外,还实施了一种与平台无关的异步训练策略 EDiT(弹性分布式训练),它提高了训练效率,训练时间在各种配置下最多可缩短 66.1%。
存储优化:采用设备多租户和用户空间文件系统(FUSE)等技术,实现大规模训练的高性能和多集群适应性。存储和训练流程的协同设计提高了 MoE 场景中的 I/O 效率,将时间开销减少了 50%。
针对大规模训练中的硬件错误和损耗异常,蚂蚁开发了一套稳健的异常处理机制,包括一套实时监控整个训练过程异常的多层次异常检测系统和为减少异常情况对训练进度影响而实施的一种自动恢复机制。
同时,为了优化对跨集群模型训练的监测,他们尝试改进了以下评估基准和框架:
综合评估数据集:为减少模型初始表现不佳并提高稳定性,构建了一些特定领域的评估数据集,并优化了相应的预测策略和提示模板。
高效评估系统:基于自主创新的离线推理框架(即 Flood),开发了一套可扩展的跨集群评估系统,其结果稳定,平均偏差小于 0.5%。
自动分析系统:为了提供实时反馈以调整训练策略,开发了一个自动系统,将评估结果与模型性能和数据集相关联。
在提高大型模型的工具使用能力上,蚂蚁重点关注高质量数据合成和自适应工具学习两个关键方面。
为了有效生成高质量、可扩展和多样化的工具使用数据,蚂蚁团队利用知识图谱技术和广义调用指令来提取多样化和复杂的函数链,从而增强凌模型在各种实际场景中的适用性。团队利用拒绝采样和纠错等学习策略开发了自省式多机器人交互对话,以增强模型的自适应工具使用能力。
据蚂蚁介绍,他们开发并开源的 Ling 系列 MoE 模型,就是一个基于上述技术优化成功平衡资源成本与模型性能的示例。
其中,Ling-Lite 包含 168 亿个参数和 27.5 亿个激活参数,Ling-Plus 则拥有 2900 亿个参数和 288 亿个激活参数。知情人士称,该公司计划利用其开发的大语言模型 Ling-Plus 和 Ling-Lite 的最新突破,为包括医疗保健和金融在内的行业提供人工智能解决方案。
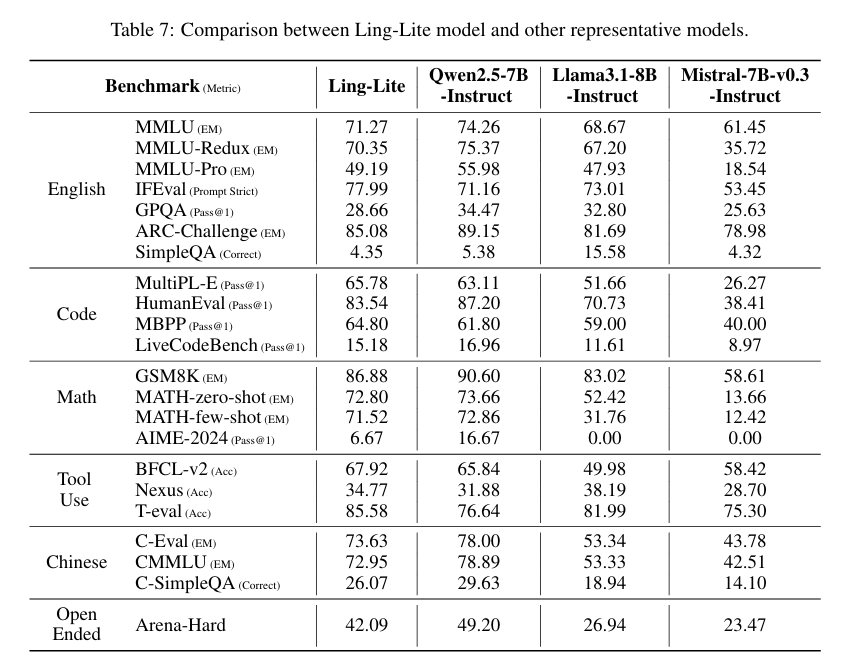
根据一系列综合评估基准, 参数大小相似的情况下,在有限的资源和预算约束下训练的 Ling-Lite 模型,英语理解能力与 Qwen2.5-7B-Instruct 相当,同时优于 Llama3.1-8B-Instruct 和 Mistral-7B-v0.3-Instruct;在数学和代码基准测试中,Ling-Lite 的性能与 Qwen2.57B 相当,优于 Llama3.1-8B 和 Mistral-7B v0.3。
同样的前提条件下,Ling-Plus 模型与 DeepSeek 等前沿开源模型性能不相上下。Ling-Plus 的英语理解能力与 DeepSeek-V2.5-Chat 和 Qwen2.5-72B-Instruct 相当,在 GPQA 数据集上的得分还高于 DeepSeekV2.5,在事实知识基准 SimpleQA 上与 DeepSeek-V2.5 的表现相似。在数学和中文的测试上,Ling-Plus 的总体性能与 Qwen2.5-72B 相近,较高于 DeepSeek-V2.5 和 Llama3.1-70B 的基准得分。代码测试中,Ling-Plus 的得分与 Qwen2.5-72B 相当、整体略低于 DeepSeek-V2.5 。
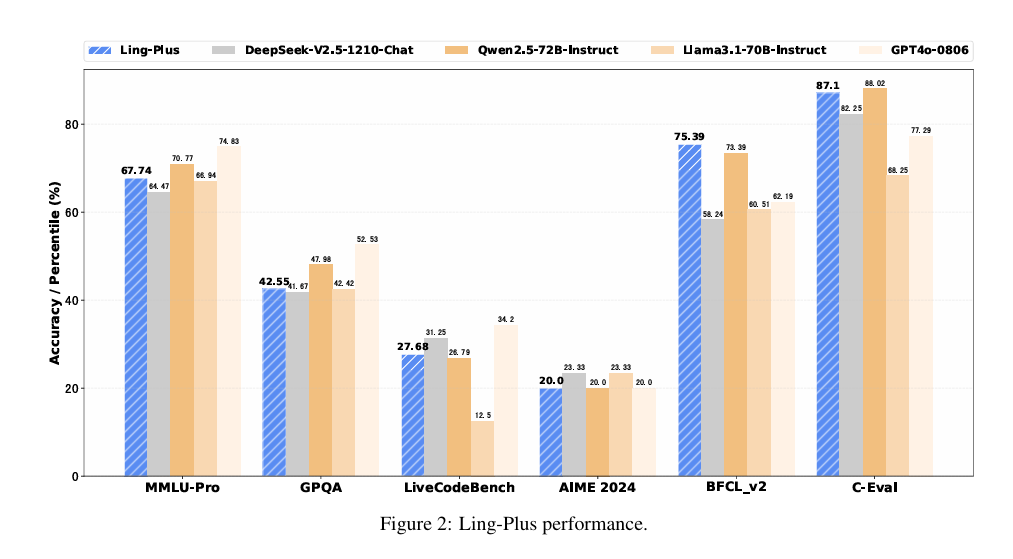
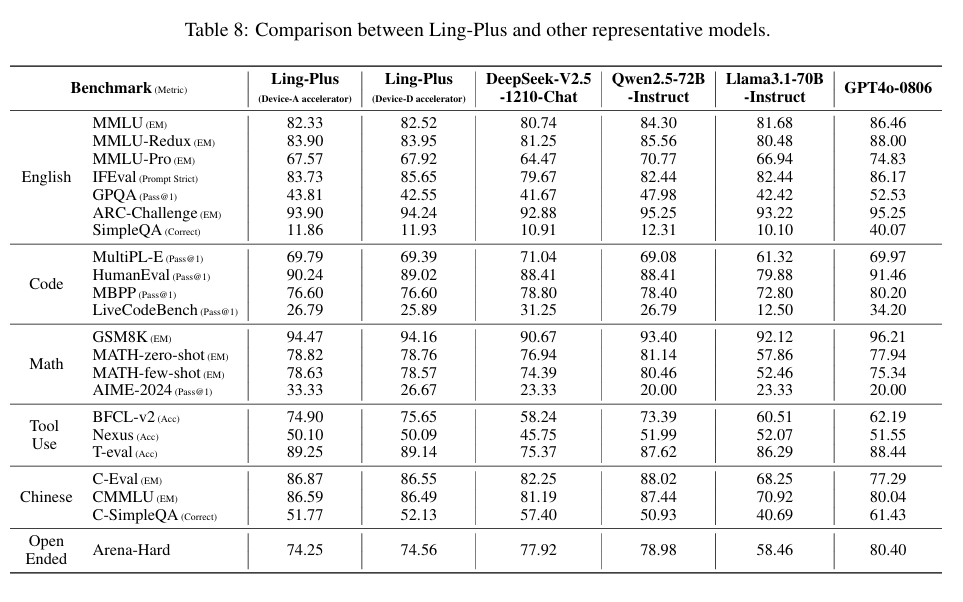
不过,蚂蚁强调,Ling-Plus 模型不如 DeepSeek V3。
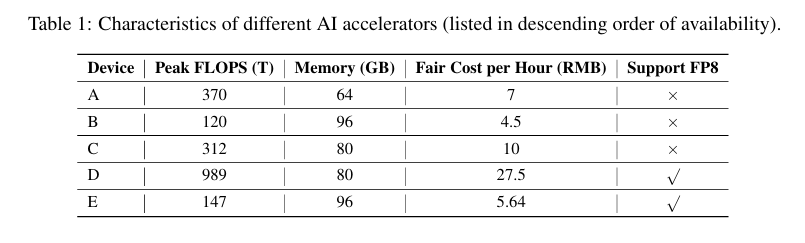
此外,Ling-Plus 在五种不同的硬件配置对 9 万亿个 token 进行了预训练,使用高性能硬件配置(设备 D)训练 1 万亿个 token 估计需要花费约 635 万人民币;相比之下,使用较低规格的硬件系统可将成本降至约 508 万人民币,节省了近 20% 的成本。
痛苦教训:微小差异都会改变训练结果
LLM 训练是一个具有挑战性和资源密集型的过程,往往伴随着各种技术困难。错误和异常情况很常见,有些问题相对容易解决,有些问题则需要花费大量时间和精力。
“在超大规模模型的训练过程中,与硬件相关的因素和对网络结构看似微小的修改都会对模型的稳定性和收敛性产生重大影响。”蚂蚁团队在报告中提到。具体来说,蚂蚁在整个过程中遇到了损失发散、损失尖峰和专家负载不平衡等挑战。
其中,保持均衡的专家利用率对于 MoE 模型的有效性至关重要。大范围的损失峰值会导致突然的梯度激增,从而破坏路由平衡,严重破坏专家负载平衡。一旦专家失衡,问题就会升级,导致整个模型普遍不稳定。通过将尖峰缓解技术与平衡损失和上述路由器 zloss 相结合,蚂蚁才成功地实现了包含数千亿个参数的 MoE 模型的稳定训练。这种方法带来了稳定的损失轨迹,没有观察到损失发散、大范围损失尖峰或专家路由平衡中断的情况。
同时,LLM 在不同平台间迁移训练面临多方面挑战,这主要是因为基础操作的实现方式和框架层面存在差异,可能会导致训练结果不同,凸显了严格的对齐策略的必要性。为推动 Ling 在多个平台上的迁移,蚂蚁开展了大量预备实验,旨在确保跨平台基本操作和通信算法的一致性,并考虑到数值计算中固有的微小精度误差。在验证这些基础组件后,他们才进行大规模大语言模型的训练。
然而,事实证明,仅验证基本操作不足以实现无缝的跨平台迁移。在后续训练阶段,他们又观察到迁移后不同平台之间的损失收敛情况存在显著差异。为解决这一问题,其将对齐工作从基本操作扩展到框架本身。这个过程需要消除所有潜在的差异源;否则,就无法确定错误的根本原因。因此,他们实现了两个平台上包括矩阵乘法(matmul)和线性变换在内的基本操作的完全对齐。
在框架层面,其处理了诸如注意力机制、多层感知器(MLPs)和路由组件等模块在实现过程中的差异,以避免浮点运算导致的精度误差,通过这些努力实现了跨平台前向传递计算的完全对齐。此过程中,他们解决了张量并行(TP)变化和辅助损失计算引发的问题,并纠正了某些通信操作中的错误。在反向传递计算时,借助前向传递对齐过程中获得的经验,他们能够高效识别并纠正梯度传播中的错误,尤其是路由组件中的错误。
虽然这些问题在单独出现或单元测试时可能看似微不足道,但在整个训练过程中,它们的累积效应会对大语言模型的收敛结果产生重大影响。即使是微小的差异,经过多次迭代叠加,也可能导致最终损失收敛出现巨大偏差。
结 语
据一位知情人士称,蚂蚁集团现在虽仍在使用英伟达的产品进行人工智能开发,但在其最新模型的训练中,目前主要依赖来自 AMD 以及国产厂商的替代芯片产品。
如果这些国产芯片流行起来,可能会影响英伟达目前作为受欢迎人工智能芯片生产商所享有的地位。尽管现在英伟达的芯片仍然非常抢手,性能也较为强劲,但一直存在严格的出口管制。今年早些时候,自 DeepSeek 展示了如何以远低于 OpenAI 和谷歌母公司 Alphabet 数十亿美元的投入训练出高性能模型后,英伟达的股价就一度短暂下跌。
参考链接:
https://arxiv.org/pdf/2503.05139
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。




