
背景及挑战
我们为日均 10 亿+用户请求流量提供推荐服务,在推荐服务背后,使用了 Elasticsearch 作为检索引擎,存储了 20TB 左右的物料数据用于推荐。同时,为了保证 Elasticsearch 服务稳定性、业务查询可靠性、快速兜底,我们引入了 Hystrix 做熔断与降级。
Hystrix 是由 Netflix 开源的 Java 库,通过使用断路器模式(Circuit Breaker Pattern)来防止分布式系统中的某个服务出现故障时,对整体系统性能造成的影响。也就是说,Hystrix 可以监控 Elasticsearch 查询方法响应时间及超时/报错比例,并在异常发生时快速触发降级逻辑,进入兜底逻辑,从而避免服务雪崩。
然而,在使用 Elasticsearch 和 Hystrix 过程中,我相信部分同学一定会遇到类似的问题:
2)查询 Elasticsearch 时,总是报“request timeout“(查询超时)
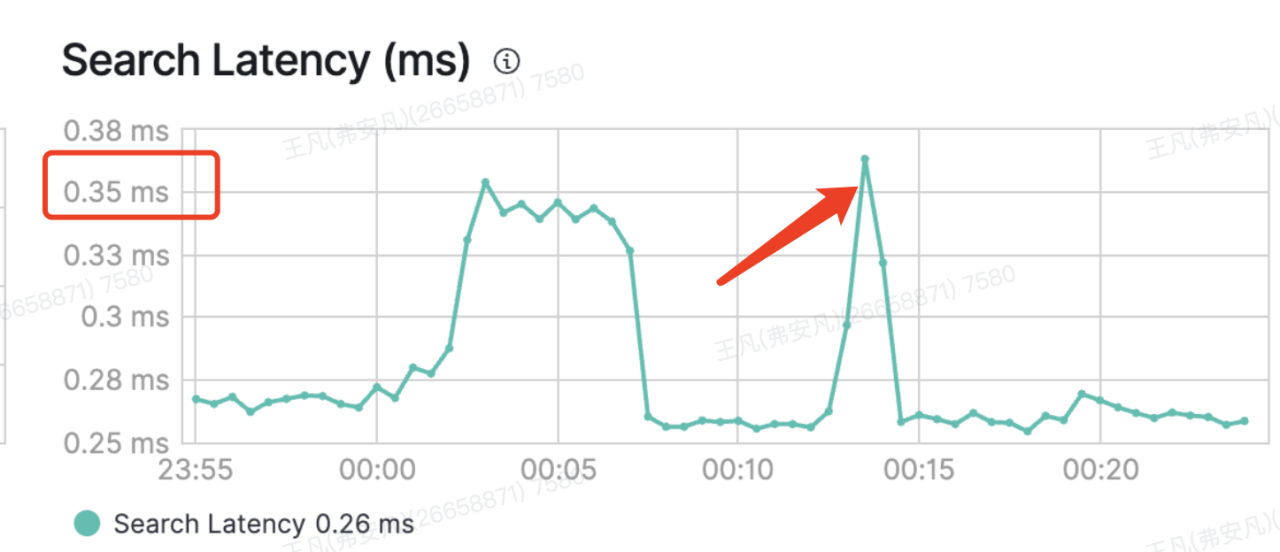
明明 Elasticsearch 集群查询延迟稳定在 10ms 以下,查询端和服务端的资源利用率也没有明显的瓶颈或波动,为什么客户端服务中的 Hystrix 保护的 Elasticsearch 查询请求却频繁触发超时熔断?是查询的压力过大,还是 Hystrix 的配置出了问题?
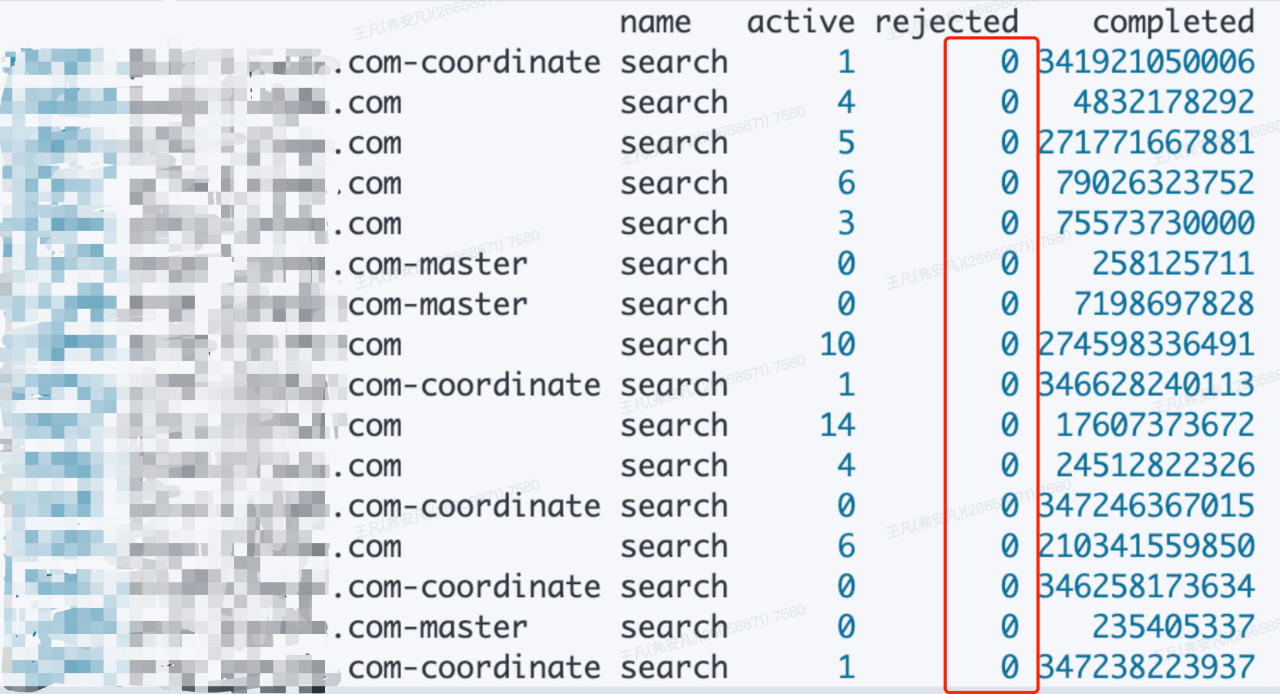
2)Hystrix,线程池未满时抛出”thread-pool rejection“(拒绝执行)
线程池配置最大线程数,但实际请求数未达到配置上限时,依然抛出了线程池拒绝异常。
3)Hystrix 发生降级后,熔断器一直打开,无法恢复
Hystrix 一直在执行降级方法,及时下游接口正常了,断路器也迟迟未自动关闭,业务请求无法快速切换回正常流量。

2、 Elasticsearch 调优
2.1 问题排查与定位
针对于文首抛出的第一个问题:查询 Elasticsearch 时,总是报“request timeout“(查询超时) ,让我们来开始踩坑和跳坑之旅。
先来 review 下项目代码。有个功能很简单的 function,通过 RestHighLevelClient 查询 Elasticsearch,方法上使用了 hystrix 做了 150ms 的超时熔断控制。在单机压测过程中,随着并发不断的升高,不断再抛出“request timeout”的异常。
首先,将怀疑的目光看向了 Elasticsearch:
1)集群维度:集群 Search Latency 指标几乎没掀起一丝波澜,并且很稳定在 1ms 以内。通过/hot_threads 查看热点线程,发现热点线程均正常。

2)单索引维度:猜测是 DSL 查询语句慢查,但通过 filebeat 监控的慢查询(设置的是> 100ms 就会上报)来看,慢查没有上升。
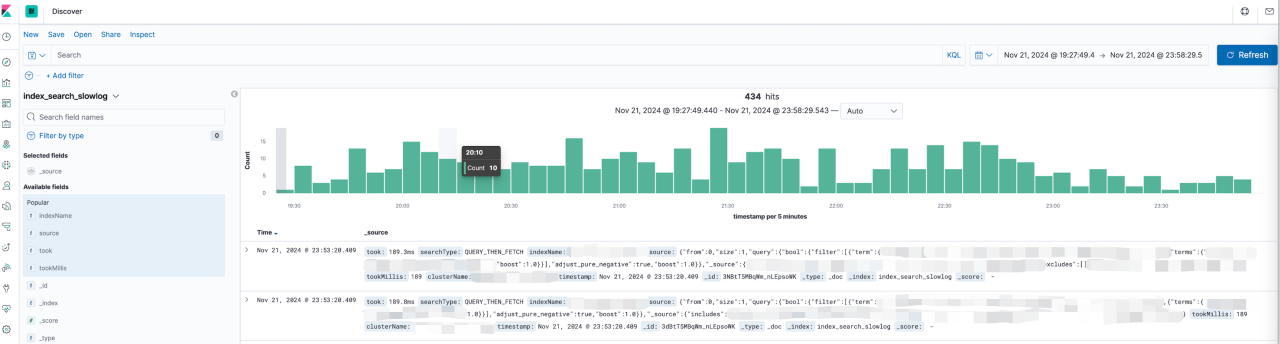
既然 Elasticsearch 内部查询执行很快,看起来就需要找其它的病因了。因此,我们对 function 执行时所经过的所有耗时步骤进行拆解与分析:
服务内部:
a. hystrix 获取线程超时。
b. http 获取链接超时。
网络传输:
a. 数据包较大,序列化性能差。
Elasticsearch:
a. 协调节点性能不足,聚合/排序数据慢
b. 获取 search 线程失败/超时
c. data 节点查询超时(上面已证明,此步骤正常)
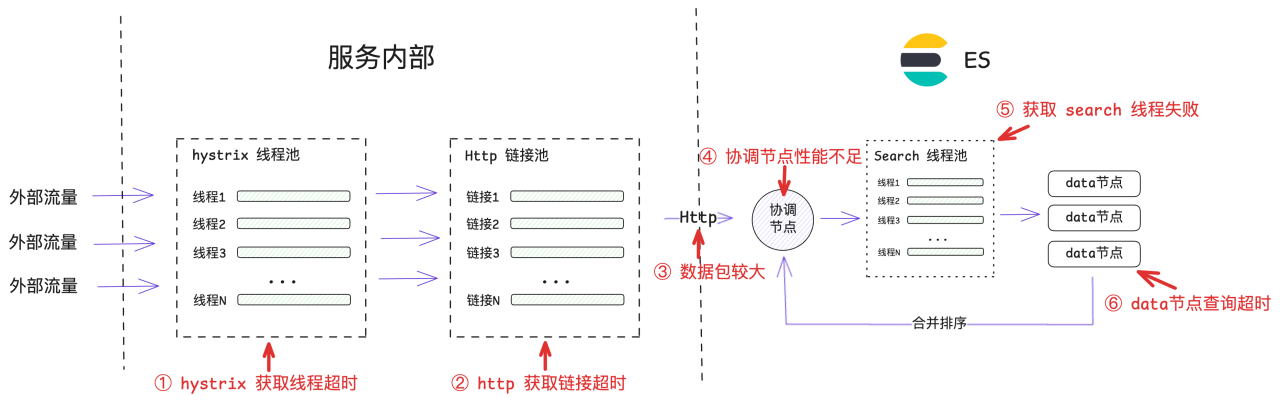
首先,看网络传输。就网络传输的数据包大小而言,网卡经过的流入 &流出量保持在 20MB/s 以内,完全在服务器可处理能力范围内。就序列化性能而言,RestHighLevelClient 本质是个标准的 HttpClient,这样成熟的框架几乎不会触发某种”特殊 case“的情况。
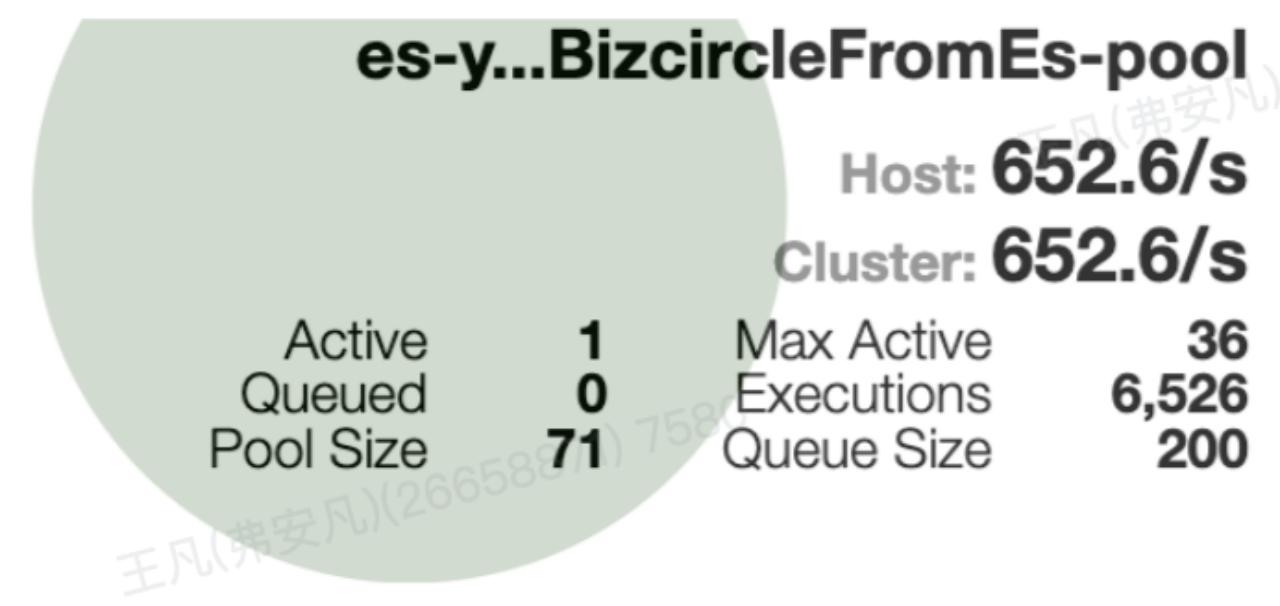
其次,看服务内部执行。分两方面,一个是获取 hysrix 线程,通过 hystrix dashboard 观测线程创建和获取正常。一个是获取 http 链接超时,有种快要接近的真相的感觉了...
将 http 链接池的信息给打印了出来,发现最大链接数竟然只有 30,和 applcation-prod 配置的 512 不一样!显而易见,30 的链接数不可能支撑单机压测的 QPS。之后排查实际生效参数与配置参数不一样的原因,其实是因为一个代码 bug,导致在设置 httpclient 中 Credentials 登录认证时,将 http 链接数的配置给覆盖掉了,导致采用了默认参数 30。
name : restHighLevelClientYz , totalStats: [leased: 0; pending: 0; available: 0; max: 30]
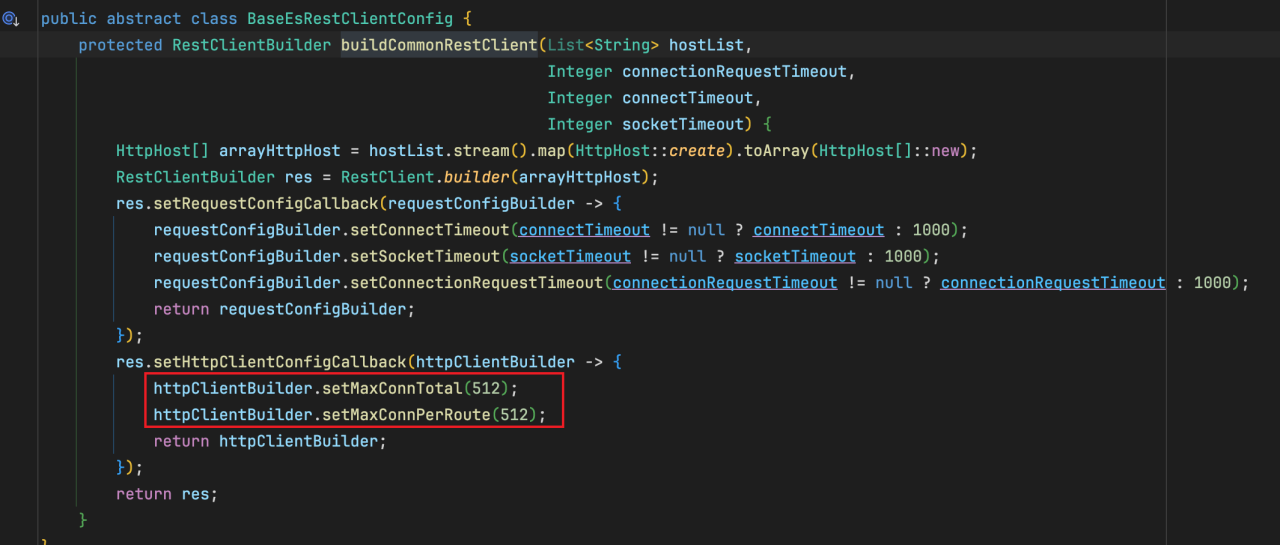
找到问题了之后,其实解决很简单,花了 10 行代码左右,将 http 链接数正确的改为 512。在之后单机压测时,hystrix 再也没有报“request timeout”的错误了,问题圆满解决。
2.2 Elasticsearch 开发实践
除了该线上问题分析以外,也想分享一些在团队内对于 Elasticsearch 的使用姿势规范,标准使用姿势对 Elasticsearch 整体读写的性能也有着非常关键的影响:
1)使用 Termquery 时,字段 mapping 设置为 keyword
因为如果字段被 dynamic mapping 为 float 等数值类型后,在 Termquery 时便不会走倒排索引,而是走 KD-Tree 的检索,效率会有显著降低。
2)合理的 shard 分片数、replica 数
创建索引之前对数据量作好充分预估,为其创建合理的分片数。一般而言,保持单分片在 2000w 数据以下。
3)合理的 refresh_interval
如果该索引内数据对实时性要求不高,可以提高 refresh_interval,以减少小 segment 的产生。
4)使用 filter 查询
filter 查询后,会将查询结果数据加载进缓存,下次查询时能够直接从缓存中查询,避免再次查询 shard。而普通的 match 则不会将数据放入缓存。
5)深分页查询场景时,避免 from size, 使用 search after
问题:深度分页问题:在分布式系统中,对结果排序的成本随分页的深度成指数上升。
比如:请求发送给协调节点查询 100-110 的数据,给所有查询的分片都返回 110 个数值,协调节点全部搜集再排序,再返回
分页查询:
如果是小数据量或者实时性较重要的场景,可以考虑使用 From/Size 参数;如果是大数据量或者离线任务的场景,可以选择 Scroll API;对于分布式环境和对性能较为敏感的场景,Search After 方法可能更适合。根据具体需求和实际测试,选择最适合的分页方法是最佳实践。
6)如果字段不需要查询,mapping 中 index 可以设置为 false
7)使用 BulkAPI 进行批量数据的写入
使用 Bulk API 向 Elasticsearch 发送一个包含多个索引、更新或删除操作的请求,以减少网络开销和提高性能。
2.3 Elasticsearch 近实时性如何解决
了解 Elasticsearch 的小伙伴都知道,Elasticsearch 中写入的数据并不是立即「对外可见的」,也就是说写进去的数据不能马上被读出来!这取决于索引设置的 refresh_interval 时长。所以,如果有要求数据立即可见的业务场景时,通常有如下几种方式:
1)query by doc_id api
Query by Doc_ID 通过文档 ID 定位到具体的分片,并直接读取最新的 Translog(事务日志) 和 Lucene 段。即使数据尚未通过 refresh 写入新的 Lucene 段(不可搜索),Query by Doc_ID 请求也能够访问写缓冲区中的数据。
写入数据:Insert with ID,将数据写入 ES 并指定唯一文档 ID。
查询数据:GET by Doc_ID,通过文档 ID 查询最新数据。
GET /my-index-000001/_doc/2?routing=user1GET /my-index-000001/_mget{ "ids" : ["1", "2"]}PUT test/_doc/1?routing=user1{ "counter" : 1, "tags" : ["red"]}优点
a)快速访问: 直接通过文档 ID 进行查询非常快速,因为 Elasticsearch 会直接根据 ID 定位并返回文档,无需执行复杂的查询解析和计算。
b)实时性: 查询按照文档 ID 可以立即返回文档的当前版本,适合需要实时数据的应用场景。
c)可缓存性: 如果启用了适当的缓存策略,GET 请求的响应可以被缓存,从而提高后续请求的性能和响应时间。
缺点
a)查询条件单一: 按照文档 ID 查询是基于单一条件的查询,无法利用复杂的查询逻辑和多个条件进行数据检索。
b)传输内容限制: GET 请求的查询参数存在长度限制,可能会受到 URL 长度限制的影响,特别是当需要传递大量的文档 ID 时。
注意事项
a)routing 路由一致:如果使用了自定义路由(如指定 routing 参数),写入和查询时必须保持一致。
2)使用 redis(或其它缓存中间件)
在写入 ES 的同时,将数据短期缓存到 Redis,用于弥补 ES 的延迟问题。
步骤:
数据写入 ES 后,同时将数据存入 Redis,设置适当的 TTL(如几秒)。
查询时,优先从 Redis 获取最新数据,如果未命中则查询 ES。
优点:
a)高效缓解延迟:Redis 的内存缓存能力可以快速返回最新数据。
b)灵活 TTL 策略: 根据业务需求调整缓存数据的过期时间。
缺点:
a)数据一致性维护: 数据更新时需同时更新 Redis 和 ES,增加双写复杂性。
b)双查带来的开销: 如果 Redis 缓存过期,则需要回源查询 ES,可能增加请求延迟。
c)内存占用:Redis 的内存有限,需定期清理过期数据,或者对冷数据及时淘汰。
3)立刻 refresh(不推荐)
indexRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);
手动让 es 中的数据每次更新后都从 indexing buffer 中刷新到磁盘中,从而让更新的数据立即可见,但是从前面的分析可见,会影响性能。
在 ES 中,每秒清空一次写缓冲,将这些数据写入文件,这个过程称为 refresh,每次 refresh 会创建一个新的 Lucene 段。但是分段数量太多会带来较大的麻烦,每个段都会消耗文件句柄、内存。每个搜索请求都需要轮流检查每个段,查询完再对结果进行合并;所以段越多,搜索也就越慢。因此需要通过一定的策略将这些较小的段合并为大的段,常用的方案是选择大小相似的分段进行合并。在合并过程中,标记为删除的数据不会写入新分段,当合并过程结束,旧的分段数据被删除,标记删除的数据才从磁盘删除。
3、 Hystrix 调优
3.1 问题背景
由于服务主要为 IO 密集型应用,依赖了很多三方服务/存储/搜索中间件,大部分使用了线程池隔离模式。在使用和优化过程中,发现了两个问题:
1. 线程池拒绝
在 hystrix 线程池还未到达最大线程数时,发生了拒绝现象。
2. 偶现断路器打开后无法关闭
触发熔断后,就算依赖的服务已经恢复,断路器也无法自动关闭,一直处于熔断状态
3.2 分析与解决
hystrix 对于线程池配置提供了几个配置参数:
Hystrix 线程池的运行和 JDK 类似,但是有些坑点,如果全部按照 JDK 线程池理解,会出现意想不到的行为,具体流程如下
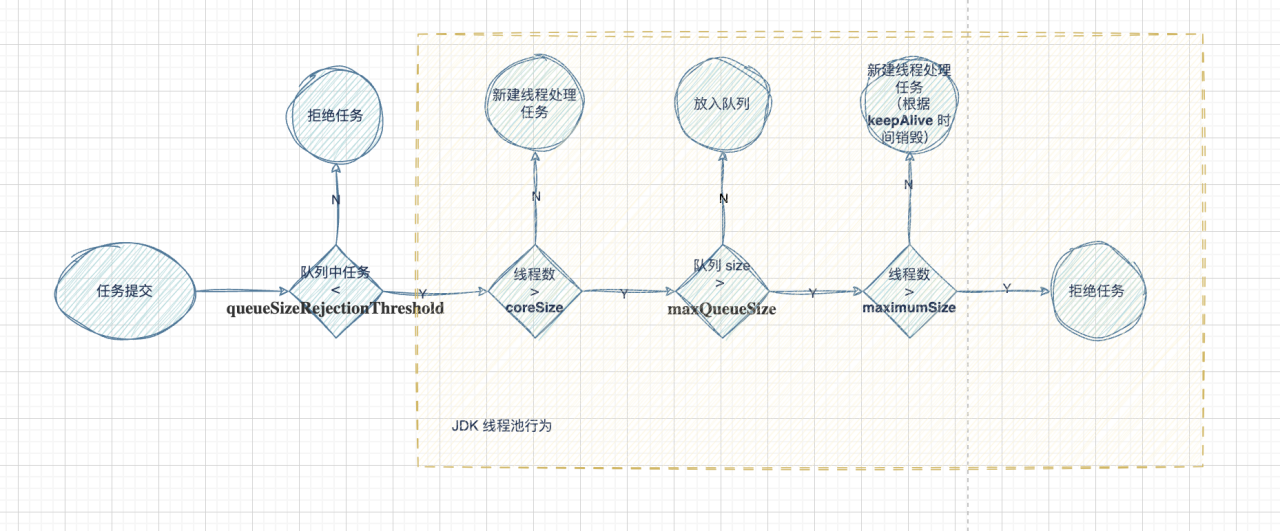
可以注意到:
1. queueSizeRejectionThreshold 优先级最高,只要没通过,后面的 maximumSize 是不会生效的,而且这个值默认是 5,并发高的情况在会发生拒绝。
2. 当 queueSizeRejectionThreshold < maxQueueSize,一定会先拒绝任务,而不是创建新线程,导致 maximumSize 失效。
3. 新建核心线程时,不会判断已有的核心线程是否空闲,而是只要线程数小于核心线程数,直接创建,这导致每个线程池无视实际并发度,固定的会创建 coreSize 个数的线程
4. 队列满了后才会,创建非核心线程,减少线程资源,但增加了任务实际执行的延时。
定位与解决:
1. queueSizeRejectionThreshold 会导致最大线程不生效,且默认值过小导致拒绝
解决:配置 queueSizeRejectionThreshold 大于 队列大小,或者不使用队列
2. 使用注解的场景下,设置最大线程等参数,需要升级到 1.5.12/1.5.13 版本,但是这两个版本都存在某些场景下断路器打开后不能关上的BUG,官方最后一个版本 1.5.18 实际上是回滚到 1.5.11 版本。
解决:使用 1.5.11/1.5.18 版本。
3.3 线程池优化
合理的线程池配置应该考虑下面几点:
1. 资源利用率:Java 虚拟机(如 HotSpot JVM)中,Java 线程与操作系统线程采用的是 1:1 的映射模型。过多的线程会带来 CPU 上下文切换,内存消耗,GC root 增加等开销
2. 隔离性:Hystrix 服务之间需要相互不影响,流量达到一点程度后需要配置单独的线程池,避免相互之间影响,导致请求拒绝
3. 突发流量:除了平稳的日常请求,当发生短时间的大量请求时,也能正常执行,不会发生请求拒绝
4. 特定方向调优:对于任务执行速度/资源使用 两个方向针对性调优
工具
1. HystrixDashboard 可以 监控断路器是否打开,执行次数,延时情况,线程池执行任务数,运行中线程,队列情况。。
2. 压测可以模拟各种场景下的流量
结果
Tips:由于 hystrix 已经不再维护,功能也不会迭代,之后会调研并且逐步把 hystrix 迁移到 resilience4j/sentinel 等替代品上。
4、 总结
在面对类似的技术问题时,作为研发人员,我们不仅是需要掌握具体的工具使用方法,更重要的是理解它们背后的设计思想与实现原理。在遇到问题时,要能够迅速分析问题的根源,找到合适的解决策略。更进一步来说,系统的长期稳定性也离不开完善的监控报警体系,之前对于常用的中间件,需要通过一次次 case 排查逐步完善关键的观测指标,当线上问题发生时,做到有的放矢,一眼观察问题所在。
最后,希望这篇关于 Elasticsearch 与 Hystrix 的线上调优实践能一定程度帮助大家。




