介绍
当我们部署服务应用到生产环境时,需要决定在线的服务器数量。这是个困难的决定,因为对于一个指定的流量负载,通常我们不知道需要多少服务器。因此,人们为了“安全起见”,不得不使用更多(也可能是过多)的服务器。但是服务器是有成本的,所以这样做会让事情变得过于昂贵。
事实上,事情比这还要糟糕。流量不会一整天都保持不变。如果我们按高峰期流量部署服务器,那么基本上大部分的服务器大多数时间都处于使用率不足的状态。特别是在一个基于云的部署场景中,服务器实例能够在任何时刻自由分配,我们应该能够意识到,如果不论何时,我们都只激活处理该时刻负载所需的服务器实例,那么就能显著地节省成本。
对于这个问题,一种可能的办法是使用一个固定的时间表,对一天中的每个小时都指定(以某种方式)所需的服务器实例数量。这种方法的难点是固定的时间表无法处理随机的变化:如果由于某种原因,今天的流量比昨天大 10%,那么这个时间表将无法提供额外的服务器来处理这个意料之外的负载。同样地,如果流量峰值提前了半个小时,一个基于固定时间表的系统也将无法应对。
与其使用一个固定的(基于时间的)计划,我们也可以考虑一种基于规则的解决方案:对任何给定的流量负载,我们有一种规则来指定使用多少服务器实例。这个方案比基于时间表的方案更具有弹性,但它需要我们(提前)知道处理每种流量负载需要多少服务器。而且如果流量的性质发生变化,这是有可能发生的,例如,如果需要长时间运行的查询的比例增加了,会发生什么呢?基于规则的方案将无法正确应对。
反馈控制是一种设计模式,它完全能够处理所有这些挑战。通过持续监视一些服务指标(例如响应时间),如果指标值偏离期望值,则做出适当的调整(例如增加或减少服务器)。因为反馈来源于被控制系统的实际行为,因此它能够处理甚至不可预见的事件(例如流量超出了所有的预期)。另外,对比之前基于规则的方案,反馈控制只需要很少的被控制系统的相关信息。其原因是反馈是真正的自我修正:因为持续对服务质量指标进行着监测,一旦它偏离期望值,将被立即观察到并立即进行修正。而且在必要时,这个过程是可以重复的。简单地说:如果响应时间恶化,反馈控制系统只需激活额外的服务器实例,如果仍然没有改善,它就再增加更多的服务器实例。这就是反馈控制的全部过程。
反馈控制一直是机械和电气工程的标准方法,但在软件架构中,它很少作为一种设计理念。它特别适用于信息不完整,并且会随机变化的情况,它与计算机科学确定性的算法解决方案完全不同。最后,尽管反馈控制的概念很简单,但要使其生效,在一个生产环境中部署一个真实的控制器仍然需要了解和明白一些实战“技巧”。本文将介绍一些概念和常见的困难。
反馈回路的本质
下图显示的是一个基本的反馈回路。在右侧,我们看到控制系统。它的“输出”是相关的服务质量指标。指标的值不停地提供给控制器,与左侧输入的期望值进行比较(系统的输出指标的期望值被称为“设定值”)。基于这两个输入(服务质量指标的实际值与期望值),控制器计算出控制系统合适的控制动作。例如,如果响应时间的实际值比期望值慢,控制动作将包括激活额外的服务器实例。
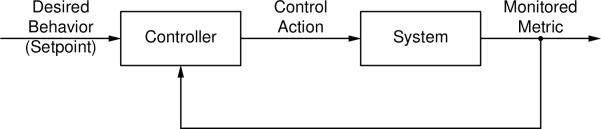
该图显示了所有反馈回路的通用结构。它的基本组件是控制器和被控制的系统。信息从系统的输出流经返回路径到达控制器,与“设定值”进行比较。通过这两个输入,控制器决定相应的控制动作。
那么,控制器实际上做了哪些工作?它如何决定应该采取什么动作?
要回答这个问题,我们要记住使用反馈控制的主要目的是减少系统实际输出与期望值的偏差。这个偏差可以表示为“跟踪误差”:
误差 = 实际值 – 期望值
为了减少这种误差,控制器可以做任何它认为合适的事情。我们当然有绝对的自由来设计这个算法,但是我们要知道被控制系统的一些知识。
让我们重新考虑数据中心这个场景。我们知道增加服务器数量可以减少平均响应时间。所以,我们可以选择这样一种控制策略,当实际响应时间比期望值差时,就增加在线服务器的数量(如果情况相反,则减少服务器数量)。但其实我们还能做得更好,因为这个算法只有标志,没有将误差的大小考虑在内。如果跟踪误差很大,我们就应该做更大的调整。事实上,通常的做法是将控制动作正比于跟踪误差。
动作 = k * 误差
其中 k 是一个数值。选择这种算法,大的偏差将导致大的修正动作,而小的偏差将导致相应较小的修正。这两个方面都很重要:大动作是为了快速减少大的偏差。但同样重要的是当误差较小时,控制动作应该变小。我们只有做到这一点,控制循环才会趋向于一个稳定的状态。否则,其行为将总是围绕着期望值振荡,通常我们希望避免这种结果。
正如我们之前所说的:可以自由地为反馈控制器选择特定算法,但通常保持简单是一种好的设计思想。反馈控制的“神奇”取决于信息流的回路结构,而不是那些特别复杂的控制器。为了允许更简单的控制器,反馈控制需要更复杂的系统架构。
然而有一件事是必须确保的:控制动作必须在正常的方向上。为了保证这一点,我们应该对被控制系统的一些行为有所了解。通常这不是问题,正如我们知道更多的服务器意味着更快的响应时间,等等。但是这是一个我们必须知道的关键信息。
具体实现面临的问题
目前为止,我们关于反馈控制的描述大部分是概念。然而,将这些高级别的想法转换成具体实现时,需要处理一些实现细节。最重要的是对于跟踪误差的大小应该产生多大的控制动作。(如果我们使用之前的公式,就是要为常量 k 选择一个值。)
在控制实现中,为这个常量选择特定值的过程,被称为控制器“调试”。控制器调试是工程上权衡的一种表达方式:如果我们选择相对较小的控制动作,控制器将缓慢地响应,跟踪误差将保持较长时间。另一方面,如果我们选择较大的控制动作,控制器将快速响应,但是也存在“过度修正”的风险,导致相反方向的误差。如果我们让控制器做过大的动作,可能让控制回路变得不稳定:当发生这种情况时,控制器尝试用不断增长的序列动作来补偿每个偏差,所有时间都在增加动作幅度,从一个极端摆到另一个极端。这种形式的不稳定比缓慢操作更糟糕,因此必须避免。控制器调试的挑战是在不造成回路不稳定的前提下,找到控制动作的最大值。
在选择控制动作的大小时,通常的作法是逆向工作:给定一个某种规模的跟踪误差,多大的修正动作能够完全消除这个误差?请记住,我们不需要精确地知道这个值,反馈控制的自修正特性确保在选择调试参数值时可以有一定的公差。但我们至少要保证量级的顺序是正确的。(换句话说:要将平均查询响应时间提高 0.1 秒,我们大约要增加一台、十台还是一百台服务器?)
有些系统对控制动作的响应比较慢。例如,一台新的(虚拟的)服务实例,可能要花几分钟的时间,才能开始接收传入的请求。在这种情况下,我们要把这种滞后或延迟考虑在内:在增加的实例生效前,跟踪误差将持续存在,我们必须防止控制器增加更多的实例,否则,我们最终将有太多的服务器在线。不能快速响应的系统是一种特殊的挑战,需要加倍小心。然而,已经有现成的方法来“调试”这类系统。(基本上,首先需要了解滞后或延迟的时间,然后使用专门的插件公式获得调试参数值。)
需要特别考虑的因素
我们要始终牢记反馈控制是一种反应式控制策略:事情会先变得糟糕(至少有一点糟糕),然后才会有修正动作。如果这是不能接受的,那么反馈控制可能不适合。在实践中,这通常不是问题:一个调试良好的反馈控制器将检测并响应甚至非常小的偏差,通常能保证系统比基于规则的策略或人工操作更接近于它所需的行为状态。
一个更加需要严重关注的情况是,没有一种反应式控制策略能够处理比控制动作生效更快的干扰。例如,如果增加在线服务器实例需要几分钟时间,那么我们无法响应几秒甚至更短时间内的流量峰值。(与此同时,我们完全能够处理几分钟或几小时内的流量变化。)如果我们需要处理波形非常尖的负载,那么我们必须想办法提高控制动作的速度(例如提供热备用服务器),或者采用非反应式的机制(例如使用消息缓冲)。
另一个值得考虑的问题是如何选择服务质量的度量方式。反馈控制器最终做的唯一事情是保持输出值与期望值匹配,因此我们要确保我们选择的度量方式能够很好地表达这种行为。同时,在任何时间,这种度量方式都必须是有效且快速的。(例如,我们无法在一个有明显延迟的度量方式上构建一个有效的控制策略。)最后要考虑的是这种度量方式不能有太多的噪音,因为噪音可能“干扰”控制器。如果这种度量方式本身会有噪音,那么通常需要先进行平滑处理之后才能用于控制信号。(例如,与最近一个请求的响应时间相比,最近数个请求的平均响应时间是一个更好的信号:取平均值能够平滑随机的变化。)
总结
虽然我们介绍了数据中心自动扩展的反馈控制,但它其实有更广泛的应用领域:不论我们是需要维护一些期望的行为,还是面对不确定和变化,都应该考虑将反馈控制作为一个选项。它比确定性的方法更可靠,也比基于规则的解决方案更简单。但它需要新的思考方式,并且明白一些特定的技术才能生效。
延伸阅读
本文只介绍了反馈控制的一些基本概念。更多信息请访问我的博客或者阅读我的书(Feedback Control for Computer Systems; O’Reilly, 2013)。
关于作者
Philipp K. Janert** 提供数据分析和算法建模的咨询服务,他之前的职业是物理学家和软件工程师。他是最畅销书《基于开源工具的数据分析》(O’Reilly)和《Gnuplot in Action: Understanding Data with Graphs》(Manning Publications)的作者。在他最近的著作《**Feedback Control for Computer Systems》中,他演示了汽车巡航控制的原理也同样适用于数据中心的管理和其它企业系统。他也为 O’Reilly Network、IBM developerWorks 和 IEEE Software 撰写文章。他拥有华盛顿大学理论物理学的博士学位。您可以访问他公司的网站。




