导言
正如从像 **《领域驱动设计》[Evans DDD] 和《领域驱动设计和模式应用》[Nilsson ADDDP] 这些书中学到的一样,在应用架构中引入领域模型模式(《企业应用架构模式》**[Fowler PoEAA])一定会有很多益处,但是它们并不是无代价的。
使用领域模型,很少会像创建实际领域模型类、然后使用它们那么简单。很快你就会发现,领域模型必须得到相当数量的基础架构代码的支持。
领域模型所需基础架构当中最显著的当然是持久化——通常是持久化到关系型数据库中,也就是对象 / 关系(O/R)映射出场的地方。但是,情况并不止持久化那么简单。在一个复杂的应用中,用来在运行时管理领域模型对象的部分占了基础架构的很大一部分。我将基础架构的这部分称为领域模型管理(Domain Model Management)[Helander DMM],或简称为 DMM。
基础架构代码放在哪里?
随着基础架构代码的增长,找到一个处理它的优良架构变得越来越重要。问题主要在于——我们是否允许把一些基础架构代码放在我们的领域模型类里面,还是无论如何应该避免这样做?
避免基础架构代码进入领域模型类的论点是强有力的:领域模型应该表示应用程序所处理的核心业务概念。对于想大量使用其领域模型的应用来说,保持这些类干净、轻量级、易于维护是一个极好的架构目标。
另一方面,我们接下来将会看到,保持领域模型类完全不含基础架构代码——通常被称为使用 POJO/POCO(Plain Old Java/CLR Objects)领域模型,这种极端的路线也被证明是有问题的。最终往往导致采用笨重的、低效率的变通方法来解决问题——而且有些功能用这种方式根本不可能实现。
也就是说,我们遇到的还是一个权衡利弊的情况,我们应该尽量在领域模型类里面只放必不可少的基础架构代码,决不超出这个限度。我们付出领域模型的轻微发胖,换来效率的提高以及使一些必要领域模型管理功能有可能实现。毕竟,软件架构很大程度上是关于如何做一笔好买卖。
重构的时机到了
不幸的是,长远看来,台面上的交易条件可能不够好。为了支持许多最有用和最强大的功能,你需要在领域模型类中放入基础架构代码实在太多了。其数量之大,很可能你的系统还没完成,业务逻辑代码就已经被淹没了。
也就是说,除非我们能找到一种方法鱼和熊掌兼得。本文试图分析我们能否找到这样一种方式,既能将必要的基础架构代码分布到领域模型中,却又不会使领域模型类变得杂乱。
我们先从一个应用看起,它将所有有关的基础架构代码都放到了领域模型类中。接着我们将重构这个应用,并且只用众所周知的、可靠的、真正面向对象的设计模式,使应用最后能具备相同的功能,但是基础架构代码却不会弄乱领域模型类。最后,我们将看看我们如何使用面向方面编程(Aspect Oriented Programming,AOP)来更简单地达到相同的效果。
但是,为了看出 AOP 为何能帮助我们处理 DMM 需求,我们首先看看没有 AOP 的时候我们的代码会是什么样——首先是“最原始”的形式,这种形式里,所有的基础架构代码都放在领域模型类里面,然后是重构后的形式,其中基础架构代码已经被分离出领域模型类——虽然仍然分布在领域模型中!
重构肥领域模型
大部分的领域模型运行时管理是基于拦截的——也就是说,当你在代码中访问领域模型对象时,你所有对对象的访问都会根据相应功能的需要被拦截下来。
一个明显的例子就是脏跟踪(dirty tracking)。它可以用于应用的很多部分,以了解一个对象什么时候已经被修改了、但是仍未保存(它处于“脏”状态)。用户界面可以利用该信息提醒用户是否打算放弃任何未保存的修改,而持久化机制则可以利用它来辨明哪些对象是真正需要被保存到持久化介质中的,从而避免保存所有的对象。
脏跟踪的一种方法是保持领域对象最初的、未修改版本的拷贝,并在每次想知道一个对象是否已经被修改的时候去比较它们。这个方案的问题是既浪费内存,又慢。一个更有效率的方法是拦截对领域对象 setter 方法的调用,以便每当调用对象的一个 setter 方法的时候,都为该对象设置一个脏标记。
脏标记放在哪里?
现在我们来看看把脏标记放在哪里的问题。一种是将它放在一个字典结构中,对象和标记分别作为键和值。这样做的问题在于,我们必须让程序中所有需要它的部分都能访问到这个字典。前面的例子已经可以看出,需要访问字典的包括用户界面和持久化机制这样截然不同的部分。
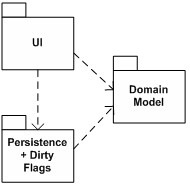
图 1将字典放在这些组件的任何一个内部,都会使其它组件难以访问它。在分层结构中,底层不能调用其上层(除了中心领域模型,它常常处于一个公共的、垂直的层里面,能被其它所有的层调用),因此要么把字典放在需要访问它的最低一层(图 1),要么放在公共的、垂直的层里面(图 2)。两种选择都不是很有吸引力,因为它引起了应用组件间不必要的耦合和不均衡的责任分配。
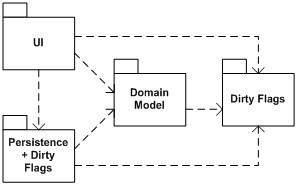
图 2 一个更吸引人的、顺应面向对象思想的选择,是将脏标记放到领域对象本身中去,这样每个领域对象都带有一个布尔型的脏属性,来表明它是不是脏的(图 3)。这样,任何组件想知道一个领域对象脏与否,可以直接问它。
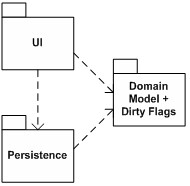
图 3 因此,我们把部分基础架构功能代码放在领域模型中,其部分原因就是我们希望从应用的不同部分都能拥有这些功能,而不会过度地增强耦合。用户界面部分不该知道如何向持久化组件询问脏标志,并且,我们宁愿在分层的应用架构中设计尽可能少的垂直层。
这个理由很重要,单凭它就足以让一些人考虑采纳本文将要检验的这种方法,不过我们还是先看看其他方法。但是在这样做之前,我们先粗略地看一下争论的另一方——我们在领域模型类中限制基础架构代码的原因。
肥领域模型反模式
让我们看看,引入脏标记、并在适当时机要求拦截唤醒脏标记之后,领域类会是什么样子。这是一个 C#代码的例子。
<span color="#0000ff">public class</span> Person : IDirty<br></br>{<br></br><span color="#0000ff">protected string</span> name;<br></br><span color="#0000ff">public virtual string</span> Name<br></br> {<br></br><span color="#0000ff">get</span> { <span color="#0000ff">return</span> name; }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (<span color="#0000ff">value</span> != name)<br></br> ((IDirty)<span color="#0000ff">this</span>).Dirty = <span color="#0000ff">true</span>;<br></br> name = <span color="#0000ff">value</span>;<br></br> }<br></br> }<p><span color="#0000ff">private bool</span> dirty;</p><br></br><span color="#0000ff">bool</span> IDirty.Dirty<br></br> {<br></br><span color="#0000ff">get</span> { <span color="#0000ff">return</span> dirty; }<br></br><span color="#0000ff">set</span> { dirty = <span color="#0000ff">value</span>; }<br></br> }<br></br>}<p><span color="#0000ff">public interface</span> IDirty</p><br></br>{<br></br><span color="#0000ff">bool</span> Dirty { <span color="#0000ff">get; set;</span> }<br></br>} 清单 1如例中所见,脏标记在接口(IDirty)中定义,然后该接口由类显式地实现。显式接口实现(explicit interface implementation)是 C#的一个良好的特性,它可以让我们避免在类的默认 API 中乱糟糟地堆满基础架构的相关成员。
这是有用的,例如在 Visual Studio IDE 中,除非将对象显示地转换为 IDirty 接口,否则 Dirty 标记在代码完成下拉菜单中是不可见的。事实上,可以从清单 2中看出,为了访问 Dirty 属性,对象首先必须转换为 IDirty 接口。
例子中的拦截代码只有两行(清单 2)。不过那是因为到目前为止,我们的例子中只有一个属性。如果我们有更多的属性,我们将不得不在每个 setter 方法中重复这两行代码,并将比较对象改成相对应的属性。
<span color="#0000ff">if</span> (<span color="#0000ff">value</span> != name)<br></br> ((IDirty<span color="#0000ff">)this</span>).Dirty = <span color="#0000ff">true</span>; 清单 2因此,写代码不会很难——并且我们的领域模型现在支持脏跟踪,应用中所有的组件只要用到对象模型都可以访问到脏跟踪信息。从不需要随时保留对象未经修改版本的拷贝来说,这种做法还是节省资源和快速的。
这种做法不利的一面是,你的领域模型类不再严格关注于商业业务。在领域模型类中忽然添加大量的基础架构代码,使得实际的业务逻辑代码变得更加难以理解,并且类本身变得更加不可靠、难以变更、难以维护。
如果脏跟踪是唯一必须插入到领域模型类中(或至少这样做有好处)的基础架构功能,我们可以不用过于担忧。但是不幸的是情况并非如此。这些功能的列表在不断增加,表 1中只列举了一些例子:
脏跟踪 对象持有一个脏标志,表示对象是否已经被修改、但仍未保存。基于拦截和新成员的引入(脏标记属性及其 getter、setter 方法)。 懒加载
对象第一次被访问的时候才加载对象状态。基于拦截和新成员的引入。 初始值跟踪 当一个属性被修改(但尚未保存)的时候,对象保留未修改值的拷贝。基于拦截和新成员的引入。
反转(Inverse)属性管理 双向关系中的一对属性自动保持同步。基于拦截。
数据绑定 对象支持数据绑定接口,从而在数据绑定情况下使用。基于新成员的引入(数据绑定接口的实现)。
复制 对象的变更分发到监听系统。基于拦截。
缓存 对象(或者至少是它们的状态,参见备忘录模式 [GoF 设计模式])拷贝到本地存储器中,随后的请求可以在本地存储器中查询,而不用到远程数据源。基于拦截和新成员的引入。
表 1这些功能——并且可能还有更多功能——都依赖于添加到领域类中的基础架构代码,干净、易于维护的领域模型忽然变得似乎遥远起来。
我曾经描述过这个问题,其中,领域模型类中的代码不断增长,以至变得很难处理,就像肥领域模型反模式[Helander 肥领域模型]。它和 Martin Fowler 描述的贫血领域模型反模式[Fowler 贫血领域模型] 正好相反,贫血领域模型反模式中领域模型类包含的逻辑过少。
Fowler 在他对贫血领域模型的描述中,解释了将业务逻辑放在领域模型之外是一种错误——实际上是一种反模式,因为不能充分利用面向对象的概念和构造。
我同意他的论点——我甚至会更进一步认为这句话对基础架构代码也一样成立。基础架构代码也可以通过分布在领域模型里,来利用面向对象的概念和构造。如果一刀切地避免在领域模型中放置任何基础架构代码,我们的代码也将沦为贫血领域模型反模式相关问题的牺牲品。
不允许在领域模型中添加基础架构代码——没有充分利用面向对象——由此带来的限制我们已经看过:在应用的不同组件之间共享基础架构功能变得更难,并且我们常常以低效率的“变通方法”而告终,比如用比较初始值来替代基于拦截的脏跟踪。甚至还有一些功能在没有拦截的情况下根本实现不了,如懒加载和反转属性管理。
那么,解决方案是什么呢?如果我们把所有的基础架构代码放置到领域模型类中,这些类就变得“肥胖不堪”——难于使用和维护。但是,如果我们把它放在领域模型类之外,我们又使其变为“贫血的”领域模型,基础架构代码不能充分利用由面向对象的潜力。
我们似乎进退维谷。更具体地说,在一个不易维护的肥领域模型和一堆与贫血领域模型共存的低效的变通办法之间,我们进退两难。这显然不是一个让人特别愉快的境遇。现在该解决这个存在很久的问题了:什么方法可以重构,让我们走出这片混乱?
使用一个公共的基础架构基类
一种想法是尝试将尽可能多的基础架构代码放到一个公共的基类中去,领域模型类继承该基类。然而,这个想法的主要问题在于,它对引进新的基础架构成员(像脏标记)到领域模型类中有用的,但是它没有为我们提供拦截,而拦截是我们想要支持的许多功能要求的。
基类方法的另一个问题是,当需要调整功能的应用方式的时候,它不能提供必要级别的粒度。如果不同的领域模型类有不同的基础架构需求,那么我们就会遇到问题。我们也许能用一组不同的基类(也许互相继承)来解决这些问题,但是如果我们遇到单一继承,比如 C#和 Java 的情况,要是领域模型本身也想使用继承,就没法这么做了。
为了明白这为什么会变成一个问题,让我们稍稍扩展一下我们的例子,使其变得稍微“生动”一些:假设我们有一个 Person 类,已经能够进行脏跟踪,还有一个 Employee 类同时具备脏跟踪和懒加载能力。最后,Employee 类需要继承 Person 类。
如果我们欣然把基础架构代码放进领域模型中,那么我们有一个像清单 1 的 Person 类,一个像清单 3 的 Employee 类。
<span color="#0000ff">public class</span> <span color="#00bfff">Employee : Person, ILazy</span><br></br>{<br></br><span color="#0000ff">public override string</span> Name<br></br> {<p><span color="#0000ff">get</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span><span color="#0000ff">)this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//call the persistence component<br></br> //and ask it to load the object<br></br> //with data from the data source<br></br> //(code omitted for brevity...)<br></br></span> }</p><br></br><span color="#0000ff">return base</span>.Name;<br></br> }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><br></br><span color="#0000ff">base</span>.Name = <span color="#0000ff">value</span>;<br></br> }<br></br> }<p><span color="#0000ff">private decimal</span> salary;</p><br></br><span color="#0000ff">public decimal</span> Salary<br></br> {<p><span color="#0000ff">get</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><p><span color="#0000ff">return</span> salary;</p><br></br> }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><p><span color="#0000ff">if (value</span> != salary)</p><br></br> ((<span color="#00bfff">IDirty</span>)<span color="#0000ff">this</span>).Dirty = <span color="#0000ff">true</span>;<p> salary = <span color="#0000ff">value</span>;</p><br></br> }<br></br> }<p><span color="#0000ff">private bool</span> loaded;</p><br></br> /// <span color="#696969"><summary></summary></span><br></br> ///<span color="#228b22">The Loaded property is "write-once" -<br></br> /// after you have set it to true you can not set<br></br> /// it to false again</span><p><span color="#696969">///</span><span color="#0000ff">bool</span> <span color="#00bfff">ILazy</span>.Loaded</p><br></br> {<br></br><span color="#0000ff">get { return</span> loaded; }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (loaded)<br></br><span color="#0000ff">return</span>;<p> loaded = <span color="#0000ff">value</span>;</p><br></br> }<br></br> }<br></br>} 清单 3正如你看到的,领域模型类中的实际业务内容有被淹没的危险,基础代码的膨胀已经开始悄悄蔓延了。肥领域模型就埋伏在前方,这种迹象应该促动我们尝试一种不同的方法——即使它可能在前面阶段更费事一点儿。我们这么做是因为就长期而言,我们希望一个干净的领域模型能够收回在可维护性和可用性上的投资。
因此,我们首先创建一个 DirtyBase 基类提供脏标志,然后我们创建一个 LazyBase 提供一个加载标志。使用多继承的语言,我们可以让 Person 类继承 DirtyBase 类,Employee 类继承 DirtyBase 和 LazyBase,如图 4 描绘的一样。
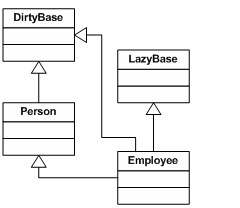
图 4 但是如果我们要使用的语言不支持多继承呢?好,我们能做的第一件事是让 LazyBase 类继承 DirtyBase(见图 5)。那样,我们仍让 Employee 类继承 LazyBase 类,并仍有脏标记和加载标记。它可能不是最佳的解决方案(如果我们有一个对象需要懒加载,但是不需要脏跟踪呢?),但是至少在这个例子中,它是一种选择。
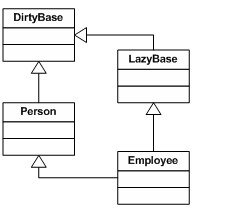
图 5 不过,这仍然给我们留了一个问题,在像 C#和 Java 这样的语言里面,Employee 类不能同时继承 Person 类和 LazyBase 类。在这些语言中,剩下的办法就是创建一个基类同时包括脏标记和加载标记(图 6),就让 Person 类继承一个多余的加载标记。
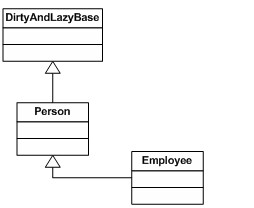 图 6 所以基类方法存在两个问题:它不能为许多功能(包括脏跟踪和懒加载)提供所需的拦截,并且(至少在单继承平台上)它导致领域类继承了一些它们并不必需的功能。
图 6 所以基类方法存在两个问题:它不能为许多功能(包括脏跟踪和懒加载)提供所需的拦截,并且(至少在单继承平台上)它导致领域类继承了一些它们并不必需的功能。
使用基础架构代理子类
幸运的是,面向对象提供了一个绝好的方法来一石击二鸟。为了同时提供拦截和粒度控制,我们所要做的就是创建继承领域模型类的子类——每个(具体的)领域模型类都有一个新子类。
这个子类能拦截对其基类成员的访问,通过重写(override)基类的成员来实现,重写的版本首先执行拦截相关的活动,然后将执行传递给基类的成员。
为了避免在所有的子类中都创建公共的基础架构成员(比如脏标记),仍然可以把它们放在所有领域类都会继承的公共基类里面;而少数类的专属功能,则可以将必要的成员放置在相关的子类中(图 7)。
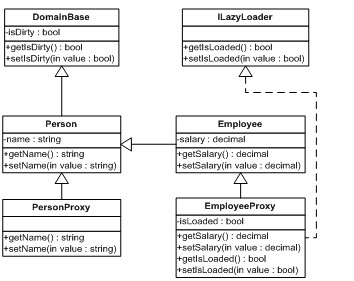
图 7公共基类实现了所有领域模型类公有的基础架构成员。不是所有领域类公用的那些功能则使用接口。
领域模型类脱离开了基础架构代码。
代理子类重写领域类成员来提供拦截。它们还实现了基础架构成员,这些成员不是所有领域类公有的。
用子类的方式来提供拦截,本质上是代理模式 [GoF 设计模式] 的一种实现。还有一种变种是使用领域模型接口——一个领域模型类一个接口——接口能被代理类和领域类同时实现(图 8)。
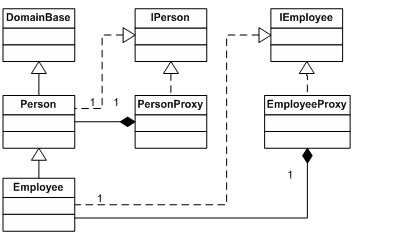 图 8 代理类在内部属性中持有一个领域类实例,它实现领域接口的时候把所有调用都转发给背后的领域对象。这实际上是在 Gang of Four 的《设计模式》[GoF 设计模式] 中描述的代理模式——只不过使用了子类来实现。
图 8 代理类在内部属性中持有一个领域类实例,它实现领域接口的时候把所有调用都转发给背后的领域对象。这实际上是在 Gang of Four 的《设计模式》[GoF 设计模式] 中描述的代理模式——只不过使用了子类来实现。
使用子类的好处是,你不必非要创建一堆没有其他用处的领域接口。同时还有一个好处,代理子类中的代码能使用“this”关键字(VB.NET 中是“Me”)调用继承自领域类的代码,而基于接口的代理中的代码将不得不通过内部属性来引用领域对象。子类还能访问受保护的成员,而基于接口的代理则要通过反射才能访问这些受保护的成员。
使用基于接口的代理还有另一个缺点,如果在领域类中有一个方法返回“this”的引用,调用代码就会得到一个“未代理”的领域类实例,这意味着脏跟踪和懒加载之类的功能在这个实例中是不可用的。
由于这些问题,我个人倾向于基于子类的代理方法,并且在整篇文章中我们会继续探讨这个方法。但是,请记住,在这篇文章中讨论的所有技术,也可以使用基于接口的代理方法来实现。
POJO/POCO 领域模型
如果我们比较一下刚刚讨论的基于代理模式的方法和我们先前的 C#例子代码,我们的领域类现在变得完全干净、没有任何基础架构代码,就像在清单 4 前面部分中看到的一样。所有的基础架构代码已经移到了基类和代理子类中,如清单 4 后面部分所示。
<span color="#228b22">//Domain Model Classes</span><br></br><span color="#0000ff">public class</span> <span color="#00bfff">Person : DomainBase</span><br></br>{<br></br><span color="#0000ff">protected string</span> name;<br></br><span color="#0000ff">public virtual string</span> Name<br></br> {<br></br><span color="#0000ff">get { return</span> name; }<br></br><span color="#0000ff">set</span> { name = <span color="#0000ff">value</span>; }<br></br> }<br></br> }<p><span color="#0000ff">public class</span> <span color="#00bfff">Employee : Person</span></p><br></br> {<br></br><span color="#0000ff">protected decimal</span> salary;<br></br><span color="#0000ff">public virtual decimal</span> Salary<br></br> {<br></br><span color="#0000ff">get { return</span> salary; }<br></br><span color="#0000ff">set</span> { salary = <span color="#0000ff">value</span>; }<br></br> }<br></br>}<p><span color="#228b22">//Infrastructure Base Class</span><span color="#0000ff">public class</span> <span color="#00bfff">DomainBase : IDirty</span></p><br></br>{<br></br><span color="#0000ff">private bool</span> dirty;<br></br><span color="#0000ff">bool</span> <span color="#00bfff">IDirty</span>.Dirty<br></br> {<br></br><span color="#0000ff">get { return</span> dirty; }<br></br><span color="#0000ff">set</span> { dirty = <span color="#0000ff">value</span>; }<br></br> }<br></br>}<p><span color="#228b22">//Infrastructure Proxy Subclasses</span><span color="#0000ff">public class</span> <span color="#00bfff">PersonProxy : Person</span></p><br></br>{<br></br><span color="#0000ff">public override string</span> Name<br></br> {<br></br><span color="#0000ff">get { return</span> base.Name; }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if (value</span> != <span color="#0000ff">this</span>.name)<br></br> ((<span color="#00bfff">IDirty</span>)<span color="#0000ff">this</span>).Dirty = <span color="#0000ff">true</span>;<br></br><span color="#0000ff">base</span>.Name = <span color="#0000ff">value</span>;<br></br> }<br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">EmployeeProxy : Employee, ILazy</span></p><br></br>{<p><span color="#0000ff">public override string</span> {</p><p><span color="#0000ff">get</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//call the persistence component<br></br> //and ask it to load the object<br></br> //with data from the data source<br></br> //(code omitted for brevity...</span> }</p><br></br><span color="#0000ff">return base</span>.Name;<br></br> }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><p><span color="#0000ff">if (value</span> != <span color="#0000ff">this</span>.name)</p><br></br> ((<span color="#00bfff">IDirty</span>)<span color="#0000ff">this</span>).Dirty = <span color="#0000ff">true</span>;<p><span color="#0000ff">base</span>.Name = <span color="#0000ff">value</span>;</p><br></br> }<br></br> }<p><span color="#0000ff">public override decimal</span> Salary</p><br></br> {<p><span color="#0000ff">get</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><br></br><span color="#0000ff">return base</span>.Salary;<br></br> }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (!loaded)<br></br> {<br></br> ((<span color="#00bfff">ILazy</span>)<span color="#0000ff">this</span>).Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><p><span color="#0000ff">if (value</span> != <span color="#0000ff">this</span>.salary)</p><br></br> ((<span color="#00bfff">IDirty</span>)<span color="#0000ff">this</span>).Dirty = <span color="#0000ff">true</span>;<p><span color="#0000ff">base</span>.Salary = <span color="#0000ff">value</span>;</p><br></br> }<br></br> }<p><span color="#0000ff">private bool</span> loaded;</p><br></br> /// <span color="#696969"><summary></summary></span><br></br> /// <span color="#228b22">The Loaded property is "write-once" -<br></br> /// after you have set it to true you can not set<br></br> /// it to false again</span><br></br> ///<span color="#696969"> </span><br></br><span color="#0000ff">bool</span> <span color="#00bfff">ILazy</span>.Loaded<br></br> {<br></br><span color="#0000ff">get { return</span> loaded; }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (loaded)<br></br><span color="#0000ff">return</span>;<p> loaded = <span color="#0000ff">value</span>;</p><br></br> }<br></br> }<br></br>} 清单 4通过与公共基类结合使用的代理模式,我们成功解决了我们看到的所有问题,无论到目前为止嘲弄我们的这些问题是来自于贫血领域模型反模式,还是肥领域模型反模式:
- 我们能将有关的基础架构代码分布到领域模型中,使我们应用中的所有部分都很容易访问,并使它能用面向对象和高效率的方法实现。
- 我们能够把我们想要的基础架构代码都分布到领域模型中,但避免了肥领域模型的结局。事实上,我们实际的领域模型类中的代码,仍然能够保持干净,完全集中在它们需要关注的业务方面。
- 我们可以混合搭配,只增加每个领域模型类需要的基础架构代码。
- 我们能构建需要拦截支持的功能。
应该注意,按照 POJO/POCO 的严格定义,我们的领域模型类不应该继承基础架构基类。不过,我们可以很容易改过来,只要将所有的逻辑从公共基类移到代理子类中去,就可以得到一个完全的 POJO/POCO 领域模型。如果一定要满足严格的 POJO/POCO,我们的方法很容易满足这项要求,只是举手之劳。如果不强求,我们可以使用基类,此时领域模型类的代码仍然完全不包含任何实际的基础架构代码。
因此到目前为止我们已经整理出了一个架构,能让我们把完全 POJO/POCO 的领域模型类和将基础架构代码分布到领域模型中去的目标结合在一起。如果我们的目标仅仅是避免肥领域模型,而不强求符合 POJO/POCO 定义,那么我们就能走“半 POJO/POCO”的路线,用一个公共基类来节省一些工作。
使用抽象工厂模式
这听起来很棒,对不对?你可能在想,用它是不是没有任何问题呢。软件业的人都有些吹毛求疵,你大概已经在疑心有那么一两个棘手问题该冒头了吧。
你是对的。有两件值得关注的事情马上就自己显现出来了。第一个相当轻微:为了让子类能够重写领域模型类的成员,并提供拦截,所有的领域模型成员(或至少打算拦截的那些成员)必须是虚拟的。
第二个问题好像更为糟糕一些:既然你想让你的程序使用代理子类的实例,你必须在应用代码中查找所有创建领域模型类实例的地方,将它们改成创建相应的代理子类的实例。
要修改已存在的应用,听起来像个噩梦吧?没错。要想避免这种大规模的查找和替换操作,只有一条出路,就是从一开始就避免使用“new”关键字来创建领域模型类的实例。
避免"new"的传统方法就是使用抽象工厂模式 [GoF 设计模式]。调用一个工厂类的 Create() 方法,而不是任由客户代码使用“new”来创建实例。Create() 方法负责调用“new”,并且在返回新的实例之前会对其做一些额外的相关设置操作。
如果你在调用领域模型的时候全都使用抽象工厂模式,那就最好不过了,接下来你只要在代码中改一个地方——工厂类——将返回领域类实例改为返回代理子类(或者是基于接口的代理)的实例。
这是使用抽象工厂模式来实例化所有的领域对象的一个重要理由——至少使用像 Java 和 C#这样的语言时是这样,这些语言不允许奇异特性,比如不能像 C++ 一样重载(overload)成员取用运算子,不能像 ObjectiveC 一样改变“new”关键字的行为,也不能像 Ruby 一样在运行时修改类。
继承反射
对于代理子类的方法,还有一个问题值得一提。虽然只是一种极端情况,但是它相当隐蔽,如果你陷入这个问题却不知道是什么引起的,会被它狠狠咬上一口。
如果你看一下图 9,你会发现 Employee 继承 Person 类,这是应该的:无论什么时候,如果一个方法期望 Person 对象,那么传递给它 Employee 对象应该也能工作。此外,PersonProxy 类继承 Person 类。这也很好,因为这意味着将一个 PersonProxy 对象作为参数传递给期望 Person 对象的方法也是“合法的”。
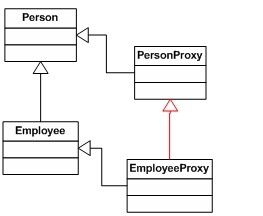
图 9以同样的方式,EmployeeProxy 继承 Employee,意味着你能把一个 EmployeeProxy 对象作为参数传递给任何期望 Employee 对象的方法。最后,由于 EmployeeProxy 继承 Employee,Employee 又继承 Person,这表明 EmployeeProxy 继承 Person。因此,任何期望 Person 对象的方法也可以接受 EmployeeProxy 对象。
所有一切都符合我们的期望。当我们让抽象工厂开始返回代理对象而不是领域模型类的简单实例时,有一点是很重要的,我们希望客户端代码仍然继续正常运行,而无需重新考虑如何处理我们的类型层次。
换句话说,如果我们原来向一个期望 Person 对象的方法传递 Employee 对象给,当我们忽然换成给它传递 EmployeeProxy 对象的时候,我们的代码必须还能正常编译(并且工作)。幸运的是,由于 EmployeeProxy 继承 Employee,并且 Employee 继承 Person,所以没有问题。
事实上,当开始使用代理来代替领域模型对象时,一切都将如常继续运转,正如我们希望的。只不过,有一个个非常微小的例外。
图 9 中的红色继承线表示 EmployeeProxy 不继承 PersonProxy。这什么时候会带来问题呢?
好,考虑一下这样一个方法,它接受两个对象,并用反射来确定其中一种对象是否是另一种对象的子类。当我们把一个 Person 对象和一个 Employee 对象传递给该方法时,它会返回 true。但是当我们把一个 PersonProxy 对象和一个 EmployeeProxy 对象传递给该方法时,突然它就返回 false 了。
除非你有基于反射的、检查继承层次的代码,不然应该是安全的。但是万一你真的有这样的代码,这里先警告一下也没坏处(你可以通过修改反射代码来避开这个问题,让它检测代理类型,并一路向上直到找到一个非代理类型)。
使用混入(Mixin)和拦截器类
我们已经向着可维护的领域模型架构努力了很长时间,让它能容下一个有效率的、可访问的基础架构来实行运行时领域模型管理。
我们是否可以做得更多呢?
让我们开始看一下那些只针对某些领域类、而不是全部领域类的功能——对于这些功能,我们需要将所需的基础架构成员放在代理子类中,而不是在公用的基类中。在我们的例子中,为懒加载功能设置的加载标记将必须添加到需要支持懒加载的每个类的子类中。
由于我们可能需要在多个子类中放相同的代码,所以我们明显会导致代码重复。只有一个标记的时候情况还好,但是对于需要多个属性、甚至需要多个有复杂实现的方法的功能呢?
在我们的例子中,加载标记是一次写入(write-once),所以在变成 true 之后不能再切换回来。因此,在 setter 方法中,我们有一些代码来实施这个规则——在需要懒加载的每个领域模型类的子类中,我们都要在 setter 方法中重复的那些代码。
我们会希望创建一个可重用的类来包含这种逻辑。但是,我们已经用了继承(仍然假定我们工作在单继承平台上),那么这个懒加载类该怎样被重用呢?一个很好的答案就是使用组合模式[GoF Design Patterns],而不是为此采用继承。使用这种模式,EmployeeProxy 子类将包含一个内部属性来引用可重用的懒加载类的实例(图 10)。
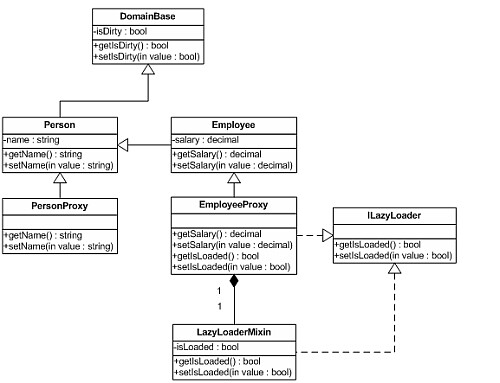 图 10这种可重用的类常常被称为混入(mixin),它反映了这样一个事实,即实现被加入到类型中,而不是成为继承层次的一部分。使用混入的作用是,让单继承语言(甚至是在只支持接口继承的平台上,比如 COM+)也能够获得类似多重继承的效果。
图 10这种可重用的类常常被称为混入(mixin),它反映了这样一个事实,即实现被加入到类型中,而不是成为继承层次的一部分。使用混入的作用是,让单继承语言(甚至是在只支持接口继承的平台上,比如 COM+)也能够获得类似多重继承的效果。
有一点可以补充说明一下,使用我们这种组合方式,以混入的形式存在的行为和状态能动态地被加到目标类中(使用依赖注入),而不是静态地绑定到目标上去(如果行为是继承下来的就会如此)。尽管在这篇文章中我们不会更多关注于如何利用它的潜能,但是它为支持一些非常灵活和动态的场景提供了非常大的空间。
通过将子类引入的成员分离到一个可重用的混入类,我们向一个真正模块化、一致的、内聚的架构迈进了一大步,这个架构还是低耦合的、高度代码可重用的。我们能向这个方向再进一步吗?
那么,接下来要做的事就是把拦截代码从子类中分离出来,并放到可重用的类里面。这些拦截器类会像混入一样包含在代理子类里面,如图 11.
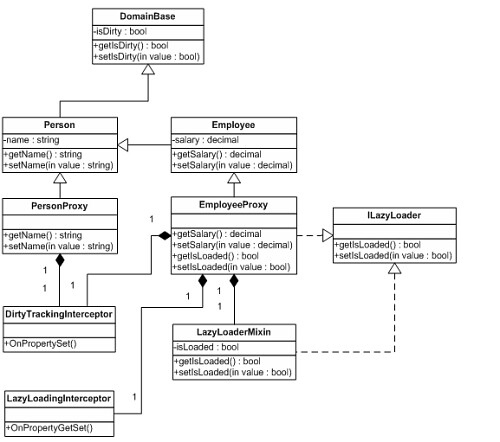 图 11 Person、Employee 和 DomainBase 与代码的上一个版本保持不变,但是 PersonProxy 和 EmployeeProxy 发生了变化,并且我们引入了两个新的拦截器类和一个新的混入类。清单 5 显示了我们进行这些重构(不包括未修改的类)之后代码的样子。
图 11 Person、Employee 和 DomainBase 与代码的上一个版本保持不变,但是 PersonProxy 和 EmployeeProxy 发生了变化,并且我们引入了两个新的拦截器类和一个新的混入类。清单 5 显示了我们进行这些重构(不包括未修改的类)之后代码的样子。
<span color="#228b22">//These proxy subclasses contain only boilerplate<br></br>//code now. All actual logic has been refactored<br></br>//out into mixin and interceptor classes.</span><br></br><span color="#0000ff">public class</span> <span color="#00bfff">PersonProxy : Person<br></br>{<br></br><span color="#0000ff">private</span> DirtyInterceptor</span> dirtyInterceptor = <span color="#0000ff">new</span> <span color="#00bfff">DirtyInterceptor</span>();<p><span color="#0000ff">public override string</span> Name</p><br></br> {<br></br><span color="#0000ff">get { return</span> base.Name; }<p><span color="#0000ff">set</span> {</p><br></br> dirtyInterceptor.OnPropertySet(<span color="#0000ff">this, this</span>.name, <span color="#0000ff">value</span>);<br></br><span color="#0000ff">base</span>.Name = <span color="#0000ff">value</span>;<br></br> }<br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">EmployeeProxy : Employee, ILazy</span></p><br></br>{<br></br><span color="#228b22">//This mixin contains the implementation<br></br> //of the ILazy interface</span>.<br></br><span color="#0000ff">private</span> ILazy lazyMixin = <span color="#0000ff">new</span> <span color="#00bfff">LazyMixin</span>();<p><span color="#0000ff">private</span> <span color="#00bfff">LazyInterceptor</span> lazyInterceptor = <span color="#0000ff">new</span> <span color="#00bfff">LazyInterceptor</span>();</p><br></br><span color="#0000ff">private</span> DirtyInterceptor dirtyInterceptor = <span color="#0000ff">new</span> <span color="#00bfff">DirtyInterceptor</span>();<p><span color="#0000ff">public override string</span> Name</p><br></br> {<p><span color="#0000ff">get</span> {</p><br></br> lazyInterceptor.OnPropertyGetSet(<span color="#0000ff">this</span>, <span color="#8b0000">"Name"</span>);<br></br><span color="#0000ff">return base</span>.Name;<br></br> }<p><span color="#0000ff">set</span> {</p><br></br> lazyInterceptor.OnPropertyGetSet(<span color="#0000ff">this</span>, <span color="#8b0000">"Name"</span>);<br></br> dirtyInterceptor.OnPropertySet(<span color="#0000ff">this, this</span>.name, <span color="#0000ff">value</span>);<br></br><span color="#0000ff">base</span>.Name = <span color="#0000ff">value</span>;<br></br> }<br></br> }<p><span color="#0000ff">public override decimal</span> Salary</p><br></br> {<p><span color="#0000ff">get</span> {</p><br></br> lazyInterceptor.OnPropertyGetSet(<span color="#0000ff">this</span>, <span color="#8b0000">"Salary"</span>);<br></br><span color="#0000ff">return base</span>.Salary;<br></br> }<p><span color="#0000ff">set</span> {</p><br></br> lazyInterceptor.OnPropertyGetSet<span color="#0000ff">(this</span>, <span color="#8b0000">"Salary"</span>);<br></br> dirtyInterceptor.OnPropertySet(<span color="#0000ff">this, this</span>.name, <span color="#0000ff">value</span>);<br></br><span color="#0000ff">base</span>.Salary = <span color="#0000ff">value</span>;<br></br> }<br></br> }<p><span color="#228b22">//The ILazy interface is implemented<br></br> //by forwarding the calls to the mixin,<br></br> //which contains the actual implementation</span>.</p><br></br><span color="#0000ff">bool</span> <span color="#00bfff">ILazy</span>.Loaded<br></br> {<br></br><span color="#0000ff">get { return</span> lazyMixin.Loaded; }<br></br><span color="#0000ff">set</span> { lazyMixin.Loaded = <span color="#0000ff">value</span>; }<br></br> }<br></br>}<p><span color="#228b22">//The following mixin and interceptor classes<br></br>//contain all the actual infrastructural logic<br></br>//associated with the dirty tracking and<br></br>//the lazy loading features.</span><span color="#0000ff">public class</span> <span color="#00bfff">LazyMixin : ILazy</span></p><br></br>{<br></br><span color="#0000ff">private bool</span> loaded;<br></br> /// <summary></summary><br></br> /// <span color="#228b22">The Loaded property is "write-once" -<br></br> /// after you have set it to true you can not set<br></br> /// it to false again</span><br></br> /// <br></br><span color="#0000ff">bool</span> ILazy.Loaded<br></br> {<br></br><span color="#0000ff">get { return</span> loaded; }<p><span color="#0000ff">set</span> {</p><br></br><span color="#0000ff">if</span> (loaded)<br></br><span color="#0000ff">return</span>;<p> loaded = value;</p><br></br> }<br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">DirtyInterceptor</span></p><br></br>{<br></br><span color="#0000ff">public void</span> OnPropertySet(<br></br><span color="#0000ff">object</span> obj,<br></br><span color="#0000ff">object</span> oldValue,<br></br><span color="#0000ff">object</span> newValue)<br></br> {<br></br><span color="#0000ff">if</span> (!oldValue.Equals(newValue))<br></br> {<br></br><span color="#00bfff">IDirty</span> dirty = obj <span color="#0000ff">as</span> <span color="#00bfff">IDirty</span>;<br></br><span color="#0000ff">if</span> (dirty != <span color="#0000ff">null</span>)<br></br> dirty.Dirty = <span color="#0000ff">true</span>;<br></br> }<br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">LazyInterceptor</span></p><br></br>{<br></br><span color="#0000ff">public void</span> OnPropertyGetSet(<span color="#0000ff">object</span> obj)<br></br> {<br></br><span color="#00bfff">ILazy</span> lazy = obj as <span color="#00bfff">ILazy</span>;<br></br><span color="#0000ff">if</span> (lazy != null)<br></br> {<br></br><span color="#0000ff">if</span> (!lazy.Loaded)<br></br> {<br></br> lazy.Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><br></br> }<br></br> }<br></br>} 清单 5通过重构,最终所有实际的基础架构逻辑都被放进了混入和拦截器类,代理子类变得很苗条,变成专注于转发请求到拦截器和混入的轻量级类。事实上,在这一点上,代理子类里面除了由很容易被代码生成工具生成的样板代码之外,再没其它什么内容。
一种选择是在设计时生成代理子类的代码,但是像 C#和 Java 这样的语言能让你在运行时生成、编译、执行代码。因此,我们也可以选择在运行时生成代理子类,这种做法就是俗称的运行时子类化(runtime subclassing)。
花一点儿时间回头想想我们走了多远。在第一步,我们将肥领域模型重构为带有代理子类的 POJO/POCO 领域模型(还可选择增加一个基类),同时基础架构代码仍然分布在领域模型中。在重构的第二步,所有实际的基础架构逻辑从代理子类分离了出来,并加入到可重用的混入和拦截器类,在代理子类中只留下了样板代码。
在最后一步,我们转向使用运行时代码生成器来为样板代理子类生成全部代码。就这样我们一路跋涉到了面向方面编程的疆界。
使用面向方面编程
很长一段时间,我对 AOP 的大肆宣传都感到很新奇,每次我尝试研究它是怎么一回事的时候,就会完全迷惑——这主要因为 AOP 社区坚持使用他们哪种奇怪的术语。而且常常有一些(不是全部!)AOP 倡导者似乎在故意让这个领域看起来那么的不同,让人兴奋并觉得胆怯。
因此,如果说读到这里,实际上你已经掌握了面向方面编程的所有主要概念,你可能会感到惊讶——不但如此,而且你已经看到了 AOP 框架在背后是如何运作的,从头到脚。
面向方面编程使用了“方面”这个核心概念,方面简单来说是一组引介(introductions,即混入)和通知(advice,即拦截器)。方面(拦截器和混入)可以通过运行时子类化(runtime subclassing)的方式(以及其他技术)在运行时应用于现有的类。
正如你看到的,你已经理解了大部分怪异但重要的 AOP 术语。被大量用来描述方面对什么有益的术语横切(crosscutting)关注点,简单意思就是你有一个能应用于大多数(不一定属于同一个继承树的)类的功能——例如我们的脏跟踪和懒加载功能,这些功能就是横切跨领域模型的关注点。
我们至今还未真正涵盖、唯一真正重要的 AOP 术语是连接点(join point)和切点(pointcutting)。连接点是目标类中的一个地方,你可以在那里应用拦截器或混入。通常,拦截器所关心的连接点是方法,而混入所关心的连接点则是类本身。简单地说,连接点就是你能加入方面的点。
为了确定哪个方面应该被应用到哪个连接点,你可以使用切点语言。这个语言可以很简单,可以是描述性的语言,比如你可能只是在一个 xml 文件中命名方面、命名连接点组合;但是也有复杂的可以使用正则表达式、甚至完整的领域特定语言(Domain Specific Languages)来进行更高级的“切点“。
到目前为止,我们还尚未关注切点,因为我们已经在我们需要的地方手工应用了我们的方面(我们的混入和拦截器)。但是,如果我们要想走完最后的一步,为应用我们的方面而使用 AOP 框架,我们还是需要考虑这个问题。
但在我们做之前,先让我们停下来思索一下这个计划。在我们前面已经完成那么多重构之后,现在加入 AOP 框架步子其实并不大。它仅仅是很小的一步,因为我们已经有效地重构了我们的应用,使其使用拦截器(通知)和混入(介绍)形式的方面。
事实上,我会认为我们实质上已经在利用 AOP 了——我们只是还没有用 AOP 框架来为我们自动化那些例行公事的部分。但是我们利用着来自 AOP 的所有基本的概念(拦截和混入),并且我们用一种可重用的方式处理横切关注点。这听起来像极了 AOP 的定义,所以 AOP 框架能帮助我们自动化完成之前的一些手工工作是一点儿也不会令人感到意外的。
目前拦截器和混入类中的代码只要轻微地修改一下就是方面了——它已经被重构为一个泛化的、可重用的形式,这正是方面应该具有的形式。我们需要 AOP 框架做的只是以某种方式帮助我们将方面应用到领域模型类中。如前所述,AOP 框架有许多方式可以做到这一点,其中一种方式是在运行时生成代理子类。
如果用的是运行时子类化框架,生成的代理子类代码看起来会和我们例子中代理子类的样板代码非常近似。换句话说,它很容易生成。如果你认为你可以写一个代码生成器来完成任务,那么你就在实现你自己的 AOP 框架引擎的半路上了。
重构到方面
在我们最后的重构中,我们将看一下,如果我们使用一个 AOP 框架来应用我们的拦截器和混入,那么我们的例子代码会怎样。在这个例子中,我将使用 NAspect,这是 Roger Johansson 和我合作完成的一个针对.NET 的开源 AOP 框架。NAspect 使用运行时子类来运用方面。
读到这里,至今你应该不难理解 NAspect 执行的“花招”——它简单地生成包含样板代码的代理子类,样板代码需要转发请求到混入和拦截器,并且它使用标准的、面向对象的、领域类成员的重写,来提供拦截。
很多人把 AOP 和最糟糕的巫术联系在一起。奇怪的术语已经令人怯步,开发人员在领域类代码中预见不到的事情忽然并“毫无察觉”地发生在拦截器中,令很多人遭受打击,深深地感到不安。
当然,具体了解这些术语是什么意思会有帮助。能理解至少一种运用方面的方法也是有帮助的,至少能让你看到这不是什么魔术——只是几个良好的、成熟的、众所周知的、面向对象的设计模式在发挥作用。
AOP 就是用我们熟知的面向对象来对付横切关注点。AOP 框架只是让你能够更舒服地运用方面,不用自己手写许多代理子类。
所以,现在我们不会再被 AOP 给吓到了,让我们看看我们如何使用它来使我们的应用向终点线迈出最后一步。
在这个例子里,我们要做的第一件事情是包含一个对 NAspect 框架程序集的引用。准备好之后,我们就可以开始创建我们的方面、确定我们的切点。我们也可以直接删除 PersonProxy 和 EmployeeProxy 类——从现在开始,NAspect 会为我们生成这些类。
如果我们愿意,我们甚至可以删除 DomainBase 基类——没有必要使用基类来应用公用于所有基类的混入,我们也可以使用 AOP 框架来做这些。这意味着,通过使用 AOP 框架,我们甚至可以无需任何额外工作就能满足 POJO/POCO 的严格要求。
为了除去基类,我们只需要把功能移到混入中去。就我们的情况而言,我们仅需要再创建一个混入——DirtyMixin,它持有先前放在基类中的脏标记。
LazyMixin 类中的代码完全保持不变,所以这里不再列出。实际上,我们真正需要去做的是创建新的 DirtyMixin 类,并稍微修改两个拦截器中的代码,让它们使用 NAspect 传进来的描述被拦截方法的数据结构。
我们还需要修改我们的工厂类,以便它使用 NAspect 来为我们创建代理子类。这假定我们已经在应用中的所有地方都转为使用抽象工厂模式。如果我们还没有这样做,现在我们一定要汲取教训,因为没有抽象工厂模式,我们将不得不进行另一项庞大的搜索、替换操作,仔细检查代码中每一个代理子类被实例化的地方,改为调用 NAspect 运行时子类化引擎。
重构后的代码如清单 6 所示,准备好使用 NAspect。
<span color="#0000ff">public class</span> <span color="#00bfff">DirtyMixin : IDirty</span><br></br>{<br></br><span color="#0000ff">private bool</span> dirty;<br></br><span color="#0000ff">bool</span> <span color="#00bfff">IDirty</span>.Dirty<br></br> {<br></br><span color="#0000ff">get { return</span> dirty; }<br></br><span color="#0000ff">set</span> { dirty = value; }<br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">DirtyInterceptor : IAroundInterceptor</span></p><br></br>{<br></br><span color="#0000ff">public object</span> HandleCall(<span color="#00bfff">MethodInvocation call</span>)<br></br> {<br></br><span color="#00bfff">IDirty</span> dirty = call.Target <span color="#0000ff">as</span> <span color="#00bfff">IDirty</span>;<p><span color="#0000ff">if</span> (dirty != <span color="#0000ff">null</span>)</p><br></br> {<p><span color="#228b22">//Extract the new value from the call object</span><span color="#0000ff">object</span> newValue = call.Parameters[0].Value;</p><p><span color="#228b22">//Extract the current value using reflection</span><span color="#0000ff">object</span> value = call.Target.GetType().GetProperty(</p><br></br> call.Method.Name.Substring(4)).GetValue(<br></br> call.Target, <span color="#0000ff">null</span>);<p><span color="#228b22">//Mark as dirty if the new value is<br></br> //different from the old value</span><span color="#0000ff">if</span> (!value.Equals(newValue))</p><br></br> dirty.Dirty = <span color="#0000ff">true</span>;<br></br> }<p><span color="#0000ff">return</span> call.Proceed();</p><br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">LazyInterceptor : IAroundInterceptor</span></p><br></br>{<br></br><span color="#0000ff">public object</span> HandleCall(<span color="#00bfff">MethodInvocation</span> call)<br></br> {<br></br><span color="#00bfff">ILazy</span> lazy = call.Target <span color="#0000ff">as</span> <span color="#00bfff">ILazy</span>;<p><span color="#0000ff">if</span> (lazy != <span color="#0000ff">null</span>)</p><br></br> {<br></br><span color="#0000ff">if</span> (!lazy.Loaded)<br></br> {<br></br> lazy.Loaded = <span color="#0000ff">true</span>;<p><span color="#228b22">//perform lazy loading...<br></br> //(omitted)</span> }</p><br></br> }<p><span color="#0000ff">return</span> call.Proceed();</p><br></br> }<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">Factory</span></p><br></br>{<br></br><span color="#0000ff">public static</span> <span color="#00bfff">IEngine</span> engine = <span color="#00bfff">ApplicationContext</span>.Configure();<p><span color="#0000ff">public static</span> Domain.<span color="#00bfff">Person</span> CreatePerson()</p><br></br> { <span color="#0000ff">return</span> engine.CreateProxyPerson>();<br></br> }<p><span color="#0000ff">public static</span> Domain.<span color="#00bfff">Employee</span> CreateEmployee()</p><br></br> {<br></br><span color="#0000ff">return</span> engine.CreateProxyEmployee>();<br></br> }<br></br>} 清单 6为了知道你的方面要应用到哪个类,NAspect 在程序的配置文件中使用一个 xml 配置段(也有其它选择)。现在我们可以在 xml 文件中定义方面,指出混入和拦截器类的类型,以及我们想应用的类型。大体上,我们准备好了尝试一下我们的 AOP 应用。
不过,仍然有一点让许多开发人员对使用 AOP 犹豫不决,甚至当他们理解了 AOP 的术语和理论,那就是由于切点体系定义得不完善而带来的脆弱性。
虽然我们通过一些巧妙的正则表达式来筛选出打算应用方面的类和成员,但风险是当领域模型变化的时候,你可能会忘了更新切点定义,以致正则表达式忽然筛选到了不应该应用方面的类。就是这类问题给 AOP 带来了巫术的坏名声。
处理切点不明确的一个方式是创建自定义的.NET 属性(Attribute)(Java 中的注释(annotations))。用自定义属性装饰领域模型,然后使用属性做为切点目标,这样就可以避免使用正则表达式之类的小花招。方面只应用于我们决定该应用的地方,通过在那里放置属性。
因此根据我们的情况,我们继续创建两个自定义属性——LazyAttribute 和 DirtyAttribute——接下来我们使用它们来装饰我们的类(清单 7)。
<span color="#0000ff">public class</span> <span color="#00bfff">DirtyAttribute : Attribute</span><br></br>{<br></br>}<p><span color="#0000ff">public class</span> <span color="#00bfff">LazyAttribute : Attribute</span></p><br></br>{<br></br>}<p>[Dirty]</p><br></br><span color="#0000ff">public class</span> <span color="#00bfff">Person : DomainBase</span><br></br>{<br></br><span color="#0000ff">protected string</span> name;<br></br><span color="#0000ff">public virtual string</span> Name<br></br> {<br></br><span color="#0000ff">get { return</span> name; }<p><span color="#00bfff">[Dirty]</span><span color="#0000ff">set</span> { name = <span color="#0000ff">value</span>; }</p><br></br> }<br></br>}<p><span color="#00bfff">[Dirty]<br></br>[Lazy]</span><span color="#0000ff">public class</span> <span color="#00bfff">Employee : Person</span></p><br></br>{<br></br><span color="#0000ff">protected decimal</span> salary;<br></br><span color="#0000ff">public virtual decimal</span> Salary<br></br> {<p><span color="#00bfff">[Lazy]</span><span color="#0000ff">get { return</span> salary; }</p><p><span color="#00bfff">[Dirty]<br></br> [Lazy]</span><span color="#0000ff">set</span> { salary = <span color="#0000ff">value</span>; }</p><br></br> }<p><span color="#0000ff">public override string</span> Name</p><br></br> {<p><span color="#00bfff">[Lazy]</span><span color="#0000ff">get { return</span> name; }</p><p><span color="#00bfff">[Dirty]<br></br> [Lazy]</span><span color="#0000ff">set</span> { name = <span color="#0000ff">value</span>; }</p><br></br> }<br></br>} 清单 7我们接着在应用的配置文件中定义我们的切点(清单 8),让方面以我们自定义的属性为目标。
<br></br><configuration></configuration><br></br><configsections></configsections><p> name="naspect" </p><br></br> type="Puzzle.NAspect.Framework.Configuration.NAspectConfigurationHandler, Puzzle.NAspect.Framework.NET2"/><br></br><configuration></configuration><p> name="DirtyAspect"</p><br></br> target-attribute="InfoQ.AspectsOfDMM.Attributes.DirtyAttribute, InfoQ.AspectsOfDMM" ><p> target-attribute="InfoQ.AspectsOfDMM.Attributes.DirtyAttribute, InfoQ.AspectsOfDMM" ></p><p> type="InfoQ.AspectsOfDMM.Aspects.DirtyInterceptor, InfoQ.AspectsOfDMM" /></p><p> name="LazyAspect"</p><br></br> target-attribute="InfoQ.AspectsOfDMM.Attributes.LazyAttribute, InfoQ.AspectsOfDMM" ><p> target-attribute="InfoQ.AspectsOfDMM.Attributes.LazyAttribute, InfoQ.AspectsOfDMM" ></p><p> type="InfoQ.AspectsOfDMM.Aspects.LazyInterceptor, InfoQ.AspectsOfDMM" /></p>现在,我们最后测试一下我们的 AOP 应用。当我们运行应用时,NAspect 会在运行时为我们生成代理子类,并在子类中插入样板代码来将所有的请求转发到拦截器和混入类。
程序最后的架构可参看图 12。注意,这个版本和先前非 AOP 版本之间的唯一实际差别是,两个代理类(使用虚线边框标识)将由 AOP 框架生成,而之前我们必须手工编码。
与图 11 比较,我们多了一个 DirtyTrackerMixin 类和一个新的 IDirtyTracker 接口,来代替 DomainBase 基类,但这些东西哪怕我们不使用 AOP,只要决定不使用公共基础架构基类(以满足更严格的 POJO/POCO 需求)就是要有的。换句话说,如果我们不想使用一个公共基类,不管我们是否使用 AOP 框架,我们最终都会得到一样的架构(图 12 所示)。
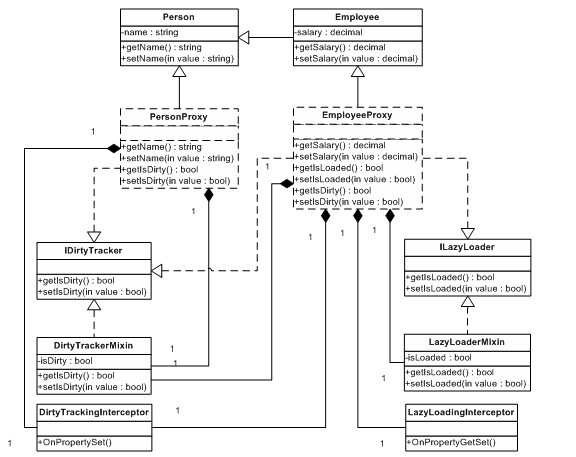
图 12 ### 切点选项
当你添加新的领域模型类时,要想使它们能够懒加载和脏跟踪,只需要用自定义属性装饰它们,就会”变魔术一样地“获得相应功能了。
用属性 / 注释来作为切点目标,很快你就会注意到,由于每项功能对应一个属性,很快领域模型中每个成员的属性就太多了。因此,为了减少属性的数量,你可能想找到它们之间的抽象性。
如果你适应基于正则表达式的切点方法,并且你觉得属性令领域模型变得杂乱,使得保持领域模型与基础架构关注点完全无关的目标受到了损害,那么另一种选择是,你可以只配置你的 xml 配置文件来匹配相关的目标类,并且不需要用自定义属性装饰你的领域类。
另外,NAspect 的 xml 切点语言(像许多其它的 AOP 框架一样)允许你简单地提供一个完整的类型清单,方面会运用于列出的类型,让你不用去找到一个刚好只匹配正确类的正则表达式。这使配置文件变得更长,但是能让你的领域模型保持完全干净。
在使用切点来动态运用方面的地方使用 AOP 框架,还有一个好处就是,当方面被用在不同的用例中时,把不同的方面应用于相同的类中会变得很容易。如果一个用例要求某个领域类懒加载,而另一个用例不需要,那么只有第一个用例需要使用应用懒加载方面的配置文件。
这个动态的方面应用可以非常强大,比如在测试场景可以额外应用一些测试用的方面,提供 mocking 之类的功能。
使用面向方面编程的结论
我们是否可以在领域模型中放置任何基础架构代码,这是我们开始时的问题。我们看到,这绝对可取,因为它令许多功能得以更有效率地实现,但是可能使我们的领域模型变得“肥胖”。
为了解决这个问题,我们重构了我们的肥领域模型——首先是把基础架构代码移到代理子类和一个基类中,然后将实际的逻辑从代理子类中移出、移到混入和拦截器类中。这使我们的领域模型变得更漂亮,但是在代理子类中最终却有很多样板代码需要写。为了解决这个问题,我们转向了面向方面编程。
结果发现迈向 AOP 框架的步子原来是如此之小——事实上应用的架构并没有任何改变——以至它大概使一些读者感到惊奇,这些读者甚至有熟悉的感觉,这种感觉就像当你第一次理解一个设计模式时,你意识到它就是你已经用了很多次的东西,只是不知道它有一个这样的名字。
你很可能在许多应用中有效地使用过 AOP,但并没认识到它是 AOP,并且好像没有使用过 AOP 框架来帮助你自动化地生成部分样板代码。
我们现在在这篇文章的结尾处,很希望在这个地方你会同意我的看法:
97. AOP 不像它看上去的那么难以理解和令人迷惑,并且使用 AOP 框架是很容易的。
98. 不管你是否使用 AOP 框架,使用 AOP 的概念和建模技术,对处理你应用基础架构中的横切领域模型管理关注点来说,仍然是一个非常好的方法。
它实际上就是一个通过使用良好的、成熟的面向对象模式,稳步提高应用架构的重构问题。这样做的时候,不要害怕走向一个使用代理来运用拦截器和混入的,可称为面向方面的应用架构。
不管你是否进一步让一个 AOP 框架来帮助你应用方面,这都不会真正影响你是否在进行 AOP。因为,如果你是顺着这篇文章讨论的路线来重构你的应用的,你就是在进行 AOP——不管有没有一个框架的帮助。
摘要
通过使用像代理模式、抽象工厂模式、组合模式这些传统的、知名的面向对象设计模式来重构我们的肥领域模型,我们得到了一个极好地结合了精益领域模型和基础架构的应用架构,基础架构充分利用了面向对象的概念和构造。这样,我们巧妙地避免陷入肥领域模型和贫血领域模型反模式的陷阱。
使用这篇文章中讨论的模式,得到了一个可以被形容为面向方面的应用架构。这是因为我们最终用混入和拦截器类解决了横切关注点,混入和拦截器则精密地与面向方面编程中的介绍和通知匹配了起来。
如果你想亲自体验使用 AOP 是不是真的那么轻松愉快,而且不介意使用不是亲手键入的代码,你可以下载本文随附的 Visual Studio 2005 工程的所有代码。
总之,在这篇文章中,我尝试去展示面向方面的概念和工具是怎样提供一个伟大的方式去看待和运用许多领域模型管理关注点,以及它们是如何大大减轻了肥领域模型反模式的风险。
关于作者
Mats Helander 是 Avanade(荷兰)的一位资深软件开发咨询师。业余时间,他和 Roger Johansson 一起开发了免费的 Puzzle.NET 套件,Puzzle.NET 是一个开源框架和工具。Puzzle.NET 包括 NPersist、ObjectMapper(对象 / 关系映射)、NAspect(面向方面编程)、NFactory(依赖注入)、以及 NPath(内存对象查询)。
Mats Helander 的博客—— http://www.matshelander.com/wordpress
Puzzle.NET—— http://www.puzzleframework.com
Avanade(荷兰)—— http://www.avanade.com/nl/
参考资料
[Evans DDD]
《领域驱动设计:软件核心复杂性应对之道》,Evans Eric 著。 ——马萨诸塞州,波士顿:Addison-Wesley 出版社,2004。
[Fowler 贫血领域模型]
Fowler Martin: http://martinfowler.com/bliki/AnemicDomainModel.html
[Fowler PoEAA] http://martinfowler.com/bliki/AnemicDomainModel.html
《企业应用架构模式》,Fowler Martin 著。 ——马萨诸塞州,波士顿:Addison-Wesley 出版社,2003。
[GoF 设计模式]
《设计模式:可复用面向对象软件的基础》,Gamma Erich、Richard Helm、Ralph Johnson、John M. Vlissides 合著。——马萨诸塞州,里丁镇:Addison-Wesley 出版社,1995。
[Helander DMM]
Helander Mats: http://www.matshelander.com/wordpress/?p=30
[Helander 肥领域模型]
Helander Mats: http://www.matshelander.com/wordpress/?p=75
[Nilsson ADDDP]
《领域驱动设计和模式应用》,Nilsson Jimmy 著。——Addison-Wesley 出版社,2006。




