篇幅一:APM 基础篇
1、什么是 APM?
APM,全称:Application Performance Management ,目前市面的系统基本都是参考 Google 的 Dapper(大规模分布式系统的跟踪系统)来做的,翻译传送门《google 的Dapper 中文翻译》
思考下:不遵守该理论的是伪APM,耍流氓吗?
APM 的核心思想是什么? 在应用服务各节点相互调用的时候,从中记录并传递一个应用级别的标记,这个标记可以用来关联各个服务节点之间的关系。比如两个应用服务节点之间使用 HTTP 作为传输协议的话,那么这些标记就会被加入到 HTTP 头中。可见如何传递这些标记是与应用服务节点之间使用的通讯协议有关的,常用的协议就相对容易加入这些内容,一些按需定制的可能就相对困难些,这一点也直接决定了实现分布式追踪系统的难度。
2、为什么要用 APM?
有业务痛点,才要寻求解决方案,个人认为,APM 需要优先解决测试环境下两个场景问题,基于测试先行的原则考虑:

优先关注宏观数据,并不是说测试人员无须关注微观层面的问题,在测试角度来看,先解决性能测试环境的数据采样、收集问题,再去评估生产环境,而线上的链路监控需要研发跟运维去配合,【研发角度场景】相对于测试人员来说是弱关注了。
3、市面上有哪些 APM 工具?
- Pinpoint
Pinpoint is an open source APM (Application Performance Management) tool for large-scale distributed systems written in Java.
https://github.com/naver/pinpoint - SkyWalking
A distributed tracing system, and APM ( Application Performance Monitoring ) .
http://skywalking.org - Zipkin
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data. Zipkin’s design is based on the Google Dapper paper.
http://zipkin.io/ - CAT (大众点评)
CAT 基于 Java 开发的实时应用监控平台,包括实时应用监控,业务监控。
https://github.com/dianping/cat
4、先说结论
目前比较贴合 Google Dapper 原理设计的,Pinpoint 优于 Zipkin。
Pinpoint 对代码的零侵入,运用 JavaAgent 字节码增强技术,添加启动参数即可。
并且符合【测试角度场景】性能测试调优监控的宏观;
当然,结论太早了,会有疑惑:
“ Spring Cloud Slueth 和 zipkin 之间的关系是什么? “
需要看详细对比的,详见下图:

5、再说对比
本质上 Spring Cloud Slueth 与 Pinpoint 没有可比性,真正对比的是 Zipkin,Spring Cloud Slueth 聚焦在链路追踪和分析,将信息发送到 Zipkin,利用 Zipkin 的存储来存储信息,当然,Zipkin 也可以使用 ELK 来记录日志和展示,再通过收集服务器性能的脚本把数据存储到 ELK,则可以展示服务器状况信息了。Zipkin 的总体展示,也是基于链路分析为主。

篇幅二:Pinpoint 实战篇
1、Pinpoint 架构图
Pinpoint is an open source APM (Application Performance Management) tool for large-scale distributed systems written in Java.

架构图对应说明:
- Pinpoint-Collector:收集各种性能数据
- Pinpoint-Agent:探针与应用服务器(例如 tomcat) 关联,部署到同一台服务器上
- Pinpoint-Web:将收集到的数据层现在 web 展示
- HBase Storage:收集到数据存到 HBase 中
2、Pinpoint 的数据结构
Pinpoint 消息的数据结构主要包含三种类型 Span,Trace 和 TraceId。
- Span 是最基本的调用追踪单元
当远程调用到达的时候,Span 指代处理该调用的作业,并且携带追踪数据。为了实现代码级别的可见性,Span 下面还包含一层 SpanEvent 的数据结构。每个 Span 都包含一个 SpanId。 - Trace 是一组相互关联的 Span 集合
同一个 Trace 下的 Span 共享一个 TransactionId,而且会按照 SpanId 和 ParentSpanId 排列成一棵有层级关系的树形结构。 - TraceId 是 TransactionId、SpanId 和 ParentSpanId 的组合
TransactionId(TxId)是一个交易下的横跨整个分布式系统收发消息的 ID,其必须在整个服务器组中是全局唯一的。也就是说 TransactionId 识别了整个调用链;SpanId(SpanId)是处理远程调用作业的 ID,当一个调用到达一个节点的时候随即产生;ParentSpanId(pSpanId)顾名思义,就是产生当前 Span 的调用方 Span 的 ID。如果一个节点是交易的最初发起方,其 ParentSpanId 是 -1,以标志其是整个交易的根 Span。下图能够比较直观的说明这些 ID 结构之间的关系。

3、Pinpoint 部署
网上太多部署文档,这里不详细说明,简要说明下:

注意版本要求:
有两种方式启动:
方式一:修改tomat 目录下bin/catalina.sh,在Control Script for the CATALINA Server 加入以下三行代码:
CATALINA_OPTS="$CATALINA_OPTS -javaagent:/home/webapps/service/pp-agent/pinpoint-bootstrap-1.6.2.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=pp32tomcattest"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=32tomcat"
第一行:pinpoint-bootstrap-1.6.2.jar 的位置
第二行:agentId 必须唯一, 标志一个 jvm
第三行:applicationName 表示同一种应用:同一个应用的不同实例应该使用不同的 agentId, 相同的 applicationName
方式二:SpringBoot 启动
java -javaagent:/home/webapps/pp-agent/pinpoint-bootstrap-1.6.2.jar -Dpinpoint.agentId=pp32tomcattest -Dpinpoint.applicationName=32tomcat -jar 32tomcat-0.0.1-SNAPSHOT.jar### 4、代码注入是如何工作的

Pinpoint 对代码注入的封装非常类似 AOP,当一个类被加载的时候会通过 Interceptor 向指定的方法前后注入 before 和 after 逻辑,在这些逻辑中可以获取系统运行的状态,并通过 TraceContext 创建 Trace 消息,并发送给 Pinpoint 服务器。但与 AOP 不同的是,Pinpoint 在封装的时候考虑到了更多与目标代码的交互能力,因此用 Pinpoint 提供的 API 来编写代码会比 AOP 更加容易和专业。
5、Pinpoint 实战效果演示
搭建一个 java 开源项目 jforum ,跑在 tomcat 下,使用 jmeter 进行压测,用户 100 个:
-
服务器图(ServerMap)
通过可视化其组件的互连方式来了解任何分布式系统的拓扑。单击节点将显示有关组件的详细信息,例如其当前状态和事务计数。
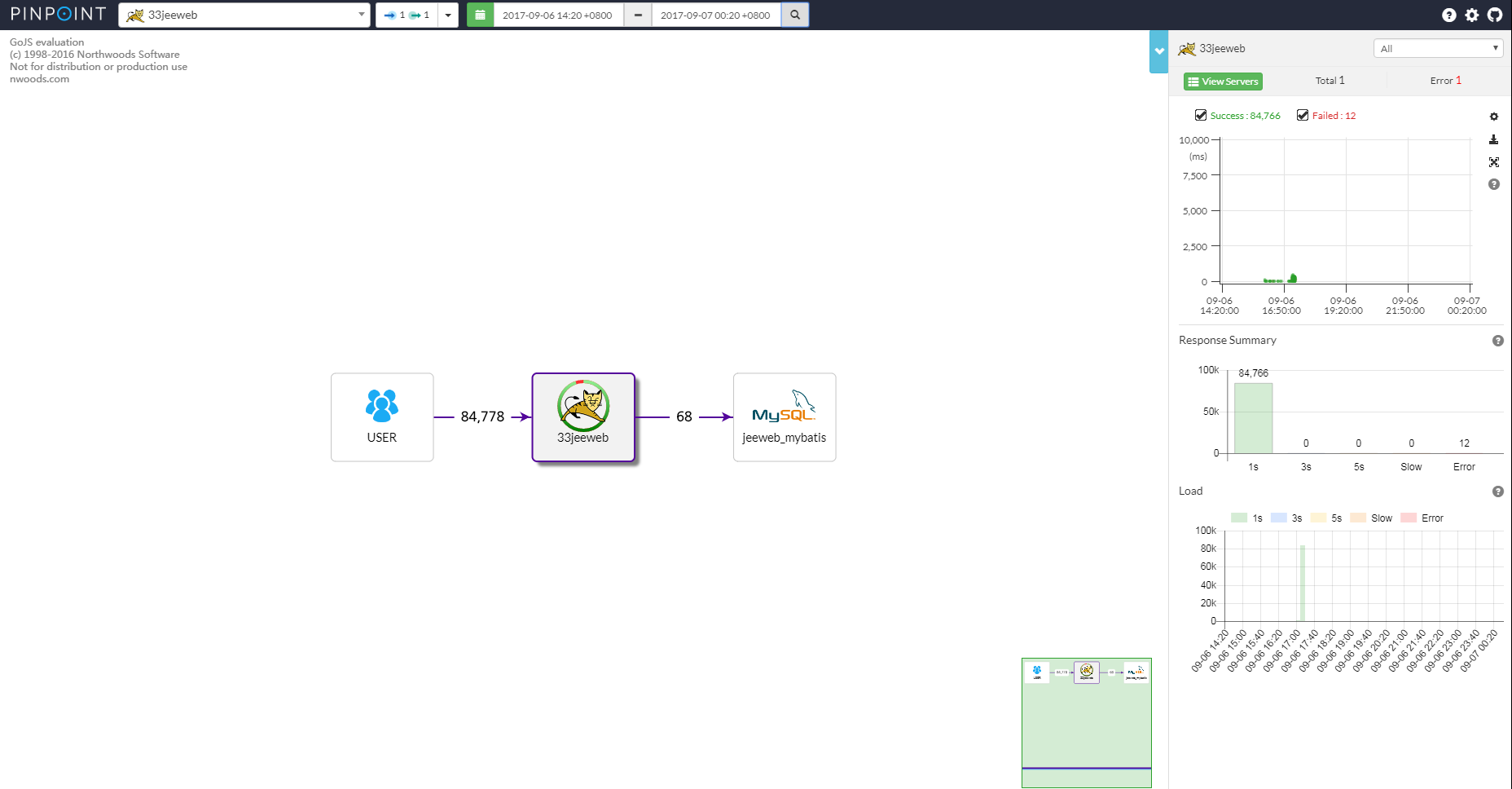
-
实时活动线程图(Realtime Active Thread Chart)
实时监视应用程序内的活动线程。(用了官方图,当时没截图)

-
请求 / 响应散布图(Request/Response Scatter Chart)
可视化请求计数和响应模式,以确定潜在问题。可以通过在图表上拖动来选择事务以获取更多详细信息。
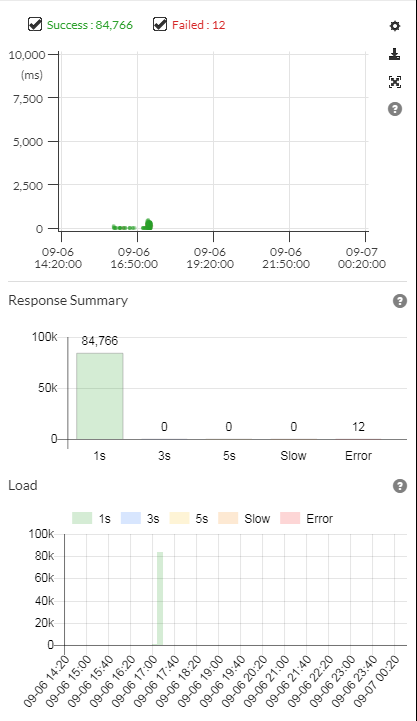
-
调用栈信息(CallStack)
增强分布式环境中每个事务的代码级可见性,识别单个视图中的瓶颈和故障点。
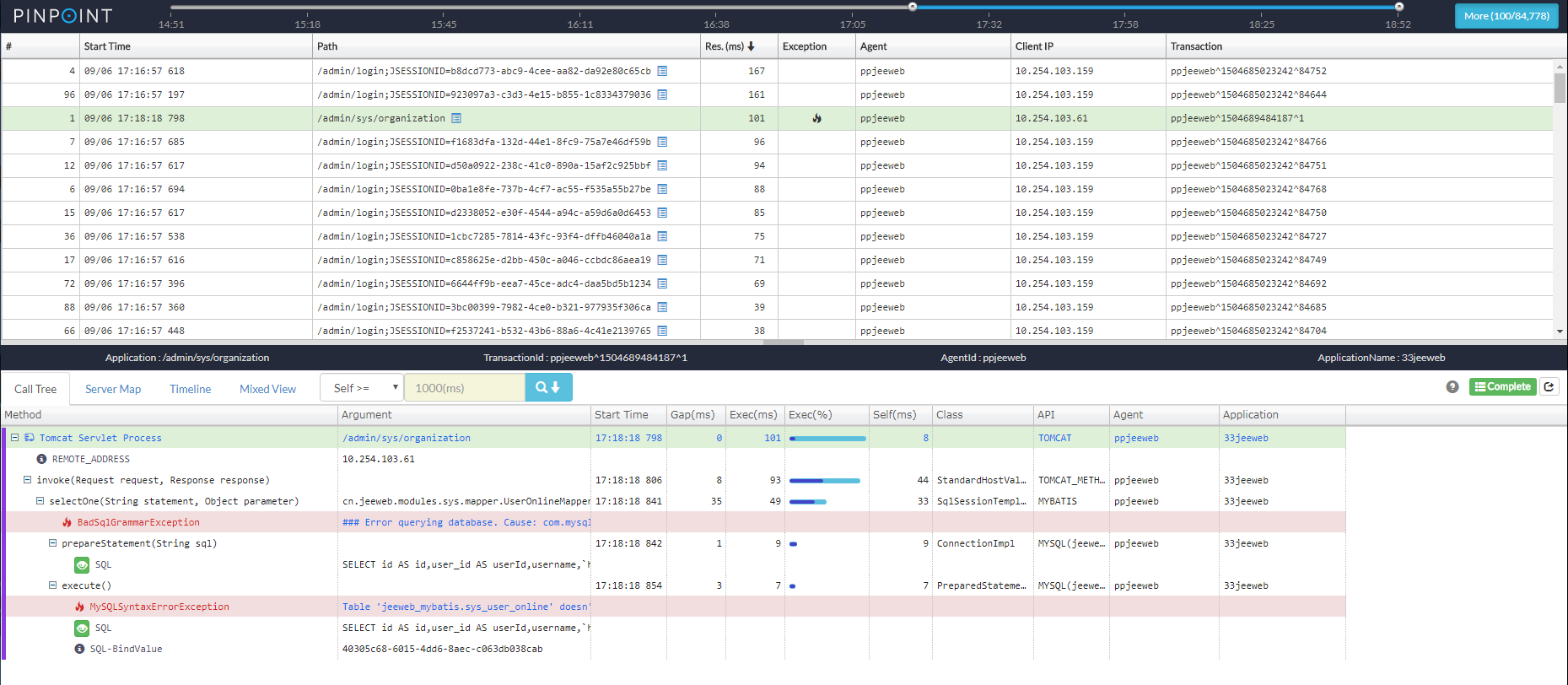
-
检查器(Inspector)




查看应用程序的其他详细信息,如 CPU 使用率,内存 / 垃圾收集,TPS 和 JVM 参数。

6、总结
第一:PinPoint 从宏观上看:总体链路、服务总体状态(cpu、内存等等信息),符合【测试角度场景】性能测试调优监控的宏观;
第二:Spring Cloud Slueth 需要结合 Zipkin 从微观来看:自身无法单独提供展示,要结合 Zipkin 展示链路问题(并没有服务器总体状态的展示),更多服务器性能状况等信息展示需要定制脚本通过 ELK 收集展示,符合【研发角度场景】性能测试调优监控的微观;
总的来说两者是结合体,要单独使用的话,从测试业务上来看:PinPoint 满足,性能测试调优监控的宏观【测试角度场景】
7、项目场景
访问某个 API,后端应用服务产生的一系列链路,为何请求一次有 23 次数据库访问呢?这里就是需要排查的的地方,详细看看 CallTree,找出可优化的 SQL 查询语句。


另外,在做性能测试的时候,服务器并发的 IO,PP 不断写入也会产生瓶颈,需要后续解决。
8、标签库项目简单压测
通过 jmeter 对标签库进行简单压测,脚本如下:

通过 APM 发现问题如下:

pquery.do 的 res 高达 6782ms,需要安排开发进一步排查定位代码问题


另外一种场景,测试人员无法在页面获取到的信息(有些情况下,测试人员是没有服务器权限),这些是服务底层的异常信息,可以通过CallTree 来查看。
9、应用服务接入 APM 后的链路全景蜘蛛网图

参考文献:
Pinpoint 源码解析(三) Dapper,大规模分布式系统的跟踪系统 Pinpoint 学习笔记 Pinpoint v1.5.0 APM 视频介绍




