
马赫是闲鱼的选品和投放系统,闲鱼业务中多数商品都是孤品即单库存商品,所以商品的实时变更需要即刻反馈到选品和投放链路中,为了满足业务诉求马赫设计之初就把实时性作为最重要的技术目标,随着系统的运行数据的膨胀实时性也遇到了瓶颈,本文将介绍近一年来在提升马赫实时性上的相关工作,目标是选品实时性延迟控制在秒级别。如果有对马赫不了解的同学可以回顾公众号内马赫相关文章。
选投实时链路
马赫整个选品和投放的过程中数据流转如下图所示主要分为三个部分,第一部分是选品数据接入,数据是马赫选品的根本,数据的实时是整个马赫流程能有效运转的基础。第二部分是选品规则计算,规则计算是马赫的核心,计算的实时性保证了马赫能把选品结果同步到各个下游节点。第三部分是商品投放,商品投放是与用户距离最近的部分,实时的反馈能给用户带来更好的体验。
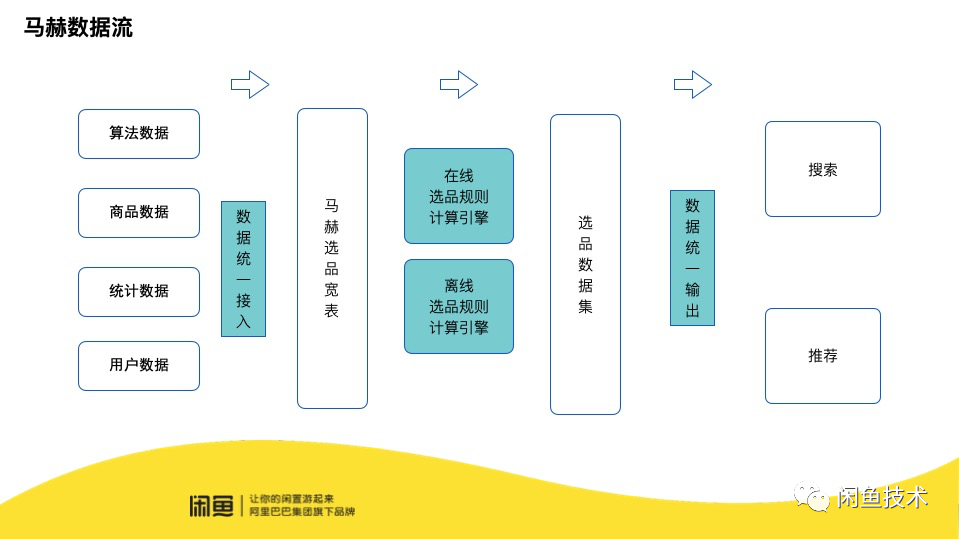
马赫实时性性能优化也是从这三部分入手,下面将针优化过程进行详细介绍。
选品数据实时性能优化
马赫选品依赖的选品宽表数据,主要由两类数据构成,一类是商品基础数据,商品基础数据指用户发布的商品信息包括:商品类型、商品状态、商品价格、商品描述、商品图片;该类数据通过订阅商品数据库的变更已经实现了实时性。另外一类是基于商品衍生出的统计和预测数据,这类的数据一般都是通过 ODPS(阿里内部离线计算平台)离线计算,产出时间与商品基础相比大多是天级别或小时级别延迟,该类数据原有的接入方案如下,无论是小时级别延迟还是天级别延迟产出的数据,都是进行统一的处理,每天把所有的数据 JOIN 到一起后输出到一个离线数据表中,然后把该数据通过 BLINK 和 MetaQ 消息通道与马赫的数据统一接入层对接。该方案的优点是所有的离线产出数据只需要处理一次方便运维,同时每天一次回流整个过程的数据量可控。缺点也是显而易见,首先每天汇总数据产出时间取决于上游耗时最长的数据,如果有数据延迟将会影响整个流程的耗时,其次明明是 H+1 产出的数据却要等到 T+1 才可使用,这严重影响了选品能力。
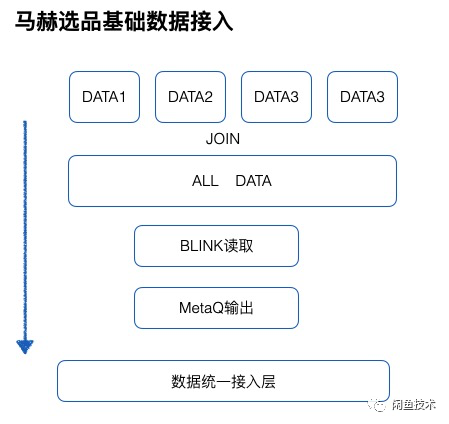
问题已经明确那剩下来的就是解法,首先要解决的汇总数据依赖上游最长耗时的问题,常规的解法是汇总数据定时产出,到了定时时间,上游各个节点数据已经产出那么就使用,如果没有产出就使用上一次产出的数据,最初解决时也确实采用了该方案,该方案会造成部分数据要 T+2 才可以进入选品宽表。虽然不是很好的解法但是解法简单,作为过渡方案在马赫里面也运行了一段时间。下面介绍这个问题马赫采用的最终解法,如下图所示:
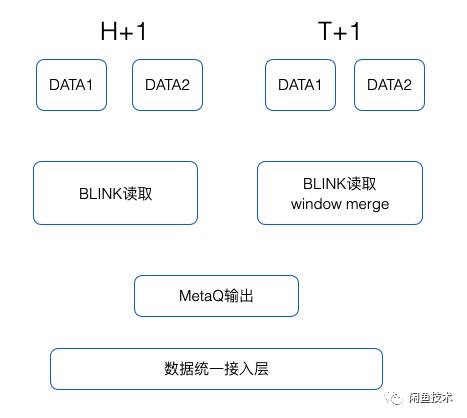
首先把数据按照产出周期进行分类,H+1 产出的数据量级在万,T+1 产出的数据量级在亿,对于 H+1 的数据直接利用 BLINK 读取后,利用 MetaQ 数据通道输出到数据统一接入层,保证了数据产出即用。对于 T+1 的数据同样直接利用 BLINK 读取,由于该部分数据过大,如果直接输出 QPS 将会达到百万级别对于下游压力过大,所以马赫利用 BLINK 的滑动窗口的聚合能力,把商品 ID 作为 KEY 对窗口内的数据进行聚合,聚合后再输出到马赫数据统一接入层。滑动窗口越小那么实时性将会越高,但是同样系统压力也会越大,目前马赫的滑动窗口时间为 6 个小时。该方案解决了商品算法和统计数据接入实时性的问题,但整个系统流量增加了 4 倍,这也是设计系统时候常常纠结的时间成本与空间成本的权衡问题,在本次优化中选择了用空间换时间并有节制的控制了两个的平衡,优化后效果从天级别延迟缩短至小时级别。
选品规则计算实时性优化
选品规则计算包含两个部分一部分是运营创建选品规则时在马赫选品宽表中运算选并产出结果集称为离线选品规则执行引擎,另一部分是当商品信息变更时需要重新计算当前商品命中的选品规则称为在线选品规则执行引擎。
首先介绍第一部分离线选品规则执行引擎的优化,运营创建的选品规则会映射成 SQL 在马赫选品宽表 ADB 上进行执行,ADB 是全索引数据表这里主要是用空间去换时间,但是有一类问题很难解决就是文本的全字段匹配,举一个例子选品宽表中有个从商品基本数据表中映射字段 ATTRIBUTE,从名字就不难看出该字段是当时商品设计中预留出的扩展字段,其内容以 kv 对分号分隔的形式进行存储,运营在进行选品时最终映射到该字段的规则 SQL 是用 LIKE 关键字进行在十几亿的数据中检索在其性能可想而知。所以针对该类字段做了多值映射即把 kv 对映射成数字进行存储,该方案虽然不复杂但是解决了创建规则时商品量计算以及商品预览的时效性问题不做过多赘述,优化后商品计算从 6 分钟级别降至 30 秒,具体效果如下:
下面介绍第二部分在线规则执行引擎的优化,在线引擎是在 BLINK 中实现的,商品的变更信息作为输入源,在执行引擎中计算出当前商品命中的商品池,把商品和对应命中的商品池作为结果输出到下游。原有的流程如下所示:
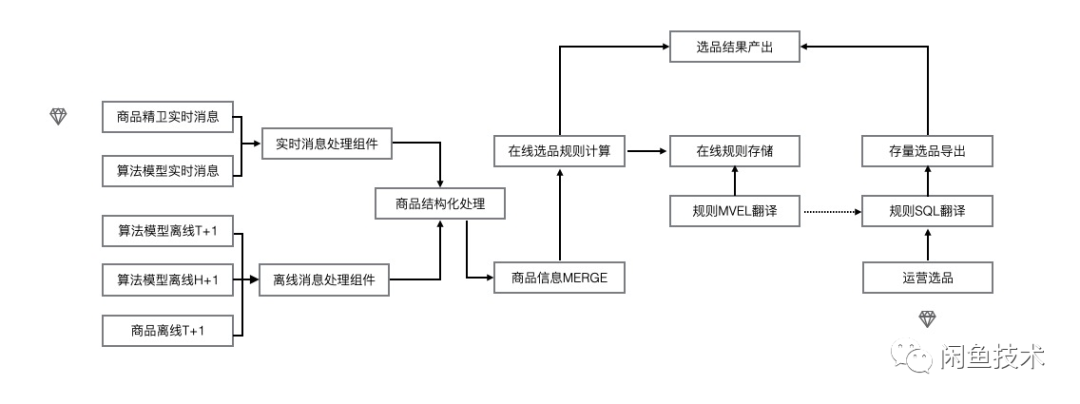
在 BLINK 中主要完成了马赫关键的 MERGE 和 DIFF 操作,MERGE 是把 BLINK 内存中的数据与输入进来的数据取字段上的最大的更新时间戳为最新数据把商品信息整合。然后把整合后的数据在所有的选品规则上运行,运行结果与上一次结果做对比,筛选出两次结果不同的数据作为结果输出这步操作称为 DIFF。这样做的好处是内存存储商品最新数据减少读取的 IO 减少时间消耗,同时输出结果时只输出 DIFF,减少数据量的传输再次节省时间。该方案也有着明显的弊端整个数据都在内存中存储,如果发生不可预期的异常内存中的数据将会丢失,从系统开始运行到优化前从没有停机过,其中付出的运维成本可想而知,同时不可停机导致系统无法升级和使用新版本的 BLINK 能力。下面针对不可停机问题进行如下解法:
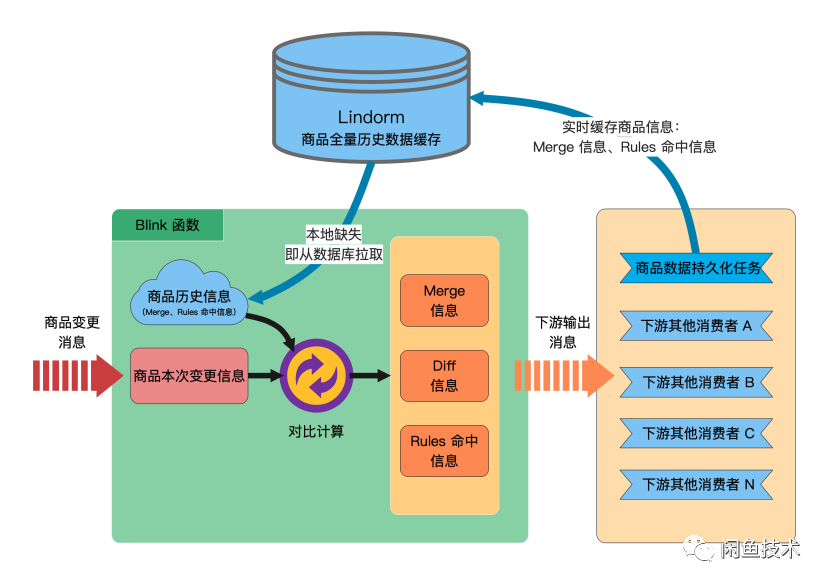
在 BLINK 接受到商品信息时首先从本地拉取数据,如果拉取不到则从商品信息库中读取对应数据,在结果输出时在输出原有的信息同时增加输出商品信息与全量的规则命中信息,作为备份存储方便停机恢复,其中为了减少存储空间和数据的 IO 在传输和存储过程中对数据都进行了压缩处理。最终方案整个逻辑不是很复杂,复杂的是如何从原有的方案平滑切换到现在的方案,其中涉及到数据同步、数据转换、数据校对,这里面踩了不少坑,该部分不是本文的重点就不赘述了。最终在解决不可停机的问题同时也升级了 BLINK 版本,升级后数据延迟从原有的 2 分钟降低至 2 秒,让整个在线规则引擎运行更快更平稳。
商品投放的实时优化
商品投放是与用户侧距离最近的能力,运营圈选商品后形成商品池,然后利用商品池搭建页面投放给用户,在用户请求时把商品从商品池中召回然后展现给用户,具体流程如下图所示。
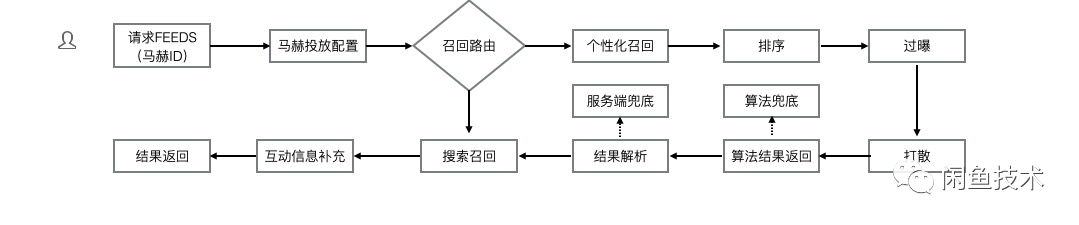
在这个过程中与马赫发生深层关系的是在召回的部分,目前马赫支持搜索召回和算法召回两种召回方式,搜索召回中把商品池的实时变更同步给搜索引擎做增量的迭代,天然支持实时召回的能力只需要保证增量的稳定即可;算法召回利用的是用户属性召回相关商品,用户和商品的关系是 T+1 产出,这与马赫场景中强调的实时性相悖,为了解决算法召回的实时性问题,马赫做出如下解法:
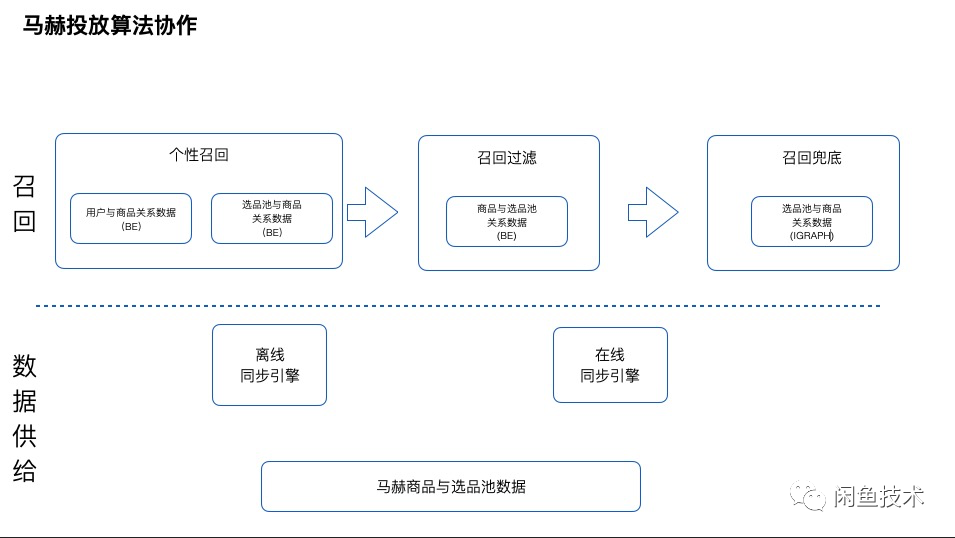
首先我们看一下召回流程:当接受到一个用户请求,我们会得到两个信息一个是用户的 ID 和商品池的 ID,首先利用用户 ID 查询用户与商品关系表进行个性化召回,然后利用商品池的 ID 查询选品池与商品关系数据表进行通用性召回,最后把两部分数据进行去重合并这里统称为个性召回,召回后的数据 JOIN 商品与商品池关系表,只保留符合该商品池 ID 下的商品这里称为召回过滤,如果此时商品数量满足召回要求则返回,如果不满足召回要求则查询商品池与商品关系数据表召回的兜底数据这里统称为兜底召回,通过召回流程后再经过 RANK 和信息补充就把数据呈现给用户了。
上面流程中提到多个数据表,那么这些数据表是如何产出又为什么这么设计下面详细介绍。首先介绍在个性召回中使用的 BE 用户和商品关系数据表的产出逻辑,这部分数据不依赖马赫的任何信息,仅仅是通过用户在闲鱼的点击浏览等用户偏好行为对用户喜欢的商品进行预测,每个用户相关商品规模在 2000 个是 T+1 产出。然后介绍个性召回中使用的 BE 选品池和商品关系数据,这部分数据是依赖马赫离线引擎同步产出的,这里的产出逻辑是首先根据各项指标对选品池中的商品进行排序,排序后保留前 5000 个作为通用召回是 T+1 产出,使用依赖这两个表完成了个性召回步骤。然后是召回过滤中 BE 商品与选品池关系数据,这部分数据是利用在线同步引擎实时更新的,之所以设计这步召回过滤是为了防止个性召回的 T+1 的商品,当前已经不在商品池中了。所以理所当然的就有了召回兜底逻辑,该部分数据是由马赫的同步引擎保证实时更新存储在 IGRAPH 中,可以用商品池的 ID 召回当前池子中最新的 2000 个商品作为兜底。通过以上的逻辑保证了用户在算法进行召回时的实时性。
总结
本文从马赫选品到马赫投放实时性优化做了全面的介绍,每一步优化呈现的都是最终方案,为了保证系统的平滑过渡优化中中踩了很多坑不过最终都平稳落地,优化后的马赫从选品到投放整个实时链路时延有一个质的变化,选品数据从 T+1 变为 H+1,选品流程从 6 分钟变为 30 秒,投放流程从 2 分钟变为 2 秒,系统更健壮也更实时,从整体功能看马赫还是属于一个工具级别系统,还远没有达到产品级别系统级。
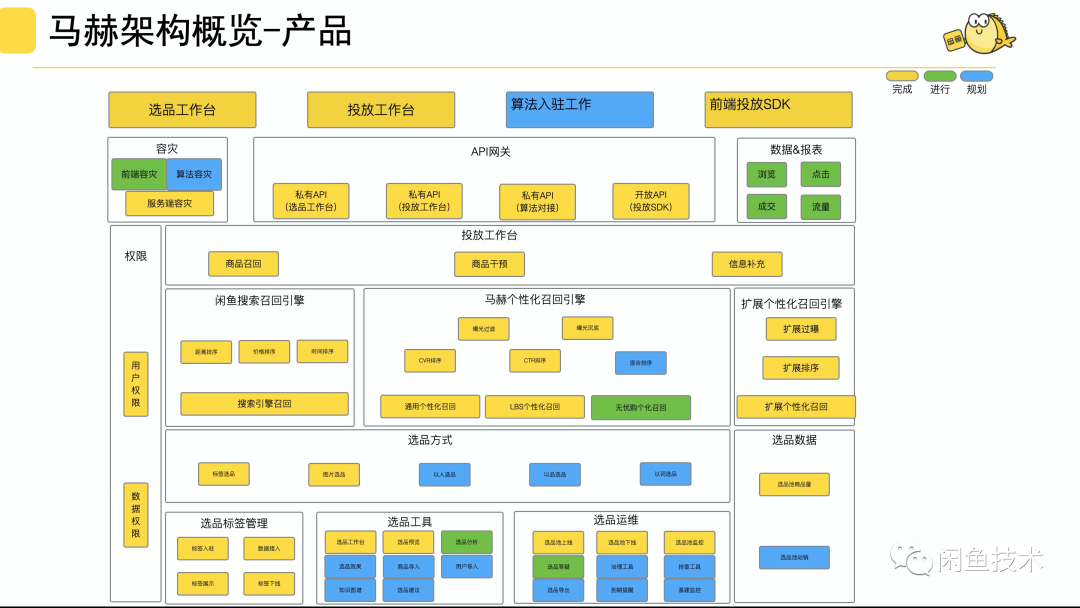
如上图所示,未来会把重点放在选品能力与整体运维能力上,在优化原有系统的同时增加新的能力,逐步把马赫打造成产品化系统。
本文转载自:闲鱼技术(ID:XYtech_Alibaba)
原文链接:闲鱼商品选投实时性优化




