
前言:数据集市的目标
数据集市,是数据仓库 ADM 层最主要的数据形态,应用在特定业务场景的高度汇总数据,支持特定人员或部门进行数据分析、统计、决策等行为。(数据仓库分层架构及建设思路可查阅作者的《浅谈银行数据仓库的构建之路》)概念理解起来不难,难在如何制定数据集市的落地方式,这时必须结果导向,从实现目标进行反推。
数据集市的目标
从概念可以了解,数据集市是应用在特定业务场景的,专门支持特定人员或部门的数据集,所以数据集市的首要目标是满足特定人员或部门提出的业务场景。比如报表集市,业务人员要求的是按照需求文档开发出固定报表查询即可,可是开发团队却开发出一张张大宽表给业务人员进行自助查询,希望业务人员通过大宽表就可以随时设计出自己想要的报表,最终业务人员愿意买账吗?
数据集市是以实现特定人员或部门提出的特定业务场景为目标进行设计。
数据集市的模型数量有标准要求吗?
别人家一个数据集市少则十几个模型,多则上百个模型,是否模型数量达到一定程度才能称为数据集市?还是从目标出发,数据集市是为了实现特定业务场景而设计,而业务场景也是有大小之分的。小的业务场景可能一张报表就可以实现,比如 2020 年度单位存款基础数据报送要求,大的业务场景确实需要上百个模型来支持,比如零售管理部的营销分析集市。无论是一张报表还是上百个模型,都属于实现了特定业务场景的数据集市。当然,数据集市过小,比如上述的一张报表,会合并到大的数据集市中,比如报表集市,为了更好实现维护与管理。
数据集市的模型数量没有标准要求,关键是能否实现目标。
数据集市的建模方式有标准要求吗?
目前主流的标准建模方式有三类:
1) 星型模型
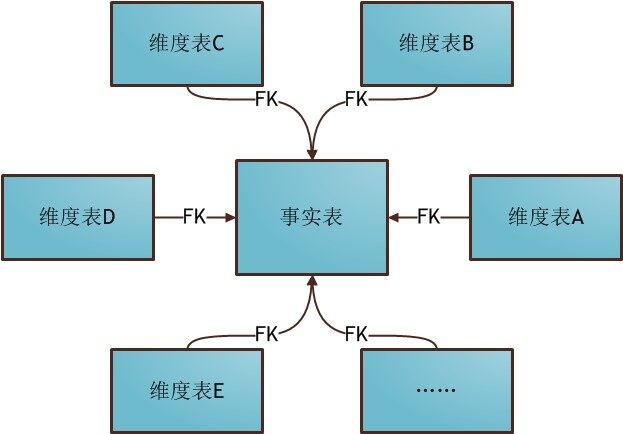
最常用的建模方式,模型由一个事实表与一组维表连接而成,维表只能与事实表关联,维表间不能关联,犹如被多个卫星环绕核心行星的系统,所以称为星型模型。
2) 雪花模型
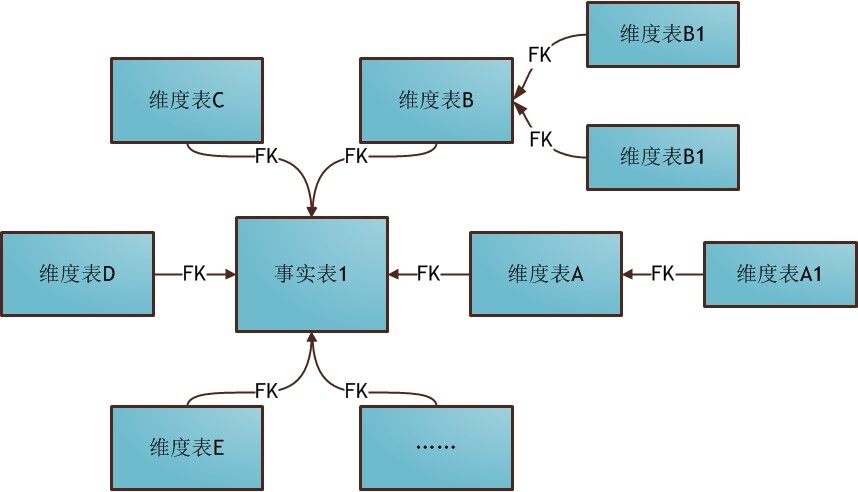
雪花模型同样由一个事实表与一组维表连接而成,对比星型模型,雪花模型的维表是由大维表与小维表连接而成,这样大维表与小维表之间又形成一个星型模型。一个大的星型模型里面嵌套小的星型模型,形状犹如一片完整的雪花四周由小雪花连接而成,所以称为雪花模型。雪花模型实际是星型模型的范式建模形态,把维表拆分成三范式避免数据冗余。实际上适量的数据冗余对数据仓库而言是允许的(数据集市也是一种数据冗余),但维表过于范式设计会增加使用的难度,所以一般很少使用雪花模型建模。
3) 星座模型
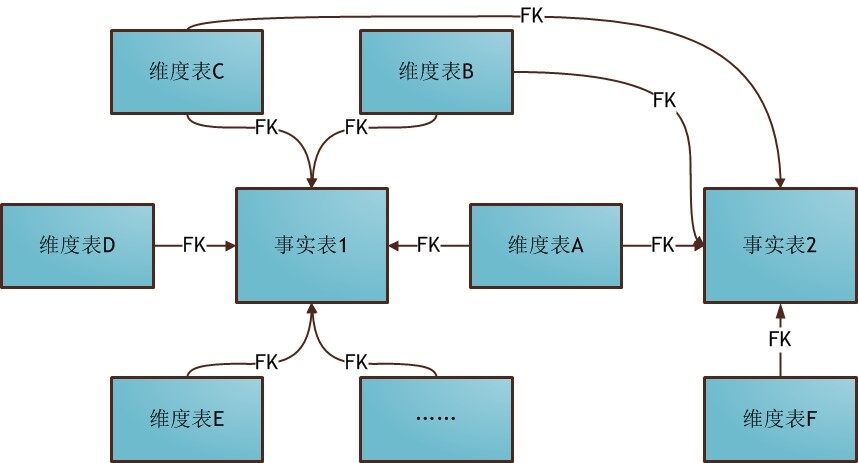
数据集市模型一般由多个事实表与一组维表连接而成的,事实表之间不能直接连接,但可以通过维表进行连接,而一个维表可以被多个事实表连接,其形状犹如由多个行星系统组成的星系,所以称为星座模型。星座模型属于星型模型的扩展,更符合数据集市的建模思路,同样属于最常用的建模方式。
所以数据集市是否必须按照某类标准方式设计模型呢?也不一定,只要数据集市能满足特定业务场景所需,哪怕由一组事实表模型组成也是允许的。实际上,为了提高数据的使用性,数据集市也会出现分层模型设计,第二章“数据集市建模思路”会进行详细介绍。
数据集市不必拘泥于标准建模方式,关键是能否实现目标。
数据集市建模思路
以下从一个监管报送项目的数据集市建模实践来逐步阐述数据集市建模思路。
需求分析
数据集市的目标是实现特定业务场景的数据集,所以设计数据集市模型前必须清晰了解需求的内容与意图。监管报送项目的需求一般都比较清晰,因为监管部门下发的报送要求文档一般会把统计项的报送口径和规范要求写得尽量清晰,减少双方关于需求内容的反复沟通。而对于分析型需求,比如营销集市或风险集市,业务人员可能都不清楚自己想要什么,更不要说在需求文档上写得清晰。针对这类需求,一般要从业务场景入手去提炼业务人员的真实需求。未来分享营销集市建模实践时会详细介绍。
这个监管报送项目包含了同业、单位、个人客户的存款、贷款、担保、债券等主题的数据报送,在这里挑选单位、个人客户的贷款部分来讲述建模实践。该部分的需求如下所示(为了信息保密,本文内容与实际需求会存在一定差异):
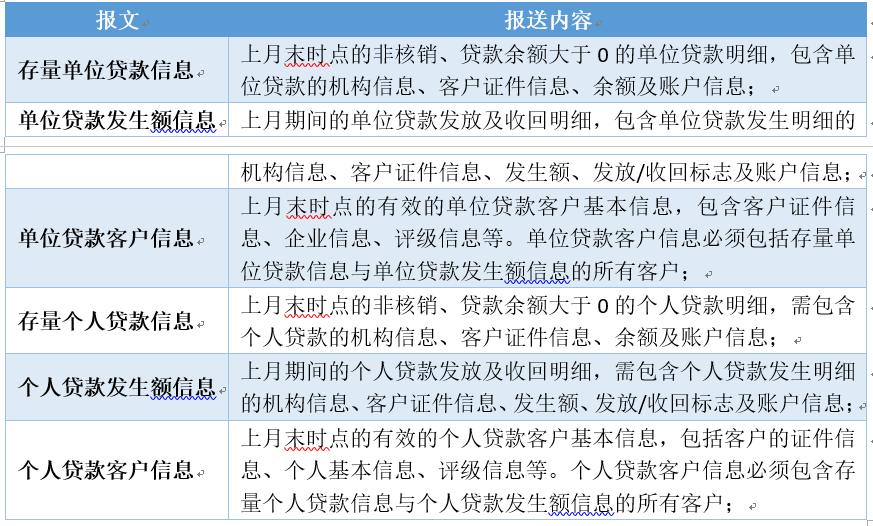
从需求内容可分析出数据集市需包含单位贷款客户信息、个人贷款客户信息、单位贷款的机构、余额、发生额及账户信息,个人贷款的机构、余额、发生额及账户信息。这个分析结果会对后续的数据建模起到关键性的作用。
从共性角度设计数据集市的分层
根据需求分析结果,可以发现除了单位贷款与个人贷款的发生额,其他信息都可以归纳为单位/个人贷款客户信息、单位/个人贷款账户信息(机构信息和余额可以归纳到账户信息内),具体为:

从模型内容可以看出两点:
1) 共性模型虽然属于原子粒度数据,但也经过了特定条件所筛选的数据集,所以数据集市应按实际场景尽量减少多余的数据;
2) 共性模型必须包含应用模型所需的所有数据,未来应用模型需要扩展属性,且扩展属性可从共性模型取数时,必须先扩展共性模型,再扩展应用模型。
具体模型如下图所示:

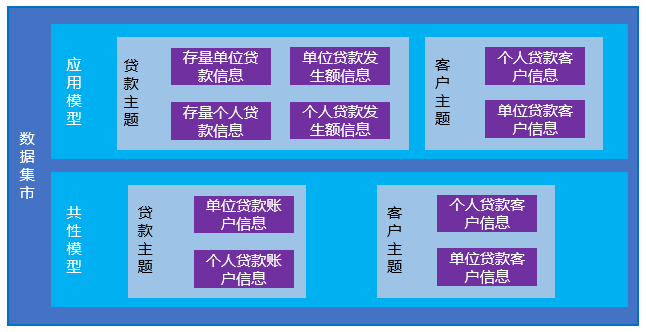
对所需的共性元素构建数据集市的共性模型,有利于数据的共享用以快速构建相关应用,也在数据集市与主题模型层之间再构建一层缓冲层,巩固应用的稳定性。
从产品角度设计数据集市的主题
数据模型设计完成后,建议划分相应主题对模型进行分类存放,有利于模型的识别及扩展。由于业务场景习惯以产品为维度进行数据展示,所以从产品角度划分数据集市主题更符合业务场景。比如上述的共性模型可划分客户和贷款两个主题,具体如下:

未来要扩展存款数据模型时,新增存款主题 FBDS_DEP 存款数据模型即可,而且整个数据模型也会显得十分清晰。
具体模型如下图所示:

对数据集市模型进行主题分类,有利于模型的识别及扩展,建议从产品的角度划分数据集市的模型主题。
从目标角度设计数据集市的对象
共性模型为应用模型提供数据预计算及复用,但一般共性模型并不能被应用系统直接使用,所以还必须生成目标数据提供应用系统使用。结合共性模型与应用模型,数据集市的对象为:
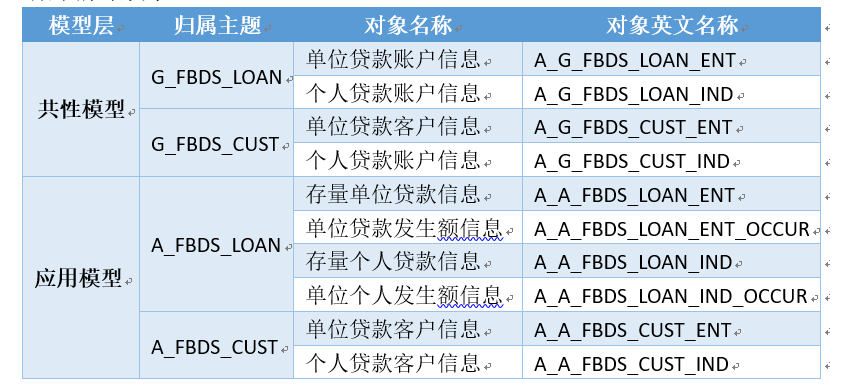
最终模型如下图所示:
总结:不追求完美建模
从上述监管报送项目的建模实践,可基本了解数据集市的建模思路,数据模型也随着设计的步伐逐渐浮现。模型设计完毕是否代表整个旅程已经结束了呢?恰恰相反,模型设计完毕只是运营维护的开始。
有些童鞋设计模型时想要追求完美,期望能设计出兼容未来需求的数据模型,但这个想法是正确的吗?比如上述监管报送项目的数据集市模型能设计出一款通用的数据模型,兼容贷款、存款、担保、债券等所有的数据吗?答案是,可能可以,但难度极高,且由于模型过度整合会导致使用者阅读及使用起来极度困难。所以,对数据模型进行整合时,必须围绕“共性”两字进行设计,且划分多主题进行表达,才能实现清晰的数据集市数据模型。
数据集市数据模型后续维护应如何进行呢?这里先不展开来讲,举个具体的例子提示一下,未来增加存款数据模型时,必定包含存款客户数据这一块,那么存款客户数据应该与贷款客户数据整合为一个模型吗?假如整合,贷款客户与存款客户可能存在较大差异,整合程度不高,最终使用模型时需消耗大量系统资源进行筛选关联;假如不整合,贷款客户与存款客户之间又存在冗余数据,导致相同的客户数据重复加工。所以,整合与拆分的权衡,还是在于能否达成目标与系统资源的支持程度。
数据集市数据建模切忌追求完美,应围绕着目标,不断迭代优化到能灵活运用即可。




