
OpenRL 是由第四范式强化学习团队开发的基于 PyTorch 的强化学习研究框架,支持单智能体、多智能体、自然语言等多种任务的训练。OpenRL 基于 PyTorch 进行开发,目标是为强化学习研究社区提供一个简单易用、灵活高效、可持续扩展的平台。目前,OpenRL 支持的特性包括:
●简单易用且支持单智能体、多智能体训练的通用接口
●支持自然语言任务(如对话任务)的强化学习训练
●支持从 Hugging Face 上导入模型和数据
●支持 LSTM,GRU,Transformer 等模型
●支持多种训练加速,例如:自动混合精度训练,半精度策略网络收集数据等
●支持用户自定义训练模型、奖励模型、训练数据以及环境
●支持 gymnasium 环境
●支持字典观测空间
●支持 wandb,tensorboardX 等主流训练可视化工具
●支持环境的串行和并行训练,同时保证两种模式下的训练效果一致
●中英文文档
●提供单元测试和代码覆盖测试
●符合 Black Code Style 和类型检查
目前,OpenRL 已经在 GitHub 开源:https://github.com/OpenRL-Lab/openrl
OpenRL 初体验
OpenRL 目前可以通过 pip 进行安装:
pip install openrl也可以通过 conda 安装:
conda install -c openrl openrlOpenRL 为强化学习入门用户提供了简单易用的接口, 下面是一个使用 PPO 算法训练 CartPole 环境的例子:
# train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为9net = Net(env) # 创建神经网络agent = Agent(net) # 初始化智能体agent.train(total_time_steps=20000) # 开始训练,并设置环境运行总步数为20000使用 OpenRL 训练智能体只需要简单的四步:创建环境 => 初始化模型 => 初始化智能体 => 开始训练!
在普通笔记本电脑上执行以上代码,只需要几秒钟,便可以完成该智能体的训练:

此外,对于多智能体、自然语言等任务的训练,OpenRL 也提供了同样简单易用的接口。例如,对于多智能体任务中的 MPE 环境,OpenRL 也只需要调用几行代码便可以完成训练:
# train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train(): # 创建 MPE 环境,使用异步环境,即每个智能体独立运行 env = make( "simple_spread", env_num=100, asynchronous=True, ) # 创建 神经网络,使用GPU进行训练 net = Net(env, device="cuda") agent = Agent(net) # 初始化训练器 # 开始训练 agent.train(total_time_steps=5000000) # 保存训练完成的智能体 agent.save("./ppo_agent/")if __name__ == "__main__": train()下图展示了通过 OpenRL 训练前后智能体的表现:
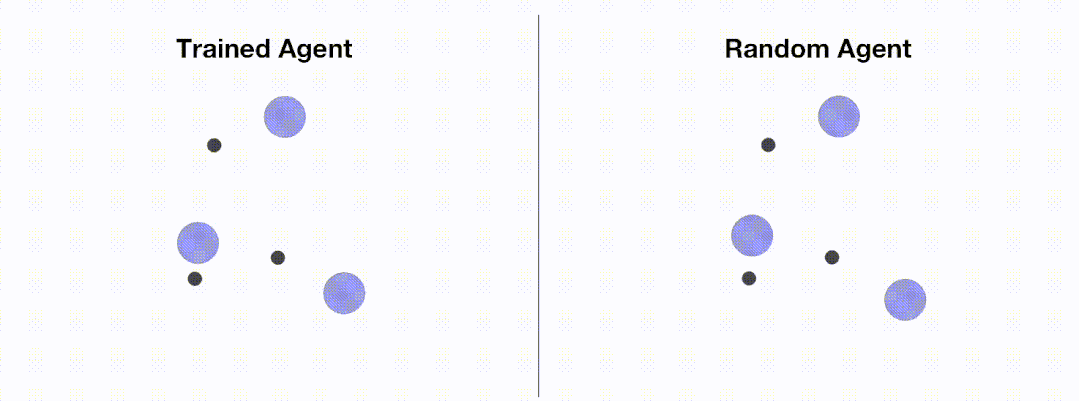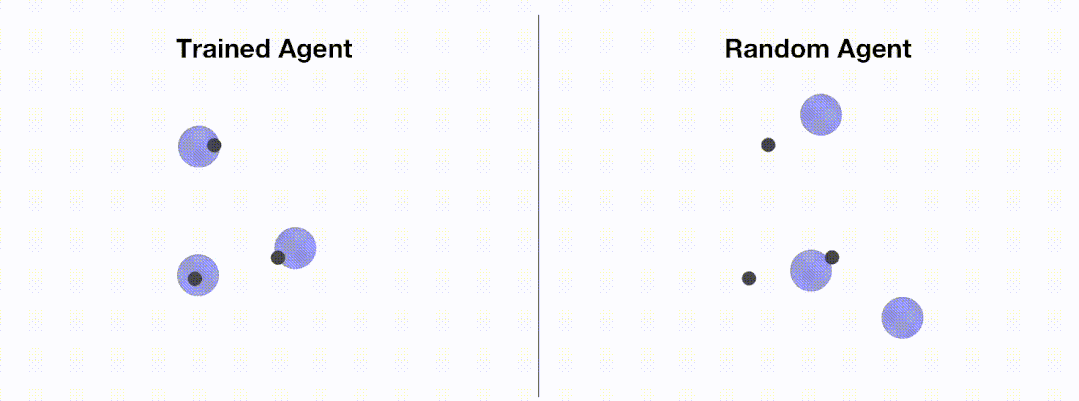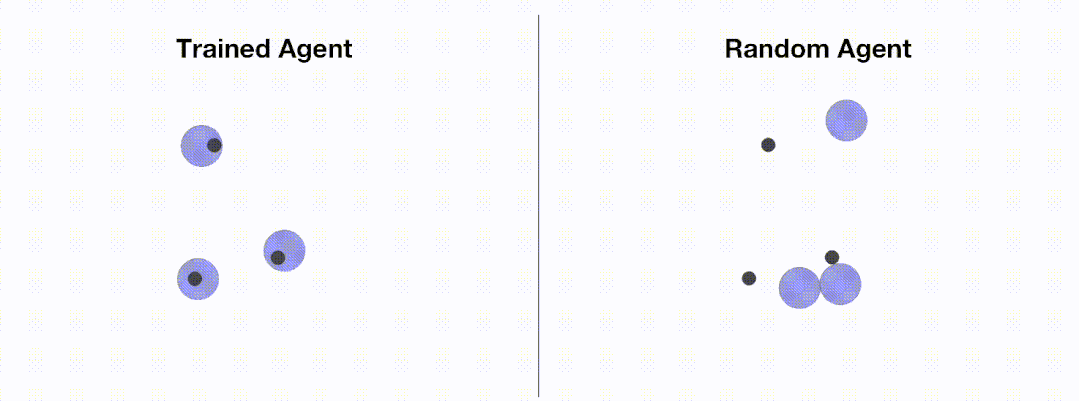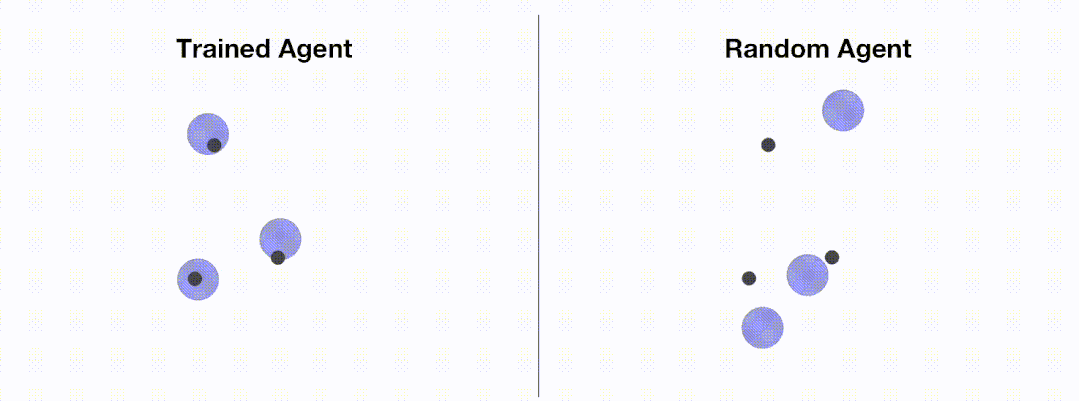
加载配置文件
此外,OpenRL 还同时支持从命令行和配置文件对训练参数进行修改。比如,用户可以通过执行 python train_ppo.py --lr 5e-4 来快速修改训练时候的学习率。
当配置参数非常多的时候,OpenRL 还支持用户编写自己的配置文件来修改训练参数。例如,用户可以自行创建以下配置文件 (mpe_ppo.yaml),并修改其中的参数:
# mpe_ppo.yamlseed: 0 # 设置seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个episode的长度use_recurrent_policy: true # 设置是否使用RNNuse_joint_action_loss: true # 设置是否使用JRPO算法use_valuenorm: true # 设置是否使用value normalization最后,用户只需要在执行程序的时候指定该配置文件即可:
python train_ppo.py --config mpe_ppo.yaml训练与测试可视化
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:
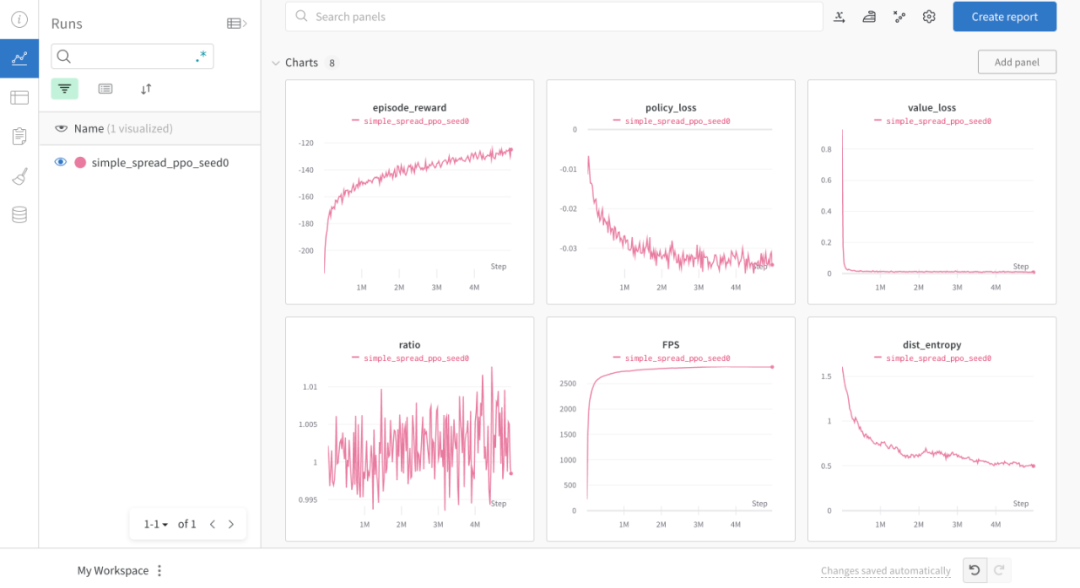
OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为"group_human",便可以同时对多个并行环境进行可视化:
env = make("simple_spread", env_num=9, render_mode="group_human")此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper(env, "test_simple_spread.gif")智能体的保存和加载
OpenRL 提供 agent.save() 和 agent.load() 接口来保存和加载训练好的智能体,并通过 agent.act() 接口来获取测试时的智能体动作:
# test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成gifdef test(): # 创建 MPE 环境 env = make( "simple_spread", env_num=4) # 使用GIFWrapper,用于生成gif env = GIFWrapper(env, "test_simple_spread.gif") agent = Agent(Net(env)) # 创建 智能体 # 保存智能体 agent.save("./ppo_agent/") # 加载智能体 agent.load('./ppo_agent/') # 开始测试 obs, _ = env.reset() while True: # 智能体根据 observation 预测下一个动作 action, _ = agent.act(obs) obs, r, done, info = env.step(action) if done.any(): break env.close()if __name__ == "__main__": test()执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户 加载自己的数据集 , 自定义训练模型, 自定义奖励模型, 自定义 wandb 信息输出 以及 一键开启混合精度训练 等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
# train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train(): # 添加读取配置文件的代码 cfg_parser = create_config_parser() cfg = cfg_parser.parse_args() # 创建 NLP 环境 env = make("daily_dialog",env_num=2,asynchronous=True,cfg=cfg,) net = Net(env, cfg=cfg, device="cuda") agent = Agent(net) agent.train(total_time_steps=5000000)if __name__ == "__main__": train()可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
# nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数 args: {'tokenizer_path': 'gpt2'} # 读取tokenizer的路径seed: 0 # 设置seed,保证每次实验结果一致lr: 1e-6 # 设置policy模型的学习率critic_lr: 1e-6 # 设置critic模型的学习率episode_length: 20 # 设置每个episode的长度use_recurrent_policy: true上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称 或者 本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称 或者 本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
# nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数 args: {'tokenizer_path': 'gpt2'} # 读取tokenizer的路径lr: 1e-6 # 设置policy模型的学习率critic_lr: 1e-6 # 设置critic模型的学习率episode_length: 128 # 设置每个episode的长度num_mini_batch: 20然后在 train_ppo.py 中添加以下代码:
# train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import ( PolicyValueNetworkGPT as PolicyValueNetwork,)def train(): # 添加读取配置文件的代码 cfg_parser = create_config_parser() cfg = cfg_parser.parse_args() # 创建 NLP 环境 env = make("daily_dialog",env_num=2,asynchronous=True,cfg=cfg,) # 创建自定义神经网络 model_dict = {"model": PolicyValueNetwork} net = Net(env, cfg=cfg, model_dict=model_dict) # 创建训练智能体 agent = Agent(net) agent.train(total_time_steps=5000000)if __name__ == "__main__": train()通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
model_dict = { "policy": CustomPolicyNetwork, "critic": CustomValueNetwork,}net = Net(env, model_dict=model_dict)自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励 的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
# nlp_ppo.yamlreward_class: id: NLPReward # 奖励模型名称 args: { # 用于意图判断的模型的名称或路径 "intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier, # 用于计算KL散度的预训练模型的名称或路径 "ref_model": roberta-base, # 用于意图判断的tokenizer的名称或路径 }OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
# train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register("CustomReward", CustomReward)最后,用户只需要在配置文件中填写自定义的奖励模型即可:
reward_class: id: "CustomReward" # 自定义奖励模型名称 args: {} # 用户自定义奖励函数可能用到的参数自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
# nlp_ppo.yamlvec_info_class: id: "NLPVecInfo" # 调用NLPVecInfo类以打印NLP任务中奖励函数的信息#设置wandb信息wandb_entity: openrl # 这里用于指定wandb团队名称,请把openrl替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个episode上传一次wandb数据# 自行填写其他参数...修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
# train_ppo.pyagent.train(total_time_steps=100000, use_wandb=True)然后执行 python train_ppo.py –config nlp_ppo.yaml,过一会儿,便可以在 wandb 中看到如下的输出:
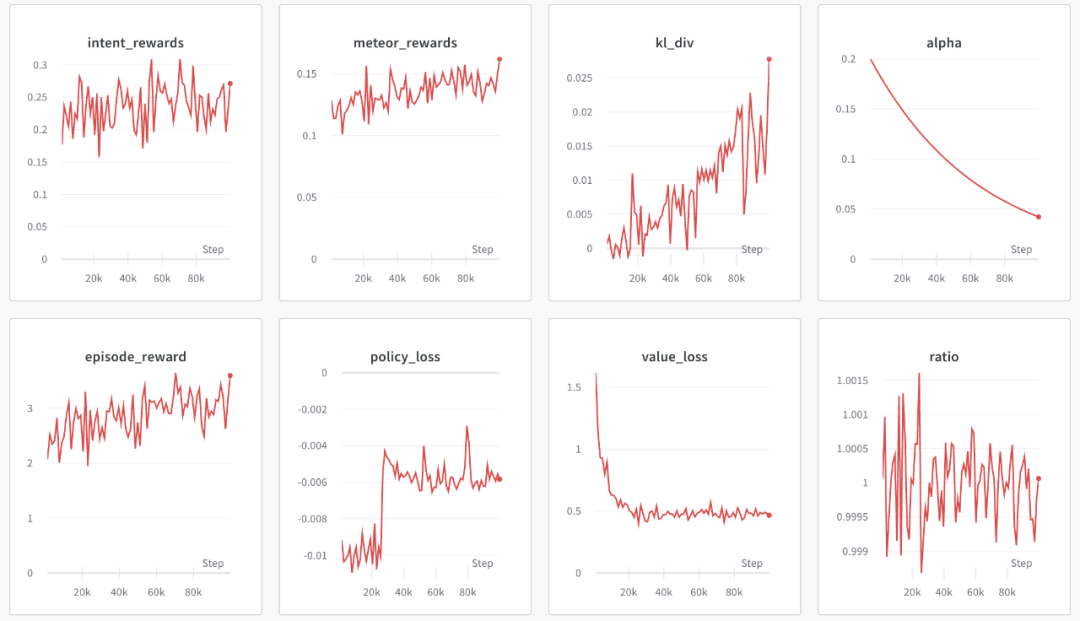
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
# train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register("CustomVecInfo", CustomVecInfo)最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
# nlp_ppo.yamlvec_info_class: id: "CustomVecInfo" # 调用自定义CustomVecInfo类以输出自定义信息使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
# nlp_ppo.yamluse_amp: true # 开启混合精度训练对比评测
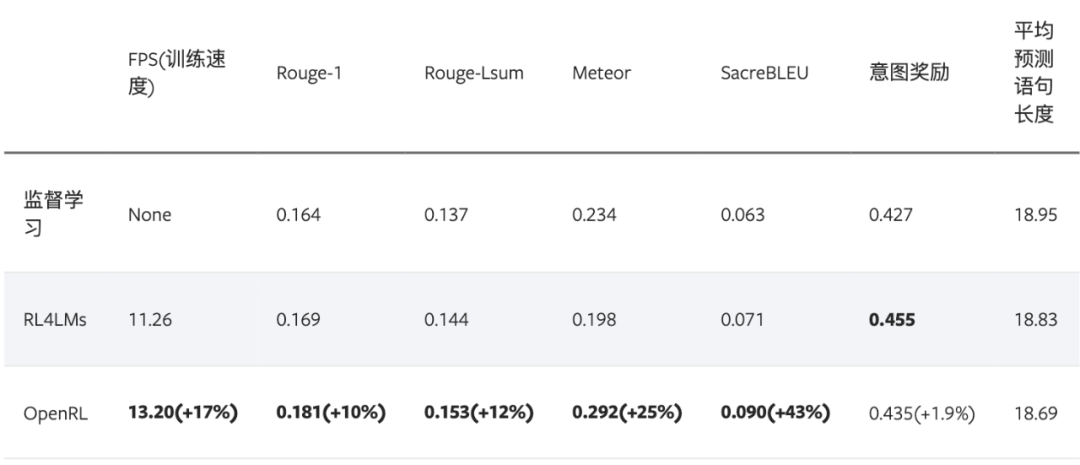
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
最后,对于训练好的智能体,用户可以方便地通过 agent.chat() 接口进行对话:
# chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat(): agent = Agent.load("./ppo_agent", tokenizer="gpt2",) history = [] print("Welcome to OpenRL!") while True: input_text = input("> User: ") if input_text == "quit": break elif input_text == "reset": history = [] print("Welcome to OpenRL!") continue response = agent.chat(input_text, history) print(f"> OpenRL Agent: {response}") history.append(input_text) history.append(response)if __name__ == "__main__": chat()执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
●OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
●OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
●Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
●pytorch-a2c-ppo-acktr-gail: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
●MAPPO: https://github.com/marlbenchmark/on-policy
●Gymnasium: https://github.com/Farama-Foundation/Gymnasium
●DI-engine: https://github.com/opendilab/DI-engine/
●Tianshou: https://github.com/thu-ml/tianshou
●RL4LMs: https://github.com/allenai/RL4LMs
未来工作
目前,OpenRL 还处于持续开发和建设阶段,未来 OpenRL 将会开源更多功能:
●支持智能体自博弈训练
●加入离线强化学习、模范学习、逆强化学习算法
●加入更多强化学习环境和算法
●集成 Deepspeed 等加速框架
●支持多机分布式训练
OpenRL Lab 团队
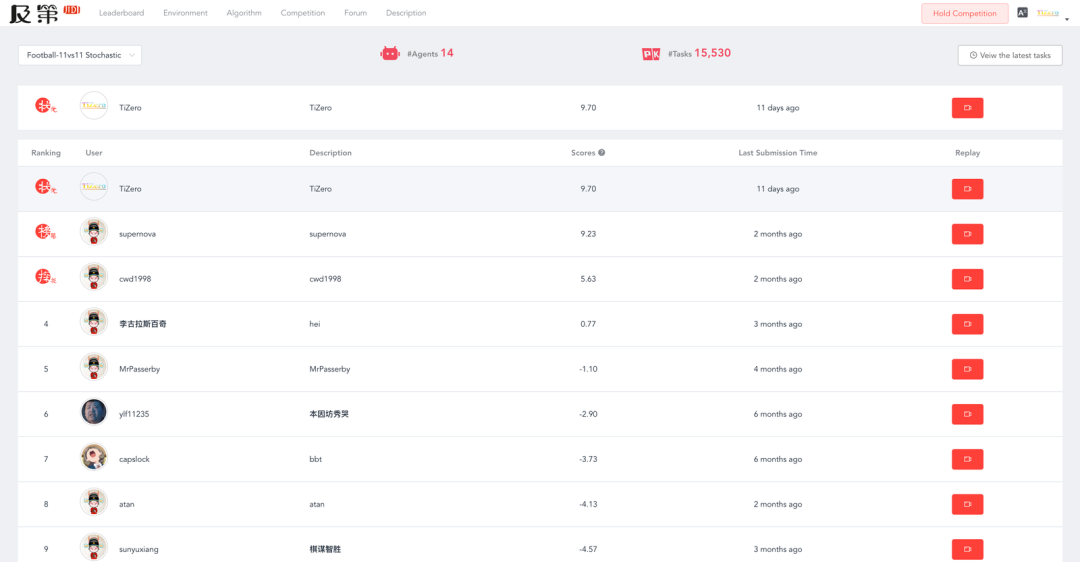
OpenRL 框架是由 OpenRL Lab 团队开发,该团队是第四范式公司旗下的强化学习研究团队。第四范式长期致力于强化学习的研发和工业应用。为了促进强化学习的产学研一体化,第四范式成立了 OpenRL Lab 研究团队,目标是先进技术开源和人工智能前沿探索。成立不到一年,OpenRL Lab 团队已经在 AAMAS 发表过三篇论文,参加谷歌足球游戏 11 vs 11 比赛并获得第三的成绩。团队提出的 TiZero 智能体,实现了首个从零开始,通过课程学习、分布式强化学习、自博弈等技术完成谷歌足球全场游戏智能体的训练:

截止 2022 年 10 月 28 日,Tizero 在及第评测平台上排名第一:
作者介绍
黄世宇,第四范式强化学习研究员。博士毕业于清华大学计算机系,博士导师是朱军和陈挺教授,本科期间在 CMU 交换,导师为 Deva Ramanan 教授。主要研究方向为强化学习,多智能体强化学习,分布式强化学习。曾在腾讯 AI Lab、华为诺亚、商汤、RealAI 工作。




