
写在前面
MuseAI 是由阿里集团爱橙科技研发的面向阿里内部的 AIGC 创作工作台,同时通过与阿里云旗下魔搭社区合作共建的形式,将主体能力通过魔搭社区的 AIGC 专区对公众开放。本文主要分析了平台由于频繁切换 Diffusion Pipeline 引起的用户体验与资源浪费问题,并从网络传输、内存管理、Host-to-Device、模型量化等方面着手优化。
考虑到 MuseAI 平台本身是公司内部服务,下文通过底层技术同源的魔搭社区 AIGC 专区来做说明与介绍,为避免混淆,下文如未特意提及,“MuseAI”和“魔搭社区 AIGC 专区”指代同一事物。
一、背景 Background
MuseAI 是一款专为设计专业人士量身定制的先进 AI 绘图工具,旨在提供卓越的绘画体验,并为设计团队打造一个既稳定又易于管理的创作平台。基于尖端的扩散模型(Diffusion Model)技术,MuseAI 不仅提供了强大的推理与训练服务,还允许用户通过简化的文本输入和参数设置(包括选择模型版本及设定分辨率等),轻松实现心中构想的视觉作品。
在 MuseAI 的核心——Diffusion Pipeline 中,多个模型协同工作以生成高质量图像。这一流程包括以下关键组件:
基础模型:包括 SD1.5、SDXL、SD3 和 FLUX 算法的基础模型,文件大小从 1GB 到 20GB 不等。
LoRA 微调模型:采用轻量级调整技术,通过添加少量可训练层来对基础模型进行个性化调整,适应多样化的风格需求,如卡通或写实效果,体积通常介于 100MB 至 1GB 之间。
ControlNet 控制模型:用于根据具体条件(如人物姿态、面部表情或背景设定)精确指导图像合成,其文件大小大约在 500MB 至 10GB 范围内。
辅助性模型:包含 VAE 编码器、CLIP 特征提取器、T5 语言模型以及其他注解工具,它们虽功能独立但不可或缺,多数情况下预先加载以便即时使用,单个文件大小约在 100MB-10GB 左右。
MuseAI 集成了丰富的资源库,涵盖数百款 Checkpoint 模型、数千种 LoRA 模型以及数十种适用于不同场景的 ControlNet 方案,并支持用户上传自定义模型,既促进了个人创意表达,也鼓励了社区内的资源共享。然而,面对如此庞大的模型库,我们面临的主要挑战之一是如何有效地管理这些资源,在不影响用户体验的前提下最小化模型切换时间。
为了应对这一挑战,MuseAI 不断探索并实践创新方法,致力于减少请求间的流水线切换时间。尽管学术界和工业界已有诸多关于提升模型推理速度的研究成果,但在减少模型切换时间方面的工作仍然相对稀缺。因此,我们将分享一些 MuseAI 在过去一段时间内积累的经验,希望能为相关研究和技术发展提供有价值的参考。
二、问题 Problem
在深入探讨之前,有必要对一些关键概念进行明确定义,以确保讨论的准确性和一致性。以下是与 MuseAI 平台性能优化相关的几个重要时间度量:
端到端生成时间:从用户提交请求开始,直到推理集群完成图像生成并将结果返回给用户为止的总时间。
模型下载时间:从 MuseAI 的远程存储中下载模型参数至推理集群所在机器磁盘所需的时间。
模型读取时间:将模型参数从磁盘加载到内存所需的时间。
模型切换时间:从模型参数加载到内存后,到其在 GPU 上准备就绪、能够执行推理任务的这段时间。
模型推理时间:模型在 GPU 上实际执行推理计算所需的时间。
请注意,虽然“请求排队时间”(即从用户发起请求到请求进入推理集群的时间)是用户体验的一个重要因素,但它主要受用户请求数量和可用集群资源的影响,因此在本文后续讨论中不会被考虑。这使得我们可以集中精力研究其他影响端到端生成时间的因素,即:
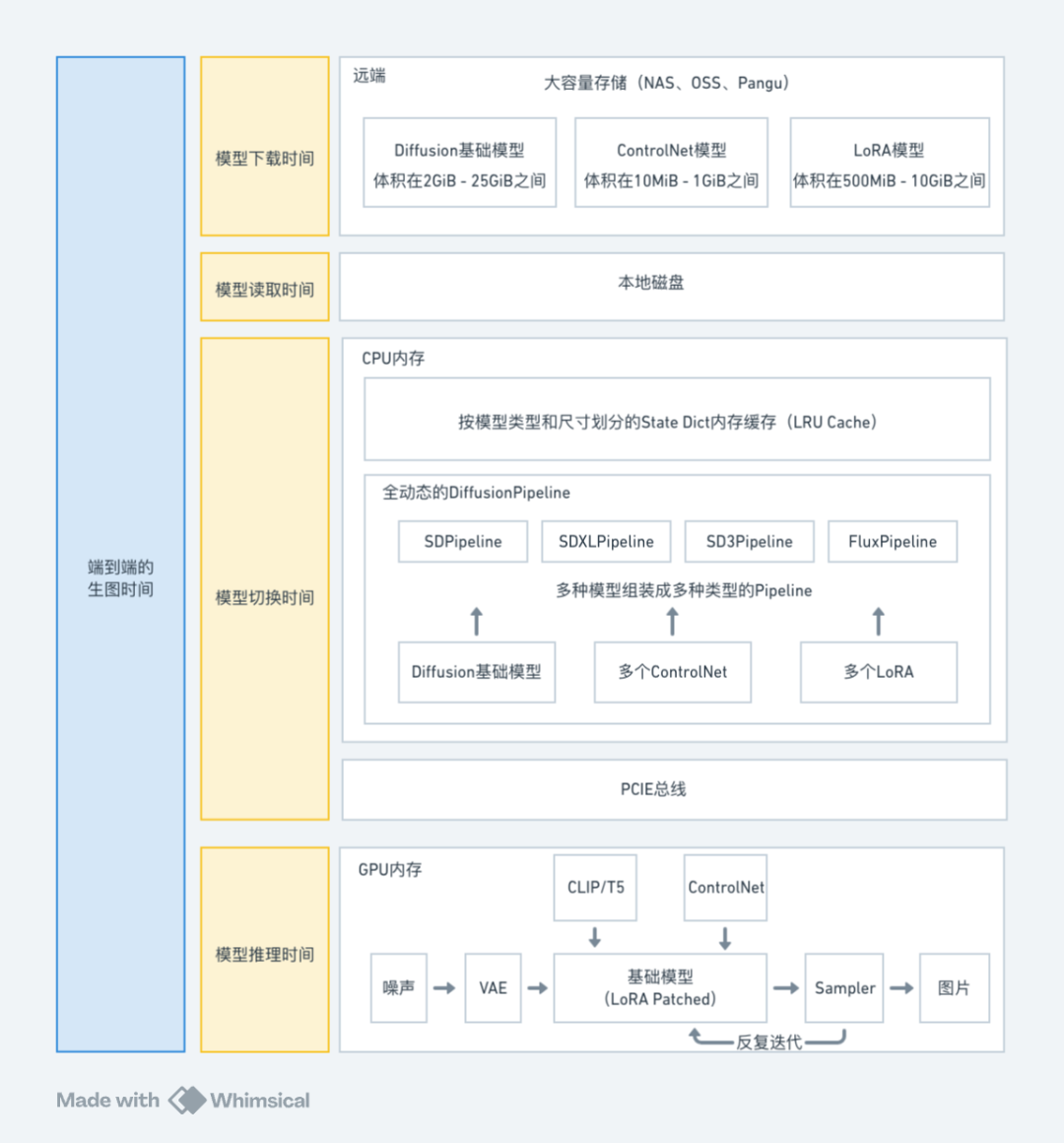
上图仅形式化地展示了各个时间阶段对应的流程内容,并不反映实际的时间占比。在实际情况中,每个阶段的时间消耗会受到多种因素的影响,包括但不限于模型类型、模型大小、模型存储方式、缓存命中情况以及硬件性能等。
为了更好地理解这些因素如何共同作用于端到端生成时间,以下是一组基于 MuseAI 平台真实请求的数据,展示了各阶段时间消耗的分布情况:

表 1. MuseAI 真实请求下端到端生图时间的耗时分布
在上述简易测试中,我们通过清空 Linux 的 PageCache(使用命令 sudo sh -c “echo 1 > /proc/sys/vm/drop_caches”),模拟了首次推理的冷启动场景。此时,系统完全没有任何缓存支持,因此模型下载时间、模型读取时间和模型切换时间都显著增加。具体表现如下:
第一次推理(冷启动):所有数据必须从远程存储下载到本地磁盘,再加载到内存,并最终迁移到 GPU 上准备就绪。这个过程涉及大量的 I/O 操作和数据传输,导致整体耗时较长。
第二次推理(PageCache 命中):这次推理是在重启 Worker 但不重启物理机的情况下进行的。虽然无法命中 Worker 内部的内存缓存,但由于 Linux PageCache 的存在,模型文件可以从缓存中快速加载,减少了模型下载时间和部分读取时间。然而,模型切换时间仍然相对较长,因为需要重新加载模型到 GPU 上。
第三次推理(内存缓存命中):当模型已经被加载到 Worker 的内存缓存中时,模型下载时间和模型读取时间几乎为零。模型切换仅需执行 Host-to-Device (H2D) 的传输操作,并且由于之前的推理已经预热了 CUDA 层面的资源,模型推理时间也达到了最短。
从上述简易测试的数据可以看出,在没有缓存命中的情况下,模型下载、模型加载和模型切换时间占据了端到端生成时间的绝大部分。这表明这些阶段的时间消耗是不可忽视的,尤其是在 MuseAI 这样的多模型环境下,缓存未命中的情况更为普遍。
MuseAI 平台集成了大量不同类型的模型,使得将所有模型都缓存到磁盘或内存中变得极为困难。因此,平台不得不频繁面对缓存未命中的挑战,这对用户体验和服务效率产生了负面影响。
鉴于此,我们的研究重点将集中在以下几个方面:
1. 增强硬件与软件协同优化:
利用新型硬件特性(如 NAS、高速网络等)提升数据访问速度。
优化软件栈,包括操作系统层面的调整和应用层的优化,以更好地匹配硬件性能特点。
2. 提升模型构建与加载效率:
使用 skip_init 技术消除 torch Module 无意义初始化时间。
通过多线程最大化 H2D 数据传输效率,减少模型切换过程中的延迟。
3. 内存管理与复用:
通过零拷贝、内存池技术,以更高效地管理内存资源,减少频繁分配和释放带来的开销。
4. 模型量化:
利用新一代 GPU 架构性能,在保持生图效果的同时为模型瘦身。
5. 模块拆解并行:
T5 语言模型独立部署,将 text encoder 与模型切换环节并行。
三、方法 Method
模型加载优化
模型加载 是指推理服务从存储介质加载模型数据到内存的时间,涵盖了前文所述的“模型下载时间”与“模型读取时间”。模型加载时间不仅依赖于存储介质的理论性能,还需要通过最佳实践来充分发挥其性能。因此,本节将围绕“基于业务特性选择存储介质”和“如何充分发挥存储介质性能”两点展开讨论。
1.1 业务特性分析
在 Diffusion 生图社区中,模型种类繁多且数量庞大,难以将所有模型都存储在服务端本地磁盘上。因此,选择适当的存储介质至关重要,以确保模型能够高效地保存并快速读取。
截至撰写本文时,最大的生图模型网站 Civitai AI 上常用的模型属性如下表所示。考虑到算法版本的迭代,SD1.5 的模型将逐渐被淘汰,同时高质量的生成效果模型相对较少。综合评估后,400 TB 的存储容量对于 MuseAI 来说是充足的。
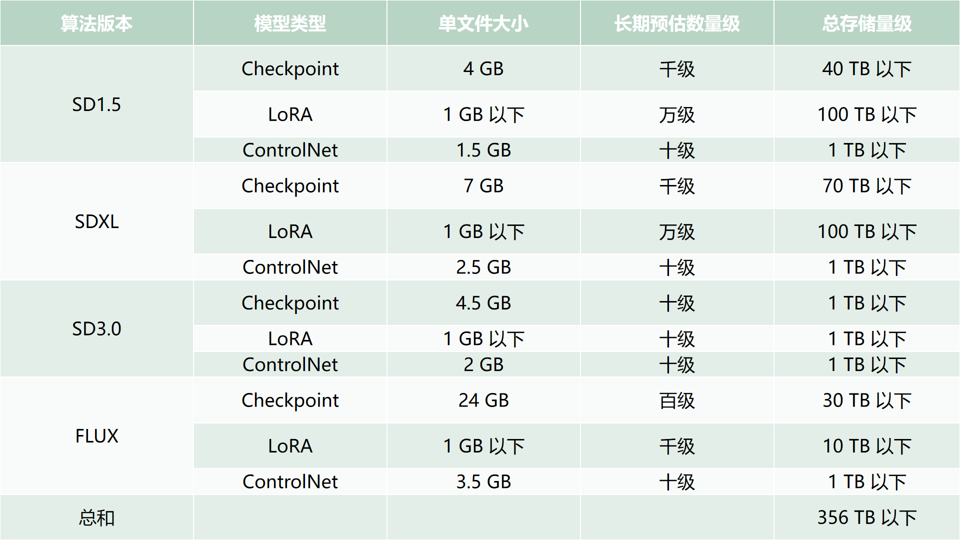
表 2. 模型总量存储统计
根据第二章提供的“MuseAI 真实请求下端到端生图时间的耗时分布”表格,当前 MuseAI 第一次生图的实际推理时间约为 10 秒,但“模型下载时间”与“模型读取时间”的总和却接近其 10 倍。这不仅严重影响了用户体验,还造成了 GPU 资源的极大浪费。目前,模型下载速度仅为 100 MB/s,而服务器的网卡带宽为 2 GB/s,显然,提升带宽利用率以减少非推理时间占比是当务之急。
简而言之,MuseAI 的业务特性对存储方案提出了以下要求:
存储容量:至少 400 TB;
单实例读取性能:超过 2 GB/s,以确保快速的数据传输;
总读带宽:尽可能大,以支持高并发请求;
读带宽横向扩展性:能够随着业务流量的增长灵活扩展。
1.2 存储方案选型
在选择适合 MuseAI 平台的存储介质时,我们考虑了多种常见的文件存储方案,包括对象存储服务(OSS)、网络附加存储(NAS)以及阿里内部的分布式集群存储服务“盘古”,三者的特点简单归纳如下:
对象存储服务 (OSS):广泛应用于互联网业务中,具备高可用性和无限扩展性,适用于大规模数据存储。然而,从 OSS 读取模型时需要先下载到本地磁盘再加载到内存,增加了两次数据拷贝的时间开销。
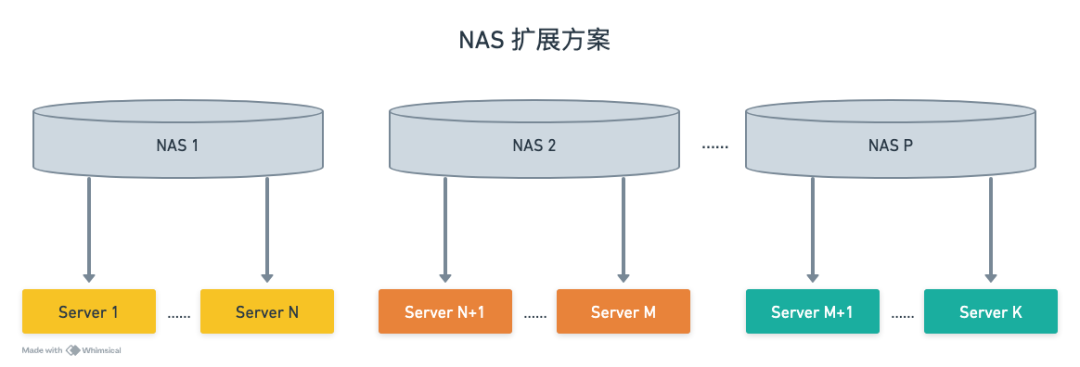
网络附加存储 (NAS):提供 POSIX 兼容的文件系统接口,易于集成和使用。NAS 的主要挑战在于单个实例的带宽瓶颈,当达到极限时,需要通过复制数据到多个 NAS 实例并分组绑定服务器来扩展,这增加了管理和维护的复杂度。
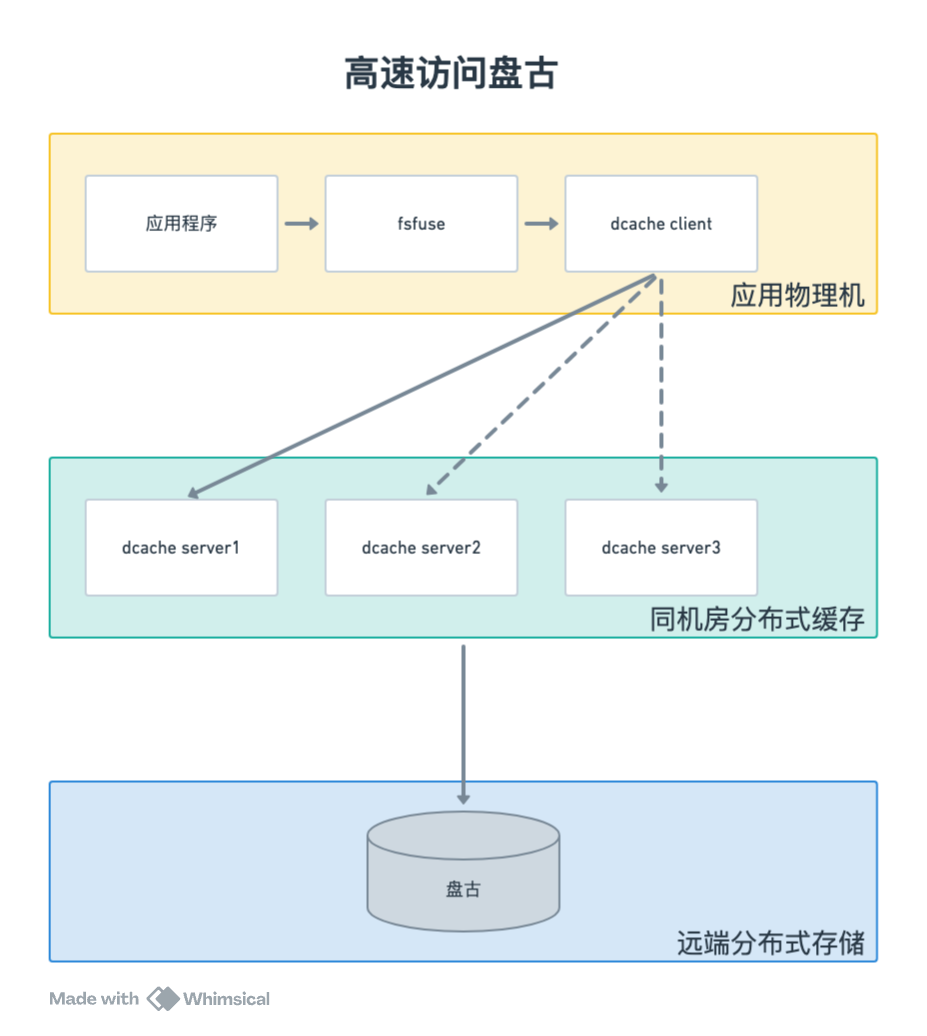
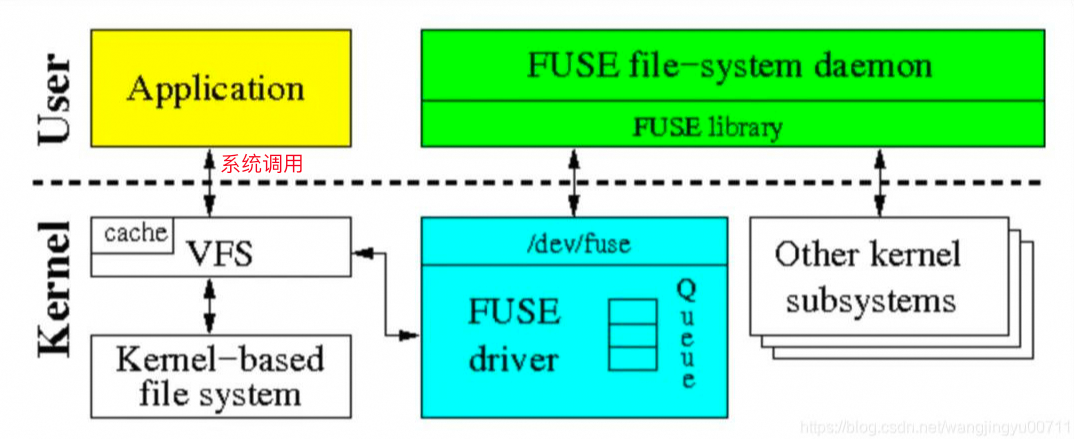
盘古: 是阿里内部的分布式集群存储系统,以高性能和稳定性著称。盘古是一个复杂的分布式服务,由 Client、ChunkServer 和 Master 组成,当上层应用通过 Client 提出读取请求时,Client 需要首先向 Master 通信查找相关 metadata,从而得知数据在哪几个 Chunkserver 上,然后拿到实际的数据。Client 提供的接口相对底层,且配置较为复杂,为降低使用难度,阿里内部为其封装了自定义 fuse(Filesystem in Userspace) 文件系统 fsfuse,并配套 dcache 服务进一步提高读取性能:
fsfuse: 提供了一种无缝、透明、高效的数据访问方法,封装了 POSIX 文件系统接口,使得业务可以像访问本地文件一样操作分布式后端存储。
dcache: 分为 dcache client 和 dcache server,在每个地域会部署一份,避免跨地域访问。dcache server 作为 LRU 分布式缓存服务,主要采用了 3 种策略提高盘古访问性能:
meta 缓存,保证本地能快速获取 meta 而降低高延时的 rpc 请求量;
block 缓存,read 系统调用通常单次读取 128K,而单次 RPC 耗时较长,每个 128K 都走 RPC 调用代价过大,所以 fsfuse 会以 8M 数据请求数据块,并将多个 8M block 组成较大的 block 缓存池,以让业务的读取请求尽可能命中本地缓存;
block 预读,业务连续顺序读取 block 时,会触发预读更多 block。
每种方案都有其独特的优势和适用场景,如下表所示。
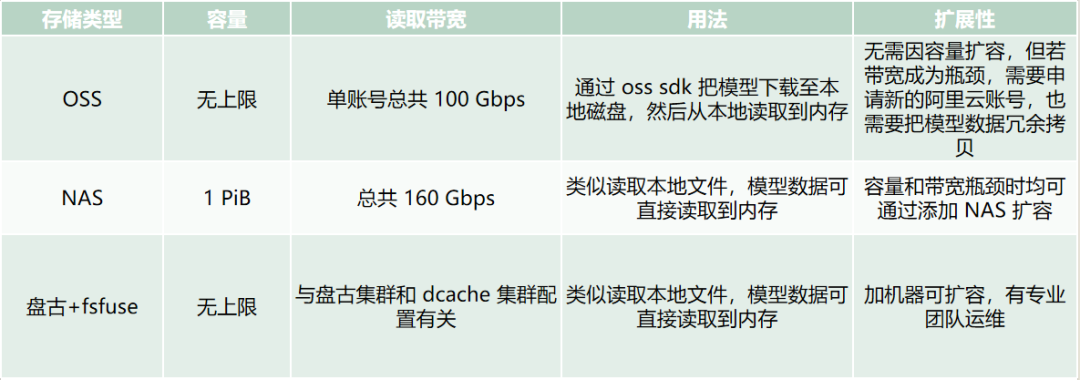
表 3. 存储方案特点
三种存储方案都能满足 MuseAI 的容量需求,但在读取性能和扩展性方面存在显著差异:
读取性能:
OSS:由于需要两次数据拷贝(从 OSS 下载到本地磁盘,再从磁盘读取到内存),整体读取时间较长。
NAS 和 盘古 +fsfuse:可以直接将远端数据读取到内存中,避免了额外的拷贝步骤,大大提高了读取效率。
扩展性:
NAS:当单个 NAS 达到带宽瓶颈时,需要进行数据复制和服务器分组绑定,增加了扩展难度。
盘古 +fsfuse:得益于盘古强大的底层支持和 fsfuse 的缓存集群服务,MuseAI 的读取流量对盘古总读带宽影响极小。只需扩容 fsfuse 缓存集群服务,即可轻松应对流量增长,无需其他变动,扩展更简单快捷。
综上所述,基于 MuseAI 的业务需求和技术特点,我们决定采用以下存储策略:
公有云:使用 NAS,因其易于集成和管理,适合外部部署。
公司内部:使用 盘古 +fsfuse,充分发挥其高性能和扩展性优势,确保快速稳定的模型加载体验。
1.3 NAS 最佳实践
在 MuseAI 平台中,选择合适的 NAS 类型和优化其配置对于确保高效的模型加载至关重要。阿里云 NAS 提供了通用型和极速型两种主要类型,前者适合存储大量数据且对总吞吐量有需求的场景,后者则适用于处理大量的读写请求和对响应延迟要求较高的场景。鉴于 MuseAI 的业务特性——需要存储大量模型数据并保证高吞吐量,我们选择了通用型 NAS。

表 4. 通用型和极速型 NAS
为了验证 ECS 实例与 NAS 之间的连接性能,我们在 ecs.g7ne.12xlarge 规格(48 核 192G 内存 40 Gbit/s 带宽)的 ECS 上进行了性能测试。由于通用型 NAS 的读带宽与容量有关,我们首先创建了一个 33TB 的文件以确保 NAS 能够达到 20 GB/s 的读带宽。
truncate -s 33T /mnt/nas通过阿里云控制台默认挂载参数进行测试,采用 nfsv3 协议并通过 TCP 访问,具体挂载参数如下。
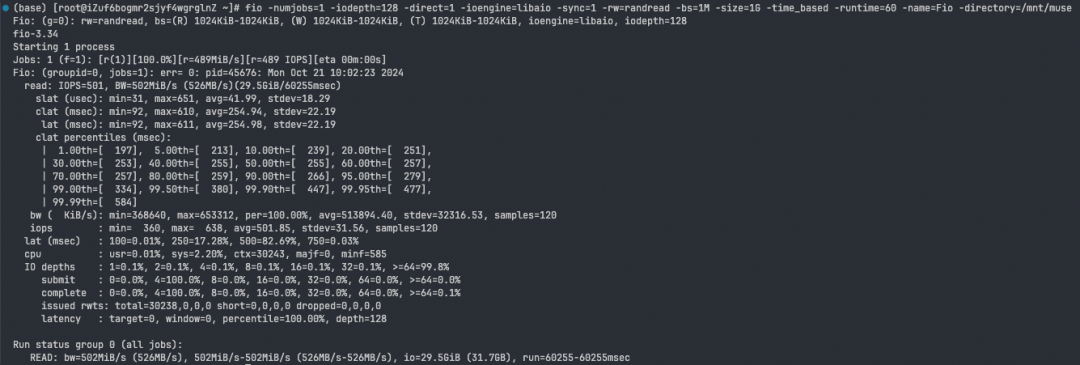
vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport使用 fio 测速工具测试 NAS 的随机读取吞吐量,命令如下。
fio -numjobs=2 -iodepth=128 -direct=1 -ioengine=libaio -sync=1 -rw=randread -bs=4M -size=1G -time_based -runtime=60 -name=Fio -directory=/mnt/muse初次测试结果显示,读取速度仅为 500 MB/s,远低于机器网卡上限(40 Gbit/s)和 NAS 读带宽上限(160 Gbit/s),显然存在性能瓶颈。
经过排查,发现 NFS 客户端和服务器之间默认仅通过一个 TCP 连接通信,并且阿里云 NAS 前端机限制了每条连接的带宽上限。为了解决这一问题,我们调整了 Linux 内核参数,特别是 nconnect 参数,该参数控制 NAS 与客户端之间的连接数,默认值为 1,最大值为 16。
优化步骤:
修改挂载选项,将 nconnect 设置为 16。
重新挂载 NAS 文件系统,确保新的连接数生效。
vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport,nconnect=16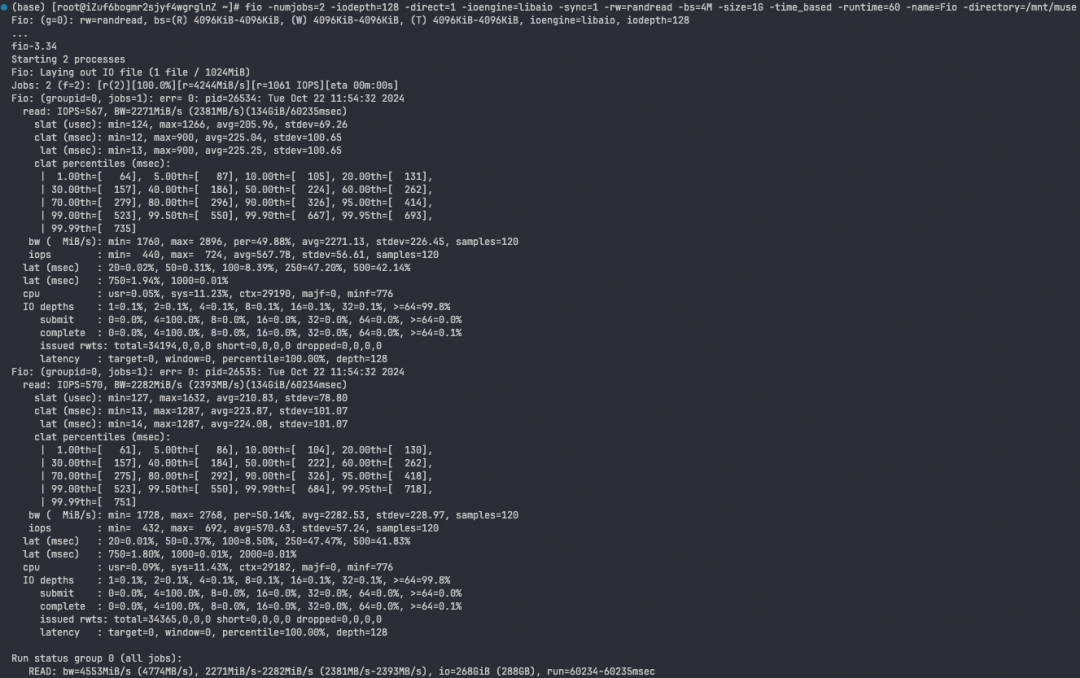
增加 TCP 连接数后,读取带宽显著提升至 4500 MB/s,达到了网卡带宽的大约 90%,效果明显。此外,我们还采用了多线程并发读取模型文件的方法,进一步充分利用网络带宽,确保了高性能的数据传输。
inline int read_file(int fd, void *buf, size_t nbytes, off_t offset) { std::stringstream oss; uint64_t total_read_bytes = 0; while (total_read_bytes < nbytes) { void *buf = (char*)buf + total_read_bytes; ssize_t n = pread(fd, buf, nbytes - total_read_bytes, offset + total_read_bytes); if (n == 0) { oss << "cannot read expected " << nbytes << " bytes, total read bytes: " << total_read_bytes; throw SafetensorsException(oss.str()); } if (n < 0) { oss << "pread failed. fd: " << fd << ", bytes: " << nbytes << ", errorno: " << errno; throw SafetensorsException(oss.str()); } total_read_bytes += n; } return 0;}void multi_thread_read_file(int fd, void *buf, size_t start_offset, size_t end_offset, int num_threads) { uint64_t file_offset = start_offset; uint64_t buf_offset = 0; uint64_t data_size = end_offset - start_offset; uint64_t block_size = (data_size + num_threads - 1) / num_threads; ThreadPool pool(num_threads); std::vector<std::future<int>> futures; char *buf = reinterpret_cast<char*>(buf); for (int i = 0; i < num_threads; ++i) { size_t read_bytes = std::min(end_offset - file_offset, block_size); void *store = reinterpret_cast<void*>(buf + buf_offset); futures.emplace_back( pool.enqueue(read_file, fd, store, read_bytes, file_offset)); file_offset += read_bytes; buf_offset += read_bytes; } for (auto &future : futures) { future.get(); }}1.4 盘古 + fsfuse 最佳实践
在 MuseAI 平台中,盘古结合 fsfuse 提供了一种高效、透明的数据访问方式,极大地提升了模型加载的性能。为了充分发挥这一组合的优势,我们总结了以下最佳实践:
挂载与目录管理:fsfuse 通过接口将盘古分布式文件系统挂载到本地,使得用户可以像访问本地路径一样读取数据。然而,fuse 的最大挂载上限数为 1024,对于 MuseAI 这样的服务,如果每次使用不同模型时都挂载不同的目录,很容易超过该上限,导致数据读取失败。最佳做法是将所有模型的父目录统一挂载到本地,这样只需要一个挂载点即可访问所有模型,避免了频繁挂载带来的问题。
缓存机制优化:fsfuse 在读取数据时会从盘古中预读取比用户请求更多的数据,并将其存储在缓存中。这种机制特别适用于顺序读取场景,因为预读取的数据能够显著提高缓存命中率,从而加快数据访问速度。推荐尽量采用顺序读取模式,以充分利用 fsfuse 的预读取和缓存机制,确保高效的数据访问。
Direct I/O 技术应用: 默认情况下,不使用 Direct I/O 技术时,每次 read 系统调用的大小为 128 KB。当读取大文件时,这会导致大量的系统调用,成为性能瓶颈。为了减少系统调用次数并提高读取效率,fsfuse 推荐使用 Direct I/O 技术。使用 Direct I/O 每次读取的 block 大小设置为 2 MB,这样可以将系统调用开销降低至原来的 1/16,极大减少了系统资源的消耗,在 fsfuse 缓存全命中的情况下,读取速度可达到 9 GB/s。
模型切换优化
在 MuseAI 平台中,模型切换时间是影响整体性能的关键因素之一。本章将详细介绍如何优化模型从内存加载到 GPU 的过程,包括 state dict 的传输、nn.Module 的构造和装载,以及进一步的性能提升策略。
2.1 内存中的模型切换时间组成
内存中的模型切换时间主要包括以下几个部分:
构造 nn.Module:创建模型实例。
nn.Module 装载 state dict:使用 load_state_dict 方法将 state dict 应用到模型上。
state dict 从 CPU 传输到 GPU:通过 to(“cuda:0”) 将内存中的 state dict 转换为 GPU 上的 state dict。
2.2 执行顺序优化
为了达成上述目标,一是可以让 nn.Module 先装载 state dict,再让 nn.Module 调用 to(“cuda:0”),二是先让 state dict 中的 tensor 执行 to(“cuda:0”),再让 nn.Module 装载 state dict。这两者之间是否有性能差异呢?
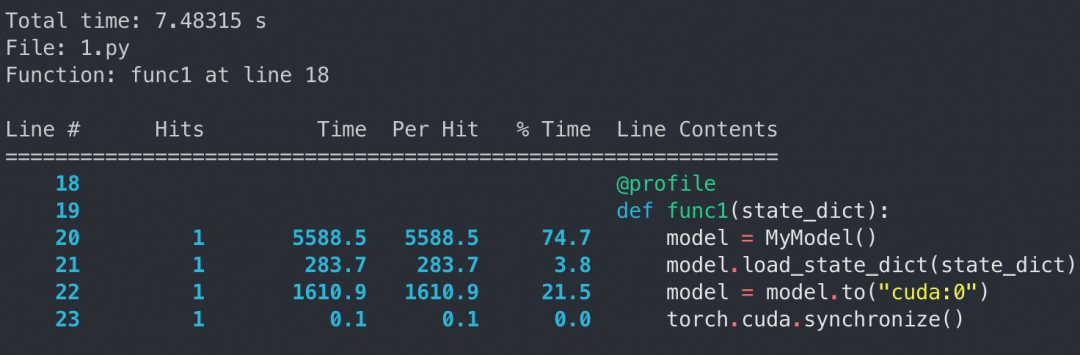
我们构造了一个 4.1 GB 的 safetensors 文件(忽略其读取时间),并通过实验对比了两种常见方案的性能差异。为了消除磁盘性能对实验的影响,我们在 profile 之前对 state dict 进行了 clone,确保每个 tensor 都已读取到内存中。
from safetensors.torch import load_file, save_fileimport torch.nn as nnclass MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.linear1 = nn.Linear(10, 1024) self.linear2 = nn.Linear(1024, 1024 * 1024) self.linear3 = nn.Linear(1024 * 1024, 10) def forward(self, x): x = self.linear1(x) x = self.linear2(x) x = self.linear3(x) return xstate_dict = load_file("test_model.safetensors")def func1(state_dict): model = MyModel() model.load_state_dict(state_dict) model = model.to("cuda:0") torch.cuda.synchronize()def func2(state_dict): model = MyModel() model = model.to("cuda:0") model.load_state_dict(state_dict) torch.cuda.synchronize()if __name__ == "__main__": state_dict = load_file("test_model.safetensors") new_state_dict = {} for key, value in state_dict.items(): new_state_dict[key] = value.clone() func1(new_state_dict) # func2(new_state_dict)先 load_state_dict 再 to:
先 to 再 load_state_dict:
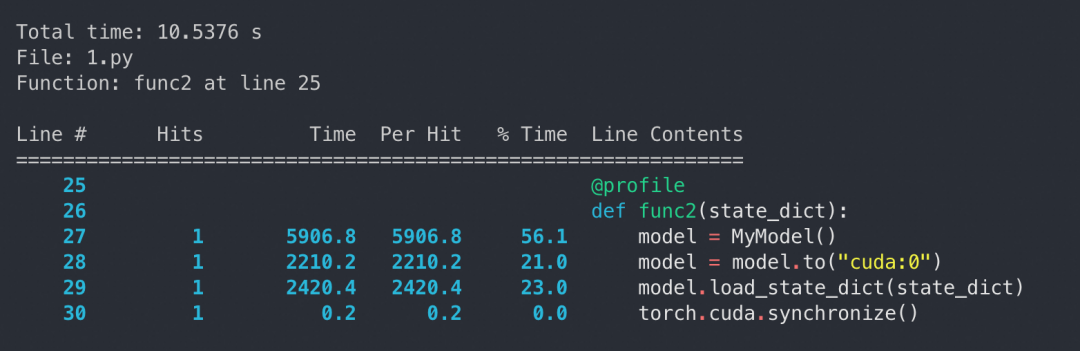
实验结果显示,先 load_state_dict 再 to(“cuda:0”) 的方法显著优于先 to(“cuda:0”) 再 load_state_dict。
问题关键点在于,MyModel 其实在构造完成后就已经持有了许多 tensor,而 load_state_dict 操作本质做的事情相当于:
model.load_state_dict(state_dict) 相当于for key, param in model.name_parameters(): param.data.copy_(state_dict[key])如果模型遵循 cpu-> gpu -> load_state_dict 的流程,并且 state_dict 本身的 tensor 在 cpu 内存上,那么就需要进行一批额外的 cpu to gpu 操作。因为 gpu tensor 只能拷贝 gpu tensor 的值,所以 state dict 被隐式的进行了 h2d 传输。
如果模型遵循 cpu -> load_state_dict -> gpu 的流程,那么就相当于把 gpu 上的 tensor copy 变成了 cpu 上的 tensor copy,节省了一大批的 h2d 操作,因此降低了整个流程的耗时。
简单总结两种执行顺序涉及的内存操作:
先 to 再 load_state_dict (cpu->gpu->load_state_dict): 需要进行 3 次 Tensor Copy 和 3 次 H2D 操作。
先 load_state_dict 再 to (cpu->load_state_dict->gpu): 仅需 3 次 H2D 操作,避免了额外的 CPU-GPU Tensor Copy。
因此,推荐采用 cpu->load_state_dict->gpu 的流程,以节省大量 H2D 操作,从而降低整个流程的耗时。
为了进一步缩短时间,可以在 load_state_dict 中传入参数 assign=True。这会直接用 state dict 的 tensor 充当 parameter 的 data,省去了参数数据拷贝的过程,从而加速模型装载。
2.3 H2D 传输性能优化
Tensor 从 CPU 到 GPU 的传输较为缓慢,主要原因在于通常持有的 tensor 内存是由 Linux 分配的 pagable memory,在传输到 GPU 前 CUDA API 会开辟临时的 pinned memory 空间,将 pagable memory 中的内容复制到该空间后再通过 PCI-E 总线传输到 GPU。
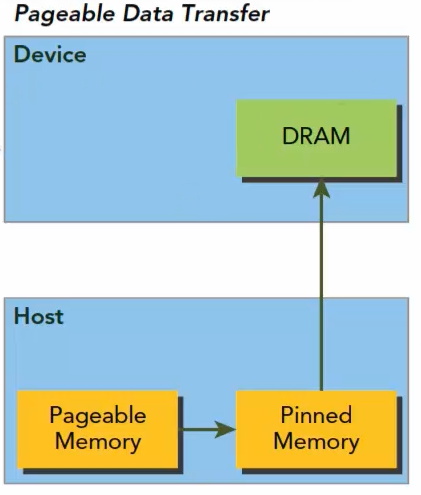
这里有一个简易的传输时间的对比,tensor 的大小是 16GB:

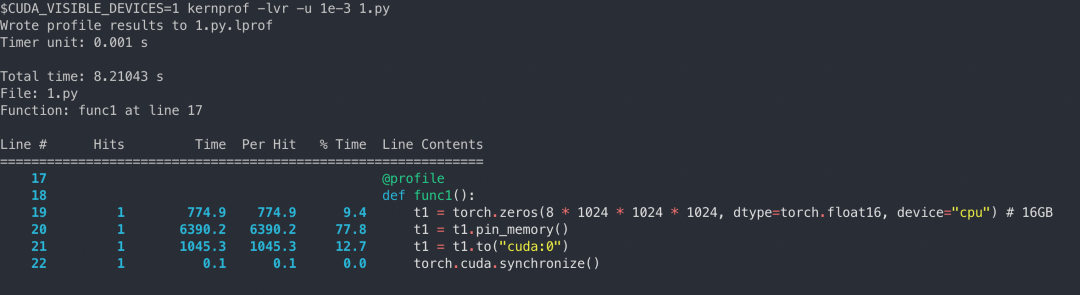
我们可以采取措施减少内存分配和拷贝的次数:
单独申请 pinned memory 可以显著减少传输时间,但申请内存本身有一定开销,利用内存池管理内存,减少分配次数。
确保 state dict 在分配时就放置在 pinned memory 上,消除 pinned memory 的分配和拷贝时间开销。
这部分优化细节放在下一章展开叙述。
2.4 H2D 传输性能优化
实际场景中的 state dict 往往包含成百上千个 tensor,顺序进行 H2D 操作效率较低。参考 PyTorch 官方文档的建议,我们可以使用 tensordict 包装 state dict,并结合 pin_memory、non_blocking 和多线程操作,实现并发异步传输,从而大幅提升性能。
2.5 Skip init 技术
我们可以看到 2.2 章节实验中的 MyModel 的构造时间其实也占了很大一块时间(5s 以上),但 2.3 章节实验中分配 16GB 的 tensor 只需要 500ms,说明 MyMode l 构造的时间大头并不是构造 tensor,这并不符合我们的预期。
我们对 nn.Linear 的 __init__ 函数进行单独 profile 可以发现,在 nn.Linear 构造过程中,绝大多数时间都集中在 reset_parameters 上:
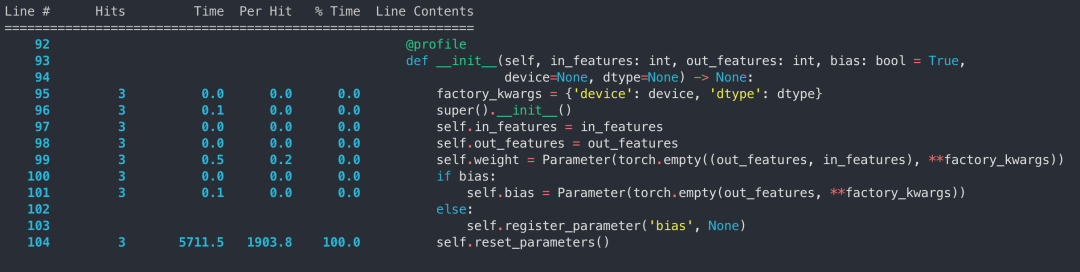
翻看 torch 的代码可以发现:
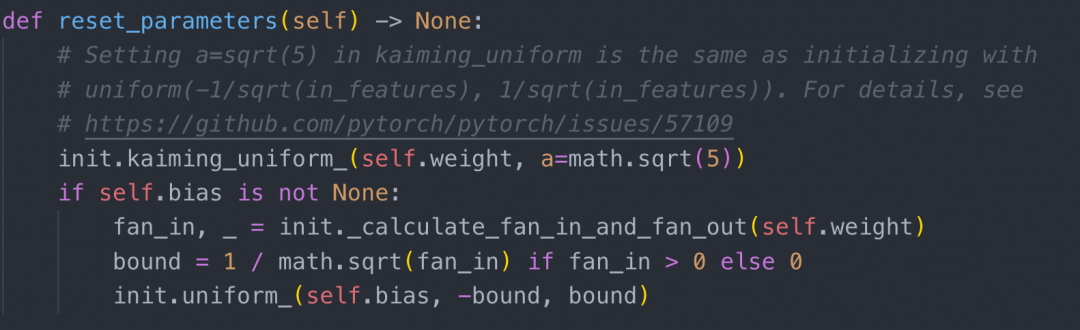
reset_parameters 本质上做的事情是在 nn.Parameters 构造后为 weight 和 bias 遵循 kaiming 初始化方法赋予初始值。这个步骤在模型训练中非常重要,但是在推理中显得很冗余,因为不管初始化 Parameter 的值是什么,我们都需要 load_state_dict 去覆盖这个值。PyTorch 提供了一种 skip init 技术,允许我们将模型构造在虚无的 meta 设备上,然后再迁移到 CPU 或 GPU,从而跳过初始化过程。
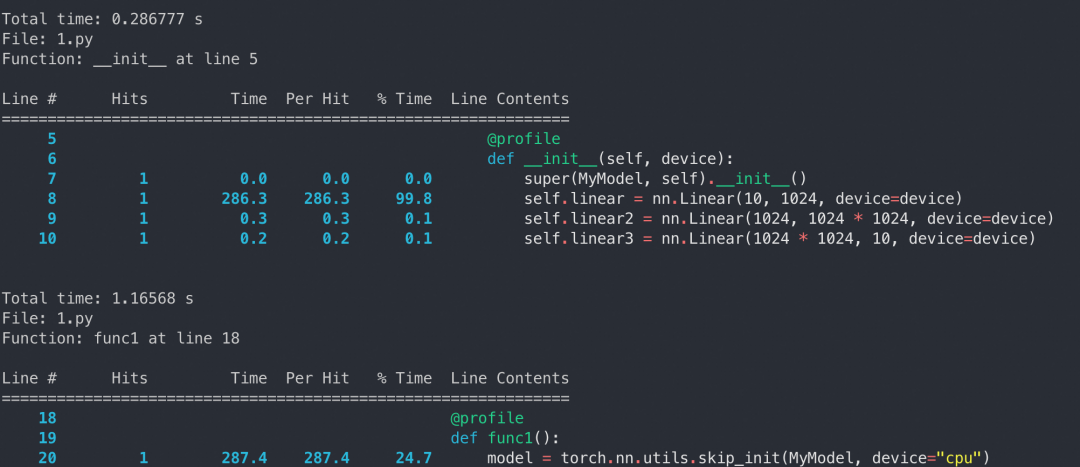
内存管理与复用
在 MuseAI 平台中,内存管理和复用是优化模型加载的关键环节。本章将详细介绍现有方案的性能问题,并提出相应的优化措施,以实现更高效的内存利用和更快的模型切换。
3.1 原方案性能分析
MuseAI 原有的模型加载和推理链路大致如下:
load_file 加载 safetensors:使用 Huggingface Safetensors 库 load_file 将 safetensors 文件加载为 state dict。
load_state_dict 初始化权重:模型调用 load_state_dict 方法初始化权重。
H2D 数据拷贝至显存:执行 model.to(“cuda:0”) 将数据从 CPU 拷贝到 GPU 显存。
推理执行:最终进行推理操作。
import torchimport torch.nn as nnfrom safetensors.torch import load_file, save_file## 定义模型 17GBclass MyModel(nn.Module): def __init__(self, device): super(MyModel, self).__init__() self.linear1 = nn.Linear(10, 1024, device=device) self.linear2 = nn.Linear(1024, 1024 * 1024, device=device) self.linear3 = nn.Linear(1024 * 1024, 1024, device=device) self.linear4 = nn.Linear(1024, 1024 * 1024, device=device) self.linear5 = nn.Linear(1024 * 1024, 1024, device=device) self.linear6 = nn.Linear(1024, 10, device=device) def forward(self, x): x = self.linear1(x) x = self.linear2(x) x = self.linear3(x) x = self.linear4(x) x = self.linear5(x) x = self.linear6(x) return x@profiledef load_baseline(model_path): state_dict = load_file(model_path) model = torch.nn.utils.skip_init(MyModel, device="cuda:0") model.load_state_dict(state_dict, assign=True) model = model.to("cuda:0") torch.cuda.synchronize() return modelif __name__ == "__main__": model_path = "test_model.safetensors" load_baseline(model_path)通过对 infer 函数进行 line profiler 分析,我们观察到了以下几个现象:
load_file 耗时 12 ms:原因是 Huggingface Safetensors 库利用 mmap 加载文件,此时模型数据实际上还未加载到内存。
model.to 耗时 14.7 秒:单线程遍历 state dict 中的所有数据,触发缺页异常实际把数据从文件读取到内存中,并且将 tensor 从内存拷贝至显存。此过程包括 malloc pinned_memory、copy pagable_memory to pinned_memory 和 copy pinned_memory to device_memory 三个步骤。
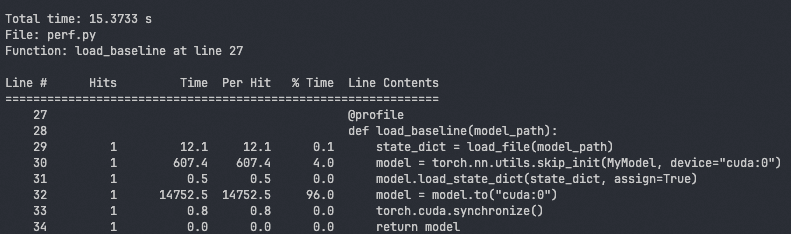
原方案存在以下性能问题:
单线程读取:无法充分利用分布式块存储服务的带宽。
非顺序访问:空间局部性差,对存储缓存不友好。
H2D 时的内存开销:
每次临时 malloc pinned_memory,用完即弃。
每次都会做一次内存拷贝,尽管内存带宽高,但增加了额外开销。
3.2 性能优化
针对上述性能问题,我们采取了以下优化措施,并已集成至文首提及的代码仓中:
改进模型加载方式: 根据前文所述的不同存储介质(NAS 和 盘古 +fsfuse),采用优化后的方案分别读取模型数据,充分利用多线程和分布式存储的优势,提升读取速度。
内存分配与拷贝优化:
维护 pinned_memory 内存池:避免每次推理重复 malloc 内存,减少不必要的内存分配和释放操作。
直接读取到 pinned_memory:消除一次内存拷贝,直接将文件数据读取到预分配的 pinned_memory 中,从而简化传输路径并提高效率。
两级内存池设计
虽然 MuseAI 涉及的模型类型较多,但每种模型大小在 [10MB, 24GB] 范围内。我们提前分配并维护几个固定大小的内存块,形成两级内存池。当有需求时从中拿一个适当的空闲块给用户,示意图如下所示 。
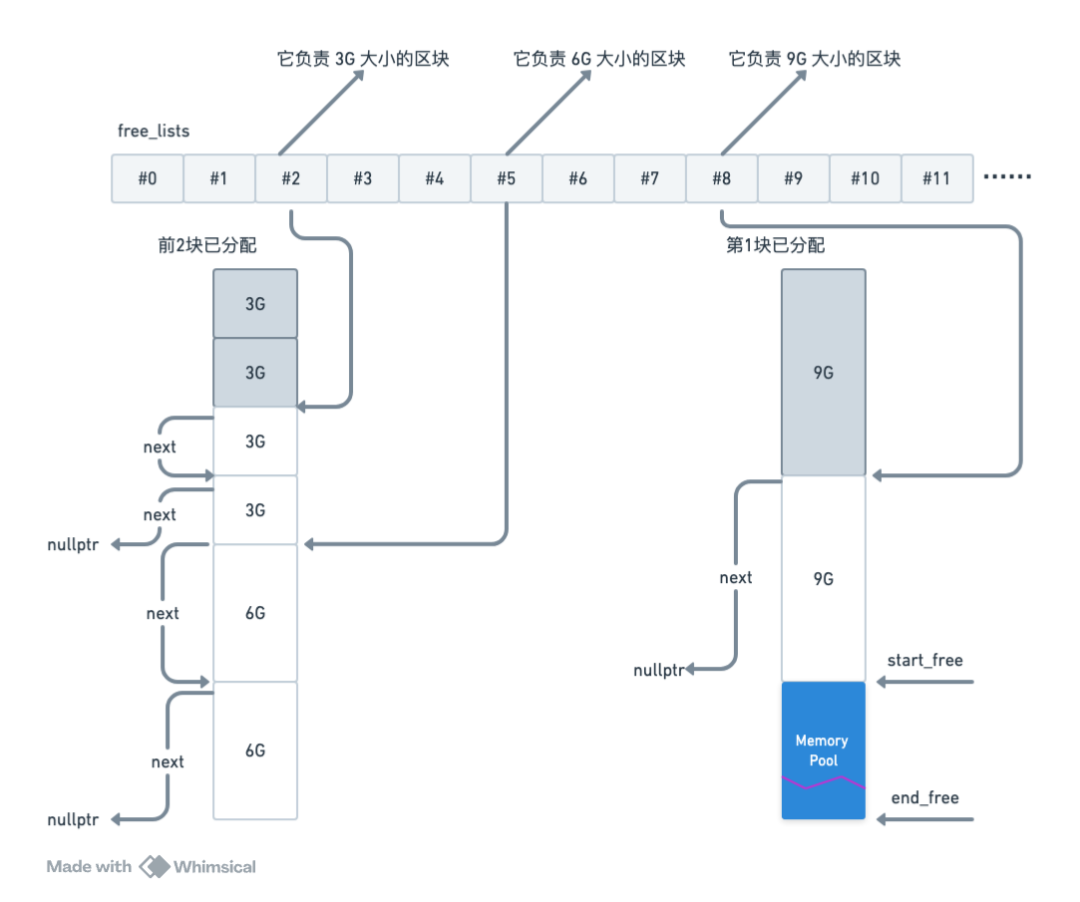
举个例子,先加载一个 2.8G 的模型,再加载一个 8.5G 的模型,紧接着卸载最先加载的 2.8G 模型,最后加载一个 2.9G 的模型,内存池会进行以下行为:
圆整模型大小:将 2.8G 模型大小圆整至 3G,从 free_lists[2] 中拨出第一块内存块来存储模型,并更新 free_lists[2] 指向第二块内存。
处理大模型:将 8.5G 模型大小圆整至 9G,从 free_lists[8] 中拨出第一块内存块来存储模型,并更新 free_lists[8] 指向第二块内存。
回收内存:根据 2.8G 模型大小,我们知道这块内存来自 free_lists[2],让 free_lists[2] 重新管理这块空闲内存,即更新 free_lists[2] 重新指向第一块内存。
再次分配:重新把第一块 3G 内存从 free_lists[2] 拨出用于存放 2.9G 模型数据。
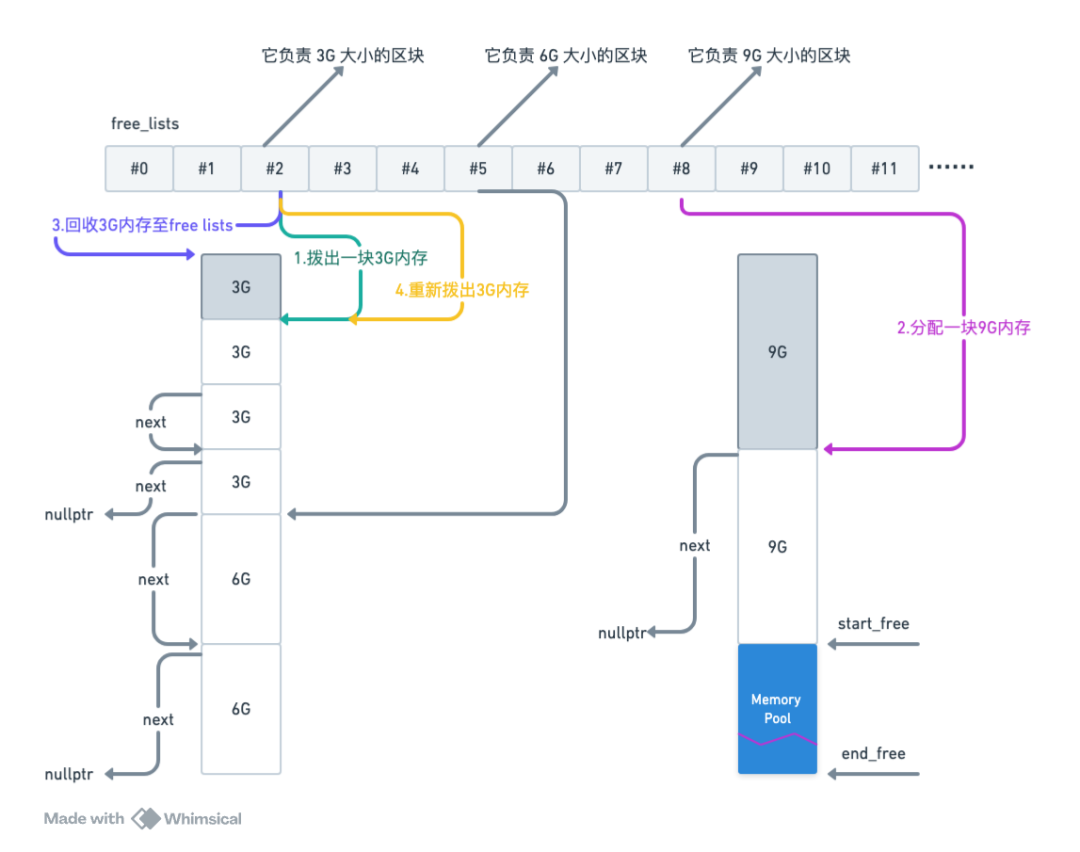
在 pinned_memory 上构造 state_dict
PyTorch 中的 state_dict 是一个简单的字典对象,其中 key 类型为 str,代表 tensor 名称;value 类型为 tensor,记录了模型权重信息,是消耗内存的主要因素。为了控制在指定的内存区域构造 tensor,我们首先理解 tensor 的数据结构:
头信息区:保存 tensor 的形状(size)、步长(stride)、数据类型(type)等信息。
存储区:真正的数据保存在 Storage 中,Storage 指向一段连续的内存,不同的 tensor 可以持有同一个 storage 对象,通过 storageOffset 标识数据在 storage 中的偏移量。
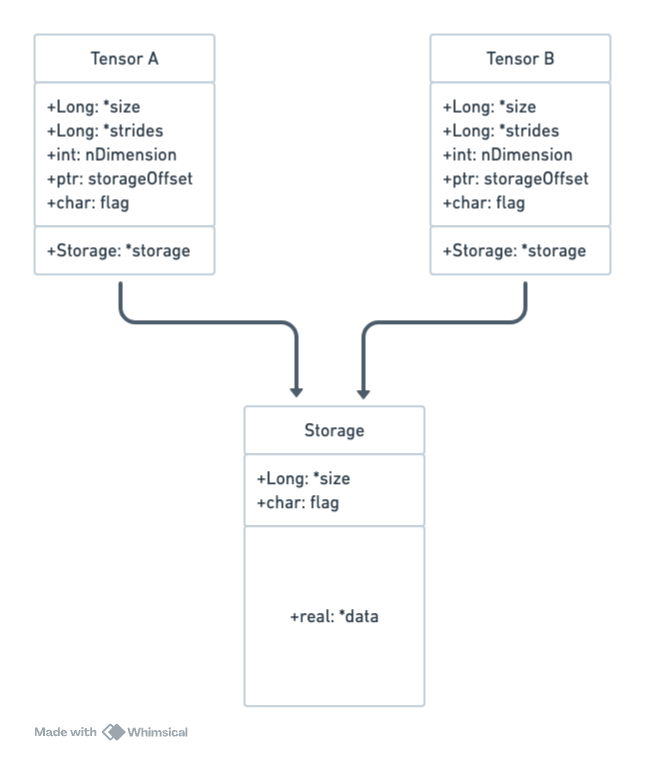
因此,我们可以首先用预分配好的 pinned_memory 构造 Storage,再设置 tensor 的 storageOffset 为适当的值。具体步骤如下:
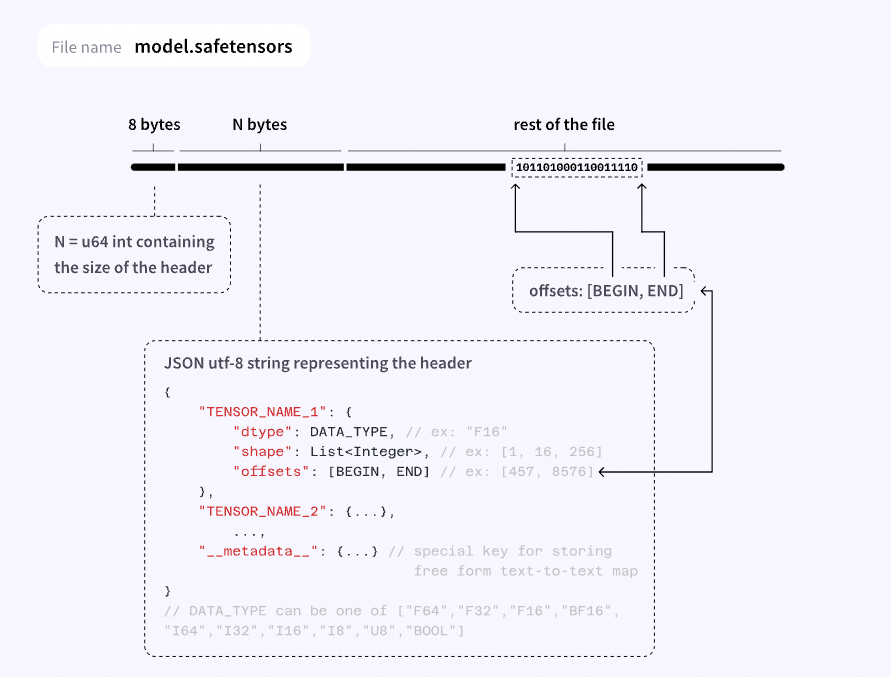
解析 safetensors 文件格式:
前 8 个字节记录 header 大小 header_size。
[8, 8 + header_size) 记录 tensors 元信息,包括数据类型、tensor shape 和数据在文件中的位置 offsets。
[8 + header_size, file_size) 记录 tensor 实际数据。
构建 tensor:将文件中的 tensor 数据段拷贝到预分配的 pinned_memory 中,根据 safetensors header 中的 offsets 构建 tensor。需要注意的是,storage_offset 是指在 storage 中元素个数的偏移量,而非字节偏移量。若同个 storage 中不同 tensor 的 sizeof(dtype) 不一致,可能导致字节偏移量计算错误,这时需要将内存按每个 tensor 占用量切分为多块连续内存,在每块内存上单独构造 storage,并绑定到对应 tensor 上。
3.3 性能评估
读取性能评估
通过比较以下三个函数的耗时,评价模型读取所带来的性能提升:
Baseline:直接使用 safetensors.load_file。
Fsfuse 方案:针对 fsfuse 采用单线程直读。
NAS 方案:针对 NAS 采用多线程读取。
@profiledef load_baseline(model_path): state_dict = load_file(model_path) model = torch.nn.utils.skip_init(MyModel, device="cuda:0") model.load_state_dict(state_dict, assign=True) model = model.to("cuda:0") torch.cuda.synchronize() return model@profiledef fast_safetensors_fuse(model_path): # 顺序直读 state_dict = fast_safetensors.load_safetensors(model_path, num_threads=1, direct_io=True) model = torch.nn.utils.skip_init(MyModel, device="cuda:0") model.load_state_dict(state_dict, assign=True) model = model.to("cuda:0") torch.cuda.synchronize() return model@profiledef fast_safetensors_nas(model_path): # 16 线程非直读 state_dict = fast_safetensors.load_safetensors(model_path, num_threads=16, direct_io=False) model = torch.nn.utils.skip_init(MyModel, device="cuda:0") model.load_state_dict(state_dict, assign=True) model = model.to("cuda:0") torch.cuda.synchronize() return model每次实验前清除 page cache 消除系统 cache 的影响。实验结果表明,优化后的方案显著提升了模型读取速度。

表 4. 读取性能比较表
内存复用性能评估
先后加载、卸载、再加载同一模型,观察第二次加载的时间差异,评估内存复用的性能收益。由于第二次加载模型时基本命中了 page cache,所以文件读取时间只有毫秒级差异,可以忽略。
def reload(model_path, load_func): model = load_func(model_path) del model gc.collect() torch.cuda.empty_cache() tic = time.time() model = load_func(model_path) toc = time.time() print(f"reload model cost {toc - tic}s")if __name__ == "__main__": reload(model_path, fast_safetensors_load) reload(model_path, load_baseline)实验结果显示,内存复用显著缩短了模型加载时间,提高了整体推理效率。

表 5. 内存复用性能结果表
4. 模型量化
随着模型复杂度和规模的不断增加,显存容量逐渐成为限制推理性能的关键瓶颈。为了应对这一挑战,社区中越来越多的用户开始采用低精度数据类型(如 FP8)来存储模型,以减少显存占用并提高加载速度。
主流的 Stable Diffusion 模型在推理时通常采用 Float16 或 BFloat16 精度计算。然而,随着模型大小的日益增加,社区用户的显卡显存容量已经难以支撑这两种精度下的推理生图需求。因此,大量社区模型开始转向使用 FP8 等低精度数据类型进行存储。这种做法的主要优势包括:
显著减少模型大小:FP8 精度存储的模型相比 Float16 可以直接减少一半的存储空间,从而缩短模型读取时间。
降低显存占用量:使用低精度数据类型可以显著减少显存占用,使得更多模型能够在有限的显存资源下运行。
支持现有框架:目前主流的生图推理框架也支持直接读取 FP8 数据类型的模型,尽管实际推理时仍然采用 Float16 或 BFloat16 精度计算。
从 Ada 架构开始,英伟达引入了第四代 Tensor Core,支持 FP8 精度计算。以 Ada 架构的 L40S 显卡为例,其 FP8 精度的理论计算性能(733 TFLOPS)可以达到 FP16 的约两倍(362.05 TFLOPS)。这为基于 FP8 的推理提供了强大的硬件支持,使得我们可以在降低显存占用的前提下,进一步提升推理速度。
为了充分利用新一代硬件的优势,我们基于 PyTorch 和 cuBLAS 库提供的算子,适配了基于 FP8 的生图推理:
模型量化:将现有的 Float16 或 BFloat16 模型转换为 FP8 精度。
推理优化:利用第四代 Tensor Core 支持的 FP8 计算能力,优化推理过程,确保推理速度和精度的平衡。
以下是 flux-dev 1.0 量化前后在 盘古 +fsfuse 环境,L40s 显卡上的耗时对比,其中 bf16 模型占 22.4GB,fp8 模型占 11GB。
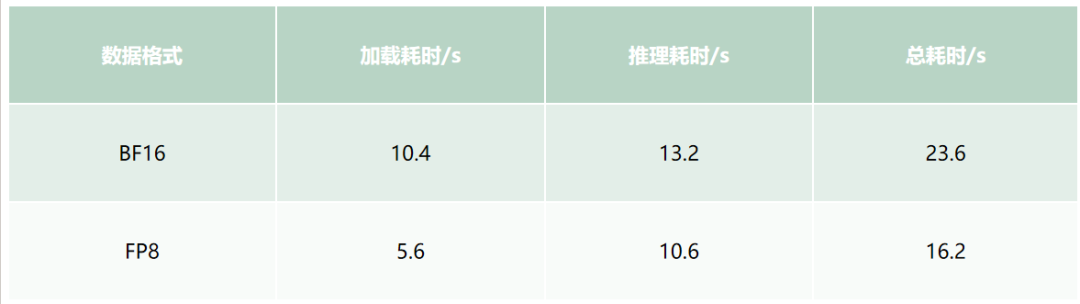
表 6. 量化前后端到端耗时
在获得大幅加速的同时,量化前后的出图效果能基本对齐。

5. T5 独立化部署
在 MuseAI 平台中,文本嵌入向量的生成是影响最终图像生成质量的关键步骤。传统模型如 SD1.5 和 SDXL 使用经典的 CLIP 模型来生成提示词对应的文本嵌入向量(Text Embedding),但由于 CLIP 模型本身的局限性,导致生成的图片对提示词的遵从性较差。2024 年中陆续开源的 SD3-Medium、FLUX 等模型引入了更强的 T5 模型来生成文本嵌入向量,显著提升了提示词的遵从性。
然而,T5 模型本身较大的体积也给推理效率带来了挑战。例如,Google 官方发布的 t5-v1_1-xxl 模型大小约为 45GB,即使量化版 T5 模型也有约 10GB 的显存占用。每次生图请求中,如果需要从本地文件加载 T5 模型或出于显存考虑卸载 T5 模型到内存,无疑会非常耗时。
为了解决上述问题,我们借鉴了大规模推荐系统中的架构设计,引入了专门的 T5 Embedding Server 来处理文本嵌入向量的生成。这种独立部署的方式使得获取提示词对应的文本嵌入向量的过程与核心去噪流程分离,从而将原本复杂的模型加载和卸载操作简化为一次轻量的 RPC 调用。
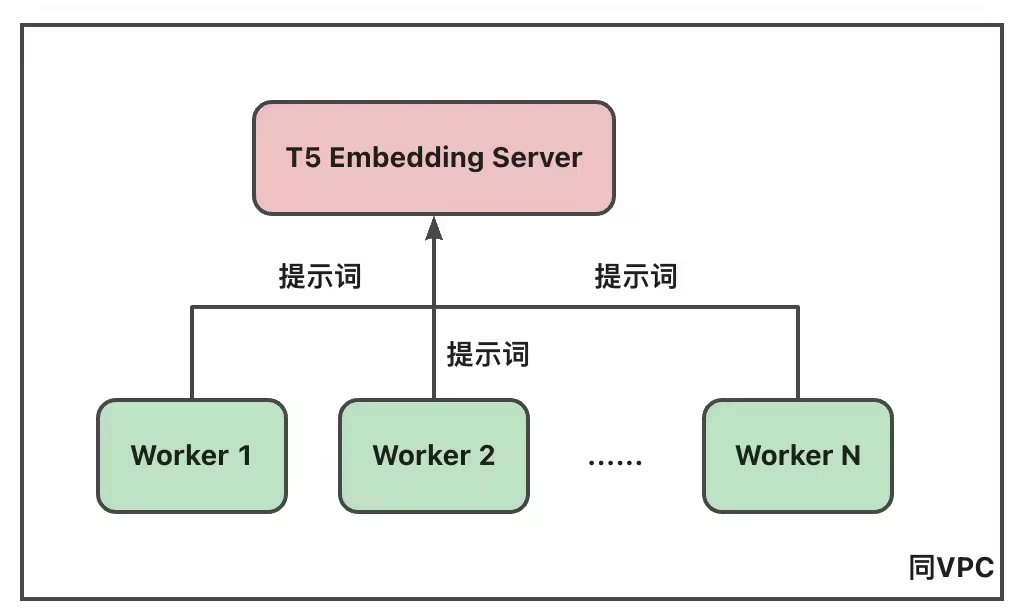
为了进一步降低 T5 Embedding Server 的响应时间,我们考虑引入了以下几种服务端优化技术:
动态凑批:将多个 Worker 发起的请求合并成一个较大的批次后进行推理,从而提升 GPU 利用率和吞吐率。
Token 缓存:不同 Worker 所需的提示词进行 Tokenization 后,往往会共享相当数量的 Token。通过在 Server 侧维护一个缓存池,其中缓存高频使用的 Token 对应的嵌入向量,后续同样包含这些高频 Token 的提示词可以直接读取到对应的嵌入向量,无需再进行 T5 推理,从而进一步减少耗时。
在拆分出 T5 模型后,我们在同 VPC 内进行了简单的跨机器性能测试,评估了大量并发请求下 T5 Embedding Server 的耗时。从下表结果中可以看到,T5 模型的推理并不足以让 GPU 利用率满载,整体耗时和并发请求数并不是一比一线性增长的关系。与之对比,在同一台机器上本地使用 T5 模型推理包含(1)调用 from_state_dict 读取模型参数并实例化 T5 对象到内存;(2)将 T5 对象从内存搬运到显存;(3)GPU 侧推理;(4)将 T5 对象 offload 到内存等 4 个主要流程,整体的耗时在 4.3 秒左右,远大于通过 RPC 调用的耗时。而这 4 个阶段的耗时热点,依然是从内存到显存的 H2D 传输阶段,而非实际推理。

想要独立化部署 T5 存在着诸多挑战,其中最关键的一点是工程实现和部署上的难度,独立的 T5 Embedding Server 会导致我们的推理 SDK 不再是一个独立的、本地可用的 SDK,而开始依赖分布式网络通信。此外针对 T5 Server 还需要引入一套新的健康检查、重启等流程。并且通过上述几节中的模型切换、内存复用技术,我们已经大幅减少了在本地使用 T5 模型进行推理的耗时,因此我们最终将该技术作为技术储备,并没有应用到生产环境。
四、实验 Experiment
为了评估本次优化对 MuseAI 业务带来的性能收益,我们使用了实际业务中最常使用的 Flux Pipeline 进行了一系列实验。本章将详细介绍实验设置、结果及分析。
4.1 实验设置
Flux Pipeline 组成
Flux Pipeline 由以下三个模型组成:
flux-dev-1.0:22.4 GB
t5xxl_v1:8.8 GB
clip_l:0.23 GB
为了比较 MuseAI、Diffusers 和 WebUI-forge 三者的性能,我们设置了以下对照实验组:
冷启动性能测试:
在清除 page cache 的情况下,分别用 MuseAI、Diffusers 和 WebUI-forge 推理 30 步生成 768 x 1360 的图片。
模型切换性能测试:
分别用 MuseAI、Diffusers 和 WebUI-forge 按 flux -> sdxl -> flux 的顺序切换 pipeline,观察最后一次图片生成的耗时。图片生成参数为 30 步 768 x 1360。
软件版本:
Diffusers 版本:0.31.0
WebUI-forge 版本:d50f390c7e470761c5734221133bedc7f0febb65
硬件环境:
盘古 +fsfuse 环境:L40S + 128GB 内存
NAS 环境:L20 + 128GB 内存
4.2 实验结果与分析
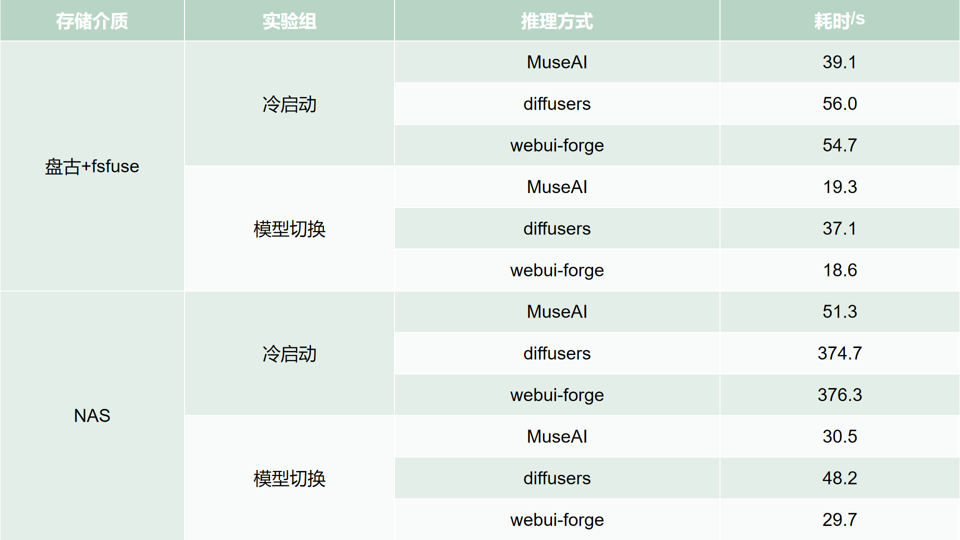
表 7. 实验结果
盘古 +fsfuse 环境
1. 冷启动性能:
不论是 MuseAI 还是 Diffusers,第二次推理 Flux Pipeline 的速度都明显比首次推理快,这是因为第二次推理时模型数据部分或全部已处于内存中,减少了读取模型数据的开销。
冷启动时,MuseAI 采用最佳实践——以 2 MB 的 block 顺序直读数据,而 Diffusers 和 WebUI-forge 通过 Huggingface Safetensors 库通过 mmap 将文件映射到内存,实际使用 tensor 时才通过缺页异常将数据读入内存。这种随机访问方式导致 fsfuse 缓存命中率低,且频繁执行 128 KB 的系统调用,对于 Flux Pipeline 30 GB 级别的模型来说效率较低。
2. 模型切换性能:
MuseAI 利用内存池节省了内存分配开销,这对于 30 GB 的文件来说是非常可观的。
MuseAI 与 Diffusers 之间的差距在模型切换时更为显著。此外,MuseAI 使用 pinned memory,在 H2D 传输时相比 Diffusers 少了一次内存拷贝。
WebUI-forge 和 MuseAI 相差很小,因为 WebUI-forge 在切换模型前会提前计算新模型显存占用大小,只有当剩余显存不足时才会卸载部分模型腾出空间。由于 Flux Pipeline 模型(约 32 GB)和 SDXL Pipeline(约 8 GB)之和小于 L40S 的 48 GB 显存,因此 WebUI-forge 无需卸载任何模型,第二次推理 Flux Pipeline 时所有模型都在显存中,比 MuseAI 少了 H2D 过程。但若模型种类增多,WebUI-forge 也会触发模型逐出,此时重新加载模型的代价与 Diffusers 差不多。
NAS 环境
1. 冷启动性能:
在 NAS 环境中,第二次推理 Flux Pipeline 的速度同样明显快于首次推理。
冷启动时,Diffusers 和 WebUI-forge 的速度约比 MuseAI 慢 7 倍,原因是 Huggingface Safetensors 单线程读取,实例与 NAS 通过单条 TCP 连接,未能充分利用网络带宽。
2. 模型切换性能:
三者表现与 盘古 +fsfuse 环境相似。值得注意的是,第二次推理 Flux Pipeline 时,得益于 128 GB 大内存,即使是 Diffusers 读取模型数据时大部分也能命中 page cache,因此与 MuseAI 的差距比冷启动时小得多。
五、总结 Conclusion
MuseAI 平台为提供丰富的绘画风格,集成了大量不同类型的模型,提供服务的过程中面临频繁切换 Diffusion Pipeline 的情况。基于用户真实请求分析,我们发现模型下载、模型加载和模型切换时间占据了端到端生图时间的绝大部分,严重影响用户体验,造成资源的极大浪费。
我们分析业务特性,在公司内外分别使用“盘古 +fsfuse”和 NAS 作为模型存储介质,并根据两者特性制定相应的访问策略——盘古 +fsfuse 采取 Direct I/O 与顺序读、NAS 多线程并发读,充分挖掘读取性能,大大降低模型下载和加载时间。
我们分析模型切换时间的组成,发现主要是 torch Module 构造和 Host-to-Device 较为耗时。我们使用了 skipInit 技术跳过 torch Module 构造时多余的初始化阶段。我们精心分析并调整代码执行顺序,避免不必要的内存拷贝,并使用多线程 H2D 技术最大化传输效率。
我们观察到 Diffusion Pipeline 切换时伴随着巨大的内存分配与释放开销,采用内存池复用内存,尽量减少了这些开销。
我们探索了模型量化和 T5 独立化部署。前者能大幅加快模型加载,但尚缺乏自动化能力,支持代价较高。后者也能加快模型加载,但对服务链路施加了较大的稳定性与运维风险,因此未实际应用。
最后,我们将 MuseAI 与 Diffusers、WebUI-Forge 进行性能比较。冷启动时,在 NAS 和“盘古 +fsfuse”上 MuseAI 均优于其他两者。热启动时,MuseAI 与 WebUI-Forge 相近,优于 Diffusers。
会议推荐
2025 年 4 月 10 - 12 日,QCon 全球软件开发大会(北京站) 策划了「面向 AI 的研发基础设施」、「更智能的企业 AI 搜索实践」、「反卷 “大” 模型」、「多模态大模型及应用」等热点专题,直击行业痛点,解锁可复制的经验与模式。如果你也有相关案例想要分享,欢迎点击链接提交演讲申请。





