
欢迎阅读新一期的数据库内核杂谈。 这是兔年后的第一篇内核杂谈,祝大家新年快乐,也希望内核杂谈新一年里不断更。这一期,我们一起来学习 AWS 在 USENIX 2022 上发表的关于 Amazon DynamoDB 的最新论文: Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service。
自 2012 年发布以来(见下图),DynamoDB 经历了多个版本的迭代,更新了很多功能。它作为底层的基础软件,支撑着 Amazon 和 AWS 的发展。这篇论文,汇聚了一些关键的系统设计和实现思路,介绍了 DynamoDB 如何从一个需要程序员自主维护,配置和使用的数据库系统,演进为一个超高可靠(highly available),超大规模(highly scale),超级稳定(predictable performant)的全自动化数据库服务(fully managed database as a service)。文中介绍了很多关键的设计细节,这些细节,不仅仅对数据库设计有帮助,对于通用的系统服务建设也很有启发。这篇文章是我很长一段时间内读到的最好的技术论文。借此博客,和大家一起学习,共同进步。

DynamoDB launch 时间线
DynamoDB 历史和简介
论文的一开始,AWS 肯定要先展示一下肌肉。DynamoDB 是一款 key-value(但同时也支持 schema definition, document, secondary index 等其他功能)的 NoSQL 数据库服务。在 2021 年的 66 个小时的 Amazon Prime Day 促销时,Amazon systems(包括 Amazon.com, Alexa, Amazon fulfillment center 等)总共调用 DynamoDB 超过 trillion 级别(10^12 次方, a million million),峰值更是将近 9000 万(89.2M)QPS。更大的肌肉在于,在如此高的峰值下,DynamoDB 依然可以保证高可用以及几毫秒级别的返回时长(文中用的是 single-digit milisecond)。
DyanmoDB 最初是以自助维护(on-demand)的数据库系统的形式对外提供服务,即每个用户需要申请硬件资源,做好数据库配置,运维,甚至升级。使用 DynamoDB 的学习曲线非常高,团队通常需要配备一两个专业的 DBA 来运维 DynamoDB。这使得 DynamoDB 的推广和使用并不是一帆风顺。
随后,AWS 推出了 S3,SimpleDB 等的 SaaS 服务,这些服务完全是自动化运维,对于用户仅仅暴露 API 调用接口(插一句题外话,SimpleDB: https://en.wikipedia.org/wiki/Amazon_SimpleDB, 是一款用 Erlang 编写的分布式 NoSQL 系统,也具备弹性,高可用,高性能的特点,但也有其局限性,比如数据量大小限制等等)。因为其易用的特点,SimpleDB 的推广远比当时的 DynamoDB 要好得多。这也推动了 DynamoDB 的研发团队的转型之路,TA 们希望能够让 DynamoDB 集 Dynamo Database 以及 SimpleDB SaaS 的优点于一身。
DynamoDB Service 作为基础底层软件,是绝大多数 AWS 服务(包括,但不限于,AWS Lambda,AWS lake formation, AWS SageMaker)等上层应用的构建基石。这些上层的 AWS 服务对于很多其他用户而言,却是平台级别的基础服务。也因此,这些服务本身对于性能,高可靠,高可用,高扩展就有极大的诉求。这些诉求传递到 DynamoDB 后,使得条件变得更加苛刻。尤其是稳定的性能表现(consistent low latency),这里稳定的性能表现不是均值,不是中位数,而是 P90,甚至是 P99。因为 DynamoDB 作为底层服务,任何性能抖动(高 latency 的 return)就会在上层服务中被放大,致使影响整个上层服务不稳定甚至不可用。所以,DynamoDB 的一个设计目标就是要确保所有的调用都能在几毫米级别返回。除了稳定的性能外,DynamoDB 的设计挑战还在于需要支持大量不同类型的服务,这也意味着需要支持多租户。且逐渐需要添加新的功能进入新版本比如 secondary-index,transaction 支持等等。研发团队总结了 DynamoDB 演进过程中始终贯彻的 6 个设计理念:
1) DynamoDB 是一个完全自动化运维的数据库 SaaS 服务。对于用户来说,就是 100%的Serverless API 的调用。其他如软件升级,故障修复,硬件资源申请, 扩容,集群维护,故障恢复,对用户来说都是黑盒且无感知的。
2)DynamoDB 是一个多租户 SaaS 服务。DynamoDB 需要支持不同类型的用户和服务,但考虑到 SaaS 服务的收费模式以及服务 SLA,需要保障高效的资源利用。底层的数据存储,以及计算节点在不同类型的服务和用户之间要做到物理共享,但又逻辑隔离。整体服务需要做好资源预留,服务监控,来保证不同类型的服务不会相互影响(最坏情况下造成雪崩效应)。
3)支持几乎无限制的横向扩展(典型的全球型分布式数据库)。DynamoDB 并不限制一个表能存多少量的数据(表可以根据业务需求弹性地增加和扩容),也不限制有多少用户:一个表的数据会被分散存储到不同的物理机上,如果有需要,可以分配到上千台物理机上。
4)稳定的高性能(>P99):当服务和 DynamoDB 部署在同一个 AWS region 里,对于读写,需要保证几毫秒的延时。挑战在于,这种稳定的延时,即使当数据增长到百亿千亿级别,仍然能够保持(文中也给出了和 MySQL 的对比,见下图,很能说明情况)。通过分布式数据存储和 routing,DynamoDB 可以做到几乎无限的横向扩展。
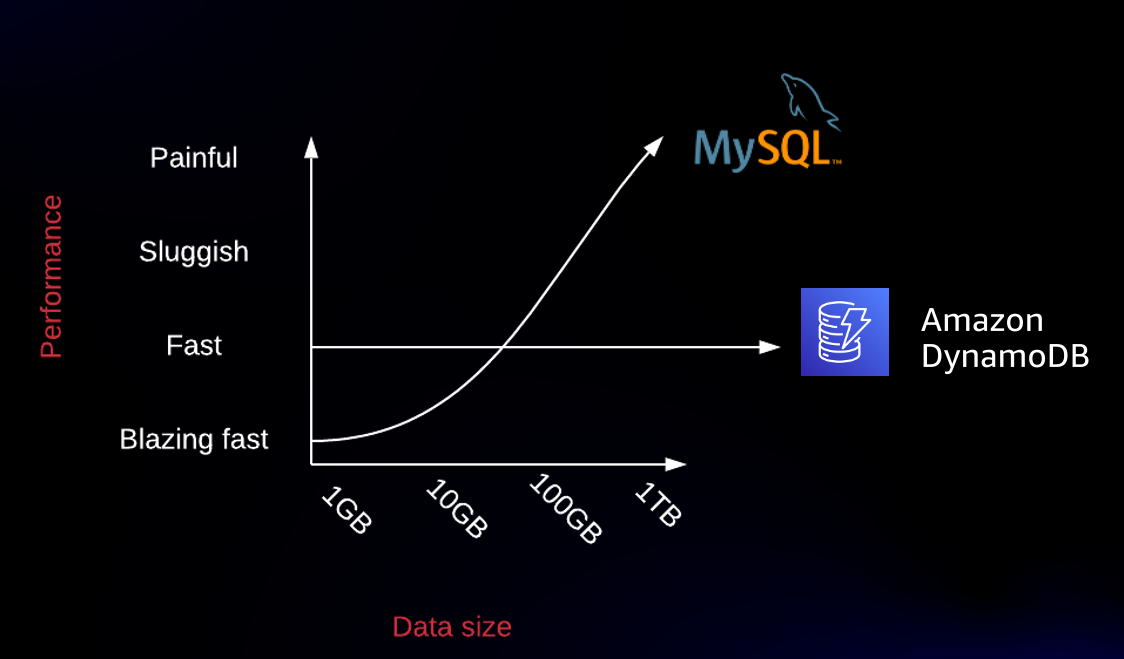
调用延时无关数据量大小,始终保持几毫秒级别
5)超级高可用:数据会被复制到多个数据中心,AWS 中称为 availability zones(AZ)。默认情况下,数据会有 3 个备份。并且,当发现某一个 replica 出现了节点故障,会自动申请一个新的 replica 来保证高可用。文中写到 DynamoDB 的普通表数据提供 4 个 9 的高可用保障,全域表(global table)提供 5 个 9 的高可用保障(因为全域表会备份到多个 region,一个 region 包含多个 AZ)。
6)功能丰富,支持多类型的应用和服务:DynamoDB 在功能上,不像其他服务(比如 SimpleDB)来限制用户使用某个固定的 Data model。支持多种收欢迎的功能如支持可扩展的 Schema,支持不同的数据类型(包括 array 类型的数据),secondary index,transaction,强一致读(strong read)和最终一致读(eventual consistency read)等等。
研发团队在迭代过程中,确保上述的 6 个设计理念始终被贯彻,才造就了 DynamoDB 的成功。其实,在平时的系统研发中,我们也需要贯彻清晰的设计理念(虽然,不需要像 DynamoDB 那样苛刻),好的设计理念会让系统在迭代中不会点错技能树。
DynamoDB 数据模型和 high-level 架构
一个 DynamoDB 的表是一个 Item 数据的集合,每个 Item 都会分配一个全局唯一的 key,即 primary key。每个 Item 是一系列的 attributes 的集合。Primary key 包含一个 partition key 或者是一个 partition 值+sort key(复合 primary key)。Partition key 的值的 hash 值,配合上 sort key(如果存在的话)会决定这个数据存储在哪里。Partition key 或者{partition value, sort key}需要保持唯一。 每个 DynamoDB 的表支持一个或者多个 secondary index,来提升非 primary key 的查询速度。DynamoDB 支持对 Item 对象进行操作的 CRUD API,并且支持 ACID transactions。
DynamoDB 通过把一张表分成多个 partitions 来应对数据量增大带来的存储和读写压力。Partition 可以被认作是存储和计算调度的基本单元。DynamoDB 通过把不同的 partition 分配到不同的物理节点上来保证每个 partition 都分配到足够多的资源来保证读写的稳定表现,从而保证整个表的读写 SLA。每个 partition 存储了一部分连续的 key 的 item,而不同 partition 之间的 item 各无交集。每个 partition 都会有多个备份(默认情况是 3 备份),每个备份会被分配到不同的 AZ 来保证高可靠,节点间的通信和状态同步通过Multi-Paxos consensus protocol 来实现。只有 leader replica 支持写操作和强一致读。当接受到写操作时,leader replica 会先生成一个 WAL (write-ahead log),并将 WAL 同步给其他的 replica,只有当满足 quorum setting 的 replica 也存储好了 WAL,这个写操作才认为被执行。除了强一致读,其他 replica 节点支持最终一致读。
如果 leader 节点因为节点硬件,网络等原因故障导致 unavailable,replica group 会根据 consensus protocol 重新选择一个新节点来做 leader。就 partition 而言,绝大部分的分布式数据库都有类似的设计。每个标准 replica 节点(storage replica)除了会存储 WAL,也会存储 B-tree 形式的 key-value 数据。DynamoDB 的一个创新是,当 replica 节点发生故障,导致 3 备份被打破时,为了保证高可靠,引入了一种新的 replica 节点,log replica。Log replica 节点只存储 WAL,而不保留 key-value。因此 Log replica 节点不接受读写操作,也不能被选为 leader 节点,只是确保写操作依然能满足 quorum setting,比如 2/3 写成功。
下面两张图展示了 storage replica 和 log replica 的区别。
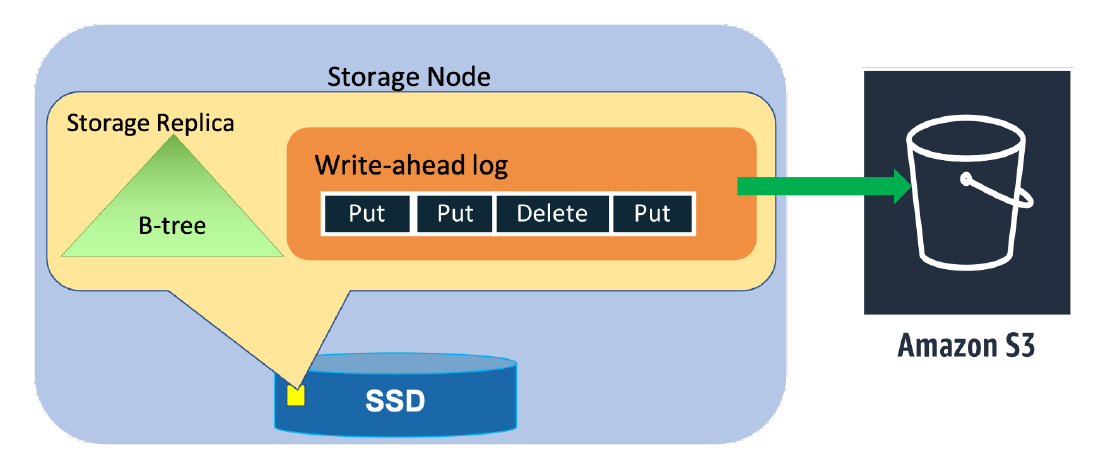
Storage replica
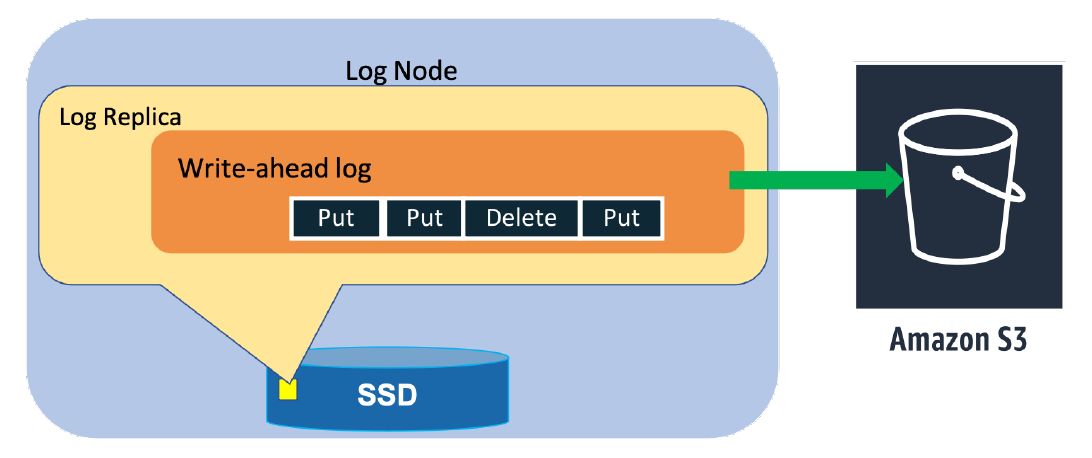
Log replica
除了 replica 节点,DynamoDB 的组成包含了十几个辅助服务。这其中,关键的服务有 metadata service,request routing service 和 autoadmin service(见下图的架构)。
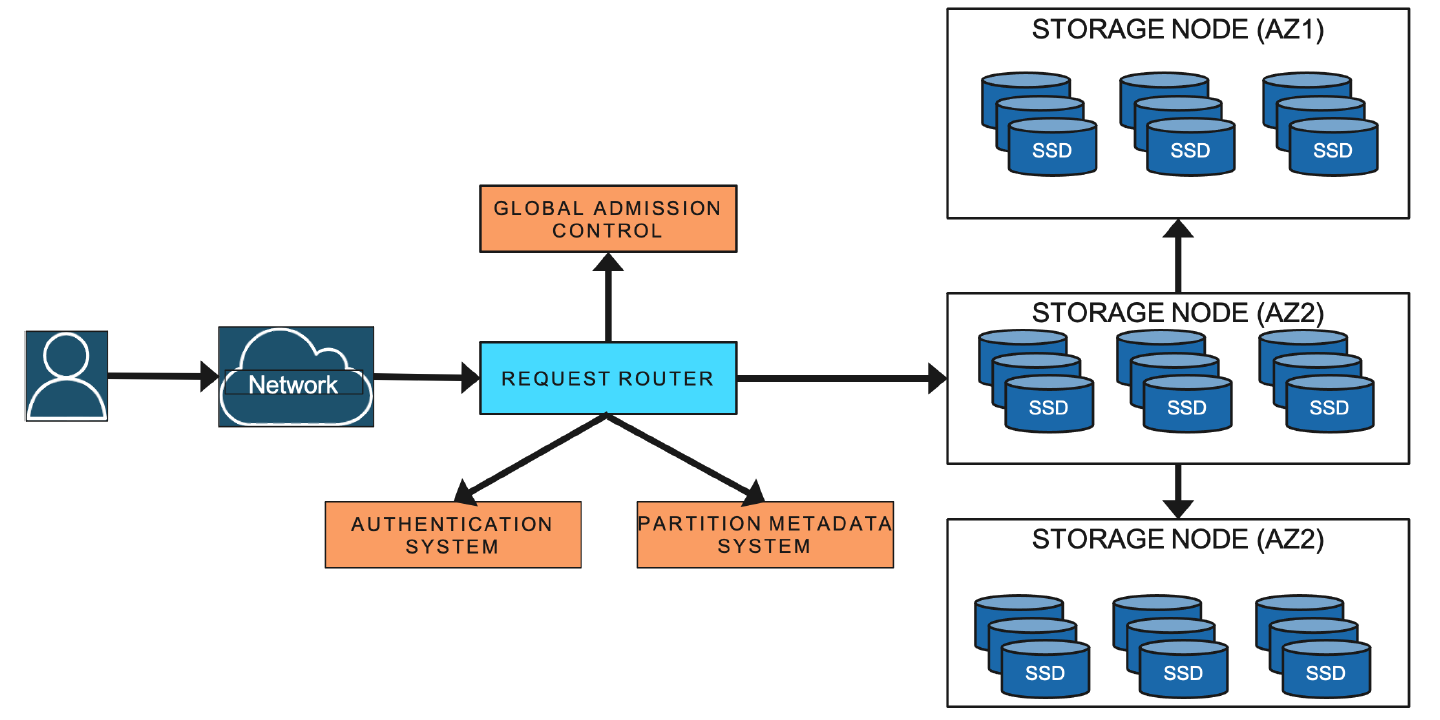
DynamoDB architecture
Metadata service 存储元信息包括表,partition,index 存储的路由信息。Request routing service 负责授权,验证和具体的路由工作(通过查询 metadata service 得到路由信息)。Autoadmin service 负责 DynamoDB 的集群控制工作来确保集群的稳定性,每个 partition 的读写稳定性,以及 scaling request 等等。Autoadmin service 会持续监控集群,replica 节点,表,partition 的关键信息来判断是否其出于不健康状态,并通过控制命令来恢复,比如,下线某个不健康的 replica 节点,将上面原先存储的 partition 转移到其他健康节点上,对某个 partition 做扩容分离(split)等。这些辅助服务的具体工作在后文中会详细介绍。
总结
这一期是 DynamoDB 2022 技术论文精读的第一篇。我们介绍了 DyanmoDB 的发展历史,6 个具体的设计理念以及 high-level 架构。下一期,我们会深入学习 Dynamo 引入的新设计思路,看这些思路如何保证当数据规模超大的情况下,DynamoDB 依然能够保证稳定的低延迟返回。感谢阅读。
相关阅读:
数据库内核杂谈 (二十二) 自动驾驶数据库 - Behavior Modeling
数据库内核杂谈(二十三)- Hologres,支持 Hybrid serving/analytical Processing 的数据引擎
数据库内核杂谈(二十四)- Hologres,支持 Hybrid serving/analytical Processing 的数据引擎




