
Rancher 作为一个开源的企业级 Kubernetes 集群管理平台。你可以导入现有集群,如 ACK、TKE、EKS、GKE,或者使用 RKE、RKE2、K3s 自定义部署集群。
作为业界领先的多集群管理平台,Rancher 可以同时纳管上千个集群和上万个节点。同时,大家也不必担心运维管理大规模集群和节点会增加额外的负担,社交通讯软件 LINE 5 个人就足以管理 130 个集群的 2000 个节点。
如何在 Rancher 中管理大规模的集群和节点这次暂且不谈,之前已经介绍过很多次了。今天我们只聊如何在单个集群中管理大规模的项目、命名空间等资源。
如何在单个集群中管理大规模的项目和命名空间
命名空间:命名空间是 Kubernetes 的一个概念,它允许在一个集群中建立一个虚拟集群,这对于将集群划分为单独的“虚拟集群”很有用,每个虚拟集群都有自己的访问控制和资源配额。
项目:一个项目就是一组命名空间,它是 Rancher 引入的一个概念。项目允许您将多个命名空间作为一个组进行管理并在其中执行 Kubernetes 操作。您可以使用项目来支持多租户,例如设置团队可以访问集群中的某个项目,但不能访问同一集群中的其他项目。
从层次上来说,集群包含项目,项目包含命名空间。如果把公司理解成是一个集群,那么项目对应的就是部门或者团队,我们可以给某个部门或者团队针对不同的项目去划分权限来管理多个命名空间。
所以,我们在生产环境中会创建大量的项目和命名空间,那么如何规划这些项目和命名空间呢?
建议项目按照部门或者团队去划分,针对不同的项目授予相关访问控制
每个项目内具有不同目的的环境使用命名空间去隔离,例如:生产环境和测试的环境
为了验证在 Rancher 单集群中具有管理大规模项目和命名空间的能力,我们在一个集群中创建了 500 个项目,并且在每个项目中创建了 10 个命名空间,最后,在每个命名空间创建:1 个 Deployment、2 个 Secret、1 个 Service、2 个 ConfigMap 来模拟真实场景下的使用。
以下是测试集群规模:
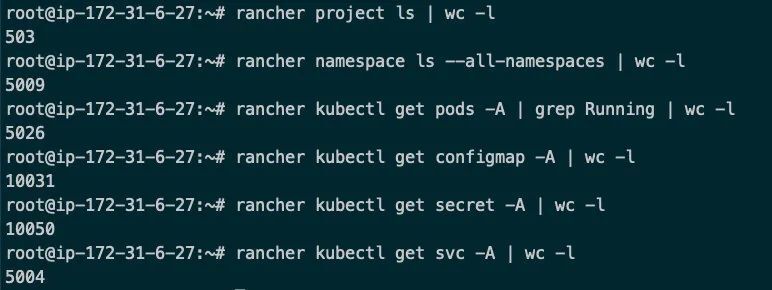
这样我们在单集群中创建了共计: 500+个项目、5000+个命名空间、5000+个 Deployment/pod、10000+个 ConfigMap、10000+个 Secret 和 5000+的 Service 的资源。
接下来,我们来体验通过 Rancher UI 来管理这些资源:
首先登录 Rancher UI,因为只有一个集群,无论集群下有多少资源,都不会被加载,所以加载速度和普通规模集群无差别
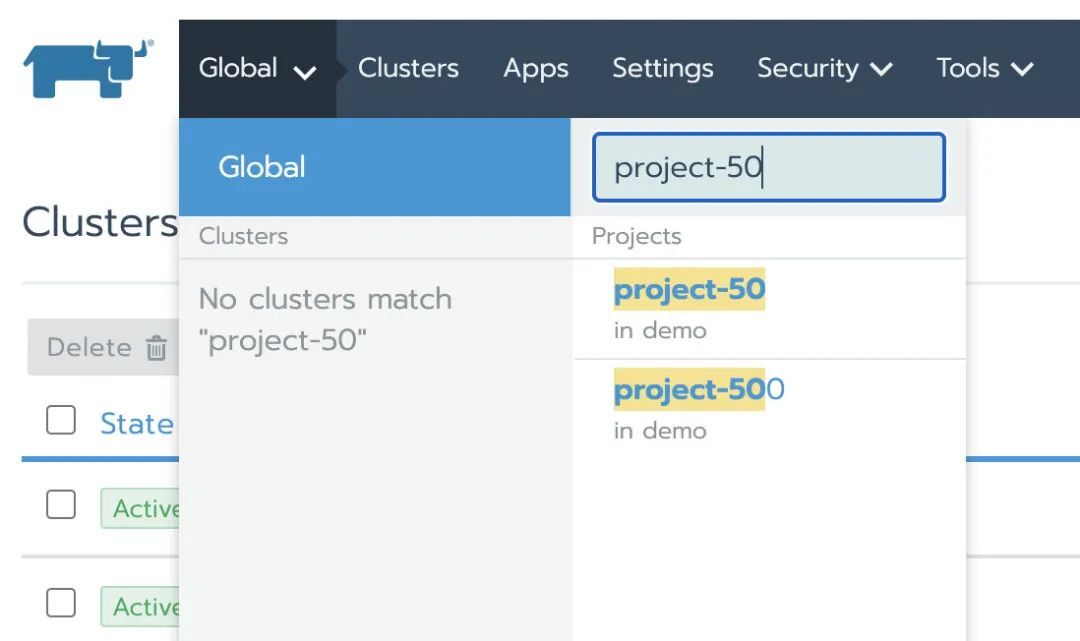
当项目非常多时,我们可以在搜索框快速定位到我们需要查询的项目:
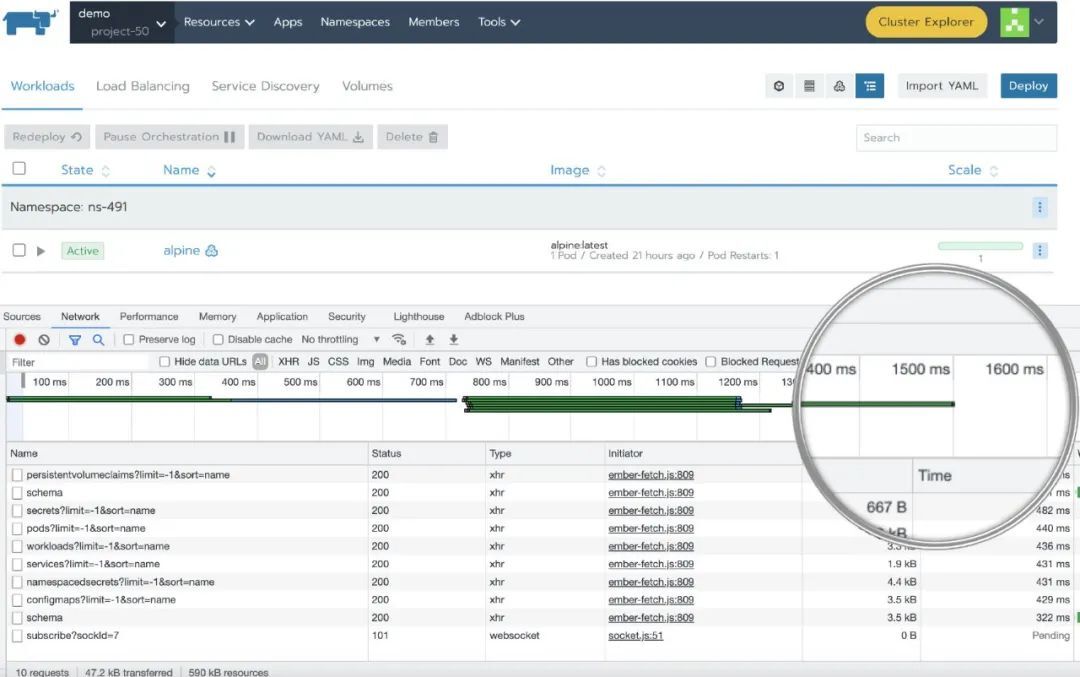
进入到某个项目,1.5 秒左右即可完成加载
接下来我们来创建一个 Deployment,从结果来看,和普通规模的集群的加载速度无区别
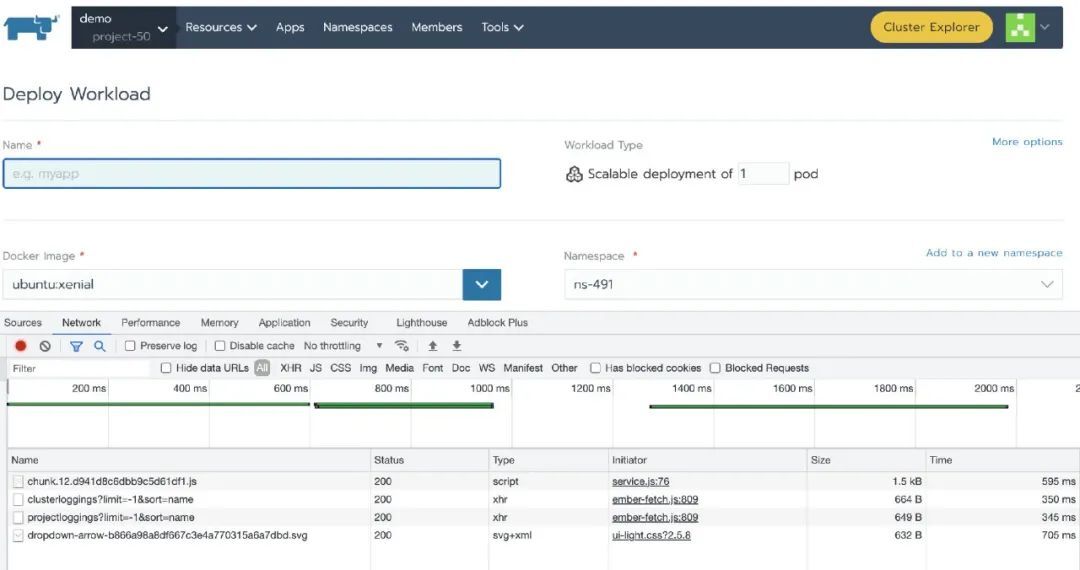
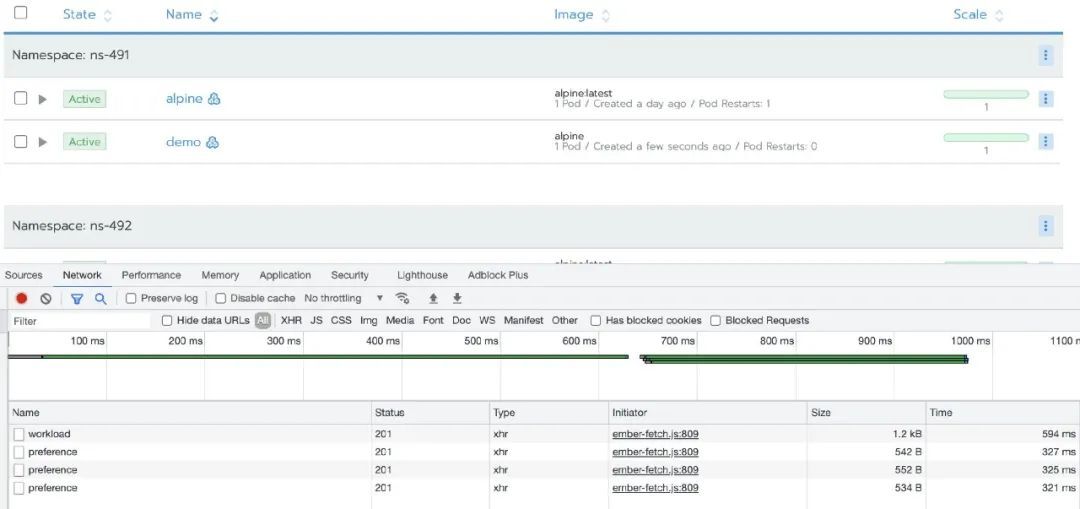
其他的资源的管理就不给大家一一展示,测试结果和普通规模集群的加载速度几乎一致。从以上的场景分析,单集群包含大规模项目、命名空间等资源并没有给 Rancher 带来太大的性能压力。
由于测试环境主机资源有限,这次验证只创建了 5000 个 deployment,只要合理的分配资源到项目,相信再多几倍的资源规模使用 Rancher 管理也会非常轻松。
一个不建议的场景
虽然是不建议的场景,但还是要说明,避免大家在单集群中管理大规模项目和命名空间时踩坑
非常不建议大家将所有的资源都堆积在同一个项目中,就比如将 5000+个命名空间都放在同一个项目中。
为什么不建议呢?简单来说,从 Rancher Cluster Manager 上进入到某个项目时,会加载项目中包含的所有资源。项目中包含的资源越多,加载项目中资源的速度也会随之变慢,如果数据量特别特别庞大,有时候会出现 timeout 的情况。而 Rancher 管理平面是通过 cluster tunnel 与下游集群的 API 通信,如果资源数量过于庞大,这条 websocket tunnel 的负担会很重。
虽然不建议大家将所有的资源都堆积在同一个项目中,但是并不代表在 Rancher 中没办法管理这种场景。如果在你的生产环境中必须将所有的命名空间等资源放在同一个项目中,而且数据量非常庞大。那么推荐你使用 Rancher v2.5 新增的 Cluster Explorer,Cluster Explorer 针对单个项目中加载资源进行了优化,几乎不会出现 timeout 的情况。
下图展示的是在 Cluster Explorer 的同一个项目中加载 3000 个命名空间、3000 个 Deployment、3000 个 Service、6000 个 ConfigMap、6000 个 Secret 的示例:
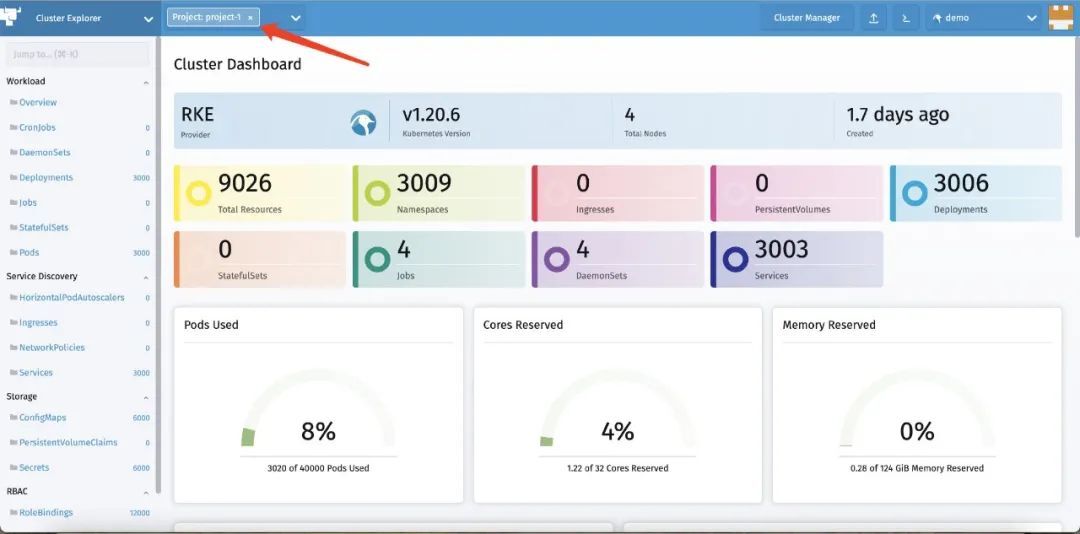
由此可见,通过 Rancher 2.5 的新 Dashboard,Cluster Explorer,也能够在单个项目管理上千个资源。
大规模集群管理调优建议
作为一个多集群的管理平台,无论是集群数量的增长还是单个集群 workload 数量的增长,都会对管理平面形成一定性能挑战。所有组件的默认参数是常用规模的最佳的产品配置,而面向大规模场景,部分平台参数甚至系统内核参数都需要进行调优,以便管理平面的核心可以获得最佳性能。
用户可根据自身的使用规模来采取相应的优化方案,所有的优化措施并不是必须的,需要针对自身的场景“量体裁衣”。Rancher 的默认的配置参数已经是绝大多数使用场景的最佳方案,如果是管理大规模集群,则需要调整相关配置,以下是一些大规模集群中的一些常见优化参数:
针对管理平面大量的 TCP 连接,从 OS Kernel 层面进行优化,已尽量发挥硬件配置的最佳性能。常见配置及其功能说明如下:
以下参数属于个人总结,仅供参考
Kernel Tuning
Kube-apiserver
针对原生资源和 CRD 的 API 的并发能力与缓存优化,提升 API List-Watch 的性能:
本文的重点不是调优,所以只介绍一些常用的参数,更详细的参数(例如:kube-controller-manager、kube-scheduler、kubelet、kube-proxy)说明还请大家参考 Kubernetes 官网。
后记
从以上验证结果来看,Rancher 具有在单个集群中管理大规模项目和命名空间的能力,只要合理的使用正确的方式搭建集群和部署业务,就不会对 Rancher 带来太大的压力,也不存在性能问题,同时也要根据集群规模来调优主机和 Kubernetes 参数,使其发挥出最佳性能。
作者介绍:
王海龙,SUSE Rancher 社区技术经理,负责 Rancher 中国技术社区的维护和运营。拥有 6 年的云计算领域经验,经历了 OpenStack 到 Kubernetes 的技术变革,无论底层操作系统 Linux,还是虚拟化 KVM 或是 Docker 容器技术都有丰富的运维和实践经验。
本文转载自:RancherLabs(ID:RancherLabs)




