
导读:随着数据行业的蓬勃发展,构建高效且顶尖的数据团队结构及其角色分配已成为业界瞩目的焦点。本期专栏深度剖析如何布局数据团队,揭示不同企业在数据角色划分与团队构成上的独到之处。通过细致分析 40 个顶尖数据团队的案例数据,我们将为你揭示洞察分析师、数据工程师与机器学习专家的比例奥秘,并探讨如何根据企业规模灵活调整团队架构。无论你是数据领域的从业者,还是对高效数据管理充满好奇的读者,本文都将为你提供宝贵的洞见与实用的策略指导。让我们携手揭开数据团队成功背后的智慧密码,共同探索最佳实践之道。
随着数据团队的日益壮大,成员数量显著增加。这通常被视为积极信号,因为数据团队如今已不仅限于驱动关键商业数据产品的开发,更超越了单纯回应临时查询的职能范畴。然而,这样的扩张也催生了一系列值得深思的问题,比如“我们在基础设施投入与数据洞察产出之间是否维系了恰当的平衡?”以及“鉴于我们所取得的成就,我们的运营效率是否达到了行业内的标准水平?”
本文旨在深入剖析美国和欧洲地区 40 个顶尖数据团队中各类数据角色的配置情况,为你解答上述疑惑,提供有价值的洞见。
数据角色分类
在数据领域,角色的命名可谓五花八门,尽管职位名称的多样性并不限制数据工作的本质,但我们可以大致将这些角色归为以下几大类别:
洞察与分析:此类别涵盖了数据分析师、产品分析师以及数据科学家。他们共同负责从数据中挖掘价值,提供深入的业务见解。
数据工程:数据工程师、数据平台工程师、分析工程师以及数据治理专家等角色构成了这一领域。他们专注于构建和维护数据基础设施,确保数据的可靠性与可用性。
机器学习:机器学习工程师是这一类别中的核心,他们利用算法和模型,从数据中学习并自动改进预测、分类等任务。
值得注意的是,数据团队中的角色定义往往不够明确,这不仅使得跨公司之间的角色比较变得复杂,也让求职者在面对不同公司时难以准确把握职位的具体期望。例如,“数据科学家”这一称谓,在某些公司可能指代的是专注于研究与机器学习的高级人才,而在另一些公司则可能只是分析师的另一种说法。
此外,虽然公司内存在众多分析师角色,如财务分析师、信用分析师等,但这些角色通常并不直接隶属于数据团队,因此在我们的分析框架中,我们仅将数据分析师和产品分析师纳入数据团队的范畴。至于机器学习角色的归属问题,尽管不同公司的组织架构各异,有的将其置于工程部门,有的则归于数据部门,但为了便于讨论,我们将机器学习角色统一视为数据团队的重要组成部分。
顶级公司数据角色构成剖析
在数据团队建设的讨论中,洞察角色与数据工程角色的比例问题常常成为焦点。过度偏重洞察角色可能会削弱数据平台的质量,进而拖慢整体工作效率;而过度依赖数据工程师,则可能导致拥有顶尖的数据平台却缺乏推动业务增长的深刻洞察或创新数据产品。
根据我们对 40 个顶级数据团队的调研,洞察角色的中位比例达到了 46%,略高于数据工程角色的 43%。
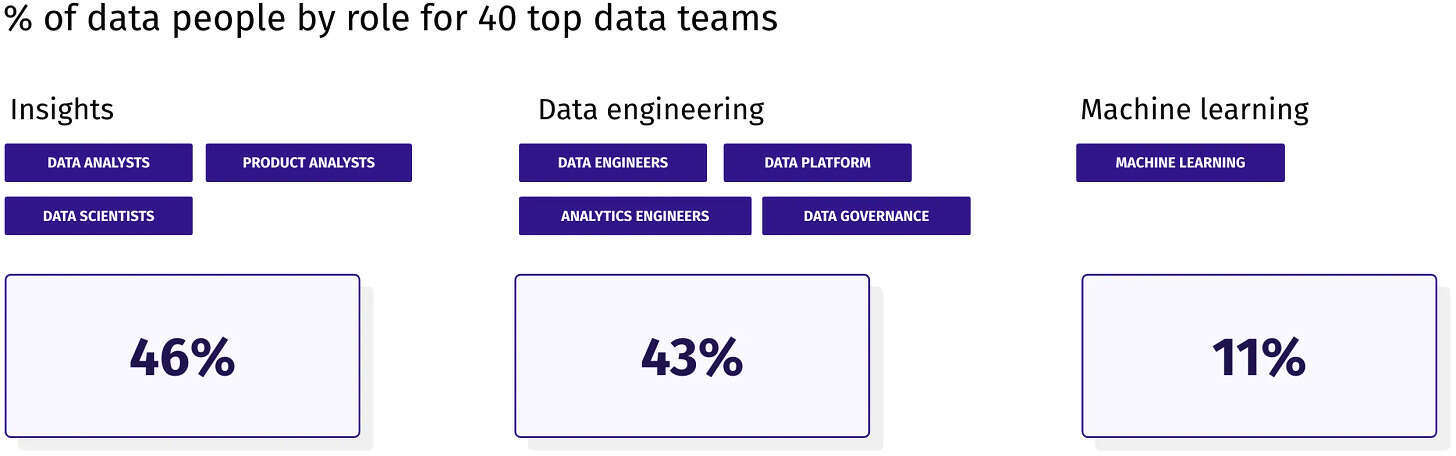
值得注意的是,这些比例因公司而异,部分原因在于角色命名的语义差异。有些公司避免使用“分析师”这一称谓,转而统称所有相关人员为“数据科学家”。而另一些公司则对数据工程师和分析工程师的职责界限有着不同的理解。因此,分析工程师比例较低的公司,并不意味着在数据建模方面的投入就相对较少,这些工作可能已被整合进了分析师的日常职责之中。
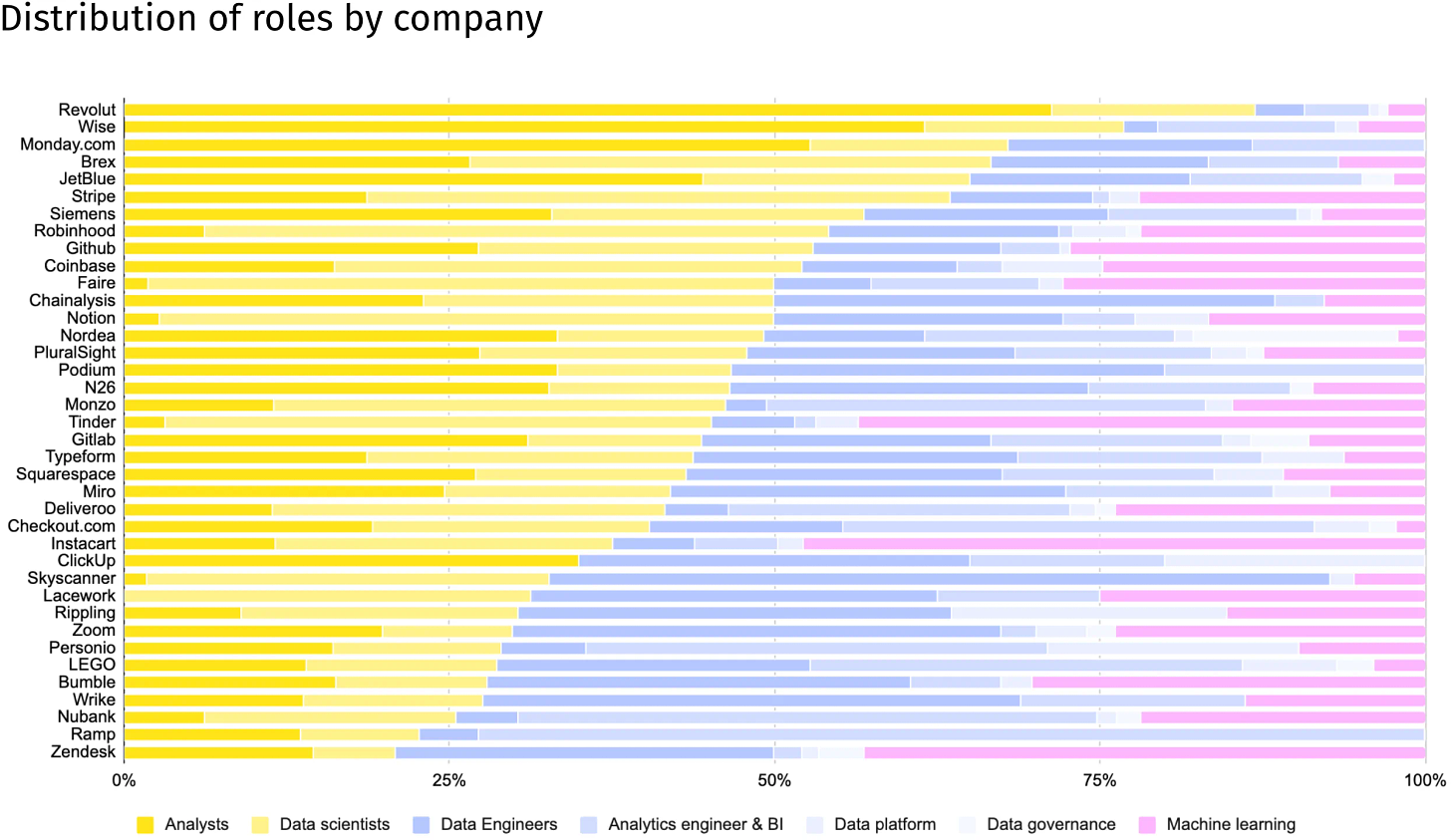
在比较不同公司的数据团队构成时,我们需要格外谨慎。通过具体案例,我们可以更清晰地看到,最佳比例往往因公司的战略重点和业务需求而异。
Revolut 拥有众多分析师,他们分布在各个市场,专注于金融犯罪预防和信用评估等领域。
Zendesk 则拥有一个庞大的机器学习团队,这与公司近期定位为“AI 时代最全面的客户体验解决方案提供商”的战略方向高度契合。
Nubank 则将数据分析师统一更名为分析工程师,这一举措彰显了公司致力于在所有业务领域深入应用软件工程原则和数据建模技术的决心。
若欲深入了解更多关于数据团队建设的最佳实践,请参阅以下文章:《数据团队占员工比例:100 家科技公司的深度剖析》(Data team as % of workforce: A deep dive into 100 tech scaleups)和《50 家科技公司中数据与产品工程师比例揭秘》)(data and product to engineer ratio at 50 tech scaleups)。
按公司规模划分的数据团队构成解析
不同规模的公司,其业务重点与数据团队的构成往往呈现出鲜明的差异。对于正处于成长阶段的公司而言,快速决策与新产品的迅速推向市场可能是它们最为关注的;而刚刚完成 IPO 的成熟企业,则可能将重心放在确保报告的精确性、合规性以及数据安全性上。
为了更清晰地揭示这些差异,我们可以将公司按照其规模划分为三个层次进行深入探讨:
中型公司:这类公司正处于快速发展期,数据团队规模相对较小,通常少于 35 人。它们中的典型代表有 Typeform、Brex 和 Personio 等。
大型公司:这类公司接近 IPO 阶段,数据团队规模在 35 至 100 人之间,如 Notion、Miro 和 N26 等企业便属于此类。
规模型企业:这一类别涵盖了更大规模的成长型企业、上市公司以及数据团队人数超过 100 人的大型企业,Zendesk、LEGO 和 Nubank 均属于其中的佼佼者。

在探讨这些不同规模公司的数据团队构成时,有两个观察点尤为值得关注:
中型公司数据工程角色的高占比:这一现象可能意味着,中型公司正致力于构建一个稳固的数据平台,以供分析师和工程师高效使用。然而,值得注意的是,数据洞察的工作可能更多地由数据团队之外的人员承担,如产品经理和工程师等。
大型公司在机器学习领域的显著投入:我们的研究发现,大型公司在机器学习角色的配置上比例更高。这很可能是因为这些公司已经找到了机器学习技术与其产品的市场契合点,并成功实现了可观的投资回报率。因此,它们需要更大的团队来维护这一优势,并持续进行投资以推动创新。
此外,我们还注意到一个有趣的现象:在大型公司中,有 60%的公司设立了专门的数据治理职能,而在其他规模的公司中,这一比例仅为 20%。这进一步印证了大型公司在数据管理和运营上的成熟度,它们更倾向于采用结构化的方法来确保数据的高效运作(DataOps)。
总结
通过对 40 个顶级数据团队的数据角色分布进行深入分析,我们将数据角色大致划分为三类:洞察(包括数据分析师、产品分析师和数据科学家)、数据工程(涵盖数据工程师、数据平台工程师、分析工程师及数据治理人员)以及机器学习(专注于机器学习工程师)。各类角色的中位比例分别为:洞察 46%,数据工程 43%,机器学习 11%。但需要强调的是,这些数字仅供参考,因为不同公司对于数据角色的定义和划分可能存在显著差异。我们得出的结论是,并不存在一种适用于所有公司的通用比例。最佳的数据团队构成应根据公司的业务重点、发展阶段及规模大小进行灵活调整。
作者简介:
Mikkel Dengsøe,Synq(http://www.synq.io)联合创始人。
原文链接:
https://mikkeldengsoe.substack.com/p/how-top-data-teams-are-structured




