
9 年开源,踩坑无数,K8s 到底坑在哪?

在 Urb-it 这家公司的早期发展阶段(那时候我还没来),公司决定使用 Kubernetes 作为我们云原生战略的基石。这一决定的背后,公司所考虑的一方面是以 K8s 应对快速增长的预期,另一方面是利用它的容器编排功能为我们的应用程序带来更加动态、弹性和高效的环境。除此之外,Kubernetes 非常适合我们的微服务架构。
早期决策
这个决定是很早就定下来的,当然它理应受到质疑,因为它意味着我们作为一家初创公司要对这项技术产生深度依赖,还要为此学习太多的知识。另外,我们当时真的需要 Kubernetes 来解决它擅长的那些问题吗?有人可能会说,我们一开始可以先搞一个很大的单体架构用很长时间,直到它遇到令人痛苦的扩展之类的问题,然后我们再转向 Kubernetes(或其他东西)也不迟。此外,Kubernetes 彼时仍处于早期开发阶段。不过这些问题下次再讨论吧。
8 年生产经验
我们在生产环境中运行 Kubernetes 已经有八年多了(每个环境都有单独的集群),期间做出了一些好的和不太好的决策。有些错误仅仅是“otur när vi tänkte”(我们决策中遇到的坏运气)造成的,而另一些错误则源于我们不完全(甚至一点都没有)理解其底层技术。Kubernetes 很强大,但也颇具复杂性。
我们在没有任何大规模运行 K8s 经验的情况下迎头而上。
从 AWS 上的自托管迁移到 Azure 上的托管(AKS)
前面几年,我们在 AWS 上运行了一个自托管的集群。如果我没记错的话,我们一开始没有选择使用 Azure Kubernetes Service(AKS)、Google Kubernetes Engine(GKE)、Amazon Elastic Kubernetes Service(EKS),因为它们那时还没有提供官方的托管解决方案。正是在 Amazon Web Services(AWS)的自托管方案上,我们遭遇了 Urb-it 历史上第一次也是最可怕的一次集群崩溃,稍后会详细介绍。
由于我们是一个小团队,因此要掌握我们所需的所有新功能是很大的挑战。同时,管理自托管集群需要持续的关注和维护,这增加了我们的工作量。
当托管解决方案开始广泛流行时,我们花了一些时间来评估 AKS、GKE 和 EKS。对我们来说,所有这些方案都比我们自己管理要好上几倍,而且我们可以轻松地看到迁移带来的快速投资回报。
当时我们的平台是 50% .Net 和 50% Python,并且我们已经在使用 Azure Service Bus、Azure SQL Server 和其他 Azure 服务了。因此,将我们的集群迁移到 Azure 不仅可以更轻松地把这些服务集合起来使用,而且还可以充分利用 Azure 的主干网络基础设施,省去与离开 / 进入外部网络和 VNET 相关的成本,而之前我们的 AWS 与 Azure 混合架构中这些成本是避免不了的。此外,我们的许多工程师都熟悉 Azure 及其生态系统。
还应该提到一点,对于 AKS 上的初始设置,我们不必为控制平面节点(主节点)付费,这是一个额外的好处(节省节点费用)。
我们在 2018 年冬天进行了迁移,尽管多年来我们在 AKS 这块也遇到了一些问题,但我们从未因为这次迁移而感到后悔。
集群崩溃 #1
在 AWS 上使用自托管方案期间,我们经历了一次大规模的集群崩溃,导致我们的大部分系统和产品出现故障。根 CA 证书、etcd 证书、API 服务器证书都过期了,导致集群停止工作、无法管理。当时,kube-aws 中没有什么支持内容可以帮助我们解决这个问题。我们请了一位专家,但到最后我们不得不从头开始重建整个集群。
我们以为每个 git 存储库中都有所有值和 Helm 图表,但令人惊讶的是,并非所有服务都是如此。最重要的是,库里没有存储创建集群的任何配置。重新建立集群并把我们的所有服务和产品都塞进去的任务成了一场赶时间的赛跑。其中一些服务需要重新设计 Helm 图表来创建缺失的配置。有时一位开发工程师会问他的同事:“你还记得这个服务应该有多少 CPU 或 RAM,或者它应该有哪些网络和端口访问权限吗?”更不用说那些已经随风而逝的密钥了。
我们花了几天时间才让它重新启动并正常跑起来。至少可以说,这不是我们最自豪的时刻。
由于我们积极主动的沟通工作,通过保持透明度、诚实和客户关系培育等对策,我们没有失去任何业务或客户。
集群崩溃 #2
现在你可能会说:第二次事故不可能是由于证书造成的,因为你一定从第一次事故中吸取了教训,对吧?是,也不是。不幸的是,当我们从崩溃 #1 中重新创建集群时,我们使用的特定版本的 kube-aws 出现了问题。当它创建新集群时,它没有将 etcd 证书的过期时间设置为我们提供的过期日期,而用的是一年这个默认值。因此,在第一次集群崩溃整整一年后,证书过期了,我们又经历了另一次集群崩溃。不过这一次恢复起来容易多了,我们不用再重建所有东西。但这仍然是一个地狱般的周末。
旁注 1:其他公司也像我们一样受到了这个错误的影响,但它并没有帮助我们的客户…
旁注 2:我们的计划是在一年后更新所有证书,但为了给自己留出一些余量,我们将有效期设置为两年(如果我没记错的话)。因此,我们是有更新证书的计划,但这个 bug 让我们不得不提前行动。
自 2018 年以来,我们没有再发生过集群崩溃……希望这不是什么 flag。
经验教训
Kubernetes 很复杂
你需要雇佣一些对 Kubernetes 的基础设施和运营方面感兴趣并愿意参与其中的工程师。就我们而言,我们需要几位工程师在日常工作外钻研 Kubernetes,这样遇到问题时他们就能扮演现场专家的角色。正如你可能想到的那样,Kubernetes 中特定任务的负载也各不相同。有些时候连着几周几乎没有什么可做的,而有些时候工程师需要连续几周提高警惕,例如在集群升级期间。
我们不可能将工作轮流分配给整个团队;这项技术太复杂,没办法只做一个星期就转向别的工作,下一周再回来。当然,每个人都需要知道如何使用它(部署、调试等)——但要在更具挑战性的方面表现出色就需要工程师投入时间来研究学习了。此外,一位有远见并能制定集群发展战略的领导者也很重要。
Kubernetes 证书
由于证书过期,我们经历了两次集群崩溃,因此熟悉内部 Kubernetes 证书及其过期日期的细节是非常重要的。
让 Kubernetes 和 Helm 保持最新
当你落后时,它的成本就会上升,用起来也会变得不顺手。我们总是等待几个月才升级到最新版本,等其他人先遇到新版本的问题再说。但即使第一时间更新到最新版本,由于 Kubernetes 和 Helm 的新版本总会有变化(Kubernetes API 从 alfa 到 beta、beta 到 1.0 等),我们还是会面临许多耗时的配置文件和图表重写工作。我知道 Simon 和 Martin 喜欢 Ingress 的所有变化。
集中管理 Helm 图表
谈到 Helm 图表,每一次版本更改都要更新所有 70 多个图表的工作实在让我们厌倦,因此我们采用了更通用的“一个图表搞定一切”的方法。集中式 Helm 图表方法有很多优点和缺点,但不管怎样,它更适合我们的需求。
灾难恢复计划
我怎么强调都不为过:一定要提前做好准备方案,这样在需要时就能重新创建集群。是的,你可以在 UI 中点击几下来创建新集群,但这种方法永远无法大规模或及时地发挥作用。
有很多方法可以处理这个问题,从简单的 shell 脚本到更高级的方法都有,比如使用 Terraform(或类似的方案)。Crossplane 还可用于管理基础设施即代码(IaC)等。
对我们来说,由于团队带宽有限,我们决定存储和使用 shell 脚本。
无论你选择哪种方法,请务必不时测试流程,以确保你可以在需要时重新创建集群。
备份密钥
制定备份和存储密钥的策略。如果你的集群消失了,你所有的密钥也都会消失。相信我,这是我们的前车之鉴;当你有多个不同的微服务和外部依赖项时,需要花费大量时间才能使一切恢复正常。
与供应商无关 VS “全力以赴”
一开始,在迁移到 AKS 后,我们试图让集群不和供应商绑定,这意味着我们将继续使用其他服务来做容器注册表、身份验证、密钥保管库等。我们的想法是,这样的方案让我们在将来某一天可以轻松迁移到另一个托管平台。虽然与供应商无关是一个好主意,但对我们来说,它带来了很高的机会成本。一段时间后,我们决定全力投入 AKS 相关的 Azure 产品,例如容器注册表、安全扫描、身份验证等。对我们来说,这改善了开发体验,简化了安全性(使用 Azure Entra Id 进行集中访问管理),等等,从而加快了上市时间并降低了成本(规模效益)。
自制资源定义
是的,我们全力投入了 Azure 产品线,但我们的指导方针是尽量不用自制的资源定义,而使用内置的 Kubernetes 资源。然而我们也有一些例外,比如 Traefik,因为 Ingress API 并不能满足我们的所有需求。
安全
见下文。
可观察性
见下文。
已知峰值期间的预缩放
就算使用了自动缩放器,我们有时也会缩放得太慢。基于流量数据和常识(我们是物流公司,节假日有高峰),我们会在高峰到来前一天手动扩容集群(ReplicaSet),第二天再缩容(一点点缩,以应对随时可能出现的第二波高峰)。
集群内的 Drone
我们将 Drone 构建系统保留在了 stage 集群中;这样做有一些好处,但也有一些缺点。由于它位于同一个集群中,因此很容易扩展和使用。然而,同时构建太多 Drone 时,它会消耗掉几乎所有的资源,让 Kubernetes 急着启动新节点。最好的解决方案可能是将其作为纯粹的 SaaS 解决方案,而不必担心产品本身的托管和维护工作。
选择正确的节点类型
虽说这是跟上下文紧密关联的,但总体来说根据节点类型,AKS 会保留大约 10-30% 的可用内存(用于内部 AKS 服务)。因此对我们来说,我们发现使用更少但更大的节点类型是有益的。此外,由于我们在许多服务上运行 .Net,因此需要选择具有高效且可观的 IO 性能的节点类型。(.Net 经常写入磁盘以进行 JIT 和日志记录,如果这需要网络访问就会变得很慢。我们还会确保节点磁盘 / 缓存的大小至少与配置的总节点磁盘大小相同,也是为了防止网络跳转)。
预留实例
你可能会争论说这种方法有点违背云的灵活性原则,但对我们来说,保留关键实例一两年可以节省大量成本。在许多情况下,与“现收现付”方式相比,我们可以节省 50-60% 的成本。是的,这对团队来说已经足够了。
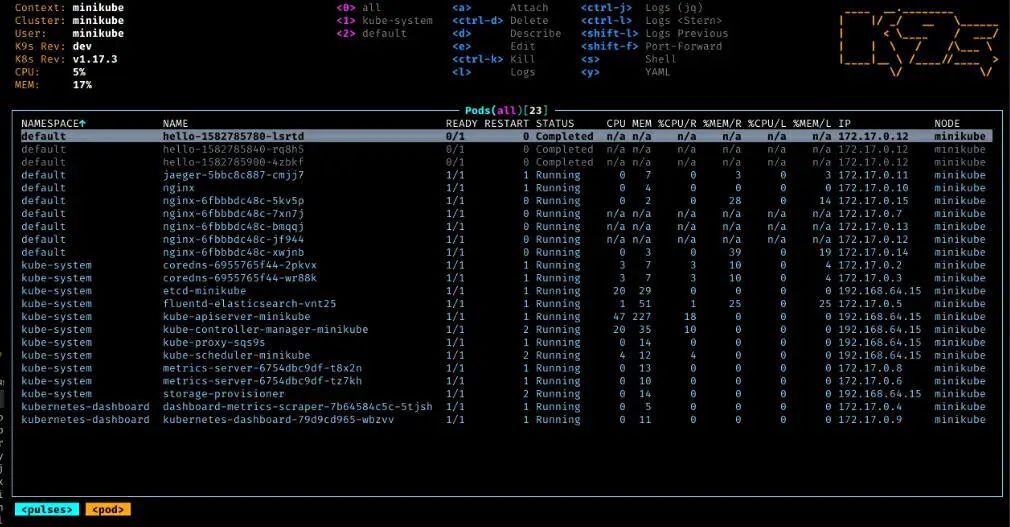
k9s
对于想要比纯 kubectl 高一级抽象的用户来说,https://k9scli.io/ 是一个很棒的工具
可观测性
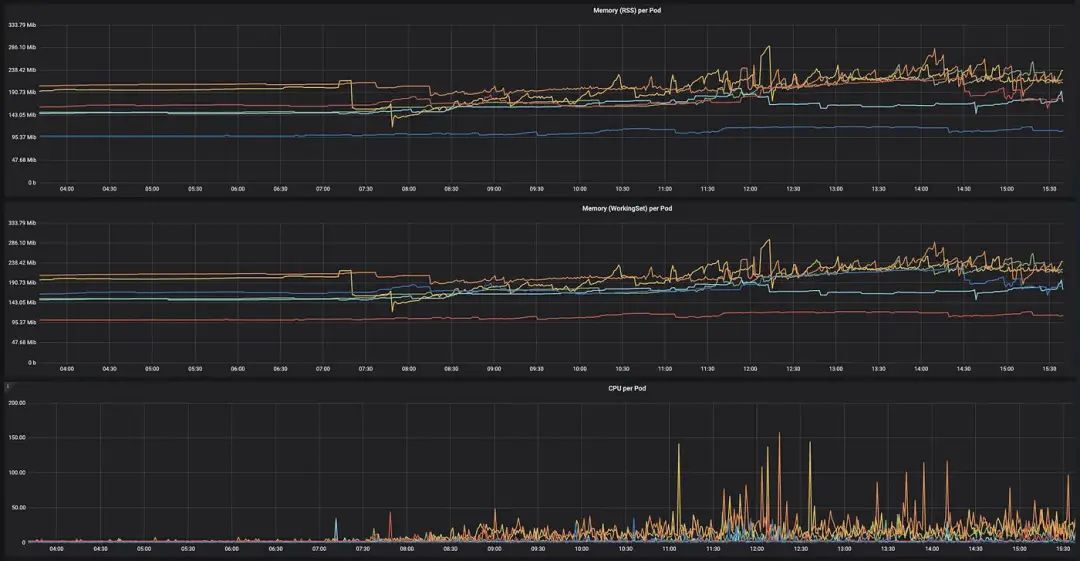
监控
一定要持续跟踪内存、CPU 等资源的使用情况,于是你就可以观测集群的性能并确定新功能是否正在改善或恶化其性能。这样就可以更轻松地为不同的 Pod 找到并设置“正确”的限制(找到正确的平衡点很重要,因为如果内存不足,Pod 就会被杀死)。
告警
逐渐完善我们的告警系统是一个过程,但到最后,我们将所有告警定向到了我们的 Slack 频道上。当集群未按预期运行或出现任何不可预见的问题时,这种方法可以让工程师方便地接收通知。

日志
对于任何微服务架构来说,将所有日志整合到一处,以及部署强大的跟踪 ID 策略(例如 OpenTelemetry 或类似策略)都是非常重要的。我们花了 2 到 3 年的时间才把这件事做好。如果我们早点实施它,就会节省大量时间。

安全性
Kubernetes 中的安全性是一个范围很大的主题,我强烈大家建议对其进行彻底的研究,以了解安全性方面的所有细微差别(举个例子,可以参阅 NSA、CISA 发布的 Kubernetes 强化指南)。以下是我们以往经验中的一些要点,但请注意,这些内容肯定不够完整。
访问控制
简而言之,Kubernetes 默认情况下并没有过度限制。因此我们投入了大量时间来加强访问控制,为 Pod 和容器实施最小权限原则。此外,由于一些特定的漏洞,无特权的攻击者有可能将其权限升级为 root,从而绕过 Linux 命名空间限制,在某些情况下,他们甚至能逃离容器以获得主机节点上的 root 访问权限。起码这不是什么好事。
你应该设置只读根文件系统,禁用服务帐户令牌自动挂载,禁用权限升级,删除所有不必要的功能等等。在我们的具体设置中,我们使用 Azure Policy 和 Gatekeeper 来确保自己没有部署不安全的容器。
在 AKS 内的 Kubernetes 设置中,我们利用基于角色的访问控制(RBAC)的稳健性来进一步增强安全性和访问管理。
容器漏洞
有很多很好的工具可以扫描和验证 K8s 容器和其他部分。我们使用 Azure Defender 和 Azure Defender for Containers 来满足一些需求。
注意:不要陷入“分析瘫痪”,也就是先试图找到“完美”的,什么花哨功能都包含的工具才开始行动。你要做的只是先选择一些工具,然后开始学习即可。
我们的长期设置
部署
与许多其他应用程序一样,我们使用 Helm 来管理和简化 Kubernetes 上应用程序的部署和打包任务。由于我们很早以前就开始使用 Helm,并且一开始就混用了 .Net/Go/Java/Python/PHP,因此我们重写 Helm 图表的次数多得我都记不清了。
可观测性
我们开始使用 Loggly 和 FluentD 一起来做集中式日志记录,但几年后,我们转向了 Elastic 和 Kibana(ELK 堆栈)。对我们来说 Elastic 和 Kibana 更易用,因为它们更流行,而且在我们的设置中更便宜。
容器注册表
我们一开始用的是 Quay,这个产品很不错。但随着我们迁移到了 Azure,自然就转向了 Azure 容器注册表,因为它是集成的,对我们来说是一个更“原生”的解决方案。(然后我们还在 Azure Security Advisor 下获取了容器)。
管道
从一开始,我们就一直使用 Drone 来构建容器。当我们刚开始时,支持容器和 Docker 的 CI 系统并不多,也没有以代码形式提供配置。多年来,Drone 为我们提供了很好的服务。当 Harness 收购它时,它变得有点混乱,但在我们屈服并转向高级版本后就获得了所需要的所有功能。
改变游戏规则
在过去的几年里,Kubernetes 改变了我们的游戏规则。它释放的功能使我们能够更有效地扩展(不稳定的流量),优化我们的基础设施成本,改善我们的开发人员体验,让我们更容易测试新想法,从而显著缩短新产品和服务的上市时间 / 赚钱时间。
我们开始使用 Kubernetes 有点太早了,那时候我们还没有真正遇到只有它才能解决的问题。但从长远来看,尤其是最近几年,事实证明它为我们提供了巨大的价值。
结 语
回顾八年的经历,我们有很多故事可以分享,其中许多已经淡入记忆。希望我们的情况、我们所犯的错误以及我们在此过程中吸取的教训能为大家带来帮助。感谢阅读。
原文链接:
声明:本文为 InfoQ 翻译,未经许可禁止转载。
今日好文推荐
3700 万美元“卖身救命”,泥潭深陷的 MariaDB 准备退市




