
贝壳作为全国领先的房产交易和租赁在线服务平台,有很多业务场景会产出大量实时和离线数据,针对这些数据进行查询分析,对于企业发展和业务拓展至关重要。不同业务线不同查询场景下,单一技术手段很难满足业务方的需求,Druid 就是我们在探索之路上发现的比较切合业务方需求的 OLAP 引擎之一,基于 Druid 我们做了深入地实践,接下来就由我和业界朋友们一起分享。
内容包括:
贝壳 OLAP 平台介绍
OLAP 技术选型策略
Druid 在贝壳的应用实践
Druid 结合贝壳业务场景的改进
未来规划
贝壳 OLAP 平台介绍
1. 平台简介
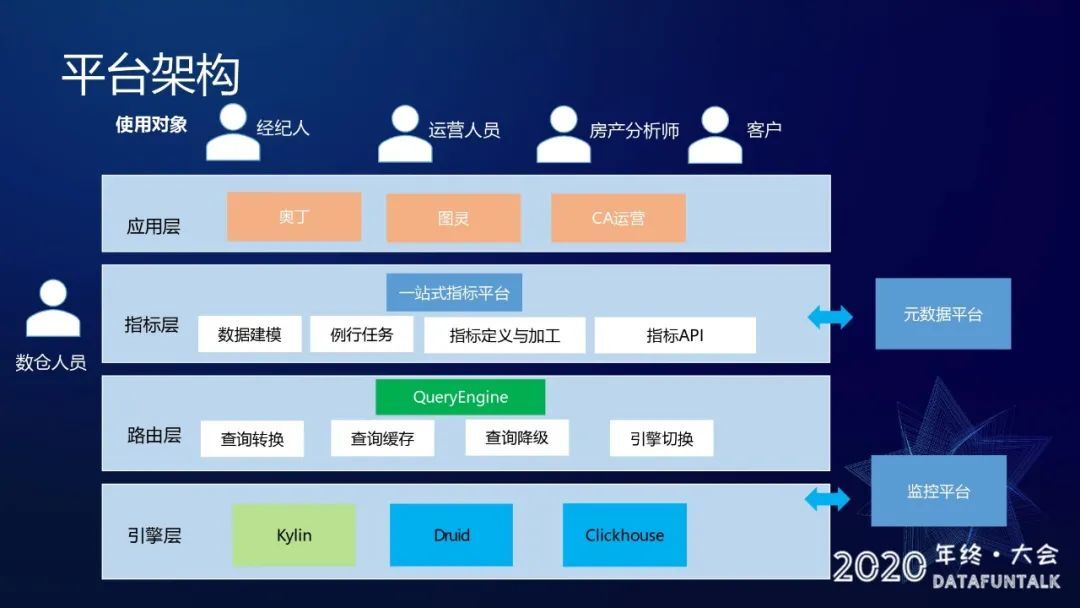
平台的使用对象主要是经纪人、运营人员、房产分析师和客户。平台的架构就如上图所示,整个平台分为四层,第一层为应用层,应用层主要是看板和报表。第二层是指标层,提供了一个一站式的指标平台,主要使用对象是数仓人员,数仓人员可以在一站式平台上做数据建模、例行作业任务配置、指标定义加工以及指标 API 输出。第三层为路由层,路由层是一个统一查询引擎,提供查询语义转换、查询缓存、查询降级以及不同类型的引擎切换。第四层是 OLAP 引擎,目前使用的主要引擎是 Kylin、Druid 以及 Clickhouse,其中 Kylin 和 Druid 主要是分担离线指标业务,Clickhouse 负担实时指标业务。在 2020 年 4 月份之前,平台底层的离线指标引擎主要依托 Kylin 为主,在 2020 年 5 月份之后,逐渐引入 Druid 引擎,目前两个引擎的流量比例 Druid 占 60%左右,kylin 在 40%左右。
2. 引入 Druid 的原因

引入 Druid 引擎是因为在使用离线指标的时候发现用 Kylin 引擎存在一些问题,主要包括五大问题:
使用 Kylin 的数据源构建时间比较长,有些业务方要求在某一个时间点前数据必须就绪。
数据源的底层存储占用比较大。
查询的灵活性比较差,有时候为了适配不一样的查询,需要构建多个 cube 进行适配。
源数据的膨胀率巨大,相对于源数据表里 ORC 的文件大小,它的膨胀率比较惊人,有可能产生可怕的维度爆炸。
它的调优门槛相对较高,需要对数仓的同学做一定的培训才能上手。
OLAP 技术选型策略
1. 为什么选择 Druid

首先分享下贝壳在选用 Druid 时候采用了哪些选型策略。其实选型最重要的是大家要知道自己需要什么样的一个 OLAP 引擎。针对贝壳来说,主要有五点要求,第一个是 PB 级别的数据量;第二个是亚秒级别的响应;第三个是支持较高的并发,在贝壳的业务场景下,QPS 来说相对较高,平均 QPS 在五六百左右,峰值可达到 2000;第四个是灵活应用的查询接口,支持在 QE 引擎层灵活接入,让统一 SQL 查询引擎屏蔽底层 OALP 引擎查询语法差异;第五个是快捷导入数据,按时生成查询数据源,满足业务方查询需求。
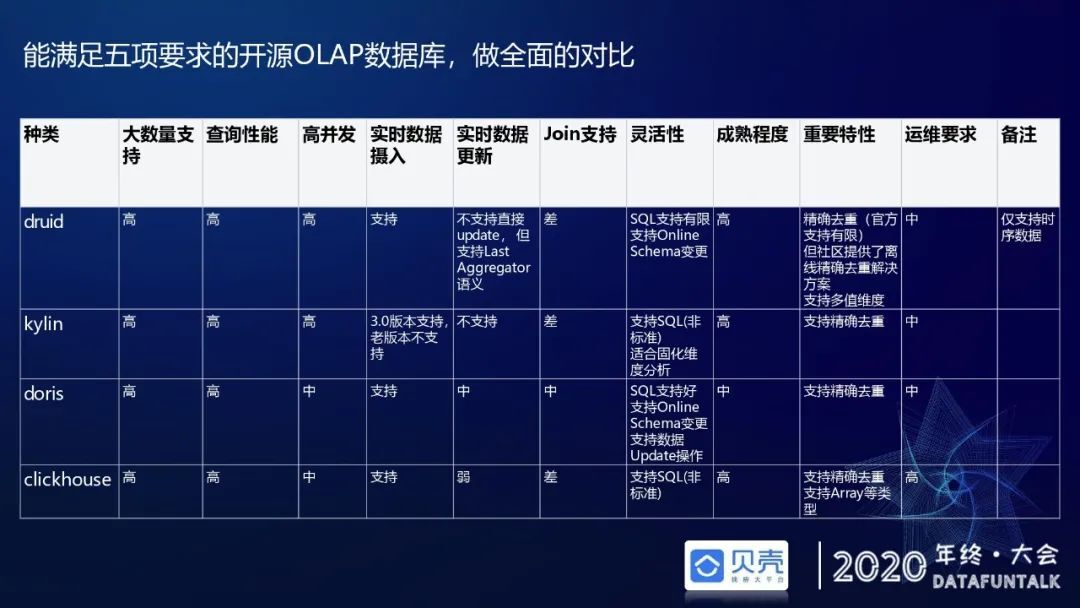
根据如上五点要求,可选用 OLAP 引擎主要是 Druid、Kylin、Doris、Clickhouse 这四种。根据贝壳需要支持高并发和支持精确去重的需求,Druid 的并发性能和 Kylin 的并发性能比较接近,Doris 比 Clickhouse 好一些,Clickhouse 的高并发性能没有那么好。Druid 的原生版本支持 SQL 级别的精确去重,但是离线的多列精确去重原生版本是不支持的。在社区里有伙伴用 bitmap 实现的一个版本,它参照 Kylin 的字典编码用 AppendTrie Tree 实现了离线多列精确去重。综合以上因素及运营成本,最终选定了使用 Druid。
2. Druid 与 Kylin 对比测试
我们做了一些初步测试来验证两种引擎的性能
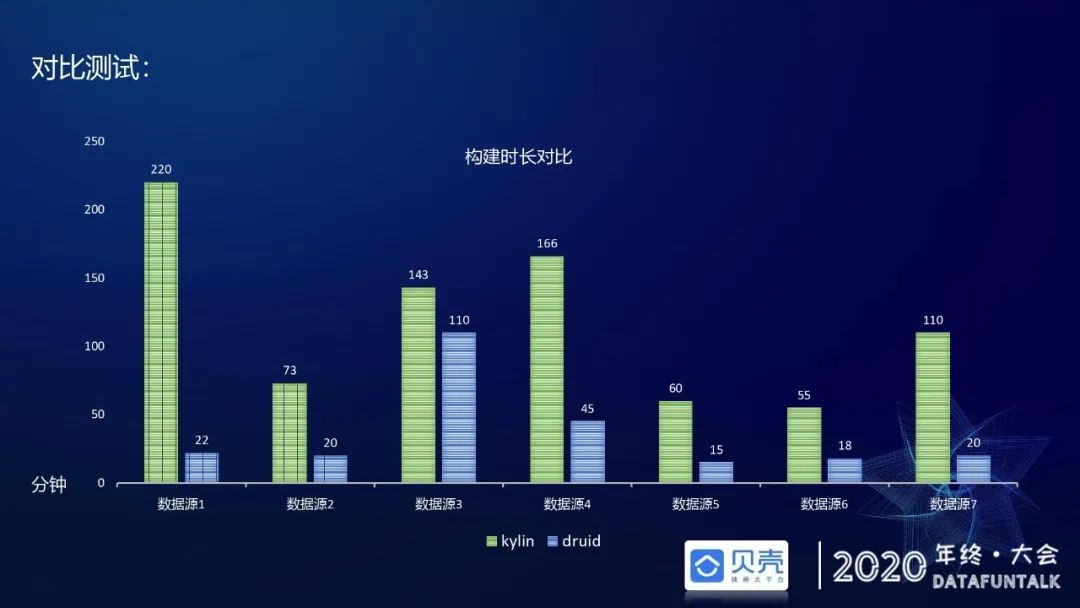
在构建时长方面,选用了包括全量表,增量表在内的线上常用七个数据源,使用相同的计算资源情况下,对近一个月的平均导入时长进行对比,Druid 导入时长比 Kylin 导时长要短,基本上是 Kylin 的 1/3 左右。
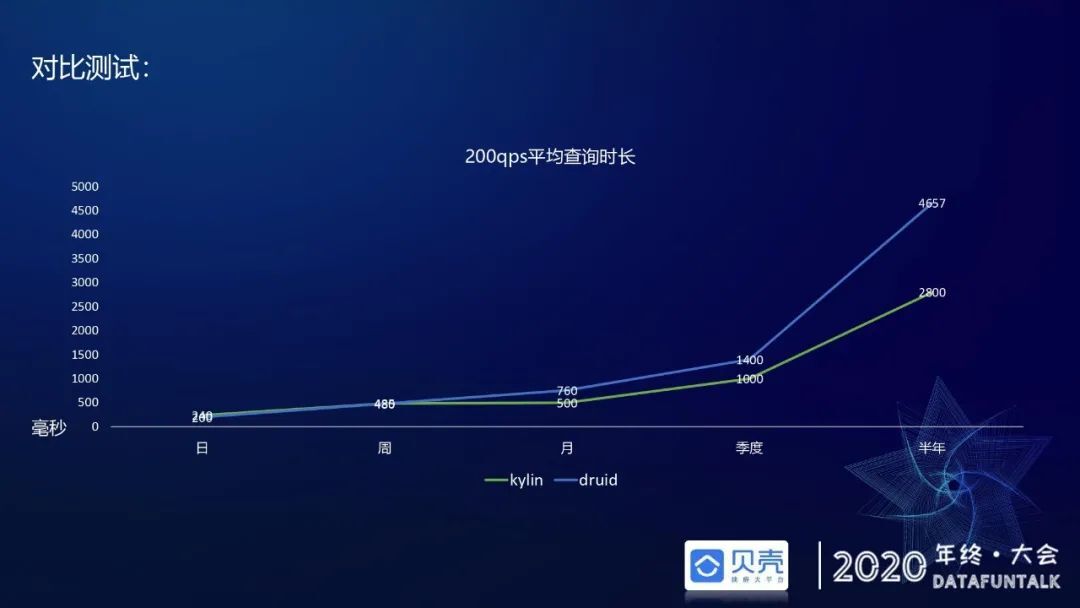
在平均查询时长方面,对比了在 200QPS 左右的查询时长,选取的查询范围包括日/周/月/季度/半年等时间范围,Druid 的查询时间和 Kylin 比较接近。理论上 Kylin 的查询时间应该更快,因为 Kylin 的预聚合程度更高,相当于把所有的查询条件及度量都已经进行了预计算,只要调优的技术比较好,它的查询速度应该是最好的。
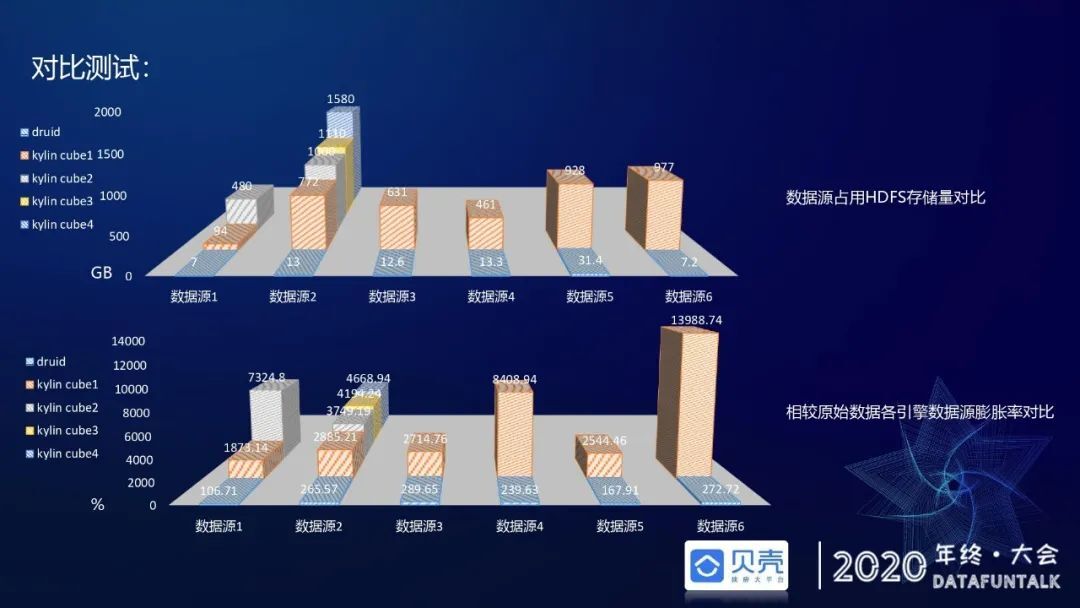
在数据源占用 HDFS 存储及相较于源数据的膨胀率方面,也做了一些统计,发现 Druid 在 HDFS 占用存储量相较与 Kylin 的 cube 占用存储明显占优。图中前面一排蓝色是 Druid,后面几个颜色都是 kylin 的 cube,可能有同学会问为什么有的数据源有很多 cube,因为 kylin 要适配不同的查询类型,会预聚合多个 cube 来满足查询速度。从膨胀率看,相较于 ADS 层的 hive 源表数据,Druid 的膨胀率大概是 1 到 3 倍左右,Kylin 的膨胀率在 18 倍到 100 倍。
3. Druid 的架构
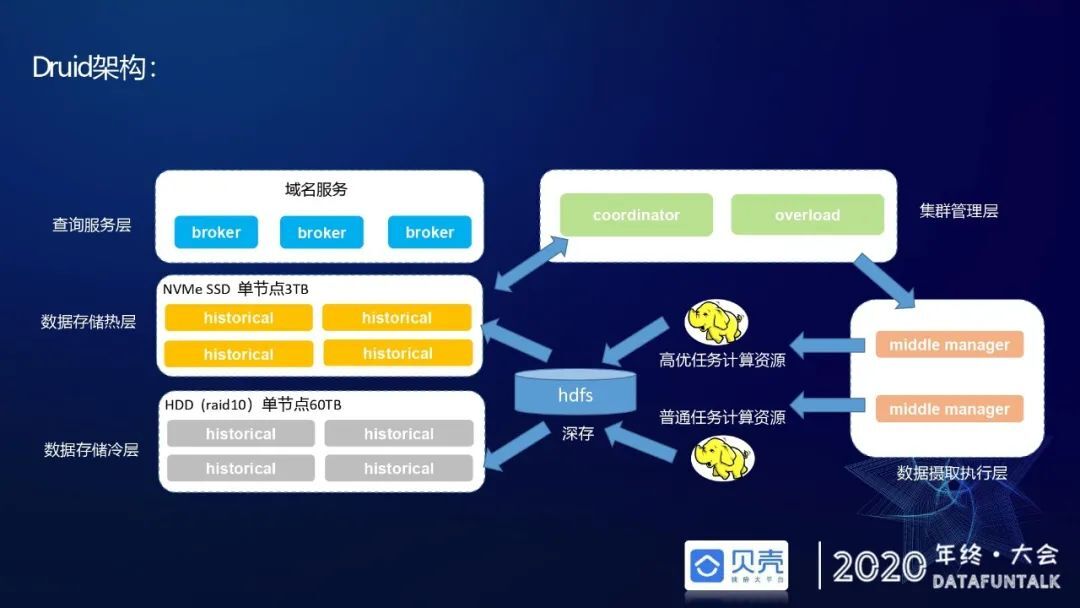
Druid 架构主要有四层,第一个是查询服务层,第二个是数据存储层,第三个是集群管理层,第四个是数据摄取层。查询服务层主要是它的 broker,用于接收用户端的查询请求。数据存储层在生产部署的时候,再分两层,一个是数据热层,一个是数据冷层。数据热层一般存储近半年的数据,以天为聚合条件;数据冷层一般存储超过半年的数据,包括一年、两年甚至五年的数据,以月度粒度聚合。它们的存储介质也有区别,热层用 NVMe 的 SSD 盘,冷层用 HDD 普通的机械硬盘做 raid10,以提升 IO 读写性能。数据摄取执行层主要是负责离线任务、实时任务执行。集群管理层就是管理数据摄取的 master 即 overlord 和数据存储层的 master 即 coordinator。
Druid 在贝壳的应用实践
1. 指标构建
Druid 在贝壳的应用是通过一站式指标平台实现的,平台整合了数仓建模、指标定义、指标加工、指标 API 四项功能。
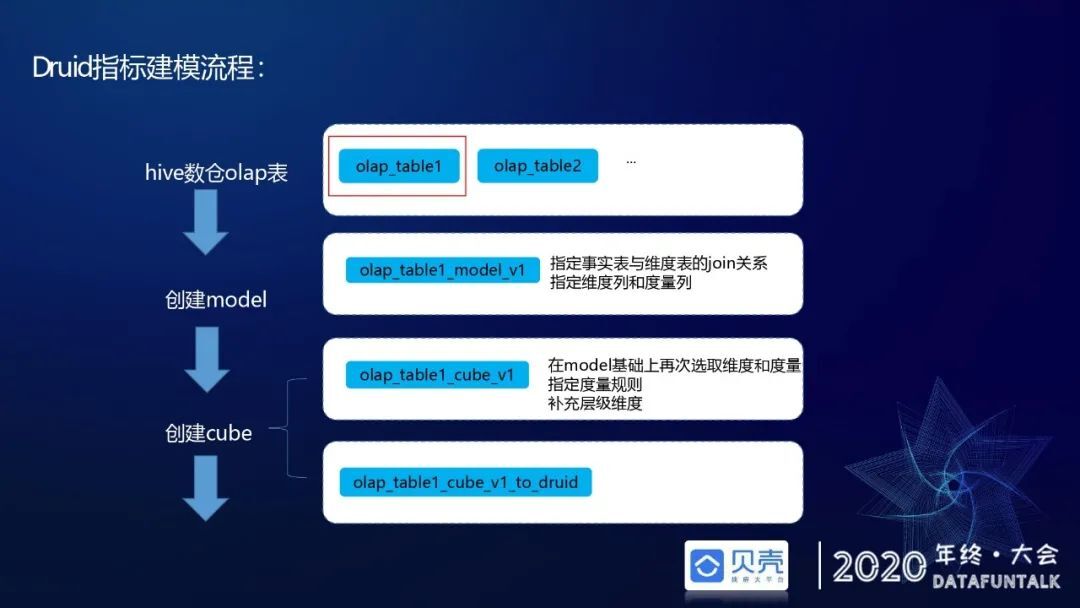
一个 Druid 指标的创建流程如下:首先,用户在元数据平台上去找到目标 OLAP 表;然后,创建 model 和 cube,这里 model 和 cube 参考 kylin 建模思想。其中 model 指定事实表和维度表的 join 关系,同时指定度量列和维度列。cube 是在 model 的基础上再次做维度和度量选取,指定度量列的度量规则,包括 count distinct/sum/count/avg 等度量规则。在创建完模型后一站式指标平台会自动构建一个 Hive2Druid 作业任务。
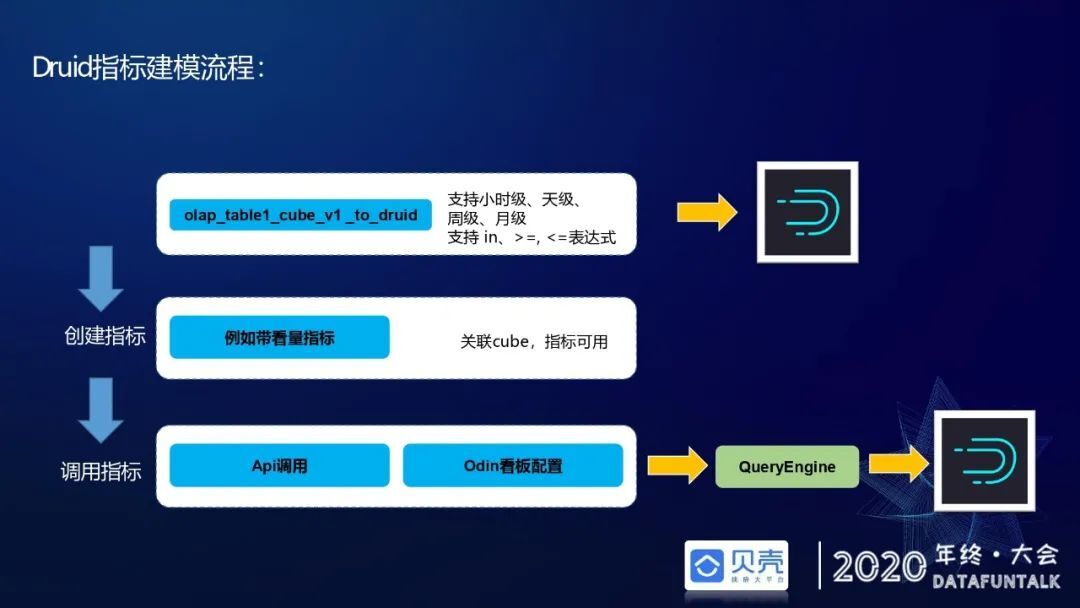
目前离线指标任务支持小时级别、天级、周级、月级,也支持 in 多少个 pt(日期分区)、大于等于、小于等于这些复杂的时间表达式,用于支持用户做历史数据重刷。任务构建完成之后,会自动在定时的时间点往 Druid 里灌入数据。最后用户可以在一站式指标平台上创建指标,比如经纪人带客户看房的指标,建完后关联相应的 cube 就可用了。一些看板的 RD 研发同学可以通过 API 的方式直接调用,还有一些用户可以直接在 Odin 上配置看板,来查询底层数据。
2. 应用效果
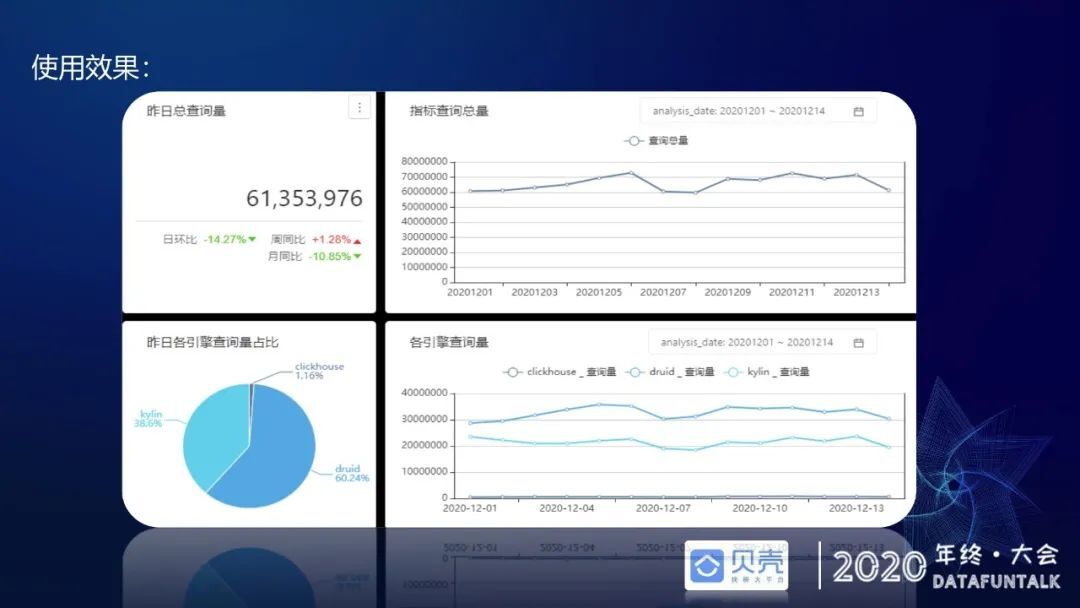
从支撑的查询量看,当下查询量每日 6000 万左右,四月份前约为 3000 万左右,相较于年初翻了一倍,Kylin 和 Druid 的分担比例大概是 4:6,Druid 占了 60%。
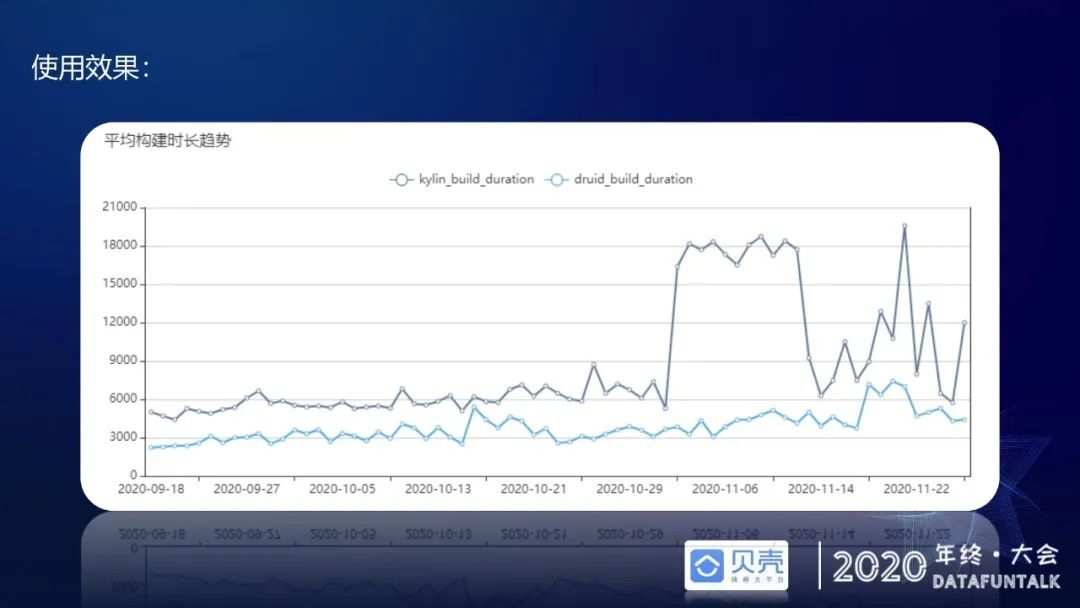
从构建时长看,Druid 的数据源构建时长仅为 Kylin 构建时长的 1/2 左右。
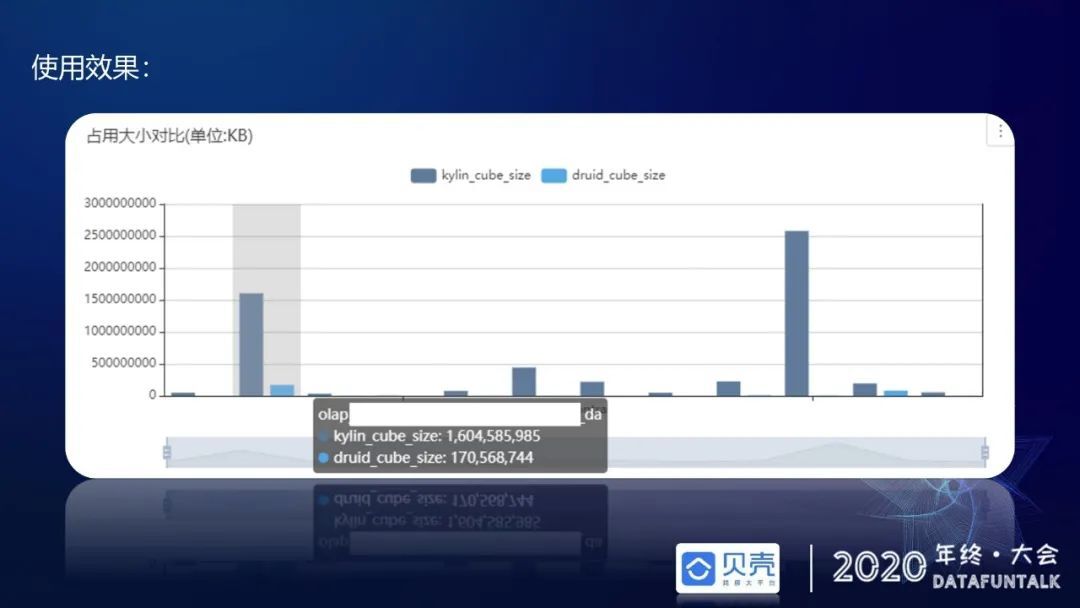
从存储占用大小看,据不完全统计,在 2020 年 4 月份,Kylin 底层占用 600TB,全部迁移 Druid 后,存储量预计为 Kylin 的 1/10 左右,节省的底层存储资源非常可观。
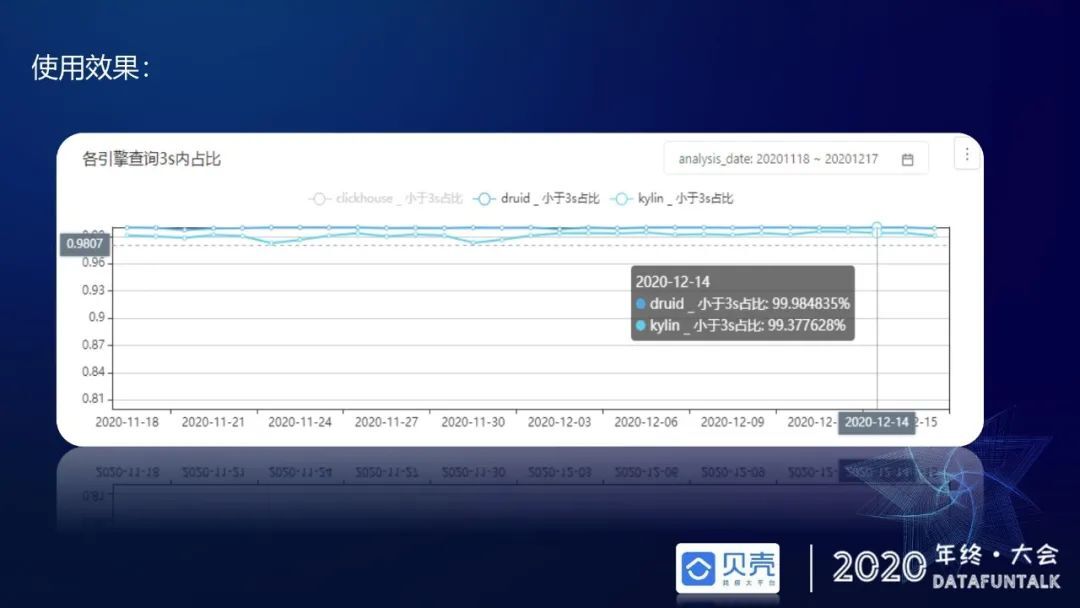
从三秒内到达率看,Druid 三秒内到达率基本维持在 99.9%以上,kylin 维持在 99.3%-99.4%的水平,因为 Kylin 的 cube 调优比较麻烦,所以预期也会比 Druid 稍低。
Druid 结合贝壳业务场景的改进
1. 改进总体说明

关于 Druid,贝壳结合业务场景做了一些改进,本次分享的改进点主要从两个方面介绍,第一个是 Druid 数据源的导入方式,第二个是保障 Druid 集群稳定性。
2. Druid 数据源导入优化
Index hadoop 作业类型数据导入优化
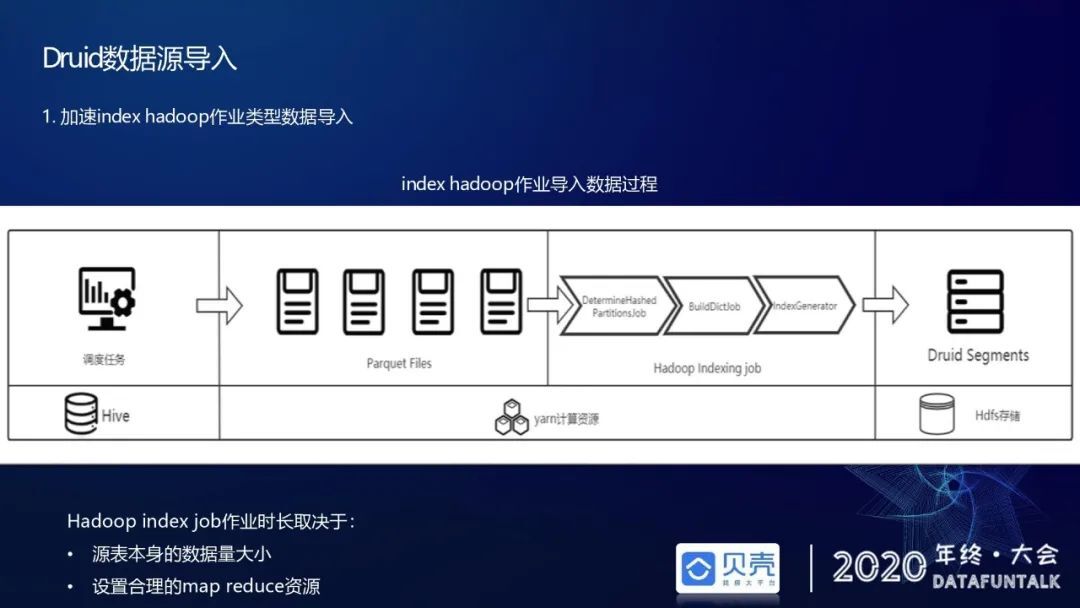
第一个方面的优化是针对离线的 hadoop 作业类型数据导入。
首先,介绍一下整个数据导入过程:
① 之前提到 cube 构建好后,会自动构建一个调度任务,在触发点触发的时候,会从 hive 仓库中获取数据。
② 从 hive 数仓中获取数据落盘形成 parquet 的文件,parquet 文件就绪后会通知 Druid overload(执行数据灌入的 master 节点)数据已经就绪。
③ overload 会去加载 hdfs 上的 parquet 文件,开始执行 hadoop index 作业;Hadoop index 作业的执行主要是分为三个步骤,第一步是 partition 作业,这一步决定会分多少个 segments。第二步是构建字典左右,当前构建字典部分引用的是社区小伙伴提供的离线精确去重的版本,注意只有度量规则中指定 count distinct 列的时候,才会去触发这个作业。第三步是生成索引作业,针对维度列和度量列生成倒排索引和 bitmap 索引。
④ Hadoop index 作业运行完后,segment 持久化到深存 hdfs,落盘后 historical 从 hdfs 上拉取文件,生成自有存储格式,这样整个数据导入就结束了。
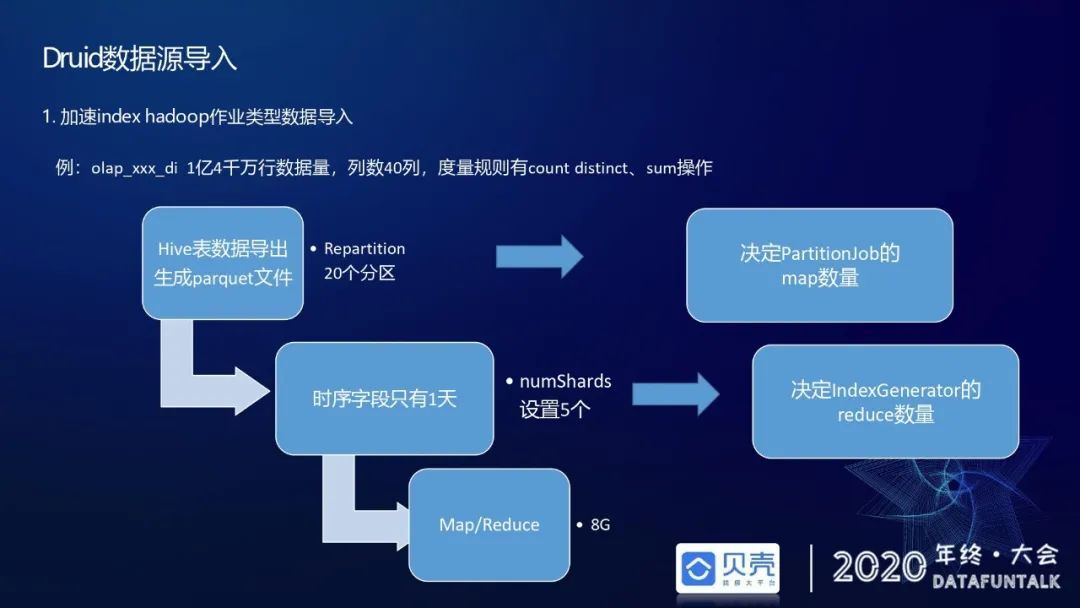
关于上述步骤中离线数据灌入的作业时长,主要取决于两个因素,第一个是源表本身的数据量大小,第二个是使用了多少 map reduce 的资源。
这里举一个例子,对于一个数据量是 1 亿 4000 万、列数 40 列、有 count distinct 和 sum 度量,基数在 600 万左右的数据增量表,去 hive 里查数据生成 parquet 文件时候,我们预先 repartition 出 20 个分区,500 万行一个分区,生成 20 个 parquet 文件,分区的数量会决定 partition job 的 map 数量;第二个是时序字段里面只有一天,因为它是一个增量表,当日 PT 里面只有昨天一日的数据,如果按照昨天一日数据直接向 druid 里面灌入,在生成索引阶段,它的 reduce 数量只有一个,作业运行效率非常差,这里我们根据经验直接指定 numShards 的数量是 5,每个 map reduce 的内存资源是 8G。按如上步骤进行优化后数据导入效率提升明显。
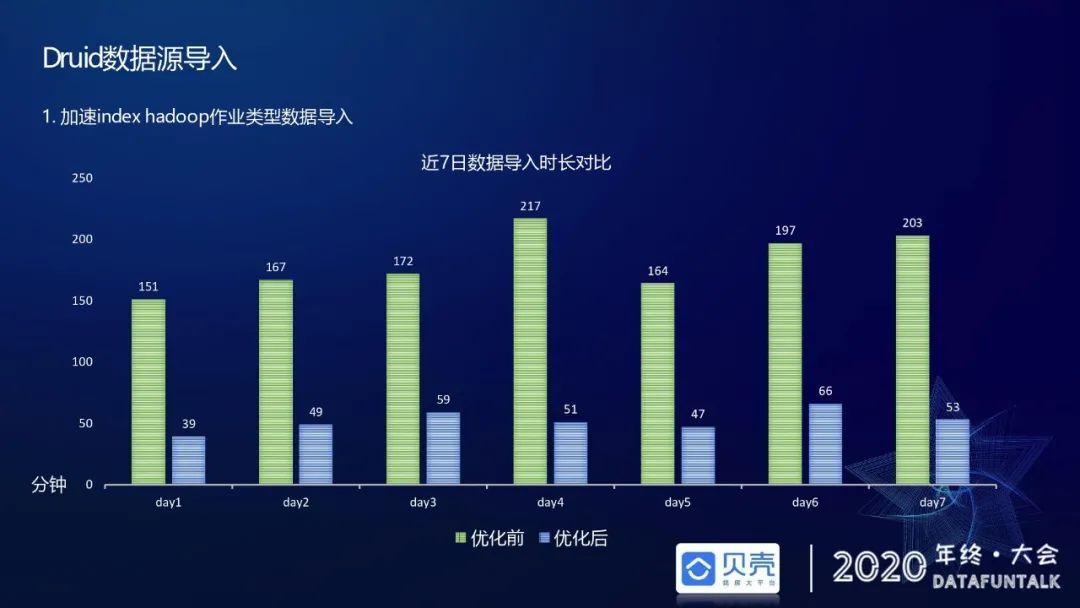
上图为近七日优化前和优化后数据源导入时长对比,优化后的时间约为优化前的 1/3。

使用 index hadoop 作业类型往 Druid 导入数据存在列精确去重的一些问题,如果列为高基数列,比如 5000 万、6000 万、1 亿这样的高基数,index generator job 在 map 阶段去拉取字典生成 bitmap 数组的时候,在 container 里会出现 full GC 的问题。一般的解决方法就是调整 map 的内存,但是不可能无限制的调整,这个也是我们未来优化的一个重点。
Kafka Index 作业类型增加多列实时精确去重能力

第二个改进是针对 kafka index 作业类型增加多列实时精确去重的能力,主要是因为我们的业务方有 GMV、GSV、分享数实时精确去重统计需求。Druid 的原生版本支持 sql 语法的精确去重,但这种查询性能并不高且只能支持单列精确去重,也就是说一个查询语句里面只能执行 select count(distinct A) from table 1,不能执行 select count(distinct A), count(distinct B) from table 1。社区之前提供的离线精确去重版本不能支持实时场景,仅可在近实时场景中采用(即小时级别任务),秒级别或者分钟级别不适合。
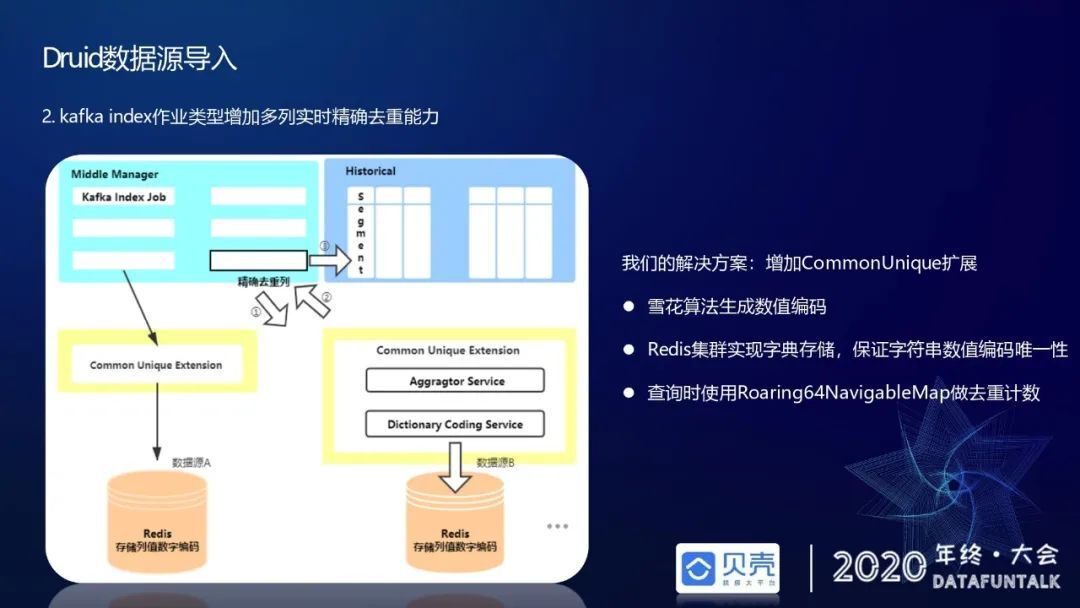
贝壳的解决方法是借鉴社区的一些经验,实现了一个 CommonUnique 的扩展。扩展的实现主要有三点,第一点是用雪花算法生成数字编码,就是在执行 kafka index job 时候在本地服务内起动一个生成雪花 ID 的 service,这样可以使得 ID 生成速率更快。第二点是用 redis 集群实现字典存储,通过 redis 基于缓存的分布式锁,可以保证字符串的数值编码的唯一性。因为 ID 是一直递增的,传递进来一个字符串生成一个 ID,再往 Redis 里 set 的时候,如果发现 value 值已经有了,直接就返回已有值。第三点是查询的时候使用 64 位的 bitmap 做去重计数,这是因为雪花 ID 生成的数值编码是 long 型,所以用 64 位更合理。测试了近一个月内的查询,基本可以达到秒级以下的返回。

上图是如何使用 CommonUnique 这种指标类型的说明,在数据摄入阶段,可以在 metricsSpec 里去定义 CommonUnique 这种指标计算类型,fieldName 是原始列,name 是需要进行 bitmap 编码的列。右边举的是一个 groupby 的查询例子,在数据查询的时候,在 aggregation 里可以指定 CommonUnique,然后 name 和 fieldName 都指定 bitmap 编码列,就可以实现一个 select count distinct 这一列的查询需求。
3. 保障 Druid 集群稳定的措施
背景说明
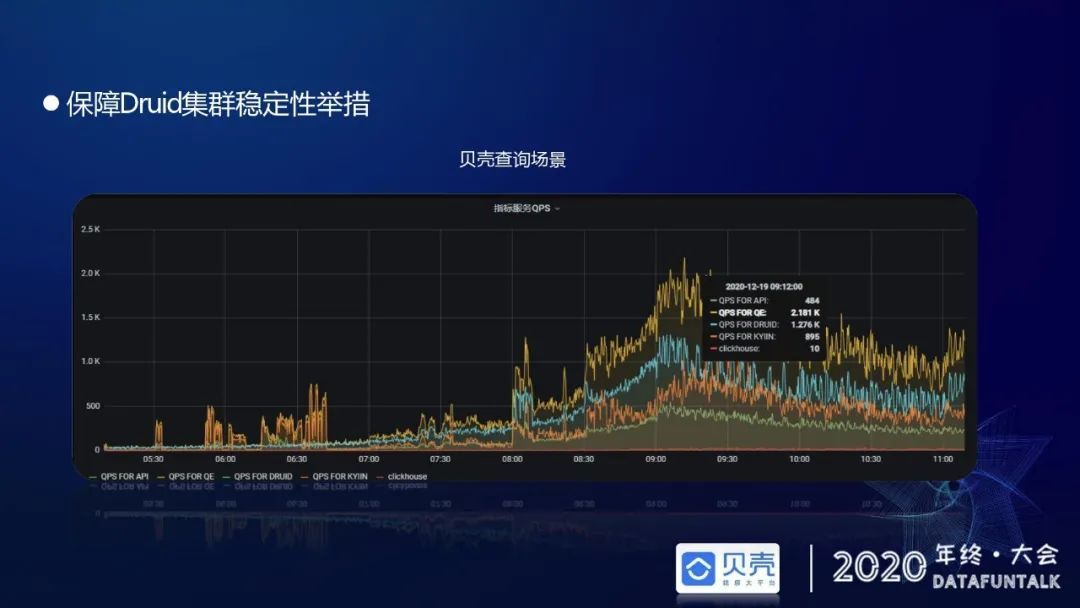
当前 Druid 查询的高峰期在上午 7 点到中午 12 点,Druid 峰值 QPS 最高约 1200 左右,上层统一 SQL 查询引擎峰值 QPS 在 2000 左右。
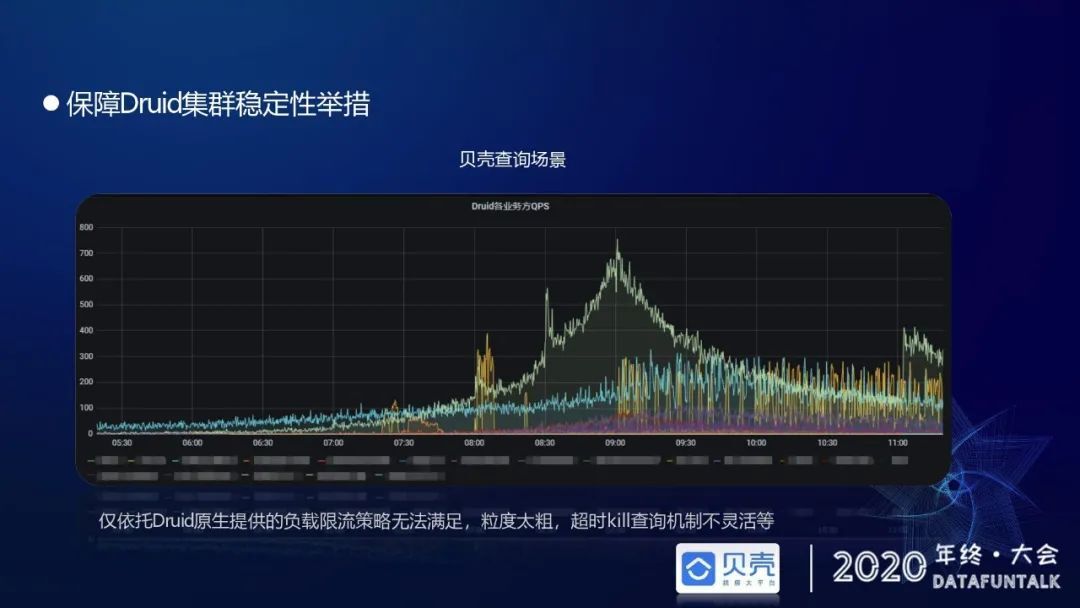
在 Druid 上面承载了 20 多个业务线的查询需求,如果仅仅依靠 Druid 原生提供的负载限流策略是没有办法满足的。因为每个业务线的查询重要程度不一样,查询的 sql 的复杂程度也不一样,所以需要针对不同的业务线、不同的查询数据源做精细化的控制,原生控制粒度太粗,单纯只是超时时长自动 kill 在高峰期很难满足不同业务线的查询需求。

三项集群稳定措施:
① 查询缓存
② 动态限流
③ hdfs 存储优化。
查询缓存
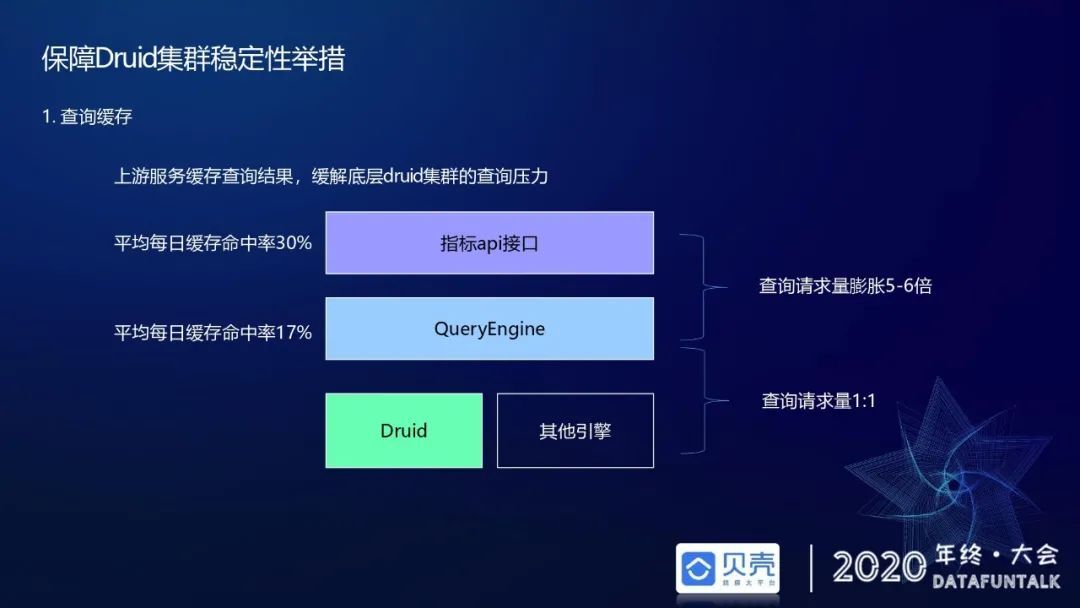
这里的查询缓存不是指 Druid 自身的缓存(即 Druid broker、historical 上的缓存)。此处的缓存是上层服务针对 Druid 查询结果的缓存,即指标 API 缓存和统一 SQL 查询引擎缓存。在实际应用当中,指标 API 层缓存命中率约为 30%,查询引擎的缓存命中率约为 17%,这样上层就可以缓解掉 40%多的请求。
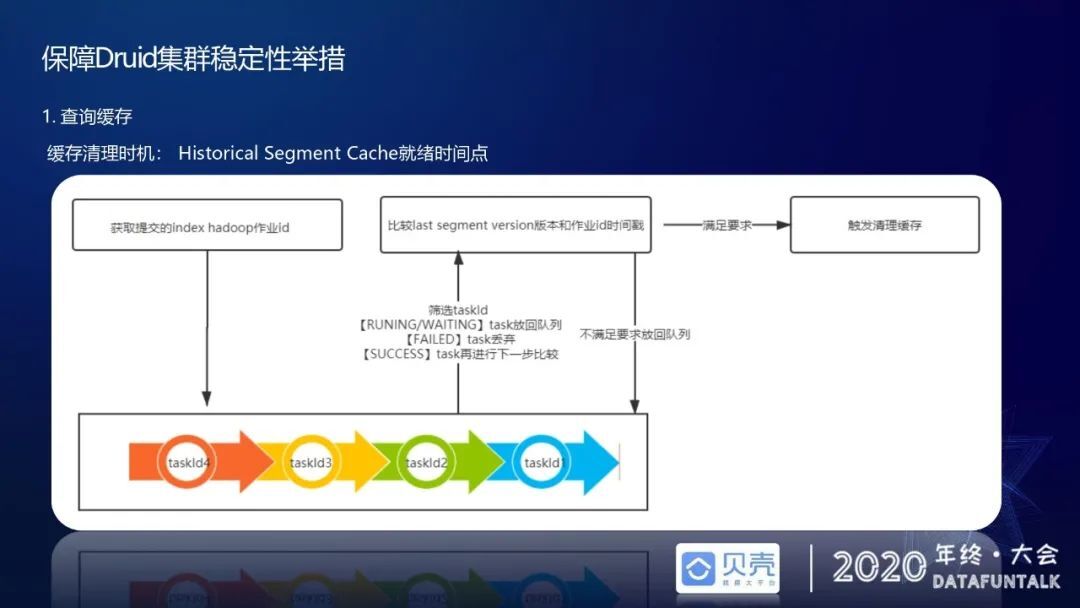
既然使用了查询缓存,就需要思考在什么样的时间点去清理查询缓存,不让用户查到一些脏数据。我们缓存清理的时机一般设置在 historical segment cache 就绪的一个时间点。这里需要提一下,Druid 数据摄取任务的 hadoop index task 作业结束的时间跟 segment 落盘的时间是不一致的,也就是说 task 任务结束了,但 segment 落盘可能还要很长时间。segment 落盘取决于两个因素,一个是 historical 的数量,一个是 historical 上用于 load segment 的线程数。此时就不能用 task 执行结束时间作为数据就绪的时间。在社区里面也有人提过能不能让 task 执行结束的时间就是 historical segment 落盘的时间,但社区没有同意这个改良建议,因为如果 task 里需要很多 segment 去落盘,比如说要灌两年的数据,就要每次落 700 多个 segment,有的用户还可能要落五年的数据,这样去落盘时会影响 task 线程,落的数据量大会导致 task 一直处于占用状态,进而会影响新的数据摄取,浪费线程资源。我们的解决办法是用户提交这种 index hadoop 作业的时候,会将 taskid 放在一个队列里,当任务是 success 后,去比较成功任务的执行时间和落到盘上的 segment 的 version 版本时间。如果 segment version 版本时间比 hadoop index 作业的时间戳要大,就认为已经落盘成功了,这样才会去触发清理缓存,如果没有的话,就直接放到队列里面等待下次轮询,超过一定生命周期会自动清理。
动态限流
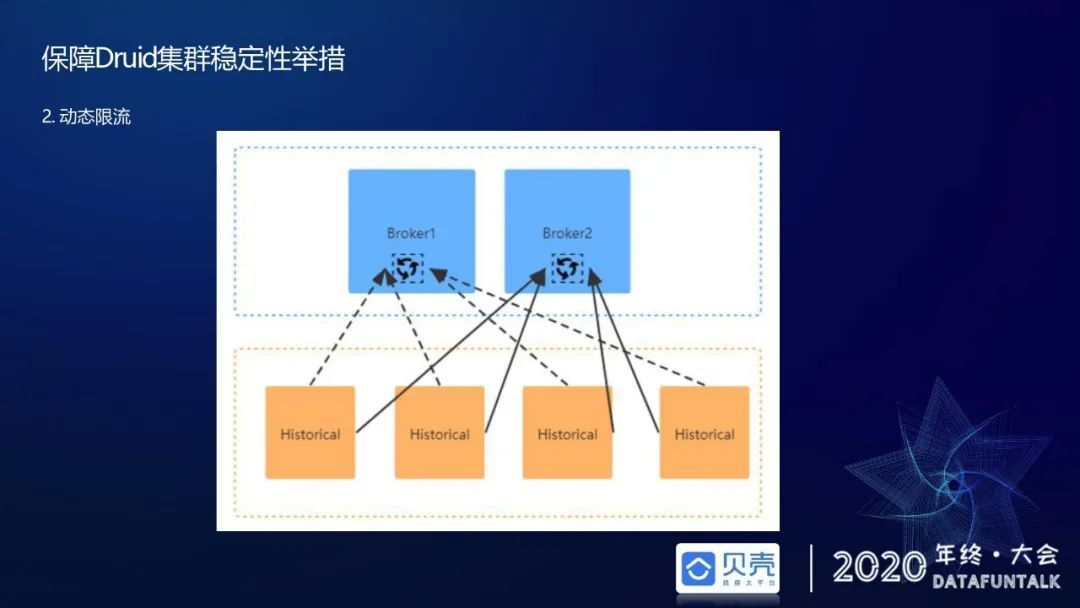
第二个举措是动态限流,原生 Druid 限流策略是在 broker 端限流,比如说集群能扛 400QPS,如果超过 400QPS 就直接拒绝,但是这不足维持我们业务场景下集群规模限流,因为当流量打过来的时候,400QPS 内的查询如果语法复杂度比较高,会直接把 historical 的 CPU 打满,进而影响到其他高优先业务线的查询。我们采用的限流策略是通过 broker 端去收集 historical 的 CPU load 负载信息,如果 historical 的负载信息相对比较高,会根据业务线的重要程度及近五分钟内高热度的查询数据源逐级去限流,也就是说会去保障最高优先级的业务线不被限流,对次要的业务线进行限流。实际应用中有些业务线的查询请求不是人工触发的,而是他们为了展现报表速度更快会用程序去刷非常高的 QPS。像这种只要保证它一次成功就可以。所以我们可以针对这种查询进行限流,在 CPU 负载比较低的时候再去执行该查询请求,保证高优的一级报表产出。
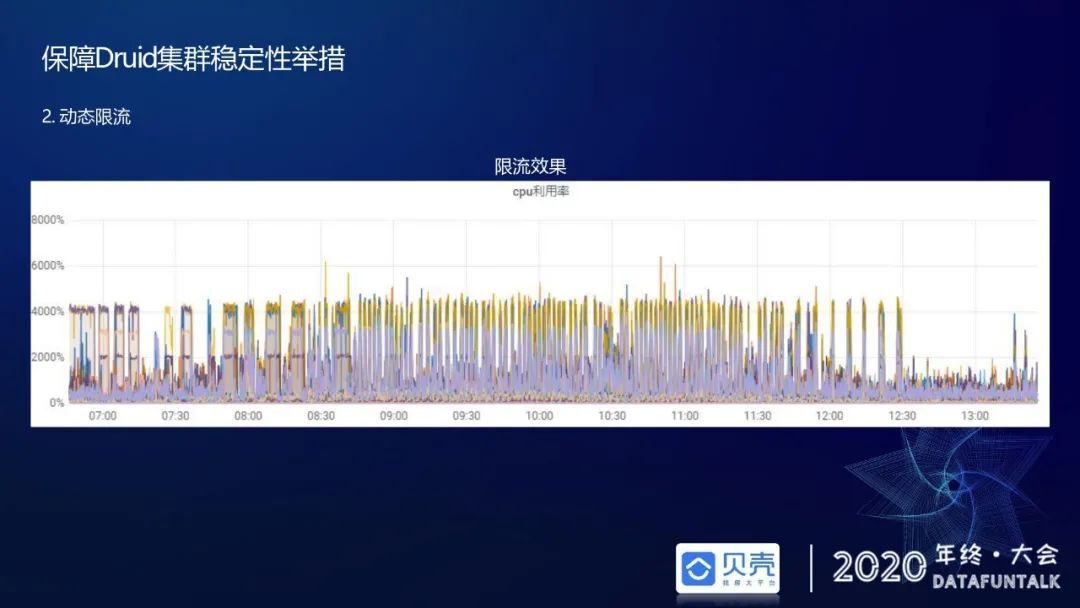
上图反映的是限流后一些效果,高峰期 7 点到 12 点左右会有很多毛刺现象,其实是 CPU 打得比较高的时候会针对某些次要的业务线或者是它使用的一些数据源进行限流,起到一个削峰填谷的作用,保证高优先级的业务线查询不受到较大影响。
深存优化
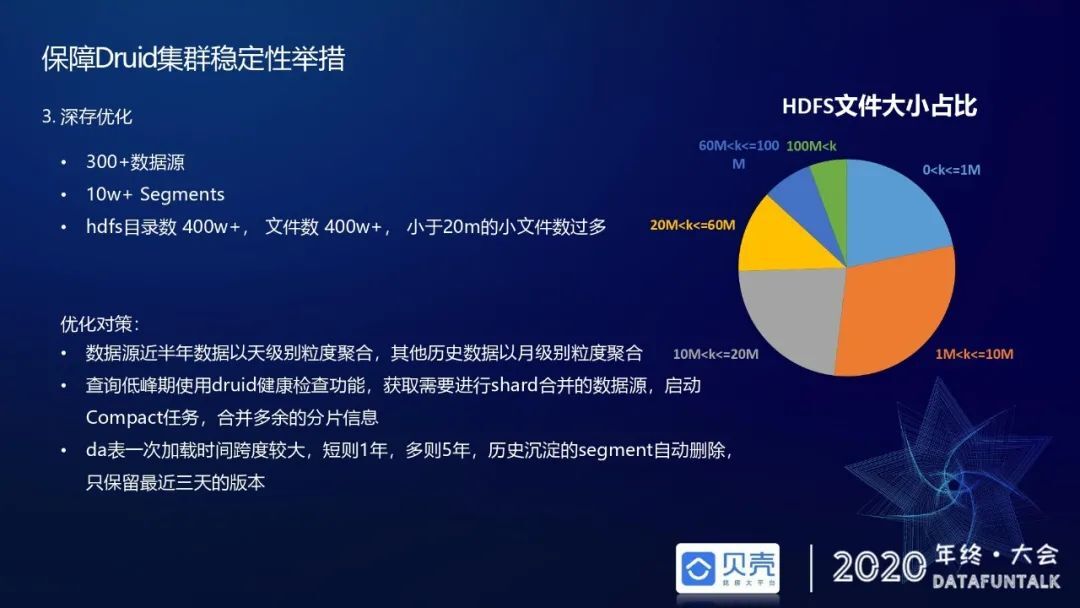
第三个举措是针对深存 HDFS 上的优化。当前整个平台的 Druid 引擎承载了 300 多个数据源,10 万多个 segment,但是在 HDFS 的数目上,有一个特别有趣的现象,就是它的目录数竟然达到 400 万,文件数也达到 400 万,小于 20 兆的小文件非常多,占比在 50%以上。主要原因是有些数据源是全量表,一次作业任务可能刷一年、两年的数据,它的 segment 是按照天进行聚合的,因此当任务例行了一个月或者是一个季度,它在 hdfs 上目录数会特别多。如果目录数太多会影响整个 hdfs namenode 的性能。我们的优化策略主要是三个方面,第一个是近半年的数据用天粒度去聚合,其他历史数据用月粒度的聚合。第二个就是在查询低峰期的时候,用 Druid 的健康检查功能自动获取哪些数据源的分片不合理,我们需要进行 shard 合并,然后在低峰区触发 compact 任务合并多余的分片信息。大家需要注意是合并任务一般不要放在查询高峰期执行,因为会影响整个集群的线程资源,特别是影响 segment 落盘,对查询性能影响比较大。第三个是刚才说的那种全量表加载时间跨度比较大,短则一年,多则五年,历史沉淀的 segment 只保留最近三天的版本。
未来规划

关于未来的规划,主要涉及两个方面:
第一个是实时指标在 Druid 上的深入实践,目前 Druid 主要承载的是离线指标,在实时指标方面,主要是用 Clickhouse 做了 100+的实时指标,数量还比较少,后续会把实时指标业务逐渐往 Druid 上倾斜。因为 Druid 已经实现了实时精确去重能力,相较于 Clickhouse 较高的运维成本,具备了分担实时业务的能力。
第二个是离线导入方式的进一步探索,主要分为三点:
① 针对离线作业类型,之前原生支持的是 index hadoop,计划尝试用 index spark job 作为导入类型,这样会比 map reduse 的导入速度有较大提升。② 尝试使用 index parallel job 这种针对小的数据源导入,如果数据源的数据级别不大,可以不依赖 hadoop 方式,因为分配 map reduce 资源也会比较耗时。
③ 使用 hive 做全局字典,因为在做高基数列精确去重的时候,index generator map 阶段很容易出现 fullGC 的问题,因为不可能无限制地对 map 内存进行调优,所以希望能参照 kylin 4.0 实现用 hive 做字典存储用于精确去重。
嘉宾介绍:
王啸
贝壳找房 | 资深研发工程师
贝壳资深研发工程师,硕士,毕业于北京邮电大学。曾就职于中国电信、百度,多年来深耕大数据领域,从 0 到 1 深度参与百度 adhoc 平台 PINGO、一站式机器学习 JARVIS 平台构建与开发,同时负责过百度商业化产品“鲁班”项目等多个大数据产品上云和私有化交付工作。于 2019 年加入贝壳,目前主要从事大数据 OLAP 查询引擎相关研发工作。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:贝壳基于Druid的OLAP引擎应用实践




