
9月21日,思科公司表示,将以每股 157 美元的价格收购网络安全软件厂商 Splunk。这笔现金交易总值约 280 亿美元(折合约 2047 亿元人民币),成为思科有史以来手笔最大的收购活动。此次收购价格相当于思科公司总市值的 12%左右。
Splunk 以强大的日志分析功能出名,是一款在混合环境中增强企业可观察性、统一安全性和无限自定义应用的数据平台。Splunk 是一家大数据厂商,也是一家安全厂商。该公司基于大数据平台构建了 SIEM 平台,将可观测性数据与安全数据相关联,帮助组织跟上动态威胁形势。另外还有一个产品线是 IT 运维类的可观测性产品,也是云计算里面比较通用的一个场景。
思科 CEO Chuck Robbins 在声明中说道,“双方合兵一处,将共同推动下一代 AI 安全性与可观测性。从威胁检测与响应、再到威胁预测和预防,我们将帮助不同规模的组织机构拥有更高的安全性和弹性。”
Splunk 的收购案刷新了日志分析场景的企业的估值记录。对于这个新闻,安全圈显得特别激动。毕竟中国网络安全上市企业前 100 强,加起来的年营收额也没有超过 1000 亿人民币。而且整个 A 股上市的公司,几个头部的厂商加起来不到 2000 亿人民币的市值。
恰巧腾讯安全在 9 月 20 日发布了一款云原生安全数据湖产品,腾讯安全也是这个领域的一个重磅玩家,这款产品也很对标 Splunk,并且性能可达到 PB 级别的数据秒级查询(详情见:腾讯安全发布云原生安全数据湖)
大数据日志分析这个细分场景为什么“价值千亿”?它有哪些应用前景?我们和腾讯云原生安全日志湖的两位资深专家进行了交流。
采访嘉宾:
洪春华,腾讯安全副总经理洪春华,自 2009 年加入腾讯以来,先后负责腾讯安全后台海量服务开发、安全运营数据平台研发等工作。
Nill,腾讯安全大数据实验室数据湖技术负责人、资深技术专家。
InfoQ:思科在 2019 年的时候也曾想收购数据分析公司 Datadog,那么 Datadog 的日志分析产品跟腾讯安全的日志湖、Splunk 之间有什么相同和不同。
答:Datadog 最早应该是做一些 IT、基础设施、APM 可观测的,后来开始做日志了,希望把一些 log、trace 和 Metrics 做到一起,形成一个统一的分析,但大的方向还是大数据方向的。
他们在日志这块儿其实本身可以说经历了三代:
1. 第一代是分布式,但是是多个租户共享一个集群,租户之间的相互影响会比较大。
2. 第二代在分布式这块儿做了一些优化,存算一体但是可以横向快速扩容。
3. Datadog 去年进行了第三代升级,真正做到了面向云原生,增加了存算分离、读写分离等一些新的特性。
从这个意义层面上来说,其实 Datadog 跟腾讯安全日志湖的目标是一致的。
而 Splunk 很早之前就是从日志出发的,慢慢发展到可观测性和安全场景,相当于是从大数据底层逻辑慢慢推上端应用。Splunk 架构相对比较稳定,已经发展多年了,最近也在往云上推。所以,其实在我们的定位里,Splunk 比较强的是它的可扩展性和应用性,用户可以在上面去定制开发自己的插件和应用,来满足各种各样的需求。
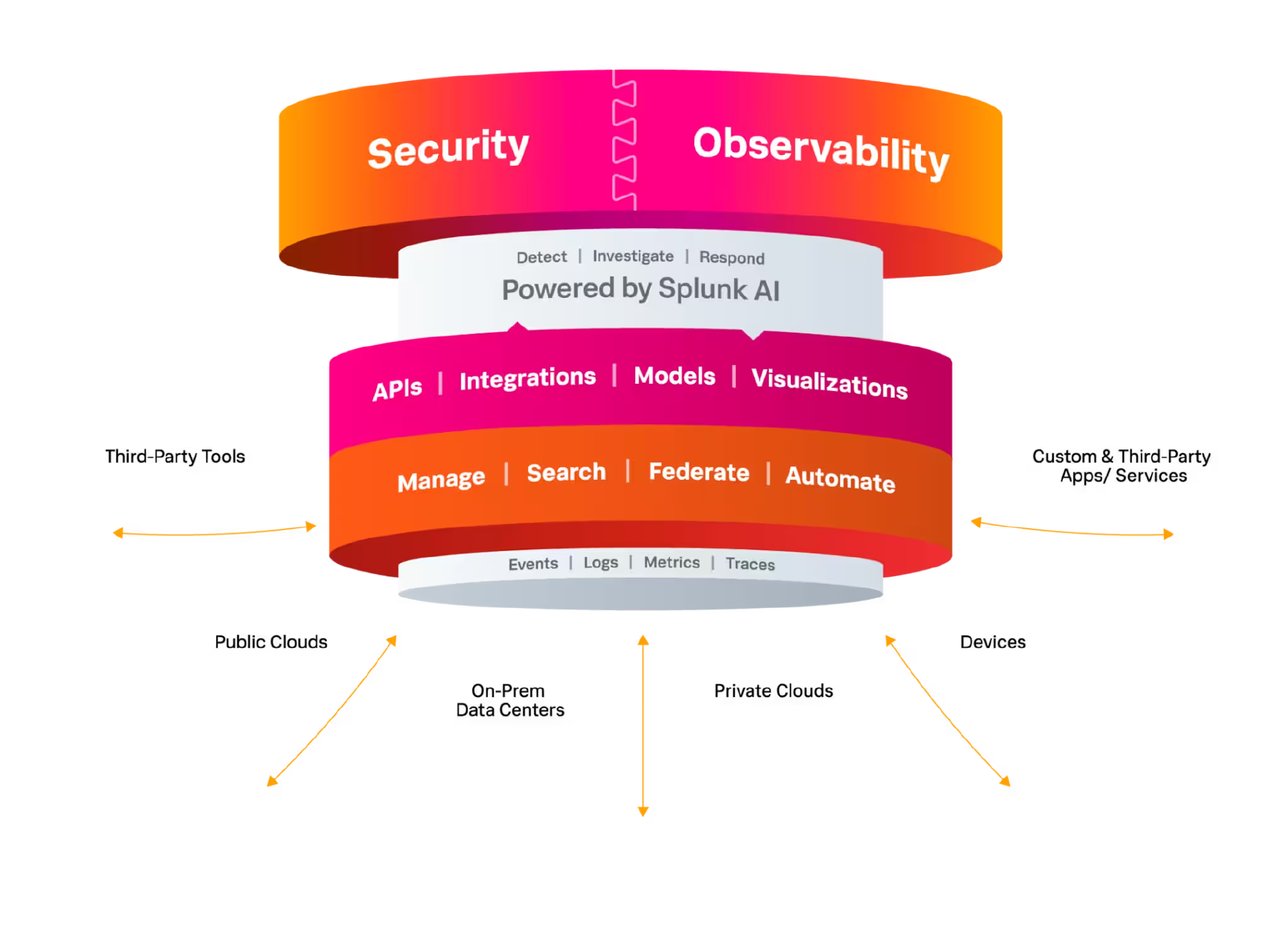
然而,从大数据能力这块儿,不管是 Datadog、Splunk,他们都在逐步升级,但升级其实也是很痛苦的,因为他们对底层架构有依赖,包括协同客户的迁移。尤其是 Datadog,可以看到它面向新的日志架构迁移的时候是非常痛苦的,因为整个架构存算分离这些东西跟原来是完全不一样的,它会背负一定的历史包袱。
对于腾讯安全日志湖的话,我们的优势是没有历史包袱。我们很早就注意到日志这块儿的苗头,比如大概在 2021 年的时候,海外 Scalyr 被安全厂商 SentinelOne 收购,Humio 被安全厂商 CrowdStrike 收购。回头看整个国内的大数据市场(或者说安全市场),传统的安全厂商主要还是依赖于底层 ES、Hadoop 这些,在这上面做安全的分析,但从大数据能力来说,这些都是好几代之前的东西了。
考虑到我们现在已经进入到新的大数据时代了,大数据是各个场景和产品的生产资料,数据的能力是至关重要的。因此我们关注到这个问题之后,就开始投入研发推动腾讯安全日志湖的建设。
其实在大的方向上,我们当时也是对标了海外比较先进的几个商业化的产品,比如 Snowflake,我们在学习它的弹性。Datedog 去年发布新的日志架构时,他们也提到了在弹性和存算分离上,他们也借鉴了 Snowflake 的理念。同时我们也一直在关注 Splunk,在应用性、App 化这块儿,也向它借鉴了不少。所以,回顾起来,我们当时看到在国内整个市场特别是安全市场,没有一款开源的东西能够满足我们自己的需求。基于这些契机,我们就决定研发了自己的安全日志湖。
InfoQ:腾讯安全的云原生数据湖的应用方式是什么?作为独立的产品来对外提供的话,还需要提供哪些功能?
答:我们现在整个路径上面主要分为两条路:
内部被集成。腾讯这几年在讲“被集成”战略,数据湖作为一个底座,会集成到 SOC(安全运营中心)、NDR、零信任,云原生安全产品会集成我们这个数据湖的能力,用来做数据的存储、分析及后续的使用。
外部被集成。我们现在也是发现特别多,包括安全厂商,包括系统集成商或者一些大型集团的信息化子公司,在应用上存在“卡点”。最近因为我们发布了这个数据湖,有友商也找过来,因为他们推了他们的 XDR(可扩展安全检测与响应)产品推出来了以后,已经在客户侧都有落地了,但他们现在很快遇到一个瓶颈,就是在于数据量大的情况下确实算不过来,成本也极其之高,所以看到我们这个方案的时候,也会找过来聊这一块的合作。或者可以这么说,他们现在的方案基本上可以认为在真正的 XDR 方向上是跑不动的,所以现在也会找过来,这就是外部被集成。这块儿战略来看,我们可能会走得更稳健一些,现在看起来需求量挺大。
另外,我们强调云原生数据湖作为“数据底座”,再在上层做 App 化。有了云原生,我们可以做弹性的伸缩,更方便地做隔离的操作。如果横向去看,整个行业来看,如果从安全厂商来看,这个我们肯定是独一份的,安全厂商多数还是在卖盒子,就是硬件服务器这种模式,远远还达不到云计算,更不用说云原生了。在整个云的大盘子里,用在安全里面我们也是独一家的技术落地。在 App 化方面,我们已经做了安全场景的 App,包括情报的回溯、主机安全、零信任、全流量的分析等,这些方面的应用我们现在整个版本都已经准备好了。
InfoQ:我们理解这次收购,一方面就是安全赛道,另一方面就是 AI 驱动的安全这条赛道,思科“借钱都要买”,您可不可以更细化地解释一下为什么安全领域的 AI 驱动是这样一个紧迫的态势?
答:我简单介绍一下,因为今天早上也看到了数据,Splunk 占了思科 12%的市值,对思科来说收购 Splunk 确实是大手笔。思科这几年收购了不少安全方向的公司,包括做网络安全的公司,还有身份安全公司,及云原生安全的公司。在这个过程中,它把组件收购了以后马上发现了一个点,就是它缺少一个“大脑”。
刚刚讲到收购的公司,大家可以把它理解成是数据的生产方。举个例子,相当于家里装了摄像头,我在家门口装了摄像头,我在每个地方装了红外的感应,这些东西确实能够很简单地感受到有没有人入侵、有没有人把你家门给打开,但是很难做到你的一些熟人或者是家里经常来的这些人,或者是绕过你家防护的人,最后他到底有没有侵入到你整个资产的安全?这个时候缺少的是数据沉淀的平台、一个大脑分析的中心节点。所以,思科就着手做这件事情了。
当数据多了以后,能够跟 AI 大模型契合起来。我们都知道要去 AI 的话,就是算力、算法加数据,我相信思科肯定是有算力,也会有算法,但是数据方面其实是需要去沉淀的,如果你的一个数据不能保存下来,不能够留存下来做后续处理,那你比如说就是 30 天的数据,那你的大脑相当于永远只能够判定过去 30 天的事件,而人脑(之所以强大)在于能够把经验整体存下来。这个过程当中,数据的驱动的可能性是非常大的。
所以,它已经走到了这一步,它原来收购的安全组件、采集端已经收到了,再一个就是智能化大模型的契机,它需要有数据沉淀的平台。所以,在这个趋势下,我们认为它应该是会担心赶不上 AI 的末班车。
InfoQ:大模型出来之后,大家看待数据的方式好像也发生了一些变化。如果落地在安全行业,您感觉我们看待数据的方式跟以前有哪些不同,或者说这次思科收购了这家公司之后,行业有哪些明显的反应?
答:安全其实是一个挺悖论的行业,当你没有出现安全事件的时候,老板领导层、投资方很难感觉到安全的价值。但是如果说你出了安全事件以后,他依然会感觉你的安全投入在哪儿去了?我们看待数据的角度是一样的,原来大家看到数据就是你有没有直接检测出来入侵的行为,将这些入侵的行为处置,只要保存下来数据,通常会只保存的是结果,不关心过程。所以,包括我们的很多法律法规还是要求六个月只是存储一些基本的告警信息就够了,这个过程是这样的。
现在去看数据的时候,就不仅仅只是存六个月来满足合规,而是数据已经是生产的要素了,当这些数据积累下来,能不能帮助安全运维人员、专家更好更快地发现问题、解决问题,从而提升效率。
在腾讯内部,我们经常讲安全团队是能够帮助业务团队去成功的。为什么呢?因为我们在安全数据里面能够挖掘到不少关于业务本身的问题,能够帮助业务去成长,类似于说某一个漏洞它影响了这个业务,甚至是说某一群客户、某一个区域的客户对这块儿业务感兴趣的程度,从而帮助业务成长。所以,我的理解,原来我们只是为了满足一个合规,只要存一个结果,到现在它是一个生产要素,它是用来生产更多的高价值内容和结果,用数据喂养大模型,能够帮助业务更快地提升转型。
在这个过程中,其实像思科收购 Splunk 也是一个典型的案例,因为 Splunk 号称能够达到 PB 级存储,在这个存储过程当中成本能做到尽可能低。我的理解,接下来会有非常多的大模型在安全行业落地,在这个过程中大家对数据(特别是原始数据)的需求会急剧提升。
InfoQ:您刚提到 Splunk 能处理 PB 级的数据,同时成本能做到很低,看报道说腾讯云原生数据湖也能做到 PB 级别的数据秒级查询,那腾讯这边是怎么平衡成本问题的呢?
答:之前我们也做了分享。

我们做的数据湖在降本这块儿做了不少工作,几个原因:
底层技术层面,架构就是面向存算分离的。在传统存算一体的架构下,进行扩容的话,整个资源都需要扩容,在实现存算分离之后,面向新的云原生架构,可以按 CPU 扩容、按存储扩容,这样的话在扩容的时候就会避免一些浪费。
之前提到弹性性能,传统的在安全领域做分析的时候,为了保证安全的可靠性,需要预留大量的资源。举个简单的例子,比如说像事件调查,可能是“偶尔”才需要,比如说一天或者是一周发生几次。但为了保证这个安全事件调查的可靠性、可用性,企业可能需要提前预留很多资源。其实现在通过我们弹性的能力,当你在需要进行情报回扫或者是事件调查的时候,我可以快速拉起你所需要的资源,帮你快速完成任务分析,完成之后释放这批资源,从这个层面会减少一些资源的损耗和成本的降低。
更底层的我们在一些技术实现上,比如说像有无索引架构,在这种情况下大家已有的解决方案需要存储大量的索引,这些索引本身是一些额外的开销,大部分的索引之前有篇文章也分析过,像传统的索引 80%在实际中是不会用到的,但是这些东西占用了大量的存储和内存,这个成本和代价都是非常高的。我们在现在的架构中也采用无索引的架构,来避免成本。
所以,整体来看,一个是从面向云原生的弹性架构上,另外一个是在底层架构的实现上,对资源的损耗做了很大的优化和提升。
InfoQ:现在国内一些安全厂家发了安全 GPT,您觉得大模型会改变安全日志这个领域吗?或者您怎么看待这件事情?
答:目前从市面上看到大家都在用 GPT 做上层应用,但这本身也是基于日志来做的。所以,基于日志本身的存储和分析上,大模型可能是没有太大的帮助,它节约的成本更多是安全专家运营的成本,传统的安全专家需要拉数据做分析,需要分析很久,现在通过 GPT 或者是通过基本的机器学习、API、自动编排的能力,把分析的链路缩短,从而提升效率。但 GPT 依赖于丰富的数据,需要存储更多的数据。
另外我们也是在朝着这个方向做,但过程中有以下前提是一定要解决的:
1. 通用大模型能力的考验,包括类似于混元的能力。
2. 通用大模型构建行业大模型,就是安全大模型,需要有安全的数据,原始数据需要数据湖的能力支撑整个数据的处理和使用。
我们一直觉得还是要把底座夯实得更好。现在整个人口红利、模式创新都已经到达瓶颈了,我们需要做些技术创新,所以腾讯推出了安全数据湖产品,这块儿是能够很好地帮助安全人员解决在应用 GPT 过程当中的难题。
总之,我们更关心底层能力。首先说数据,在大模型上我们怎么把安全数据梳理好、整理好,能够提供高性能的分析。整个安全数据湖未来也会走商业化的能力,因为本身我们的架构是完全兼容的,我们在做这方面的探索。这样的话,就把数据进入到湖里之后,大模型去转化的时候,又往前推进了一步。然后就是整个大模型底层模型的能力,腾讯混元底层能力一直在打磨。还有一块就是 GPT 交互能力,包括对于自然语言的识别能力,包括对上下文的对话能力,在技术方面我们安全团队也一直在打磨和探索。
在目前的地缘政治和国际形势的情况下,有些我们该练的内功还是要提前布局好,特别是对腾讯这种公司,确实还是需要尽到一定的职责解决卡脖子方面的像中间件以及其他软件的问题。




