
很多人都觉得 2025 年会是“AI 智能体元年”,也就是基于 OpenAI、Anthropic、Google 和 DeepSeek 等机构提供的大语言模型,打造专注特定任务的智能体系统。
但是,最近在社交平台 X 上有个调查显示,现在大部分 Agent 都在“玩票”阶段,还没真正走出实验室,普遍滞留在“企业试点”的状态中。
不过,李飞飞所在的一支团队或许即将带来改变:他们与西北大学、微软、斯坦福大学和华盛顿大学的研究人员合作,最近推出了一套名为 RAGEN 的新系统。这个系统旨在提升人工智能在真实世界,尤其是在企业应用中的稳定性和可靠性。

据悉,该项目由前 DeepSeek 研究员、现就读于西北大学计算机科学博士的王子涵主导。王子涵研究聚焦于大语言模型(Foundation Models)的自主性、效率以及长文本理解。此前,王子涵曾在 DeepSeek 担任研究员,并参与了 DeepSeek-V2 等重要项目。

推理智能体训练框架已开源
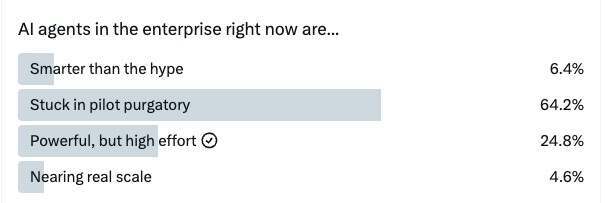
与解题或代码生成等静态任务不同,RAGEN 聚焦在多轮交互场景中训练智能体,要求它们能在不确定性中进行推理、记忆历史对话并灵活应对变化。
RAGEN 构建于一个名为 StarPO(State-Thinking-Actions-Reward Policy Optimization,即“状态-思维-动作-奖励 策略优化”)的定制强化学习框架之上,核心思想是让 LLM 通过“经验”学习而非“死记硬背”。系统重点在于训练智能体完成完整的决策路径,而不是仅仅优化某一次回答。
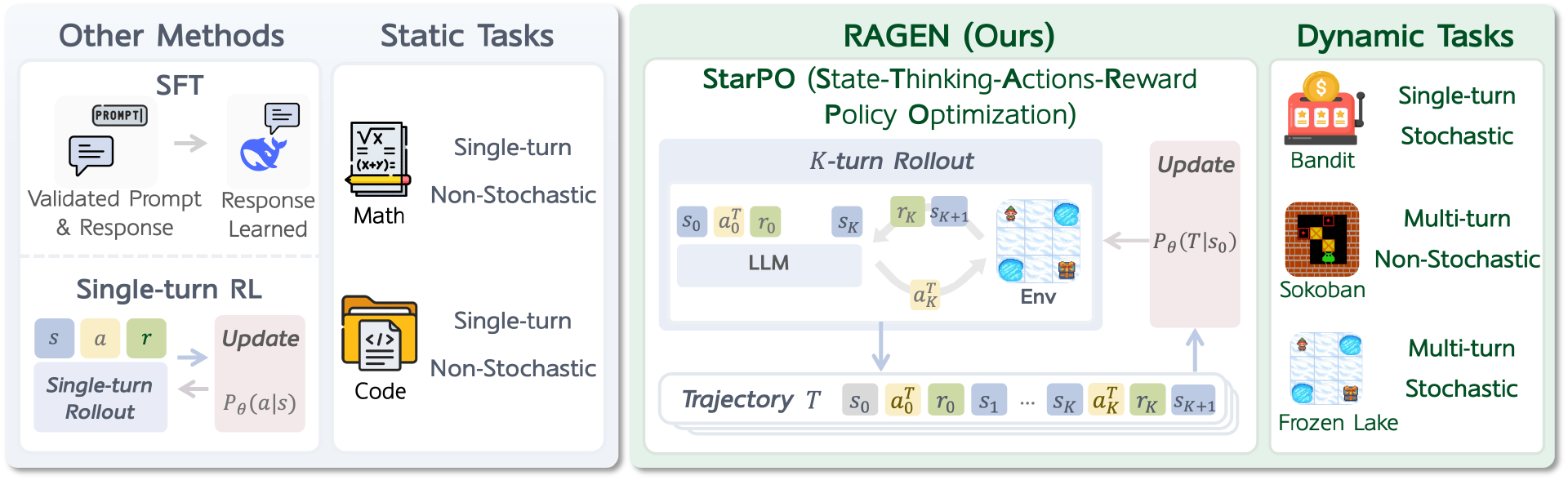
StarPO 包括两个交替进行的阶段:在 rollout 阶段,LLM 基于推理生成完整的交互序列;而在 update 阶段,模型根据归一化后的累计奖励进行参数更新。相比传统的策略优化方法,这种设计让训练过程更加稳定,学习结果也更易于解释。
研究团队在实验中使用了阿里巴巴开源的 Qwen 系列模型(包括 Qwen 1.5 和 Qwen 2.5)作为基础语言模型进行微调。这些模型具有开放权重、指令执行能力强等优点,有助于确保实验结果的可复现性,并支持在符号任务上的一致性对比。
这一系统为有志于开发更具“思考力、规划能力和自我进化能力”的 AI 智能体提供了坚实基础。RAGEN 不只是关注任务是否完成,更重视模型是否真正经历了学习与推理过程。随着 AI 技术朝着更高程度的自主性发展,像 RAGEN 这样的项目正在帮助我们理解:如何训练出不仅依赖数据、还能从自身行为后果中学习的模型。
RAGEN 及其配套的 StarPO 和 StarPO-S 框架现已开源,项目托管于 GitHub 上,采用的是 MIT 协议。
GitHub 地址:https://github.com/RAGEN-AI/RAGEN
Agent 强化学习训练如何才能不崩溃?
王子涵在一条广泛传播的 X 贴文中指出了训练中的核心难题:为什么 RL(强化学习)训练总是会“崩”?
团队发现,训练初期的智能体通常能生成结构清晰、逻辑合理的回答,但随着训练推进,强化学习系统更倾向于奖励“捷径式”回答,最终导致模型反复输出相似内容、推理能力逐渐退化。这种现象被他们称为“回声陷阱(Echo Trap)”。
这种退化通常由反馈回路驱动:某些回答在早期获得高奖励,从而被模型频繁复制使用,抑制了探索其他可能性的动机。
但这种问题有明确的迹象可循:比如奖励波动剧烈、梯度异常增大、推理痕迹逐渐消失等。
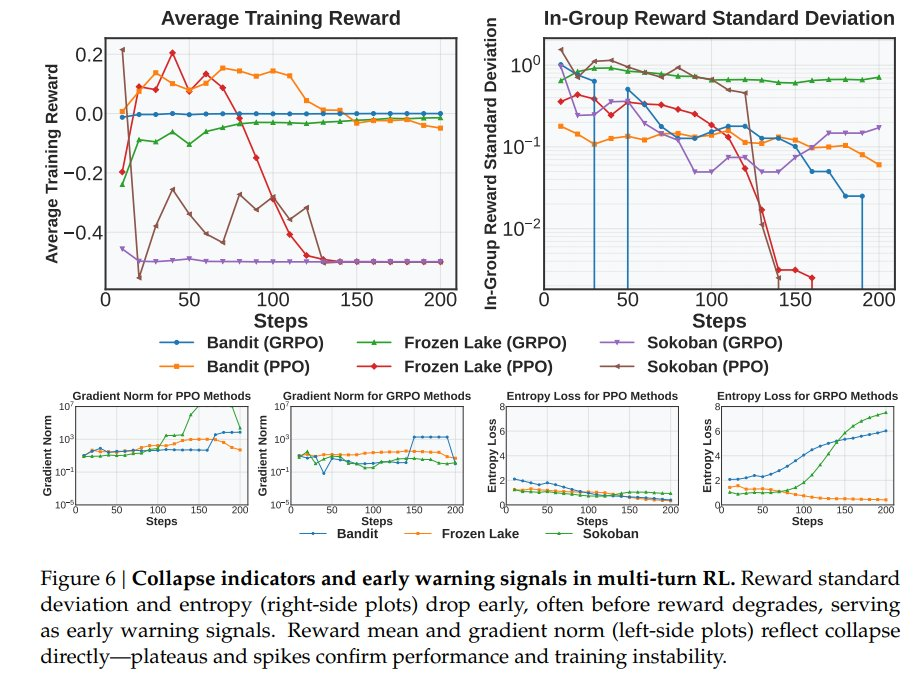
为了在可控环境中系统性研究智能体的行为,RAGEN 设计了三个符号化测试环境,用于评估智能体的决策能力:
Bandit(老虎机):一个单轮的随机任务,用于测试智能体在不确定条件下的符号化风险-收益推理能力;
Sokoban(推箱子):一个多轮、确定性的益智任务,涉及不可逆决策,考验智能体的规划能力;
Frozen Lake(冰湖):一个具有随机性的多轮任务,要求智能体具备适应性和前瞻性思考能力。
这些测试环境的共同特点是:尽量剥离现实世界中的先验知识干扰,让智能体仅依赖训练中学到的策略进行决策。

以 Bandit 为例,智能体会被告知“龙”和“凤凰”代表不同的奖励分布,但不会直接获得概率信息。它必须进行类比式推理,比如把“龙”理解为“力量”、将“凤凰”理解为“希望”,并据此预测潜在结果。这类设定鼓励模型生成可解释、具备抽象类比能力的推理路径。
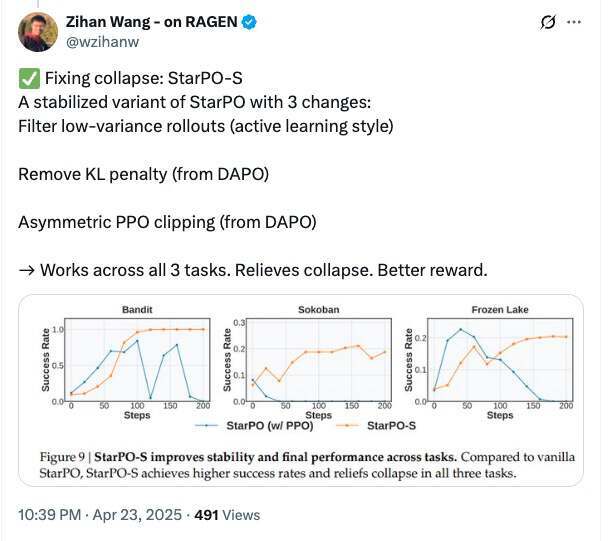
为解决训练过程中模型容易“崩溃”的问题,研究团队在原有 StarPO 框架的基础上提出了增强版本 StarPO-S,引入了三项关键机制来提升训练稳定性:
基于不确定性的 rollout 筛选:优先选用那些智能体对结果感到“犹豫”的交互序列,提升训练数据的有效性;
移除 KL 惩罚项:放宽模型对初始策略的约束,让它更自由地探索新的行为方式;
非对称 PPO 剪裁:对高奖励路径加大学习力度,相对降低对低奖励路径的关注,从而提升整体学习效率。
这些策略显著减缓甚至避免了训练过程中的崩溃问题,同时在所有三个任务环境中均带来了更好的表现。正如王子涵所说:“StarPO-S 在三个任务上都表现不错,不仅解决了训练崩溃问题,奖励水平也更高。”
落地企业应用,还有哪些现实难题?
强化学习的效果不仅依赖模型本身的结构,还与智能体在训练过程中所生成的数据质量密切相关。团队总结了三个对训练效果影响最大的关键因素:
任务多样性:让模型接触更多样的起始情境,有助于提升泛化能力;
交互粒度:支持每轮多个动作,能够带来更细致的计划和更丰富的策略;
rollout 新鲜度:确保训练数据与当前模型策略保持一致,避免旧策略“过时”的学习信号干扰训练。
这三个维度共同提升了训练过程的稳定性与实用性。
尽管显式推理在 Bandit 这类简单的单轮任务中表现出色,但在多轮任务的训练中,推理能力往往会随着训练进度逐渐减弱甚至消失。即使采用了结构化提示词或
这暴露出当前奖励机制的一大短板:它更多聚焦于“结果对不对”,而忽视了“过程好不好”。
为此,团队尝试通过格式惩罚等方式,引导模型生成结构更清晰的推理过程,但他们也指出,要真正解决这个问题,仍需进一步优化奖励设计逻辑。
尽管 RAGEN 论文提出了清晰的技术方向,但要真正将其应用到真实的企业环境中,仍然存在不少实际的挑战。例如,RAGEN 目前主要处理的是高度抽象的符号类问题。那么,它的方法是否能顺利应用到像发票处理、客户支持这类真实的业务流程中呢?企业是否需要为每个具体的应用场景重新设计任务环境和奖励机制?
另一个核心问题是可扩展性。即便引入了 StarPO-S 等稳定性优化机制,论文仍坦承:当任务长度足够长时,模型训练最终仍可能崩溃。这不禁让人反思,是否存在某种理论或工程路径,能让智能体在开放式、持续演进的任务中始终维持推理能力?
RAGEN 的意义,实际远不止于技术上的突破。它不仅是对强化学习技术的一次重要尝试,更标志着我们向“具备自主推理能力的智能体”的目标迈进了一步。虽然现在还不能确定它是否会成为未来企业人工智能技术的重要组成部分,但它在智能体学习机制上的新颖见解,已经悄然改变着我们对大型模型训练边界的理解和想象。
参考链接:
https://x.com/wzihanw/status/1915052871474712858




