
AI 算法在视频娱乐行业得到了广泛应用,在处理视频数据过程中最大瓶颈之一是视频抽帧延时,抽帧延时往往占据了整体服务的大部分时间。此外,不同的 AI 算法应用于不同业务时,对视频抽帧需求也不同。
对此,本文介绍一种高效通用的抽帧工具在 AI 视频推理服务中的应用,可以降低服务整体处理延时;并针对 AI 算法对视频抽帧的不同需求,在不同的使用场景下,提供通用化的功能。
AI 算法已经广泛应用于 AI 视频推理服务中,目前爱奇艺 AI 服务中与视频数据相关的服务多达数百个,每个服务又由多个算法组成。这些 AI 算法对输入视频数据的需求不同,部署硬件平台也不同,导致 AI 算法在视频推理服务面临多方面的挑战。
例如:以用户上传的短视频为主的视频审核业务而言,其主要挑战为:为了提升用户体验,需要在很短的时间内审核完成;用户上传的视频编码格式多样,需要视频抽帧工具能够支持不同的编码格;视频审核业务需要对低俗、血腥、暴力、政治、儿童邪典等多方面进行审核,有的算法部署在 GPU 上,有的算法部署在 CPU 上,这需要抽帧工具无论是在 CPU 上还是在 GPU 上都能够以很短的延时处理。
而以长视频为主的词生产、转场点、行为识别、视频插帧等业务而言,其主要挑战为:抽帧工具需要确保抽帧的结果精准,即抽取的视频帧以及其时间戳与原视频完全吻合,此外长视频抽帧在高吞吐来提升资源利用率的使用场景下,也希望尽快处理完成,来提升不同业务线同学的工作效率。
一、整体服务延时大、硬件资源利用率低
由于视频往往数据量较大,以 1 小时、25FPS、1080P 的视频为例,全抽帧后的图像总数将达到 9 万张,单个服务整体耗时很长,严重影响服务生产效率,导致整个业务效率低下。AI 视频推理服务环节主要由几下几方面组成:下载、抽帧、预处理、AI 算法处理、后处理、上传。其中视频抽帧和 AI 算法推理占据了大部分时间。例如:1 小时、H.264、1080P 视频使用 4 核 6148 CPU 抽帧存 JPEG 图像需要 760 秒。
当 AI 视频推理在预处理或者抽帧时使用 CPU 资源计算时,GPU 资源没有被充分使用;或者单个算法模型对 GPU 硬件资源消耗较少,都有可能导致整体 GPU 资源利用率偏低。
二、算法需求差异较大、部署硬件资源不同
爱奇艺 AI 算法在视频图像领域蓬勃发展,不同的 AI 算法用在不同的业务时,对抽帧需求也不一致:每秒抽取的帧数,抽帧时是否需要保存不同格式的图像,抽帧时 RGB 数据是否直接存放内存或显存,对特定时间段抽帧,只对关键帧抽帧,抽帧时缩放、裁剪图像,获取图像时间戳等等。不同的需求导致很难通过某一套现有的方案来满足所有需求。
方案调研
目前视频解码的硬件平台主要有 CPU、GPU、FPGA 以及专业的编解码芯片,其中 FPGA 对 AI 算法支持不太完善,而专业解码芯片则功能太单一。因此较为常见的方案采用 CPU 和 GPU 作为服务侧常用的编解码硬件。CPU 解码最常用的工具是使用 FFmpeg,该工具能够较好的满足目前 AI 算法不同的抽帧需求。下文将分别从 CPU 与 GPU 两方面说明。
一、CPU 抽帧应用于 AI 算法的通用方案
目前在 CPU 上使用 FFmpeg 抽帧运用于 AI 算法最常见的方法主要有以下两种:
1.FFmpeg 将视频抽帧保存为图像后,AI 算法调用:最传统的做法将视频下载后,使用 FFmpeg 解码并保存图像,AI 算法读取图像,预处理后进行推理,后处理完成后将结果上传。这种传统的方式导致整体服务处理增加一些没必要的时间开销,具有主要的两个缺陷:
一、视频抽帧和算法推理处理延时太大,每个模块均为阻塞方式,需要前置步骤完全处理完成后,后续步骤才能够开始处理;
二、一张 1080P 的 RGB 无损原图保存需要 5MB 存储空间,1 小时、1080P 视频全部抽帧并保存原图将需要 450G 的存储空间,这将带来巨大的存储压力。
为此视频抽帧往往保存 JPEG 格式图像,JPEG 图像具有极高的压缩率,1 张 1080P 的 JPEG 图像往往只需要 0.1MB 存储空间,相比保存原图能够节约数十倍存储空间。但其缺陷为有损压缩,即 JPEG 保存后的图像读取后与原图相比存在一定的信息丢失,有可能导致 AI 算法推理时精度降低。此外 AI 算法读取图像时又需要将 JPEG 格式图像解码为 YUV 格式,并将 YUV 格式图像转换为算法需要的 RGB 格式。由此可见,抽帧保存为 JPEG 图像提供给算法使用实为下策,然而有的服务中又确实需要将图像完全保存,故该方案还是在一些服务中被使用。

方案一 CPU 抽帧落盘
2.鉴于上述方案的缺陷,目前 CPU 上使用 FFmpeg 抽帧提供给 AI 算法使用比较好的方案为:将视频解码 YUV 格式后,颜色空间转换为 RGB 格式,保存在内存中;AI 算法直接读取内存中的 RGB 图像数据,并将每个环节进行流水线处理,使得每个环节都能够异步处理。其框架图为:

方案二 CPU 抽帧不落盘
方案二相比方案一在延时上有较大的减少,且不再需要有损压缩图像,能够最大程度保留图像真实信息,避免 AI 算法精度降低。然而现今视频往往分辨率很高,对 1080P、4K 的视频抽帧时,即使是不落盘方式(不落盘:视频解码后,YUV 格式转 RGB 数据,直接保存在内存或者显存中),抽帧的延时都可能大于 AI 算法处理时长。尤其体现在 AI 算法经过图优化、算子优化以及定点量化后,整体服务延时大的主要瓶颈体现在使用 CPU 抽帧耗时长。使用不落盘方式 1 小时 H.264 1080P 视频在 CPU 6148 需要 350 秒,而使用落盘方式(落盘:视频解码为 YUV 格式,将解码的 YUV 格式图像重新编码后保存在非易失存储上(如硬盘、SSD),通常保存为 JPEG 格式。),抽帧则需要 760 秒。此外,爱奇艺作为视频娱乐公司,AI 算法在视频处理处理时,往往需要准确的时间戳来标定抽帧的图像精确对应的视频位置,而开源的 FFmpeg 抽帧时无法直接提供准确的时间戳。
二、GPU 抽帧应用于 AI 算法的通用方案
NVIDIA 提供的 GPU 抽帧相比 CPU 上使用 FFmpeg 抽帧能够大幅提升速度,在 GPU V100 上,H.264、1080P 视频可达 500 FPS 以上,在 GPU T4 更是能够达到 1000 FPS 以上。故 GPU 抽帧相比 CPU 抽帧延时更小,其存在的主要缺陷为:
1. 相比 FFmpeg 提供的功能太少,没有 1 秒抽 n 帧、只对关键帧抽帧,解码后保存 JPEG 图像等功能;
2. 解码仅支持部分格式,无法满足所有情况;
3. GPU 解码后的图像依然存放在显卡上,AI 算法推理前往往需要对图像进行预处理,而视频 GPU 抽帧后的预处理仍在 CPU 计算上,存在数据传输耗时较大,导致不必要延时,这尤其体现在需要对视频每一帧的数据都需要处理的情形,两次 CPU-GPU 之间的数据拷贝耗时较大,无法完全在计算延时中掩盖。
最佳方式是将预处理使用 CUDA 函数直接在 GPU 上计算,然而服务太多,对每个算法的预处理进行 CUDA 优化需要消耗较多人力,使得该方案无法推广到所有服务。
4. 当前 AI 算法大多数由 Python 编写,也给直接使用 GPU 抽帧带来困难,虽然 NVIDIA 提供了相关工具来使得用 Python 调用 GPU 抽帧成为可能,但对安装环境有较多限制,有时与 AI 算法依赖环境冲突,使其无法满足大多数 AI 服务的要求。

方案 3 GPU 抽帧不落盘
通用高效抽帧在视频推理中的方案实施
基于以上的调研,本节将会详细阐述在 CPU 和 GPU 上的抽帧的优化和功能完善,增加 Python 接口,以及整体流程中抽帧工具和 AI 算法的流水线优化。
1. CPU 抽帧的完善与优化
(1)准确获取抽帧图像时间戳:视频中的时间戳有显示时间戳 PTS 和解码时间戳 DTS,DTS 主要用来标识待解码视频帧送入解码器解码的顺序,而 PTS 指的是图像帧在视频中实际显示的时间点位,如果视频中没有 B 帧时,DTS 和 PTS 顺序一样,但当时视频中存在 B、P 帧时,则 DTS 和 PTS 的顺序不一样。AI 服务中,使用的时间戳为 PTS,对应视频帧在实际播放时的时间点位。抽帧的图像通过 AI 算法推理得到的结果需要与视频中的 PTS 时间点位完全一致,这就严格要求抽帧时获取的 PTS 必须完全准确。然而 FFmpeg 抽帧时无法直接返回该帧的 PTS,本方案通过优化 FFMPEG 输出控制逻辑,来保证抽帧获取的 PTS 与原视频流中的点位一致。
(2)CPU 抽帧在不落盘与落盘情况下加速优化:本方案采用资源换速度的方法,对于落盘的加速优化,使用多线程分别抽取视频中的部分片段。而不落盘的视频抽帧,使用多线程分片抽帧时,需要保证将抽帧结果顺序提供给算法使用,每个子线程负责多个小时间段,每个子线程抽取后获取的图像使用时间戳做顺序校准。确保每个子线程依次提供的数据能够与单线程抽取结果完全一致。

方案 4 CPU 抽帧不落盘抽帧优化
2. GPU 抽帧的完善与优化
(1)GPU 抽帧功能增加与完善:在与算法和业务沟通需求后,本方案增加了 GPU 对视频单位时间内抽 n 帧,对视频关键帧抽帧,对视频的某个时间段抽帧,准确获取时间戳,抽帧时可保存 JPEG 等图像格式,以及其它一些功能。鉴于视频编码为 YUV 格式的图像后,保存 JPEG 图像时需要对 YUV 格式图像进行编码,编码使用 CPU 处理延时较大。为了能够减少存 JPEG 延时,本方案通过编写 CUDA 函数实现 YUV 格式图像编码为 JPEG 格式。在 GPU V100 上,峰值性能可达 3000 FPS。
(2)对抽帧后图像直接使用 GPU 显存情形的优化:一些重要的服务需要及时的返回结果,业务希望能够最大限度的减少延时。对此,本方案将视频解码的 YUV 数据,在 GPU 上调用 CUDA core 实现 YUV 转 RGB 以及其他的所有预处理函数,确保整体处理尽量减少 CPU 与 GPU 之间的数据拷贝。
(3)增加抽帧后的图像回传至内存,AI 算法直接使用 Python 调用 GPU 抽帧、CUDA 函数功能:考虑到当前 AI 算法大多基于 Python 开发,开发人员难以完全对所有的 AI 算法进行改造。为了基于 Python 开发的 AI 算法能够使用 GPU 抽帧(C++开发),本方案采用 Pybind11,使得 C++和 Python 很方便的混合调用。此外,对于某些处理延时很大的服务,也希望能够在 Python 端调用 CUDA 函数来实现预处理加速,对此我们提供了上述相同的策略。
图五为 GPU 抽帧整体框架图,视频数据以及抽帧需求信息,通过 Pybind11 传递给 GPU 抽帧模块使用。cuda 初始化模块仅在主线程中初始化 CUDA 上下文一次,子线程解码时将 cuda 上下文压栈来避免每个视频抽帧时需要重新初始化。视频帧解码后,通过后续处理模块完成颜色空间转换以及 AI 算法对解码后的图像处理需求。如果算法需要将预处理、后处理放在 GPU 上处理,则调用对应的 CUDA 函数否则直接将图像数据输出给 AI 算法使用。此外,GPU 抽帧和 AI 算法推理并行处理,其他环节为异步执行,能够最大层度减少延时。
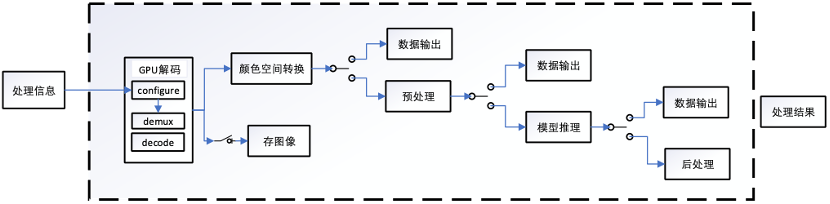
方案 5 GPU 抽帧优化框架图
3. 整体流程的优化
GPU 抽帧相比 CPU 抽帧延时更小,但只支持 H.264、H265、VPx 等常用格式,对于 H263 等目前较少使用的编码格式并没有提供支持,客户上传的视频编码格式无法确定 GPU 解码是否支持。本方案使用 ffprobe 获取视频的编码格式后,来判断该视频使用 GPU 或者 CPU 进行抽帧解码。此外考虑到输入数据或许并非视频,AI 算法存在 bug 等情况,本方案进行了详细的异常处理和日志管理。
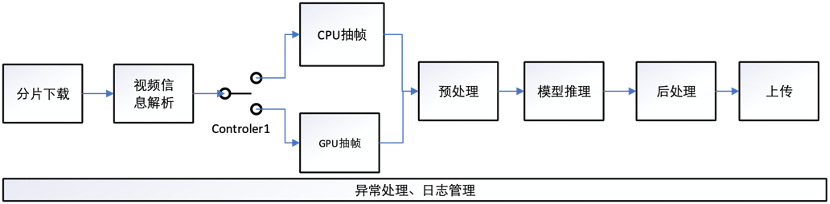
总结
为了针对不同应用场景和需求,本方案针对不同的业务需求从不同角度进行了优化:在公司短视频“先发后审”业务上,满足了业务方对 5 分钟视频 30 秒内审核完成的需求。其中以低俗调性检测子服务为例,相对改造之前使用 FFmpeg 抽帧保存为图像后处理性能提升 10 倍。长视频“台词生成”业务中,优化前方案需要在 CPU 上抽帧,抽帧完成后上传到云端再下载到 GPU 容器上执行算法推理,优化后提升 10.6 倍。在长视频“转场点分析”业务上,鉴于算法输入需要全抽帧的 JPEG 图像,性能整体虽然也能提升 2 倍,但是相比不落盘方案,性能提升较少。可见要使整体服务处理延时最小化,最佳方式是解码后的数据不落盘直接存放在显存中提供给 AI 算法使用。
随着 AI 视频推理服务在爱奇艺各个业务线的广泛使用, AI 服务团队除了需要提供丰富的 AI 算法模型,从节约硬件资源、提升工作效率、以及满足某些业务延时敏感的角度考量,都需要尽可能的减少服务处理时间。为此,后续还需改造原线上延时较大的服务,完善抽帧工具,在算法的预处理、后处理提供加速函数库,AI 算法模型深入优化等多个方面深入展开工作。
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)




