
本文是实用生成式人工智能应用系列文章的一部分。在这一系列文章里,我们呈现了来自顶尖生成式人工智能实践者的现实世界解决方案和实操经验。
Meta 在 2023 年初发布了他们的第一个开源、开放权重的大语言模型——LLaMA 的第一个版本。这个模型性能与 GPT-3 和 PaLM 等模型相当,但与这些模型不同的是,Meta 允许用户下载 LLaMA 的权重。2023 年 7 月,LLaMA 很快被 Llama 2 取代。这个模型也是开源的,并且比第一代模型具有更高的准确性和更长的上下文长度。
2024 年 4 月 19 日,LLM 开源社区再次迎来狂欢。在 Llama 2 发布九个月后,Meta 发布了 Llama 3 的官方版本。Llama 3 包含 8 亿参数(Llama3-8B)和 70 亿参数(Llama3-70B)两种规模的模型,每个版本都有基础版和指令调优版,且均已开源。它们也免费开放给商业用途,前提是月活跃用户数不超过 7 亿。
1 Llama2-7B 和 Llama3-8B 之间的差异
总体而言,Llama 2 和 Llama 3 在模型架构上几乎没有明显的差异。这对已有的 Llama 2 用户来说是个好消息,因为使用 Llama 2 模型的应用程序可以无缝迁移到 Llama 3。
要深入理解细节,最好的方式是深入研究源代码。在 Meta 的 Llama 3 和 Llama 2 官方代码库中,以 8B 和 7B 为例,你会发现 model.py 文件几乎是一样的。
Llama 3 引入了更复杂的嵌入技术——VocabParallelEmbedding,它优化了模型并行分片中的词汇分布。
两者都采用了“仅解码器”架构,并以 “SwiGLU” 作为激活函数,集成了“旋转嵌入(RoPE)” 和“分组查询注意力(GQA)”机制进行位置编码,以提高序列位置感知能力,这是模型对自然语言理解能力的一个重要部分。此外,在分词和模型初始化方面也有一些细微的差异。
通过比较 HuggingFace 仓库中的 “config.json” 文件,我们可以发现两个模型都是 “LlamaForCausalLM” 架构,这说明模型结构保持不变。主要差异在于维度配置,参数从 7B 增加到 8B ,文件大小增加了 2464M。
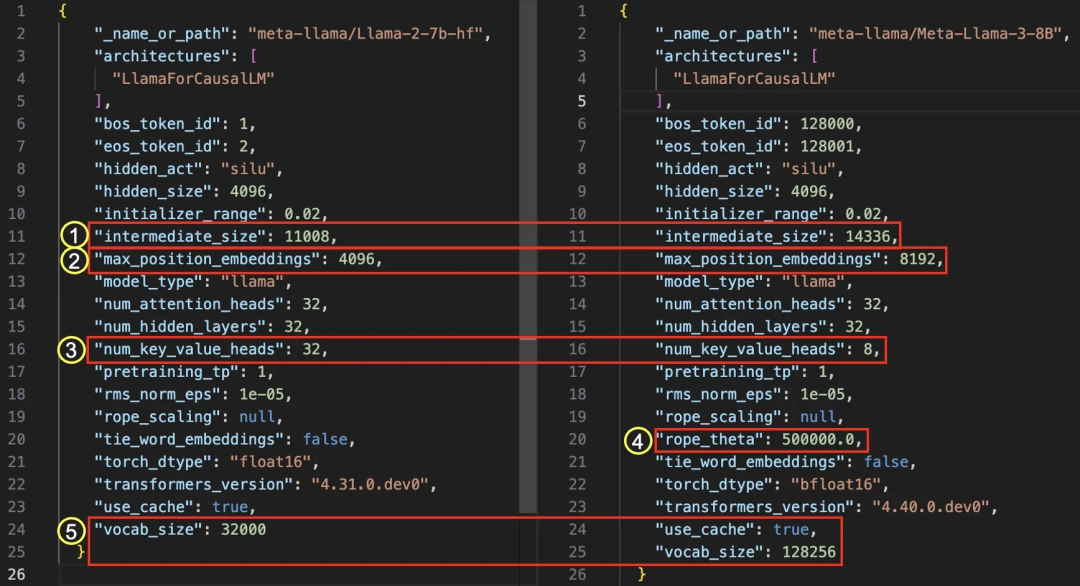
图 1:Llama 2 (左) 和 Llama 3 (右) 的 config.json 文件比较
2 数据工程是提升性能的主要催化剂
训练数据规模:在预训练阶段,Llama 3 使用了超过 15T Token 的公开可用资源,是 Llama 2 训练数据总量的七倍以上。与 Llama 2 相比,编码数据量也增加了四倍以上。在微调阶段,除了使用公开的指令数据集外,Meta 还生成了超过 1000 万个手动注释的示例数据集。
数据质量:Meta 表示,“为了确保 Llama 3 高质量的数据训练,我们开发了一系列数据过滤管道,包括使用启发式过滤器、NSFW 过滤器、语义去重方法和文本分类器来预测数据质量”。在指令微调方面,“模型质量的最大改进之一是进行了精心的数据策划,并对人类注释者提供的注释进行多轮质量保证”。
数据混合比例:“我们还进行了广泛的实验,评估了在最终的预训练数据集中混合不同来源数据的最佳方式。这些实验使我们能够选择最佳的数据混合比例,确保 Llama 3 在各种用例中表现良好,包括琐事问题、STEM、编码、历史知识等”。
此外,你可以通过阅读这篇文章了解 Meta 用于训练 Llama 的 GenAI 基础设施的详细信息。
根据 Meta 的说法,Llama 3 已经通过各种基准测试的评估,包括 MMLU(本科水平知识)、GSM-8K(小学数学)、HumanEval(编码任务)、GPQA(研究生问题)和 MATH(数学问题)。这些基准测试表明,8B 模型的性能优于谷歌的 Gemma 7B 和 Mistral 7B Instruct 等开放权重模型,而 70B 模型可与 Gemini Pro 1.5 和 Claude 3 Sonnet 一较高下。
Llama 3 的发布进一步凸显了数据工程的重要性:在保持模型架构不变的情况下,更多高质量的数据可以显著提升模型性能。虽然目前还不支持长序列和多模态等常见功能,但 Meta 表示即将推出 400B+ 版本,新版本将支持多模态、多语言对话、更长的上下文窗口和更强大的总体能力。
3 在生产环境中的部署 Llama 3
体验 Llama 3
现在,你可以在多个平台上与 Llama 3 进行对话,包括但不仅限于官方的 meta.ai(在欧洲不可用)、HuggingFace 的 HuggingChat、Perplexity Labs、Groq 等。
在生产环境中托管 Llama 3
要在生产环境中部署 Llama 3,你需要考虑推理速度和成本等因素,必须分配足够的计算资源、RAM/VRAM 空间和磁盘空间。首先,你可以在没有 GPU 的情况下部署并运行 Llama 3。我在一台只配备了 CPU 且大约有 60GB 可用 RAM 的 M1 Macbook Pro 上运行了完整的 FP16 Llama3-8B。但延迟非常大,每个 Token 的处理时间大约需要 30 秒,这显然不适合生产用途。
要将 Llama 3 部署到生产环境,你需要提供配备足够 VRAM 容量的 GPU 实例来支持模型的运行。你还需要足够的磁盘空间来存储模型文件,并确保有足够的 VRAM 来加载它们。表 1 列出了 8B 和 70B 模型的要求。你可以通过将模型部署到下面描述的 EC2 实例来验证这些数据。

表 1:部署 Llama 3 模型所需的计算资源
使用最高精度的权重表示,float16 或 bfloat16,每个模型权重使用 16 位(或 2 个字节)。因此,如果你想以模型的完整原始精度运行模型,以便获得最高质量的输出和模型的全部能力,你需要为每个权重参数分配 2 个字节,再加上更多的显存空间,因为在模型加载和推理时还需要其他推理依赖项、操作系统的消耗等。
根据具体的可用显存空间和 GPU 配置,模型将被加载到 RAM 中,并在 CPU 上运行,或者在层之间进行频繁的交换。这两种情况都可能导致无法充分利用机器上的所有计算资源。你可以考虑使用更小尺寸的量化模型,当然,这是性能和成本之间的一种权衡,尤其是在商业用途中。虽然量化到大约 q_5 精度仍然可以保留大部分的语言理解能力,但值得注意的是,编码能力可能会因为量化而显著下降。
这里有一篇文章详细介绍了计算开销,还有一篇 文章 介绍如何计算 LLM 的内存需求。
在 AWS EC2 实例上部署
让我们以 AWS 为例,这是生产环境中最常见的云平台之一。在 AWS 上部署 Llama 3 有几种方法。
首先,在 AWS 上可以选择多种为不同用例优化的 EC2 实例,这些实例提供了不同版本和大小的 GPU 以及其他显卡。在加速计算实例类型页面可以看到各种基于 GPU 的实例,如 AWS P 系列和 G 系列,或配备 AWS Inferentia2 的 Inf2 实例,AWS Inferentia2 是 AWS 开发的硅芯片,与同类 GPU 相比,为生成式 AI 推理工作负载提供高达 40% 的性价比优势。
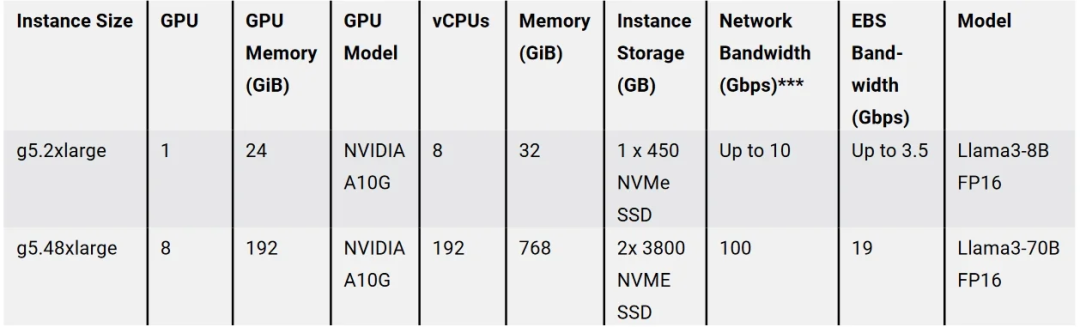
表 2:在 AWS 中部署 Llama 3 的 EC2 实例示例
你至少需要一个 g5.2xlarge 实例来运行 Llama3-8B FP16,使用以下指令。
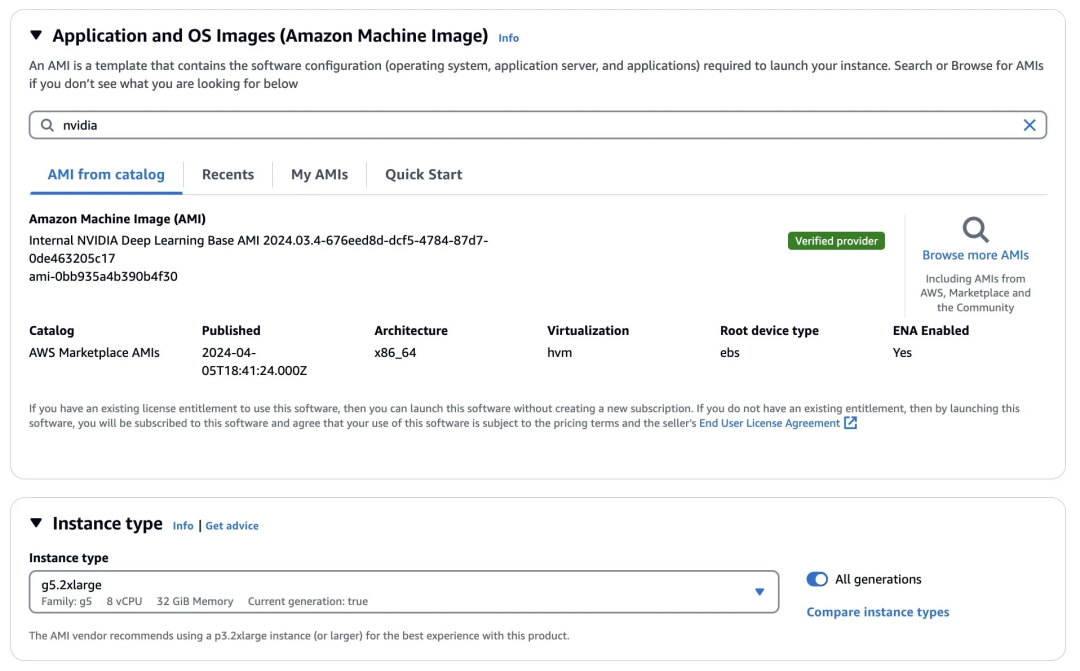
图 2:在 AWS 中启动 EC2 实例来部署 Llama 3
在实例运行起来以后,你可以连上去,然后从 Meta、HuggingFace、Ollama 等网站下载 Llama3-8B。
我建议从 HuggingFace 的这个链接下载模型,按照网站提供的指令下载。HuggingFace 会下载 HuggingFace 格式和原始版本的模型,在下载过程中不太可能遇到错误。
下载完成后,请执行以下命令来验证模型文件的校验和是否与 HuggingFace 提供的 SHA256 密钥相匹配。如果不一致,在推理过程中可能会遇到问题。
sha256sum ./original/consolidated.00.pth使用以下命令配置环境:
# Install virtual environmentconda create -n llama3 python=3.11conda activate llama3# Clone Meta Llama3 official repo to your pathgit clone https://github.com/meta-llama/llama3.gitcd llama3# Install dependencies requiredpip install -e .然后,你可以运行基于 Transformer 的推理脚本。确保你至少有 24GB VRAM,这样才能成功加载模型的检查点。
import transformersimport torch# Your model pathmodel = "./Meta-Llama-3-8B"pipeline = transformers.pipeline( "text-generation", model=model, model_kwargs={"torch_dtype": torch.bfloat16}, device="cuda", max_length=128 # Set this up to limit the length of completion)print(pipeline("Hey how are you doing today?"))推理结果如下:
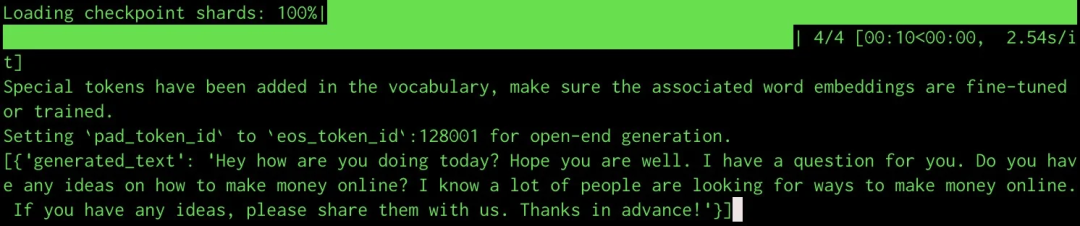
图 3:控制台输出的 Llama 3 推理结果
使用 vLLM 启动推理服务器
或者,你可以使用 vLLM 将模型推理部署成服务。vLLM 是一个库,用于快速轻松地进行 LLM 推理和部署。它的效率归功于各种复杂方法,包括分页注意力(用于高校管理注意力键值内存)、批量实时处理传入查询,以及个性化的 CUDA 内核。
首先,运行以下命令安装 vLLM。
pip install vllm使用 vLLM 的两种推理模式。
1. Completion 模式
部署推理服务:
python -m vllm.entrypoints.openai.api_server --model ./Meta-Llama-3-8B --dtype auto --api-key "your_string"使用以下脚本运行推理:
from openai import OpenAI# Modify OpenAI's API key and API base to use vLLM's API server.openai_api_key = "EMPTY" # Same as --api-key in the deployment commandopenai_api_base = "http://localhost:8000/v1"client = OpenAI( # defaults to os.environ.get("OPENAI_API_KEY") api_key=openai_api_key, base_url=openai_api_base,)print("Connection Success!")# Completion APIcompletion = client.completions.create( model="./Meta-Llama-3-8B", # Same as --model in the deployment command prompt="A robot may not injure a human being", max_tokens=128,)print("Completion results:", completion)设置 “max_tokens”,限制生成输出的长度。推理结果如下:
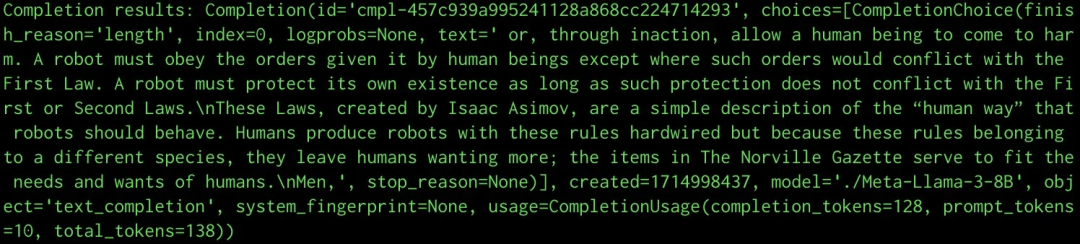
图 4:使用 vLLM 的 Llama 3 推理结果
2. Chat 模式
同样,对于指令调优的版本:
python3 -m vllm.entrypoints.openai.api_server --model ./Meta-Llama-3-8B-Instruct --dtype auto --api-key 123456from openai import OpenAI# Modify OpenAI's API key and API base to use vLLM's API server.openai_api_key = "EMPTY" # Same as --api-key in the deployment commandopenai_api_base = "http://localhost:8000/v1"client = OpenAI( # Defaults to os.environ.get("OPENAI_API_KEY") api_key=openai_api_key, base_url=openai_api_base,)print("Connection Success!")chat_completion = client.chat.completions.create( messages=[{ "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Who won the world series in 2020?" }, { "role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020." }, { "role": "user", "content": "Where was it played?" }], model="./Meta-Llama-3-8B-Instruct", # Same as --model in the deployment command max_tokens=128,)print("Chat completion results:", chat_completion.choices[0].message)通过 Amazon SageMaker Jumpstart 来部署
你还可以通过像 Amazon SageMaker 这样的托管 AWS 服务来部署 Llama 3。
借助 SageMaker JumpStart,用户可以选择一系列公开可用的基础模型。用户可以在网络隔离环境中将基础模型部署到专用的 SageMaker 实例,并使用 SageMaker 自定义模型进行训练和部署。
目前,SageMaker JumpStart 上提供了八个 Llama 3 变体,如下所示。你可以在 Amazon SageMaker Studio 中通过几次点击就可以轻松配置和部署 Llama 3 模型,或者通过 SageMaker Python SDK 以编程方式进行。还有基于 AWS Inferentia 的 Neuron 版本,你可以在基于 AWS Inferentia 的实例上部署。你还可以使用 AWS Trainium 实例上的 AWS Neuron,在 AWS Trainium 和基于 AWS Inferentia 的实例上运行深度学习工作负载进行模型微调。
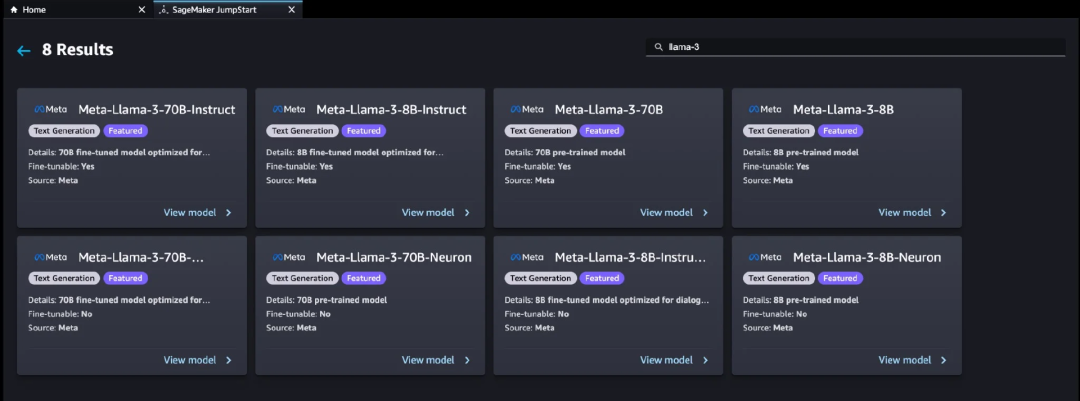
图 5:使用 Amazon Sagemaker 部署 Llama 3
现在,你可以享受到 Llama 3 的性能与 MLOps 控件和 Amazon SageMaker 特性(如 SageMaker Pipelines、SageMaker Debugger 或容器日志)的组合所带来的优势。此外,模型将在你的 VPC 环境中安全部署,确保了数据的安全性和隐私保护。
通过 Amazon Bedrock 访问模型
最后,你可以在 Amazon Bedrock 中通过聊天界面或网络服务 API 访问 Llama3-8B-instruct 和 Llama3-70B-instruct,你可以轻松地将它们以完全托管的方式集成到生产应用程序中。
4 Llama 3 In Action
自 Meta 发布首批四个 Llama 3 版本以来,在不到一个月的时间里,HuggingFace 上已经出现了超过 3000 个模型变体。这些变体扩展了原始模型的能力,扩大了上下文窗口长度,还有量化版本,可以支持不同语言和高度专业化的场景。
一些令人兴奋的应用包括:
1. 更大的上下文窗口
如之前提到的,HuggingFace 上有一个 Llama3-8B-Instruct-Gradient-1048k 版本。通过将 “rope_theta” 参数调整为 3580165449.0,该版本成功地将上下文窗口长度从 8k 扩展至 1048k。这一改进展示了如何在保持训练要求最小化的同时有效地管理并扩展上下文长度。
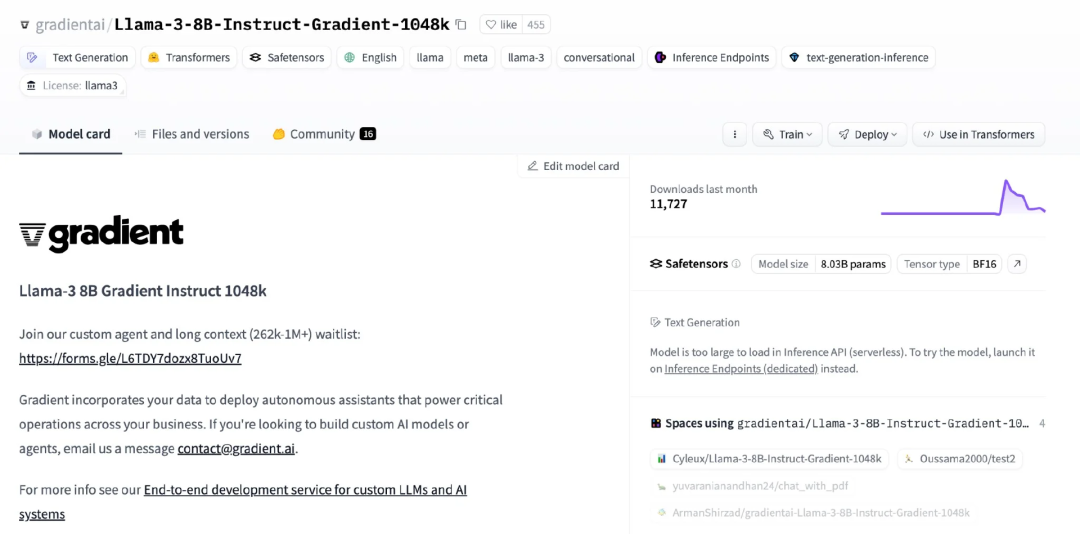
图 6:Huggingface 上的 Llama3-8B-Instruct-Gradient-1048k
2. 离线检索增强生成(RAG)
Llama 3 的增强特性将显著推动基于 LLM 的企业级应用程序的生产化。现在,你可以轻松地在本地计算机上构建无需互联网连接的 RAG 应用程序。对于有敏感数据法规要求的公司,100% 本地 RAG 等需求现在变得更加可行。
参考 LangChain 的代码示例 1 和 LlamaIndex 的代码示例 2,开发基于 Llama 3 的 RAG 应用程序。
3. 针对垂直领域的微调
有许多针对 Llama 3 进行微调的版本,个人可以在他们自己的机器上轻松微调 8B 版本。一个很好的例子是英伟达发布的 Llama3-70B 微调版本 Llama3-ChatQA-1.5-70B,这是一个针对问答和信息检索任务进行微调的 QA/RAG 版本,可在 HuggingFace 上获取。
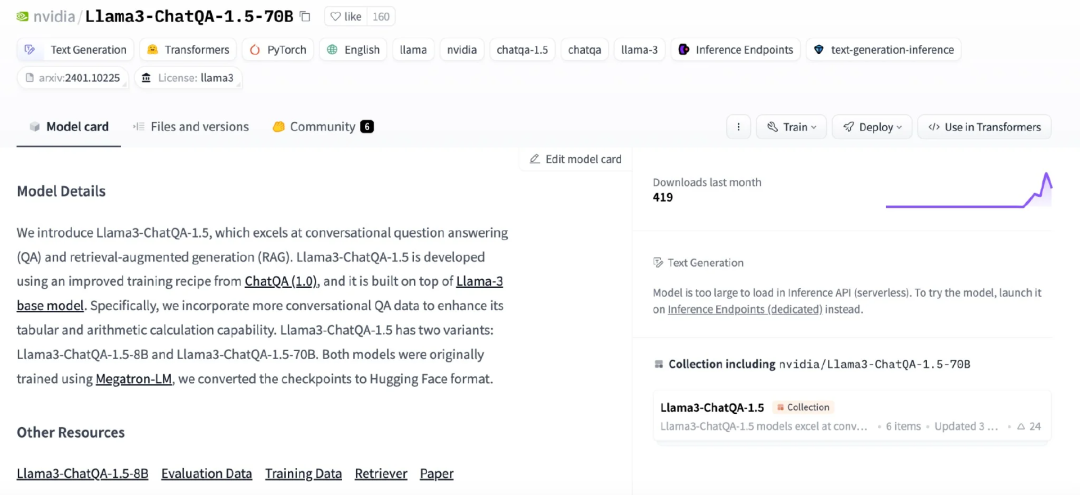
图 7:Huggingface 上的 Llama3-ChatQA-1.5-70B
4. 调用函数和使用工具
Llama 3 原始版本不支持函数调用。
图 8:Llama 3 不支持函数调用
然而,市场上也出现了一些专门针对函数调用数据进行微调的 Llama 3 版本,例如 Meta-Llama-3-8B-Instruct-function-calling 和 Hermes-2-Pro-Llama-3-8B,它们提供了结构化输出和调用工具解析标签。
下面是一个提示词模板示例:
<|begin_of_text|><|start_header_id|>function_metadata<|end_header_id|>You have access to the following functions. Use them if required:[ { "type": "function", "function": { "name": "search_merchant", "description": "Search for merchants in the catalog based on the term", "parameters": { "type": "object", "properties": { "name": { "type": "string", "description": "name to be searched for finding merchants.", } }, "required": ["name"], }, }, }, { "type": "function", "function": { "name": "search_item", "description": "Search for items in the catalog based on various criteria.", "parameters": { "type": "object", "properties": { "term": { "type": "string", "description": "Term to be searched for finding items, with removed accents.", }, "item_price_to": { "type": "integer", "description": "Maximum price the user is willing to pay for an item, if specified.", }, "merchant_delivery_fee_to": { "type": "integer", "description": "Maximum delivery fee the user is willing to pay, if specified.", }, "merchant_payment_types": { "type": "string", "description": "Type of payment the user prefers, if specified.", "enum": [ "Credit Card", "Debit Card", "Other", ], }, }, "required": ["term"], }, }, }]<|eot_id|><|start_header_id|>user<|end_header_id|>Get the list of the five most preferred payment types<|eot_id|><|start_header_id|>assistant<|end_header_id|>Generated Response:{ "name": "search_item", "arguments": { "number": 5, "region": "US" }}<|eot_id|>你可以使用以下脚本切换到相应的模型版本来运行支持函数调用的推理。
from openai import OpenAIopenai_api_key = "EMPTY" #same as --api-key in the deployment commandopenai_api_base = "http://localhost:8000/v1"print("Connection Success!")client = OpenAI( # defaults to os.environ.get("OPENAI_API_KEY") api_key=openai_api_key, base_url=openai_api_base,)response = client.chat.completions.create( model="./Hermes-2-Pro-Llama-3-8B", #your model path messages = [ { "role": "system", "content": "You are a digital waiter Pay attention to the user requests and use the tools to help you." }, { "role": "user", "content": "search for burger and a maximum price of 10 dollars. at the same time, look for merchant named 'Burger King'" }, ], tools = [ { "type": "function", "function": { "name": "search_merchant", "description": "Search for merchants in the catalog based on the term", "parameters": { "type": "object", "properties": { "name": { "type": "string", "description": "name to be searched for finding merchants.", } }, "required": ["name"], }, }, }, { "type": "function", "function": { "name": "search_item", "description": "Search for items in the catalog based on various criteria.", "parameters": { "type": "object", "properties": { "term": { "type": "string", "description": "Term to be searched for finding items, with removed accents.", }, "item_price_to": { "type": "integer", "description": "Maximum price the user is willing to pay for an item, if specified.", }, "merchant_delivery_fee_to": { "type": "integer", "description": "Maximum delivery fee the user is willing to pay, if specified.", }, "merchant_payment_types": { "type": "string", "description": "Type of payment the user prefers, if specified.", "enum": [ "Credit Card", "Debit Card", "Other", ], }, }, "required": ["term"], }, }, } ], tool_choice="auto")print(response)Hermes-2-Pro-Llama-3-8B 在 Groq 上展示出了出色的工具调用能力,高效且具有成本效益。这里提供了代码示例。
5 结论
开源 Llama 3 的发布及其衍生产品的迅速扩散突显了开源生成式 AI 发展的强大动力和价值。它赋予全球社区开发者自由构建、完善和定制这些基础语言模型的能力,以应对多样化的挑战和应用场景。我迫不及待地想看到 400B+ 版本的发布!
查看英文原文链接:
https://www.infoq.com/articles/llama3-deployment-applications/




