
随着京东供应链业务数十年的发展,作为第一环节的采购系统(BIP)俨然在业务复杂度、订单数据量上达到了前所未有的规模,随之而来的数据库查询性能问题屡见不鲜。本文主要介绍了研发团队在面对海量订单场景下,为了提升用户体验、降低系统技术风险,所做的真实优化案例。
0.前言
•系统概要:BIP 采购系统用于京东采销部门向供应商采购商品,并且提供了多种创建采购单的方式以及采购单审批、回告、下传回传等业务功能。
•系统价值:向供应商采购商品增加库存,满足库存周转及客户订单的销售,供应链最重要的第一环节。
•JED:京东自研的基于 MySQL 存储的分布式数据库解决方案
•JimKV/JimDB:京东自研的新一代分布式 KV 存储系统
1.背景
采购系统在经历了多年的迭代后,在数据库查询层面面临巨大的性能挑战。核心根因主要有以下几方面:
•复杂查询多,历史上通过 MySQL 和 JED 承载了过多的检索过滤条件,时至今日很难推动接口使用方改变调用方式
•数据量大,随着业务的持续发展,带来了海量的数据增长
•数据模型复杂,订单完整数据分布在 20+张表,经常需要多表 join
引入的主要问题有:
•业务层面:
◦订单列表页查询/导出体验差,性能非常依赖输入条件,尤其是在面对订单数据倾斜的时候,部分用户无法查询/导出超过半个月以上的订单
◦查询条件不合理,1.归档筛选条件,技术词汇透传到业务,导致相同周期的单子无法一键查询/导出,需要切换“是否归档”查询全部;2.无法区分“需要仓库收货”类的单子,大部分业务同事主要关注这类单子的履约情况
•技术层面:
◦慢 SQL 多,各种多表关联复杂条件查询导致,索引、SQL 已经优化道了瓶颈,经常出现数据库负载被拉高
◦大表多,难在数据库上做 DDL,可能会引起核心写库负载升高、主从延迟等问题
◦模型复杂,开发、迭代成本高,查询索引字段散落在多个表中,导致查询性能下降
2.目标
业务层面:提升核心查询/导出体验,加强查询性能,优化不合理的查询条件
技术层面:1.减少慢 SQL,降低数据库负载,提高系统稳定性;2.降低单表数据量级;3.简化数据模型
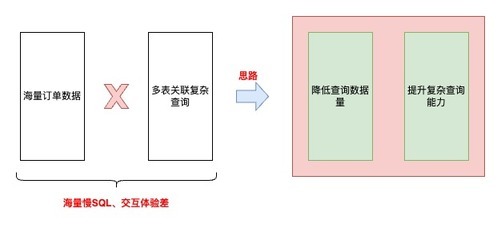
3.挑战
提升海量数据、复杂场景下的查询性能!
•采购订单系统 VS C 端销售订单系统复杂度对比:
4.方案
思路
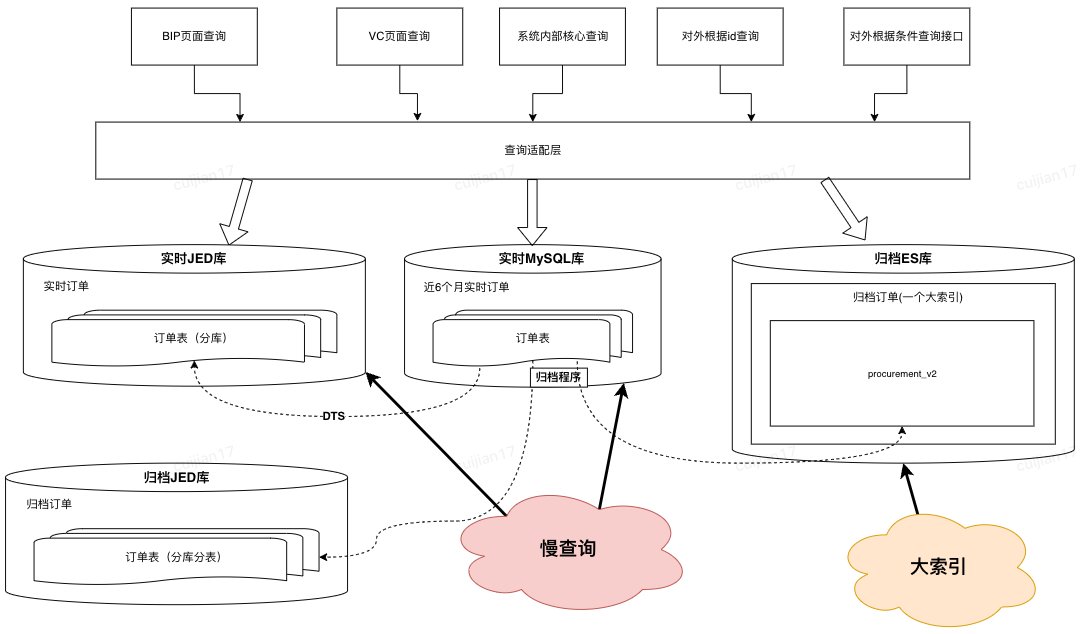
优化前
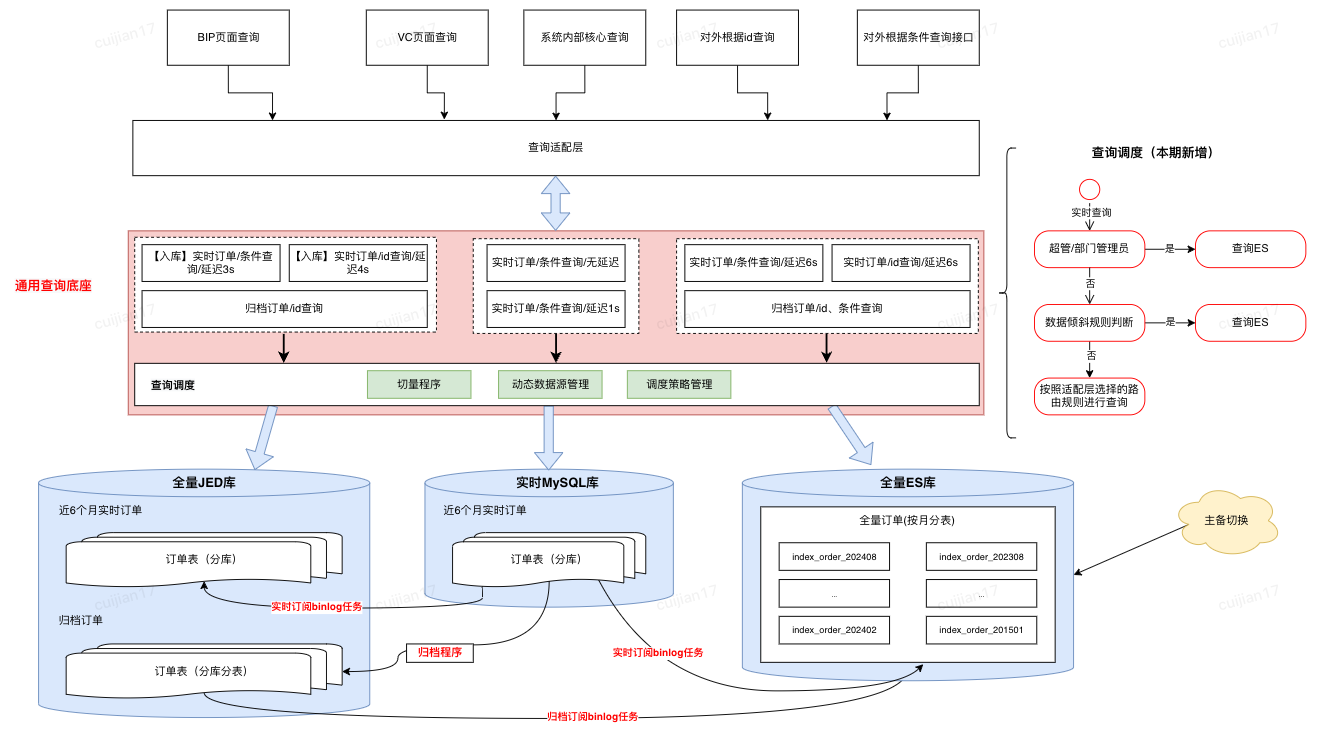
优化后
4.1 降低查询数据量
4.1.1 前期调研
基于历史数据、业务调研分析,采购订单只有 8%的订单属于“需要实际送货至京东库房”的范围,也就是拥有完整订单履约流程、业务核心关注时效的。其余订单属于通过客户订单驱动,在采购系统的生命周期只有创建记录

基于以上结论,在与产品达成共识后,提出新的业务领域概念:“入库订单”,在查询时单独异构这部分订单数据(前期也曾考虑过,直接从写入层面拆分入库订单,但是因为开发成本、改动范围被 pass 了)。异构这部分数据实际也参考了操作系统、中间件的核心优化思路,缓存访问频次高的热数据
4.1.2 入库订单异构
执行流程
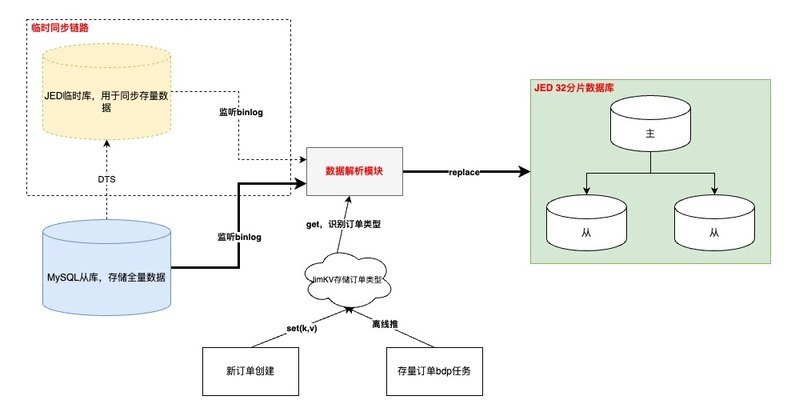
•“入库”订单数据打标
◦增量订单在创建订单完成时写入;存量订单通过离线表推数
◦需要订单创建模块先完成改造上线,再同步历史,保证数据不丢
◦如果在【数据解析模块】处理 binlog 时无法及时从 JimKV 获取到订单标识,会补偿反查数据库并回写 JimKV,提升其他表的 binlog 处理效率
•binlog 监听
◦基于公司的【数据订阅】任务,通过消费 JMQ 实现。其中订阅任务基于订单号进行 MQ 数据分区,并且在消费端配置不允许消息重试,防止消息时序错乱
◦其中,根据订单号进行各个表的 MQ 数据分区,第一版设计可能会引起热分区,导致消费速率变慢,基于这个问题识别到热分区主要是由于频繁更新订单明细数据导致(订单(1)->明细(N)),于是将明细相关表基于自身 id 进行分区,其他订单纬度表还是基于订单号。这样既不影响订单数据更新的先后顺序,也不会造成热分区、还可以保证明细数据的准确性
•数据同步
◦增量数据同步可以采用源库的增量 binlog 进行解析即可,存量数据通过申请新库/表,进行 DTS 的存量+增量同步写入,完成 binlog 生产
◦以上是在上线前的临时链路,上线后需要切换到源库同步 binlog 的增量订阅任务,此时依赖“位点回拨”+“数据可重入”。位点回拨基于订阅任务的 binlog 时间戳,数据可重入依赖上文提到的 MQ 消费有序以及 SQL 覆盖写
•数据校对
◦以表为纬度,优先统计总数,再随机抽样明细进行比对
◦目前入库订单量为稳定在 5000 万,降低 92%
4.2 提升复杂查询能力
4.2.1 数据准备
•考虑到异构“入库”订单到 JED,虽然数据查询时效性可以有一定保障,但是在复杂查询能力以及识别“非入库”订单还没有支持
•其中,“非入库”订单业务对于订单数据时效性要求并不高(1.订单创建源于客户订单;2.没有履约流程;3.无需手动操作订单关键节点)
•所以,考虑将这部分查询能力转移到 ES 上
ES 数据异构过程
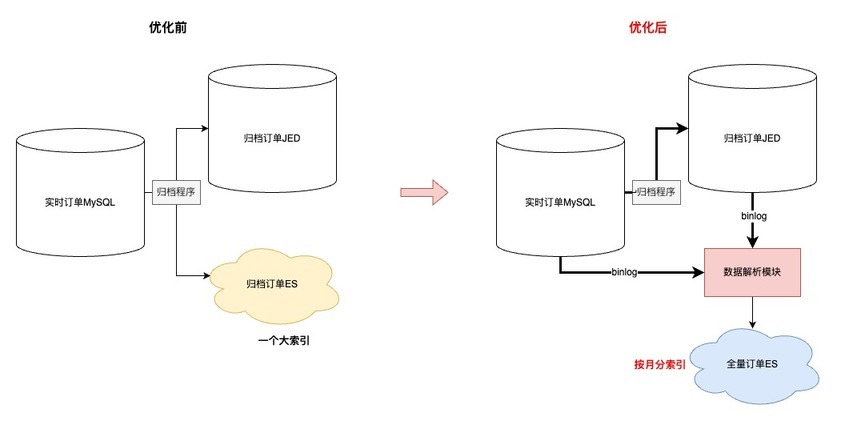
•首先,同步到 ES 的数据的由“实时+归档”订单组成,其中合计 20 亿订单,顺带优化了先前归档 ES 大索引(所有订单放在同一个索引)的问题,改成基于“月份”存储订单,之所以改成月份是因为根据条件查询分两种:1.一定会有查询时间范围(最多 3 个月);2.指定单号查询,这种会优先检索单号对应的订单创建时间,再路由到指定索引
•其次,简化了归档程序流程,历史方案是程序中直接写入【归档 JED+归档 ES】,现在优化成只写入 JED,ES 数据通过【数据解析模块】完成,简化归档程序的同时,提高了归档能力的时效性
•再次,因为 ES 是存储全量订单,需要支持复杂条件的查询,所以在订单没有物理删除的前提下,【数据解析模块】会过滤所有 delete 语句,保证全量订单数据的完整性
•接着,为了提升同步到 ES 数据的吞吐,在 MQ 消费端,主要做了两方面优化:1.会根据表和具体操作进行 binlog 的请求合并;2.降低对于 ES 内部 refresh 机制的依赖,将 2 分钟内更新到 ES 的数据缓存到 JimKV,更新前从缓存中获取
•最后,上文提到,同步到入库 JED,有的表是根据订单号,有的表是根据自身 id。那么 ES 这里,因为 NoSQL 的设计,和线程并发的问题,为了防止数据错误,只能将所有表数据根据单号路由到相同的 MQ 分区
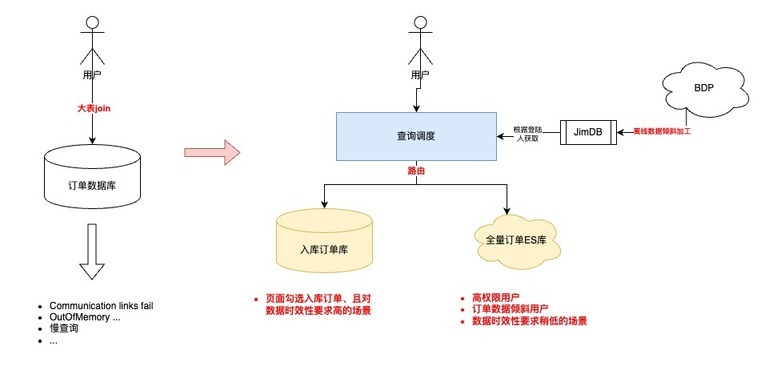
4.2.2 查询调度策略设计
优化前,所有的查询请求都会直接落到数据库进行查询,可以高效查询完全取决于用户的筛选条件是否可以精准缩小数据查询范围优化后,新增动态路由层
•离线计算 T-1 的采销/供应商的订单数据倾斜,将数据倾斜情况推送到 JimDB 集群
•根据登陆用户、数据延迟要求、查询数据范围,自动调度查询的数据集群,实现高性能的查询请求
查询调度
5.ES 主备机制 &数据监控
1.主/备 ES 可以通过 DUCC 开关,实现动态切换,提升数据可靠性
2.结合公司的业务监控,完成订单数据延迟监控(数据同步模块写入时间-订单创建时间)
3.开启消息队列积压告警
5.1 ES 集群主/备机制
1:1ES 集群进行互备,应急预案快速切换,保证高可用

5.2 数据监控

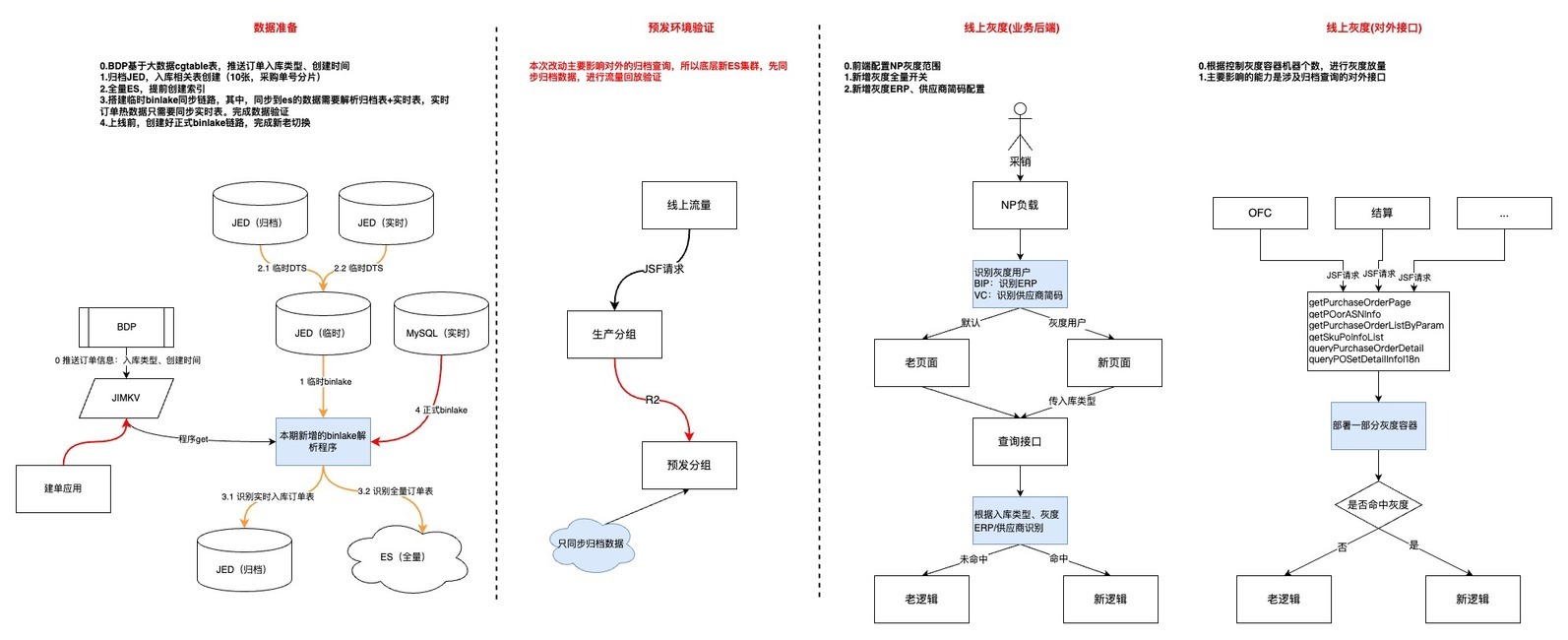
6.灰度上线
•第一步,优先上线数据模块,耗费较多时间的原因:1.整体数据量级以及历史数据复杂度的问题;2.数据同步链路比较长,中间环节多
•第二步,预发环境验证,流量回放并没有做到长周期的完全自动化,根因:1.项目周期相对紧张;2.新老集群的数据还是有一些区别,回放脚本不够完善
•第三步,用户功能灰度,主要是借助 JDOS 的负载均衡策略结合用户 erp 完成
•第四步,对外接口灰度,通过控制新代码灰度容器个数,逐步放量
7.成果
平稳切换,无线上问题
8.未来展望
•主动监控层面,新增按照天纬度进行数据比对、异常告警的能力,提高问题发现率
•优化数据模型,对历史无用订单表进行精简,降低开发、运维成本,提升需求迭代效率
•精简存储集群
◦逐步下线其他非核心业务存储集群,减少外部依赖,提高系统容错度
◦目前全量订单 ES 集群已经可以支持多场景的外部查询,未来考虑是否可以逐步下线入库订单 JED
•识别数据库隐患,基于慢日志监控,重新梳理引入模块,逐步优化,持续降低数据库负载
•MySQL 减负,探索其他优化方案,减少数据量存储,提升数据灵活性。优先从业务层面出发,识别库里进行中的僵尸订单的根因,进行分类,强制结束
•降级方案,当数据同步或者数据库存在异常时,可以做到秒级无感切换,提升业务可用率
9.写在最后
•为什么没考虑 Doris?因为 ES 是团队应用相对成熟的中间件,处于学习、开发成本考虑
•未来入库的 JED 相关表是否可以下掉,用 ES 完全替代?目前看可以,当初设计冗余入库 JED 也是出于对于 ES 不确定性以及数据延迟的角度考虑,而且历史的一部分查询就落在了异构的全量实时订单 JED 上。现在,JED 官方也不是很推荐非 route key 的查询。最后,现阶段因为降低了数据量和拆分了业务场景,入库 JED 的查询性能还是非常不错的
•因为项目排期、个人能力的因素,在方案设计上会有考虑不周的场景,本期只是优化了最核心的业务、技术痛点,未来还有很大持续优化的空间。中间件的使用并不是可以优化数据库性能的银弹,最核心的还是要结合业务以及系统历史背景,在不断纠结当中寻找 balance




