
背景介绍
作业帮的服务端技术体系正向着云原生化发展,提升资源利用率是云原生技术栈的核心目标之一,资源利用率的提升意味着以更少的计算节点承载更多的应用实例,极大地降低资源开销。而 Serverless 具有弹性伸缩、强隔离性、按量计费、运维自动化等特点,带来了降低交付时间、降低风险、降低基础设施成本、降低人力成本等核心优势。
Serverless 化一直是作业帮基础架构探索的核心方向。Serverless 化长期来看有两种方案,一种是函数计算,一种是 Kubernetes Serverless 虚拟节点。
Kubernete Sserverless 虚拟节点对已经运行在 Kubernetes 上服务无实际使用差异,用户体验较好,业务服务使用无感知,可以由基础架构进行调度迁移。比如,阿里云 ECI 就是一种典型 Kubernetes 虚拟节点方案。
但我们的业务场景需要更精细化的资源管理策略,需要我们更紧密结合资源管理述求的调度策略。所以我们在云厂商能力之上研发了自己的方案:
2020 年,我们开始尝试将部分密集计算调度到 Serverless 虚拟节点上,用 Serverless 虚拟节点底层服务器的强隔离能力来规避服务间相互影响;
2021 年,我们就将定时任务调度到 Serverless 虚拟节点,替代节点扩缩容,应对短期运行任务,提升资源利用率降低成本;
2022 年,我们开始将核心在线业务调度到 Serverless 虚拟节点,而在线业务是最敏感、用户易感知。
同时在线业务有着明显的波峰和波谷,在高峰期弹性调度到 Serverless 虚拟节点将带来巨大的成本收益。随着而来的要求也越高,尽可能保证在线业务在性能、稳定性上和物理服务器效果一致,业务观测感知上一致。也就是让上层业务服务感知不到 Serverless 虚拟节点和物理服务器之间的差异。
Kubernetes Serverless 虚拟节点
虚拟节点并不是真实的节点,而是一种调度能力,支持将标准 kubernetes 集群中的 pod 调度到集群服务器节点之外的资源中。部署在虚拟节点上的 pod 具备裸金属服务器一致的安全隔离性、网络隔离性、网络连通性,又具有无需预留资源,按量计费的特性。
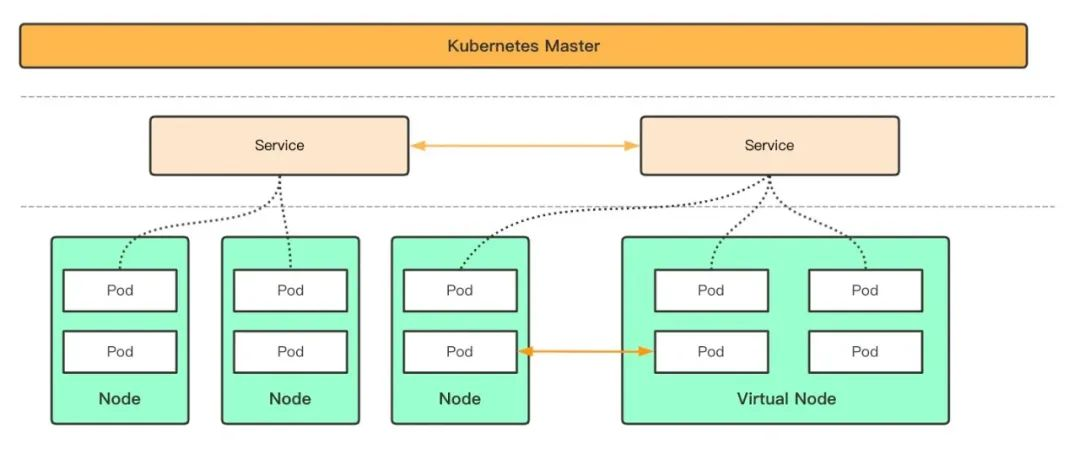
Kubernetes Serverless 虚拟节点的成本优势
作业帮的大部分服务都已经完成容器化,在线业务有着典型的高峰期,且高峰期持续时间较短(4 个小时/每天),全部使用裸金属服务器,高峰期服务器平均负载接近 60%,而低峰期负载只有 10%左右。此场景就非常适合 Serverless 的弹性伸缩落地,可以做一个简单的计算:假设全部使用自有服务器每小时的成本为 C,平均每天高峰期的时间为 4 小时,使用 Serverless 的单位时间成本为 1.5C,那么:
1. 全部使用自有服务器的总成本为 C * 24 = 24C
2. 保留 70%的自有服务器,高峰期增加 30%的 Serverless 来应对,此时的总成本为:C * 24 * 0.7 + 1.5C * 4 * 0.3 = 18.6C
理论上高峰期波峰部分使用 Serverless 可降低的成本为:(24C - 18.6C) / 24C = 22.5%, 可见,将在线服务高峰期弹性调度到 Serverless 可以节省大量的资源成本。
问题和解决方案
虽然 Kubernetes Serverless 虚拟节点拥有诸多优点,但也仍然存在一些问题。
调度和管控问题
调度层面主要解决两个问题:一是扩容时创建 POD 基于何种调度策略调度到虚拟节点,二是缩容时应优先缩虚拟节点上的 POD。这两种能力在我们当前使用的 Kubernetes 版本中能力是不足的。
扩容/缩容调度策略
扩容调度策略应该由基础架构和运维来统一把控,与业务关联度不大,因为业务方不知道底层资源层还有多少服务器计算资源可以被利用。我们理想情况下,是希望当本集群池内,物理服务器资源达到利用率瓶颈后,扩容到 serverless 虚拟节点上。这样就可以既没有容量风险也可以获得成本优势。
业界使用虚拟节点的演进过程:
1. 虚拟节点和标准节点是完全分开的,只能调度到指定的池子。
2. 用户不用指定 selector,当 POD 因固定节点资源不足调度 pending 的时候,会自动调度到虚拟节点上,该过程会有延迟。
3. 云厂商比如(阿里云 ACK Pro)的调度器会当资源不足时自动调度到虚拟节点上,这个过程自动且无延迟,相对比较理想。
但我们的业务场景需要更精细化的资源管理策略,需要我们更紧密结合资源管理述求的调度策略,所以我们在云厂商的能力之上研发了我们自己的方案:
扩容:基于在线服务的波峰波谷,进行预测推荐调度,预测高峰该服务能在集群物理机上运行的副本数阈值,通过自研调度器将超过阈值的 POD 调度到虚拟节点上。该阈值数据即集群物理机上运行副本的最优解。既能满足物理机集群的利用率也能满足性能要求。阈值太低则物理机资源浪费,阈值太高则物理机部署密度太高,资源利用率过高,影响业务。
缩容:缩容时优先缩 serverless 虚拟节点上的 pod 很好理解,因为常备的资源池是包年包月的单价更低,虚拟节点上的资源是按量计费的单价较高,优先缩虚拟节点上的 pod 来达到成本最优;我们通过自研调度器对虚拟节点上的 pod 注入自定义的注解,修改 kube-controller-manager 的缩容逻辑,将带有虚拟节点自定义注解的 pod 置于缩容队列的顶部,来完成优先缩容虚拟节点上的 POD。
管控面 devops 平台除了支持自动计算调度到虚拟节点的阈值,还支持手动设置以便于业务进行更精细的调控。调度到虚拟节点的能力可以结合 hpa、cron-hpa 同时使用,来满足业务更灵活的需求。管控面还支持故障场景下一键封锁虚拟节点,以及应对更极端情况(如机房整体故障)的多云调度能力。
观测性问题
我们的观测服务都是自建,比如(日志检索、监控报警、分布式追踪)。因为是虚拟节点,POD 里跑的监控组件、日志采集是由云厂商内置的。我们需要保证业务感知层面上,pod 在 Serverless 虚拟节点和物理服务器上运行一致,所有就有一个转化到我们自有观测服务的过程。
监控:在监控方面,云厂商虚拟节点完全兼容 kubelet 监控接口,可以无缝接入 Prometheus。完成 Pod 实时 CPU/内存/磁盘/网络流量等监控,做到了和普通节点上的 POD 一致。
日志:在日志采集方面,通过 CRD 配置日志采集,将日志发送到统一的 Kafka。我们自研了日志消费服务,记录各云厂商和自有节点上的消费情况。
分布式追踪:在分布式追踪方面,由于无法部署 daemonset 形式的 jeager agent,我们 jeager client 端做了改造,通过环境变量识别 pod 运行的环境,如果是在虚拟节点上则跳过 jeager agent,直接将分布式追踪的数据推送到 jeager colletror。
性能、稳定性及其他问题
serverless 虚拟节点底层性能差异:由于底层计算资源规格的不同以及虚拟化层带来的开销,性能可能和裸金属服务器有所差异,这就需要对时延非常敏感的业务,在上虚拟节点之前进行充分的测试和评估。
云服务器库存风险:高峰期大量扩容,如果云厂商某个规格的的资源池水位低,可能会扩不出来指定规格的资源。这里我们是开启自动升配,也就是申请 2c2G,理论上应该匹配 2c2G 的 ECI,如果没有库存,会匹配到 2c4G 的 ECI。以此类推。
问题定位排查:因为虚拟节点本质上使用的是云厂商资源池,不在我们自身的管控范围内,当业务出现异常时虽然可以自动摘流,但无法登陆到机器排查问题,比如像查看系统日志、取回 core dump 文件等操作就比较困难。在我们的建议下,云服务(阿里云 ECI)已经支持将 core dump 自动上传到 oss 了。
规模和收益
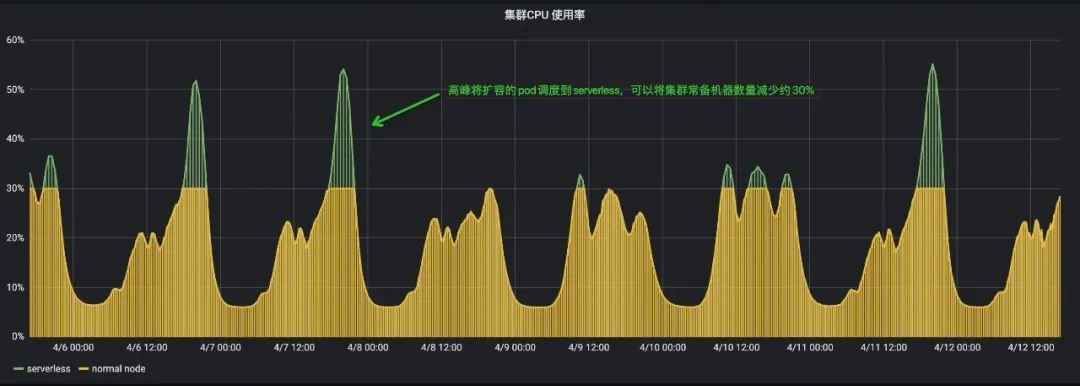
目前该方案已经成熟,高峰期已有近万核规模的核心链路在线业务运行在 Kubernetes Serverless 虚拟节点。随着业务的放量,未来运行在 Serverless 虚拟节点上的服务规模会进一步扩大,将节省大量的资源成本。
作者介绍:
吕亚霖,作业帮基础架构 - 架构研发团队负责人。负责技术中台和基础架构工作。在作业帮期间主导了云原生架构演进、推动实施容器化改造、服务治理、GO 微服务框架、DevOps 的落地实践。
别路,作业帮基础架构-高级研发工程师,在作业帮期间,负责多云 k8s 集群建设、k8s 组件研发、linux 内核优化调优相关工作。




