
谷歌用一种奇妙的态度宣布了他们认为的三个“好”消息:该故障模式不会影响其他用户;谷歌弃用了该配置工具;客户团队值得称赞,并且谷歌云还是最好的云.....
2023 年,一家澳大利亚基金管理机构 UniSuper 将数千台虚拟机迁移到 GCP。2024 年 5 月 2 日,该机构遭遇了重大危机: 整个基础设施被意外删除,导致灾难恢复机制失效,超过 62 万名基金成员无法访问其养老年金账户长达一周时间。
UniSuper 此前曾使用 Google Cloud VMware Engine 将基于 VMware 的硬件基础设施从两个数据中心迁移到 Google Cloud。作为私有云合同的一部分,UniSuper 的服务和数据在两个 Google Cloud 区域中进行双重复制。然而,这种区域分离实际上是虚拟的,因为两个区域的数据副本均因 Google 内部错误被意外删除,导致 UniSuper 现有灾难恢复方案失效。 由于没有建立外部灾难恢复设施,最终酿成重大服务中断事件。
幸运的是,UniSuper 在另一家供应商处保留了额外的备份,这帮助他们最大限度地减少了数据丢失并加快了恢复速度。
谷歌于 5 月 25 日发布了一篇博客文章,给出了“详细”的故障分析报告:
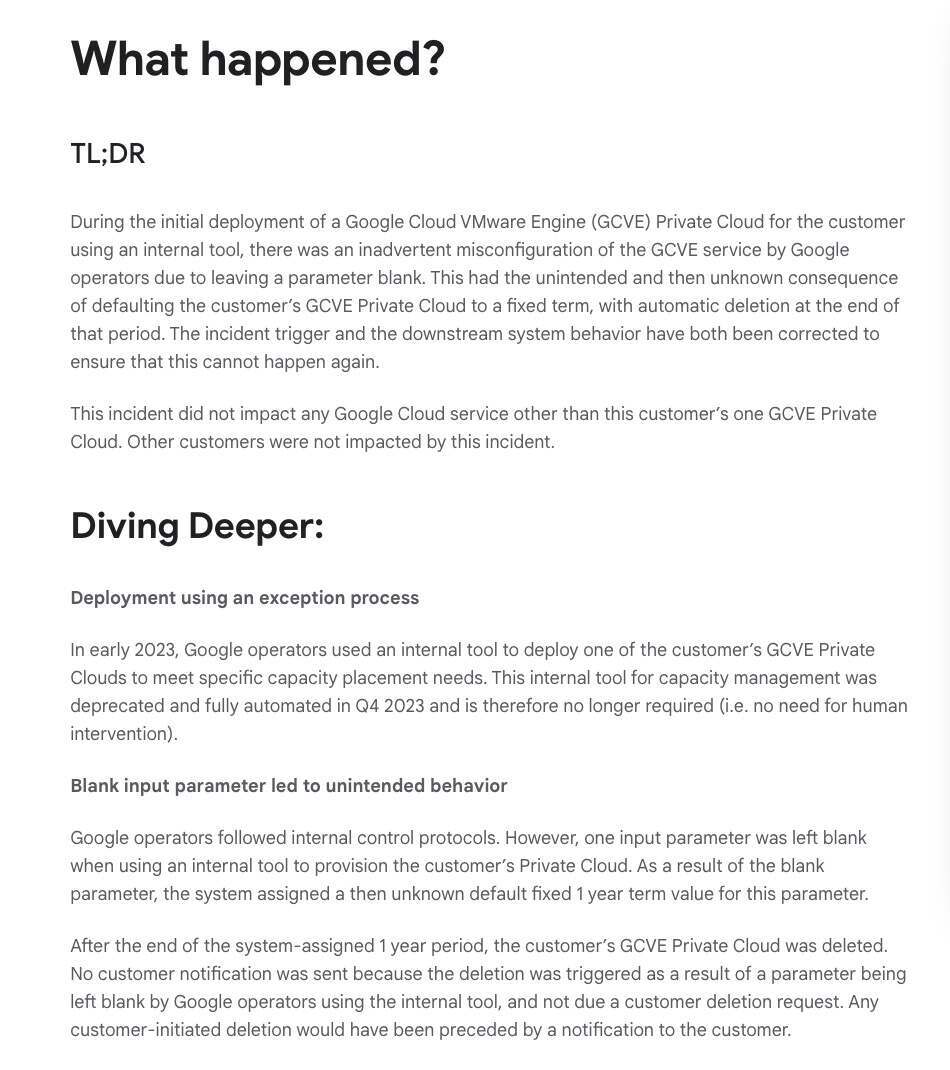
深入解析:
2023 年初,谷歌运维人员使用内部工具部署了客户的一个 GCVE 私有云,以满足特定的容量需求。该内部工具用于容量管理,并已在 2023 年第四季度弃用且完全自动化,因此不再需要人工干预。
谷歌运维人员遵循了内部控制协议。然而,在使用内部工具配置客户的私有云时,一个输入参数被留空。由于这个空白参数,系统为该参数分配了一个当时未知的默认一年的固定期限。
在系统分配的一年期限结束后,客户的 GCVE 私有云被删除。由于删除是由谷歌运维人员使用内部工具时留空参数引起的,而非客户删除请求,因此没有向客户发送通知。任何客户发起的删除请求在执行前都会通知客户。
也就是说,UniSuper 的生产级 Google Cloud VMware Engine (GCVE)私有云在创建一年后被自动删除,原因是创建过程中,创建脚本包含一项 bug,导致传递了一个 null 值。于是该私有云实际上未能被正确创建为永久订阅形式,而仅拥有一年订阅期。一年之后,Google Cloud 按时操作,“尽职尽责”地删除了这套私有云。
从谷歌“独一无二”的故障中,我们能吸取什么教训?
在 5 月 2 日至 13 日期间,Unisuper 在经历了重大宕机事故后,在随后的相关说明中将事件归咎于 Google Cloud,谷歌对此也没有进行反驳。
UniSuper 服务中断,源自 Google Cloud 当中的一系列罕见问题。这些问题导致 UniSuper 私有云在创建过程中发生了意外配置错误,进而触发一个此前未知的软件 bug,最终影响到 UniSuper 的系统。此前从未发生过类似事件,我们也已经采取措施确保该问题不会再次发生。
这是由 Google Cloud CEO Thomas Kurian 签字认可的最终定性新闻稿,从内容上看,事件似乎源自 Google Cloud 中一个奇特且罕见的 bug。Google Cloud CEO Thomas Kurian 确认称,此次中断是由一系列前所未有的事件所引发,即在配置 UniSuper 私有云服务期间无意发生的错误配置,最终导致 UniSuper 私有云订阅遭到删除。
这号称是一个孤立的“独一无二的事件”,从未发生在全球任何 Google Cloud 客户身上,完全就是个悲惨的意外。
只是当前这些新闻稿一直用模糊的语言,掩盖掉了事件中的种种技术细节。
事情曝光实际已经有 20 多天,咱们专业人员对这起“独一无二”的案例充满了兴趣,有不少人做了相关推测,那咱们就结合已知的细节,先看看被删的到底是什么。
Google Cloud 上并不存在所谓“订阅”资源,与之最接近的概念应该是“计费账户”。虽然谷歌方面提供虚拟私有云(VPC),但它并不能算我们所熟悉的云实例,而且删除 VPC 似乎不至于引发公告中描述的毁灭性影响。
但通过回溯 UniSuper 的 Google Cloud 迁移过程,就会发现他们使用的其实是 Google Cloud VMWare Engine (GCVE)。从 2023 年 6 月开始:
到目前为止,该退休基金已经将几乎所有非生产工作负载从自有数据中心迁移至 Google Cloud。
UniSuper 采用了 Google VMware Engine(GCVE)托管服务,并聘请合作伙伴 Kasna 协助完成迁移。
GCVE 中包含一种名为私有云的资源。所谓私有云,具体包含 VMware 技术栈的主机、管理服务器、存储及网络等要素。
下面来看如何使用 API 方法删除这种私有云:
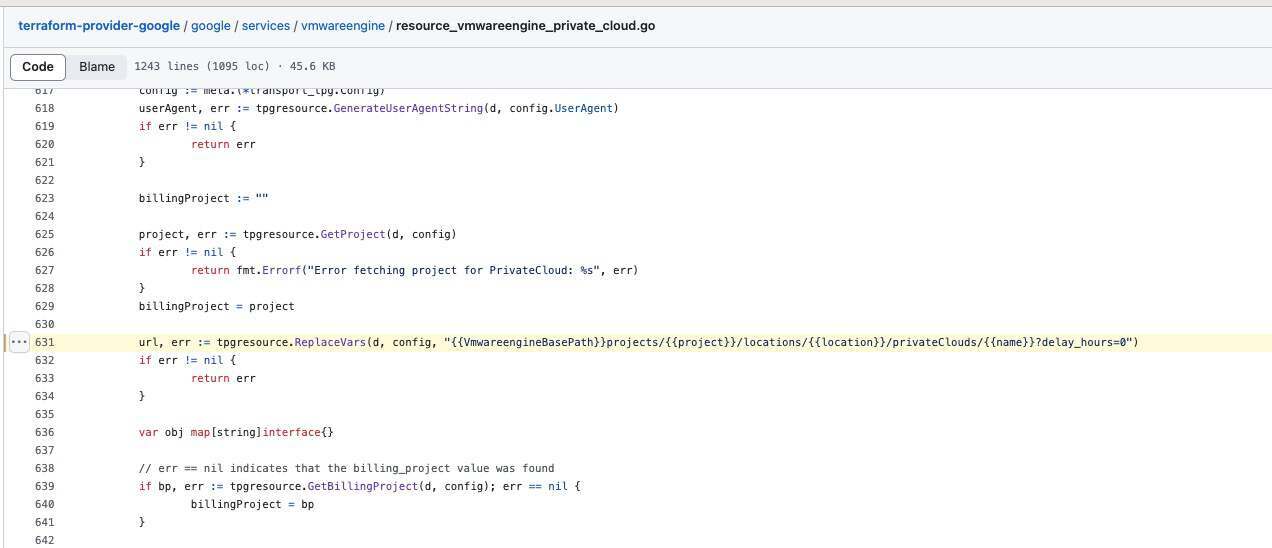
对于计划删除的私有云资源,可以将 PrivateCloud.state 设置为 DELETED,并将 expireTime 设置为删除完成且无法撤销的时间。一旦 PrivateCloud 删除任务设置成功(包括将 delayHours 设置为 0 的情况),删除操作就会被标记为已完成,即操作状态在 PrivateCloud 被实际清除前并不会保持在“待处理”阶段。在 expireTime 到期之前,仍可使用 privateClouds.undelete 方法恢复该 PrivateCloud。而一旦达到 expireTime,则删除将成为定局,一切私有云资源将被不可逆转地删除并停止计费。
从“一切私有云资源将被不可逆转地删除”来看,这似乎就是引发 UniSuper 业务中断的原因。有人说谷歌删除了他们的整个 Google Cloud 账户,但这种可能性不大,毕竟谷歌在删除项目前会采取一系列保护措施与延迟机制:
警告:如果您在 30 天内恢复项目,则仍可还原大部分资源。某些服务在恢复中会存在延迟,您可能需要等待一段时间才能恢复服务。其中部分资源(例如 Cloud Storage 及 Pub/Sub 资源)删除速度更快。即使您在 30 天内恢复项目,这些资源也可能无法完全恢复。
为什么连备份都被删除了?UniSuper 在新闻稿中指出:
UniSuper 在两个地理区域间设置有灾备,以防止业务中断和数据丢失。可一旦对 UniSuper 的私有云订阅进行删除,则会导致两个地理区域的资源均被删除。
同样的,这样的表述既含糊不清又让人难以理解,唯一能确定的就是 Google Cloud 删除了不同地理区域上的多个独立私有云。Google Cloud 并未设置“地理区域”的概念,而仅分为区域和可用区两种。乍看之下,这里描述的似乎是指多区域间设置。Google Cloud 在澳大利亚设有两个区域,分别是悉尼和墨尔本,似乎与 UniSuper 的情况对得上。
但认真查看文档,会发现 GCVE 提供两种私有云:其一是托管在单个区域的标准私有云,其二则是“扩展私有云”。扩展私有云运行在跨两个可用区的单一区域之上,同时由第三个可用区充当故障转移选项。所以根据新闻稿的表述,也不能排除 UniSuper 在单一区域运行扩展私有云的可能性。也就是说,此次事件要么是删除了单个扩展私有云,要么就是删除了两个独立私有云。
仔细检查 Terraform 代码
5 月 21 日,Miles Ward 在 X 帖子中详细介绍了故障原因,说法跟 25 日官方发布的一致(不明白为什么这些消息先要由非员工通过 Twitter 发布,而不是先经由官方渠道予以说明):

有开发者随后表示,根据与 Google Cloud 专业服务团队打交道的经验来看,谷歌云跟合作伙伴往往会推荐使用 Terraform 来定义基础设施即代码。
专注于 Clojure 和大型系统的软件开发人员 Daniel Compton 提出了几种可能:
第一,UniSuper 使用包含“配置错误”的 Terraform 代码运行了一项操作,因此触发了 Google Cloud 中的一个 bug,导致 Google Cloud 意外删除了该私有云。这也符合 UniSuper 在整个中断期间的公告内容。
第二,UniSuper 运行了一项存在配置错误的 terraform 操作,也可能是通过 prod tfvar 文件执行的 terraform destroy。Terraform 计划中显示“删除私有云”,且操作得到批准。
这样的自动化其实每天都在发生,只是结果通常不会这么夸张。所以 Daniel Compton 认为这种解释比 UniSuper 遇上了所谓百万分之一几率的罕见 bug 更加合理。
第三,UniSuper 运行了 Google Cloud 专业服务团队提供的自动化脚本,但其中存在 bug。配置错误导致脚本脱轨,而删除生产私有云的提示同样得到批准。
Daniel Compton 认为如果想把客户在自动化流程中犯的错推给 Google Cloud,这才能说得通。
基于 Daniel Compton 的分析,有 HN 用户 smcwhtdtmc 指出,vmwareengine_private_cloud 的 Terraform 资源会将 delayHours 参数硬编码为 0,即立即删除。所有私有云资源都将被立即且不可逆转地删除,这似乎跟 UniSuper 的中断事件对得上了。
“也许 UniSuper 是 Terraform 新手配置的?UniSuper 支付了新手税?Terraform 擅长将初学者的错误变成‘删除你的基础设施’。这是一个令人不安的猜测,但它是合理的。”
考虑到目前公布的细节很少,大家其实很难对整个事件做出总结性的陈述。
有意思的是,在故障报告中,谷歌表示为了确保此类事件不会再次发生,他们采取了多项措施:
弃用了触发此事件序列的内部工具。现在,此过程已完全自动化,并由客户通过用户界面进行控制,即使需要特定的容量管理也是如此。
清理了系统数据库并手动检查了所有 GCVE 私有云,以确保其他 GCVE 部署不受风险。
修正了针对此类部署工作流程设置删除 GCVE 私有云的系统行为。
永远不要嫌备份太多
另外,谷歌在故障报告中称,UniSuper 的“首席信息官和技术团队值得称赞,他们与 Google Cloud 团队紧密合作,快速且精准地执行了 24x7 恢复工作。”
他们最后用了一句总结陈述:“Google Cloud 依然拥有世界上最具韧性和稳定性的云基础设施。尽管发生了这次单一事件,我们的正常运行时间和韧性仍被独立验证为领先云服务中最佳的。”
但不管怎么说,如果 UniSuper 没有额外的备份,这个事情就可能有点万劫不复了。
Hacker News 上的一位开发者点评道:
有趣的是,澳大利亚金融服务监管机构 (APRA) 要求企业为每个应用程序制定多云计划。例如,“公司关键”应用程序需要能够在四周内迁移到辅助云服务。
我不确定这项规定在澳大利亚各个行业有多普遍,或者在其他国家是否也普遍。
而 Reddit 上也有人回复道:
客户支持根本不是 Google 的 DNA。虽然这种情况可能发生在任何提供商身上,但 Google 上发生这种情况的频率更高。
这个故事经典地提醒了我们一个“1”规则:1 是 0,2 是 1(the rule of 1: 1 is 0, and 2 is 1)。谢天谢地,他们可以从其他提供商那里恢复。
参考链接:
https://cloud.google.com/blog/products/infrastructure/details-of-google-cloud-gcve-incident
https://news.ycombinator.com/item?id=40366867
https://www.infoq.com/news/2024/05/google-cloud-unisuper-outage/
https://www.reddit.com/r/devops/comments/1co8qbi/google_cloud_accidentally_deletes_unisupers/




