
编者按:
随着企业数字化转型步入深水区,设备数量增加,业务系统更加复杂,除了要保证物理硬件的稳定性和可靠性,运维目的和手段也发生了深刻变革。对此,龙蜥社区系统运维 SIG 组 Maintainer、统信软件资深操作系统研发工程师高冲从系统运维的趋势与挑战、系统运维 SIG 组项目及未来展望和规划三个方面,带我们了解操作系统运维和可观测性。本文整理自 2022 年阿里巴巴开源开放周技术演讲,视频回放已上线至龙蜥官网(首页-动态-视频),欢迎大家观看。
一、系统运维的趋势与挑战
随着企业数字化转型步入深水区,设备数量增加,业务系统更加复杂,除了要保证物理硬件的稳定性和可靠性,运维目的和手段也发生了深刻变革,通过平台化和智能化保证运维环境的实时性、数据安全性和业务连续性。
运维的整个发展历程主要有下面四个阶段:
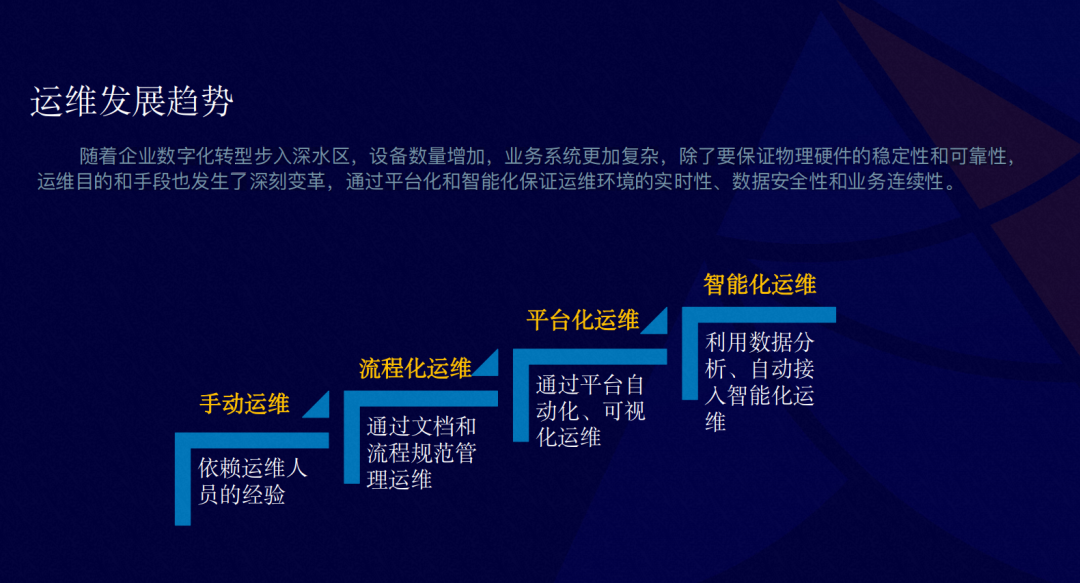
从最初的手动运维,依赖于运维人员的经验,发展为流程化的一个运维,依赖流程的规范化管理来实现运维,前两种的运维方式为企业带来很大的运维成本,现阶段的主流运维方式有两种:
平台化的运维。通过平台化的自动化和可视化的运维,来大大减少企业运维的成本。
智能化运维。随着数据分析、人工智能的技术引入,慢慢地我们也会介入智能化运维。
下面为大家介绍下运维业务的架构。
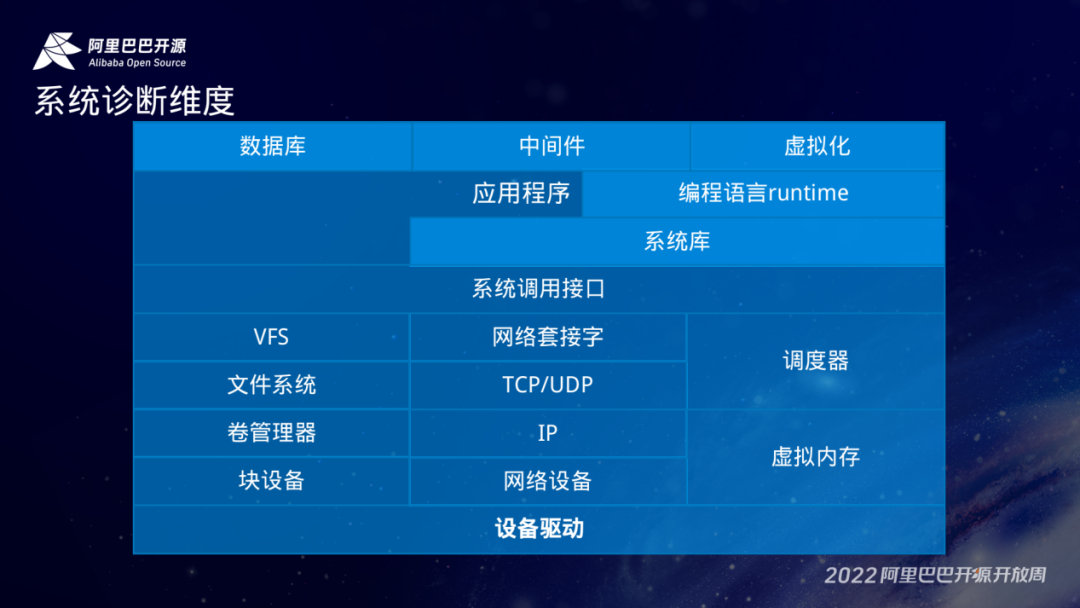
最底层的是对于硬件的一个运维,通常就包含硬件的一些信息,比如温度、读写寿命、风扇转速等等。再往上层就是对操作系统的运维,还有是通过外挂的一些运维,比如 IPMI 协议,通常比较常见就是 BMC 。
在整个系统的运维方面,其实有两大部分,一个是管控,另外一部分是诊断。
1、管控主要分为三个方向:
第一是资源管理。首先就是对资源的一个纳管,比如说主机的一些纳管。另外就是监控,如对资源的一些监控,包含 CPU 的算力、磁盘的使用情况、带宽、内存,最后是对资源的分配。
第二是配置管理。它包含有三部分:安全、包管理、自动化。在整个运维方向来看,其实都视为是配置。配置中的安全一个是 CVE,还有一些是配置项的安全,比如说端口扫描都属于安全。另外是包的管理,现在比较主流的有两种:一个是 RPM 包,另一个是 deb 包。包管理其实就包含这个包的升级回退、版本控制。最后就是自动化,也是相对比较重要的一部分,比如说我们配置的批量下发、定时任务,还有一些模板下发。
第三就是权限管理。权限管理分两部分,一部分是用户权限控制,相对比较常见的 RBCA。另外是审计,包含行为审计和日志审计。除了审计,还有一部分是危险拦截,比如拦截危险命令的操作、提权操作等。
2、另外比较核心的一块是 SLI:
SRE(站点可靠性工程)的概念是由 gongle 创建出的, SLI 是指度量系统可靠性的测试指标。OS SLI 通常有可靠性、可用性、性能等方向,OS 通常为延迟、吞吐量、相应时间、准确性、完整性。一部分 SLI 是传统式主动触发,比如说网络延迟抖动发生的时候,运维人员去调用相关的 SLI 一些工具,做下钻式的分析或者是我们去利用凌晨或者定时巡检来发现问题,类似于轮询这样的方式。
传统的 SLI 的采集是通过系统调用获取系统信息,比较耗费资源的。目前比较火的 eBPF 技术就解决了底噪占用高和安全的问题,可以结合一些基本处理手段来获取更有价值的数据。
以上介绍的管控和诊断,我们都会通过这两块业务收集到数据,也就涉及到数据处理。
数据处理,目前有四个方向的处理方式:
一个是时续化的数据处理。我们将整个诊断,还有管控的数据做一个时续化的处理来帮助运维人员做一些更好的、更深层次的分析。第二就是一些性能的分析,需要对整个性能做负载画像。第三系统的各个的方向实际是相对比较复杂的,我们需要利用一些算法做聚合分析。最后就是异常检测。比如 IO 的一个延迟,需要对 IO 企业的时间或者读时间比较长,做一个离群检测分析。
有了这些数据之后,我们会对数据利用运维的一些经验或者 AI 技术,做一些智能化的一些介入,当然也包含告警。
结合传统运维工具和 eBPF 技术,我们可以对整个系统的进行全栈观测。从最底层,比如 CPU 的诊断来说,我们可以利用 CPU frequency 去看到每个进程在对 CPU 的一个调动频率的观测。再到上层的一个设备驱动、网络,还有文件系统,系统调用等,都是可以利用 eBPF 技术来做到很深层次的观测。
那同样的对用户态的一些进程,比如说数据库、中间件或者是 runtime 的一个状态都可以就是利用 uproble 技术去做观测。
二、龙蜥社区系统运维 SIG 核心项目技术实践
系统运维 SIG 组(Special Interest Group)是致力于打造一个集主机管理配置部署,还有监控报警、异常诊断、安全审计等一系列功能的一个自动化运维平台。目前 SIG 组有三个核心的项目:一个是 SysOM,提供一站式的运维的管理平台。SysAK 是系统的一个分析诊断套件,也是核心驱动 SysOM 一些诊断功能的技术底座。最后是比较前瞻性的 coolbpf,是对 BPF 编译套件的增强,包括一个远程编译的技术。还有是对低内核版本的在 eBPF 上特性的回合。目前整个 SIG 组比较活跃的,PR 提交了有一千多。
下面为大家介绍一下 SysOM 的整个的架构。SysOM 的架构核心是分为两部分,一个是 server 端,另一个是 client 端。
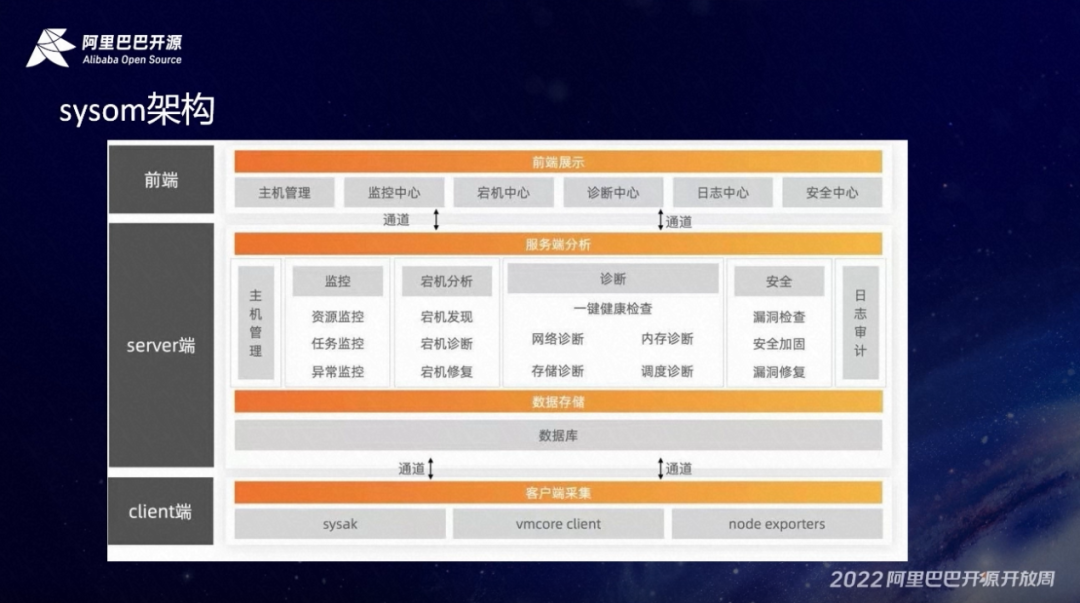
前端主要是 dashboard 的展示。有主机管理、监控中心、宕机中心、诊断中心、日志中心和安全中心,主要是负责和用户的一个 UI 交互。后端是负责一些核心的技术实现。比如说监控,有资源监控(目前是通过 prometheuse 的 exporter-node 去实现资源的监控)、任务监控、异常监控。还有宕机分析、诊断,依托的是 SysAK 的一些功能去做到网络诊断、存储诊断、内存诊断和调度诊断。最后在安全这一块,主要包括漏洞检查、漏洞修复,加固以及日志审计。
整个的后端存储有两部分,一部分是关系型数据库,就是 RDB,还有一个就是时序性数据库。
client 包含 SysAK 负责提供系统的性能和故障诊断。vmcored client 主要是负责提供诊断信息的收集。node exporters 负责整个资源的一个诊断,还包含时序化的处理、回传 prometheus。
那下面我将是通过前端的展示,为大家直观的了解 SysOM 整个的功能:
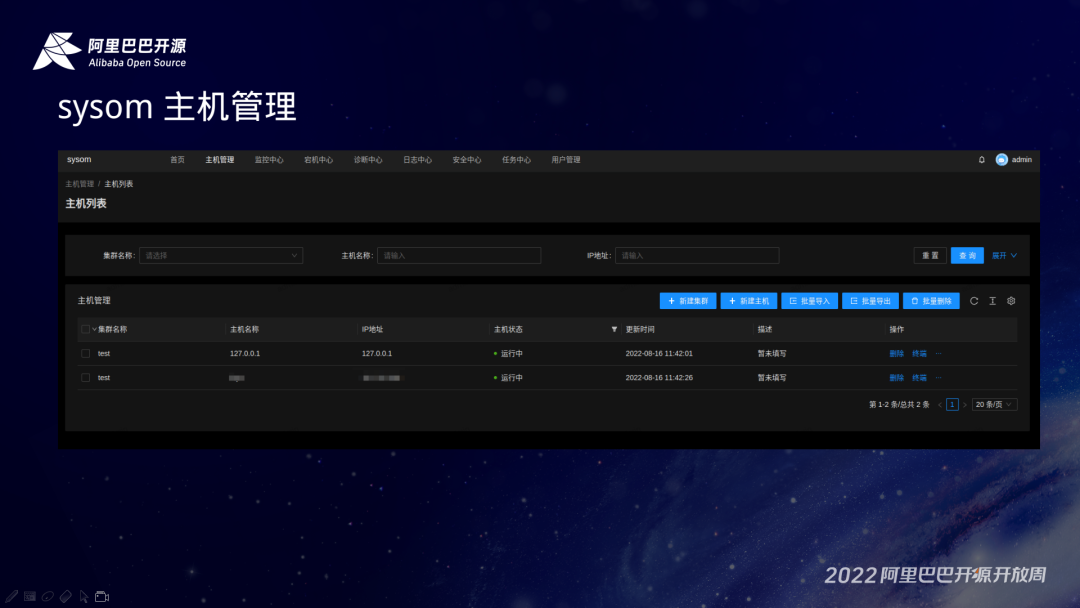
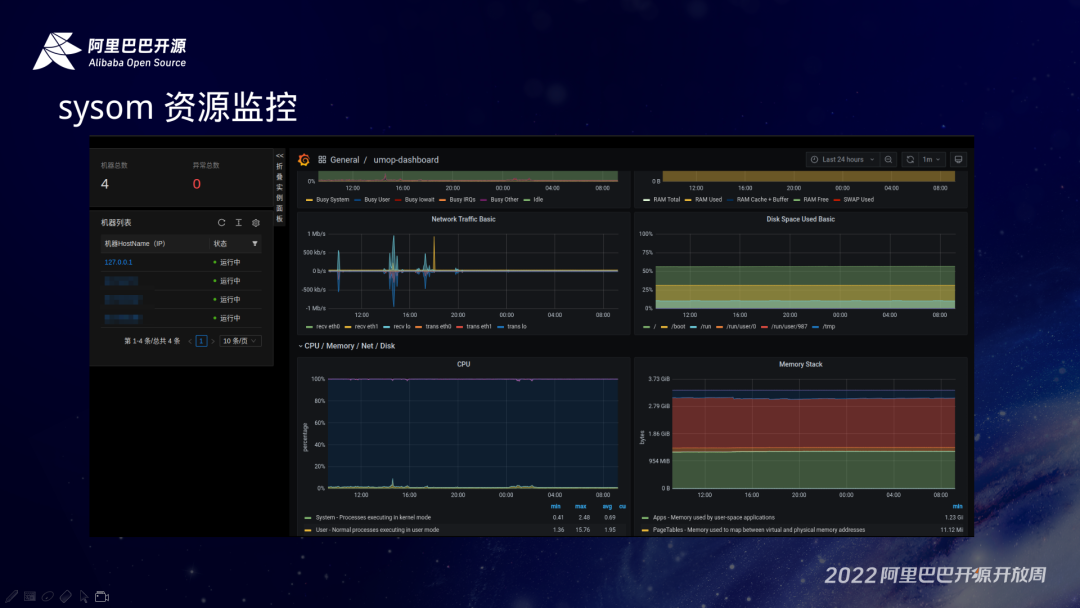
SysOM 主机管理,支持批量导入导出、集群化管理,当然也支持远程的终端。监控中心集成了一些常用的资源的配置项。比如说磁盘、CPU 算力,还有网络带宽的使用情况,也包含一些关键进程的监控,还有网络的延时情况。
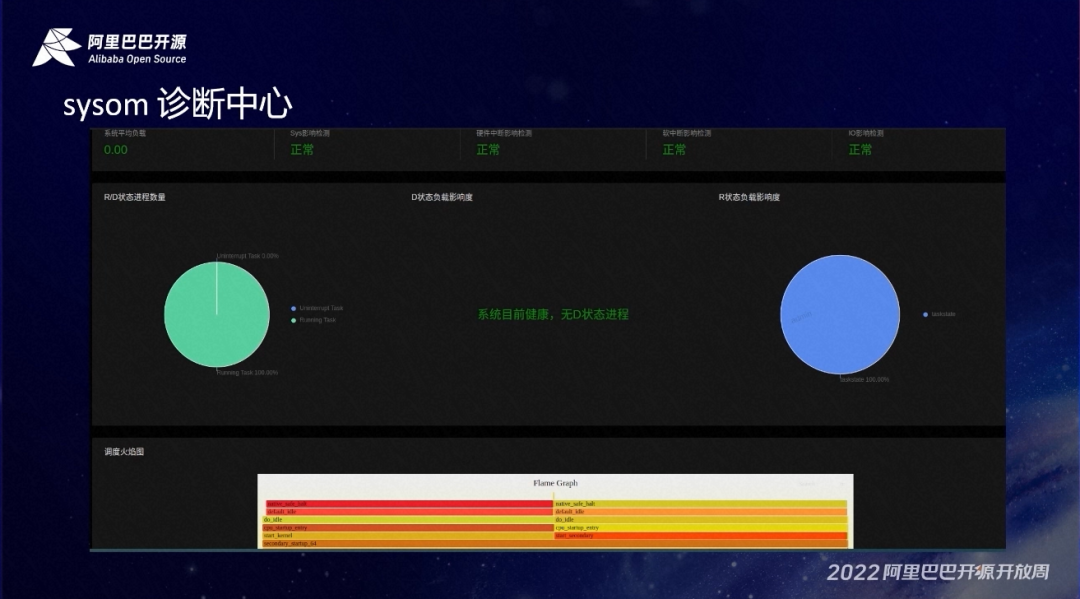
SysOM 诊断中心,也是相对比较核心的功能。我们目前对系统做了 SRE 诊断,另外也包含整个的软硬件诊断的情况,还有 IO 诊断,也去做了系统的低状态的检查。性能包括系统的调度的使用情况做了火焰图的分析,这样我们也就能够通过很直观的去看到系统的一些瓶颈、性能的问题。
也包括可用性的检查,我们做了静态的一些配置项检查。比如说调度、内存和 IO 网络去通过和我们专家经验去做对比,分析出性能或者是一些故障隐患。
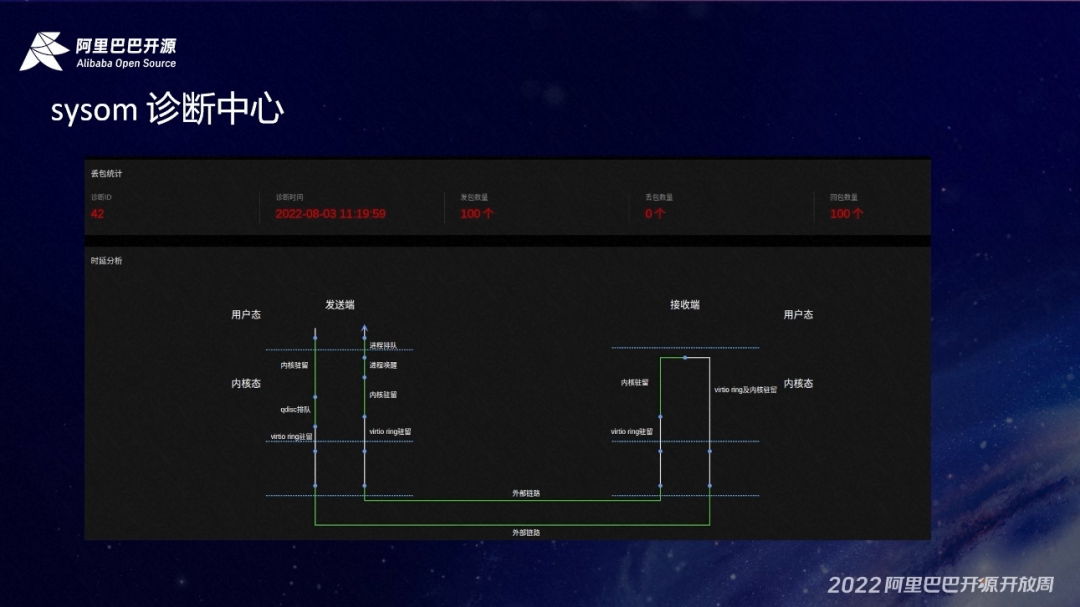
SysOM 比较有亮点的两个功能:网络诊断和 IO 诊断。我们现在从单时报能看到的是网络诊断,通过从 server 端发包给 agent 端,然后把整个调用链,在每个阶段平均的耗时计算出来,通过一个直观的图展示出来,也可以通过鼠标的悬停去看具体的某个阶段的耗时情况做一个下转式的分析。比如下图对用户态的整个内核的实验做了分析:
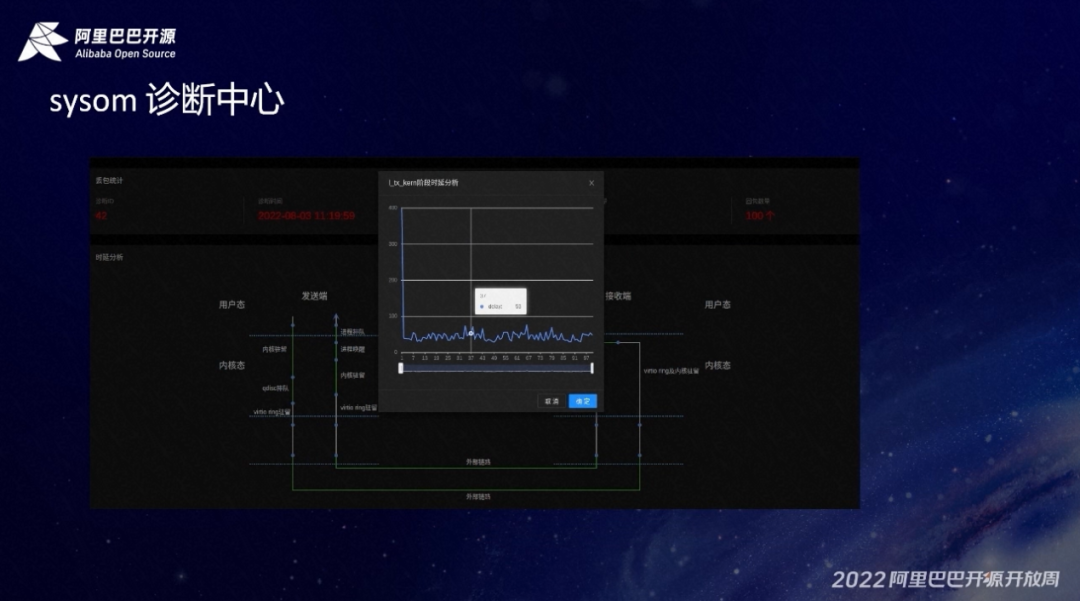
从上图中我们能看到它整个的一个平衡平均耗时是三十七毫秒。但是在具体的某个时间段是有一定的波动的。
整个 SysOM 的功能是相对比较多的,也欢迎感兴趣的小伙伴可以做一些有趣的探索。
最后是 SysOM 安全中心。安全中心通过是 errata 的机制,结合 Anolis 的公勘去做了漏洞的一个实施,定期扫描。当然也是支持漏洞的第三方配置。我们通过比如说配置漏洞数据库,接入第三方的一些数据库来增强整个系统或者是运维环境的安全性。
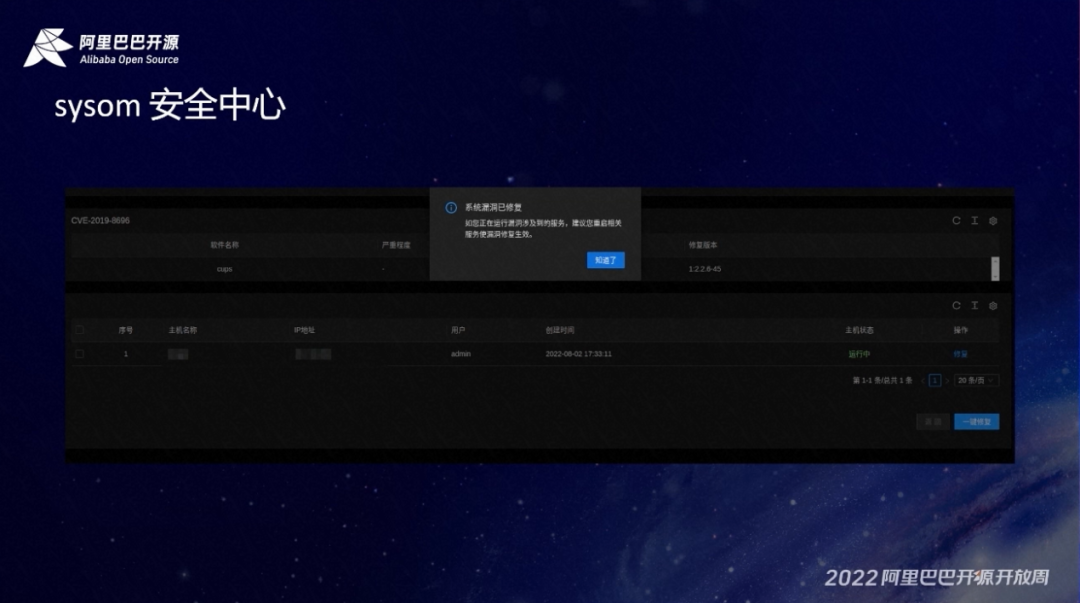
那对一些高危的或者是需要我们重启的一些 CUE,我们在修复之后也是会给出相应的提示。如重启服务或者说内核需要重启系统来生效。
以上是整个 SysOM 相关内容的介绍,关于 SysAK 和 coolbpf 相关介绍可以通过 SIG 组了解,也希望大家参与到系统运维 SIG 组,大家一起来多多贡献。
三、展望和规划
目前 eBPF 提供了一种全新的动态插桩技术,为运维的性能和故障诊断带来新活力。统信软件也将持续贡献在 OS 方向的专家运营经验,携手龙蜥社区一起把系统运维 SIG 组做好,也把龙蜥生态做好,未来也将会在故障诊断、安全和权限管理持续发力。




