
一、什么是数据倾斜
数据倾斜即指在大数据计算任务中某个处理任务的进程(通常是一个 JVM 进程)被分配到的任务量过多,进程运行时间超长甚至最终失败,进而导致整个计算任务超长时间运行或者失败。外部表现的话,在 MR 任务(如跑 HiveSQL)里看到 map 或者 reduce 的进度一直是 99% 持续数小时没有变化;在 SparkSQL 任务里则是某个 stage 里,正在运行的任务数量长时间是 1 或者 2 不变。总之如果任务进度信息一直在输出,但内容长时间没有任何变化的时候,大概率是出现数据倾斜了。有个特例需要注意,有时候大家会看到 SparkSQL 的任务信息也显示有 1 到 2 个任务在运行中,但进度信息不再刷新而表现为假死很久的时候,这通常是在进行最后阶段的文件操作,并不是数据倾斜(虽然这通常意味着小文件问题严重)。
再细分一下,倾斜可以分为以下四类:
1)读倾斜。即某个 map(HiveSQL)或者 task(SparkSQL)在读取数据阶段长期无法完成。这通常是因为文件分块过大或者此分块数据有异常。这种场景出现频率较小。
2)算倾斜。即在某个需要排序(如开窗函数或者非广播关联时)或者聚合操作的时候,同一个 key(通常是一个或者多个字段或者表达式的组合)的处理耗时过长。这通常是最多的情况,情况也较为复杂。
3)写倾斜。即某个操作需要输出大量的数据,比如超过几亿甚至几十亿行。主要出现在关联后数据膨胀及某些只能由一个 task 来操作(如 limit)的情况。
4)文件操作倾斜。即数据生成在临时文件夹后,由于数量巨大,重命名和移动的操作非常耗时。这通常发生在动态分区导致小文件的情况。OPPO 已在国内和印度及新加坡三区域集群上线了自动小文件合并的功能,其中基于亚马逊科技的小文件合并功能尚属业界首创,相关分享实践参看Spark小文件合并功能在AWS S3上的应用与实践。
二、为什么会有数据倾斜
大数据计算依赖多种分布式系统,需要将所有的计算任务和数据经过一定的规则分发到集群中各个可用的机器或节点上去执行,最后可能还需要进行汇总到少数节点进行最后的聚合操作,以及将数据写到 HDFS/S3 等分布式存储系统里做持久化。这个过程的规则被设计来应对大多数情况,并不能应对所有的情况。它具有以下几个限制:
1)业务数据分布规律无法预知。比如系统无法不经过计算而提前知道某个表的某个字段的取值分布是否大致均匀。
2)计算结果数量无法预知。比如两表关联的结果对于某些 key(关联的一个字段或者多个字段组合)的输出行数无法不经过计算而预知进而针对性处理;又比如对某个字段的值进行 split 操作或者 explode 等操作后产生的结果数量无法预知而进行针对性的应对。
3)某些操作只能由单一节点进行。一切需要维护一个全局状态的大多数操作,如排序、Limit、count distinct,全局聚合等,一般会安排到一个节点来执行。
上述限制有概率导致在单结点上处理巨量的数据,造成了所谓的倾斜问题。当然,这些困难并不是理论上不可解决的。随着时间的推移,越来越多的针对性的优化措施已逐渐出现(如 Spark3 已经能自动应对部分数据倾斜的情况了),也许在不久的将来业务同学不会再被倾斜问题烦恼,但现阶段还需要数据开发工程师主动关注并应对。
三、典型案例
以下展示一些日常工作较为典型或者困难的数据倾斜样例,供大家参考。由于 OPPO 主推 SparkSQL,因此以下案例将主要以 SparkSQL 的角度来展示。
在这里我必须要强调一个原则:如果发生了数据倾斜,有不少的概率是业务逻辑不合理,因此需要跟业务方反复确认逻辑的合理性。优化业务逻辑一定要高过优化技术方案。
3.1 写倾斜 - 事实表关联事实表数据膨胀
OPPO 有业务同学提出一个比较麻烦的问题,就是事实表关联事实表,其中有若干个 key 的输出达数十亿行,数据膨胀严重,造成数据输出的倾斜。比如以下场景:
在反复确认了业务逻辑是合理的前提下,我们统计了两个表的倾斜 KEY 值分布:
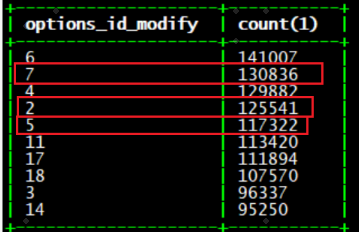
a 表:
b 表:
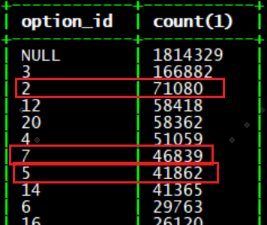
大家可以看出,只看 option_id=7 的关联结果最后是
46839*130836=6128227404,即 61 亿行;
option_id=2 的关联结果是
71080*125541=8923454280,即 89 亿行。
属于严重倾斜的情况。
这种事实表关联事实表的情况在非报表类的计算任务偶尔会遇到。平时我们解决数据倾斜主要是计算结果的过程涉及太多数据要处理导致慢,但通常输出的行数可能并不多,不存在写的困难,所以类似过滤异常数据或者广播关联等方法都不起作用。
这个问题的本质是一个 task 最多由一个进程来执行,而相同的 key 也必须在同一个 task 中处理,因此在无法改变这个机制的前提下,我们只有想办法减少一个 task 输出的行数。
那如何在不影响最终结果的前提下,减少单个 task 所需要处理数据行数呢?
其实网上也有许多建议,都是单独处理倾斜的 key,通过加前缀后缀等方式打散 key,再最后合并处理,但这样做法太麻烦了,不够优雅。我们要追求对业务同学更友好,代码更优雅的方式。
最后我寻遍所有可用的系统函数,发现了 collect_set/collect_list 这个聚合函数,可以在保证数据关系不丢失的前提下将数据收拢减少行数。比如以下两行:

可以收拢成一行:

最后再通过 explode+lateral view 的方式,可以实现一行展开为多行,从而还原成用户最后期望的明细结果方式。
上述办法的核心是将原来倾斜的操作(同一个 key 关联),修改为不再相互依赖的操作(一行变多行)。
最终代码如下:

以上代码里值得注意的地方:
代码里的 hint(repartition(1000))的作用是考虑到经过 collect_list 聚合后的数据单行携带的数据经过一行变多行的展开操作后会膨胀很多倍,因此单个任务处理的数据量必须很小,才能保证处理速度够快。这个 hint 的作用是告诉系统将上一阶段关联后的结果分成 1000 份,交给下游处理;
group by 语句里的 ceil(rand()*N) 作用是将一个 key 分成最多 N 行,这样可以限制最后按 key 关联后生成的行数的上限。
经过验证,原来无法完成的任务,20 分钟任务就完成了,生成了近 800 亿行的数据,其中包括了 19 个超十亿行的 key,满足了业务需求。
3.2 算倾斜 - 避免排序
在单机数据库里(mysql,oracle 等)进行排序操作是非常常见的;但大数据中动辄上亿行的数据,如果有排序(order by 和 sort by)的需求而且数据量巨大的话,通常会产生溢写磁盘的操作,非常耗时,且容易造成 OOM 异常。幸运的是 99.99% 的大数据场景下,完全的排序都是不必要的,因为业务通常需要的是统计信息而非具体某一条记录的细节信息。由于多数大数据数据开发同学是从传统单机数据开发转行过来的,经常会写上排序关键字,引发性能问题。下面介绍 2 个通过改写代码从而避免排序的案例。
(1)用 max 函数替换排序
最近收到一个同事的业务需求,需要对某个业务的埋点数据做一次样本展示,要在约 1200 亿行数据中,捞出约 1 万条数据。很简单的一个 SQL 如下:

稍微解释一下 SQL 的意思:希望取出上报数据里针对某个维度组合的一条内容较为丰富的样本数据,因此以某字段的 size 作为降序排序并取结果的第一条。
这个 SQL 当然跑失败了。我对 partition by 的字段集合(后续简称 key)进行了统计,最大的 key 有 137 亿行,另外还有至少 10 个 key 的数据量超过 20 亿行。这样 executor 的内存加得再大都无法跑成功了。
既然用户只需要排序后的最大的一条,本质上不就是取某个 key 的最大值嘛。取出这个最大值,最后再跟源表进行关联,就可以取出最大值对应的那一条数据了。其他的记录的序号计算其实都是多余的操作。
但这里有个前提条件,要想在第二步关联回源表数据的时候干掉排序,我们只有走一条路:广播关联(如果走 sort-meger 关联,还是会避免不了 sort 步骤)。这就要求我们的小表(key-最大值)要足够小。通常这个条件都会满足的,因为如果不满足的话,说明 key 值非常多,非常稀疏,也不会产生倾斜的困境了。如开始就说明了,最后 Key 的去重数据量不到 1 万条,完全可以走广播关联。
最后的代码如下:
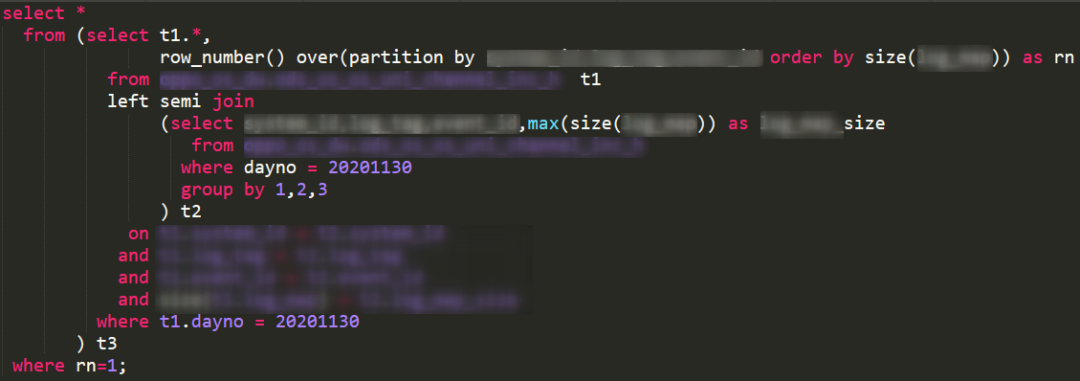
注意上述 SQL 有两点说明:
我们使用了 semi join,这在日常代码中比较少见。它的意思是,左表去匹配右表,如果一旦发现左表的某条数据的关联 key 在右表,便保留此条左表的数据,不再继续在右表里查找了。这样做有两个结果:1)速度更快;2)不会把右表的数据放到结果里。
它等价于 select * from left_table where key in (select key from right_table)。但大数据发展过程中一度不支持 in 的用法(现在部分支持了),因此有这种语法,从效率上看,一般认为这样更高效。
因为能匹配到最大值的数据可能有许多条,所以对最后结果再做一次 row_number 的开窗并取其中一条即可。这个时候由于 size(xxxx) 的值都是一样的,因此任意取一条均符合业务需求。
在一般情况下,上述 SQL 能较好的运行。但我们这次情况出了点意外:经过上述操作后,我们得到的数据还有 800 多亿行。因为 max(size(xxxx) = size(xxxx) 的数据占了绝大多数,导致我们匹配回去无法有效的筛选出少量结果。我们必须找到一个能有效区分各行数据的字段,这个字段的值必须很松散。最后我发现比较好的是 userid。因此将 max(size(xxxx)) 替换成了 max(userid),任务很快就跑完了。因为不影响我们讲述优化的原理,所以不再描述这部分细节。
(2)用分位函数替换排序
在一个画像任务相关跑得很慢时,业务同学求助于我们,发现慢的代码如下:
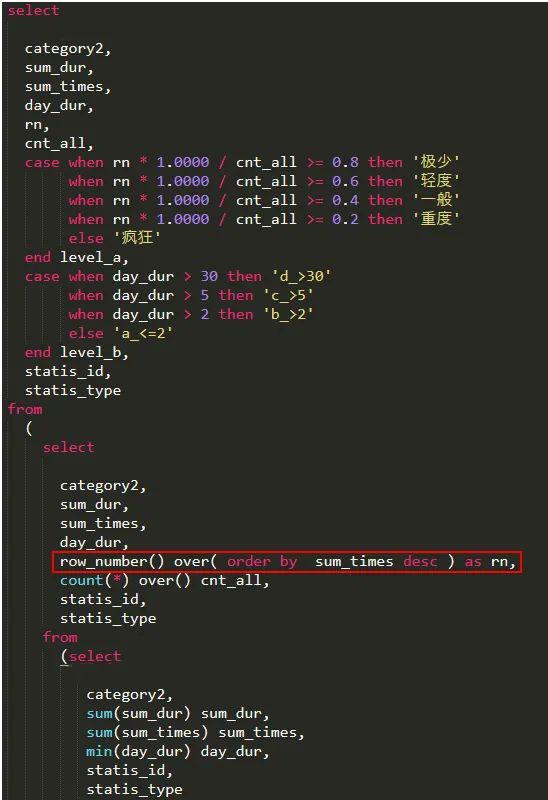
问题点:上面的代码是想做一个全局排序,然后使用其序号所在位置来进行分类打标。上述代码在排序数据小于 5 亿 5 千万行的情况下勉强能运行出结果。但在某一天数据量到了 5 亿 5 千万行后就跑不出来,加了 reducer 的内存到 10G 也不行。
新思路:虽然可能还有一些参数能调整,但我认为这不是正确的方向,于是停止了研究,把方向转为干掉全局排序。在和一位前辈沟通的时候,突然意识到,既然业务是想做一个分档,本质上就并不需要具体的排序号,所以理论上完全的排序是可以省掉的。于是自然想到了分位数函数,立马想到了新方案。分位函数用于计算出某个值,大于这个值的数据行才能处于整个数据排序的某个百分比位置。
改之后代码如下:
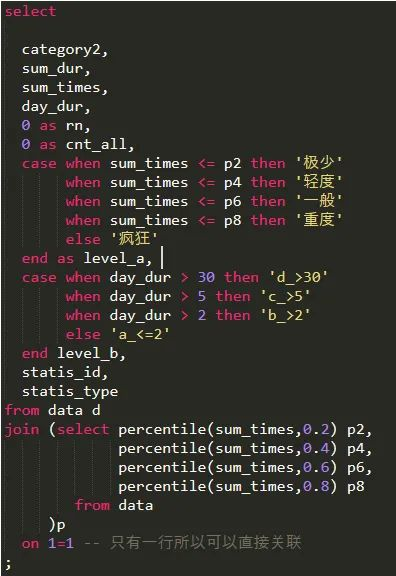
注意上述代码有个小技巧,即与只有一行的子查询结果进行笛卡尔积关联,从而变相的实现了引入 p2 到 p8 等 4 个变量的效果,还算实用。
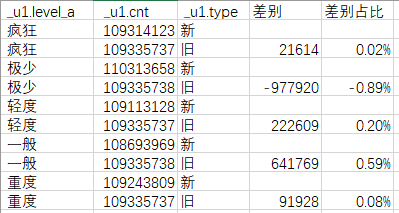
效果:对比了新旧算法的结果,差异极小,也在预期范围内,业务表示接受。
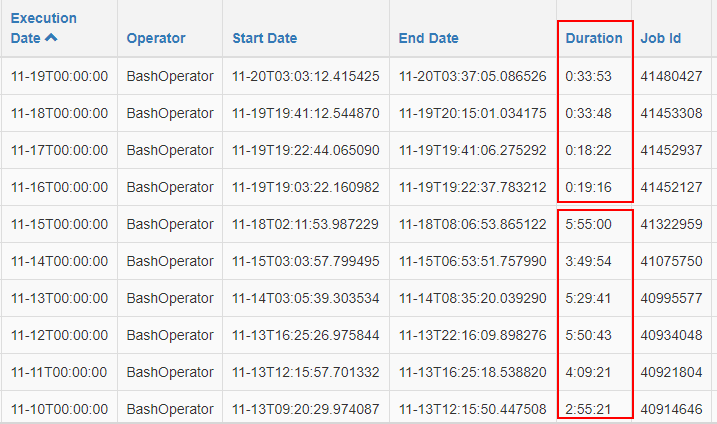
再对比了任务执行时间,约有 87% 的降幅:
这个案例的本质在于识别出了费尽资源计算的全局序号是完全不必要的,业务真正的目的只是找到一个评价的档位而已。
(3)通过广播关联彻底避免排序
SparkSQL 目前处理关联( join )的方法主要有两种:
a) 广播关联。小表(通过参数 spark.sql.autoBroadcastJoinThreshold 控制,目前我们的默认值是 20M)的话会采用广播关联,即将小表的全部数据传输到各节点的内存中,通过直接的内存操作快速完成关联。这种方式最大的好处是避免了对主表的数据进行 shuffle,但会增加任务使用的内存量。另外特别说明 3 点:
目前 sparksql 优化器尚不能非常准确地判断一个子查询结果(也被当成一张小表)是否适合进行广播;
左表无论大小都不能被广播;
某些情况下会有类似:Kryo serialization failed: Buffer overflow 这样的 OOM 出现,并 “To avoid this, increase spark.kryoserializer.buffer.max value”。但其实这样设置会无效。实质原因是:虽然某张表小于 32M,但由于高度压缩后,解压结果的行数达到了数千万,造成了节点的 OOM。这个时候,只能手动禁掉广播关联。
b) Sort-Merge 关联。即先将两表按 join 字段进行排序,然后在此基础上进行匹配关联。由于数据是排序过的,只需要一次性的匹配即可完成最终的关联,不需要往复查验,速度较快。但这种方法的弊端是要进行对关联 key 的排序,并且每个相同的 Key 和对应的数据必须分配到一个 executor 里,引发大量的 shuffle 操作;另一方面如果一个 executor 需要处理一个巨量的 key,通常会花费大量的时间以及大量的磁盘 IO。
通过上述原理描述可以看出如果采用广播关联,引擎完全不用做任何排序和 shuffle,自然也不会有相应的倾斜的可能性,这是效率巨大的提升,当然代价就是会增加内存占用。一般来说这种内存使用的增加被认为是划算的。
如果引擎没有识别出来,我们可以通过主动指示(hint)的办法影响执行计划。比如以下代码:
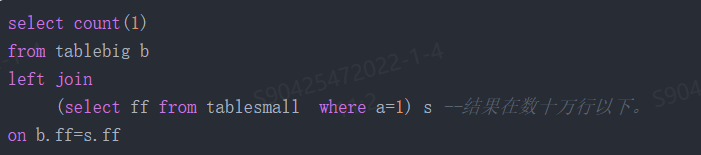
要让执行计划改成广播 s 子查询结果,加 hint mapjoin (也可以是 broadcast)就可以了。
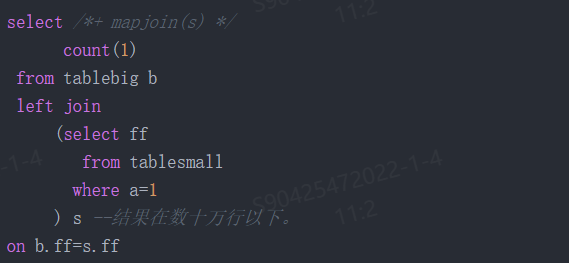
从实际的结果看,广播关联的提速都非常喜人。
3.3 算倾斜 - 非法值过滤
这应该是网上讲得比较多的情形,我也简略说下。在优化某任务的时候,我们发现运行时间一直在增长,一度达到 7 个小时,直到 8 月 1 号便再也跑不成功,总是 OOM(内存不够),即使将 executor 的内存调高到 10G 依然解决不了问题。经过仔细诊断,发现任务慢在一个开窗函数阶段,代码如下:
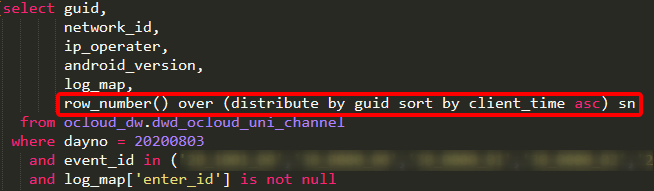
在对 guid 这个 key 进行初步统计后,发现为空值的数量竟然有数亿行,并不断增长:
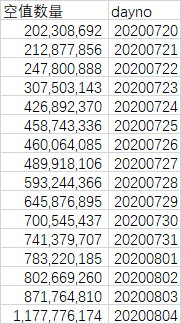
这也就解释了运行时长不断增长,排序的内存开销和时长都不断增长,直到某个阈值连加内存也不管用了。经过和业务同学的沟通,确认空值无意义,进行排除过滤。然后在默认的参数下进行了重跑,30 分钟内就跑完了。耗时下降约 90%,效果明显。
这个例子里,倾斜值恰好是无效的可以直接过滤,比较幸运。那同学们会问,如果倾斜值是有价值的怎么办?通常来说是需要将这类倾斜值单独拎出来以另外一套针对性的逻辑来计算,然后将结果 union all 回到其他非倾斜的数据计算结果里。我不推荐大家使用对倾斜字段加盐(加上随机的前缀和后缀以伪装成不同的 key),因为会让代码不够优雅,同时掩盖了数据质量问题。更重要的还是优先从业务上排查这些倾斜的值的合理性,尽量保证从最初源头消灭异常。
四、结语
数据倾斜处理的情况基本上局限在上述案例分类里,相信大家稍加学习都能掌握。总结一下核心的点:
1、分布式数据处理系统无法预知输入和输出的数据量,加上单节点处理有限,造成了倾斜;
2、大多数情况下业务逻辑不需要完全排序;
3、一切的优先从业务逻辑着手,从源头处理脏数据,不要把倾斜带往下游。
本文作者简介:
Luckyfish,OPPO 大数据基础平台 SRE 及服务负责人。主要负责公司大数据平台 SRE 及用户支持工作,曾供职于京东科技,有较丰富的大数据任务开发和性能优化经验,同时对产品体验及成本优化工作有较多兴趣和经验。




