
直到最近,我们都和许多公司一样在基于 Java 或 Scala 的那几种技术(包括 Apache Spark、Storm 和 Kafka)中选一种来构建我们的数据管道。但 Java 是一种非常冗长的语言,因此用 Java 编写这些管道时需要大量样板代码。例如,bean 类这么简单的东西也需要编写多个常规的 getter 和 setter 以及多个构造器和/或构建器。一般来说,哈希和相等方法必须用一种很平常但啰嗦的方式覆盖掉。此外,所有函数参数都需要检查是否为“null”,为此需要多个污染代码的分支运算符。分析哪些函数参数可以或不可以为“null”是非常耗时的(而且很麻烦!)。
处理那些用 Java 编写的管道出来的数据时,往往需要基于管道数据的类型或值来做分支,但 Java“switch”运算符的限制让人们不得不大量使用庞大的“if-then-elseif-...”构造。最后,大多数数据管道使用不可变数据/集合,但 Java 几乎没有对分离可变和不可变构造的内置支持,于是人们只能编写额外的样板代码。
为了解决 Java 在数据管道方面的这些缺点,我们选择了 Kotlin 作为后端开发的替代方案。
为什么是 Kotlin?
我们选择 Kotlin 主要基于如下考虑:
Kotlin 中对数据 bean 类的丰富支持让我们无需再编写显式的 getter 和 setter。
可选参数和简化的构造器语法让我们无需再编写多个构造器和构建器。
“数据类”结构让我们不必再使用简单的样板代码显式覆盖哈希/相等函数。
内置的类型系统空指针安全保证不会跳过任何必要的空指针检查,并且我们会收到关于不必要检查的警告,从而大大减少样板代码。我们切换到 Kotlin 后,几乎没再见过可怕的运行时 NPE 异常。
用于分离可变数据和不可变数据的强大机制允许我们对并行数据处理进行更简单的推理。
通用的“when”运算符允许我们根据数据类型和值编写灵活简洁的分支表达式。
与 Java 的无缝集成让我们能继续使用所有 Java API,无需额外的心智负担。在 Java 中使用 Kotlin 接口也几乎不存在摩擦,并且我们在 Kotlin 中实现的 API 还被其他使用 Java 的团队用上了。
下面是 Kotlin 代码的一个简单示例,它展示了上面列举的一些要点:
enum class RequestType {CREATE, DELETE}data class RuleChange(val organizationId: String, val userIds: List<String>, val request: RequestType)Java 中的等效实现如下所示:
enum RequestType {CREATE, DELETE}public final class RuleChange { final private String orgraniztionId; final private List<String> userIds; final private RuleChange ruleChange; RuleChange(String organizationId, List<String> userIds, RuleChange ruleChange) { this.orgraniztionId = organizationId; this.userIds = userIds; this.ruleChange = ruleChange; } final public String getOrgraniztionId() { return orgraniztionId; } final public List<String> getUserIds() { return Collections.unmodifiableList(userIds); } final public RuleChange getRuleChange() { return ruleChange; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; RuleChange that = (RuleChange) o; return Objects.equals(getOrgraniztionId(), that.getOrgraniztionId()) && Objects.equals(getUserIds(), that.getUserIds()) && Objects.equals(getRuleChange(), that.getRuleChange()); } @Override public int hashCode() { return Objects.hash(getOrgraniztionId(), getUserIds(), getRuleChange()); }}这两段代码做的是几乎完全一样的事情。Kotlin 还有一些好东西我们没放在示例里面,它们需要额外的样板代码才能在 Java 中实现,但是这个示例已经足够说明问题了——Kotlin 代码更加简洁,并且为开发人员提供了很多免费赠品。
Kotlin 中的一个清晰的代码示例
Kotlin 简洁易懂的代码的一个很好的例子是我们的规则更改处理器 Kafka 流作业,它对输入数据进行空安全验证,使用扩展函数反序列化数据,然后使用详尽的模式匹配对数据执行操作。
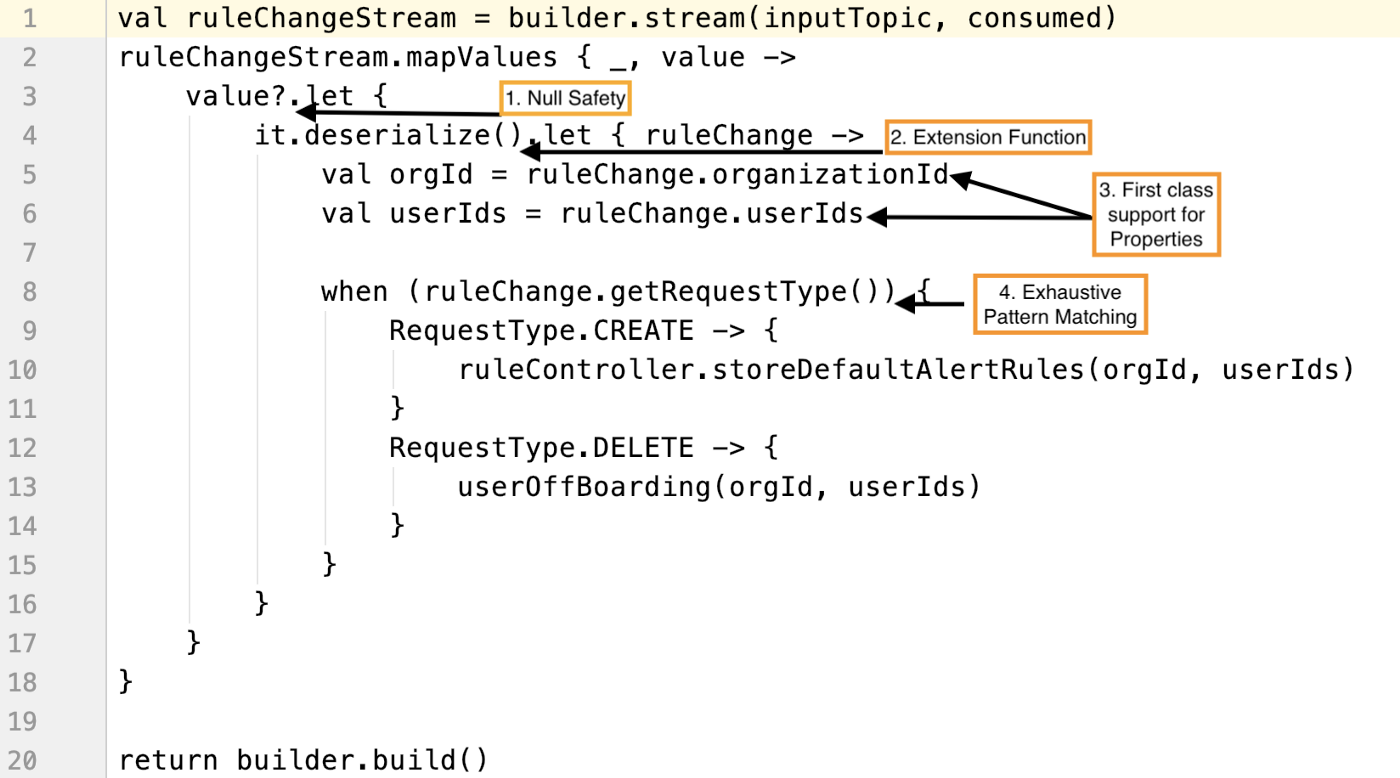
这里你可以清楚地看到 Kotlin 为我们提供的几个好处:
空值安全性:再也没有难看的的 if/else 空检查了。我们使用了 Kotlin 的内置空值安全性检查,它可以防止 NPE 并让代码更具可读性。
扩展函数:Kotlin 提供了向现有类添加新函数的能力,添加时无需继承该类。第 4 行的 it.deserialize()是不是看起来比使用一些辅助类来反序列化数据更易读?
对属性的一流支持:我们不需要编写 get/set 方法,因为 Kotlin 为属性提供了一流的支持,如第 5 行和第 6 行所示。
使用 when 构造的详尽模式匹配:从第 8 行开始,Kotlin 的 when 表达式对枚举值和 case 类进行详尽的模式匹配。使用 Java 的 switch 构造时我们必须编写 no-op default case,现在再也用不着了。
Kotlin 用于 Salesforce 的活动平台
活动平台(Activity Platform)是我们的一个大数据事件处理引擎,每天摄取和分析 100 多万次客户交互,以自动捕获数据、生成见解和推荐。
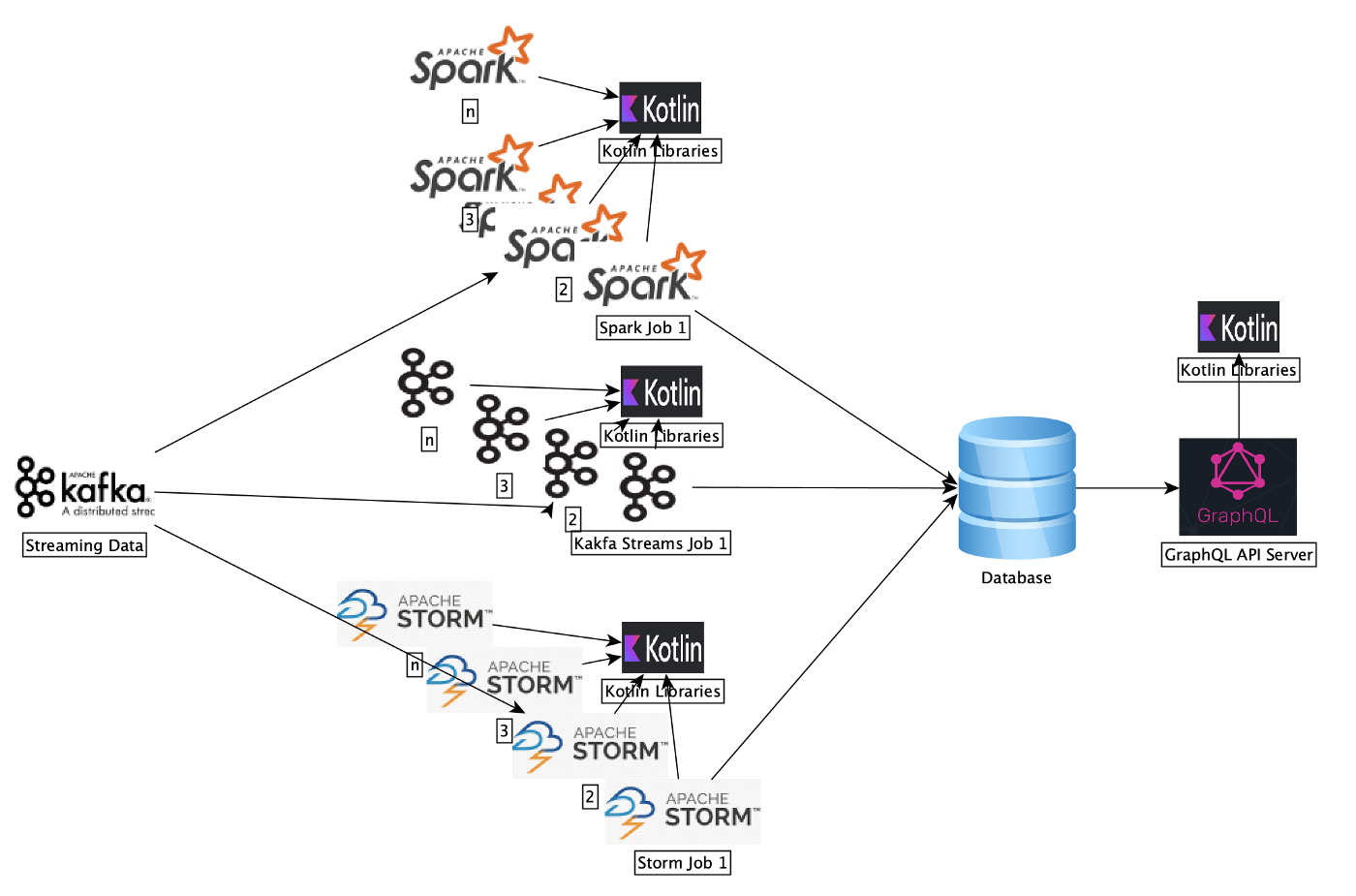
如上图所示,我们广泛采用了 Kotlin 代替 Java 进行跨活动平台的后端开发工作。下面是具体的流程:
我们以流媒体方式处理活动数据,并使用 AI 和机器学习生成智能见解,为 Salesforce 中的多种产品提供支持。
为了处理这些数据并生成见解,我们会运行一些大数据系统(如 Kafka-Streams、Spark 和 Storm)并公开一个 HTTPS GraphQL API 供其他团队消费数据。
我们用 Kotlin 编写所有业务逻辑库。
Kafka Streams 作业是用 Kotlin 编写的。我们使用 Kafka Streams 作业进行简单的映射、过滤和写入操作。
Apache Storm 拓扑是用 Kotlin 编写的。Storm 拓扑对我们的数据执行通用数据保护条例(GDPR)操作。
Spark 作业是用 Scala 编写的,但它们会消费用 Kotlin 编写的库。我们使用这些 Spark 作业运行复杂的 SparkML 模型。
GraphQL API 也是用 Kotlin 编写的,同时由一个 Jetty 服务器提供支持。
所以基本上来说,我们在所有可以使用 Java 或其他 JVM 语言的地方都改用了 Kotlin。
迁移到 Kotlin 后为我们带来的好处
当其他团队使用我们的库时,Kotlin 的数据类和不变性确保了一致性(防止意外数据损坏)。它的函数式语法和不变性为我们编写数据管道所需的处理流提供了一种优雅的方式。Kotlin 可以在一个文件中拥有多个类,并能够使用顶级函数,这让我们的代码组织起来更轻松了,大大减少了我们需要导航的文件数量。这篇博文中还没具体介绍 Kotlin 中我们喜欢的很多内容,例如扩展函数、类型别名、字符串模板、使用协程和 async-await 的并发代码执行等。
使用 Kotlin 构建数据管道可以获得很多好处,尤其是提升开发人员的生产力。让来自不同编程背景(如 Java、Scala、Python)的工程师上手 Kotlin 都是非常轻松的事情,而且他们都喜欢 Kotlin 提供的编程结构。这就是为什么它是 2020 年最受欢迎的编程语言之一。我们将继续扩大其采用范围,同时用它来构建新的管道、并将旧管道也逐渐切换到 Kotlin 上。当 Kotlin 对 Spark 的更稳定支持可用时,我们也有兴趣使用 Kotlin 来构建 Spark 作业。对于所有对构建数据管道感兴趣的读者,我们都建议大家尝试使用 Kotlin,看看它相对于其他编程语言有哪些优势。
原文链接:
https://engineering.salesforce.com/building-data-pipelines-using-kotlin-2d70edc0297c




