
出品|InfoQ 《大模型领航者》
访谈主持|霍太稳,极客邦科技创始人兼 CEO
访谈嘉宾|陈勇,吉利汽车研究院人工智能中心主任
作者|褚杏娟
“开车下班回家,路上可能没有什么事,那我可以跟大模型聊聊天,聊聊技术发展怎样、今天过得如何,可以做很多互动交流。我觉得这就是大模型上车后能够带来的一个方向转变。”吉利汽车研究院人工智能中心主任陈勇说道。
实际上,聊天只是开始。大模型一定程度上重新定义了汽车:汽车从原来的出行属性变成了社交属性,这背后带来的想象非常大。因此,大模型上车已经是车企的必答题,对于老牌车企吉利来说,亦是如此。
吉利汽车在 2021 年便开始策划自研大模型,当时的焦点还是基座模型,行业模型概念并不像现在一样成为共识。在各种不确定中,吉利汽车还是决定自己做大模型。
今年 1 月份,吉利便推出了全栈自研的全球首个汽车行业全场景 AI 大模型星睿大模型,该模型目前已经陆续应用在银河 L6、银河 L7 等车型中。从大模型研发到真正上车,吉利汽车用近 3 年的时间初步完成了这一探索。本期 InfoQ《大模型领航者》,吉利汽车向我们揭开了大模型上车神秘面纱的一角。
做大模型的“基本功”
“之前几年对我们来讲,是一种历练和成长。”
每个做大模型的开发者都要面临的难题是数据、算力、算法,吉利汽车也不例外。吉利汽车人工智能研发团队在构建自己的数据集上花费了很多精力。数据决定了大模型认知的天花板,而全面的数据才能训练出更加通用的模型,因此,这个数据集必须是高质量且全面的。“对于那个时候的我们来讲,构建数据集是非常难的一件事情,”陈勇坦诚道。
那么,大模型训练所需要的大量数据从哪里来?
以智能驾驶为例,智能驾驶的大部分数据是从实际道路上采集而来,但这种采集方式周期长、成本高、难度大。比如需要采集在上海下雪天的高架上前方有一辆车插进来的数据,这样的场景非常少难度也很高。
因此,吉利汽车开始思考利用大模型生成数据,前期用大量合成数据或虚拟生成数据训练模型,然后再用真实的道路数据做精调,来提升模型的准确率。这种方式在数据非常缺乏的产品开发冷启动阶段,也是适用的。
算力是模型研发的绝对制约因素。为解决这个问题,吉利大手笔构建了星睿智算中心。吉利的动作很快,从 21 年提出到 22 年建成,再到 23 年的正式揭牌,这个总投资 10 亿元、占地 52.12 亩、规划机柜 5000 架的智算中心,成为国内车企自建设备规模最大的智算中心之一。
根据官方披露的数据,星睿智算中心目前的云端总算力达 102 亿亿次每秒、通信网络传输速度达 800GB/s,存储带宽 4.5TB/s。结合算力调度管理算法和研发体系,吉利的整体研发效能得到了 20% 的提升,更是让星睿 AI 大模型训练速度直线提升 200 倍。
算法方面,吉利汽车组建了自己的算法团队,团队初期也踩了很多坑,比如在算法架构、加速框架的选择上就做了很多尝试,因为当时业内并没有确定的适用框架,团队需要不断试错找到最合适自己的。这个过程中,吉利汽车团队也与一些高校和机构开放合作,更快速地进行验证。
但在数据、算力和算法这大模型三要素之外,陈勇表示,更重要的是要把汽车行业的经验数据融入到大模型里,让大模型应用能够更符合业务发展需求。
汽车模型还可以更“垂”
“可能我们会因为一个声音喜欢上一个车。”
“虽然现在大模型企业很多,但 base 模型可能不需要那么多,垂类模型的需求会更多一点。”陈勇表示。
吉利本身做的是汽车行业的大模型,但在这个垂类下面,吉利做了更细化的分类。吉利星睿 AI 大模型可以看作是一个综合的模型平台,其中包含了语言大模型、多模态大模型、数字孪生大模型 3 大基础模型,并由此衍生出 NLP 语言大模型、NPDS 研发大模型、多模态感知大模型、多模态生成大模型、AI DRIVE 大模型、数字生命大模型 6 大能力模型。
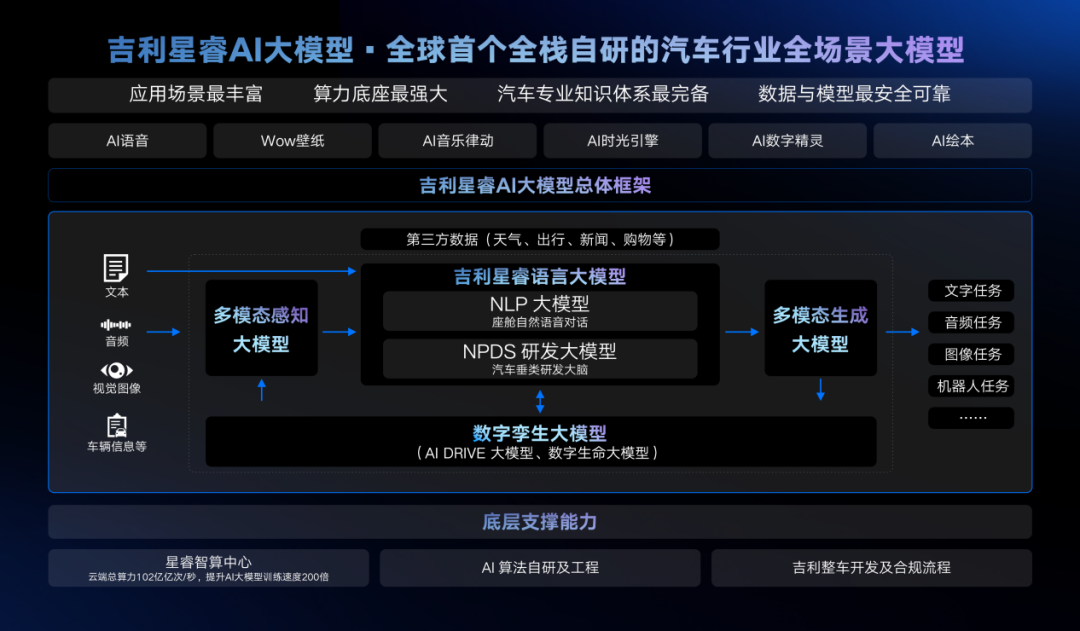
“做垂类的模型,还是要结合场景去做。”陈勇表示。
以智能座舱为例,之前的语音回应,都只是很简单的“好的”等,但如今用大模型做语音交互后,人们可以跟系统聊天,这时对语音技术要求变高了:人们会希望它声色像真人、说话有感情等,也就是说,车里的情感交互变得十分重要。
吉利汽车团队今年 4 月发布的 HAM-TTS 语音合成大模型,就可以合成自然流畅、富有情感的语音,并根据声音样本复刻出逼真的声音。语音交互模型的迭代优化需求来自用户,毋庸置疑也是未来吉利重点推进的方向。
陈勇还提到了另一种垂类模型,就是可以识别特定场景下的用户意图,比如车上有小孩子睡着时,空调应该设置成什么样等等。汽车摄像头可以识别到车内人的状态等“多模态”输入,都是大模型理解的信息来源。
在汽车中构建各种垂类模型并落地应用也是当前汽车行业重点思考的方向。
而在模型的部署上,云端模型协同已经成为业内共识。云端模型协同使用一方面可以让系统运行得更好,另一方面也更具有经济价值。“现在的大模型不经济,训练出一个模型要花很多钱。”陈勇建议要理性消费大模型。“不是说大模型来了后就替代了原来所有的东西,一个产品的定位技术要跟它的产品定位匹配。”
具体实践中,根据吉利汽车的经验,高频、高价值、低时延的需求可以部署在端侧,一些丰富生态的需求则可以在云端部署。比如,像智能驾驶动力系统这种对时间响应要求比较高的需求就适合端侧,而娱乐性的需求更适合云端。另外,端侧更适合做实时推理,云端更适合离线训练,云端训练完可以下传到本地,让本地端做车云协同。
自己先成为“受益人”
“用大模型讲笑话那就只能是讲笑话的钱。”
虽然吉利汽车是大模型的提供方,但首批获益的人可能并不是其用户,而是吉利汽车自己。
在陈勇看来,好的产品是企业的竞争力,好的组织也是企业的竞争力。“产品都比较卷,推出一个新产品后市场上会快速出现一批类似产品,可模仿性比较强。但是一个组织的竞争力是很难被模仿和替代的。”陈勇说道。
“如果利用 AI 加强我们的组织竞争力,用 AI 文化、AI 流程、 AI 体系、 AI 开发等系列逻辑体系大大提升我们的效率,那这个组织的竞争力构建起来后,可复制性的难度是很大的。”陈勇进一步补充道。他认为,这种竞争力相当于每个人底层的逻辑和文化,难以被拿走和替代。
基于此,吉利汽车构建了星睿智能体平台来提升组织效能,这个平台上有几百个面向不同场景的智能体,包括办公领域、产品定义、营销领域、软件开发等。吉利汽车的员工可以使用智能体应用来更好地完成工作任务。
比如,原来的一些开发工作,工程师要自己写代码、做代码注释,还要去做测试等。现在可能大模型可以帮着生成一些代码,然后工程师检查是不是满足要求,不满足稍微再改一改,这样的话就提升很多效率了。
“我们的员工可以解放更多的精力,专注把产品设计、产品创新、产品体验做得更好。”陈勇说道。
陈勇对大模型的期待,不止于此。
“大模型刚出来的时候,大家思考人工智能会不会替代我们的工作,但我觉得人工智能其实是让我们变得更美好、更幸福。”
在陈勇看来,未来人机协同、人机共存会变成一种常态,机器可以辅助我们去做很多事情。其中,具身智能是陈勇个人比较看好的方向。
“之前,大家更强调机器人的运动能力,但现在大模型相当于给机器人加上了一个大脑,有五官的感知能力,然后会运动、会思考决策,这种状态就是具身智能。”陈勇说道。
在陈勇看来,具身智能未来会慢慢走进人们的生活,尤其是家庭陪伴。“现在全球的老龄化程度越来越严重,有了大模型加持的具身智能作为陪伴,体验会更好一些。”另外,在工业场景中,尤其是在重体力、重复性和充满危险的工作环境中,具身智能完全可以替代人类劳作。
审视自己所处的行业,陈勇认为,汽车一定程度上也可以看作是具身智能:汽车本身有能源、有感知系统,加上大模型也会思考做决策,这就是具身智能的一个雏形。
当把思维放得更开一些,陈勇还设想“大脑 + 脑机接口 + 大模型”这种双脑协同工作,两个思想可以随时碰撞,可能让人机协同的融合度更高。
结束语
大模型上车后,整个行业都在等一个现象级产品的出现,但现在没人知道是什么。陈勇预计,这样一款现象级产品可能要两、三年后才会出现。
如今,大模型上车更多还是解决旧场景里的旧问题,车企们正在思考如何在新场景解决新问题。但汽车行业的路就是这样一步步走出来的。大模型能够上车的一个重要前提是,行业自身已经完成了动力结构从燃油到新能源的转变,但在新能源汽车来临时没有人能设想到大模型上车。如今大模型上车了,也没人能预测出未来到底会给汽车带来哪些变革。
谁能率先交出大模型上车的答卷,我们拭目以待。
华卫对此文亦有贡献。




