
本文介绍如何使用 NVIDIA 官方推荐工具和 K8S 插件,在谷歌云 GCP 的虚机上搭建用于机器学习任务的带显卡 K8S 集群。
另外,也介绍了如何更新 K8S 插件,来解决当带显卡 Node 维护重启时,由于 GPU ID 发生变化而导致训练任务无法继续的问题。该问题的描述可以参考在线记录。注意,该问题在使用各公有云虚机时都可能发生,触发原因是虚机维护重启后,从一台宿主机迁移到另一台宿主机,所配置的显卡实例也随之改变,显卡 ID 变化,而 NVIDIA K8S 插件在 0.9.0 版本之前不能容忍这个变化,而导致上层 Tensorflow 等应用无法在重启后获取到显卡。此问题在谷歌云 GKE 环境中不会发生,因为谷歌云 GKE 使用的是定制版插件。
本文搭建一个包含一台 Master 和一台 Node 的 K8S 集群,其中 Node 上配置一块 NVIDIA T4 显卡。之后复现显卡 ID 问题,并介绍升级环境解决问题的步骤。
创建虚机实例
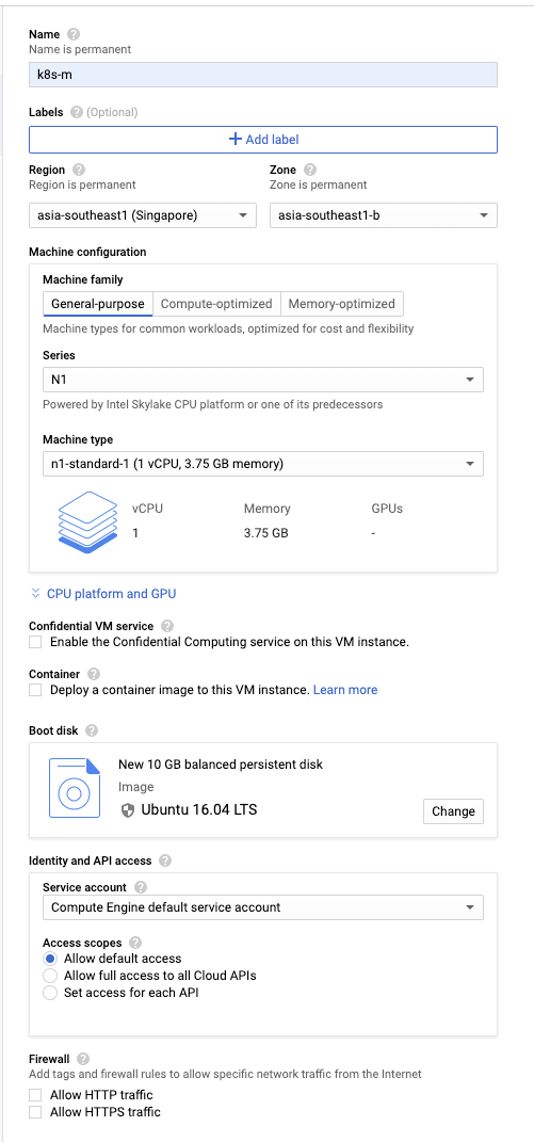
在谷歌云控制台创建以下配置的虚机。注意确认使用的项目和区域有充足的 CPU 和 GPU quota。
● 一台 Master 节点
○ k8s-m
○ n1-standard-1
○ Ubuntu LTS 16.04
● 一台 Node 节点
○ k8s-t4-node
○ n1-standard-1
○ Ubuntu LTS 16.04
○ T4 GPU
创建完后确认 master 和 node 都运行正常。

搭建 K8S 集群
参考 NVIDIA 官方文档
以及 DeepOps 文档
https://github.com/NVIDIA/deepops/tree/master/docs/k8s-cluster
首先,登录到 k8s-m,执行以下命令安装 Ansible 工具

下载并初始化 DeepOps 脚本

创建 SSH 密钥对,并将公钥配置为 Node 的允许密钥。注意要将私钥配置为其它用户不可访问。

参照下面截图更改 Ansible 配置文件,指定 K8S 的 master 和 node 信息,以及密钥对信息

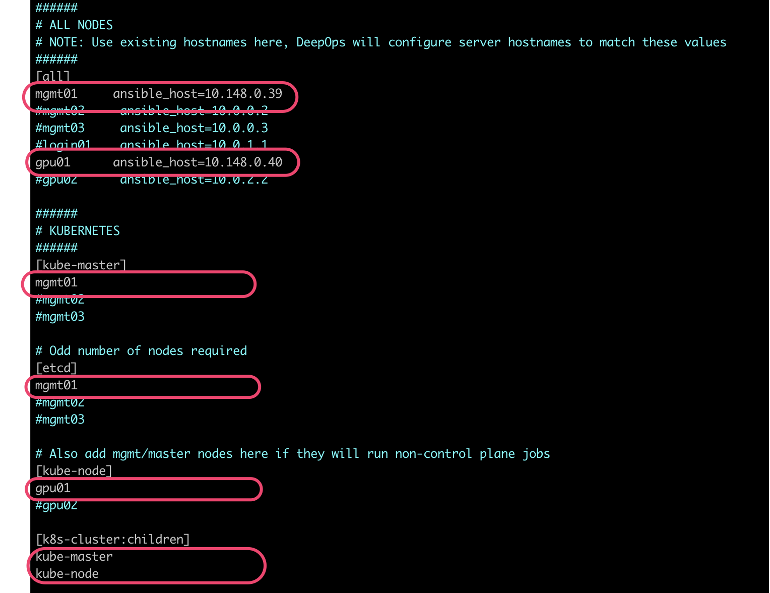
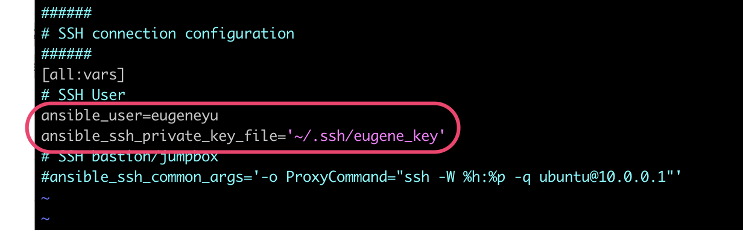
验证 Ansible 配置

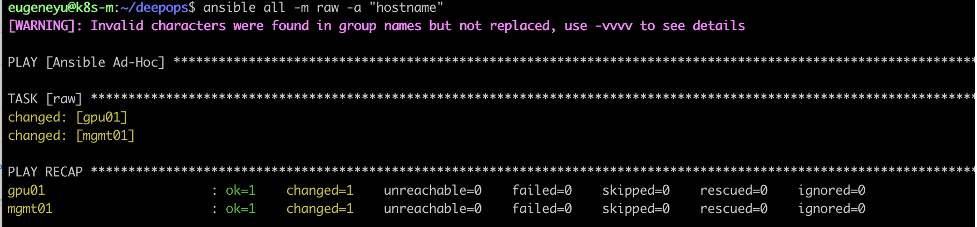
启动 Ansible 来安装 K8S 集群

安装完成后,用下面命令来验证集群运行正常

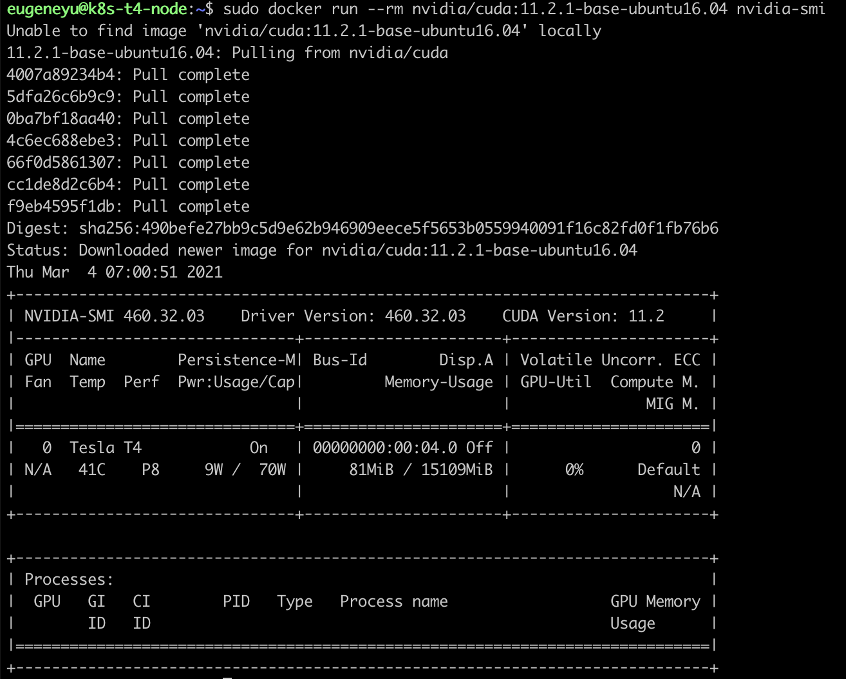
在 gpu01 节点上运行以下命令确认容器环境可以识别到显卡。

注意:Image 版本需要参考官方文档
至此,K8S 集群安装完毕。现在可以部署机器学习训练或预测任务在此集群。
复现节点重启后 GPU Device ID 变化问题
在刚搭建好的 K8S 集群 master 上查看 NVIDIA K8S Plugin 的版本

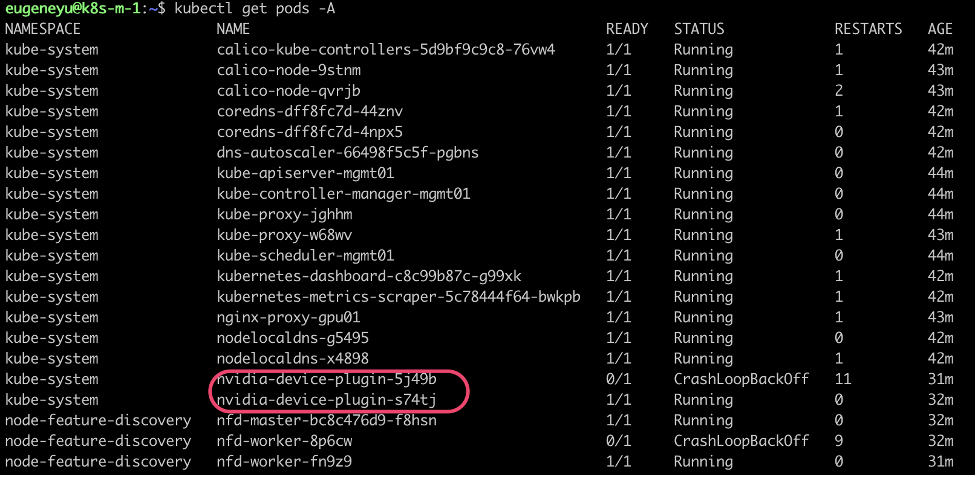

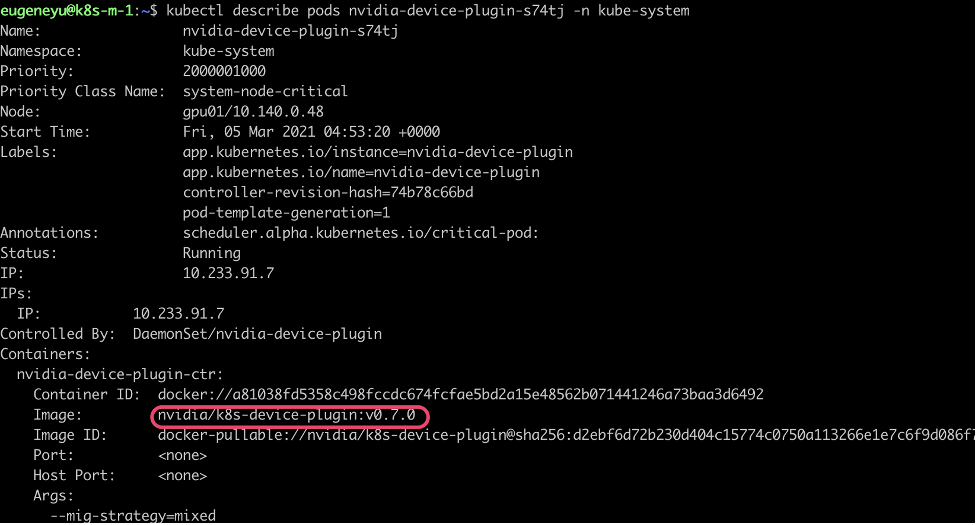
根据输出,此集群上使用的 NVIDIA K8S 插件为 0.7.0 版本。此版本会产生重启后显卡 Device ID 变化而找不到显卡的问题。
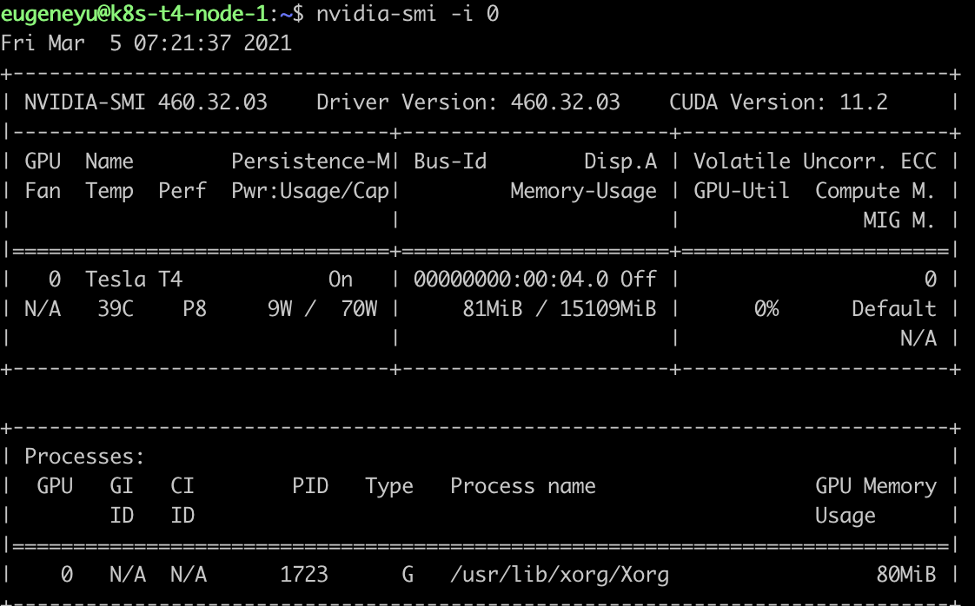
查看当前显卡 Device ID 。


用下面命令用序号查看显卡设备。

安装并运行测试程序容器 nvidia-loop 。其功能是持续占用显卡并不断打印 GPU Device ID 。
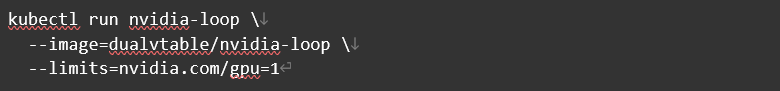
查看 nvidia-loop 的日志

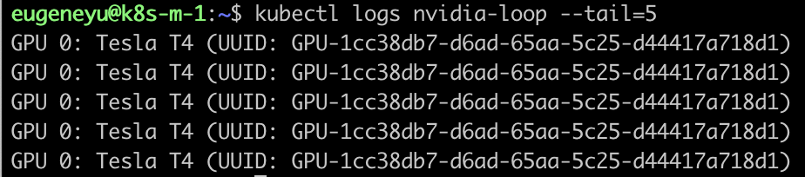
以上命令都应该成功无错。到此都不会出现任何问题。
使用以下命令模拟 GCP 虚机维护事件。

命令完成后 1 小时,节点会进行重启( 1 小时延迟因为需要完成一个重启前一小时的通知消息)。重启后 node 虚机应该会迁移到另一台宿主机并配置不同 ID 的显卡。此时可以登录到 Node 来查看 GPU Device ID。


也可以使用 cuda 镜像来测试在容器内获取 GPU Device ID,也一样发生了变化

可以看到 Device ID 发生了变化。
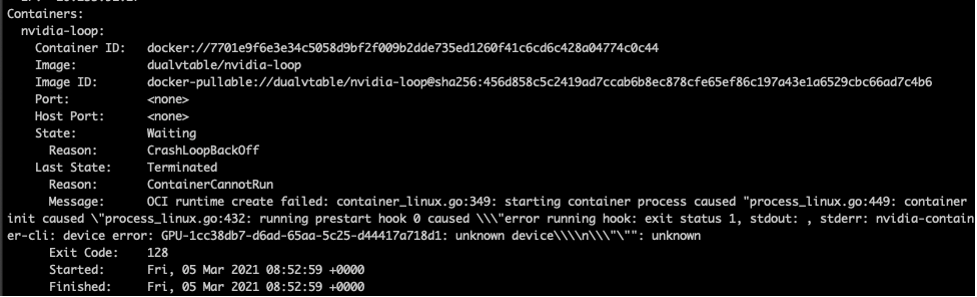
此时查看 nvidia-loop 容器的状态,由于 Device UUID 发生了变化,导致不断 crash。


查看 pod 描述,可以看到具体错误为 UUID 变化。

修复节点重启后 GPU Device ID 变化问题
下面步骤验证 NVIDIA K8S Plugin release 0.9.0 修复了节点重启后 Device ID 变化的问题。
首先安装 NVIDIA K8S Plugin 的 0.9.0 版本,并删除之前版本。
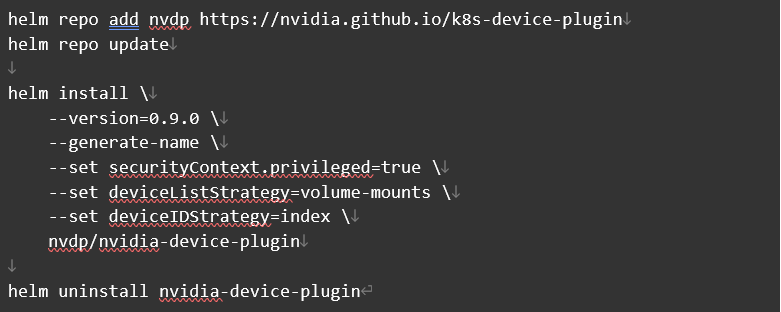
确认安装成功


更新 Node 上 nvidia-runtime 的配置文件,允许 volume mount (否则测试容器 nvidia-loop 会运行失败)。
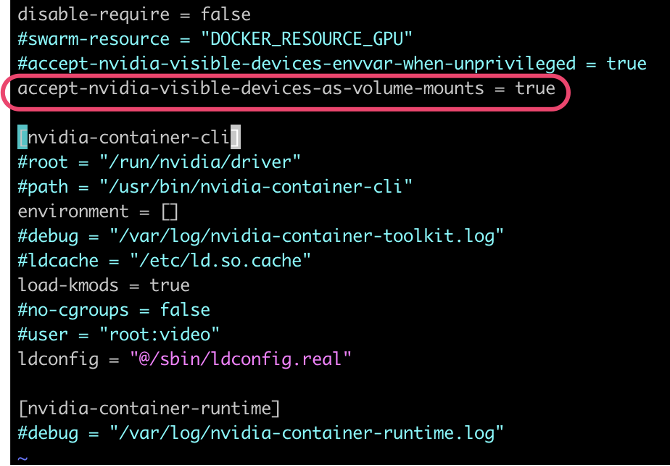
现在 K8S 插件更新完毕。可以验证问题修复。
再次使用以下命令模拟 GCP 虚机维护事件。

等一小时后维护重启完成后,查看 nvidia-loop 容器状态,应该是 Running,而不会再因为维护重启而导致崩溃。


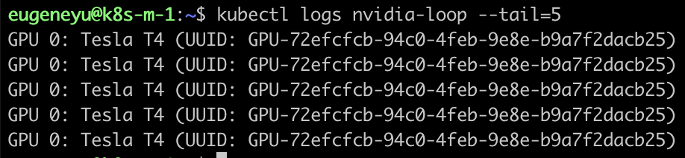
也可以查看 nvidia-loop 的日志,确保输出 ID 正常。
kubectl logs nvidia-loop --tail=5
参考文档
[1] Using the GPU id instead of uuid in the NVIDIA device plugin




