
整理 | 华卫、核子可乐
卡耐基梅隆大学的两位研究人员最近发现,压缩信息的过程有望解决复杂的推理任务,且无需在大量示例之上进行预训练。他们的系统仅依靠谜题本身就可以解决某些类型的抽象模式匹配任务,直接挑战了关于机器学习系统要如何获取问题解决能力的传统观念。
“无损信息压缩本身,能否启发智能行为?”,一年级博士生 Issac Liao 和他的导师、卡耐基梅隆大学机器学习系的 Albert Gu 教授提出这样的猜想。他们的研究工作表明,答案很可能是肯定的。为了进行验证,他们开发了 CompressARC 软件,并在 Liao 的个人网站上发表了一篇综述文章,公布了相关结果。
两人在抽象和推理语料库(ARC_AGI)上测试了相关方法,这是机器学习研究员 François Chollet 于 2019 年创建的视觉基准库,用于测试 AI 系统的抽象推理能力。ARC 为系统提供基于网格的谜题,每个谜题对应几个示例以演示基本规则。系统必须从中推断出规则,才能正确解开新示例。
例如,一个 ARC-AGI 谜题显示一个网格,其中浅蓝色的行和列将空间划分为多个框。该任务需要根据颜色的位置确定哪些颜色属于哪个框:黑色代表边角、洋红色代表中央,其余方框则以色彩作为方向区分(红色代表上、蓝色代表下、绿色代表右、黄色代表左)。以下是另外三个 ARC-AGI 示例谜题:

ARC-AGI 基准测试中的三个示例谜题
这些谜题所测试的能力,被部分专家认为决定一般性类人推理(即通用人工智能 AGI)的关键性能,包括理解对象的持久性、目标导向行为、计数与不需要专业知识的基本几何。普通人约能解决 76.2%的 ARC-AGI 问题,而人类专家的解决率可达到 98.5%。
OpenAI 于去年 12 月宣布 o3 模拟推理模型在 ARC-AGI 基准测试中获得了破纪录的成绩,引发轰动。在受限计算测试中,o3 的得分为 75.7%,而在高计算测试(即思考时间几乎无限)中得分则为 87.5%。OpenAI 表示,这样的结果已经与人类相当。
CompressARC 在 ARC-AGI 训练偏大(用于系统开发的谜题集合)上的准确率为 34.75%,而在评估集(一组未见过的单独谜题,用于测试该方法在新问题上的推广效果)上的准确率为 20%。在消费级 RTX 4070 GPU 上,每个谜题需要约 20 分钟才能解决完毕。相比之下,顶级方法则须使用重型数据中心级设备,研究人员称其将产生“天文数字般的计算量”。
并非典型的 AI 方法
CompressARC 采用的方法与大多数当前 AI 系统完全不同。它并不依赖预训练(即机器学习在处理特定任务前,先从大量数据集中学习的过程),甚至完全不需要外部训练数据。系统仅使用需要解决的特定谜题本身即可实时训练。
研究人员写道,“无需预训练;模型在推理期间可随机初始化并完成训练。无需数据集;模型仅在目标 ARC_AGI 谜题上进行训练并输出单一答案。”
研究人员还提到此方法“无需搜索”,即 AI 问题解决中的另一种常见技术——系统尝试从多种不同的潜在解法中选择出最佳解法。搜索算法的基本原理是系统探索各选项(类似国际象棋程序中的走法评估),而非直接学习解法。CompressARC 回避了这种反复试错的方法,而是完全依靠梯度下降——一种逐步调整网络参数以减少错误的数学技术,类似于靠不断向下走找到通往谷底的路径。
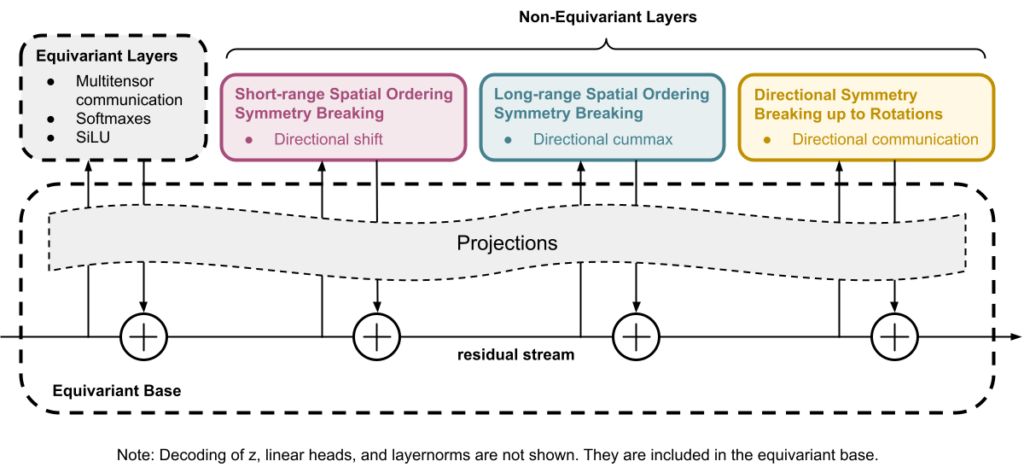
研究人员设计的 CompressARC 架构框图
该系统的核心原理,在于使用压缩(即通过识别模式与规律以找到最有效的信息表达方式)作为智能的底层驱力。CompressARC 寻求的是对谜题的最短描述,以便在解压时准确重现示例与解法。虽然 COmpressARC 借鉴了 Transformer 的部分结构原理,但仍属于专为压缩任务设计的自定义神经网络架构,独立于大语言模型或标准 Transformer 模型。
与典型机器学习方法不同,CompressARC 仅将其神经网络用作解码器。在编码(即将信息转换为压缩格式的过程)期间,系统会微调网络的内部设置与输入数据,逐渐进行细微调整以最大限度减少错误。此过程会创建出压缩度最高的表示,同时正确重现谜题中的已知部分。之后,这些经过优化的参数将转换为压缩表示,以高效格式存存储谜题及其解法。

动图所示,为 CompressARC 解决 ARC-AGI 谜题的多步骤过程。
研究人员解释称,“其中的关键挑战,在于无需答案输入即可获得这种紧凑的表示结果。”该系统本质上将压缩作为一种推理形式。这种方法在没有大型数据集的领域、或者要求以最少示例学习新任务的场景下极具价值。这项研究表明,某些形式的智能可能并不是从记忆大量来自数据集的模式中产生,而是来自以紧凑形式高效表示信息而来。
压缩与智能的关联
压缩与智能之间乍看之下似乎并没有什么关联,但这一点在计算机科学概念中却有着深厚的理论根源,例如柯尔莫哥洛夫复杂度(即能产生指定输出的最短程序)与所罗门诺夫归纳法(一种理论黄金标准,用于预测效果上的最佳压缩算法)。
为了高效压缩信息,系统必须识别模式、找到规律并“理解”数据的底层结构——而这些能力,反映的正是不少专家认定的智能行为,即要想有效压缩特定序列、系统必须能够预测序列接下来会发生什么。于是过去几十年来,不少计算机科学家认为压缩能力就等同于通用智能。基于这些原则,Hutter 奖开出悬赏,鼓励研究人员尝试将 1 GB 文件压缩到最小体积。
2023 年 9 月,DeepMind 曾经发表一篇论文,发现大语言模型在某些情况下的表现要好于专门的压缩算法。在这项研究中,研究人员发现 DeepMind 的 Chinchilla 70B 模型能够将图像块压缩到原始大小的 43.4%(优于 PNG 的 58.5%),将音频样本压缩至仅 16.4%(优于 FLAC 的 30.3%)。
当时的研究结果表明,压缩和智能之间确实存在着深刻关联——即只有真正理解数据中的模式,才能实现更高效的压缩。这也与此次卡耐基梅隆大学的研究发现一致。而不同于 DeepMind 在训练过的模型中展现出压缩能力,Liao 和 Gu 的工作采用自己的方法,证明压缩过程可以从零开始实现智能行为。
这项新研究之所以意义重大,是因为它挑战了 AI 开发领域的主流观点,即 AI 开发往往依赖于大量预训练数据集和具有极高计算成本的模型。尽管各大领先 AI 厂商仍在努力开发基于广泛数据集的更大模型,但 CompressARC 认为智能完全可以基于不同原理逐步实现。
研究人员们总结道,“CompressARC 的智能并非源自预训练、庞大的数据集、详尽的搜索或者大规模计算,而是源自压缩。我们对此前需要大量预训练和数据集的传统思路提出挑战,并提出新的可能性,即量身定制的压缩目标加高效的推理计算可以共同协作,以最少的输入实现深度智能。”
局限性与未来展望
尽管取得了成功,但 Liao 和 GU 的系统仍存在明显的局限性,因此结论可能会面临质疑。虽然它成功解决了涉及颜色分配、填充、裁剪和识别相邻像素等难题,但在计数、远程模式识别、旋转、反射或者模拟代表行为等任务中却表现得举步维艰。这种局限性也凸显出,简单的压缩原理恐怕并不适用于所有领域。
这项研究尚未经过同行评审。尽管在未经预训练的情况下,在未接触过的谜题中实现 20%的准确率已然令人印象深刻,但这样的成绩仍远低于人类表现和当前顶尖 AI 系统。批评者可能会认为,CompressARC 其实是利用了 ARC 谜题中可能无法推广到其他领域的特定结构模式,进而质疑压缩本身到底是否可以作为通用智能的实现基础。或者说,其仅仅是实现强大推理能力所必需的众多组成要素之一。
但随着 AI 技术的持续快速发展,如果 CompressARC 经得起进一步审查,仍有可能揭示一条可能的替代路径。这条路径也许同样可以实现具备实用性的智能行为,同时避免了当前主流方法提出的严苛资源需求。或者至少,它有望成为解锁机器通用智能中的一项重要组成部分,而这一点目前仍不太清楚。
原文链接:




