
刚刚,华为云在华为开发者大会(Cloud)上发布了全球最大的中文语言(NLP)及视觉(CV)预训练模型——盘古系列大模型。
据悉,华为云盘古系列 AI 大模型计划包括四大模型:NLP 大模型、CV 大模型、多模态大模型、科学计算大模型。整个大模型设计遵循三大原则:一是超大的神经网络;二是网络架构强壮,相比于定制化小模型,大模型综合性能提升了 10% 以上;三是健壮(Robust)的网络性能,全场景覆盖率提升 10 倍以上。

为什么我们需要大模型?
2020 年 5 月,OpenAI 发表了一篇关于 GPT-3 的论文,GPT-3 模型迭代之后,拥有 1750 亿个参数。2019 年,GPT-2 就凭借 30 亿条参数获得了“最强 NLP 模型”的称号,1750 亿条参数的 GPT-3 发布之后,自然也就在工业界和学术界引发了广泛的谈论。
我们真的需要大模型吗?大模型会给我们带来哪些改变?
过去十年,AI 算法对算力的需求增长了 40 万倍,神经网络从小模型到大模型已经成为了必然的发展趋势。同时,我们也看到人工智能与科学计算深度融合,已经在众多领域都有所应用,大模型就是解决 AI 模型定制化和应用开发碎片化的一种方式,它可以吸收海量的知识,提高模型的泛化能力,减少对领域数据标注的依赖。
大模型出现之后,高度定制化的小模型可能会被“兼并”。在技术方面,大模型对于 AI 框架的深度优化和并行能力都有很高的要求,同时它也会牵引 AI 产业快速收敛,成为 AI 产业底座,从而改变 AI 发展的规则和格局。
现在业界普遍的 AI 开发方式还是作坊式的,针对不同场景的 AI 应用需要进行定制化开发,不仅要投入大量的专家和时间,而且 AI 模型的性能也很难做到极致。一旦场景变化,整个模型可能都需要重新开发。如果把工业化模式引入到 AI 开发过程,让一个模型可以应用到多个场景中,那么 AI 开发就会获得突飞猛进的发展。
业界首个千亿参数的中文大模型——盘古 NLP 大模型
为了加速 AI 工业化开发进程,华为发布了全栈全场景 AI 解决方案。2019 年 8 月,发布了昇腾 910 芯片力和计算框架 MindSpore;2020 年 3 月,在 HDC.Cloud 发布了视觉研究计划,正式开源 MindSpore;2020 年 9 月,升级发布了 AI 一站式开发平台 ModelArts3.0。
就在刚刚,华为云又发布了业界首个千亿参数的中文大模型——盘古 NLP 大模型。
据了解,盘古 NLP 大模型,由华为云、循环智能和鹏城实验室联合开发,是全球最大的中文语言预训练模型,在预训练阶段就学习了 40 TB 的中文文本数据,其中包括细分行业的小样本数据,可以优化提升模型在具体场景中的应用性能。与其他大模型不同的是,盘古 NLP 大模型瞄准的是细分行业,主要解决商业环境中低成本大规模定制的问题。
在最新的中文语言理解评测基准(CLUE)中,盘古 NLP 大模型获得了总排行榜、分类任务、阅读理解三项榜单第一,其中,总排行榜得分 83.046。
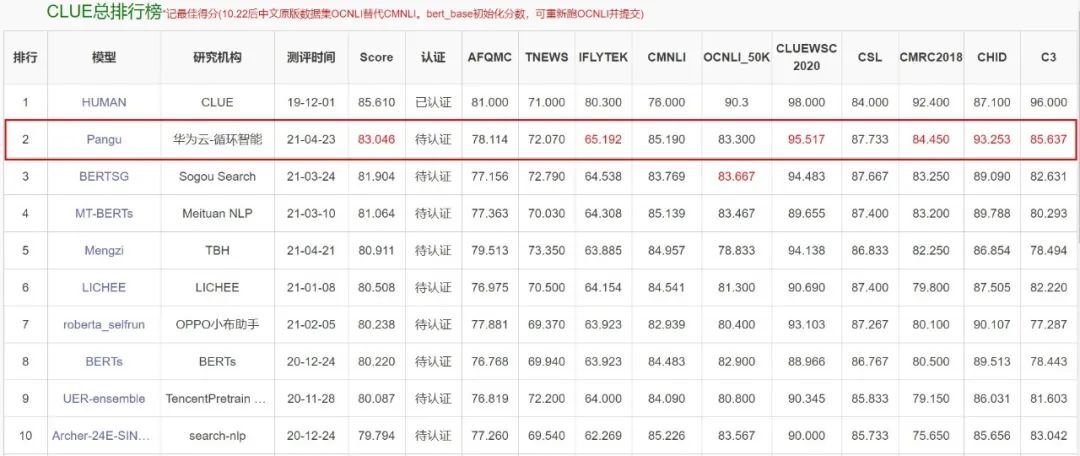
盘古 NLP 大模型获得 CLUE 总排行榜第一
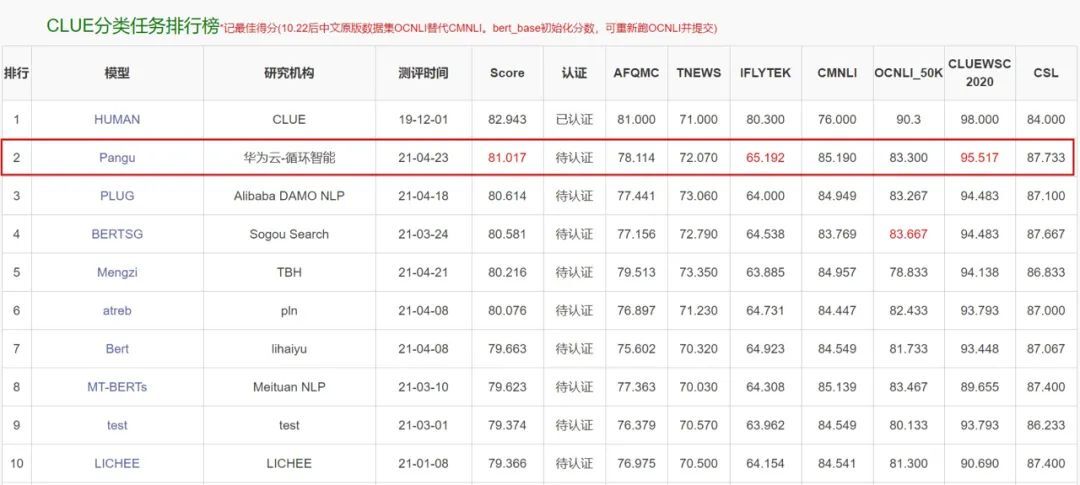
盘古 NLP 大模型在 CLUE 分类任务排名第一
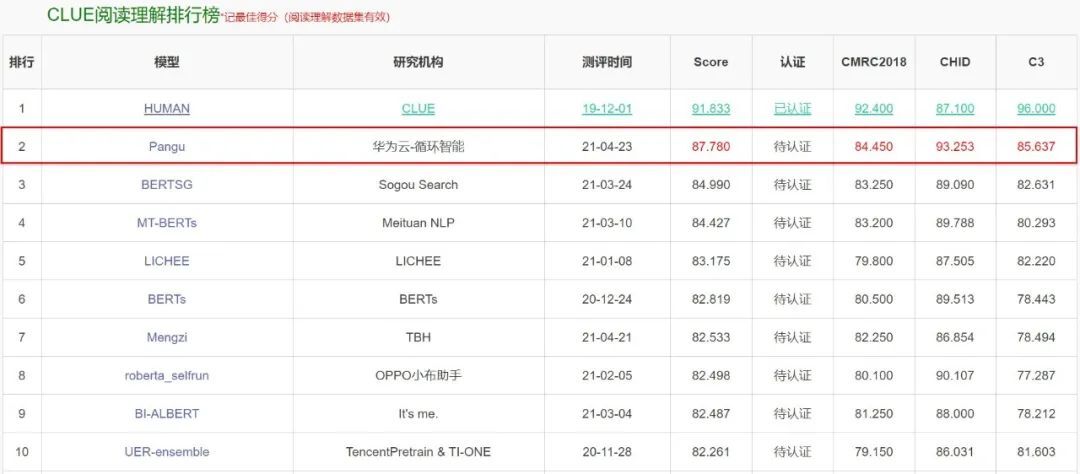
盘古 NLP 大模型在 CLUE 阅读理解任务排名第一
为什么盘古 NLP 大模型能够在 CLUE 刷新三项历史记录?相比于业界其他大模型,它又有哪些不同呢?
第一,盘古 NLP 大模型在预训练阶段沉淀了大量的通用知识,既能做生成又能做理解的特性让它有能力支持行业知识库和数据库的嵌入,进而对接行业经验。大模型可以充当系统中的任意模块,快速适配和扩展不同的场景。
第二,盘古 NLP 大模型在 encoder-decoder 的架构基础上植入了华为云的训练技巧和方法,所以性能优异,在 CLUE 三项榜单中都获得了第一名。同时,盘古 NLP 大模型还进行了 nlpcc2018 文本摘要任务的评测,获得了 Rouge Score 平均分 0.53 的业界最佳成绩,超越第二名百分之六十。
第三,之前业界发布的大模型基本都不调优,或者是使用 non-gradient(非梯度下降)调优,为了追求泛化能力而牺牲一些场景的性能。而盘古 NLP 大模型为了改变这一缺陷,采用了大模型小样本的调优方式,基于提示(prompt-based)的调优、动态冰化等一系列正则化技术,实现了小样本学习任务上超越 GPT 系列。
盘古 NLP 在各种榜单中都获得了不错的成绩,那么在具体场景中它的表现如何呢?在华为开发者大会(Cloud)现场,华为云人工智能首席科学家、IEEE Fellow 田奇就在现场对盘古 NLP 大模型进行了连续追问。




通过这几个来回的问答,我们发现盘古 NLP 大模型可以如同人类一般自如交流,体现出惊人的理解能力和生成能力。通过 40TB 中文文本的训练,它能够通过少样本学习对意图进行识别,准确回答我们的问题,而且即使你在一句话中提出了多个问题,它也能够逐一识别并回答,具备了多重意图识别能力。在其中一个问题中,完全没有提到“碳中和”这个关键词,盘古也可以基于上下文推断出当前的讨论对象,并且针对“碳中和”话题发表自己的观点与看法。
三十亿参数、十亿级图像知识的 CV 模型——盘古 CV 大模型
除了 NLP 模型,华为云还同时发布了盘古 CV 大模型。据了解,该 CV 模型包含 30 亿 + 参数,是目前业界最大的 CV 模型,并且在 ImageNet 1%、10% 等数据集上的小样本分类精度上均达到目前业界最高水平(SOTA)。
与其他 CV 大模型不同的是,盘古 CV 大模型首次兼顾了图像判别与生成能力,能够同时满足底层图像恢复与高层语义理解的需求,同时融合了各行业知识,能够快速适配各种下游任务。目前,盘古 CV 大模型已经在医学影像、金融等 100+ 项任务中应用实践,不仅可以大幅提升业务测试精度,还能平均节约 90% 以上的研发成本。
现有的 AI 工程通常都需要针对不同场景做定制化开发,费时费力。盘古 CV 大模型的出现,解决了 AI 工程难以泛化和复制的问题,让 AI 开发进入工业化模式,一套流水线可以复制到不同的场景中,节约人力和算力。
在功能方面,盘古 CV 大模型提供了大模型预训练、大模型部署和大模型迭代三个功能,三者既是个有机整体,也形成了 AI 开发的完整闭环。
大模型预训练:这个阶段解决的核心问题是如何将超大规模数据,特别是各种行业数据中蕴含的知识,存储在大模型中。预训练的关键是整合无标签和有标签图像,捕捉其中隐含的结构化特征,特别是样本和样本之间的关系信息。盘古 CV 大模型中包含了数据处理、架构设计和模型优化三个步骤,支持层次化空间特征聚合、监督式对比语义调整等算法,可以将图像的表征效率提升数千倍。
大模型部署:这个阶段解决的核心问题是如何覆盖各类算力差别较大的设备,包括用于高清遥感影像分析的云侧设备、用于电力线路巡检的边侧设备、以及用于铁路故障检测的端侧设备等等。三十亿参数的大模型未必能够满足用户的速度要求,盘古 CV 大模型中专门设计了模型抽取和知识蒸馏算法,能够根据用户需求抽取高效子模型,并且确保将大模型学习到的知识最大限度地传递给子模型。
大模型迭代:盘古 CV 大模型配备了数据挖掘和增量学习模块,其中的一比特监督学习、双向自步学习等算法能够减少 90% 以上的人力干预;同时类别增量、难例增量学习等技术也能够在增量学习过程中减少 90% 以上的算力消耗。配合基于图网络的模型融合技术,盘古 CV 大模型最终可实现闭环迭代,模型的泛化能力也会在使用过程中逐渐增强。
大模型背后的技术支撑以及实践案例
盘古 NLP 大模型具备千亿参数、10 的 23 次方、40TB 的中文文本训练数据,如果是使用单卡来支持盘古大模型训练,需要数百年的时间才能训练完。那么,盘古大模型背后到底有着什么样的技术支撑呢?
据悉,盘古大模型的 AI 算力和数据吞吐能力都是由鹏城云脑 II 提供的,这是国内最大规模的 AI 训练集群。除了硬件算力支持,华为底层软件、训练框架、ModelArts 平台也为盘古大模型提供了技术保障。
在算法方面,华为云的算法团队和循环智能(Recurrent AI)的 NLP 团队联合攻关,突破了大模型微调的难题。
针对底层算子性能,盘古大模型基于 CANN 采用了算子量化、算子融合优化等技术,单算子性能能够提升 30% 以上。
针对并行策略,华为 MindSpore 采用了“流水线并行、模型并行和数据并行”的多维自动混合并行技术,大幅降低了手动编码的工作量,集群线性度提升 20%。
针对训练资源调度,华为云 ModelArts 支持 E 级算力调度,提供最优的网络通信能力。借助 ModelArts 平台的海量数据处理能力,盘古大模型仅用 7 天就可以完成 40TB 文本数据处理。
光说不练假把式,了解了盘古大模型背后的技术支撑之后,我们来看看盘古大模型是如何应用到实际案例中。
国网重庆永川供电公司是国内早期采用无人机智能巡检技术来替代人工巡检的电力公司,并将无人机数据采集应用于输电线路、变电站、配电线路自主巡检等多个业务场景。但是传统的无人机智能巡检 AI 模型开发中,他们遇到了两个难题,一是如何进行缺陷样本的高效标注,二是智能巡检故障种类繁多。
为了解决这两个问题,国网重庆永川供电公司与华为云合作应用了盘古 CV 大模型。
在数据标注方面,盘古 CV 大模型利用海量无标注电力数据进行预训练,并结合少量标注样本微调的高效开发模式,提出了针对电力行业的预训练模型。应用之后,样本筛选效率提升约 30 倍,筛选质量提升约 5 倍,以永川每天采集 5 万张高清图片为例,可节省人工标注时间 170 人天。
在模型通用性方面,结合盘古搭载的自动数据增广以及类别自适应损失函数优化策略,可以做到一个模型适配上百种缺陷,一个模型就可以替代永川原先的 20 多个小模型,极大地减少了模型维护成本,平均精度提升 18.4%,模型开发成本降低 90%。
国网重庆永川供电公司的应用案例,让我们见识到了盘古大模型在电力智能巡检方面的优势,盘古大模型能够快速适配到电力行业的不同场景,真正做到了规模化可复制。相信未来,我们可以在更多行业领域看到盘古大模型的应用实践。




