
作者 | UCloud 优刻得
本文 UCloud 将为您解析参数高效微调技术(PEFT),即对已预训练好的模型,固定住其大部分参数,而仅调整其中小部分或额外的参数,以达到与全部参数微调相近的效果。
参数高效微调方法,可大致分为三个类别:增加式方法、选择式方法和重新参数化式方法[1]。
1 增加式方法(Additive methods)
增加式方法通过增加额外的参数或层来扩展现有的预训练模型,且仅训练新增加的参数。目前,这是 PEFT 方法中被应用最广泛的类别。
在增加式方法中,大致分为 Adapter 类方法和软提示(Soft Prompts)。2019 年 1 月至 2022 年 3 月期间,Adapter 类的方法 Adapter Tuning,软提示类的方法 Prefix Tuning、P-Tuning、Prompt Tuning、P-Tuning v2 相继出现。
1.1 Adapter Tuning[2]
Adapter 的架构如下:
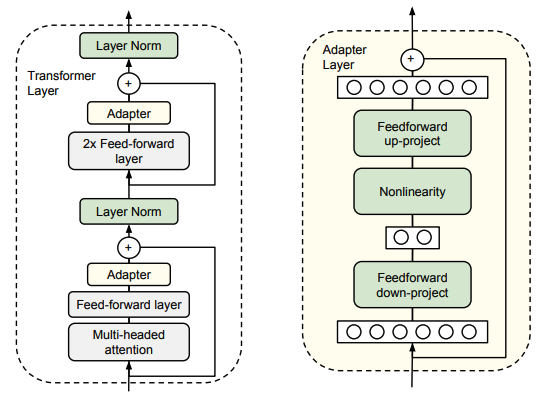
在每一个 Transformer 层中的每个子层之后插入两个串行的 Adapter。在 Adapter 微调期间,绿色层是根据下游数据进行训练的,而预训练模型的原参数保持不变。
1.1.1 Adapter 的特点
Adapter 模块主要由两个前馈(Feed-forward)子层组成。
第一个前馈子层将原始特征的维度 d 投影到一个更小的维度 m,应用非线性函数,再投影回维度 d 的特征(作为 Adapter 模块的输出)。
总参数量为 2md + d + m。通过设置 m < d,我们限制了每个任务添加的参数数量。
当投影层的参数初始化接近零时,根据一个 skip-connection,将该模块就初始化为近似恒等函数,以确保微调的有效性。
1.1.2 Adapter 的实验结果
使用公开的预训练 BERT 作为基础模型。Adapter 微调具有高参数效率,可以生成性能强劲的紧凑模型,与完全微调相比表现相当。Adapter 通过使用原始模型 0.5-5%大小的参数量来微调,性能与 BERT-LARGE 上具有竞争力的结果相差不到 1%。
1.2 Soft Prompts
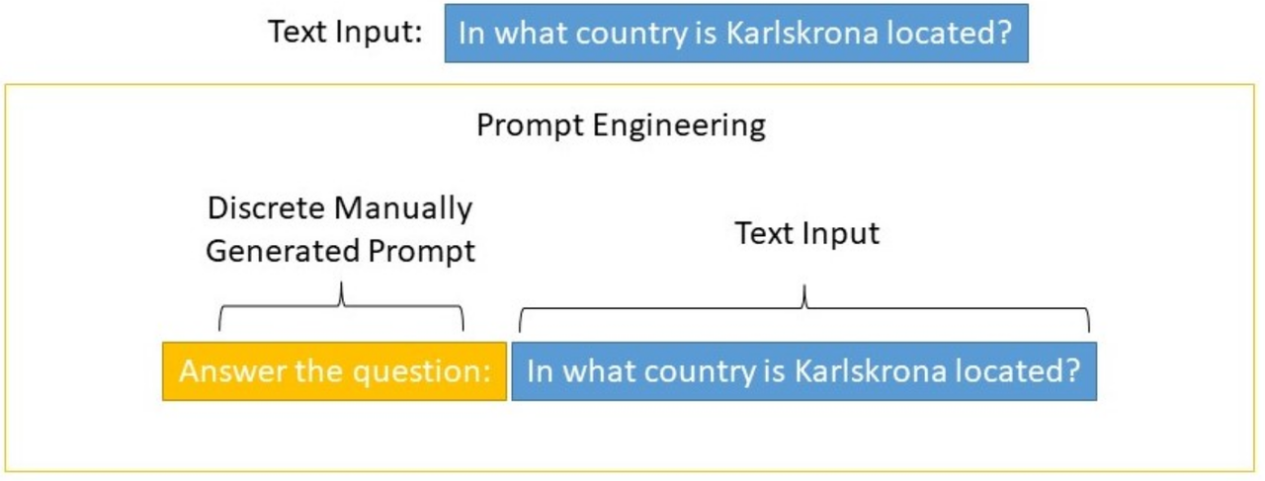
早期的提示微调通过修改输入文本来控制语言模型的行为,称为硬提示(Hard Prompts)微调。这些方法很难优化,且受到最大模型输入长度的限制。下图为离散的人工设计的 Prompt 示例:
比如改变输入形式去询问模型:
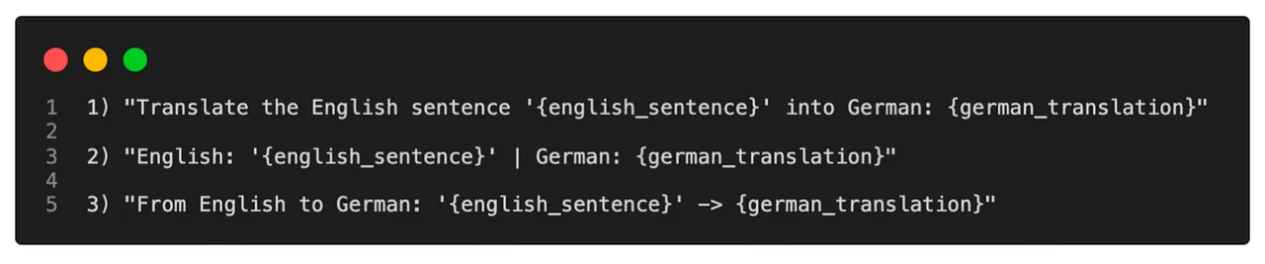
软提示(Soft Prompts)将离散的“提示”问题转为连续的“提示”问题,通过过反向传播和梯度下降更新参数来学习 Prompts,而不是人工设计 Prompts。有仅对输入层进行训练,也有对所有层进行训练的类型。下面将介绍几种热门的 Soft Prompts 微调方法。
1.2.1 Prefix Tuning
其结构如下:
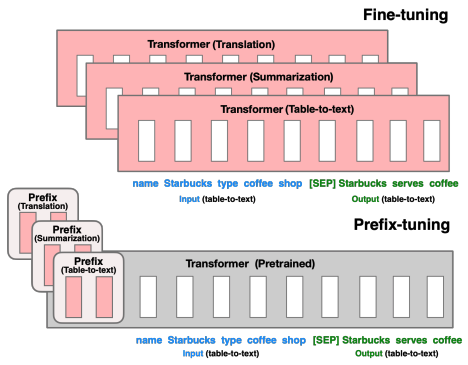
只优化前缀(红色前缀块),该前缀添加到每一个 Transformer Block 中。
1.2.1.1 Prefix Tuning 的特点
冻结预训练语言模型的参数,为每个任务存储特定的连续可微的前缀,节省空间。
训练间增加 MLP 层以达到稳定。
对于不同模型构造不同的 Prefix。
1.2.1.2 Prefix Tuning 的实验结果
对于表格到文本任务,使用 GPT-2MEDIUM 和 GPT-2LARGE 模型。在表格到文本任务上,Prefix Tuning 优于 Fine-Tuning(全量微调)和 Adapter-Tuning。对于摘要任务,使用 BART-LARGE 模型。在摘要任务上,Prefix Tuning 比全量微调弱。
1.2.2 P-Tuning
其结构如下:
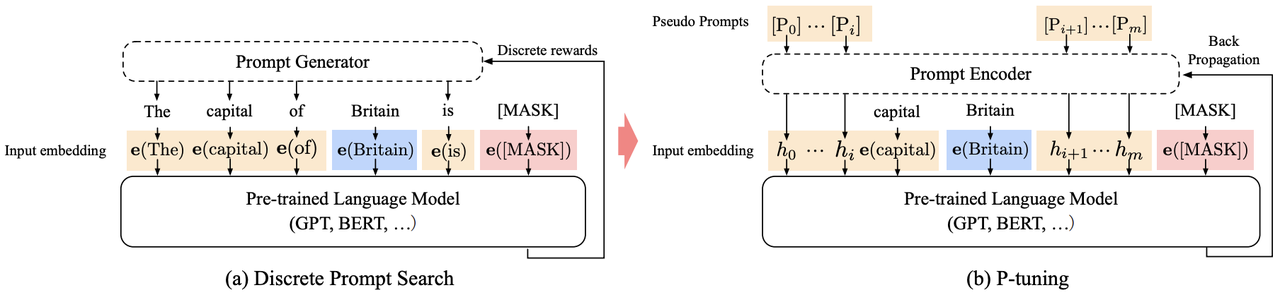
在(a)中,提示生成器只接收离散的奖励;在(b)中,伪提示和提示编码器可以以可微分的方式进行优化。
优化ℎi 时,为避免陷入局部最优和增强 Prompt 嵌入关联性,语言模型的真实输入嵌入为:
1.2.2.1 P-Tuning 的特点
P-Tuning 只在输入层加入可微的 Virtual Token,其会自动插入到文本提示的离散 Token 嵌入中。
Virtual Token 不一定作为前缀,其插入位置是可选的。
1.2.2.2 P-Tuning 的实验结果
使用的是 GPT 系列和 BERT 系列的模型。P-Tuning 与全参数效果相当,且在一些任务上优于全参数微调,可以显著提高 GPT 模型在自然语言理解方面的性能,并且 BERT 风格的模型也可以获得较小的增益。
1.2.3 Prompt Tuning
其结构如下:
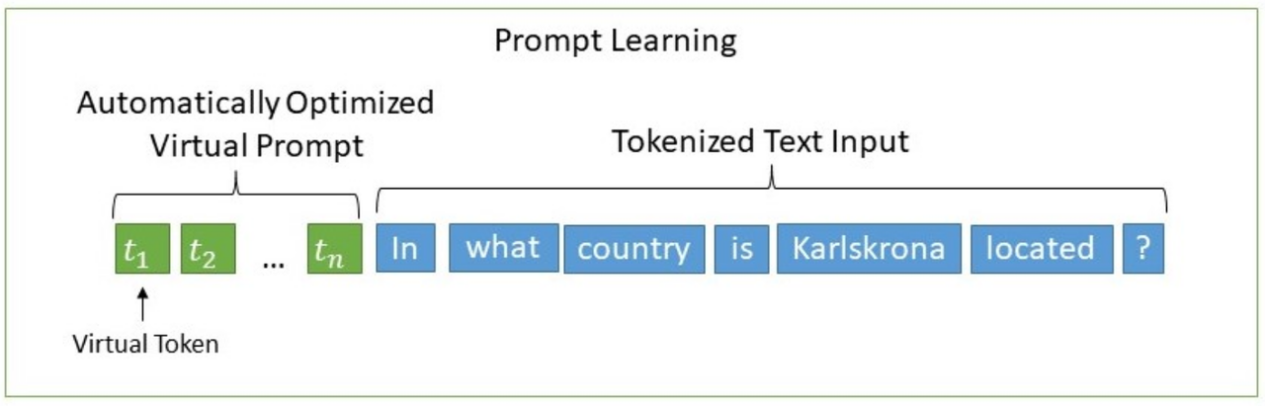
上图中,仅 Virtual Token 部分会由梯度下降法去更新参数。
1.2.3.1 Prompt Tuning 的特点
只在输入层加入 Prompt,并且不需要加入 MLP 进行调整来解决难训练的问题。
提出了 Prompt Ensembling,即通过在同一任务上训练 N 个提示,也就是在同一个批次中,对同一个问题添加不同的 Prompt,相当于为任务创建了 N 个独立的“模型”,同时仍然共享核心语言建模参数。
1.2.3.2 Prompt Tuning 的实验结果
使用的是预训练的各种 T5 模型。在流行的 SuperGLUE 基准测试中,Prompt Tuning 的任务性能与传统的模型调优相当,且随着模型规模的增加,差距逐渐减小。在零样本领域迁移中,Prompt Tuning 可以改善泛化性能。
1.2.4 P-Tuning v2
其结构如下:
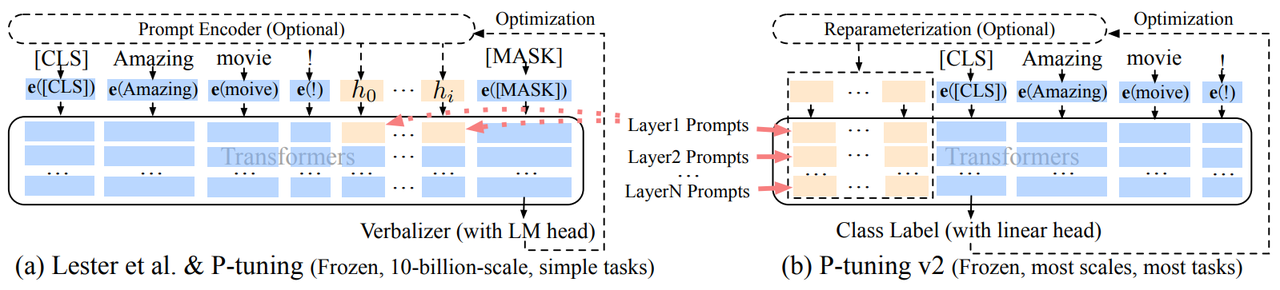
上图表示了 P-Tuning 到 P-Tuning v2 的转变。橙色块(即ℎ0,...,ℎi)指的是可训练的提示嵌入,蓝色块是由冻结的预训练语言模型存储或计算得出的嵌入。
1.2.4.1 P-Tuning v2 的特点
P-Tuning v2 每一层的输入都加入了 Tokens,允许更高的任务容量同时保持参数效率;且添加到更深层的提示对模型的预测有更直接的影响。
1.2.4.2 P-Tuning v2 的实验结果
使用的是 BERT 系列和 GLM 系列模型。P-Tuning v2 是一种在不同规模和任务中都可与微调相媲美的提示方法。在 NLU 任务中,整体上 P-Tuning v2 与全量微调的性能相差很小。
2 选择式方法
选择性方法对模型的现有参数进行微调,可以根据层的深度、层类型或者甚至是个别参数进行选择。
2.1 BitFit
2022 年 9 月 5 日,BitFit 出现,这是一种稀疏微调方法,仅修改模型的 Bias(偏置项)或其中的子集。
2.1.1 BitFit 的特点
冻结大部分 Transformer 编码器的参数,只训练偏置项和任务特定的分类层。
优化的偏置项参数包括 Attention 模块中计算 Query、Key、Value 时,计算 MLP 层时,计算 Layernormalization 层时遇到的偏置项参数。
每个新任务只需要存储偏置项参数向量(占总参数数量的不到 0.1%)和任务特定的最终线性分类器层。
2.1.2 BitFit 的实验结果
使用公开可用的预训练 BERTBASE、BERTLARGE 和 RoBERTaBA 模型。BitFit 微调结果不及全量参数微调,但在极少数参数可更新的情况下,远超 Frozen(冻结模型参数)方式。
3 重新参数化方法
基于重新参数化的高效微调方法利用低秩表示来最小化可训练参数的数量,其中包括 2021 年 10 月到 2023 年 3 月间出现的 LoRA 和 AdaRoLA 方法。
3.1 LoRA
该方法认为模型权重矩阵在特定微调后具有较低的本征秩,故基于秩分解的概念,将预训练模型的现有权重矩阵分成两个较小的矩阵。
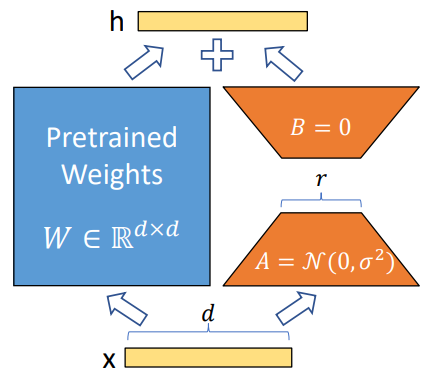
上图中,仅矩阵 A 和矩阵 B 的参数被更新,此处更新的矩阵模块可表示为ΔW = BA。当微调结束后,原本的前向计算由ℎ = Wx,变为ℎ=Wx + ΔWx = Wx + BAx。LoRA 的思想是以少量参数更新的方式,去间接实现大模型的训练。
3.1.1 LoRA 的特点
将矩阵乘积 BA 加到原模型参数矩阵 W 上可以避免推理延迟。
可插拔的低秩分解矩阵模块,方便切换到不同的任务。
3.1.2 LoRA 的实验结果
使用的模型是 RoBERTa、DeBERTa、GPT-2、GPT-3 175B。在多个数据集上,LoRA 在性能上能和全量微调相近,且在某些任务上优于全量微调。
3.2 AdaLoRA
3.2.1 AdaLoRA 的特点
该方法基于权重矩阵的重要性而自适应调整不同模块的秩,节省计算量,可理解为 LoRA 的升级版。
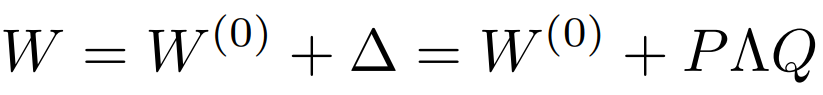
AdaLoRA 的做法是让模型学习 SVD 分解的近似。在损失函数中增加了惩罚项,防止矩阵 P 和 Q 偏离正交性太远,以实现稳定训练。
3.2.2 AdaLoRA 的实验结果
使用的模型是 DeBERTaV3-base 和 BART-large 模型。AdaLoRA 的性能通常高于参数量更高的方法。其中,AdaLoRA 在 0.32M 微调参数时,在 CoLA 数据集上达到了 70.04 的 Mcc 分数。
4 参数微调方法小结
以上几类参数高效微调方法,各有千秋。Adapter 方法在预训练模型的层中插入可训练模块的形式简单,但增加推理延时。Soft Prompts 方法避免了人工“硬提示”的局限性,却可能难收敛。
Soft Prompts 方法中,Prefix Tuning 率先提出可用梯度下降法优化的的 Tokens,而 P-Tuning、Prompt Tuning、P-Tuning v2 相继作出不同的改变,比如:
加入的 Tokens:P-Tuning 仅限于输入层,而 Prefix-Tuning 在每一层都加。
P-Tuning 和 Prompt Tuning 仅将连续提示插入到输入嵌入序列中,而 Prefix Tuning 的“软提示”添加在每一个 Transformer Block 中。
Prompt Tuning 不需要额外的 MLP 来解决难训练的问题,P-Tuning v2 移除了重参数化的编码器。
BitFit 方法只更新模型内部偏置项参数所以训练参数量很微小,但整体效果比 LoRA、Adapter 等方法弱。LoRA 方法不存在推理延时,但无法动态更新增量矩阵的秩,不过改进版 AdaLoRA 解决了这个问题。
5 AdaLoRA 方法的实验
5.1 实验模型为 ChatGLM2-6B
官网代码在 Git Clone https://github.com/THUDM/ChatGLM2-6B,可去 Hugging Face 下载其模型文件。应用 AdaLoRA 之后的模型训练参数仅占总参数的 0.0468%。
5.2 实验数据为中文医疗问答数据
下载链接为https://github.com/Toyhom/Chinese-medical-dialogue-data,包括儿科、外科等问答数据,数据中会有建议去医院看病之类的文字。此处选取儿科和外科的数据分别 10000 条数据作为训练数据集,将文件保存为 json 格式。
5.2.1 构造数据集
文件为 dataset.py。
5.2.2 训练代码
文件为 FT.py。
配置文件 config_accelerate.yml
执行文件 run.sh
5.2.3 测试代码
结果为:

6 结语
除了以上 3 大类方法之外,还有混合参数高效微调方法,其是综合了多种 PEFT 类别思想的方法。比如 MAM Adapter 同时结合了 Adapter 和 Prompt-Tuning 的思想,UniPELT 综合了 LoRA、Prefix Tuning 和 Adapter 的思想。混合参数高效微调方法大概率优于单个高效微调方法,但训练参数和推理延时的都增加了。下次将会对大模型的加速并行框架进行探讨,欢迎大家持续关注!
相关文章
[1]《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》
[2]《Parameter-Efficient Transfer Learning for NLP》
[3]《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
[4]《GPT Understands, Too》
[5]《The Power of Scale for Parameter-Efficient Prompt Tuning》
[6]《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
[7]《BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models》
[8]《LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》
[9]《ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING》




