
拉卡拉早期基于 Lambda 架构构建数据系统面临存储成本高、实时写入性能差、复杂查询耗时久、组件维护复杂等问题。为此,拉卡拉选择使用 Apache Doris 替换 Elasticsearch、Hive、Hbase、TiDB、Oracle / MySQL 等组件,实现了 OLAP 引擎的统一、查询性能提升 15 倍、资源减少 52% 的显著成效。
拉卡拉(股票代码 300773)是国内首家数字支付领域上市企业,从支付、货源、物流、金融、品牌和营销等各维度,助力商户、企业及金融机构数字化经营。随着实时交易数据规模日益增长,拉卡拉早期基于 Lambda 架构构建的数据平台面临存储成本高、实时写入性能差、复杂查询耗时久、组件维护复杂等问题。为此,拉卡拉选择使用 Apache Doris 来替换 Elasticsearch、Hive、Hbase、TiDB、Oracle / MySQL 等组件,完成 OLAP 引擎的统一,实现了查询性能提升 15 倍、资源减少 52% 的显著成效。
面临的挑战
早期数据平台基于 Lambda 架构建设。左侧部分是批处理,右侧是实时流处理。

为满足不同业务数据需求,两条处理链路的计算结果分散存储在 Hive、HBase、Elasticsearch 、TiDB 和 Oracle / MySQL 多个组件,存储层多栈并存,体系技术繁杂,数据冗余问题较为严重。这样的架构给我们带来了众多的挑战:
报表系统存储成本高: 报表系统采用 Hive 计算和 Oracle 存储,随着业务和数据量的增长,Oracle 的扩容复杂,迫切需要“去 O”。
交易查询系统挑战: 交易系统依赖备库进行查询,但备库的存储周期短(通常一周),且部分场景需与其他主题数据关联查询,Elasticsearch、MySQL/Oracle 难以高效支持星型 / 雪花模型的多表关联查询。此外,部分业务使用 MySQL 作为存储库,分库分表的存储方案也增加了查询的复杂性。难以满足业务侧低延时查询需求。
标签系统构建挑战: 在标签构建过程中,标签数量众多采用宽表存储;标签需要频繁增加,需要数据库能够快速响应 schema 变更;需要支持商户标签点查询和实时多维度查询;且商户标签按域计算后需经常进行数据更新。该架构不能很好处理这种宽表写入、实时更新、快速 schema 变更、多种复杂查询的场景。
实时与离线分析割裂:Elasticsearch 和 MySQL 缺乏 HTAP 能力,需与外部数仓配合使用,Oracle 虽支持混合负载但资源隔离不足,易导致 OLTP 与 OLAP 相互干扰
生态兼容性局限:Elasticsearch 的 SQL 支持不完善,MySQL 分析函数有限,Oracle 与云原生工具链集成弱,难以无缝对接主流 BI 工具实现交互式分析
架构复杂性与运维成本: 早期架构基于多个 OLAP 组件,虽然功能丰富,但复杂的架构增加了运维成本和学习成本,同时也提高了保证多份存储数据一致性的难度。
基于 Apache Doris 打造统一 OLAP 引擎
为解决上述问题,从 23 年起引入 Apache Doris,从 1.2.x 版本升级至如今的 2.1.x 版本。并在 Doris 的基础上相继重构了报表系统、标签系统、对账单系统等关键应用。并陆续新上线了风控营销合作平台、营销平台、交易实时看板等业务。
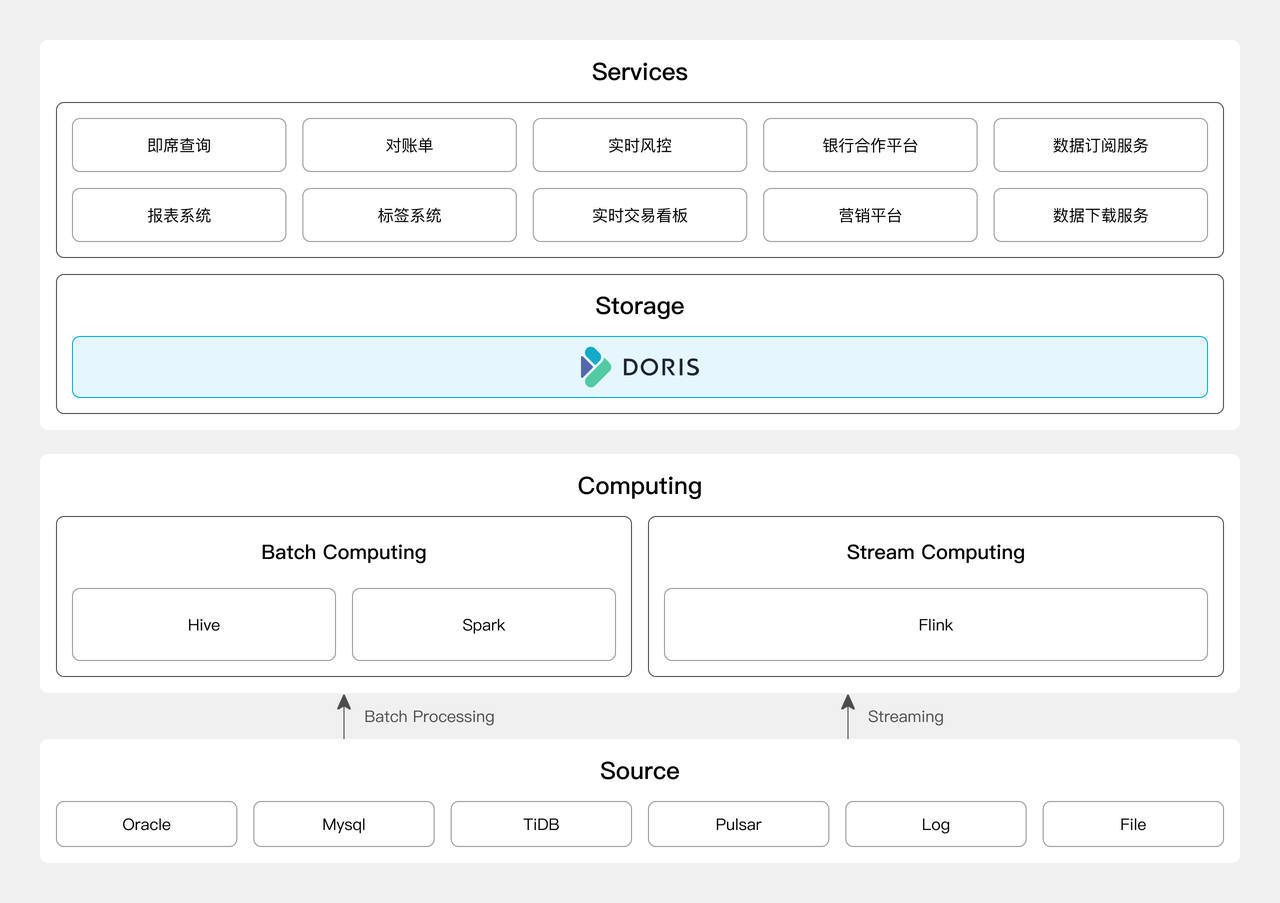
上图为引入 Apache Doris 的架构图。主要变化在数据存储层,使用 Doris 替换了 Elasticsearch、HBase、TiDB 和 Oracle / MySQL 多技术栈,实现了统一的对外存储查询引擎。统一的平台能够更好地支持数据分析和业务决策,促进企业在降本增效方面取得显著的成效:
服务器数量下降 52%:原本系统架构中同时运行 10 台 HBase、10 台 Elasticsearch 和一套 Oracle 一体机服务器,此外还占用了部分 TiDB 集群和 MySQL 资源。通过引入 Doris,并对架构进行整合优化,我们将原本分散的组件统一替换为一个 10 台规模的 Doris 集群。服务器数量下降 52%。
查询性能提升 15 倍: 引入 Doris 之后,其查询性能相较于之前的组件分别有不同程度的性能提升,尤其是在 Elasticsearch 替换后体现的尤为明显,查询耗时从原先的 15s 缩短至 1s,查询性能提升 15 倍。
开发运维效率大幅提升: 只需要使用和维护 Apache Doris 一个组件,大大简化了运维的复杂性和学习的成本。所有数据都在 Doris 中统一存储和管理,减少了数据的流转、数据管理和数据冗余,提升了开发效率。
此外,Apache Doris 在其他几方面的优势也比较明显:
丰富的生态对接: 兼容 MySQL 协议和标准 SQL 语法,支持 Tableau、Grafana 等 BI 工具直接接入,迁移成本降低 90%。提供 JDBC / ODBC 接口,与 Flink、Kafka 等流批处理框架无缝集成。
高吞吐秒级实时数据接入: 支持 Stream Load(百万行/秒)和 Kafka 直接订阅,延迟 <1 秒,写入吞吐比 ES 提升 5 倍。主键模型 (Unique Key) 支持 UPSERT 和部分列更新,避免全量重写。
LakeHouse 支持:可以和 Hive 和 Hudi 中的数据打通,做数据湖查询和处理加速。
金融核心场景实践
01 对账单系统
商户工作台内部的对账单系统,面向商户提供交易信息查询与批量对账单文件下载服务,帮助商户快速掌握交易情况,进行对账核对和经营分析。Doris 作为实时数仓,承担交易明细查询、统计报表生成等核心能力,支持高并发、低延迟的数据服务。
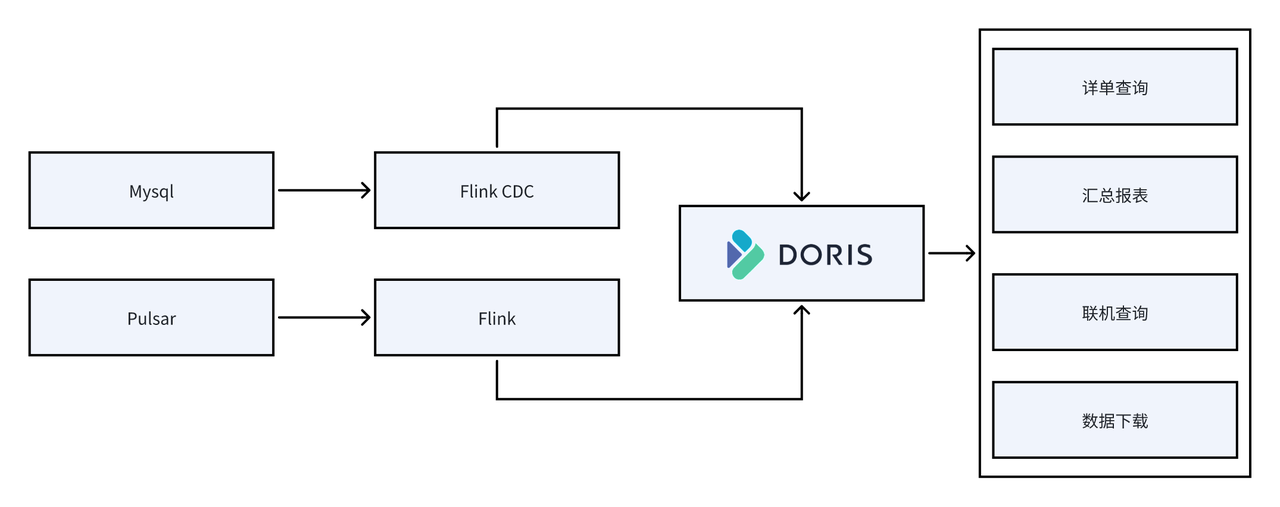
如上图所示,使用 Flink CDC 实时监听和同步 MySQL 中的商户信息、账户信息、产品配置等基础表数据;交易系统将实时增量交易数据写入 Pulsar 消息队列,Flink 消费 Pulsar 中的交易流水数据流,经过处理后实时导入到 Doris。由 Doris 支持多种查询场景,包括:
明细查询:用户可以通过多条件快速定位单笔交易信息。
汇总报表:按天、月或自定义条件生成交易汇总结果。
多表联合查询:结合商户、产品等维度信息进行多表关联分析。
数据下载:支持对账单文件、明细结果的批量导出,方便离线对账。
系统数据量庞大,每日新增数据量达到亿级规模,历史数据保留一年,总数据量达到 20TB;商户对账查询场景具有强烈的时间集中性,高峰期日查询次数达到百万级别,并发请求压力巨大。借助 Doris 优秀的并发处理和极速查询能力,查询 99 分位数响应时长在 2s 以内,结合 Flink checkpoint 控制,数据延迟可控制在 5s,极大保障了商户查询体验与业务稳定性。
Doris 主键模型解决数据乱序
在构建对账单系统的过程中,上游交易系统在完成数据处理后,由于非同步写入和其他处理步骤的介入,出现数据乱序问题。而 PaaS 消息中间件数据补传或数据片段回放时,也加剧了这一问题。
我们基于 Doris 主键模型成功杜绝了这一问题,并通过设置
sequence_column参数,以确保数据的最终一致性。具体来说,数据版本号作为一个整型字段,在交易系统的计算过程中始终保持递增,从而确保数据按照正确的顺序进行处理。
CREATE TABLE `info` ( `s_no`varchar(64) NULL COMMENT'流水号', `s_date`date NOT NULL COMMENT '日期', `s_id`varchar(32)NULL COMMENT 'ID号', `b_id`varchar(32)NOT NULL COMMENT'唯一标识', `s_b_ver`int(11)NULL COMMENT'数据版本号', ... INDEX idx_s_date (`s_date`) USING BITMAP COMMENT'', INDEX idx_s_id (`s_id`) USING BITMAP COMMENT'' )ENGINE=OLAP UNIQUE KEY(`s_no`, `s_date`,`s_id`, `b_id`) COMMENT'信息表' PARTITION BY RANGE(`s_date`) (PARTITION partition_namel VALUES [('0000-01-01'),('2024-06-01')), PARTITION p_2025 VALUES [('2025-01-01'), ('2099-01-01')) DISTRIBUTED BY HASH('s_id`) BUCKETS 10 PROPERTIES ( "replication_allocation" = "tag.location.default:3", "bloom_filter_columns" = "s_eid, s_nno, s_bno, s_n:id, t_no", "is_being_synced" = "false", "storage_format" = "V2", "enable_unique_key_merge_on_write" = "true", "light_schema_change" = "true", "function_column.sequence_col" = "s_b_ver", "disable_auto_compaction" = "false", "enable_single_replica_compaction" = "false" );使用倒排索引优化大表关联
在优化大表关联的场景中,需要对两个数据量庞大的事实表进行关联操作。这两个事实表虽然都采用了分区存储,但它们的分区时间和业务含义各不相同。在尝试将其中一张表与另一张表关联时,无法准确获取右表的查询范围,通常会导致全表扫描,从而占用大量资源并延长查询时间。
为了解决这一问题,添加了倒排索引、调整分桶策略以及右表的表结构,经过调整,查询耗时从原先的 200 秒大幅缩短至 10 秒,查询效率提升超过 20 倍。
02 实时交易看板
金融市场瞬息万变,交易者需要实时监控市场动态以做出快速决策。实时交易看板能够提供最新的市场数据、价格波动和交易量信息,帮助用户及时响应市场变化。
在实时交易看板场景中,为了提升交易信息的时效性,原先的架构采用 Java 代码从 TiDB 获取数据,经过计算后再写回至另一套 TiDB,数据加工链路较长,且对外部计算逻辑依赖较重。现在,我们优化方案为使用 Flink 进行实时处理,直接将数据写入 Doris,并在 Doris 内部完成 ETL,极大简化了数据加工链路,同时提升了架构的稳定性和容错能力。
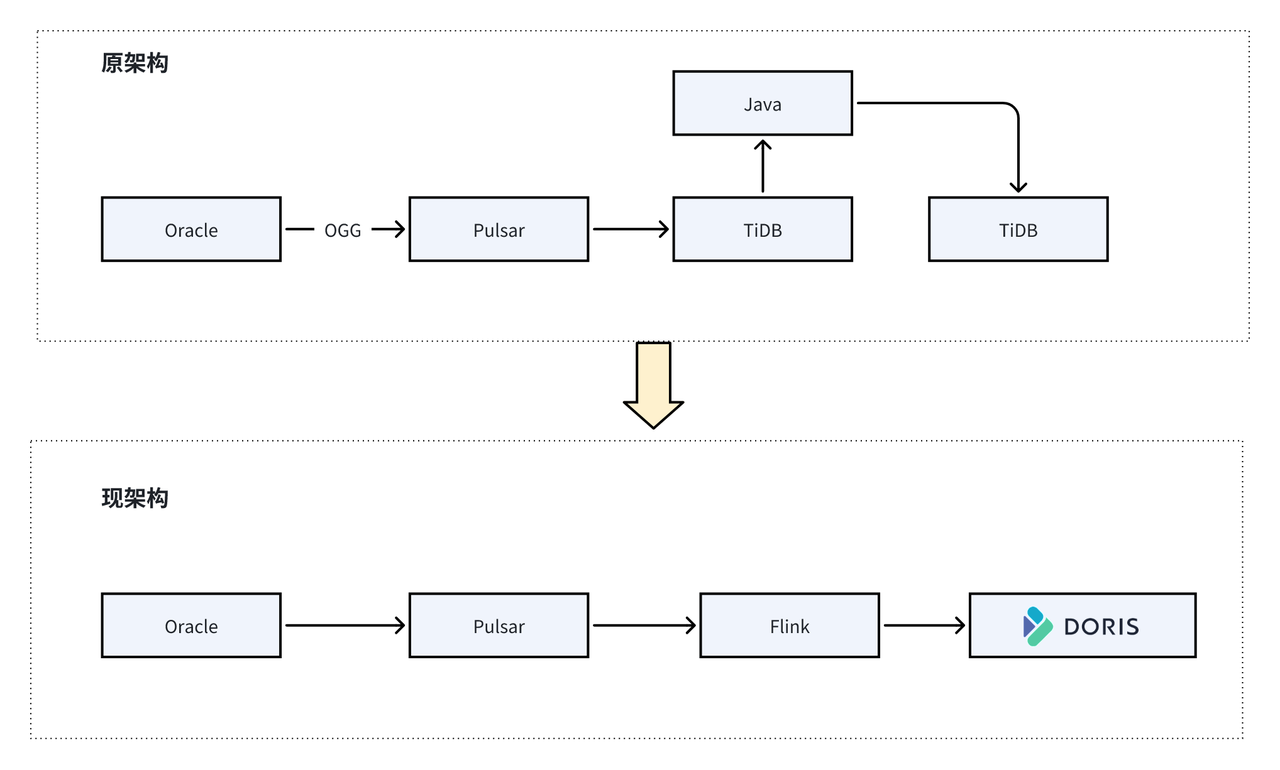
引入 Doris 后,我们进行了以下几项工作,充分发挥了其优势:
集群升级: 将 Doris 集群从 1.2.6 升级至 2.0.7 版本,整体查询与分析性能提升超过 30%。
采用 Merge-on-Write(MoW):对于主键模型的存储机制由 Merge-on-Read(MoR) 优化为 Merge-on-Write(MoW),有效避免了写入过程中多版本数据合并的问题,大幅提升了并发查询分析的效率。
部分列更新: 对于退款和调账等场景,需要对历史数据的部分字段进行修改。借助主键模型的部分列更新能力,可高效执行局部字段变更,无需重新写入整行数据,从而提升更新效率。
友好生态: Doris 与 Flink 生态友好,通过 Flink + Doris Connector,实现流式数据无缝对接,简化数据加工链路,提升架构的稳定性和容错能力。
03 实时风控场景
在风控场景中,风控系统和风控人员通过多维度筛选条件,从海量历史交易数据中快速定位可疑交易记录,并结合历史交易行为,全面了解交易背景和细节。不仅为风险评估和策略调整提供重要依据,同时也支持人工干预和决策,使风控反应更加敏捷、精准、高效。
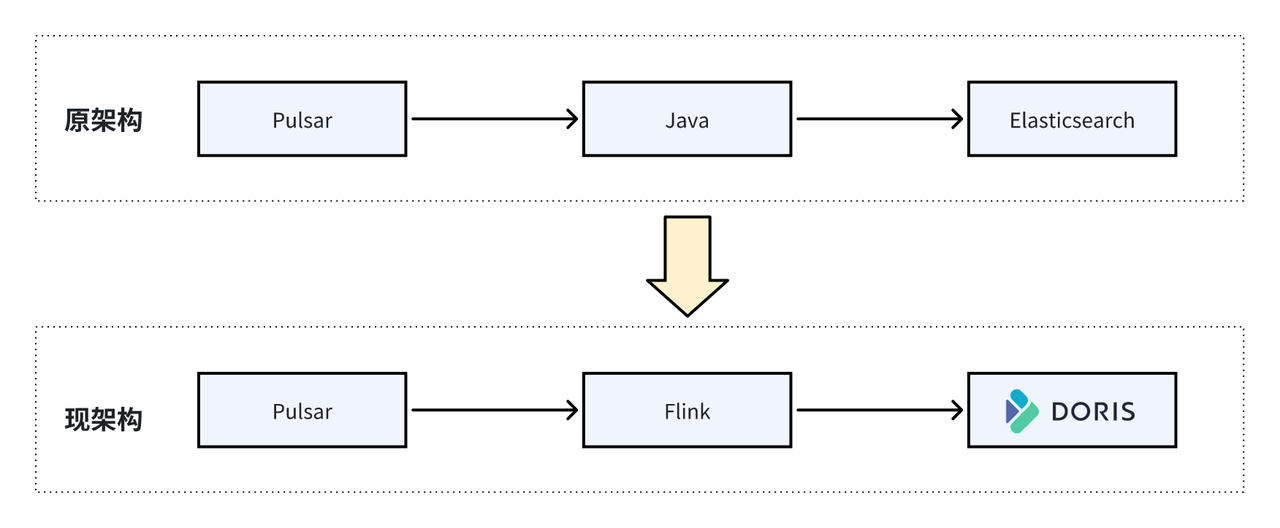
在引入 Apache Doris 之前,实时风控场景主要依赖 Elasticsearch 实现,但存在诸多问题:开发复杂度高,查询性能无法满足业务需求,且最核心的痛点在于 Elasticsearch 不支持 Join 操作,难以进行多表关联查询,严重限制了风控场景下对交易背景和细节的综合分析能力。而替换为 Doris 之后,其展现出多项显著优势:
灵活的 Schema 变更能力:在风控场景中,业务需求不断演进,要求数据库具备灵活的 Schema 变更能力。Doris 提供 Light Schema Change 支持灵活的字段和索引的增删修改。相比 Elasticsearch 需要通过 Reindex 进行 Schema 变更,Doris 的 Schema Change 机制更加高效、灵活,极大提升了数据管理的便捷性和业务适应性。
标准 SQL 查询接口:Doris 提供标准 SQL 查询接口,兼容 MySQL 协议,开发团队能够以熟悉的 SQL 方式高效查询和分析数据。相比之下,Elasticsearch 使用 DSL 查询语言,学习成本较高,复杂查询编写难度大。
强大的多维分析和复杂查询能力:随着风控业务复杂度的提升,对多维分析和多表关联的需求越来越频繁。 Elasticsearch 在处理这类复杂查询时存在局限,特别是在多维度聚合统计、复杂的多表 JOIN、子查询和窗口函数等场景中,无法满足需求。引入 Doris 后,不仅能够高效处理大规模数据,还在多维度聚合、复杂查询和多表关联、子查询等方面更加友好。
查询性能 15 倍提升: 在性能方面, Elasticsearch 查询响应时间长达 15 秒,尤其在数据量大或查询复杂的情况下,响应速度难以满足业务需求。相比之下,Doris 在相同场景下能够将查询响应时间控制在 1 秒以内,显著提升了查询效率。 而且在高并发、大数据量的查询处理上,相较于 Elasticsearch 优势更加明显。
结束语
随着业务复杂度和数据实时性要求的不断提升,未来拉卡拉也将在以下几个方向持续推进:
加大 Lakehouse 场景应用: 加大 Lakehouse 建设,将 Hive 的报表结果数据全部迁移至 Doris,解决 Hive 在时效性和交互性不足的问题,提升查询体验,满足实时查询和多角度分析需求。
加大数据加工能力建设: Apache Doris 除了支持高速查询外,在数据加工和模型构建方面也具备强大能力。后续将重点投入离线计算场景,利用物化视图的建设,实现更灵活的数据建模方式,提升对复杂指标和报表场景的支撑能力,为实时分析、风险监控、指标计算等场景提供更强算力保障。
跨集群复制 CCR 的应用: Apache Doris 在 2.0 版本中实现了跨集群复制(CCR)功能,未来将基于 CCR 功能在异地灾备、数据同步等场景进行应用,以提供更为安全可靠的使用体验,确保业务的稳定连续运行。
更多场景覆盖、高 SLA 保证和资源隔离落地: 随着更多业务场景逐步迁移至 Apache Doris 集群,当前也在积极规划混合场景下的资源管理策略。通过合理的资源隔离、以及按需拆分集群等方式,进一步优化资源利用效率,提升系统整体弹性,保障各类业务系统在高并发、高负载情况下的高 SLA 要求。




