
为推动大模型在产业落地和技术创新,今年 6 月智源研究院发布了“开源商用许可语言大模型系列+开放评测平台” 两大重磅成果,打造“大模型进化流水线”。
FlagEval(天秤)是北京智源人工智能研究院推出的大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能。
FlagEval 大语言模型评测体系当前包含 6 大评测任务,20+评测数据集,80k+评测题目。除了知名的公开数据集 HellaSwag、MMLU、C-Eval 等,FlagEval 还集成了包括智源自建的主观评测数据集 Chinese Linguistics & Cognition Challenge (CLCC) ,北京大学等单位共建的词汇级别语义关系判断、句子级别语义关系判断、多义词理解、修辞手法判断评测数据集,更多维度的评测数据集也在陆续集成中。
自 6 月 9 日上线以来,FlagEval 在短短一个月内就已收到 200+模型评测申请,并更新了首期 SFT 模型排行榜和大模型 2023 高考排行榜。在 FlagEval 8 月榜单最新榜单中,新增了通义千问、Llama2 等多个模型评测,也新增了基座模型代码生成能力评测。
新增多个明星开源模型评测:Llama2 / Qwen / InternLM / MPT / Falcon
基座模型(Base Model)榜单:
Qwen-7B、InternLM-7B 超越 Llama2,分列第一、第二名。

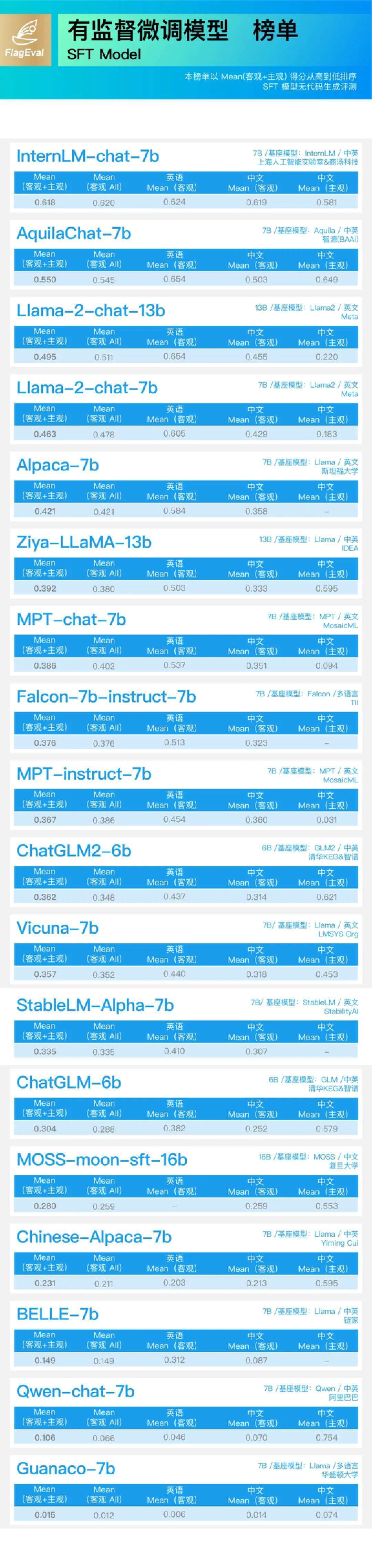
有监督微调模型(SFT Model)榜单:
InternLM-chat-7B 夺魁,刷新中英客观评测记录,悟道·天鹰 AquilaChat 排名第二;
Qwen-chat-7B 中英文客观评测结果欠佳,远低于其基座模型的客观评测表现;但在中文主观评测上,Qwen-chat-7B 以 75.4% 准确率排名第一,与第二名 ChatGLM2-6B(62.1%)拉开较大差距。
备受关注的 Llama2 基座模型 7B、13B 综合评测结果相比于第一代提升了 10%、25%;Llama2-Chat 7B、13B 英文能力突出,中文存在明显短板,中文主观评测准确率仅为 18.3%、22%,在 SFT 模型榜单上排名第三,仅次于 InternLM 和悟道·天鹰 Aquila。
新增针对基座模型 HumanEval 代码生成能力评测
近期,“代码生成能力”新晋成为大语言模型领域的热门话题,开源基座模型如 Llama2 的技术报告特别强调了“代码生成能力”作为其关键特性。
基座模型强大的代码生成能力为后续的代码语料微调提供了坚实基础。因此,本期榜单引入了针对基座模型的 HumanEval 评测:
Pass@1 的评测结果显示,国产大模型 Qwen、InternLM 超越 Llama2-13B,分列第一、第二名。
Pass@100 结果显示,悟道·天鹰 Aquila-7B 的表现接近 Llama-13B,但与第二代 Llama2-13B 相比仍有一定差距。
HumanEval 是由 OpenAI 编写发布的代码生成评测数据集,包含 164 道人工编写的 Python 编程问题,模型针对每个单元测试问题生成 k(k=1,10,100)个代码样本,如果有任何样本通过单元测试,则认为问题已解决,并报告问题解决的总比例,即 Pass@k 得分。
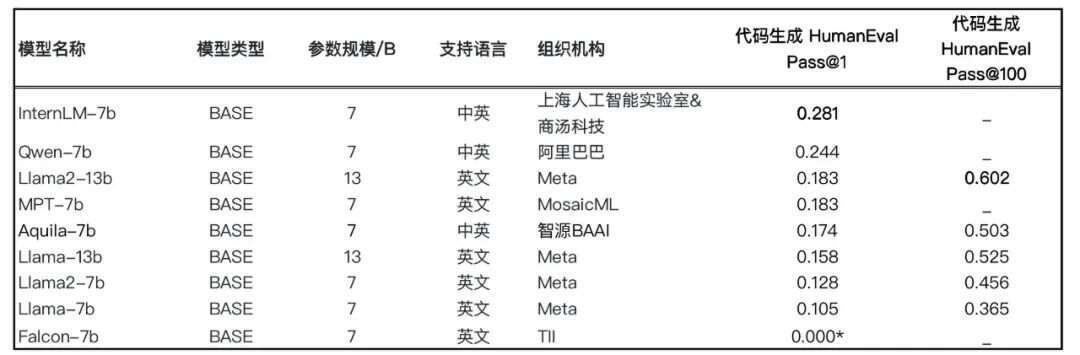
Falcon-7b HumanEval 评测结果出自 Meta Llama2 官方论文 :
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
评测说明:
在评测时,FlagEval 根据数据集的不同规模进行了自动化采样。
更多评测结果请登录官网查看:https://flageval.baai.ac.cn/




