
1.背景
vivo 人工智能计算平台小组从 2018 年底开始建设 AI 计算平台至今,已经在 kubernetes 集群、以及离线的深度学习模型训练等方面,积累了众多宝贵的开发、运维经验,并逐步打造出稳定的基础容器平台 - AI 容器平台(VContainer)。为了支撑公司 AI 在线业务的发展,满足公司对算力资源的高效调度管控需求,需要将在线业务,主要包括 C 端、推理等业务,由原来的虚拟机或物理机迁移至 AI 容器平台。于是小组从 2020 年初开始,基于在线业务的需求对 AI 容器平台进行进一步建设,并将平台与公司的 CMDB、CICD 等基础模块进行打通,使在线业务能够顺利从虚拟机、物理机迁移至 AI 容器平台。
2.ingress 简介
kubernetes 将业务运行环境的容器组抽象为 Pod 资源对象,并提供各种各样的 workload(deployment、statefulset、daemonset 等)来部署 Pod,同时也提供多种资源对象来解决 Pod 之间网络通信问题,其中
,Service 解决 kubernetes 集群内部网络通信问题 (东西向流量),Ingress 则通过集群网关形式解决 kubernetes 集群外访问 集群内服务的网络通信问题 (南北向流量)。
kubernetes Ingress 资源对象定义了集群内外网络通信的路由协议规范,目前有多个 Ingress 控制器实现了 Ingress 协议规范,其中 Nginx Ingress 是最常用的 Ingress 控制器。Nginx Ingress 有 2 种实现,其一由 kubernetes 社区提供,另外一个是 Nginx Inc 公司提供的,我们采用是 kubernetes 官方社区提供的 ingress-nginx。
ingress-nginx 包含 2 个组件:ingress controller 通过 watch kubernetes 集群各种资源(ingress、endpoint、configmap 等)最终将 ingress 定义的路由规则转换为 nginx 配置;nginx 将集群外部的 HTTP 访问请求转发到对应的业务 Pod。
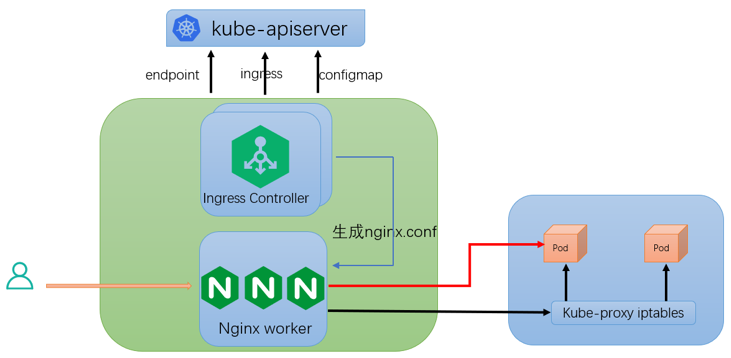
1.nginx 所有转发逻辑都是根据 nginx.conf 配置来执行的,ingress controller 会 watch kubernetesapiserver 各种资源对象,综合起来形成最终的 nginx.conf 配置;
2.ingress 资源对象:生成 nginx 中 server host、location path 配置,以及根据 ingress annotation 生成服务维度的 nginx 配置;
3.configmap 资源对象:生成全局维度的 nginx 配置信息;
4.endpoint 资源对象:根据 Pod IP 动态变更 nginx upstream ip 信息。
其中针对 ingress nginx upstream 有 2 种路由方案:
方案一: 上图 红色箭头所示方案:nginx upstream 设置 Pod IP。由于 Pod IP 不固定,nginx 基于 ngx-lua 模块将实时监听到的 Pod IP 动态更新到 upstream,nginx 会直接将 HTTP 请求转发到业务 Pod,这是目前 ingress nginx 默认方案;
方案二: 上图 黑色箭头所示方案:nginx upstream 设置 Service name。由于 Service name 保持不变,nginx 直接使用 kubernetes 集群已有的 Service 通信机制,请求流量会经过 kube-proxy 生成的 iptables,此时 nginx 无需动态更新 upstream,这是 ingress nginx 早期方案。
由于 ngx-lua 动态更新 upstream 这个方案非常稳定,以及 kubernetes Service 通过 iptables 通信的网络延时、DNAT 和 conntrack 的复杂性,我们采用了方案一。
3.架构
kubernetes ingress-nginx 控制器基于 kubernetes 容器化部署,官方提供多种部署方案。
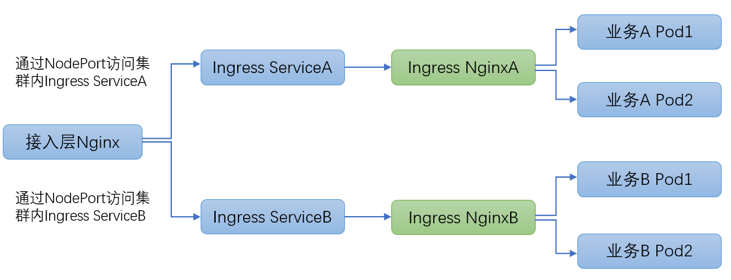
3.1 deployment + service 部署方案
方案细节详见官方文档:https://kubernetes.github.io/ingress-nginx/deploy/baremetal/#over-a-nodeport-service。
此方案中 ingress 控制器通过 deployment 部署,通过 NodePort service 暴露服务,公司接入层 Nginx 通过 NodePort 访问集群内 ingress 服务,每个业务都独立部署完全隔离的 ingress 集群。
方案优点:每个服务可以独立部署 ingress 集群,ingress 集群彼此完全隔离。
方案缺点:
(1)接入层 Nginx 需要通过 NodePort 方式访问集群内 ingress 服务,NodePort 会绕经 kubernetes 内部的 iptables 负载均衡,涉及 DNAT、conntrack 内核机制,存在端口资源耗尽风险,网络延时较高并且复杂性非常高,稳定性较差。
(2)每个业务都独立部署 ingress 集群,由于 ingress 必须高可用部署多副本,由此在部署诸多长尾小业务时会极大浪费集群资源。
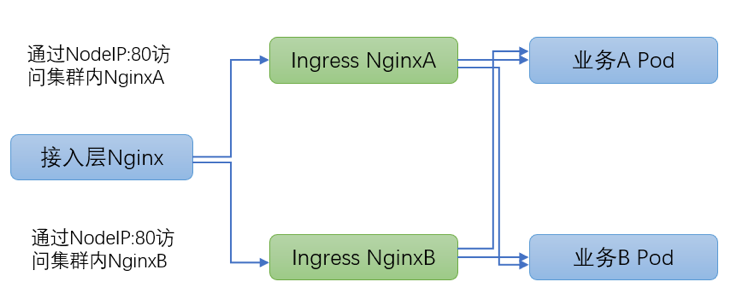
3.2 daemonset + hostNetwork 部署方案
方案细节详见官方文档:https://kubernetes.github.io/ingress-nginx/deploy/baremetal/#via-the-host-network
此方案中 ingress 控制器通过 daemonset 部署,并且采用宿主机网络,每个 node 机器只部署 1 个 ingresspod,并且 ingress pod 独占 node 整机资源。
方案优点:
(1)ingress pod 使用宿主机网络,网络通信绕过 iptables、DNAT、conntrack 众多内核组件逻辑,网络延时低并且复杂性大为降低,稳定性较好;
(2)多业务共享 ingress 集群,极大节省集群资源。
方案缺点:
(1)多业务共享 ingress 集群,由于隔离不彻底可能会互相干扰造成影响;
(2)ingress daemonset 部署需要提前规划 node 节点,增删 ingress nginx 控制器之后需要更新接入层 Nginx upstream 信息。
经过仔细考量和对比两种部署方案之后,我们采用方案二,针对方案二存在的两个问题,我们提供了针对性解决方案。
针对缺点 1,我们提供了 ingress 集群隔离方案,详见 3.3 章节。
针对缺点 2,我们提供 ingress 一键部署脚本、并且结合公司接入层 Nginx 变更工单实现流程自动化。
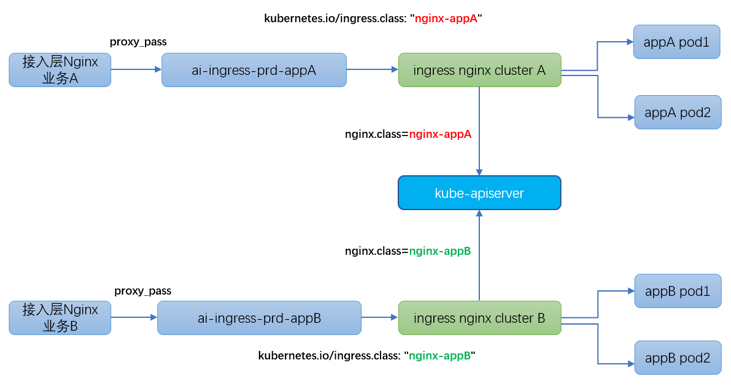
3.3 ingress 多集群隔离部署
kubernetes 集群部署业务时,某些场景下需要将 ingress 隔离部署,例如预发环境和生产环境的业务流量需要严格区分开,某些大流量业务、重保核心业务也需要进行隔离。
ingress nginx 官方提供多集群部署方案,详见官方文档:https://kubernetes.github.io/ingress-nginx/user-guide/multiple-ingress/。
事实上,多业务共享 ingress 集群的原因在于 ingresscontroller 在监听 kubernetes apiserver 时 拉取了所有 ingress 资源对象,没有做过滤和区分。所幸 ingress nginx 官方提供“kubernetes.io/ingress.class”机制将 ingress 资源对象进行归类。
最终达到的效果是:
ingress controllerA 仅仅只 watch"属于业务 A 的 ingress 资源对象"
nginx controllerB 仅仅只 watch “属于业务 A 的 ingress 资源对象”
我们在 3.2 章节 daemonset + hostNetwork 部署方案的基础之上,结合 ingress 集群隔离部署方案,最终实现了 ingress 集群的高可用、高性能、简单易维护、特殊业务可隔离的部署架构。
4.性能优化
ingress-nginx 集群作为 kubernetes 集群内外通信的流量网关,需要优化性能满足业务需求,我们在 nginx 和内核配置层面做了相应的优化工作。
4.1 宿主机中断优化
ingress-nginx 物理机执行 top 命令发现每个 CPU 的 si 指标不均衡,针对此问题 我们开启了网卡多队列机制 以及中断优化。
开启网卡多队列:
ethtool -l eth0 // 查看网卡可以支持的多队列配置ethtool -L eth0 combined 8 // 开启网卡多队列机制中断打散优化:
service irqbalance stop // 首先关闭irqbalance系统服务sh set_irq_affinity -X all eth0 // Intel提供中断打散脚本:https://github.com/majek/ixgbe/blob/master/scripts/set_irq_affinity4.2 内核参数优化
我们针对内核参数也做了优化工作以提升 nginx 性能,主要基于 nginx 官方提供的性能优化方案:https://www.nginx.com/blog/tuning-nginx/
(1)调整连接队列大小
nginx 进程监听 socket 套接字的 连接队列大小默认为511 ,在高并发场景下 默认的队列大小不足以快速处理业务流量洪峰,连接队列过小会造成队列溢出、部分请求无法建立 TCP 连接,因此我们调整了 nginx 进程连接队列大小。
sysctl -w net.core.somaxconn=32768(2)调整源端口使用范围
nginx 进程充当反向代理时 会作为客户端与 upstream 服务端建立 TCP 连接,此时会占用临时端口,Linux默认的端口使用范围是32768-60999,在高并发场景下,默认的源端口过少会造成端口资源耗尽,nginx 无法与 upstream 服务端建立连接,因此我们调整了默认端口使用范围。
sysctl -w net.ipv4.ip_local_port_range="1024 65000"(3)调整最大文件描述符数限制
nginx 进程充当反向代理时 会作为服务端与接入层 nginx 建立 TCP 连接,同时作为客户端与 upstream 服务端建立 TCP 连接,即 1 个 HTTP 请求在 nginx 侧会耗用 2 条连接,也就占用 2 个文件描述符。在高并发场景下,为了同时处理海量请求,我们调整了最大文件描述符数限制。
sysctl -w fs.file-max=1048576(4)调整 TIME_WAIT 参数
nginx 进程充当反向代理时 会作为客户端与 upstream 服务端建立 TCP 连接,连接会超时回收和主动释放,nginx 侧作为 TCP 连接释放的发起方,会存在 TIME_WAIT 状态的 TCP 连接,这种状态的 TCP 连接会长时间(2MSL 时长) 占用端口资源,当 TIME_WAIT 连接过多时 会造成 nginx 无法与 upstream 建立连接。
处理 TIME_WAIT 连接通常有 2 种解决办法:
net.ipv4.tcp_tw_reuse:复用TIME_WAIT状态的socket用于新建连接net.ipv4.tcp_tw_recycle:快速回收TIME_WAIT状态连接由于 tcp_tw_recycle 的高危性,4.12内核已经废弃此选项,tcp_tw_reuse 则相对安全,nginx 作为 TCP 连接的发起方,因此启用此选项。
sysctl -w net.ipv4.tcp_tw_reuse=1以上内核参数都使用kubernetes提供的initContainer机制进行设置。
initContainers: - name: sysctl image: alpine:3.10 securityContext: privileged: true command: - sh - -c - sysctl -w net.core.somaxconn=32768; sysctl -w net.ipv4.ip_local_port_range='1024 65000'; sysctl -w fs.file-max=1048576; sysctl -w net.ipv4.tcp_tw_reuse=14.2 nginx 连接数
nginx 作为服务端与接入层 nginx 建立 TCP 连接,同时作为客户端与 upstream 服务端建立 TCP 连接,由此两个方向的 TCP 连接数都需要调优。
(1)nginx 充当服务端,调整 keep-alive 连接超时和最大请求数
ingress-nginx 使用keep-alive选项设置 接入层 nginx 和 ingress nginx 之间的连接超时时间(默认超时时间为 75s)。
使用keep-alive-requests选项设置 接入层 nginx 和 ingress nginx 之间 单个连接可承载的最大请求数(默认情况下单连接处理 100 个请求之后就会断开释放)。
在高并发场景下,我们调整了这两个选项值,对应到 ingress-nginx 全局 configmap 配置。
keep-alive: "75"keep-alive-requests: "10000"(2)nginx 充当客户端,调整 upstream-keepalive 连接超时和最大空闲连接数
ingress-nginx 使用 upstream-keepalive-connections选项 设置 ingress nginx 和 upstream pod 之间 最大空闲连接缓存数(默认情况下最多缓存 32 个空闲连接)。
使用upstream-keepalive-timeout选项 设置 ingress nginx 和 upstream pod 之间的连接超时时间(默认超时时间为 60s)。
使用upstream-keepalive-requests选项 设置 ingress nginx 和 upstream pod 之间 单个连接可承载的最大请求数(默认情况下单连接处理 100 个请求之后就会断开释放)。
在高并发场景下,我们也调整了这 3 个选项值,使得 nginx 尽可能快速处理 HTTP 请求(尽量少释放并重建 TCP 连接),同时控制 nginx 内存使用量。
upstream-keepalive-connections: "200"upstream-keepalive-requests: "10000"upstream-keepalive-timeout: "100"4.3 网关超时
ingress nginx 与 upstream pod 建立 TCP 连接并进行通信,其中涉及 3 个超时配置,我们也相应进行调优。
proxy-connect-timeout选项 设置 nginx 与 upstream pod 连接建立的超时时间,ingress nginx 默认设置为 5s,由于在 nginx 和业务均在内网同机房通信,我们将此超时时间缩短到 1s。
proxy-read-timeout选项 设置 nginx 与 upstream pod 之间读操作的超时时间,ingress nginx 默认设置为 60s,当业务方服务异常导致响应耗时飙涨时,异常请求会长时间夯住 ingress 网关,我们在拉取所有服务正常请求的 P99.99 耗时之后,将网关与 upstream pod 之间读写超时均缩短到 3s,使得 nginx 可以及时掐断异常请求,避免长时间被夯住。
proxy-connect-timeout: "1"proxy-read-timeout: "3"proxy-send-timeout: "3"如果某个业务需要单独调整读写超时,可以设置 ingress annotation(nginx.ingress.kubernetes.io/proxy-read-timeout 和 nginx.ingress.kubernetes.io/proxy-send-timeout)进行调整。
5.稳定性建设
ingress-nginx 作为 kubernetes 集群内外通信的流量网关,而且多服务共享 ingress 集群,因此 ingress 集群必须保证极致的高可用性,我们在稳定性建设方面做了大量工作,未来会持续提升 ingress 集群稳定性。
5.1 健康检查
接入层 nginx 将 ingress nginx worker IP 作为 upstream,早期接入层 nginx 使用默认的被动健康检查机制,当 kubernetes 集群某个服务异常时,这种健康检查机制会影响其他正常业务请求。
例如:接入层 nginx 将请求转发到 ingress nginx 集群的 2 个实例。
upstream ingress-backend { server 10.192.168.1 max_fails=3 fail_timeout=30s; server 10.192.168.2 max_fails=3 fail_timeout=30s;}如果某个业务 A 出现大量 HTTP error,接入层 nginx 在默认的健康检查机制之下会将 ingress nginx 实例屏蔽,但是此时业务 B 的请求是正常的,理应被 ingress nginx 正常转发。
针对此问题,我们配合接入层 nginx 使用 nginx_upstream_check_module 模块来做主动健康检查,使用/healthz 接口来反馈 ingress-nginx 运行的健康状况,这种情况下接入层 nginx 不依赖于实际业务请求做 upstream ip 健康检查,因此 kubernetes 集群每个业务请求彼此独立,不会互相影响。
upstream ingress-backend { server 10.192.168.1 max_fails=0 fail_timeout=10s; server 10.192.168.2 max_fails=0 fail_timeout=10s; check interval=1000 rise=2 fall=2 timeout=1000 type=http default_down=false; check_keepalive_requests 1; check_http_send "GET /healthz HTTP/1.0\r\n\r\n"; check_http_expect_alive http_2xx; zone ingress-backend 1M;}5.2 无损发布
ingress nginx 社区活跃,版本迭代较快,我们也在持续跟踪社区最新进展,因此不可避免涉及 ingress nginx 自身的部署更新。在 ingress nginx 控制器部署更新的过程中必须保证流量完全无损。
接入层 nginx 基于 openresty 开发了 upstream 动态注册和解绑接口,在此之上,我们结合 kubernetes 提供的 Pod lifecycle 机制,确保在解绑 ingress nginx ip 之后进行实际的更新部署操作,确保在 ingress nginx 新实例健康检查通过之后动态注册到接入层 nginx。
5.3 webhook 校验配置
ingress nginx 提供 main-snippet、http-snippet 和 location-snippet 机制使得上层应用可以自定义官方仍未支持的 nginx 配置,但是默认情况下,ingress nginx 不会校验这些自定义配置的正确性,如果某个应用自定义了错误的 nginx 配置,nginx 读取该错误配置之后 reload 操作会失败,控制器 pod 会一直 crash 并不断重启。由于一个应用使用了错误的 ingress 配置导致整个 ingress 集群受损,这种问题非常严重,所幸 ingress nginx 官方提供了相应的vadatingwebhook来主动校验应用的 ingress 配置,如果配置错误就直接拦截,由此保护了 ingress 集群的稳定。
containers: - args: - --validating-webhook=:9090 - --validating-webhook-certificate=/usr/local/certificates/validating-webhook.pem - --validating-webhook-key=/usr/local/certificates/validating-webhook-key.pem5.4 监控告警
ingress nginx 官方提供grafana模板来做可视化监控,基于官方提供的监控指标,我们使用内部的告警平台配置了 ingress 相关的告警项,包括 ingress controller HTTP 请求成功率、响应延时、CPU 使用率、内存使用率、Pod 状态异常、Pod 重启、Reload 失败等。基于这些监控告警项,会第一时间获知 ingress 集群的运行状态,并迅速排查和解决问题。
5.5 优化重试机制
nginx 提供了默认的upstream请求重试机制,默认情况下,当 upstream 服务返回 error 或者超时,nginx 会自动重试异常请求,并且没有重试次数限制。由于接入层 nginx 和 ingress nginx 本质都是 nginx,两层 nginx 都启用了默认的重试机制,异常请求时会出现大量重试,最差情况下会导致集群网关雪崩。我们和接入层 nginx 一起解决了这个问题:接入层 nginx 必须使用 proxy_next_upstream_tries 严格限制重试次数,ingress nginx 则使用 proxy-next-upstream="off"直接关闭默认的重试机制。
6.总结展望
vivo AI 计算平台 kubernetes 集群 ingress 网关目前承担了人工智能 AI 业务的大部分流量,随着业务不断容器化部署,ingress 网关需要在功能丰富性、性能、稳定性方面进一步提升。展望后续工作,我们计划在以下方面着手,进一步完善 ingress 网关。
6.1 服务限流
目前大多数业务共享 ingress 集群,如果某个业务出现流量激增暴涨 超过了 ingress 集群服务能力,会影响其他业务的可用性,虽然 ingress 网关配置了一系列监控告警以及相应的快速扩容方案,但仍然存在流量洪峰拖垮 ingress 集群的风险。ingress nginx 提供了服务限流能力,但是只支持以客户端 IP 维度做限流,不具备实际使用的可能性,我们希望能做到以业务 ingress 维度做服务限流,提高服务限流能力的易用性,最大程度保护 ingress 集群避免流量洪峰的冲击。
6.2 支持 grpc
目前有个别业务希望直接暴露 GRPC 服务供其他服务调用,但是 ingress nginx 只支持GRPCS(grpcbase tls-http2),这其中带来了证书分发和管理的复杂性、加解密的性能损耗,而且内网可信环境下 普通业务无需加密通信,因此需要支持 GRPC(grpc base plaintext http2(non-TLS)),社区也迫切希望具备这个能力,相关的 issue 和 PR 数不胜数,但是均被项目创始人回绝了,主要是目前 ingress nginx 不能以 ingress 维护开启 http2 特性 以及现有机制无法自动探测和分发 HTTP1.x 和 HTTP2 流量。
6.3 日志分析
ingress nginx 默认日志方案是标准的云原生方式,还不具备日志收集以及日志分析运营的能力。如果 ingress nginx 日志能对接公司内部的日志中心(日志文件落盘并由 agent 程序收集至统一的日志中心),那么 ingress 集群的排错易用性、服务质量分析运营能力会大幅提升。鉴于 ingress 集群流量巨大、日志文件落盘的性能损耗、日志中心单服务的写入限制,我们会谨慎推进这项工作,一切工作都需要在保证 ingress 集群的稳定性前提之下有序开展。
作者简介:
王杰,曾就职于阿里,目前是 vivo 人工智能部计算平台组资深工程师,热衷于 Kuberneres、容器、ServiceMesh 等云原生技术。




