
在信息爆炸的互联网时代,推荐系统可以理解用户的个性化偏好和需求,帮助用户筛选出自己感兴趣的产品和服务。然而,传统的基于协同过滤的推荐系统无法解决数据稀疏和冷启动问题。知识图谱是一种表示实体之间的复杂关系的异构图。在本文,我会介绍如何将知识图谱作为辅助信息引入推荐系统,以解决传统方法的缺点和提升推荐系统的性能。主要介绍:
推荐系统
知识图谱
知识图谱辅助推荐系统
推荐系统
推荐系统的目标是满足用户个性化需求,降低用户筛选信息的难度。推荐系统有着广泛地应用,在 MDB 的电影推荐中可以推荐更多人喜欢的电影,在 Amazon 的图书推荐会推荐与当前书相似的书,Booking.com 会推荐可能会感兴趣的旅游的目的地,Quora 上对用户可能感兴趣问答的推荐,Tik tok 上对用户可能感兴趣的短视频推荐,以及音乐网站对用户可能感兴趣的音乐推荐。
推荐系统有两大任务,评分预测和点击率预测。
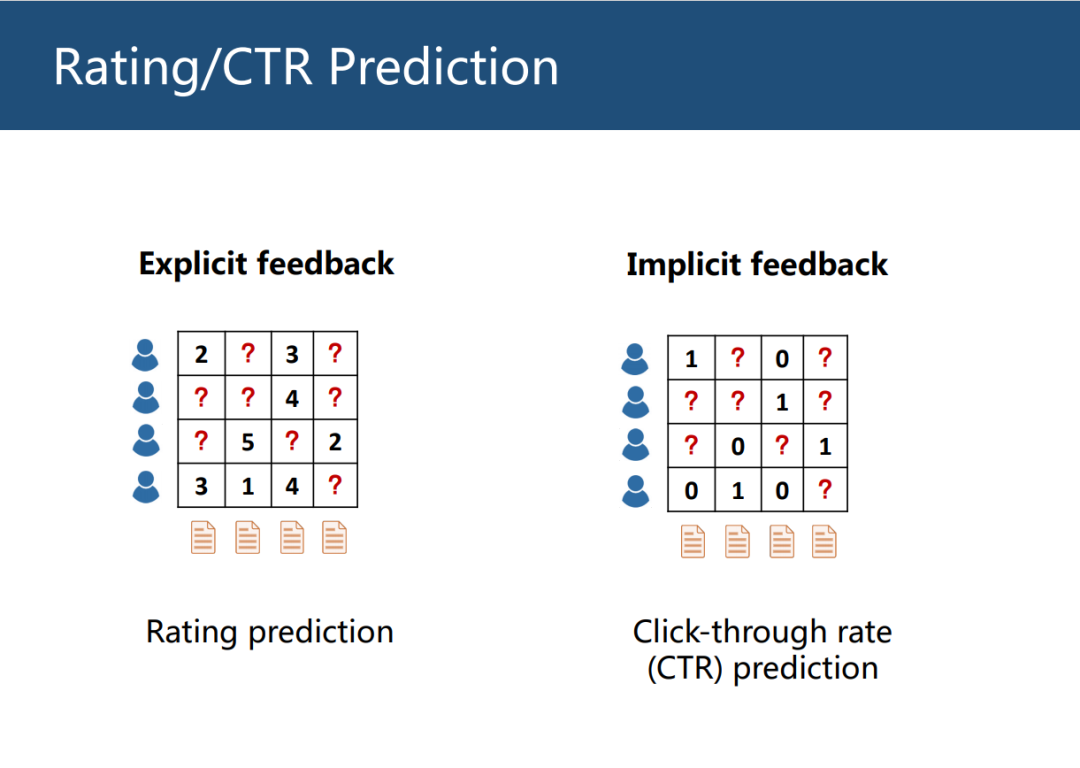
评分预测是给定用户对物体的打分,可以直接地反应用户喜好程度,因此称为显式反馈(Explicit feedback)
点击预测是给定用户对物体的点击情况,并不能显式地反应出用户偏好,因此称为隐式反馈(Implicit feedback),隐式反馈收集难度更低,因此真实线上环境中常用 Implicit feedback
1. 协同过滤 collaborative filtering
协同过滤(Collaborative Filtering, CF)假定相似用户有相似偏好,根据用户历史行为算出用户相似度,并用相似度加权平均其他用户的评分来预测该用户未打分物体的评分。
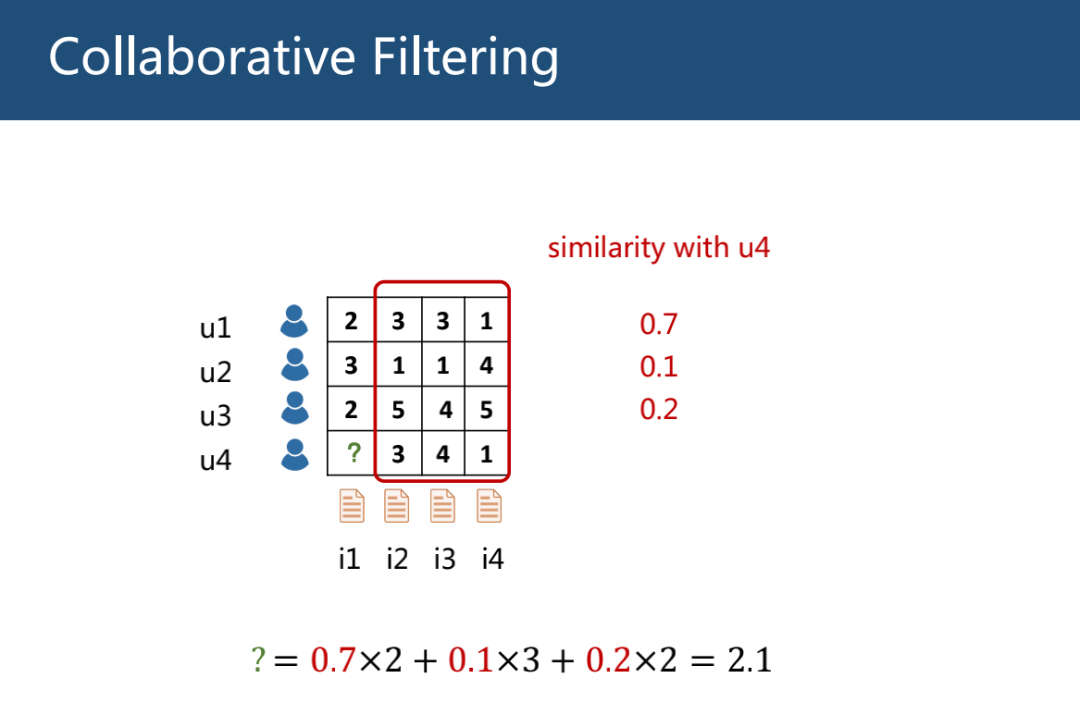
CF 存在的缺点:
用户、物体矩阵存在稀疏性,用少量数据预测大量缺失的数据存在过拟合的风险。
冷启动问题,难以解决新用户和新物品没有历史数据的情况。
2. CF + Side Information
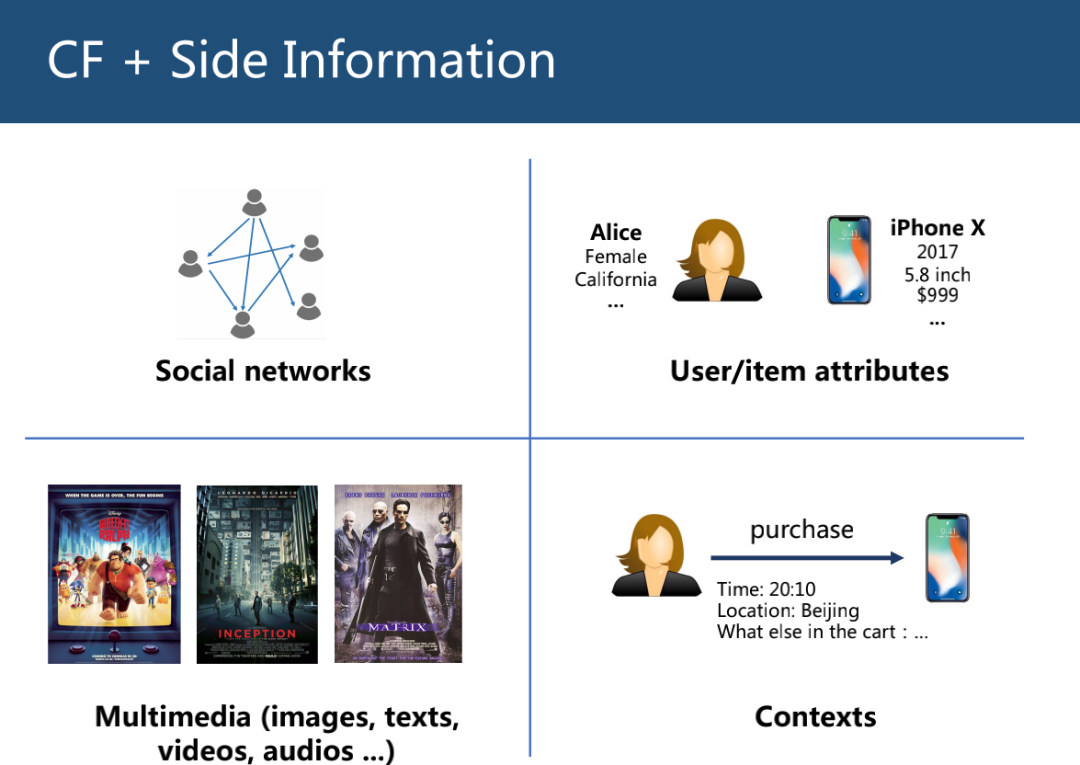
通过引入辅助信息(Side Information)来解决协同过滤存在的问题,常用的辅助信息包括社交网络比如微博间关注的关系、用户物品的属性信息、图片文本音频视频等多媒体信息、上下文信息比如购买时的位置时间信息。
知识图谱
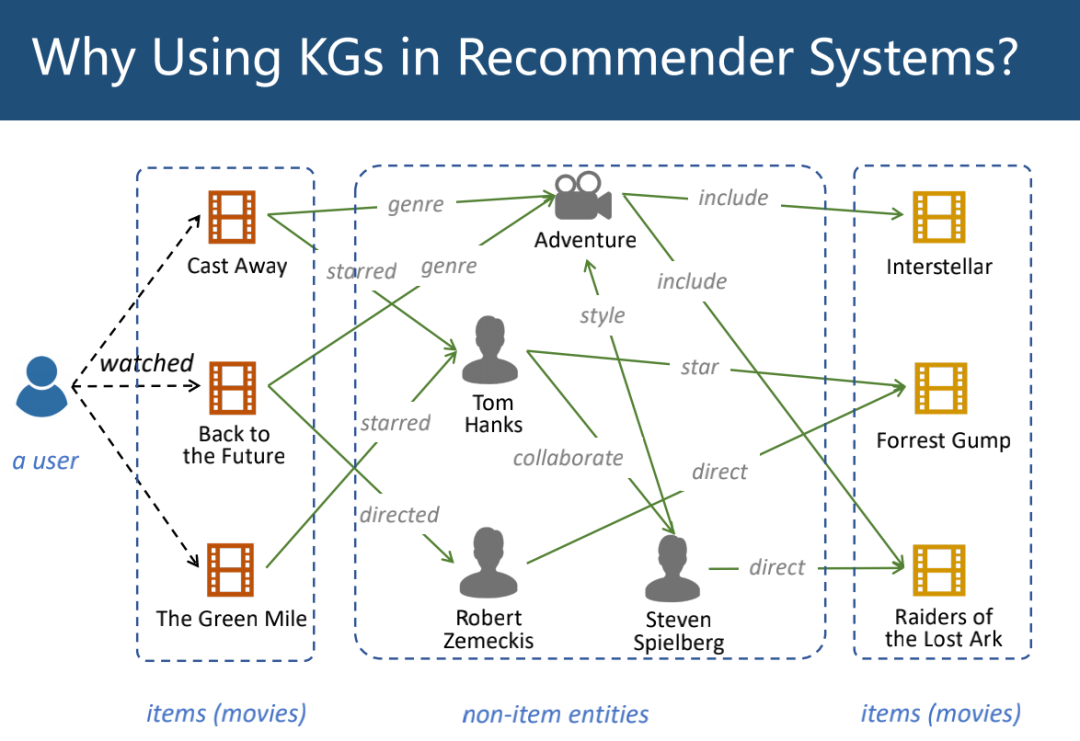
知识图谱(Knowledge Graph, KG)也可以看作一种辅助信息,KG 是一种有向异构图,它的节点表示实体,边表示实体间关系。一个 KG 通常包含多个三元组,形如(head, relation, tail),表示头实体与尾实体存在某种关系。我们假定推荐系统中的物品也是一个 KG 中的节点,因此 KG 提供了物品和物品之间的关系。
1. 知识图谱实例
以电影推荐为例,一个用户看过的电影可以靠 KG 中的实体连接到其他电影,通过合理推断,可以认为用户也会喜欢与该电影紧密连接的电影,因此从电影的属性和特征出发,一个 KG 可以帮助我们合理地推测用户的兴趣。
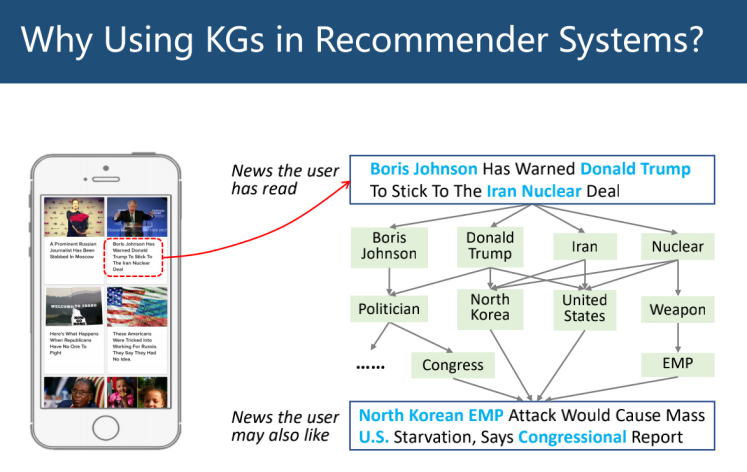
以新闻推荐为例,可以通过用户阅读过的新闻实体,利用 KG 重复扩展并连接到另一条新闻。虽然下图中上下两条新闻字面上没有重合,但可以通过常识知识图谱进行判断关联非常紧密。
2. 知识图谱嵌入 Knowledge Graph Embedding
知识图谱嵌入(Knowledge Graph Embedding, KGE)可以解决知识图谱作为复杂图结构难以直接利用的问题,KGE 可以学习 KG 中实体关系的低维向量表示。
常用转移距离模型(Translate Distance Model)
TransE 目标是使 head 实体 embedding 加上 relation embedding 接近 tail 实体 embedding。
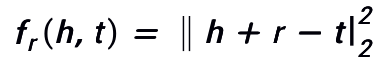
TransH 解决一对多多对多关系,通过计算 head 和 tail 实体 embedding 在关系 embedding 上的投影,计算投影之间的关系。
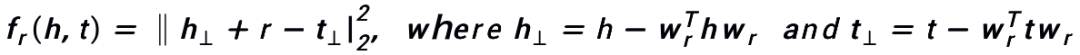
TransR 通过将 head、tail embedding 转换到 relation embedding 空间,是转换后的投影满足三元组的关系。

知识图谱辅助推荐系统
Knowledge-Graph-Enhanced Recommender Systems
问题定义(Problem Formulation):给定用户集合、物品集合、用户参与标签,以及相关知识图谱 G,目标为预测用户点击概率 y^uv。
知识图谱嵌入方法分为两类:
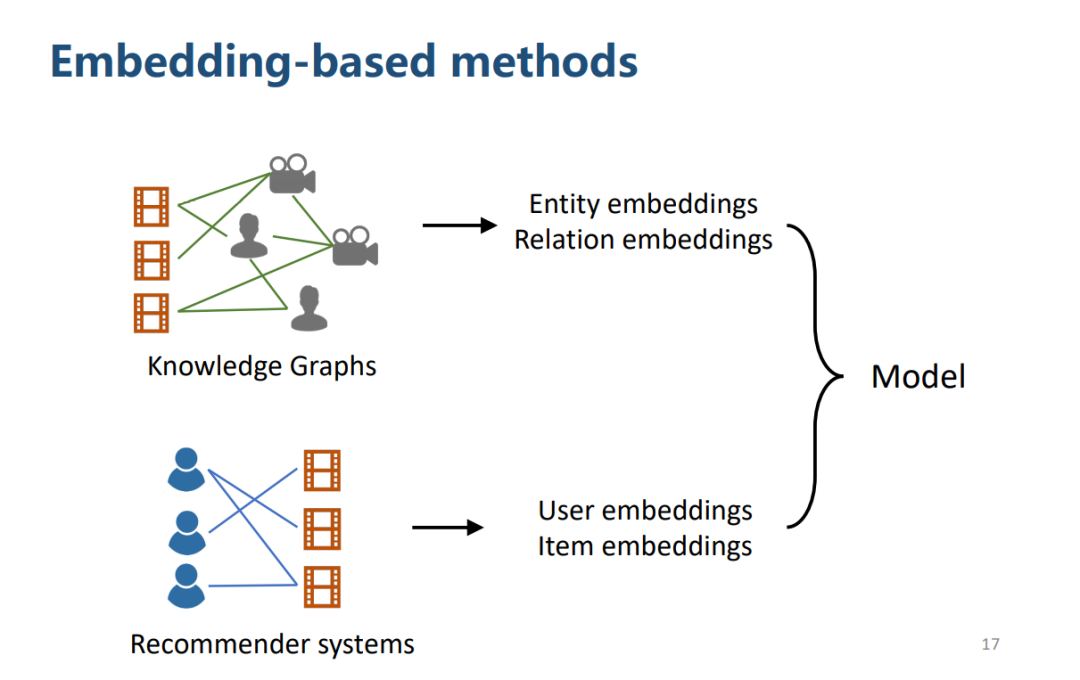
基于嵌入方法(Embedding-based methods)
首先用 KGE 的方法处理 KG,得到实体、关系的 embedding,利用推荐系统的方法得到物品、用户的 embedding,设计一种模型来融合四类 embedding。
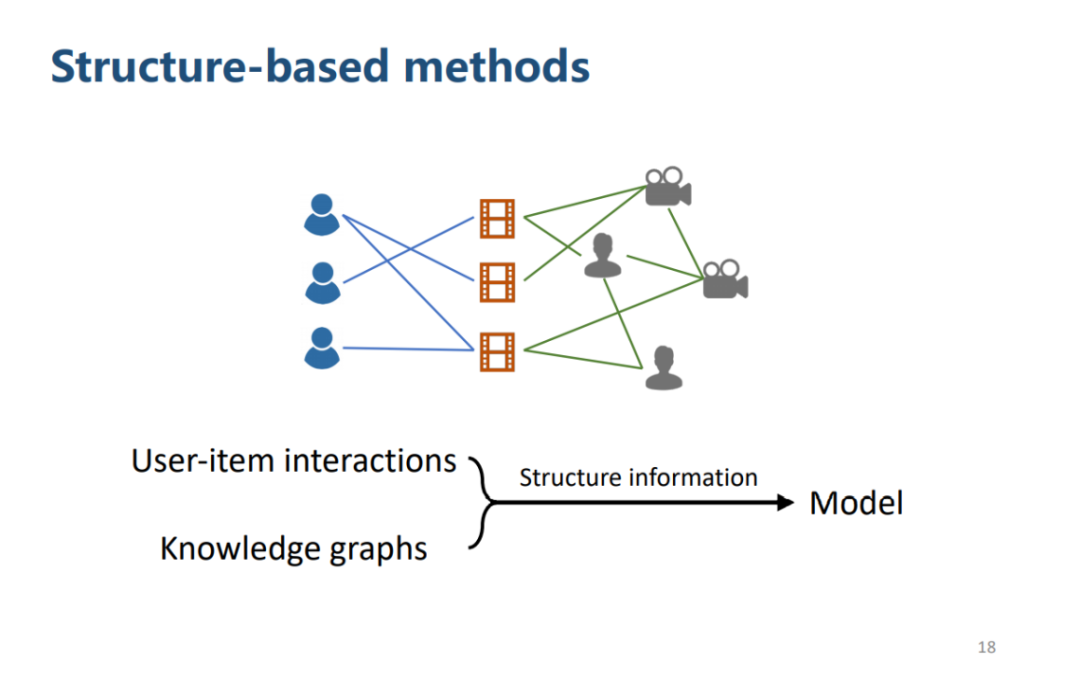
基于结构方法(Structure-based methods)
将 KG 和用户物品交互的图结构概括在一个统一的框架下,挖掘图结构信息。
1. Deep Knowledge-aware Networks
embedding-based 方法(H. Wang, et al. "DKN: Deep knowledge-aware network for news recommendation." WWW 2018.)
① 框架
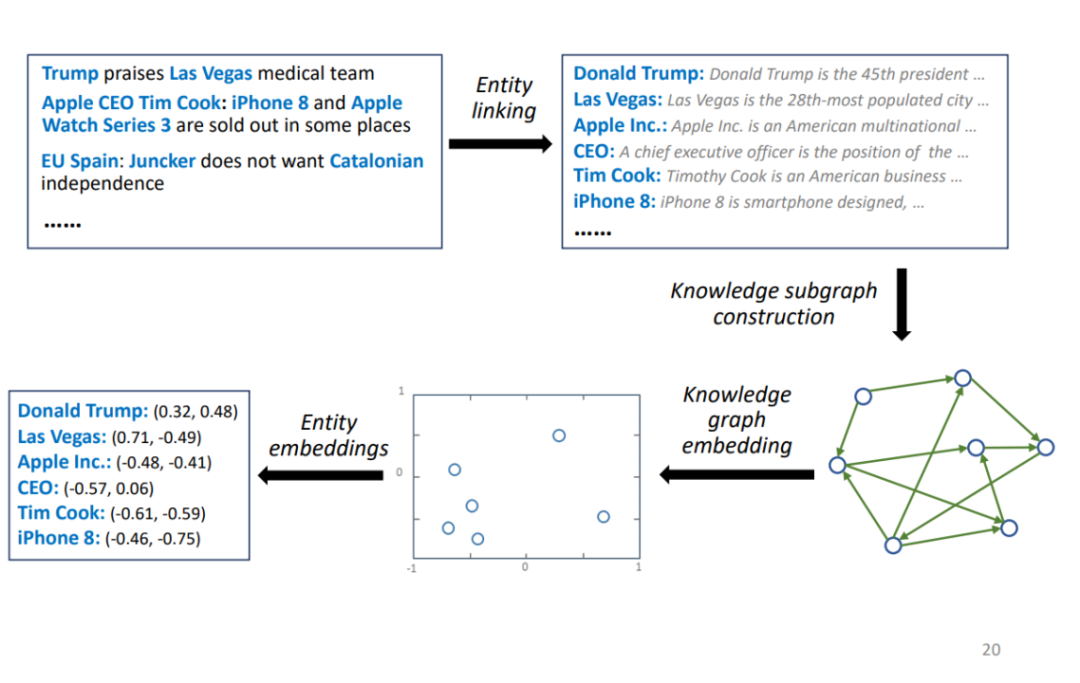
给定新闻数据,使用实体链接提取出相对应的实体,利用给定实体取出完整知识图谱的子图,用 KGE 的方法处理子图,得到实体 embedding。
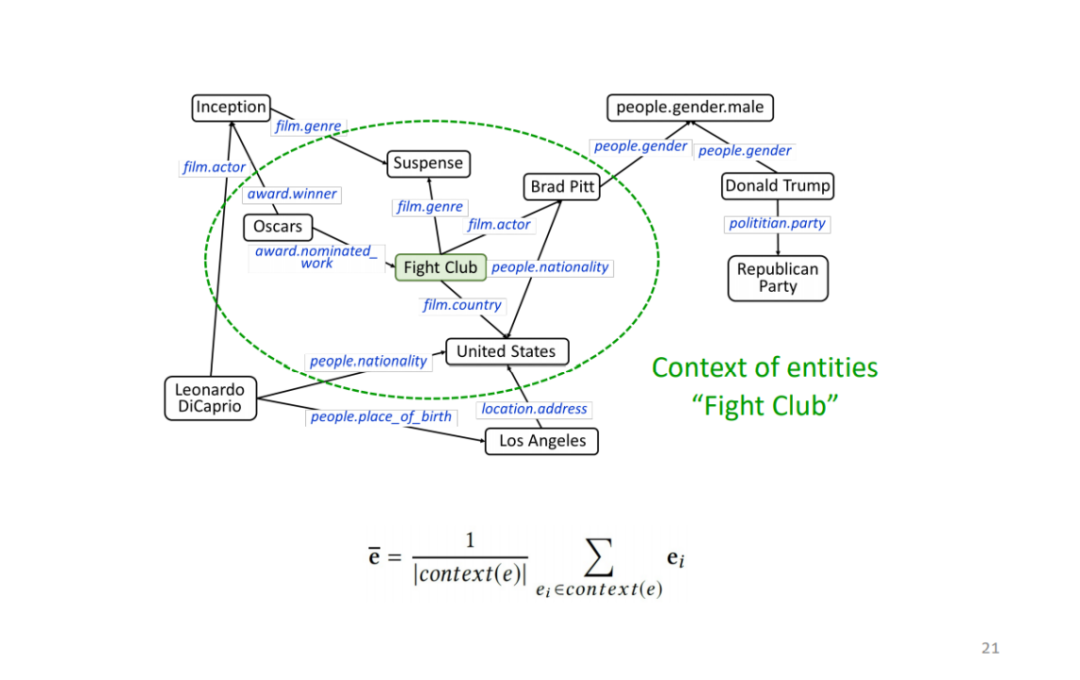
将邻居实体 embedding 平均得到该实体的 embedding 表示。
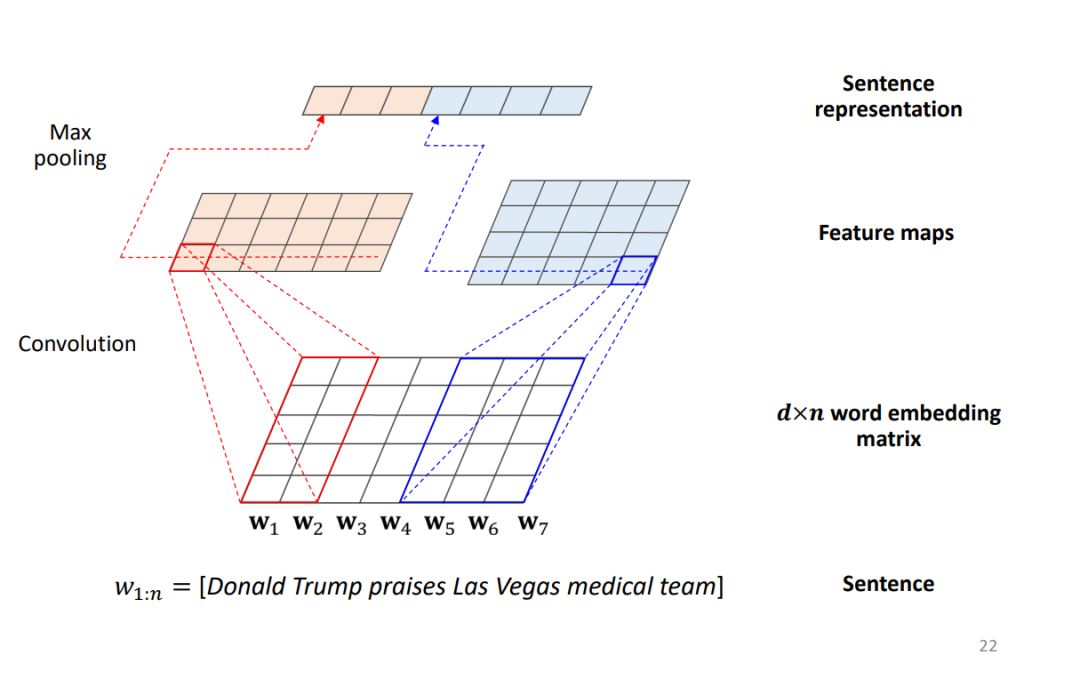
Knowledge-Aware CNN
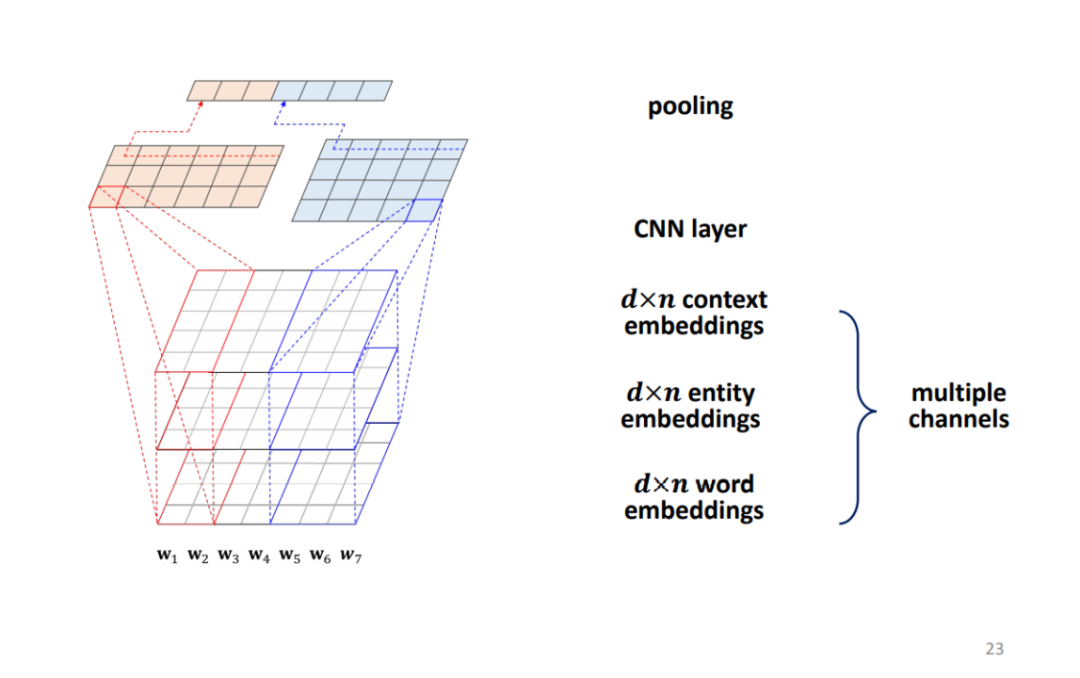
Kim CNN 用来学习句子的 embedding。给定句子中有 n 个词语,词嵌入维度为 d,使用 3 个长度为 d 宽度为 2 的 1 维卷积核处理词嵌入矩阵,再用 4 个宽度为 3 长度为 d 的一维卷积核处理词嵌入矩阵,对最后一维进行 max-pooling,将池化结果 concat 后得到的向量作为 sentence embedding。
Knowledge-Aware CNN(KCNN)是对 Kim CNN 的扩展,输入为三个 embedding,包括 word embedding、entity embedding 和 context embedding。如果 word embedding 中单词对应一个实体 entity embedding 中对应位置为学到的实体 embedding,如果不对应实体则用 0 来填充。此时的卷积核高度变为 3。
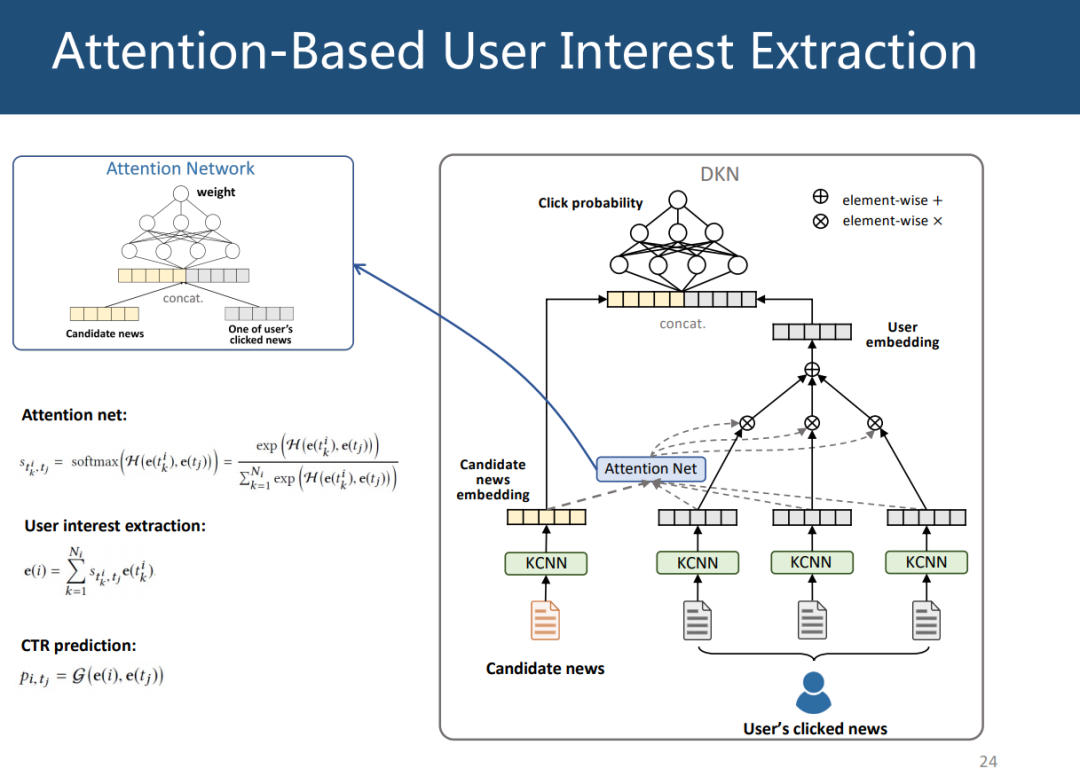
Attention-Based User Interest Extraction
给定用户历史新闻数据和候选新闻,判断用户是否对候选新闻感兴趣。先使用 KCNN 的方法学习新闻 embedding,并用 attention net 来判断以前读过的新闻对候选新闻的重要程度,attention network 通过将向量拼接并经过 dnn 来计算最后的权重,利用 attention net 的权重加权用户历史数据可以得到用户的 embedding,最后将用户 embedding 和候选新闻 embedding 拼接并通过 dnn 得到点击候选新闻的概率。
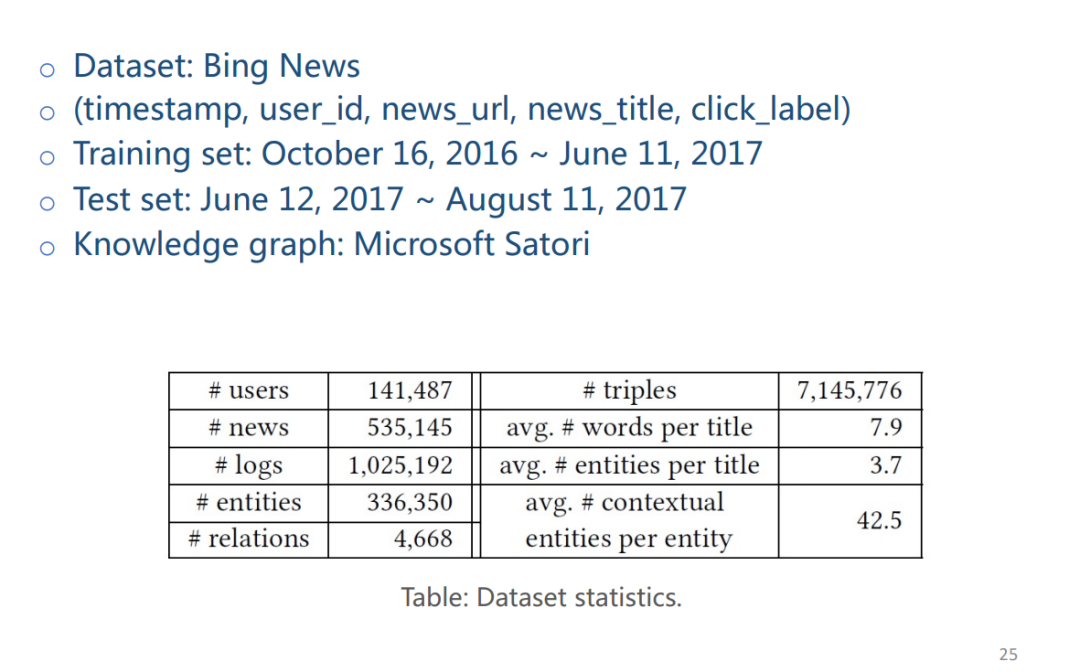
② 实验
使用 Bing News 作为数据集,KG 使用微软 Satori。Bing News 数据集中标题平均词数量为 7.9 个,平均实体数量为 3.7 个。
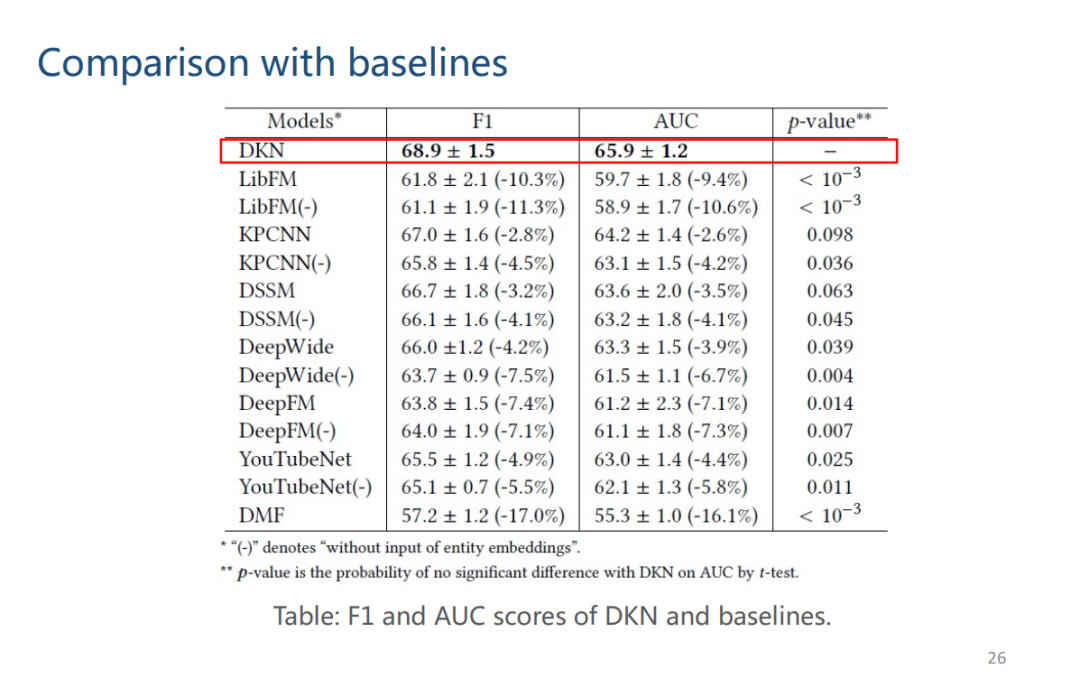
实验结果如下图,(-)代表没有使用 KG 的方法,可以看到 DKN 方法显著地好于其他 baseline 的方法。
2. Multi-Task Feature Learning for KG-Enhanced RS
embedding-based 方法(H. Wang, et al. "Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation. " WWW 2019)
① 框架
多任务学习框架,下图左为推荐系统的框架,下图右为 KGE 的框架。
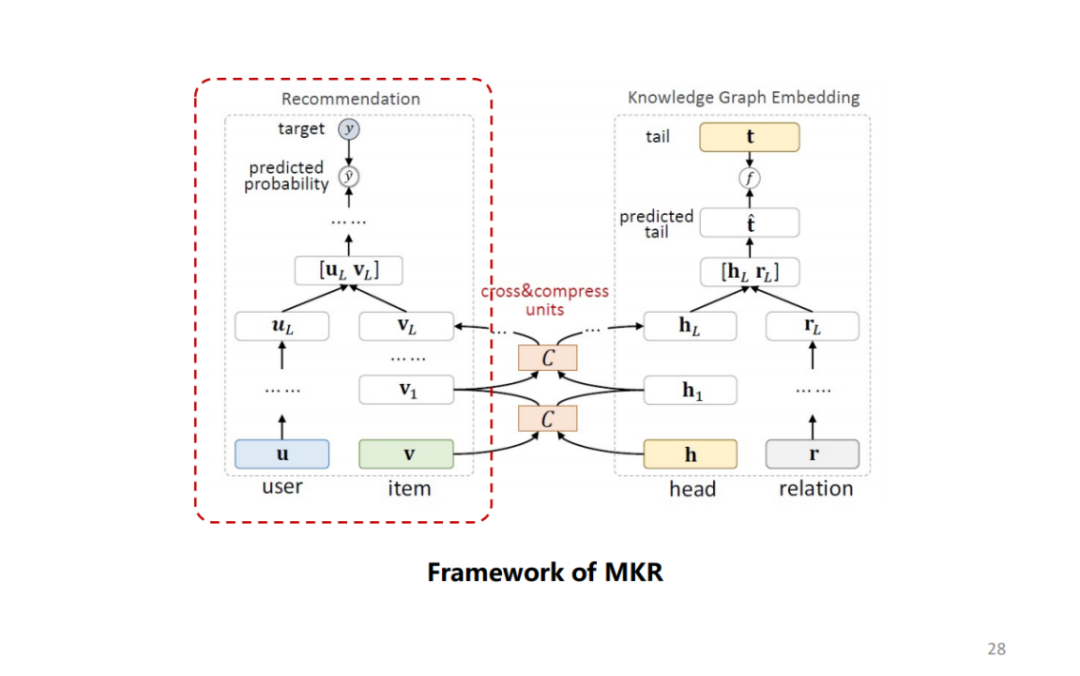
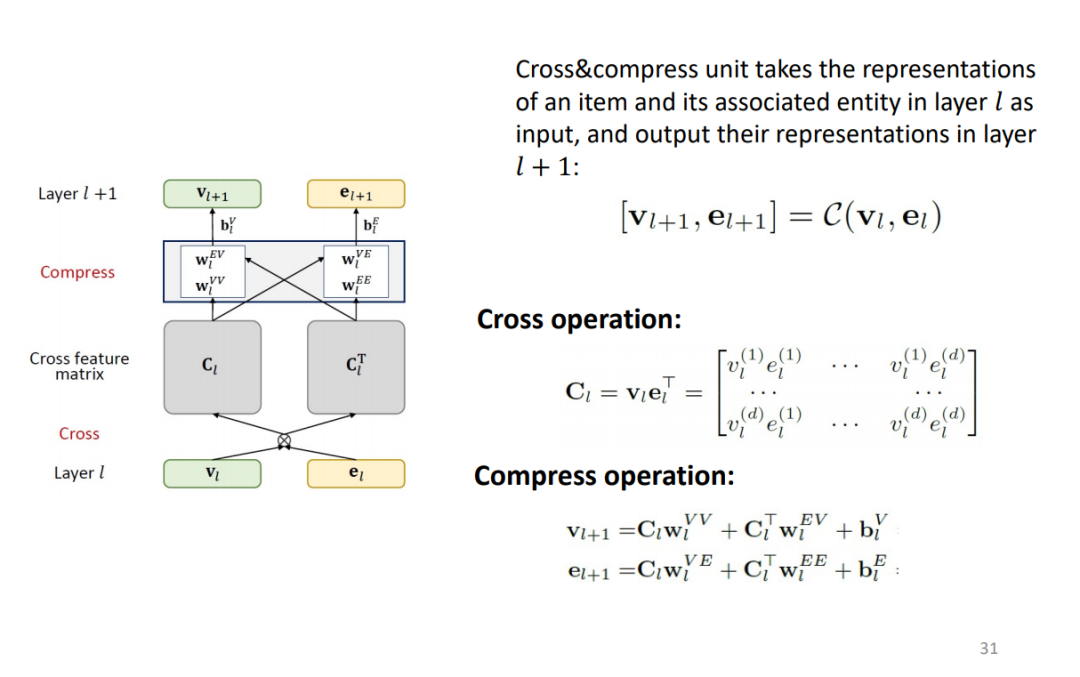
由于知识图谱中的实体就是推荐系统中的 item,可以认为它们的 embedding 存在特定的关系,因此使用 cross&compress units 来建模实体和物品 embedding 之间的关联。其中 cross 操作将计算向量内积得到矩阵,compress 操作通过将矩阵压缩为向量。
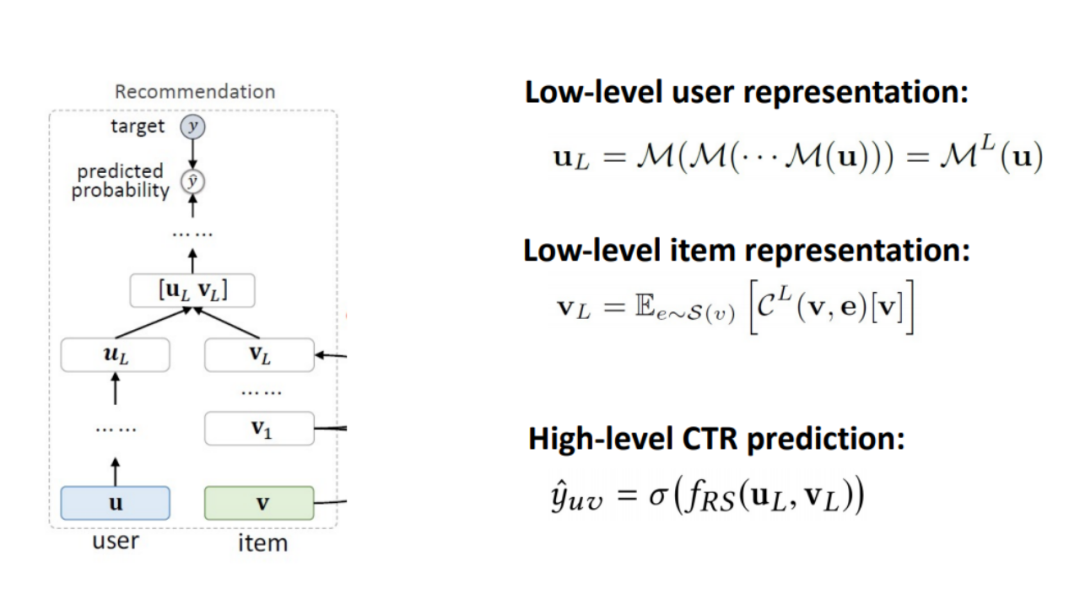
推荐系统用 MLP 处理用户 embedding,并使用 cross & compress 计算物品的 embedding,最后拼接来计算点击概率。
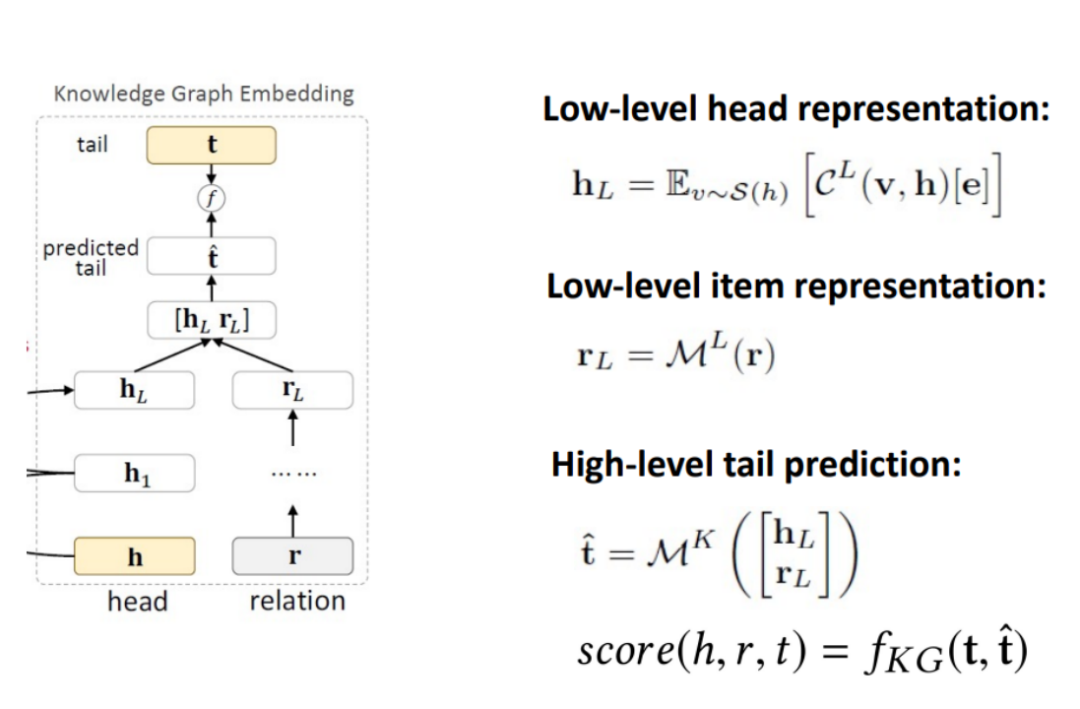
KGE 模块中,使用 cross & compress 处理 head 实体 embedding,使用 MLP 处理关系 embedding,拼接后通过 MLP 计算 tail 实体的预测值,并以 embedding 预测值和真实值之间的差距作为损失函数。
因此,整体的损失函数分为三块:推荐系统的损失、KGE 的损失和正则损失。

② 实验
分别在四个数据集上进行了实验,实验结果好于其他方法。
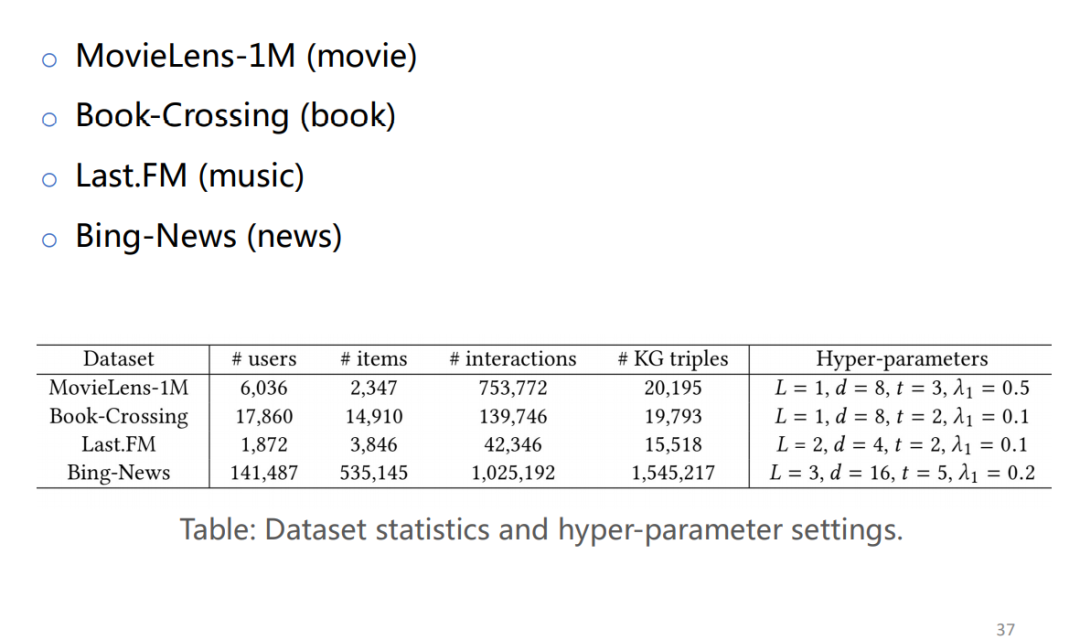
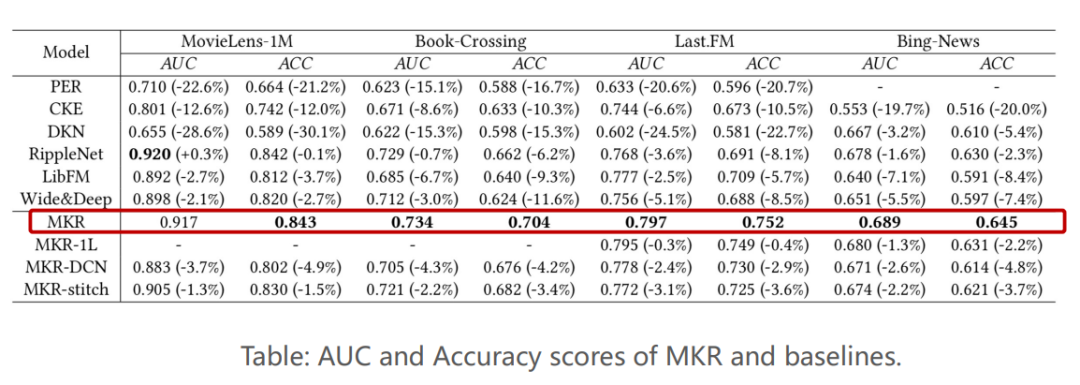
3. RippleNet: Propagating User Preference in KGs
Structure-based 方法,以跳数来表示用户的兴趣传播,类似于水滴的传播过程,因此称为 RippleNet。(H. Wang, et al. "RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems.” CIKM 2018.)
① 框架
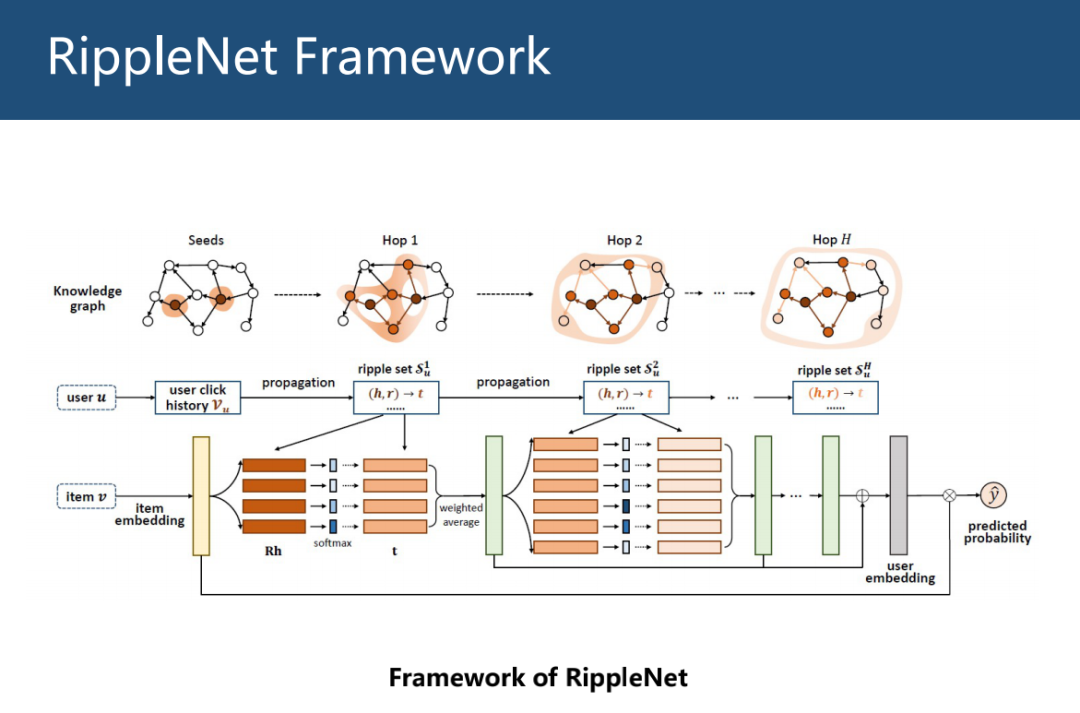
输入为用户和物品,输出为用户点击物品的概率。利用用户的历史点击数据 vu,将 vu沿着 KG 向外传播,得到历史点的邻节点 t 和关系 r,并利用下式计算邻节点 t 与候选物品 v 的关联概率。
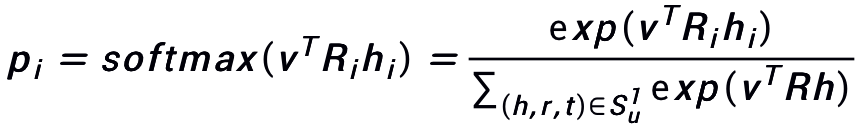
利用关联概率加权平均得到用户的一阶表示,不断重复传播过程,得到多个用户 embedding,将其相加作为最终用户 embedding,最后使用用户 embedding 和 item embedding 内积的 sigmoid 激活结果作为最终的点击概率。
在给定 KG 和用户物品历史数据时,基于最大化后验概率来计算模型参数,利用贝叶斯方法将概率公式拆为三项。
第一项为模型参数的先验分布,采用高斯分布作为先验。

第二项为给定模型参数判断观测知识图谱的可能性函数,即通过头实体、尾实体、关系 embedding 的乘积来模拟出现的概率,如下图公式。

第三项为给定 KG 和模型参数判断用户历史行为的物品点击概率函数,为伯努利分布,如下图公式。
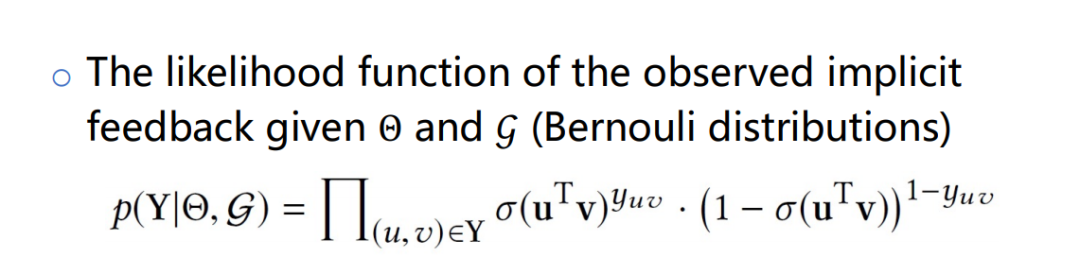
将概率公式取负对数后得到最终损失函数。
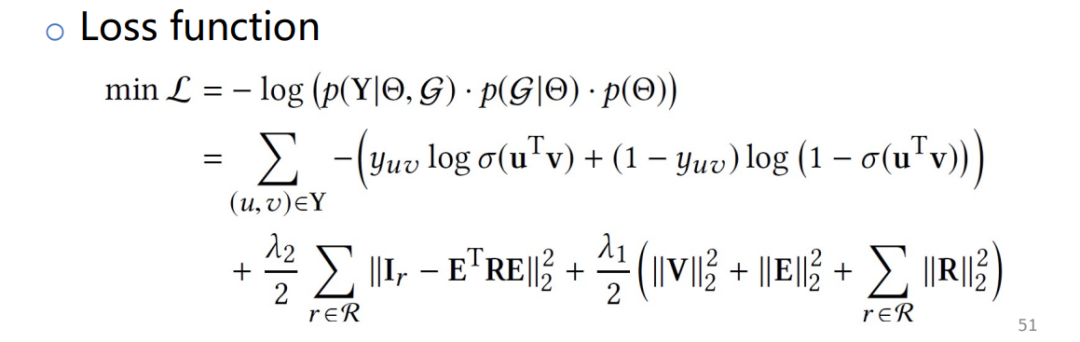
② 实验
实验结果好于其他方法。
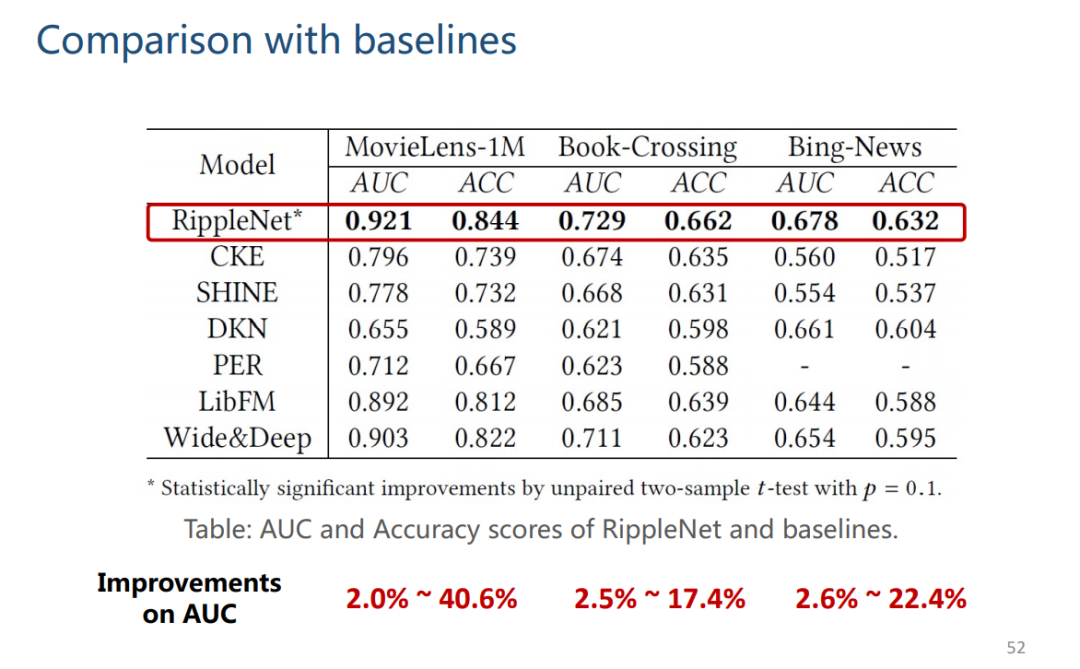
4. Knowledge Graph Convolutional Networks
Structure-Based Methods (H. Wang, et al. Knowledge Graph Convolutional Networks for Recommender Systems. WWW 2019.
H. Wang, et al. Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems. KDD 2019)
① 方法
KG 中的边不存在权值,因此引入,通过用户 embedding 和关系 embedding 的内积,将权值引入 KG。
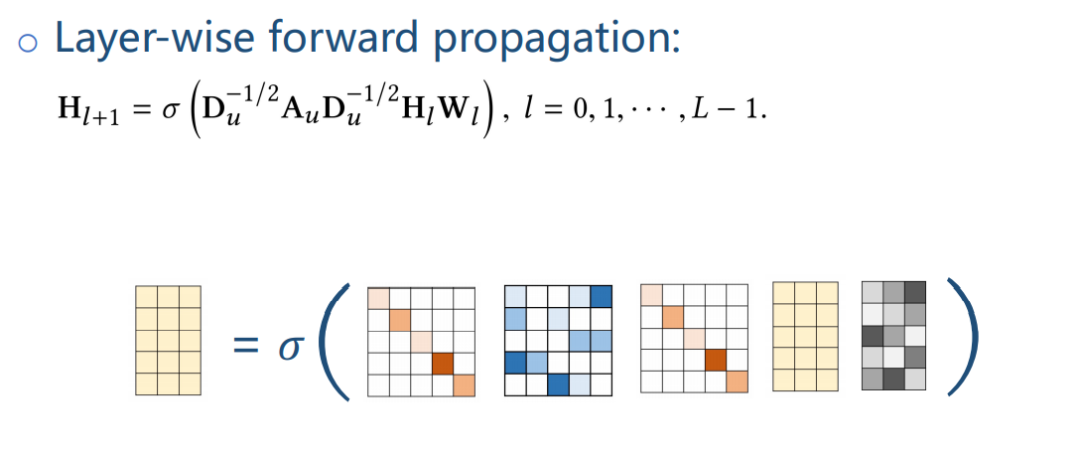
逐层传播的函数如下图,其中 Au为每个用户 u 的 KG 邻接矩阵,Du为 Au的对角矩阵,Hl为第 l 层实体 embedding,Wl为参数矩阵。
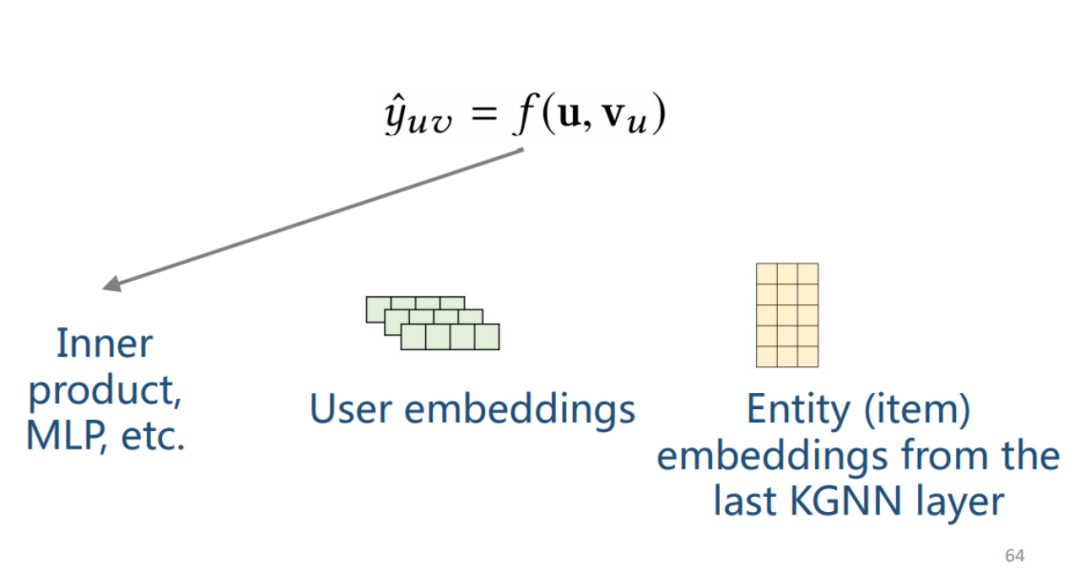
最终点击概率如下图公式计算。
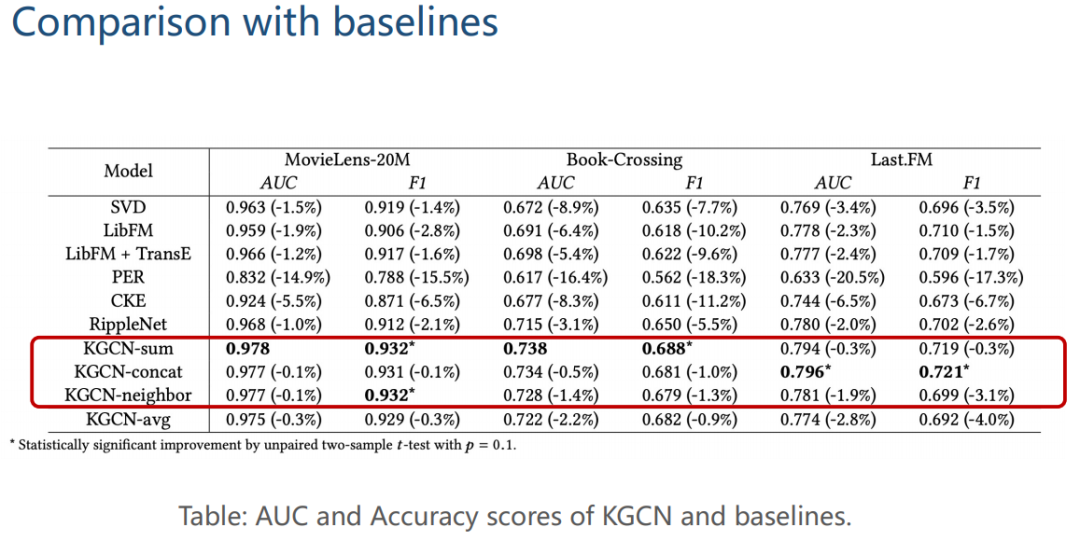
② 实验
实验结果如下图,一般使用 KGCN-sum 的方法效果最好。
5. 比较
在性能方面,KGCN 性能最好,DKN 表现最差。
在可扩展性方面,embedding-based 方法可扩展性更好,因为 embedding 方法可以复用,而 structure-based 方法在面对新的物品、用户时需要对整个方法需要重新训练。
在可解释性方面,我们认为 structure-based 方法的图结构比 embedding 更直观。

总结
知识图谱可以作为解决数据稀疏性和冷启动问题的一种新的推荐系统辅助信息,引入知识图谱辅助推荐系统,可以提高推荐系统的准确性、多样性和可解释性。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:如何将知识图谱引入推荐系统?




