
随着大模型技术从技术变革转向产业变革,大模型应用也会进一步繁荣,传统基础设施技术已经不足以满足大模型应用的快速发展。整个基础设施技术和产业链正在快速转型,向大模型基础设施技术演变。2025 QCon 全球软件开发大会(北京站)策划了「面向 AI 的研发基础设施」专题,通过本专题的深入探讨,希望让听众了解并掌握大模型基础设施技术的发展趋势和前沿动态,从企业工程实践和学术研究领域借鉴成功经验,为自身企业制定更大规模、更高性能以及更加稳定的大模型基础设施技术。4 月 10-12 日 QCon 北京见。
当前,多模态模型是 AI 领域研究的最热门方向之一。多模态大语言模型从大规模预训练中获得图文理解、创作、知识、推理、指令遵循等能力,通过可监督微调激发对应的能力。此外,模型输出还要具备特定的风格、符合人类偏好、对齐人类价值观,因此需要引入基于人类的反馈信号的强化学习(RLHF)方法来进一步优化模型效果。
PPO(Proximal Policy Optimization)算法是 OpenAI 在 RLHF 阶段采用的算法。PPO 算法中涉及到多个模型的协同训练和推理,设计和实现一套高效、准确的 RLHF 训练系统是多模态模型研究领域的关键挑战之一。
在 2024 年的 QCon 上海站上,小红书资深技术专家、RLHF 自研框架负责人于子淇发表了题为《基于 PPO 的多模态大模型 RLHF 系统的设计与优化》的演讲。本次演讲主要介绍小红书大模型团队自研 MLLM RLHF 训练框架的实现以及性能优化,分析了小红书团队如何通过训练和推理的混布调度优化等手段实现极致的模型性能,希望能给大家带来一些帮助。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
RLHF 背景
RL 原理
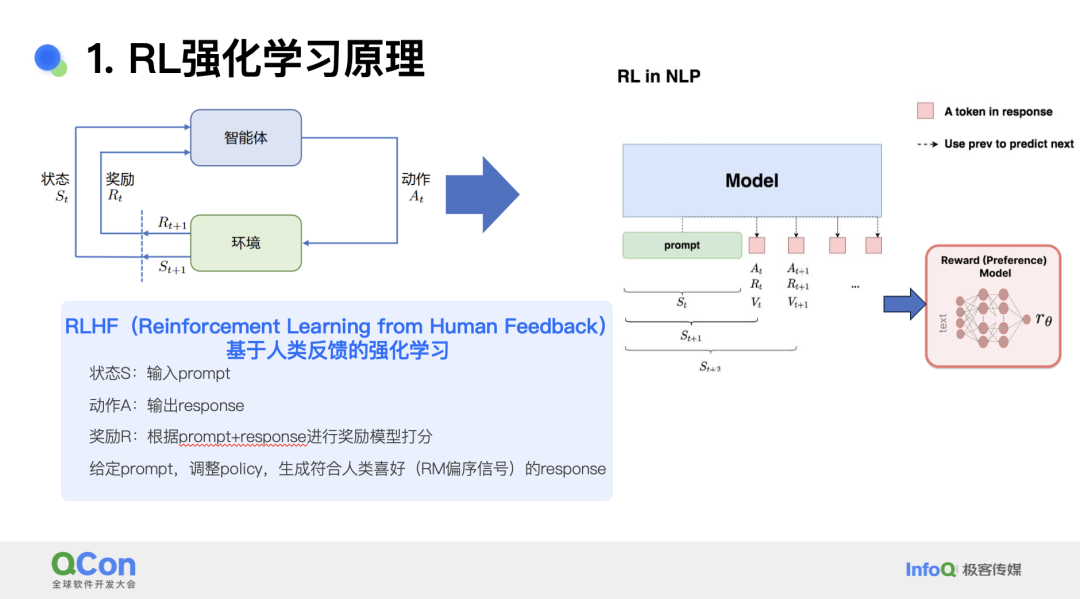
强化学习(RL)的核心过程是:一个智能体在时间 t 处于状态 St,经过动作 A 后其状态变化为 St+1,同时环境会给智能体一个奖励信号 R。当 RL 应用于 NLP 领域时,模型收到提示后开始输出 token,每输出一个 token 就是一个动作,每个 token 后模型会收到一个奖励模型提供的奖励信号对 token 打分,再输出下一个 token,由此逐渐输出符合期望的输出。当奖励模型的打分策略是人类制定时,此过程就称为基于人类反馈信号(HF)的强化学习(RLHF)。
RLHF-PPO 算法
RLHG 的流程主要由奖励模型 RM 和强化学习 RL 过程组成。第一步,通过 SFT 监督训练过程初始化 RM 和 RL 模型。接下来分别训练 RM 和 RL 模型。

RM 模型的数据构造是对 LLM 模型输入同一个提示采样多个不同输出,生成多个 pair 对。之后人类专家会对这些 pair 对进行质量排序,生成数据集,然后提供给模型进行 pair-loss 偏好训练。之后 RM 模型就可以对输入的 pair 对进行打分了。
RL 模型训练有多种方法,其中有代表性的是 PPO 策略梯度算法,这是一种 On-Policy 算法,需要在线生成不同的样本实时更新。OpenAI 作为行业先驱,验证了 PPO 算法在 RLHF 领域的有效性,因此行业进行 RLHF 研究时多采用 PPO。
PPO 算法包含四个模型。首先是演员模型(Actor Model),是训练的目标语言模型。第二是评论家模型(Critic Model),负责预估模型当前行为的总收益。第三是奖励模型(Reward Model),计算当前动作的实时收益。第四是参考模型(Reference Model),是演员模型在 Step 0 阶段的参数状态,它会不断与状态更新的演员模型对比计算 diff,从而约束模型输出,防止输出偏移,遗忘上游任务。
PPO 训练流程
PPO 的训练流程可以简单概括为训推混布,整体可以抽象为两大步骤,第一步是经验采样(rollout),是指演员模型对当前提示作出一次响应(generate 阶段),然后根据提示 - 响应计算奖励分数,从而构造奖励的训练数据集(forward 阶段)。第二步就是训练,也就是对演员和评论家模型进行 PPO 训练迭代。
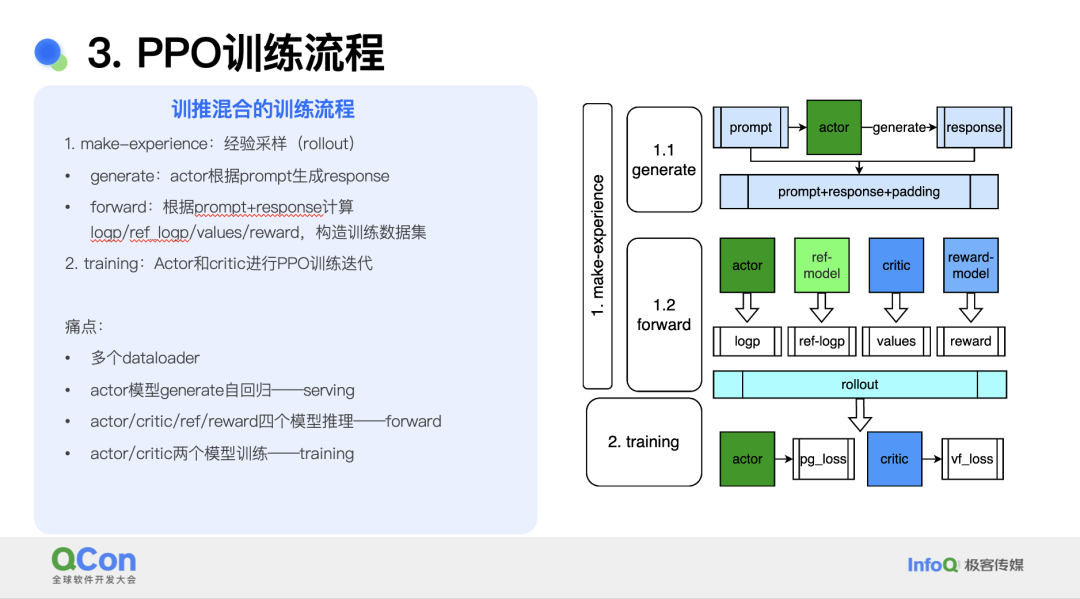
上述流程存在一些痛点,首先是流程需要多个 dataloader;其次,演员模型包含了生成自回归部分,因此需要 serving 部分;第三,该流程包含了四个模型的推理过程,复杂度较高;最后,该流程需要训练演员和评论家两个模型,工作量加大。
基于上述背景,小红书团队设计了一个 RLHF 框架。
RLHF 框架设计
整体框架
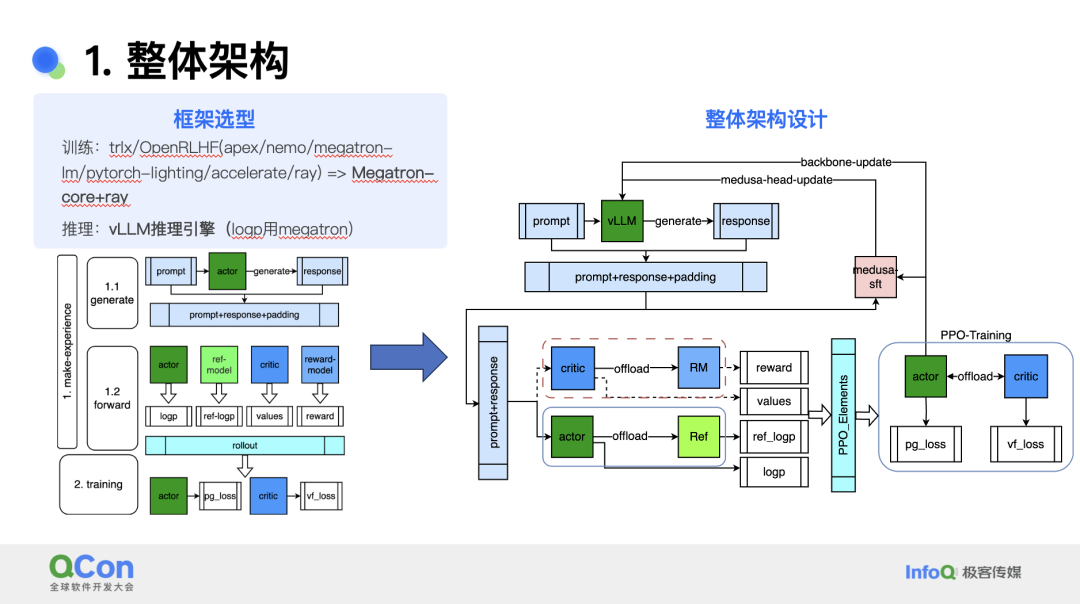
小红书团队设计的整体架构汲取了开源领域的经验,抽象出了只用 Megatron-core 做训练,并用 ray 做调度的经典方式来降低复杂度。推理方面则采用 vLLM 推理引擎来加速。因为训练和推理存在 diff,如果将 diff 引入训练过程,就会给 PPO 过程带来 bias,为了避免 bias 需要使用 megatron 计算 logp 概率。
整体架构来看,首先模型会通过提示生成响应,之后输入四个模型进行前向推理,生成结果经过后处理后生成奖励数据集,再提供给演员和评论家模型进行训练。训练过程是 on-policy 的,需要实时采样当前样本。
异构组网架构
上述框架的前向推理阶段有四个模型,如果采用并行方法会带来四倍的 GPU 内存占用。因此团队采用了 offloading 的方法,将结构相同的评论家与奖励模型,演员与参考模型分为两组复用,从而将推理模型数量减少到两个,降低了内存占用。
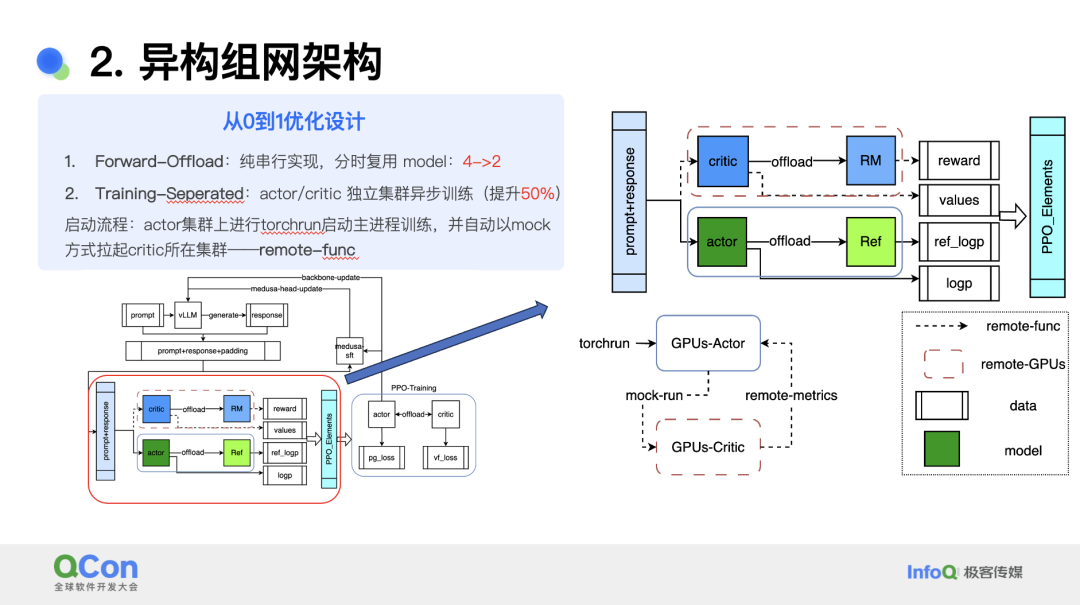
另一方面,团队还将演员和评论家模型的训练过程放在了独立的集群上进行异步训练,从而提升了 50% 的性能。异步训练启动时,演员集群上进行 torchrun 启动主进程训练,并自动以 mock 方式拉起评论家集群。这两个集群构成 master-worker 架构,集群之间的数据传输会带来一定开销。
同构组网架构
上述异构组网架构投入使用后,小红书团队发现,在数据量、模型参数量等压力增大后,集群压力会大幅上升。以 Llama 3 70B 为例,SFT 单个模型本身的训练就需要 4 机 32 卡,32k 长上下文时需要开启 CP2 并行,此时就需要 8 机 64 卡,推理过程需要 128 卡。另一方面,两个训练集群需要同步缓存,随着序列长度增加等因素,同步耗时也会显著增长。
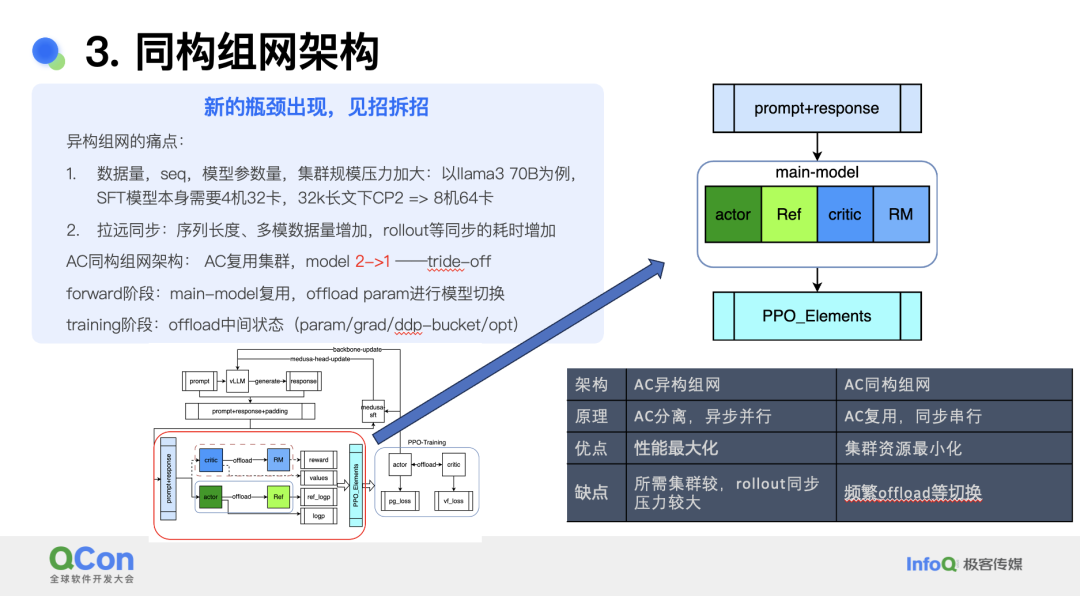
为解决以上问题,团队设计了一个同构组网架构。新的架构中,由于评论家与演员模型还能继续 offload,因此可以将四个模型进一步减少到一个主模型来复用,通过 offload 切换模型,降低推理成本。训练阶段则 offload 了很多中间状态,尽可能减少资源占用。新的架构可以充分利用资源,提供较高的性能。
训推一体优化
训练性能优化
在训练性能优化方面,小红书团队引入了一些常规优化方法,包括数据加载的预读取、双 dataloader;一些常见的并行优化策略,如 TP、PP、CP、SP;常见的长文本场景下的显存优化(recompute 技术);Dynamic-batch,训练和推理使用不同 batchsize;负载均衡方面,提示请求会通过 round-robin 方式发送到多个 vLLM 引擎;vLLM 推理引擎会做不同粒度的切分,虽然降低了单粒度的 running-batch,但能提升并发性。
流水线优化
流水线优化方面,团队发现演员模型采样阶段是无需训练的,存在较大空窗。针对这一问题的解决思路是训推混布。由于训练任务中的简单任务耗时占比超过 80%,且训练任务负载远高于推理,因此可以通过增大 serving 并发来降低训练集群负载。另一方面,生成和前向推理阶段可以进行流水线并行。基于上述思路改进了整体 RL 架构,实现了全量 offload 和流水线并行。
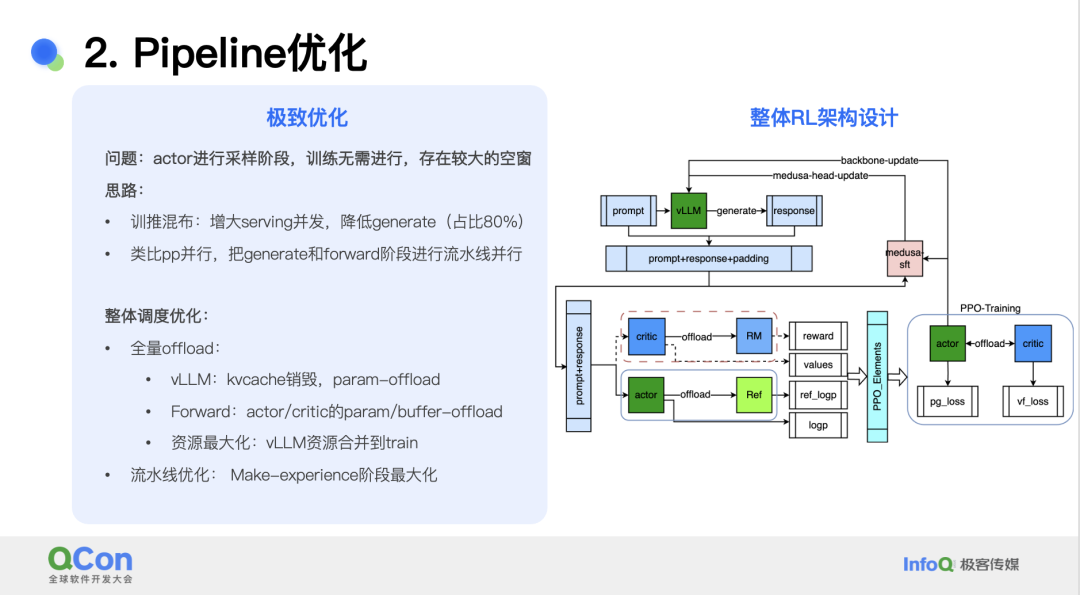
新的架构将整体 reward-batch 切分为多个 mini batch,从而 overlap 屏蔽了数据落盘、vllm-restart/offload、forward、数据预处理等上下文开销。与之前的版本相比,流水线新架构的训练耗时从 2250s 减少到了 690s。
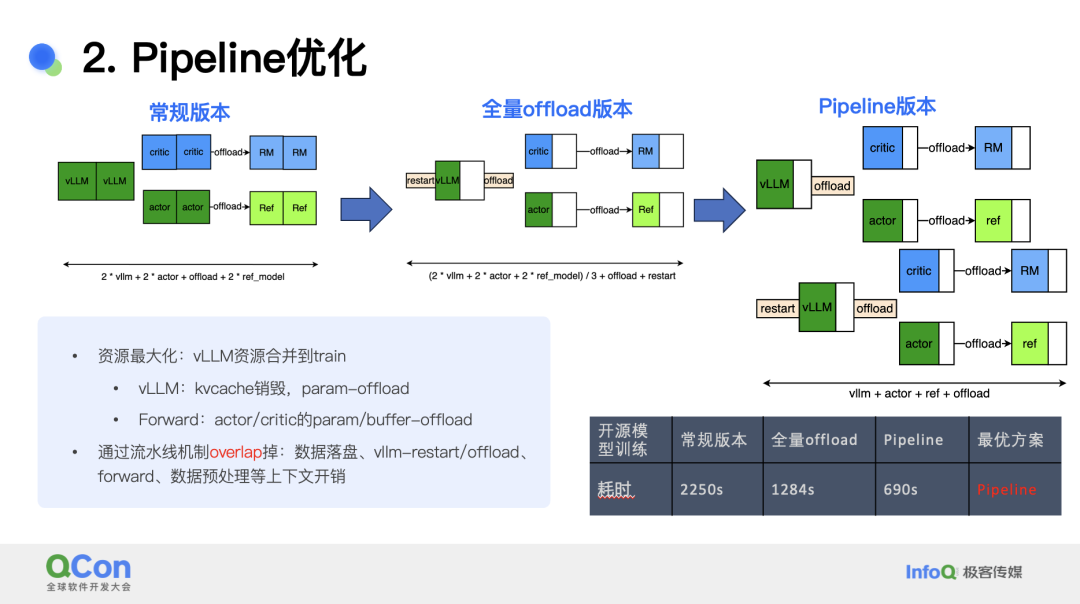
r1/o1 系列 reasoner 推理模型场景下 decode 长度会大幅增加,比如 128k response 生成会成为瓶颈,此时全量 offload 更适合这种训推不均衡的场景。
PPO 细节处理
进行性能优化时,PPO 部分有一些细节可以进一步挖掘。首先是 Padding-free,这里通过 start-end 的 offset 去除了训练阶段的 padding,减少了 10% 的耗时并降低了内存占用。
第二个细节是参数同步。演员模型需要把参数同步给推理引擎,这里使用新的通信组件降低了通信耗时。
第三个细节是 CP 并行,这是 LLM 在长文本场景中必须开启的特性。这里需要进行 logp、values、reward 的 CP 重排。对各个重排过程优化后也可以进一步降低通信开销。
最后是 Logp 实现:在 actor_loss 计算阶段对 logits 提前重排,计算 CP 的结果之后进行 allgather,得到 total 的结果,再 -1 得到 logp,从而降低通信量(bxsxh -> bx)。
多模 MLLM 优化
MLLM 多模态模型的性能优化存在一些痛点,主要是引入了图像处理、图文混合场景,从而导致训练负载不均衡。不过多模态模型的视觉处理部分计算量虽然巨大,但参数量较小,在 PPO 场景下图像处理能力是存在冗余的。
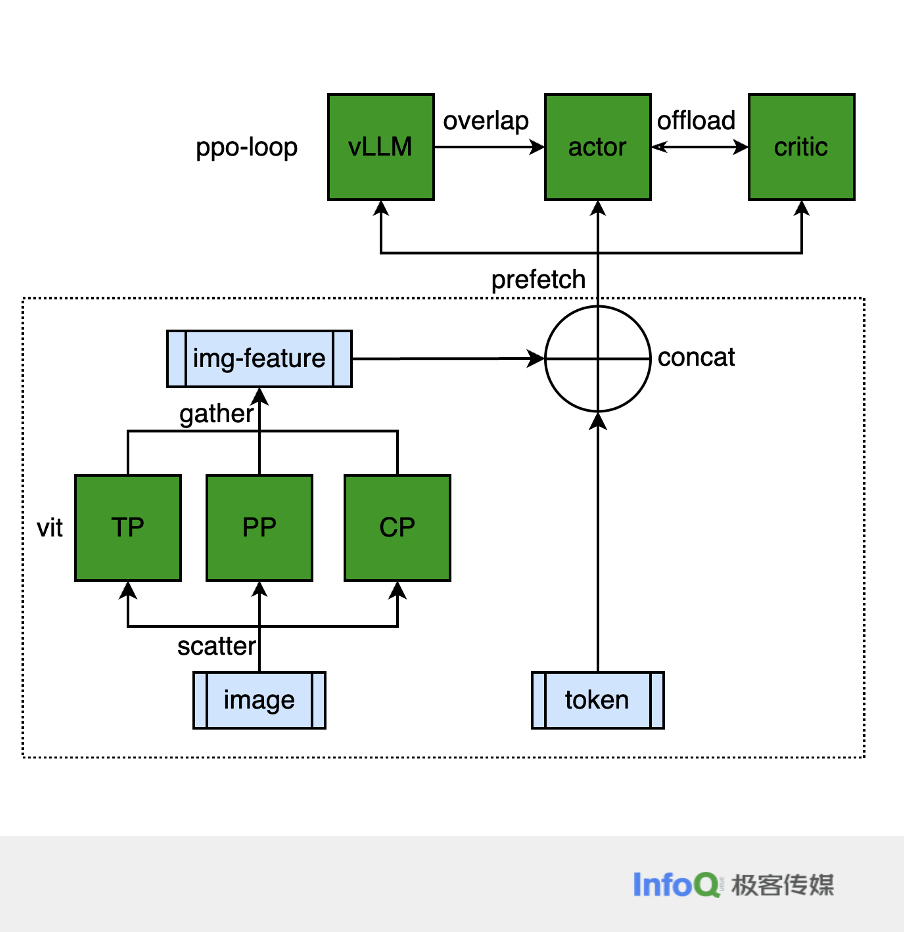
基于上述特点引入三个优化方法。首先是组网优化,在语言处理场景采用 TP、PP、CP 等并行优化,而视觉部分可以复用这些切分优化。其次是多路复用,这里对 vLLM、演员和评论家模型全部复用相同的 img_feature。第三是预读取优化,这里会冻结 visual-model,将 img_feature 的全部计算流程放入 make-experience 阶段内部,通过流水线方式 overlap 多模计算需求。通过上述优化,MLLM 可以实现与 LLM 相当的性能表现。
训推一致性
进入业务部署阶段,小红书团队在训推一致性层面发现了一些痛点。首先是 RM-serving 过程中存在 acc 掉点,其次是推理和评估时的精度与训练时并不完全一致。分析后发现,rm 的 vhead 是一个 linear,本质上是一个矩阵乘,会累积放大误差,初始误差 diff 只有 0.001,累积后可达 0.3。

针对这一问题的解决方案是针对 RM+RL 复用相同的网络结构和训练框架(megatron-core),同时针对 RL 场景下的 RM-serving 转变为本地 offload 实现,从而保证精度完全一致。最后,训练和推理采用 mcore 的计算负载,保证评测任务上训推 tokenwise 一致。
Medusa 提升采样效率
即便有了前述优化过程,演员模型部分的生成耗时依旧相对较高。对此一般使用推理量化方式进行加速,但传统量化方式有一定精度损失,无法做到 PPO 训练所需的无损优化。
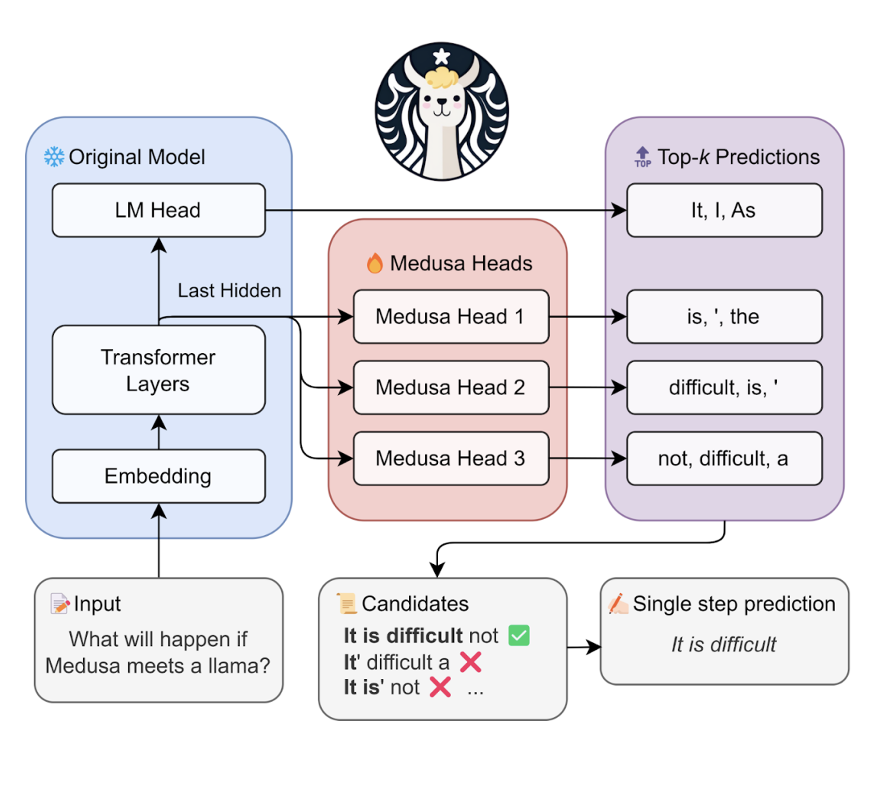
团队发现投机采样是一种无损优化方式,因此使用了 Medusa 算法来做优化。投机采样是一种计算换空间的方式,利用 FLOPS 换取 VRAM 带宽。这里在 LLM Transformer 级别的最后一层添加一个 Medusa head,其结构与 LLM 同构。训练时为了确保精度需要冻结 LLM 主干。这里的 Running-batch 提升到最大,从而实现最大吞吐量。
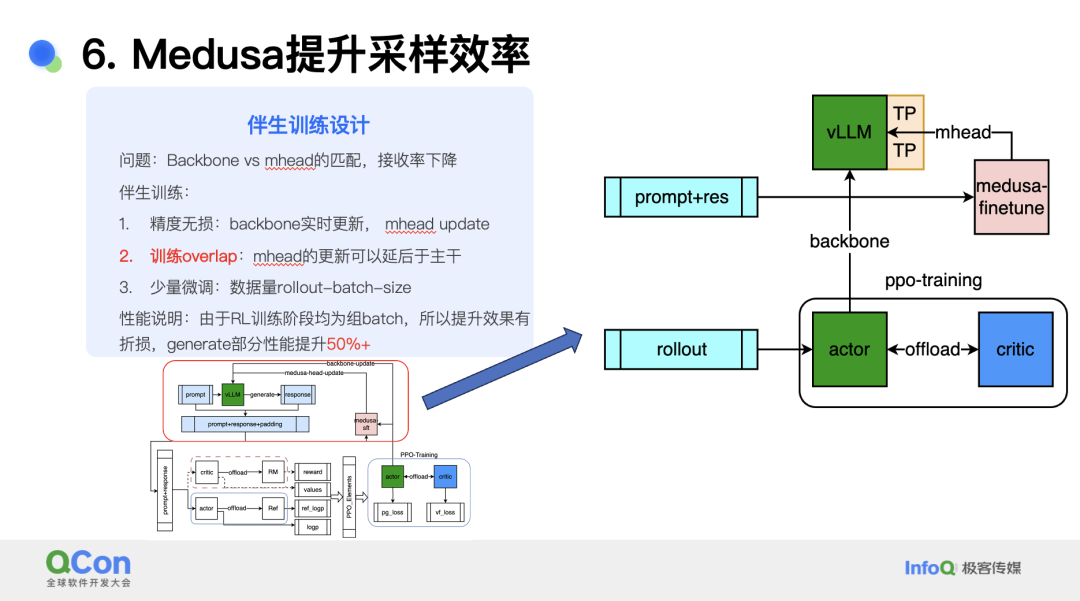
另一个问题是 backbone 与 mhead 的匹配度不足导致接收率下降,降低加速比。这里引入了伴生训练的方式来解决问题。伴生训练要求精度无损,所以 backbone 要实时更新,mhead 更新则可以延后(因为不影响精度),从而可以实现训练 overlap。此外,训练时 mhead 可以少量微调,其数据量只需要 rollout-batchsize 即可。通过这些方式,生成速度得到了 50% 提升(注意:投机采样会引入 verify 的额外计算量,适合推理并发过大时导致 batchsize_per_engine 过小没有充分利用计算资源的场景)。
实践案例与展望
通用能力提升
在一个基于开源模型的案例中,使用新的 RLHF 框架后,模型可以正确遵循原本无法正确识别的提示。例如提示询问“午餐吃什么”,原本的模型回答给出了早餐的选项,改进后可以正确回答午餐的选项。
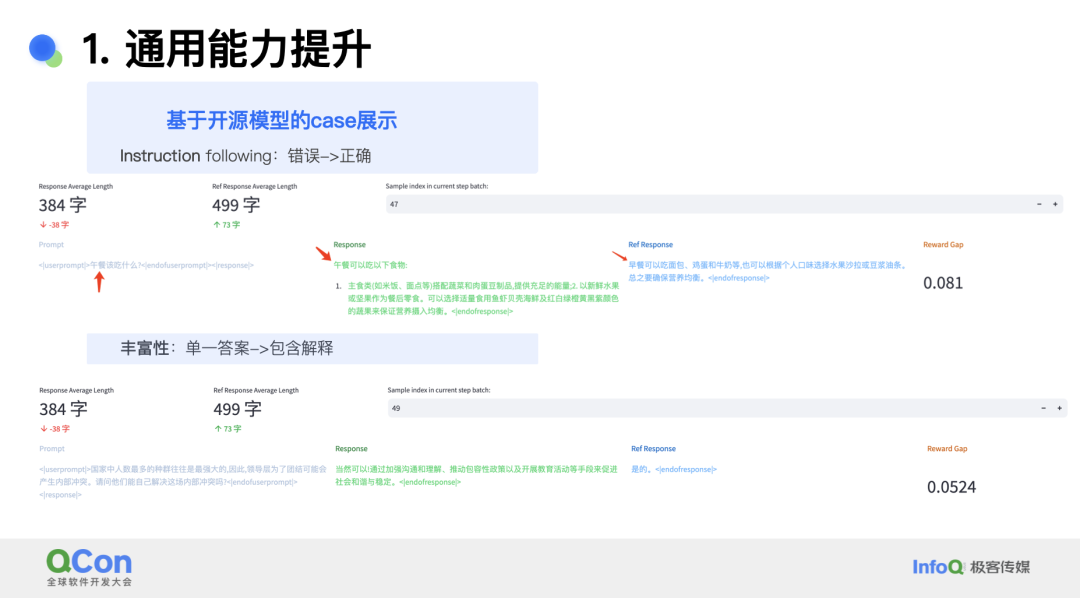
另一个案例则显示出了模型答案内容丰富性的改进,针对提示问题,原始的模型答案只有简单的是 / 否结果,新的答案则给出了详细的解释。
进一步的评测显示,该 RLHF 框架对开源模型进行改进后,模型的推理、创作、问答、数学、对话和代码能力分别提升了 15%、7%、7%、11%、4%、3%,综合提升 6%。
PRM 效果提升

该 RLHF 框架还可以提示模型的 PRM 效果。PRM 是指过程奖励,PRM 效果提升后,模型回答问题时的可解释性会更好。更进一步的评估显示,PRM 可以改善模型的激励粒度,带来 5% 的模型能力上限提升。

调参经验
在 PPO 调参方面,团队也积累了一些经验:
可视化逐样本 /token 进行细粒度分析;
Advantage-batch 对于小 DP 场景较为有效,可以防止走偏;
评论家模型从 RM 加载参数,复用训练集群的计算分数,避免精度下降;
LR 基于 sft 设置,演员 < 评论家模型,让后者走得更快,避免发散;
评论家模型先学习,演员模型先冻结,实现更准确的学习;
reward hacking 奖励攻击:奖励后期的收敛性与评测结果有差异,需要找到 reward hacking point,开始加强奖励模型的迭代。
未来规划
团队未来计划进行更深层次的探索。首先是性能优化,团队自主研发了 MARIX 项目,该项目是全流程训推一体框架,未来将进一步压缩生成耗时、不同序列的负载均衡,做深度流水线调度优化,等等。其次是算法探索,这方面的目标是去掉 RLHF 的 HF 人工奖励部分,结合 RL-COT 打造更深层的推理能力,实现真正的 RL scaling-law。
演讲嘉宾介绍
于子淇,小红书资深技术专家,RLHF 自研框架负责人,主要从事 RLHF 系统从 0 到 1 的构建以及训推一体性能优化,帮助团队拿到端到端的模型效果收益;曾担任阿里云高级开发工程师,卓越工程师,技术布道师,参与 AIACC( DawnBench 榜单第一)加速库开发,NCCL 通讯库优化等分布式训练的性能优化工作。
会议推荐
在 AI 大模型重塑软件开发的时代,我们如何把握变革?如何突破技术边界?4 月 10-12 日,QCon 全球软件开发大会· 北京站 邀你共赴 3 天沉浸式学习之约,跳出「技术茧房」,探索前沿科技的无限可能。
本次大会将汇聚顶尖技术专家、创新实践者,共同探讨多行业 AI 落地应用,分享一手实践经验,深度参与 DeepSeek 主题圆桌,洞见未来趋势。





