
“很多业务的数据库分配它一个 CPU 都浪费,但是还不能停,我们内部大概有几百个这样的实例,隔离性是很好,但是成本太高了。”例如,OA 系统每天可能只有 3 个请求,但无法确定这 3 个请求什么时候会来,虽然这个系统很重要,却会占用多余资源,造成浪费。
这是某城商行在数据库应用过程中非常大的一个挑战,并且不是个例,很多不同行业的企业都面临着类似的问题。与此同时,除了资源利用率的困境之外,近年来,企业对数据库提出了越来越多的精细化需求,比如如何在不影响业务负载的情况下更快地扩容,再比如优先满足重要业务需求的前提下,如何将剩余资源合理分配给其它业务等等。
“十年前 TiDB 诞生的时候,是希望解决 MySQL 在面对数据量快速增长时所遇到的挑战,而现在的种种经验表明,客户的需求已经远远超越了这一要求,他们的关注点完全不一样了。”PingCAP 联合创始人兼 CTO 黄东旭在日前的媒体沟通会上表示。
回顾十年前 TiDB 架构设计之初,黄东旭表示,当年最正确的决定就是做了分层设计。换言之,其计算引擎、分布式存储、存储介质之间是分层的,针对上述企业提出的一系列痛点时,可以迅速基于云技术满足其需求。
那么,在面对滚滚而来的 AI 浪潮时,TiDB 的底层技术逻辑还是否同样具备这样的前瞻性?下一代数据库内核又有哪些关键的设计要点呢?
“为了未来十年更好地发展,我们必须向前再迈进一步。”黄东旭强调。
AI 业务的本质仍是数据业务
在黄东旭看来,如今很多 AI 业务,其本质仍然是数据业务,虽然大部分的创新故事都聚焦于大模型和人工智能,但最终,在创新真正落地和应用过程中,都需要依靠数据技术来支撑和实现。
最近 AI 数据分析平台 Databricks 的百亿美元融资同样印证了这一点——据了解,Databricks99%的营收仍来自数据业务,Data+AI 的融合趋势超出业界预期。
自 2023 年 ChatGPT 横空出世之后,AI 经历了从“Amazing”到“x Everything”的演变,业界开始不断思考并付诸实践,希望可以利用 AI 能力改造现有应用。那么,下一个阶段是什么样的呢?黄东旭认为,未来 AI 的核心在于 From “AI” to “Your Own AI”,使 AI 能够访问并有效利用人与世界互动所产生的数据。“这里的关键不在于 AI 本身,而在于数据的来源、存储方式和使用策略。”
对此,黄东旭及其团队曾尝试使用高质量行业数据和个人数据,基于开源基础模型进行微调,探索数据增强和开发微调工具链的可能性,最终得出两个结论:第一,微调的方向是不可控的;第二,每一次微调的时间周期非常长,如果效果不佳就需要重新再来,迭代速度慢,且成本非常高。
经过一系列尝试,其证明了当下以及在可预见的未来,能够让大模型真正发挥作用的只有一条路,就是 RAG。“在 RAG 的商业模式中,使用哪个大型语言模型并不重要。我们今天可以用 Llama,明天可以用 OpenAI,后天可以用 Databricks 的模型,这些模型本身并没有本质区别。真正宝贵的是什么?是数据。很快,整个世界将会发现,数据库将成为下一波受 AI 影响最大的一个行业。”
但是,旧瓶装不了新酒,大模型和 RAG 对数据基础设施也提出了新的要求:
一方面是向量索引,黄东旭指出,一个优秀的 RAG 应用需要整合向量搜索、检索、知识图谱等多种技术。2025 年主流的数据库都会支持向量索引类型,单独的向量数据库的市场增长会停滞。
另一方面,它还需要记录与系统的交互记录,包括公司文档、TiDB 产品文档以及结构化数据等,这些元素共同构成了 RAG 应用的核心,使其能够有效地理解和响应用户的查询。一个能够实现一站式服务的,多模态的数据库解决方案会越发流行。
为确保自己在新浪潮下“不掉队”,PingCAP 近日发布了 TiDB 最新的长周期支持——TiDB v8.5 LTS。
意料之中的是,TiDB 8.5 引入了强大的向量搜索功能,适用于 RAG、语义搜索、推荐系统等多种应用场景。并且,TiDB 的向量搜索 SQL 语法与 MySQL 语法风格一致,使得熟悉 MySQL 的开发者也能轻松构建 AI 应用。
事实上,早在 2019 年的 TiDB DevCon 上,黄东旭就曾用下图(图 1)指出未来 5 年 TiDB 不仅要支持图索引,还要支持向量索引和全文索引。“虽然那时还没有大语言模型,但我们已经将向量搜索纳入了产品蓝图中。可以看到,如今我们也正沿着这个方向努力,最终这些功能都将由 TiDB 来提供。”
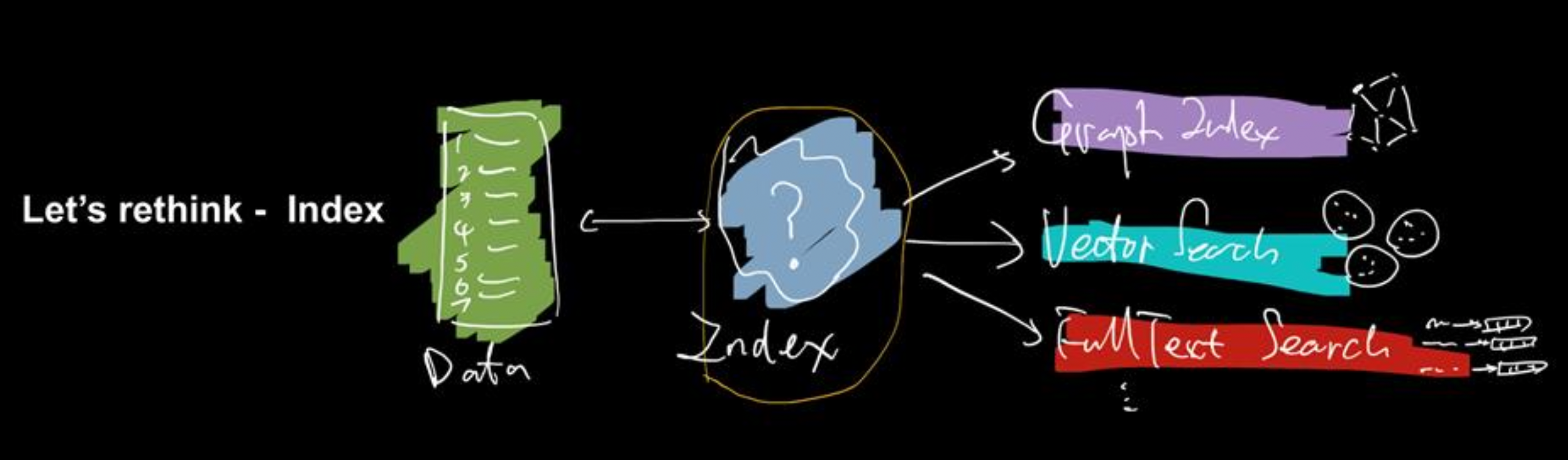
图 1
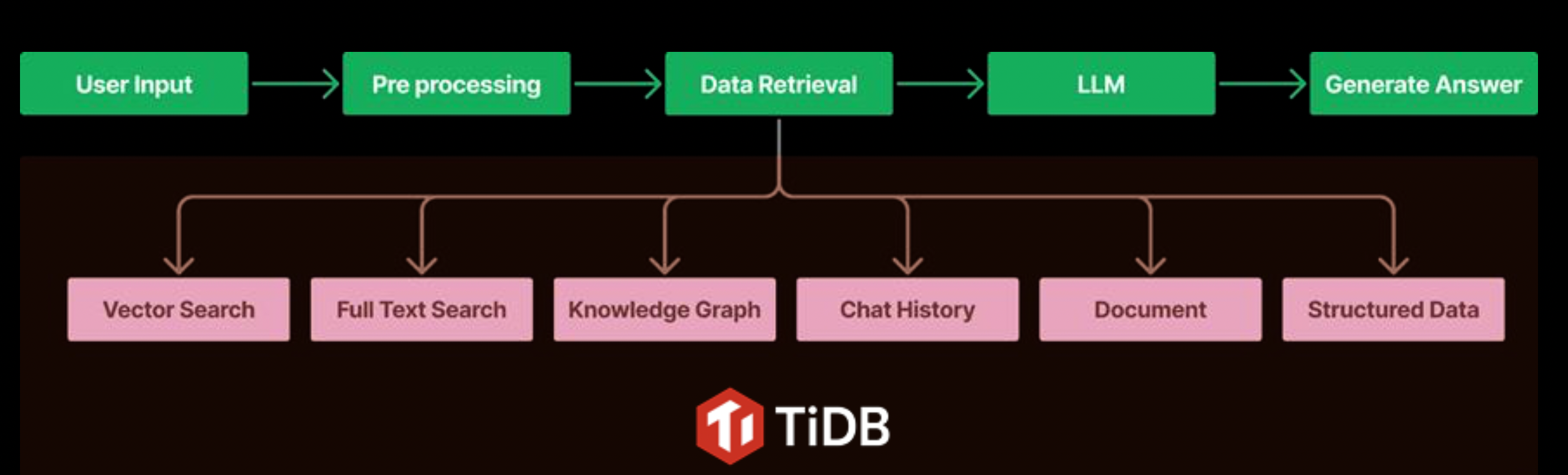
图 2
未来的数据库长什么样?
当然,向上支持 AI 应用只是数据库“职能”的一部分,作为基础设施,黄东旭强调下一代数据库还应当具备足够的可扩展性、灵活性、成本效益和简洁性。
以 SaaS 客户为例,很多企业向 TiDB 提出了支持创建上千万表、库的需求。这背后展示的不仅仅是数据量大小的可扩展性,而是更多数据维度的可扩展性,包括能保持的连接数,支持的表库数量,后台任务(例如 DDL)的扩展性,导入导出和 CDC 任务的速度和吞吐,多租户下的可观测性和运维性等等。
目前,TiDB 8.5 版本每个集群支持超过 100 万张表,并确保跨租户的一致查询性能。这项能力对于采用多租户架构和处理多样化工作负载的应用至关重要。
灵活性方面,进入 AI 时代发起数据请求的主体将从人变成 AI,这意味着数据库必须跳出过去的固有限制。“当需要提供千人千面的个性化服务时,就不能用固化的思路来解决问题,数据库本身的限制会反过来变成应用层面的限制。比如,你不能告诉 AI,我的底层数据库只支持静态的表。”黄东旭表示。
与此同时,随着数据量和数据维度的爆发式增长,规模和灵活性两个因素叠加将带来指数级的复杂性。对此,PingCAP 坚定地认为,未来的数据库一定是云原生与 AI 的结合,而下一代数据库内核关键的设计要点涉及两个方面:
第一,使用对象存储多 OLTP 引擎,借此可以规避分布式存储引擎带来的异常检测、数据搬迁等复杂性问题,同时最大限度地降低成本。黄东旭举例,过去的数据库是一个独立的软件,而今天在云上重新设计系统时,它们变成了一组微服务的组合,每个模块都在自我迭代,只需保持 Serverless 接口的稳定性。
第二,实现真正的多租户。“如今很多数据库厂商谈多租户时只谈隔离性,但隔离往往是容易解决的,其中最具挑战的问题是在多租户基础上实现资源共享。”正如文章开头举例,很多企业希望在保证重要业务 100%安全可靠隔离的情况下,在逻辑上把资源分配给其它优先级更低的业务使用。黄东旭表示,这恰恰是 TiDB 独创的能力。
举例来说,TiDB 8.5 也增强了资源组的管理能力,允许根据不同业务应用的需求设置资源使用上限,并控制后台任务的资源消耗,确保在高并发情况下关键业务负载的服务质量得到保障。这也是 TiDB 能够帮助企业实现成本效益的重要抓手。
“对于新一代引擎,其重点在于未来 3 年内的持续迭代、创新和验证,最终,我们希望可以逐步演进到‘TiDB one’的状态。对于开发者而言,最大的挑战之一是如何用单一数据库解决各种复杂问题,如果能够有一个 All-in-one 的解决方案,将极大地简化开发者的工作。”黄东旭强调。
TiDB V9“剧透”
遵循“All-in-one”这一目标和愿景,PingCAP 研发副总裁唐刘透露,明年发布的 TiDB V9 版本将继续专注于内部的优化和能力增强。具体来说,将在以下几个方面发力:
第一,稳定性,持续改进 TiDB 的内存控制机制,尽可能减少 OOM(Out Of Memory)错误的发生,确保系统的稳定运行;
第二,自动执行优化,TiDB V9 将引入类似于 Oracle SPN(Stored Procedure Native Compilation)的技术,实现自动化的性能优化;
第三,性能提升,TiDB V9 将正式发布多模混合搜索(Hybrid Search)功能,进一步提升 TiDB 的搜索能力;
第四,Cascades 优化器改进,确保在提升性能的同时,保持高度的稳定性;
第五,继续关注可扩展性,基于 8.5 版本的可扩展性基础,通过 TiCDC 和用户的业务生态进行对接,同时,基于海量数据加速批量 DDL,让整个业务的变得更加敏捷,支持企业业务的快速发展。
唐刘表示,过去十年的时间里,PingCAP 始终在探索和实践,并且努力寻找一个问题的答案——什么才是“好的数据库”。如今他的答案是,一个“好的数据库”首先要具备广泛的全球化应用,拥有大量的全球客户,并且始终专注于产品最核心的基本能力,持续不断地为客户创造价值,真正帮助用户的业务实现持续增长。
而对于 TiDB 来说,从产品创建和社区建设初期,到规模化商业化和出海阶段,从全面拥抱云原生技术,再到如今又全面拥抱 AI,可以看到,其正在不遗余力地朝着“All-in-one Database”的方向发展,提供全面的服务。这将是 TiDB 打造下一阶段的“好数据库”的新方向和新起点。




